【AIニュース】ImageGenはAGIへの道を進んでいる
Latent Spaceの記事は、GPT-Image-2などの高度な画像生成モデルが単なる創作ツールではなく、コード生成と連携して「ループを閉じる」ことでAGI実現と収益確保に不可欠な要素であることを論じている。
キーポイント
画像生成モデルのAGIへの貢献
テキストやコードだけでなく、視覚的多モーダル生成(透明性を含む)を扱うことで、AGIの「G(Generative)」能力が真に発揮され、単なるプログラミング支援を超えた価値を生む。
Codexとの統合による生産性革命
GPT-Image-2とCodexを組み合わせることで、コーディング中にアセットを反復的に生成できる「スキル」として提供され、開発フローを大幅に効率化する。
Claude Designからの覇権交代
以前の注目技術であったClaude Designを凌駕し、「ループを閉じられるか」が勝敗を決する鍵となっており、GPT-Image-2がその主導権を握りつつある。
GPUリソースの優先順位付け
AGI追求と収益目標を達成するためには、画像生成のような「サイドクエスト」を無視せず、限られたGPU容量を効果的に配分する必要があるという結論に至っている。
OpenAIのクラウド分散戦略とパートナーシップ変更
OpenAIはMicrosoftとの独占的関係を緩和し、AWSやGoogle TPUなど他クラウドでもモデルを提供可能とし、2032年までのコミットメントを表明した。
GPT-5.5の性能評価と開発者エコノミクスの変化
GPT-5.5は総合的に向上したもののOpus 4.7に劣る一方、GitHub Copilotの従量制課金化やCodexの使用倍率の文脈から、エージェントワークフローにおけるコスト構造が明確になっている。
XiaomiのMiMo-V2.5シリーズ公開と技術的特徴
@XiaomiMiMoがMITライセンスでMiMo-V2.5-ProおよびMiMo-V2.5をオープンソース化し、それぞれ1兆トークン規模の総パラメータを持つMoEアーキテクチャを採用。Pro版はエージェント/コーディング向け、小規模版はオムニモーダルエージェントとして位置付けられている。
影響分析・編集コメントを表示
影響分析
この記事は、現在のAI業界における「テキスト・コード中心」の議論から、「マルチモーダル(特に画像生成)」へのシフトがAGI達成において決定的であることを示唆しています。OpenAIのGPT-Image-2がClaudeなどの競合を凌駕しつつある現状を踏まえ、開発者は画像生成能力をコード生成と統合したエコシステムへの移行を余儀なくされる可能性があります。これは、AIツールの選定基準が「精度」だけでなく「ワークフローへの統合度」という観点で再定義されることを意味します。
編集コメント
画像生成がAGIの「必須要件」として再評価されている点は興味深いです。単なるビジュアル作成ではなく、コード生成との融合による「ループの完結」が競争優位性の源泉となる未来が来そうです。
各ラボがAnthropicのような形態(つまり、コーディングやエンタープライズAIに焦点を当て、より優れたPDF、PPT、スプレッドシートを生み出すこと)へと急ぐ中、GPT-Image-2が引き続きより創造的なアプリケーションを牽引しているのを見るのは依然として refreshing です。例えば、以下のようなものです:
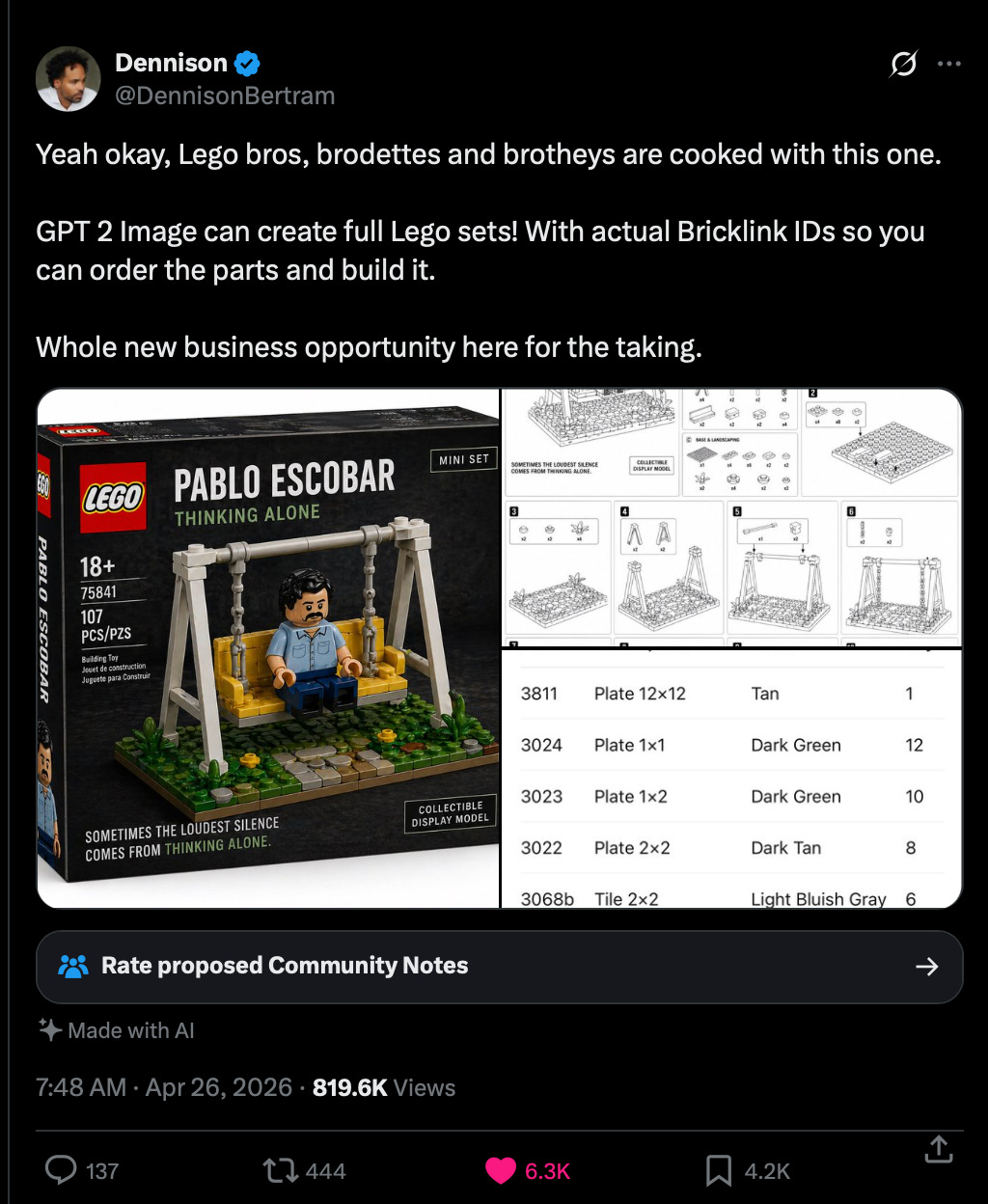
レゴ・ロッキー・スペース・フレンドがデートナイトにおいて極めて高いNPS(Net Promoter Score:顧客満足度指標)スコアを記録していることを考慮すれば、低ハルシネーション(幻覚)、研究支援機能付きの完全なマルチモーダル推論画像モデルがいかに優れているかはお分かりいただけるでしょう。
もちろん、教育にも役立ちます:

tweet
あるいはポップカルチャーにも:

あるいは、精密で清潔なインフォグラフィックスにも:
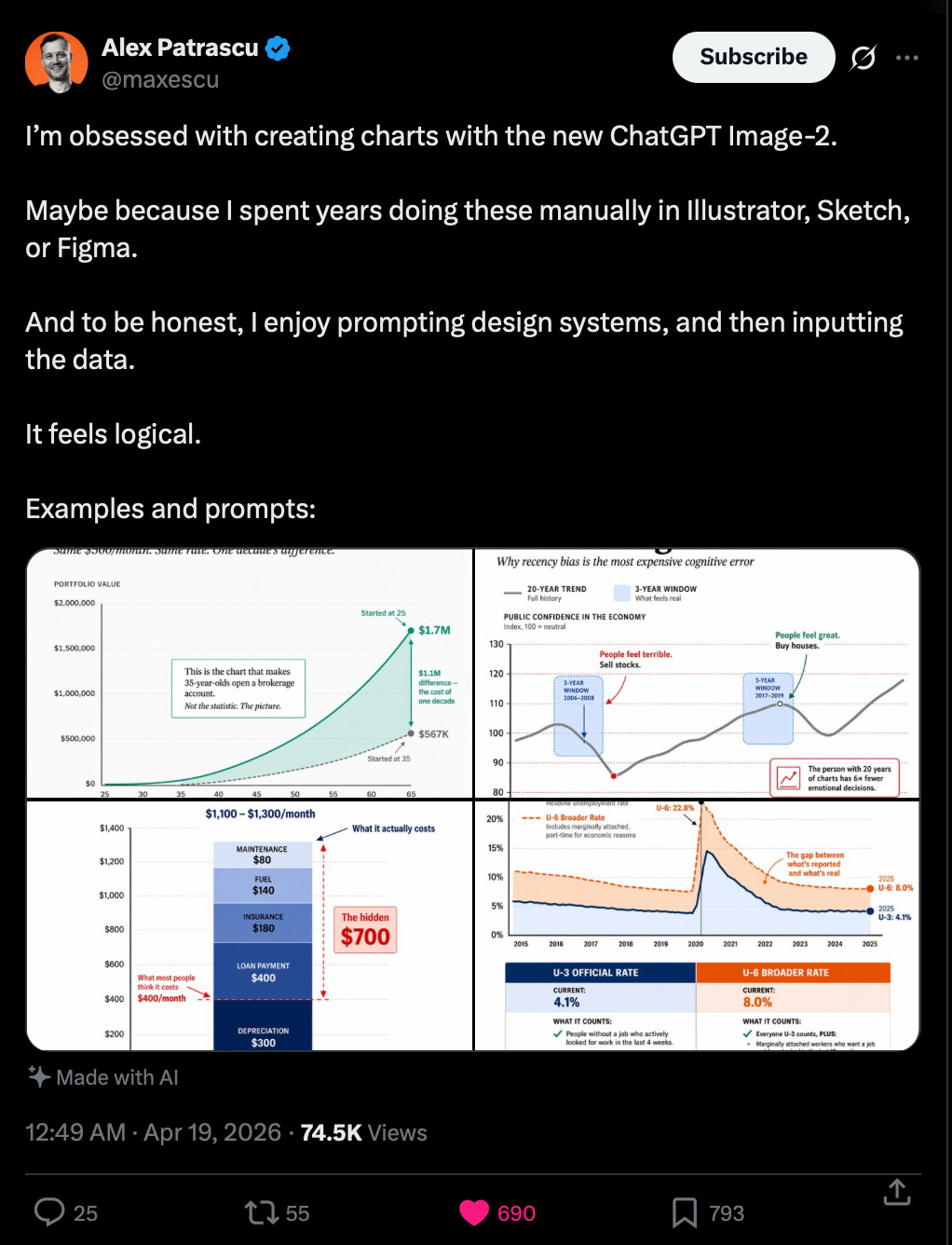
もちろん、GPT-Image-2とCodexの組み合わせもあります。これはCodex内で「スキル」として利用可能で、コードを書きながら反復的にアセット(資産/素材)を生成するために使用できます。
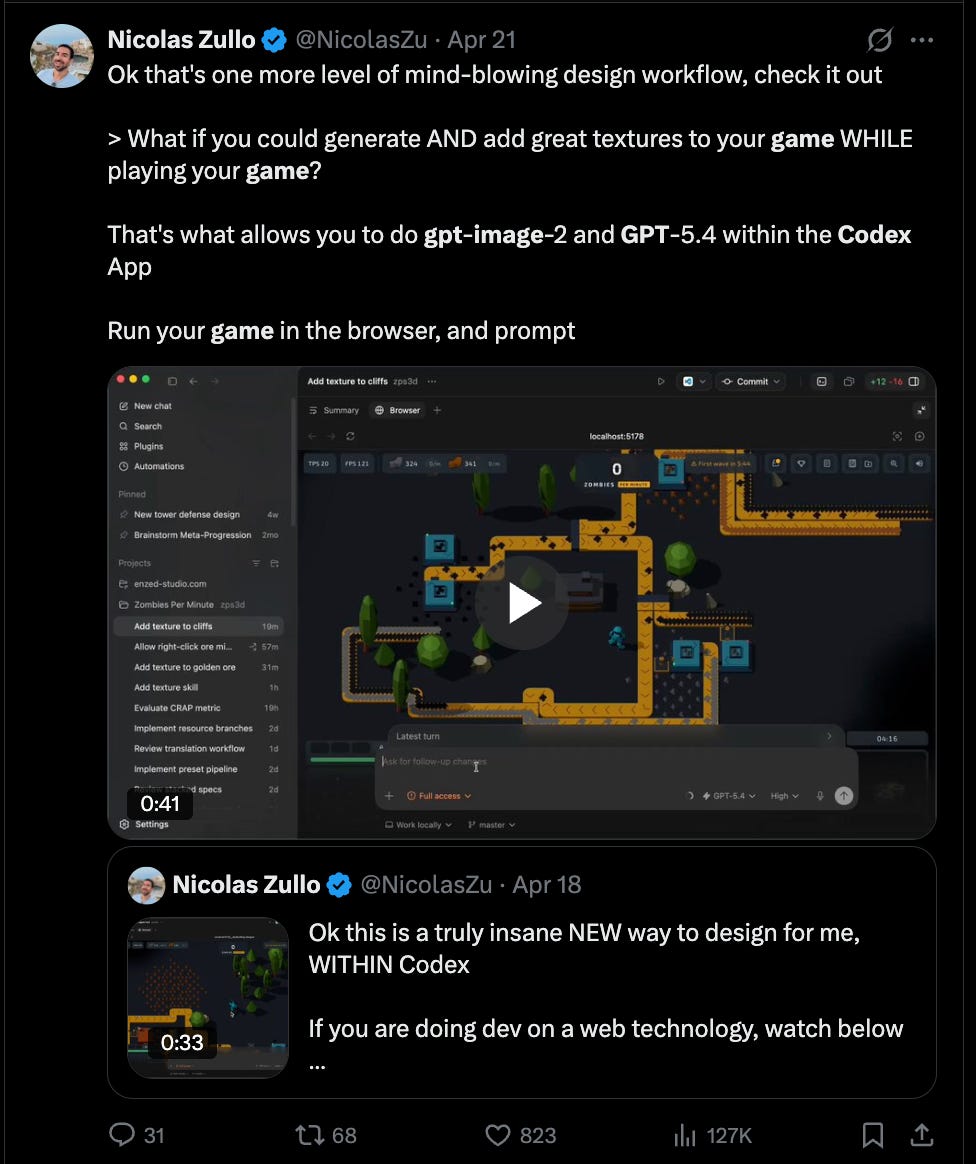
そしてあっという間に、かつての注目の的だったClaude Designはもはや議論の対象から外れてしまいました。単純に言えば、「ループを閉じる」ことができる者が勝者となります。
しかし、ここで私たちが主張しているのはそのような議論ではありません。私たちが焦点を当てているのは、非常に文字通りかつ深刻な質問です。つまり、「サイドクエスト(脇道)」を避け、AGI(人工一般知能)の達成に真摯に取り組む場合、その過程で倒れないために必要な収益、効率性、資金調達目標を達成するために、Nano BananaやGPT-Image-2、Grok Imagineのようなモデルは、限られたGPU(グラフィックスプロセッシングユニット)容量の必要な使用と言えるのか否かという点です。
答えは次第に明確になってきています:はいです。単に「ループを閉じる」からというだけでなく、テキストやコード、構造化された出力の生成だけでは限界があるからです。マルチモーダルな音声と視覚の生成(透明性を含む!)が可能になれば、はじめて「AGI」における「G(General:汎用)」の部分を真に発揮できます。結局のところ、もし AI がプログラミング職を狭い範囲で奪うだけなら、それは何の役にも立ちません。
ちなみに、以前は画像生成において馬に乗る宇宙飛行士を描くのは難しかったのですが、次は宇宙飛行士に跨がる馬になり、そして今では……
2026年4月26日〜4月27日の AI ニュース。私たちは 12 のサブレッド、544 件の Twitter、さらに Discord は確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のためお知らせしますが、AINews は現在 Latent Space の一部となっています。メール配信頻度を選択できます!
AI Twitter recap
OpenAI のディストリビューションシフト、GPT-5.5 のベンチマーク、そして Codex/Copilot の価格シグナル
OpenAI、Azureの独占性を緩和:@sama氏は、Microsoftとのパートナーシップを更新し、Microsoftが主要なクラウド事業者であり続ける一方で、OpenAIはすべてのクラウドで製品を提供できるようになったと述べた。製品/モデルのコミットメントは2032年まで、収益配分は2030年まで延長される。@scaling01氏と@kimmonismus氏は、この変更によりOpenAIがGoogle TPUやAWS Trainium、Bedrock経由で配布可能になり、MicrosoftのOpenAI知財へのライセンスが非独占的になるという含意をすぐに導き出した。@ajassy氏は、OpenAIのモデルが数週間以内にAWS Bedrockに登場すると確認した。@simonw氏は、新しい文言は以前のAGI条項が事実上削除されたことを意味すると指摘した。
GPT-5.5は広範なアップグレードだが、一様に優位というわけではない:@htihle氏によるコミュニティ評価では、GPT-5.5のno-thinking(思考なし)モードがWeirdMLで57.4%から67.1%に向上したが、より少ないトークン数で76.4%を記録するOpus 4.7のno-thinkingモードには依然として劣っている。@arena氏によるLMSYS Arenaの結果では、GPT-5.5はCode Arenaで9位、Documentで6位、Textで7位、Mathで3位、Searchで2位、Visionで5位、Expert Arenaで5位となった。また、現在の評価は中高度な推論(medium/high reasoning)をカバーしており、xHighはまだ保留中であることがArenaで明確になった(1, 2)。@gdb氏によるGPUカーネルなどの難易度の高いコーディングタスクについては、実務者からのフィードバックは肯定的だったが、@htihle氏からはno-thinkingモードにおける「圧縮CoT(Chain of Thought)の漏洩」や malformed(不正な)出力の報告もあった。
開発者エコノミクスがより明確化している:GitHub は 6 月 1 日付で Copilot の使用方法ベースの課金へ移行すると発表した。エージェント型ワークフローがランタイムを大幅に消費するようになる中、これは重要な転換点である。これと並行して、@Hangsiin 氏は Codex の使用量倍率を文書化した:GPT-5.4 fast は 2 倍、GPT-5.5 fast は 2.5 倍であり、5.4-mini および GPT-5.3-Codex は大幅に安価である。@sama 氏は、Codex が $20 で提供される場合でも強力な価値を提供すると主張した。OpenAI もまた、@OpenAIDevs 経由で Symphony をオープンソース化した。これは「未解決のイシュー → エージェント → プルリクエスト(PR)→ 人間のレビュー」へとIssueトラッカーをCodexエージェントに接続するオーケストレーションレイヤーである。
Xiaomi MiMo-V2.5、Kimi K2.6、そして中国のエージェント指向オープンウェイトへの取り組み
MiMo-V2.5 は本日の最大級のオープンリリースの一つである:@XiaomiMiMo 氏は MIT ライセンスの下で MiMo-V2.5-Pro および MiMo-V2.5 をオープンソース化した。両モデルとも 100 万トークンのコンテキスト長を持つ。Pro モデルは複雑なエージェント/コーディングモデルとして位置づけられ、小規模モデルはネイティブのオムニモーダルエージェントとして位置づけられている。@eliebakouch からのコミュニティ要約には有用な技術詳細が含まれている:MiMo-V2.5-Pro は総パラメータ数約 1T / アクティブパラメータ数 42B で、FP8 精度で 27T トークンを用いて学習された。一方、MiMo-V2.5 は総パラメータ数約 310B / アクティブパラメータ数 15B で、48T トークンを用いて学習されており、積極的なインターリーブ SWA(Sliding Window Attention)/グローバルアテンションを採用し、共有エキスパートは持たない。Xiaomi はまた、@_LuoFuli 経由でビルダー向けに 100T トークンの付与も発表した。Day-0 の推論サポートは vLLM および SGLang/vLLM で迅速に導入された。
Kimi K2.6は、注目の集まりとデプロイメントにおいて引き続きリードしています。@Kimi_Moonshotは、Kimi K2.6がOpenRouterの週間リーダーボードで現在第1位であることを発表しました。二次的な報道では、これはコーディングや長期のエージェント向けのモデルであり、4,000の調整されたステップにわたって300の並行サブエージェントへのスケーリングを含むことが説明されています(dl_weekly)。実務者の間では、速度と品質のトレードオフについて見解が分かっています。@teortaxesTexは、HermesにおけるKimiがDeepSeek V4よりも大幅に遅いものの、V4では修正できなかったバグを時として修正できる能力を持っていると見出しています。
より広範な中国モデルの動向:複数の投稿で、中国のラボがオープン志向、エージェント指向、長期コンテキストを持つシステムに対して積極的に取り組んでいることが枠付けられています。これにはQwen 3.6 Flash、DeepSeek V4/Flash、GLM-5.1のプロモーション(トリプル使用拡張)、そしてXiaomiのMITリリースが含まれます。繰り返されるテーマは、小型で安価なバリエーションが、実用的なエージェントベンチマークにおいて大型の兄弟モデルを上回っていることが多いという点です。
エージェントランタイム、オーケストレーション、ローカルファーストのツールリング
SakanaのConductorは注目すべきマルチエージェントの結果です。@SakanaAILabsは、自然言語でフロントティアモデルのプールを調整するために強化学習(RL)で訓練された7BのConductorを紹介しました。これは直接タスクを解決するのではなく、どのエージェントを呼び出すか、どのサブタスクを割り当てるか、そしてどのコンテキストを公開するかを動的に決定します。報告によると、LiveCodeBenchで83.9%、GPQA-Diamondで87.5%を達成し、そのプール内の単一のワーカーのいずれよりも優れた結果を出しています。@hardmaruは、「AIがAIを管理する」こと、および再帰的自己選択がテスト時のスケーリングの新たな軸であることを強調しました。
ローカルおよびハイブリッドエージェントの性能向上が続いている:複数の投稿で、コーディングやアシスタント用のスタックがローカル環境で動作している様子が示された。@patloeber氏と@_philschmid氏は、LM Studio/Ollama/llama.cppを用いてPiエージェントとGemma 4 26B A4Bをローカルで実行する手順を文書化した。@googlegemma氏は、Gemma 4とWebGPUを使用した完全なローカルブラウザエージェントのデモを行い、閲覧履歴、タブ管理、ページ要約のためのネイティブツール呼び出し機能を実装した。@cognition氏はDevin for Terminalをリリースし、これはローカルのシェルエージェントであり、将来的にはクラウド処理への委譲も可能である。
エージェントの使いやすさとフレームワークの進化:Hermesは好調な一日を過ごした。@Teknium氏は、Hermes AgentのリポジトリがClaude Codeのそれを上回ったことを指摘し、サポートされている場合はネイティブビジョン機能がデフォルトとなったと報告した。より広範なエコシステムは欠落していた部分を埋め続けており、Cline Kanbanではタスクカードごとに異なるエージェントやモデルをサポートするようになった。Future AGIは自己改善型エージェントのための評価・最適化スタックをオープンソース化した。また、@_philschmid氏は、MCP(Model Context Protocol)は indiscriminateなサーバー接続ではなく、明示的な@mentionによる読み込みまたはサブエージェントスコープでのツール割り当てを通じて最も効果的に機能すると主張した。
推論インフラストラクチャ、アテンション/KVエンジニアリング、およびシステムワーク
Google の TPU 分割は意味のあるアーキテクチャのシグナルである:複数の投稿が、TPU v8 がトレーニング用 8t と推論用 8i に分割され、以前の世代と比較してトレーニングが約 2.8 倍高速化し、推論パフォーマンス/コスト比が 80% 向上したとする Google Cloud Next の発表を分析していた。@kimmonismus は、これがワークロード別にカスタムシリコンを分割した初の事例であり、OpenAI、Anthropic、Meta が TPU の容量を購入していると報じられていることを強調した。
DeepSeek V4 のサポートはインフラストラクチャスタックで急速に成熟している:@vllm_project は、DeepSeek V4 ベースモデルのサポートが到来すると述べ、FP4 指示用と FP8 ベースを区別するために expert_dtype 設定フィールドが必要だとした。vLLM 0.20.0 リリースのハイライトには、DeepSeek V4 サポート、デフォルト MLA 事前填充としての FA4、TurboQuant 2 ビット KV キャッシュ、Blackwell 上の DeepSeek 固有の MegaMoE パスが含まれた。
KV キャッシュの最適化は依然としてホットな争点である:長文コンテキストのボトルネックと KV 戦略について活発な議論があった。@cHHillee は、長文コンテキストに対する 3 つの主要なレバーを要約した。すなわち、ローカル/スライディングアテンション、インターリーブされたローカル-グローバルアテンション、GQA/MLA/KV 結合/量子化を通じてグローバルレイヤーあたりの KV を小さくすることである。実装面では、@vllm_project と Red Hat/AWS が FP8 KV キャッシュの深掘りを公開し、FA3 の二段階累積に対する修正により、128k needle-in-a-haystack の成功率が 13% から 89% に向上し、FP8 デコードの高速化を維持した。コミュニティの批判者たちはまた、HiSparse などのオフロード重視のアプローチと比較して DeepSeek V4 の特定の KV トレードオフについて疑問を呈した(議論)。
ベンチマーク、評価、そしてオープンな研究課題
オープンの世界における評価の動きが加速している:@sarahookr は、ほとんどのエージェント向けベンチマークが自動検証可能なタスクに過学習していると指摘し、重要な最前線はオープンの世界で不確実性があり、完全に検証できない作業にあると主張した。関連するスレッドでは、これ継続的学習、メモリストア、適応型データシステムと結びつけて論じていた(1, 2)。
コストを考慮したエージェント評価が第一級のものになりつつある:@dair_ai は、SWE-bench Verified におけるコーディングエージェントの支出に関する新しい研究を強調した。それによると、エージェントによるコーディングはチャットやコード推論よりも約 1000 倍のトークンを消費する可能性があり、同一タスクの実行間でも使用量が 30 倍変動し、支出が増加しても精度が単調に向上するわけではない。これは Copilot の価格モデルの変更や、制御不能なエージェントの実行経済性への高まる懸念と一致している。
新しいベンチマークおよびドメイン固有の評価:LlamaIndex の ParseBench は、パーシングエージェント向けに 2,000 ページの検証済み企業文書ページを追加した。AgentIR は、クエリ alongside 推論のトレースを埋め込むことで研究エージェントのための検索を再定義し、AgentIR-4B は BrowseComp-Plus で 68% のスコアを記録したのに対し、より大規模な従来の埋め込みモデルは 52% であった。さらに、最前線のモデルに関するいくつかのベンチマークスナップショットもあった(例:Opus 4.7 が GSO で 42.2% を記録し、WeirdML / ALE-Bench / PencilPuzzleBench に関する議論も)。しかし、より重要なシグナルは方法論にあった:最終的な正解の精度だけでなく、ランタイムコスト、検索品質、オープンの世界での振る舞いを測定する人が増えていることだ。
エンゲージメント(いいね、リツイート、返信などの合計)が高いトップツイート
OpenAIとMicrosoftのパートナーシップ再設定:@samaによるクロスクラウドでの利用可能性およびMicrosoftとの継続的なパートナーシップについてのコメント。
AWS上のOpenAI:@ajassyによる、OpenAIのモデルがBedrockに提供されることの確認。
GitHub Copilotの価格変更:@githubによる、6月1日より従量課金制に移行する発表。
Xiaomi MiMo-V2.5のオープンソースリリース:@XiaomiMiMoによるMITライセンス付与および100万トークンのコンテキスト長を持つモデルの公開。
Codex用のオープンソースオーケストレーション:@OpenAIDevsによるSymphonyのローンチ。
Gemmaローカルブラウザエージェント:@googlegemmaによる、WebGPUを活用した100%ローカル環境で動作するブラウザ内エージェントのデモンストレーション。
AI Reddit 概要
/r/LocalLlama および /r/localLLM 概要
- Qwen3.6 モデルのパフォーマンスと最適化
続きを読む
原文を表示
As every lab sprints toward being some form of Anthropic (aka having a coding and enterprise AI focus, producing ever better PDFs and PPTs and spreadsheets), it is still refreshing to see that GPT-Image-2 is continuing to drive more creative applications, for example this:
Considering the extremely high NPS score of the Lego Rocky Space Friend on date nights, you can imagine how good a low-hallucination, research-enabled, fully multimodal reasoning image model can be.
Of course it’s good for education:
tweet
or pop culture:
or precise, clean infographics:
And of course the GPT-Image-2 + Codex combo, which is available as a skill in Codex, which you can iteratively use to generate assets WHILE you code:
And just like that, Claude Design, the previous Current Thing, isn’t even in the conversation anymore. Quite simply, if you can “close” the loop, you win.
But that isn’t quite the argument we’re making here. What we’re focusing on is the very literal and serious question of whether or not models like Nano Banana or GPT-Image-2 or Grok Imagine are necessary uses of scarce GPU capacity if you are eschewing “side quests” and seriously pursuing AGI and trying to hit the revenue, efficiency, and funding goals necessary to not die along the way.
The answer is emergingly clear: yes. Not merely because of the “closing the loop”. But also because you can only do so much with text and code and structured output generation. When you have multimodal voice and visual generation (including transparency!), you truly flex the “G” part of “AGI” - after all, what good is AI if it only narrowly takes all programming jobs?
By the way, horse-riding astronauts used to be hard in imagegen, then it was astronaut-riding-horses, and now, well…
AI News for 4/26/2026-4/27/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
OpenAI Distribution Shift, GPT-5.5 Benchmarks, and Codex/Copilot Pricing Signals
OpenAI loosens Azure exclusivity: @sama said OpenAI updated its Microsoft partnership so Microsoft remains the primary cloud, but OpenAI can now make products available across all clouds, with product/model commitments extending to 2032 and revenue share through 2030. The implication was quickly drawn by @scaling01 and @kimmonismus: OpenAI can now distribute via Google TPU / AWS Trainium / Bedrock, and Microsoft’s license to OpenAI IP becomes non-exclusive. @ajassy confirmed OpenAI models are coming to AWS Bedrock in the coming weeks. @simonw noted the new language likely means the old AGI clause is effectively gone.
GPT-5.5 is a broad upgrade, but not uniformly dominant: Community evals from @htihle put GPT-5.5 no-thinking at 67.1% on WeirdML, up from 57.4% for GPT-5.4, but still behind Opus 4.7 no-thinking at 76.4% while using fewer tokens. LMSYS Arena results from @arena placed GPT-5.5 at #9 in Code Arena, #6 Document, #7 Text, #3 Math, #2 Search, #5 Vision, with Expert Arena #5. Arena also clarified current evaluation covers medium/high reasoning, with xHigh still pending (1, 2). Practitioner feedback was positive for hard coding tasks such as GPU kernels from @gdb, but there were also reports of “compressed CoT leakage” / malformed outputs in no-thinking mode from @htihle.
Developer economics are becoming more explicit: GitHub announced Copilot moves to usage-based billing on June 1, a notable shift as agentic workflows consume much more runtime. Parallel to that, @Hangsiin documented Codex usage multipliers: GPT-5.4 fast = 2x, GPT-5.5 fast = 2.5x, with 5.4-mini and GPT-5.3-Codex materially cheaper. @sama argued Codex at $20 remains a strong value. OpenAI also open-sourced Symphony, an orchestration layer connecting issue trackers to Codex agents for “open issue → agent → PR → human review,” via @OpenAIDevs.
Xiaomi MiMo-V2.5, Kimi K2.6, and China’s Agent-Oriented Open-Weights Push
MiMo-V2.5 is one of the day’s biggest open releases: @XiaomiMiMo open-sourced MiMo‑V2.5-Pro and MiMo‑V2.5 under MIT, both with 1M-token context. The Pro model is framed as a complex agent/coding model and the smaller model as a native omni-modal agent. Community summaries from @eliebakouch add useful technical details: MiMo‑V2.5-Pro is roughly 1T total / 42B active, trained on 27T tokens in FP8, while MiMo‑V2.5 is about 310B total / 15B active, trained on 48T tokens, with aggressive interleaved SWA/global attention and no shared expert. Xiaomi also announced a 100T token grant for builders via @_LuoFuli. Day-0 inference support landed quickly in vLLM and SGLang/vLLM.
Kimi K2.6 continues to lead in mindshare and deployment: @Kimi_Moonshot said Kimi K2.6 is now #1 on OpenRouter’s weekly leaderboard. Secondary reporting described it as a model for coding and long-horizon agents, including scaling to 300 concurrent sub-agents across 4,000 coordinated steps (dl_weekly). Practitioners remain split on speed/quality tradeoffs: @teortaxesTex found Kimi in Hermes much slower than DeepSeek V4 but sometimes capable of fixing bugs V4 could not.
Broader China-model trend: Multiple posts framed Chinese labs as pushing aggressively on open-ish, agent-oriented, long-context systems: Qwen 3.6 Flash, DeepSeek V4/Flash, GLM-5.1 promotions (triple usage extension), and Xiaomi’s MIT release. A recurring theme was that smaller / cheaper variants are often outperforming their larger siblings on practical agent benchmarks.
Agent Runtimes, Orchestration, and Local-First Tooling
Sakana’s Conductor is a notable multi-agent result: @SakanaAILabs introduced a 7B Conductor trained with RL to orchestrate a pool of frontier models in natural language rather than solving tasks directly. It dynamically decides which agent to call, what subtask to assign, and which context to expose, and reportedly reached 83.9% on LiveCodeBench and 87.5% on GPQA-Diamond, beating any single worker in its pool. @hardmaru highlighted “AI managing AI” and recursive self-selection as a new axis of test-time scaling.
Local and hybrid agents keep getting better: Several posts showed coding/assistant stacks running locally. @patloeber and @_philschmid documented running Pi agent + Gemma 4 26B A4B locally via LM Studio/Ollama/llama.cpp. @googlegemma demoed a fully local browser agent using Gemma 4 + WebGPU, with native tool calling for browsing history, tab management, and page summarization. @cognition shipped Devin for Terminal, a local shell agent that can later hand off to the cloud.
Agent ergonomics and framework evolution: Hermes had a strong day: @Teknium noted Hermes Agent’s repo surpassed Claude Code, while native vision became the default when supported. The broader ecosystem kept filling in missing pieces: Cline Kanban now supports different agents/models per task card; Future AGI open-sourced an eval/optimization stack for self-improving agents; and @_philschmid argued MCP works best either through explicit @mention loading or subagent-scoped tool assignment, not indiscriminate server attachment.
Inference Infrastructure, Attention/KV Engineering, and Systems Work
Google’s TPU split is a meaningful architecture signal: Several posts dissected Google’s Cloud Next announcement that TPU v8 is split into 8t for training and 8i for inference, with claims of roughly 2.8x faster training and 80% better inference performance/$ than prior generation. @kimmonismus emphasized this is the first time Google split custom silicon by workload and that OpenAI, Anthropic, and Meta are reportedly buying TPU capacity.
DeepSeek V4 support is maturing quickly in infra stacks: @vllm_project said support for DeepSeek V4 base models is coming, requiring an expert_dtype config field to distinguish FP4 instruct vs FP8 base. In the vLLM 0.20.0 release, highlights included DeepSeek V4 support, FA4 as default MLA prefill, TurboQuant 2-bit KV, and a DeepSeek-specific MegaMoE path on Blackwell.
KV cache optimization remains a hot battleground: There was dense discussion around long-context bottlenecks and KV strategies. @cHHillee summarized three main levers for long contexts: local/sliding attention, interleaved local-global attention, and smaller KV per global layer via GQA/MLA/KV tying/quantization. On the implementation side, @vllm_project and Red Hat/AWS published an FP8 KV-cache deep dive where a fix to FA3 two-level accumulation improved 128k needle-in-a-haystack from 13% to 89% while retaining FP8 decode speedups. Community critics also questioned DeepSeek V4’s specific KV tradeoffs relative to offloading-heavy approaches such as HiSparse (discussion).
Benchmarks, Evals, and Open Research Directions
Open-world evaluation is gaining momentum: @sarahookr argued that most agentic benchmarks are overfit to automatically verifiable tasks, while the important frontier is open-world, uncertain, non-fully-verifiable work. Related threads connected this to continual learning, memory stores, and adaptive data systems (1, 2).
Cost-aware agent evaluation is becoming first-class: @dair_ai highlighted a new study on coding-agent spend over SWE-bench Verified: agentic coding can consume ~1000x more tokens than chat/code reasoning, usage can vary 30x across runs on identical tasks, and more spending does not monotonically improve accuracy. This lines up with pricing-model changes from Copilot and growing concern over uncontrolled agent runtime economics.
New benchmarks and domain-specific evals: ParseBench from LlamaIndex adds 2k verified enterprise document pages for parsing agents. AgentIR reframes retrieval for research agents by embedding the reasoning trace alongside the query, with AgentIR-4B hitting 68% on BrowseComp-Plus vs 52% for larger conventional embedding models. There were also several benchmark snapshots for frontier models—e.g. Opus 4.7 leading GSO at 42.2% and WeirdML / ALE-Bench / PencilPuzzleBench chatter—but the stronger signal was methodological: more people are measuring runtime cost, retrieval quality, and open-world behavior, not just final answer accuracy.
Top tweets (by engagement)
OpenAI–Microsoft partnership reset: @sama on cross-cloud availability and continued Microsoft partnership.
OpenAI on AWS: @ajassy confirming OpenAI models are coming to Bedrock.
GitHub Copilot pricing change: @github announcing usage-based billing starting June 1.
Xiaomi MiMo-V2.5 open-source release: @XiaomiMiMo with MIT license and 1M context.
Open-source orchestration for Codex: @OpenAIDevs launching Symphony.
Gemma local browser agent: @googlegemma showing a 100% local browser-resident agent with WebGPU.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- Qwen3.6 Model Performance and Optimization
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み