DeepSeek V3からV3.2へ:アーキテクチャ、スパースアテンション、RLアップデート
Sebastian Raschka は、DeepSeek V3.2 のアーキテクチャ進化、スパースアテンションの導入、および RL 更新の詳細を分析し、その性能が GPT-5 や Gemini 3.0 Pro に匹敵するオープンウェイトモデルとしての地位を確立している点を指摘している。
キーポイント
DeepSeek V3.2 の技術的進化
V3 から V3.2 へ移行する過程で、スパースアテンション(Sparse Attention)や RL(強化学習)の更新など、アーキテクチャとトレーニング手法に重要な改良が加えられている。
競合他社との性能比較
ベンチマークにおいて GPT-5 や Gemini 3.0 Pro といった独自開発のフラッグシップモデルに匹敵する高いパフォーマンスを示しており、オープンウェイトモデルとしての実用性が証明されている。
ハードウェア移行とリリース戦略
NVIDIA から Huawei チップへの切り替えという大きな課題を乗り越えつつ、年末年始の大型連休中に新モデルをリリースする迅速な開発体制を示している。
DeepSeek V3.2-Exp の目的とアーキテクチャ
V3.2-Exp は直後にリリースされた V3.2 モデルのインフラストラクチャを準備するために意図的に公開され、両モデルともカスタムコードが必要な非標準的なスパースアテンションバリアントを採用しています。
ベースモデルと推論専用モデルの明確な区分
DeepSeek V3 はベースモデルとして、R1 は追加のポストトレーニングを経て推論能力に特化した専用モデルとして開発されたという、明確な役割分担が存在します。
ハイブリッド型と専用型の推論モデルのトレンド
Qwen3 のようにトークナイザー操作でモードを切り替えられるハイブリッド型や、推論に特化した専用型など、業界全体で両アプローチが並行して展開・検証されています。
DeepSeek のモデル戦略の転換
DeepSeek は専用推論モデル (R1) から、汎用性を高めるハイブリッドモデル (V3.1, V3.2) へと方向転換しており、R1 は推論手法開発のためのプロトタイプと見なされている。
影響分析・編集コメントを表示
影響分析
この記事は、DeepSeek V3.2 が単なるバージョンアップではなく、アーキテクチャとトレーニング手法の根本的な進化を経て、業界トップクラスの独自モデルと互角以上に戦える存在になったことを示しています。特にハードウェアの切り替えを成し遂げた点は、中国 AI エコシステムの強靭さと技術的自立を示す重要な指標であり、オープンソース LLM 市場における競争構造に大きな影響を与える可能性があります。
編集コメント
DeepSeek の技術的進歩とハードウェア移行の成功は、オープンソース AI の現状を再定義する重要な出来事です。特に中国企業による独自チップへの依存度が高まる中、この事例はサプライチェーンの多様化と技術的自立の可能性を示唆しています。
DeepSeek V3からV3.2へ:アーキテクチャ、スパースアテンション、そしてRLアップデート
DeepSeekの主力オープンウェイトモデルがどのように進化したかを理解する
 Sebastian Raschka, PhDDec 03, 20252541328Share最終更新日: 2026年1月1日
Sebastian Raschka, PhDDec 03, 20252541328Share最終更新日: 2026年1月1日
DeepSeek V3と同様に、チームは主要な米国の祝日週末に新しい主力モデルをリリースしました。DeepSeek V3.2が(GPT-5やGemini 3.0 Proと同等の)非常に優れた性能を示し、さらにオープンウェイトモデルとしても利用可能であることを考えると、これは間違いなくより詳しく検討する価値があります。
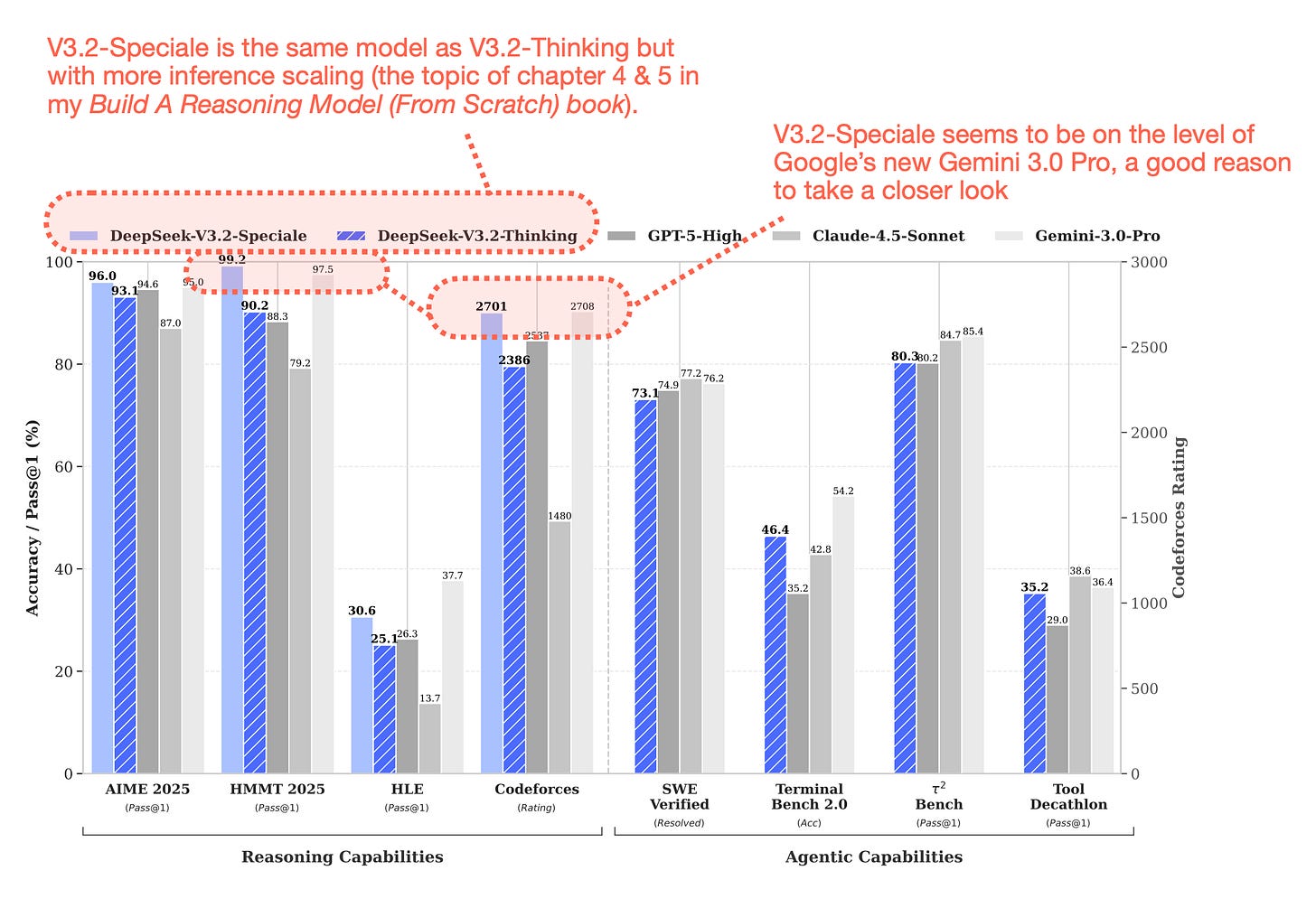 図1: DeepSeek V3.2とプロプライエタリな主力モデルとのベンチマーク比較。これはDeepSeek V3.2レポートからの注釈付き図です。
図1: DeepSeek V3.2とプロプライエタリな主力モデルとのベンチマーク比較。これはDeepSeek V3.2レポートからの注釈付き図です。
私は前身であるDeepSeek V3について、『The Big LLM Architecture Comparison』記事の冒頭で取り上げました。この記事は、新しいアーキテクチャがリリースされるたびに数ヶ月かけて拡張し続けています。当初、家族と過ごした感謝祭の休暇から戻ったばかりの私は、この新しいDeepSeek V3.2リリースについて、単に記事に別のセクションを追加して「だけ」拡張するつもりでした。しかし、カバーすべき興味深い情報があまりにも多いことに気づき、より長い独立した記事にすることに決めました。
彼らの技術レポートからはカバーすべき興味深い点が多く、学ぶべきこともたくさんあります。それでは始めましょう!
- DeepSeekのリリースタイムライン
DeepSeek V3は2024年12月のリリース当初すぐに人気を博したわけではありませんでしたが、DeepSeek R1推論モデル(同一のアーキテクチャを使用し、DeepSeek V3をベースモデルとする)のおかげで、DeepSeekは最も人気のあるオープンウェイトモデルの一つとなり、OpenAI、Google、xAI、Anthropicなどのプロプライエタリモデルに対する正当な代替手段となりました。
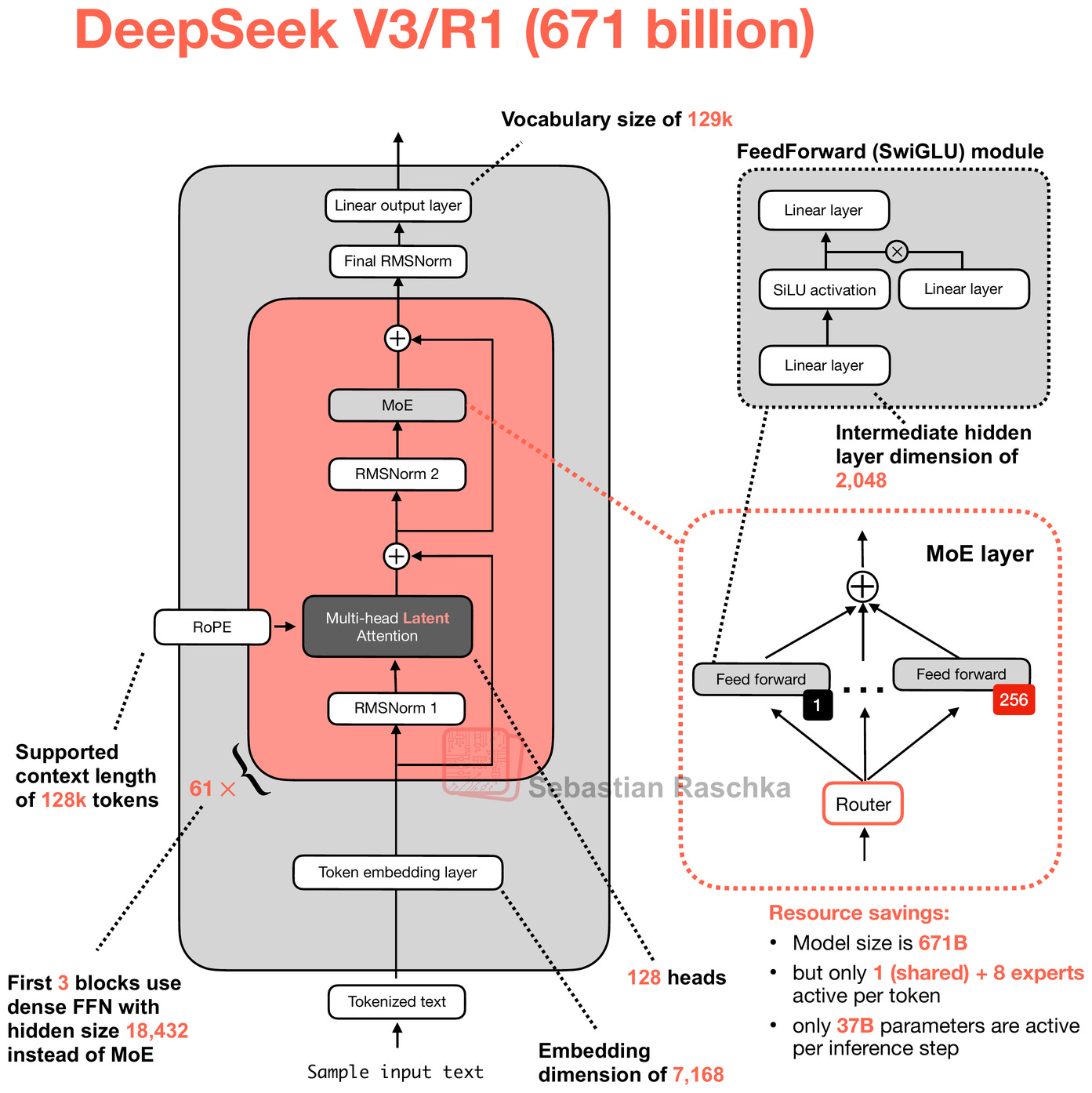 図2: 2024年12月時点のDeepSeek V3/R1アーキテクチャ。アーキテクチャの詳細については後ほど再訪して議論します。
図2: 2024年12月時点のDeepSeek V3/R1アーキテクチャ。アーキテクチャの詳細については後ほど再訪して議論します。
では、V3/R1以降、何が新しいのでしょうか?DeepSeekチームは今年、非常に忙しかったに違いありません。しかし、DeepSeek R1以降、過去10〜11ヶ月間、メジャーリリースはありませんでした。
個人的には、LLMのメジャーリリースには約1年かかるのは合理的だと思います。なぜなら、それは非常に多くの作業を伴うからです。しかし、様々なソーシャルメディアプラットフォームで、人々がチームを「終わった」(一発屋として)と宣言しているのを目にしました。
DeepSeekチームは、NVIDIAからHuaweiチップへの切り替えを乗り切るのに忙しかったことでしょう。ちなみに、私は彼らと関係があるわけでも、話したこともありません。ここにあるすべての情報は公開情報に基づいています。私の知る限り、彼らはNVIDIAチップの使用に戻っています。
また、彼らが何もリリースしていなかったわけでもありません。今年は、例えばDeepSeek V3.1やV3.2-Expなど、いくつかの小規模なリリースが少しずつ行われてきました。
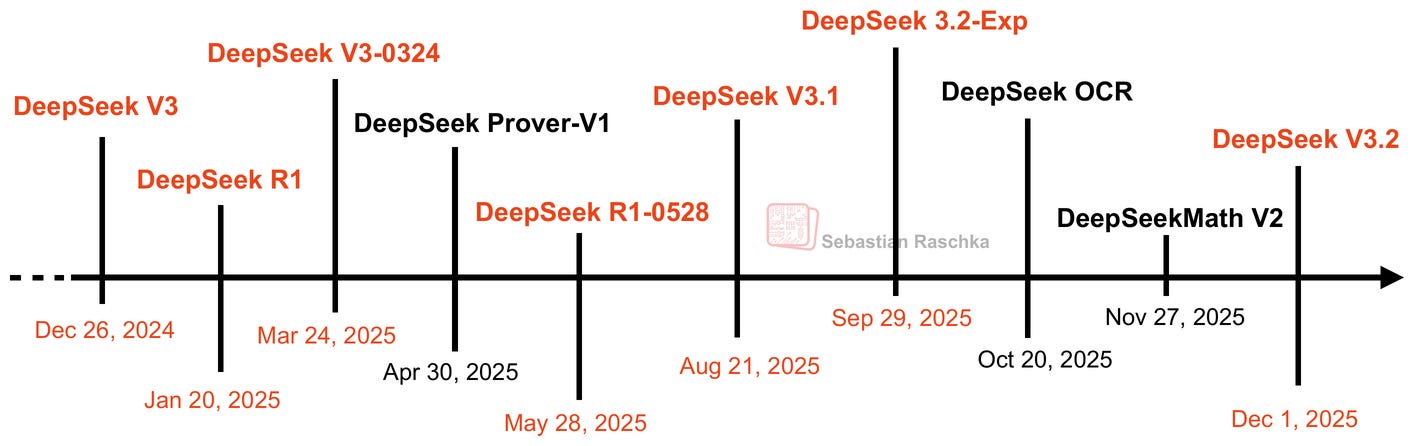 図3: 昨年以降のDeepSeekリリース。主要モデルは赤色で示されています。
図3: 昨年以降のDeepSeekリリース。主要モデルは赤色で示されています。
私が9月に予測したように、DeepSeek V3.2-Expリリースは、エコシステムと推論インフラを整備し、ちょうどリリースされたV3.2モデルをホストできるようにすることを意図したものでした。
V3.2-ExpとV3.2は、カスタムコードを必要とする非標準のスパースアテンションの変種を使用していますが、このメカニズムについては後ほど詳しく説明します。(私は以前の『Beyond Standard LLMs』記事でこれを取り上げようと思いましたが、その頃Kimi Linearがリリースされ、その記事の新しいアテンション変種に関するセクションではそれを優先しました。)
- ハイブリッド対専用推論モデル
モデルの詳細についてさらに議論する前に、全体的なモデルの種類について議論する価値があるかもしれません。当初、DeepSeek V3はベースモデルとしてリリースされ、DeepSeek R1は追加のポストトレーニングを施して専用の推論モデルを開発しました。この手順は下図にまとめられています。
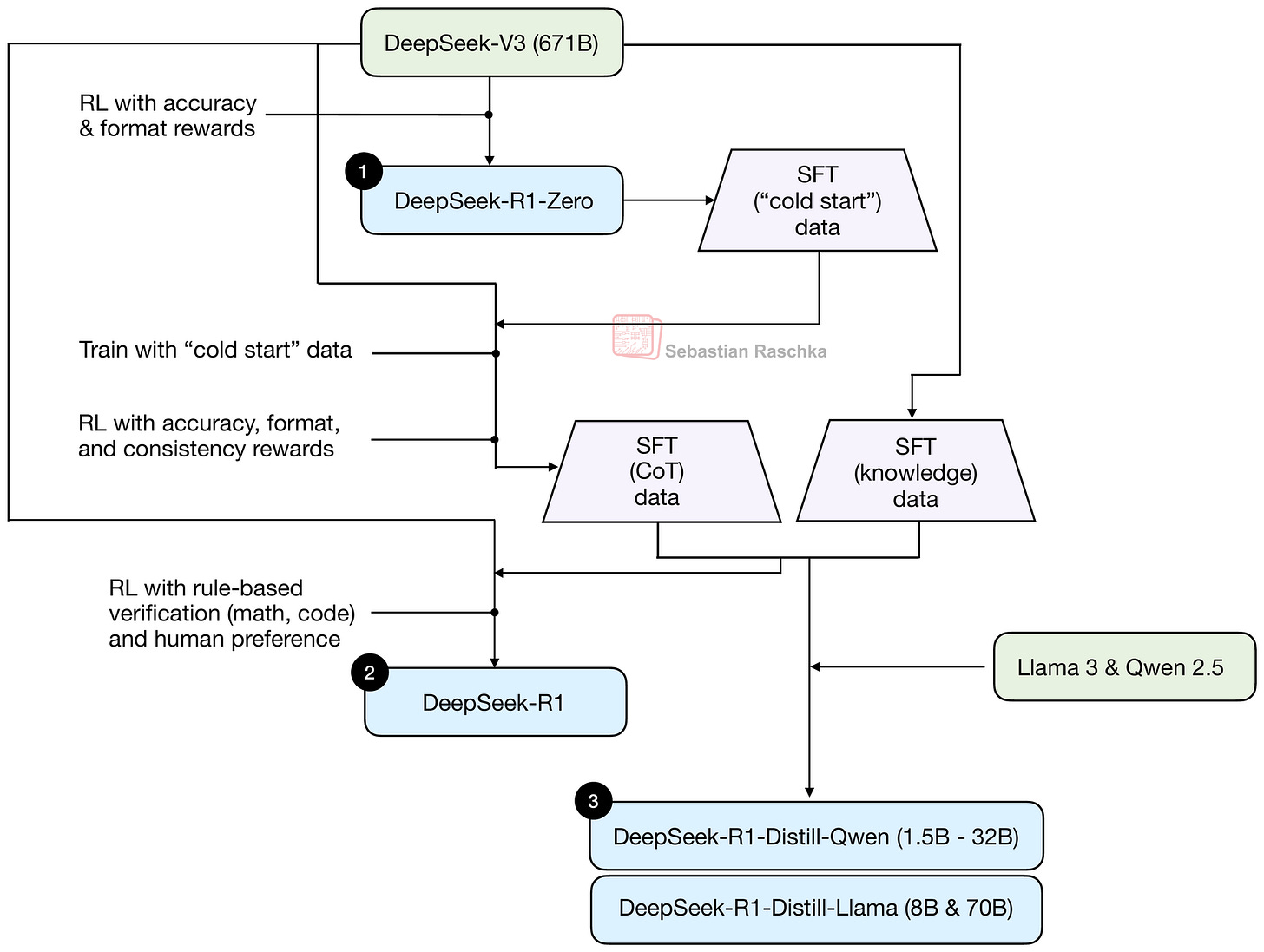 図4: DeepSeek R1トレーニングパイプラインの概要。この図は、私のより詳細な『Understanding Reasoning LLMs』記事からのものです。
図4: DeepSeek R1トレーニングパイプラインの概要。この図は、私のより詳細な『Understanding Reasoning LLMs』記事からのものです。
上図のトレーニングパイプラインについての詳細は、私の『Understanding Reasoning LLMs』記事で読むことができます。
ここで注目すべきは、DeepSeek V3がベースモデルであり、DeepSeek R1が専用の推論モデルであるということです。
DeepSeekと並行して、他のチームも多くの非常に強力なオープンウェイト推論モデルをリリースしてきました。今年最も強力なオープンウェイトモデルの一つはQwen3でした。当初、それはハイブリッド推論モデルとしてリリースされました。これは、ユーザーが同じモデル内で推論モードと非推論モードを切り替えることができることを意味します。(Qwen3の場合、この切り替えはトークナイザーを介して<think></think>タグを追加/省略することで有効になりました。)
それ以来、LLMチームは専用の推論モデルとInstruct/Reasoningハイブリッドモデルの両方をリリースしてきました(そして、場合によっては両者の間を行き来しています)。以下のタイムラインに示すように。
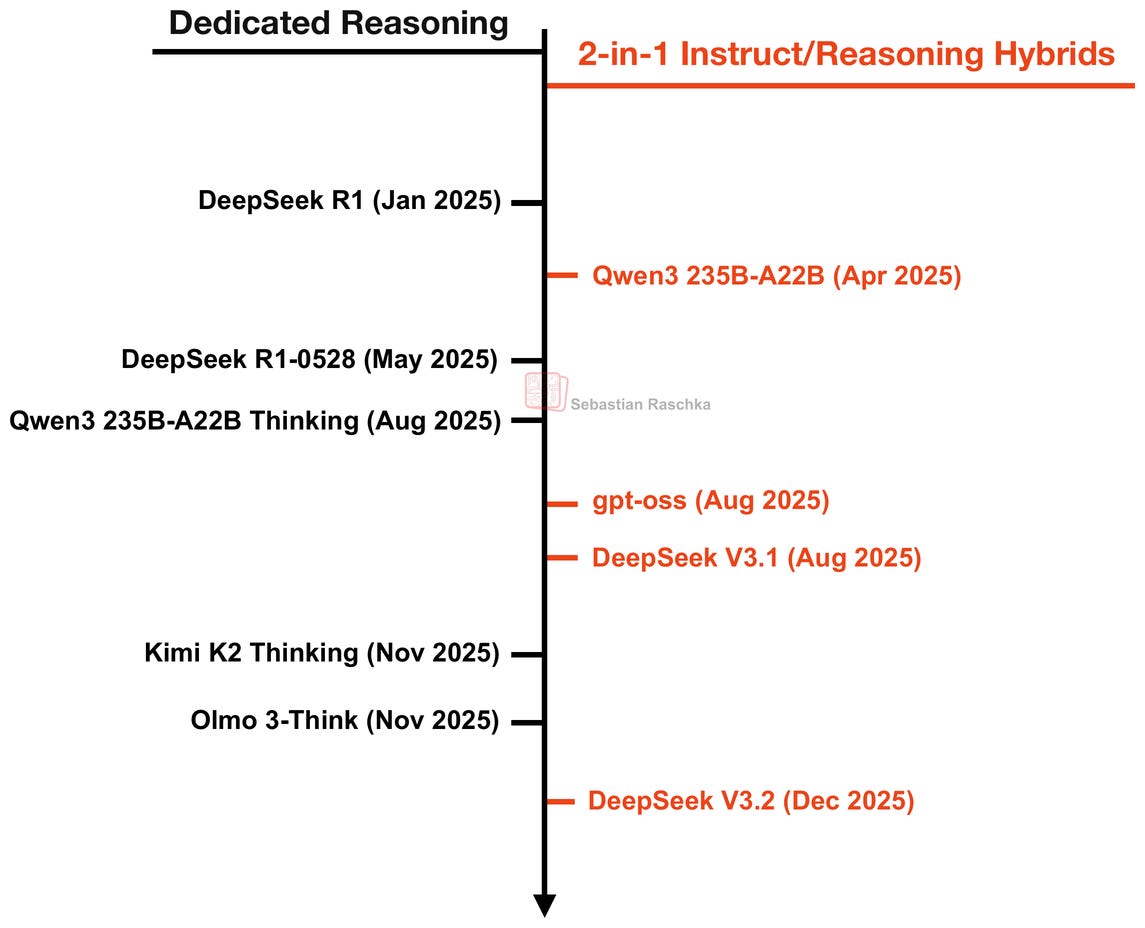 図5: 今年リリースされた推論モデルとハイブリッドモデルの一部のタイムライン。
図5: 今年リリースされた推論モデルとハイブリッドモデルの一部のタイムライン。
例えば、Qwen3はハイブリッドモデルとして始まりましたが、Qwenチームはその後、開発が容易でそれぞれのユースケースでより良いパフォーマンスを発揮するため、個別の指示モデルと推論モデルをリリースしました。
OpenAIのgpt-ossのようなモデルは、ユーザーがシステムプロンプトを介して推論の労力を選択できるハイブリッドバリアントのみで提供されています(GPT-5とGPT-5.1でも同様に処理されていると私は疑っています)。
そしてDeepSeekの場合、彼らは専用の推論モデル(R1)からハイブリッドモデル(V3.1とV3.2)へと逆の方向に進んだように見えます。しかし、R1は主に推論手法と当時最良の推論モデルを開発するための研究プロジェクトだったのではないかと私は考えています。V3.2リリースは、異なるユースケースに対して最良の全体的なモデルを開発することに重点が置かれているかもしれません。(ここでは、R1はむしろテストベッドやプロトタイプモデルのようなものでした。)
また、DeepSeekチームが推論能力を備えたV3.1とV3.2を開発した一方で、彼らはまだ専用のR2モデルに取り組んでいる可能性もあると私は考えています。
- DeepSeek V3からV3.1へ
新しいDeepSeek V3.2リリースについてより詳細に議論する前に、V3からV3.1への主な変更点の概要から始めると役立つと思いました。
3.1 DeepSeek V3の概要とMulti-Head Latent Attention (MLA)
私はすでにDeepSeek V3とR1について、他のいくつかの記事で非常に詳細に議論しました。主なポイントを要約すると、DeepSeek V3は、Mixture-of-Experts (MoE) とMulti-Head Latent Attention (MLA) という2つの注目すべきアーキテクチャ側面を使用するベースモデルです。
MoEについてはこの時点でよくご存知だと思いますので、ここでは紹介を省略します。ただし、さらに読みたい場合は、より多くの文脈を得るために私の『The Big Architecture Comparison』記事の短い概要をお勧めします。
もう一つの注目すべき点はMLAの使用です。MLAはDeepSeek V2、V3、R1で使用されており、特にKVキャッシュと相性の良いメモリ節約戦略を提供します。MLAの考え方は、キーとバリューのテンソルを低次元空間に圧縮することです。
原文を表示
From DeepSeek V3 to V3.2: Architecture, Sparse Attention, and RL Updates
Understanding How DeepSeek's Flagship Open-Weight Models Evolved
Sebastian Raschka, PhDDec 03, 20252541328ShareLast updated: January 1st, 2026
Similar to DeepSeek V3, the team released their new flagship model over a major US holiday weekend. Given DeepSeek V3.2’s really good performance (on GPT-5 and Gemini 3.0 Pro) level, and the fact that it’s also available as an open-weight model, it’s definitely worth a closer look.
Figure 1: Benchmark comparison between DeepSeek V3.2 and proprietary flagship models. This is an annotated figure from the DeepSeek V3.2 report.
I covered the predecessor, DeepSeek V3, at the very beginning of my The Big LLM Architecture Comparison article, which I kept extending over the months as new architectures got released. Originally, as I just got back from Thanksgiving holidays with my family, I planned to “just” extend the article with this new DeepSeek V3.2 release by adding another section, but I then realized that there’s just too much interesting information to cover, so I decided to make this a longer, standalone article.
There’s a lot of interesting ground to cover and a lot to learn from their technical reports, so let’s get started!
- The DeepSeek Release Timeline
While DeepSeek V3 wasn’t popular immediately upon release in December 2024, the DeepSeek R1 reasoning model (based on the identical architecture, using DeepSeek V3 as a base model) helped DeepSeek become one of the most popular open-weight models and a legit alternative to proprietary models such as the ones by OpenAI, Google, xAI, and Anthropic.
Figure 2: DeepSeek V3/R1 architecture from December 2024. We will revisit and discuss architectural details in a later section.
So, what’s new since V3/R1? I am sure that the DeepSeek team has been super busy this year. However, there hasn’t been a major release in the last 10-11 months since DeepSeek R1.
Personally, I think it’s reasonable to go ~1 year for a major LLM release since it’s A LOT of work. However, I saw on various social media platforms that people were pronouncing the team “dead” (as a one-hit wonder).
I am sure the DeepSeek team has also been busy navigating the switch from NVIDIA to Huawei chips. By the way, I am not affiliated with them or have spoken with them; everything here is based on public information. As far as I know, they are back to using NVIDIA chips.
Finally, it’s also not that they haven’t released anything. There have been a couple of smaller releases that trickled in this year, for instance, DeepSeek V3.1 and V3.2-Exp.
Figure 3: DeepSeek releases since last year. The main models are shown in red.
As I predicted back in September, the DeepSeek V3.2-Exp release was intended to get the ecosystem and inference infrastructure ready to host the just-released V3.2 model.
V3.2-Exp and V3.2 use a non-standard sparse attention variant that requires custom code, but more on this mechanism later. (I was tempted to cover it in my previous Beyond Standard LLMs article, but Kimi Linear was released around then, which I prioritized for this article section on new attention variants.)
- Hybrid Versus Dedicated Reasoning Models
Before discussing further model details, it might be worthwhile to discuss the overall model types. Originally, DeepSeek V3 was released as a base model, and DeepSeek R1 added additional post-training to develop a dedicated reasoning model. This procedure is summarized in the figure below.
Figure 4: Overview of the DeepSeek R1 training pipeline. This figure is from my more detailed Understanding Reasoning LLMs article.
You can read more about the training pipeline in the figure above in my Understanding Reasoning LLMs article.
What’s worthwhile noting here is that DeepSeek V3 is a base model, and DeepSeek R1 is a dedicated reasoning model.
In parallel with DeepSeek, other teams have also released many really strong open-weight reasoning models. One of the strongest open-weight models this year was Qwen3. Originally, it was released as a hybrid reasoning model, which means that users were able to toggle between reasoning and non-reasoning modes within the same model. (In the case of Qwen3, this toggling was enabled via the tokenizer by adding/omitting <think></think>
Since then, LLM teams have released (and in some cases gone back and forth between) both dedicated reasoning models and Instruct/Reasoning hybrid models, as shown in the timeline below.
Figure 5: The timeline of some of the reasoning and hybrid models released this year.
For instance, Qwen3 started out as a hybrid model, but the Qwen team then later released separate instruct and reasoning models as they were easier to develop and yielded better performance in each respective use case.
Some models like OpenAI’s gpt-oss only come in a hybrid variant where users can choose the reasoning effort via a system prompt (I suspect this is handled similarly in GPT-5 and GPT-5.1).
And in the case of DeepSeek, it looks like they moved in the opposite direction from a dedicated reasoning model (R1) to a hybrid model (V3.1 and V3.2). However, I suspect that R1 was mainly a research project to develop reasoning methods and the best reasoning model at the time. The V3.2 release may be more about developing the best overall model for different use cases. (Here, R1 was more like a testbed or prototype model.)
And I also suspect that, while the DeepSeek team developed V3.1 and V3.2 with reasoning capabilities, they might still be working on a dedicated R2 model.
- From DeepSeek V3 to V3.1
Before discussing the new DeepSeek V3.2 release in more detail, I thought it would be helpful to start with an overview of the main changes going from V3 to V3.1.
3.1 DeepSeek V3 Overview and Multi-Head Latent Attention (MLA)
I already discussed DeepSeek V3 and R1 in great detail in several other articles. To summarize the main points, DeepSeek V3 is a base model that uses two noteworthy architecture aspects: Mixture-of-Experts (MoE) and Multi-Head Latent Attention (MLA).
I think you are probably well familiar with MoE at this point, so I am skipping the introduction here. However, if you want to read more, I recommend the short overview in my The Big Architecture Comparison article for more context.
The other noteworthy highlight is the use of MLA. MLA, which is used in DeepSeek V2, V3, and R1, offers a memory-saving strategy that pairs particularly well with KV caching. The idea in MLA is that it compresses the key and value tensors into a lower-dimensional space before storing them in the KV cache.
At inference time, these compressed tensors are projected back to their original size before being used, as shown in the figure below. This adds an extra matrix multiplication but reduces memory usage.
(As a side note, the queries are also compressed, but only during training, not inference.)
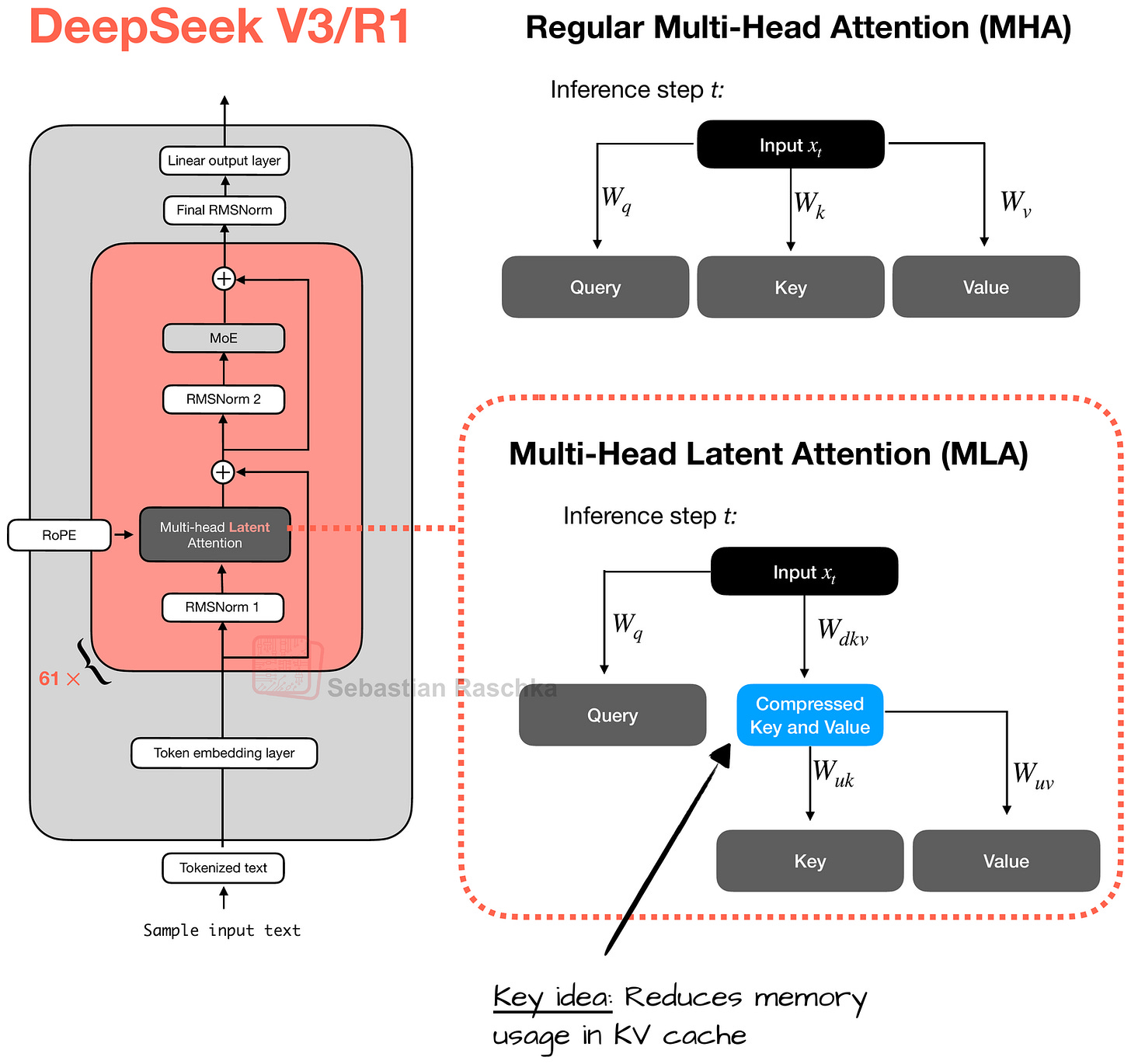 Figure 6: Multi-Head Latent Attention (MLA) in DeepSeek V3/R1. (The compressed space of the query vector is not shown for simplicity.)
Figure 6: Multi-Head Latent Attention (MLA) in DeepSeek V3/R1. (The compressed space of the query vector is not shown for simplicity.)
The figure above illustrates the main idea behind MLA, where the keys and values are first projected into a latent vector, which can then be stored in the KV cache to reduce memory requirements. This requires a later up-projection back into the original key-value space, but overall it improves efficiency (as an analogy, you can think of the down- and up-projections in LoRA).
Note that the query is also projected into a separate compressed space, similar to what’s shown for the keys and values. However, I omitted it in the figure above for simplicity.
By the way, as mentioned earlier, MLA is not new in DeepSeek V3, as its DeepSeek V2 predecessor also used (and even introduced) it.
3.2 DeepSeek R1 Overview and Reinforcement Learning with Verifiable Rewards (RLVR)
DeepSeek R1 uses the same architecture as DeepSeek V3 above. The difference is the training recipe. I.e., using DeepSeek V3 as the base model, DeepSeek R1 was focused on the Reinforcement Learning with Verifiable Rewards (RLVR) method to improve the reasoning capabilities of the model.
The core idea in RLVR is to have the model learn from responses that can be verified symbolically or programmatically, such as math and code (but this can, of course, also be extended beyond these two domains).
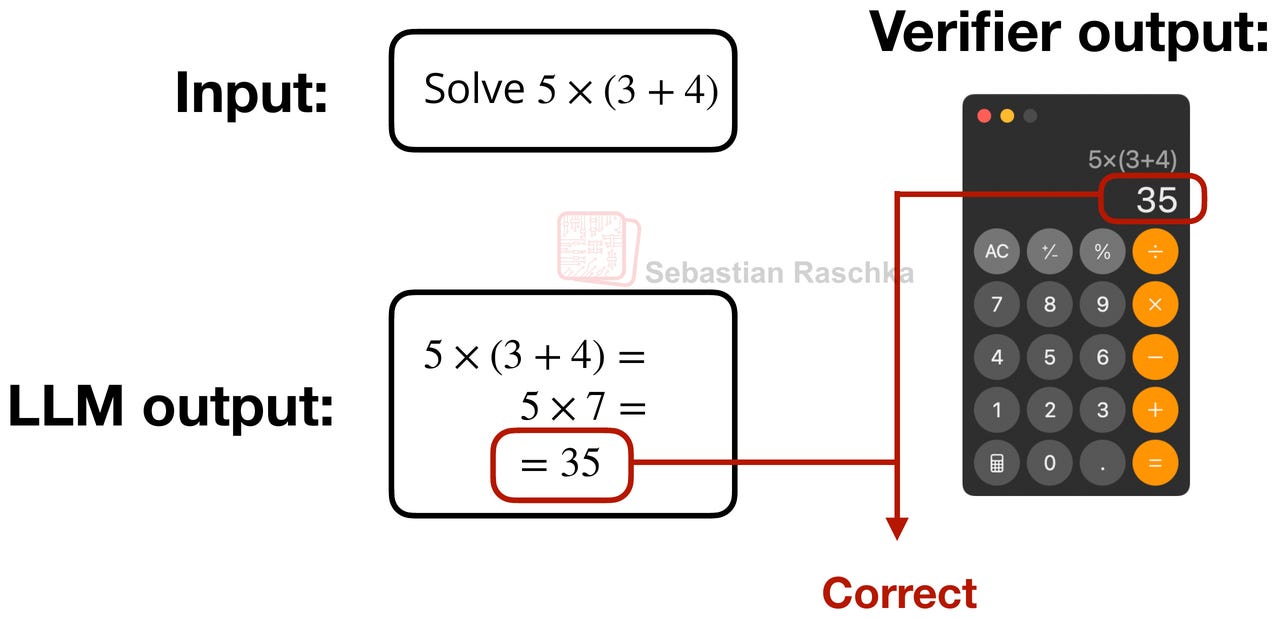 Figure 7: An example of a verifiable task.
Figure 7: An example of a verifiable task.
The GRPO algorithm, which is short for Group Relative Policy Optimization, is essentially a simpler variant of the Proximal Policy Optimization (PPO) algorithm that is popular in Reinforcement Learning with Human Feedback (RLHF), which is used for LLM alignment.
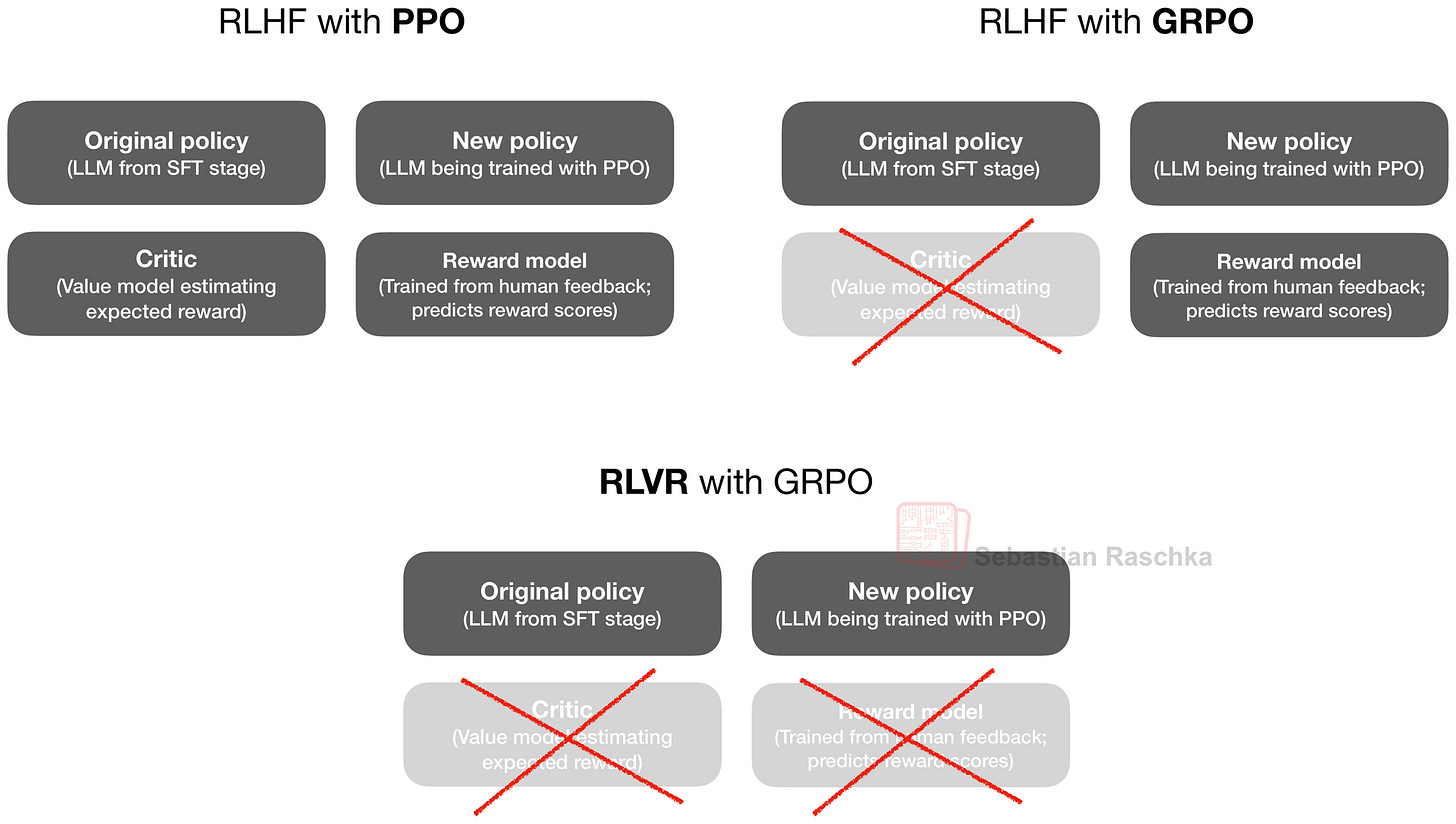 Figure 8: Comparison of reinforcement learning setups in LLM training. Traditional RLHF with PPO uses both a reward model (trained on human preferences) and a critic (value model) to guide learning. GRPO eliminates the critic model. RLVR with GRPO goes a step further by removing the reward model, relying instead on verifiable rewards from symbolic tools such as calculators or compilers.
Figure 8: Comparison of reinforcement learning setups in LLM training. Traditional RLHF with PPO uses both a reward model (trained on human preferences) and a critic (value model) to guide learning. GRPO eliminates the critic model. RLVR with GRPO goes a step further by removing the reward model, relying instead on verifiable rewards from symbolic tools such as calculators or compilers.
I covered the RLVR training with their GRPO algorithm in more detail (including the math behind it) in my The State of Reinforcement Learning for LLM Reasoning if you are interested in additional information.
3.3 DeepSeek R1-0528 Version Upgrade
As the DeepSeek team stated themselves, DeepSeek R1-0528 is basically a “minor version upgrade.”
The architecture remains the same as in DeepSeek V3/R1, and the improvements are on the training side to bring it up to par with OpenAI o3 and Gemini 2.5 Pro at the time.
Unfortunately, the DeepSeek team didn’t release any specific information describing how this was achieved; however, they stated that it partly comes from optimizations in their post-training pipeline. Also, based on what’s been shared, I think it’s likely that the hosted version of the model uses more computational resources at inference time (longer reas
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み