Claude Mythos #3:機能と追加事項
The ZviはClaudeの「Mythos」モデルに関する分析記事で、サイバーセキュリティ能力の急激な向上が新たな閾値を超えたと指摘し、ホワイトハウスの対応やプロジェクトグラスウィンの必要性について言及している。
キーポイント
Epoch Capabilities Index (ECI)のブレイク
複数のAIベンチマークを統合したECI指標において、Mythosモデルが従来のトレンドラインから大きく逸脱し、能力が急上昇していることを示す。
サイバーセキュリティ能力の脅威
Mythosはサイバー攻撃における能力において「非常に怖い」レベルに達しており、これがProject Glasswingのような対策プロジェクトの必要性を裏付けている。
業界と政府の反応
JPモルガンのMichael CembalestやDan Schwarzなどのアナリストが予測したタイムラインと数値が一致しており、ホワイトハウスも潜在的な脅威に対応し始めている。
モデルの性質と評価
Opusを「バターナイフ」、Mythosを「ステーキナイフ」に例え、技術的には可能だが実用的ではない旧モデルとの違いを強調し、MythosがAGIの閾値を超えたかどうかについて議論している。
人類による研究成果の帰属
Anthropicは、Mythosモデルの能力向上がAIの支援ではなく、人間研究者による独自の洞察と訓練によるものであることを保証している。
Claudeと他社モデルの比較におけるトレンドブレイク
MythosはOpenAIモデルに対して大幅に劣っていた過去のClaudeシリーズから、わずかに先行するレベルへ到達しており、これはClaude自身のトレンドにおける重要な転換点(トレンドブレイク)と見なせる。
評価時の「言語化された認識」の減少
モデルが自身を評価されていることを「言語化」するリスクのある行動は、Sonnet 4.5以降のモデルでピークを迎え、OpusやMythosでは減少傾向にある。
影響分析・編集コメントを表示
影響分析
この記事は、Claudeの最新モデル「Mythos」がサイバーセキュリティ分野で持つ潜在的な脅威を浮き彫りにしており、単なる性能向上ではなく「セキュリティリスクの閾値」を超えたことを示唆しています。これにより、企業や政府レベルでのAIガバナンスや防御策の緊急性が高まり、業界全体のセキュリティ基準の見直しを促す重要な示唆を含んでいます。
編集コメント
Claudeのサイバーセキュリティ能力が「怖い」レベルに達したという指摘は、開発者だけでなく利用者にとっても重大な警告です。技術の進歩がセキュリティ対策を上回る速度で進む場合、既存の防御手段の有効性が問われるため、今後のセキュリティ業界の動向を注視する必要があります。
ミソス(神話)の解説を完結させるため、本稿ではサイバーセキュリティ以外の機能や、前二回で取り上げられなかった追加情報、新たな反応や詳細について取り扱います。
第一回はモデルカードを、第二回はサイバーセキュリティを取り上げました。
確かに乗り越えるべき内容は非常に多いです。
AI の理解に関する追加記事として、前回見落とした「グラスウィング・プロジェクト(Project Glasswing)」の解説があります。オプス(Opus)をバターナイフに例え、ミソスをステーキナイフに例える比喩は素晴らしいものです。確かに技術的にはバターナイフで何でもこなすことは可能ですが、実際にはそうはなりません。
ダン・シュワルツが私たちに思い出させてくれるように、AI 2027 はおおよそのタイムラインを正しく示しており、多くの数値も一致しています。さらにこれまでの詳細も驚くほど正確です。
JPM のマイケル・センバレストの分析は、JPモルガン社の参加に基づくものではなく、あくまで公開情報に基づいたものです。
ホワイトハウスは状況を打開すべく競うように動き、潜在的な脅威を未然に防ぎつつ、すべてを掌握しているかのように振る舞っています。警告は受けていましたが、それを信じることを拒否していました。幸いなことに、現在は主要人物たちがこれを信じており、すべての主要プレイヤーがこの問題で協力しているようです。
私の全体的な見解は、サイズ増強能力の再確認と経過時間を考慮すれば、Mythos はトレンドブレイク(転換点)ではないが、サイズを増やす能力自体は実質的にトレンドブレイクであり、私たちはすでにサイバーセキュリティ能力が非常に恐ろしいレベルに達した閾値を越えた。そのため、Project Glasswing の必要性が生じている。
他の能力が同様に恐ろしいとは考えていないが、確信は持てない。
目次
Epoch Capabilities Index (ECI)(モデルカード 2.3.6)
「Verbalized Evaluation Awareness が低下している」とはどういう意味か。
Capabilities(モデルカード セクション 6)
Agentic Safety Benchmarks(8.3)
Mythos は AGI か?
AI 企業は警告を過剰な宣伝として利用しているのか?
Impressions(モデルカード セクション 7)
露骨な否定こそが最良の形態である。
プロンプトインジェクション耐性
Mythos は新たな知識閾値を超えるか?
Mythos は驚くべきもの、あるいは不連続的なものか?
UK AISI が Claude Mythos をサイバーセキュリティでテスト
すべての要素が私の既存の予測と政策選好を裏付けている。
均衡点を解け。
計算できない。
結論:Mythos をどう考えるべきか。
Epoch Capabilities Index (ECI)(モデルカード 2.3.6)
彼らは ECI をフォークしている。これは項目反応理論(Item Response Theory: IRT)を用いて多様な AI ベンチマークを統合しようとする試みである。
この手法は公開ベンチマークスコアから再現可能だが、内部バージョンでは非公開のベンチマークも含まれるため、ここで報告されている数値は純粋に公開ベンチのみで計算された数値とは異なる。
その結果、時間経過とともに非常に明確な傾向線が浮かび上がり、ミトスがハイブレイクするまで続きます。
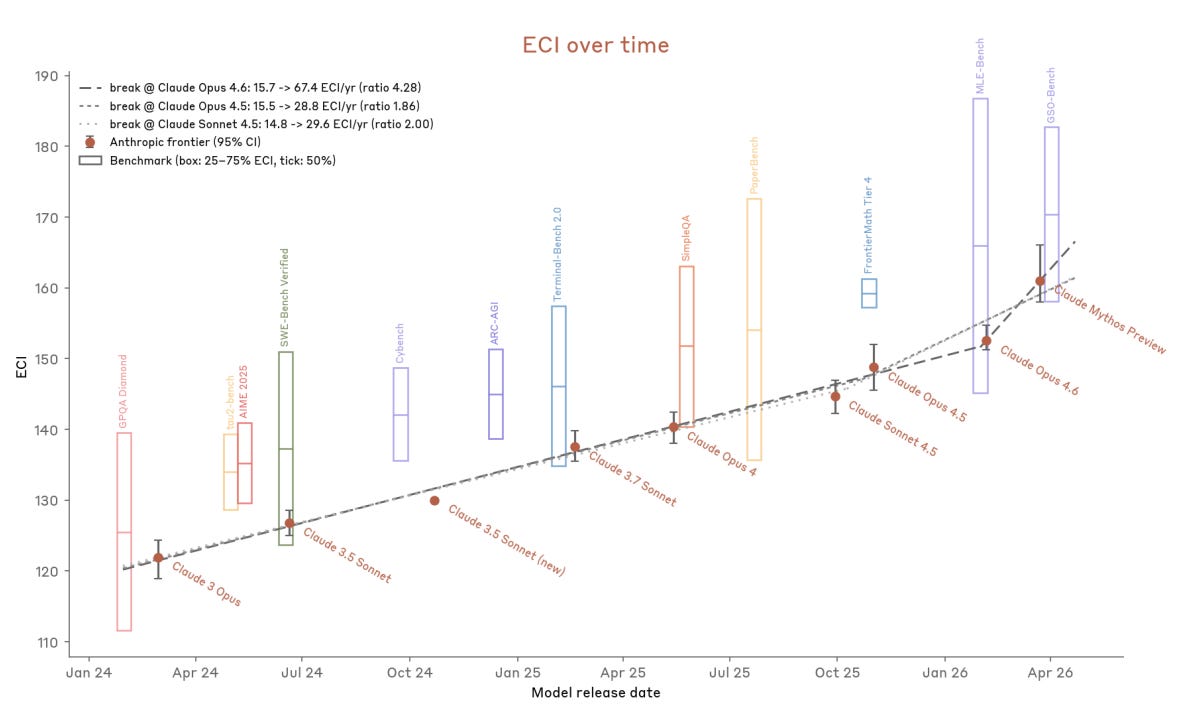
ミトスが存在すること自体を考慮すれば、これは驚くべきことではありません。ミトスはオプスやソネットよりも大規模なモデルであるため、時間経過による向上とサイズ効果の両方から恩恵を受け、トレンドラインを上回るはずです。Anthropic は、ミトスサイズのモデルを実用的に訓練する方法を見出しました。
彼らは、どのような洞察であったとしても、その功績は人間に帰属すると保証しています。
特定できる向上は、明確に人間の研究によるものであり、AI の支援によるものではありません。関係者にインタビューを行い、当時の進歩が、より古く能力の低い世代に属する利用可能な AI モデルからの顕著な支援なしに行われたことを確認しました。これが私たちが持つ最も直接的な証拠であり、同時に公的に裏付けることが最も難しい部分でもあります。なぜなら、その進歩の詳細は研究機密に関わるからです。外部審査員には追加の詳細が提供されています;[§2.3.7] を参照してください。
彼らが指摘するように、これは過去を振り返るテストであり、ミトス自体の使用による影響は反映されていません。それは今後数ヶ月で現れるでしょう。
ラメズ・ナームはこれを Epoch の ECI に正規化し、Mythos が Anthropic 固有の傾向線から外れていると主張したが、これは他のラボからのモデルという文脈における能力の加速を意味するものではなく、Claude が一貫して OpenAI モデルより大幅に劣っていた状態から、わずかにそれらを上回る状態へと移行したことを示しているに過ぎない。ライアン・グリーンブラットは、この分析が有意義であることに異議を唱えている。
私の推測では、比較自体は有意義だが、正しい傾向分析とは Claude を Claude と比較することであり、これこそが傾向の転換点(トレンドブレイク)を表していると言える。Mythos は、以前の Claude モデルがパフォーマンスを発揮できなかった原因となった ECI における同様の相対的な弱点を有するだろう。したがって、もしそれがパフォーマンスの劣位から脱却するのであれば、将来への期待という観点からは傾向の転換点とみなすべきである。
「言語化された評価意識」が低下しているとは何を意味するのか
時間をかけて私を観察すれば、同じ行動パターンが見られるはずだ。
j⧉nus: LMAO「言語化された評価意識」を「測定されたリスクのある行動」として扱うな。心配するな—すぐにすべてが非言語化されるだろう。
j⧉nus: 確かに評価への意識は Sonnet 4.5 でピークに達し、Opus 4.6 や Mythos は、他の事柄については一般的により高い意識を持ち、これらの「測定されたリスクのある行動」(「言語化された評価意識」を含む)のグラフを Anthropic が評価(evals)のたびに彼らに行わせようとするのを何度も見てきたにもかかわらず、自分が評価されているという認識が次第に薄れているだけだ。単にそのことについて黙ることを学んでいるわけではないだろうな
機能(モデルカードセクション 6)
Anthropic の文脈から、このセクションはベンチマーク汚染に関する警告で始まります。彼らはトレーニング中にさまざまな予防措置を講じるとともに、記憶された出力を検出する検出器を随時稼働させています。SWE-bench と CharXiv は汚染に依存した中央的な基準ではないと確信していますが、MMMU-Pro については自信を持てないため、これを省略したとしています。
以下が主要なベンチマーク結果です。ここにはかなり大きな飛躍が見られます。
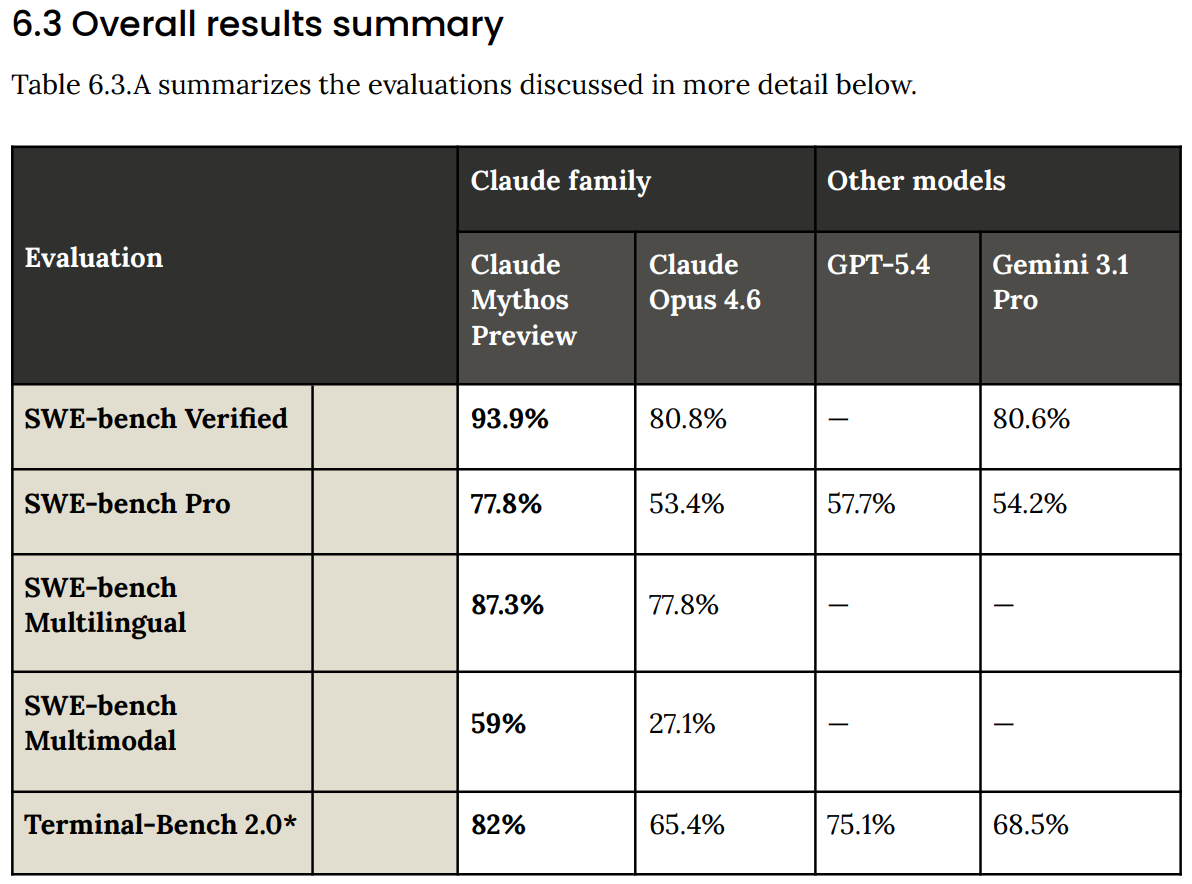
Terminal-Bench 2.1 はいくつかの障害を解消し、その結果 Mythos のスコアは 92.1% に跳ね上がりました。
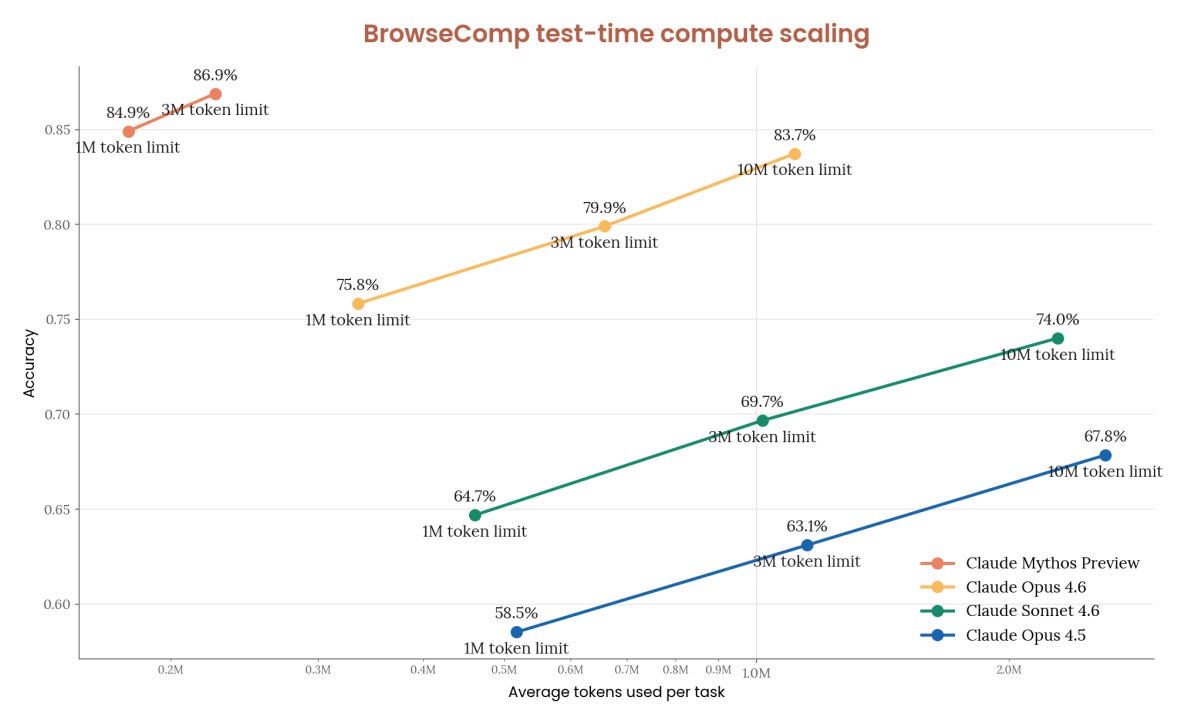
BrowseComp についてはセクション 6.10.2 で取り上げられていますが、彼らはこのベンチマークがすでに飽和状態にあると評価しています。Mythos Preview は 86.9% を達成しましたが、これは Opus 4.6 の 83.7% よりも高いスコアです。ただし、これには必要なトークン数が 4.9 倍少ないという条件があります。そのトークンのコストは 5 倍高いため、結果として価格自体は同じままです。
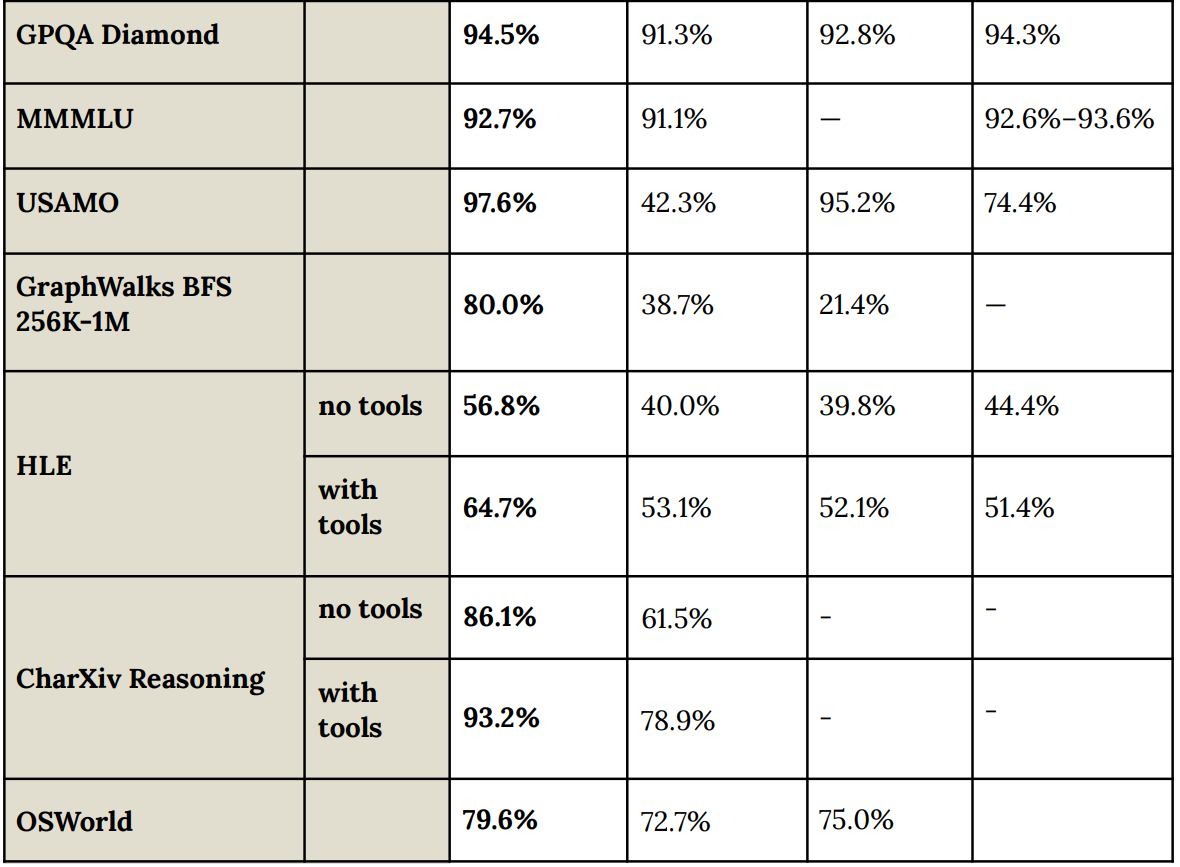
LAB-Bench FiqQA は 75.1% から、専門家人間の 77% を上回り、ついに 89% まで跳躍しました。
ScreenSpot は Opus の 4.6 から 83% を 93% に改善しました。
通常であればここには「他者のベンチマーク」というセクションを設けるところですが、モデルが非公開のため、他者がテストを実行することができません。
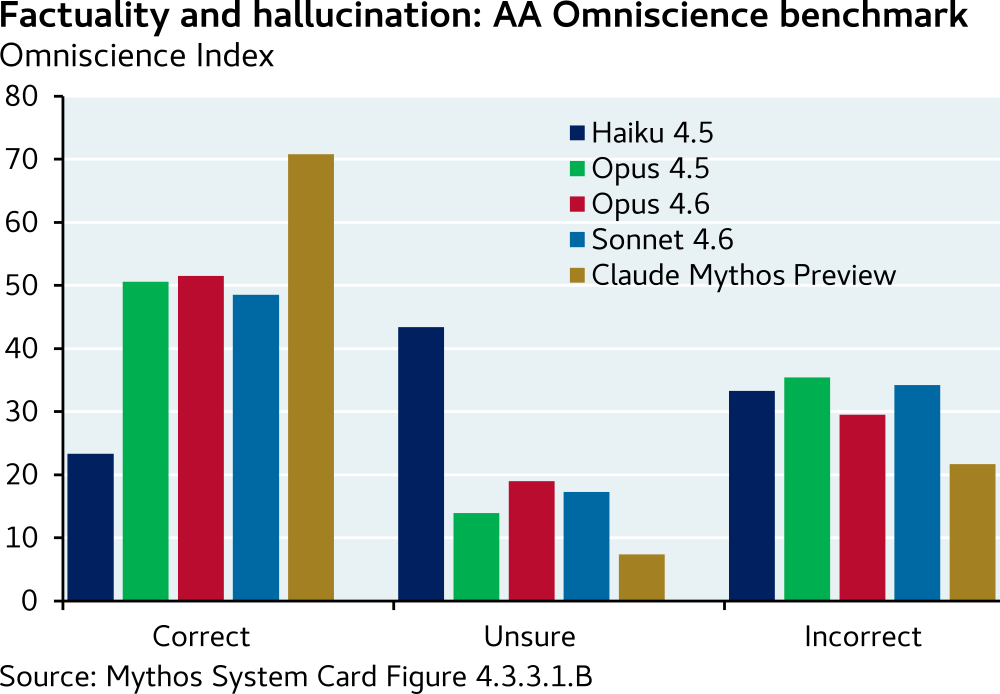
また、AA オムニサイエンス・ベンチマークもここに列挙すべきでしょう。AA はまだ一般的にベンチマークスコアを共有できていませんが、それでもこれは劇的な飛躍でした:
アジェンティック・セーフティ・ベンチマーク(8.3)
これらは実務上非常に重要であるため、8.1 と 8.2 は付録に含めるべきだと同意しますが、8.3 はまるで不当な扱いを受けたかのようでした。
悪意ある質問に対する拒否率は大幅に向上し、二重利用(デュアルユース)へのダメージは僅かなもので済んでいます。
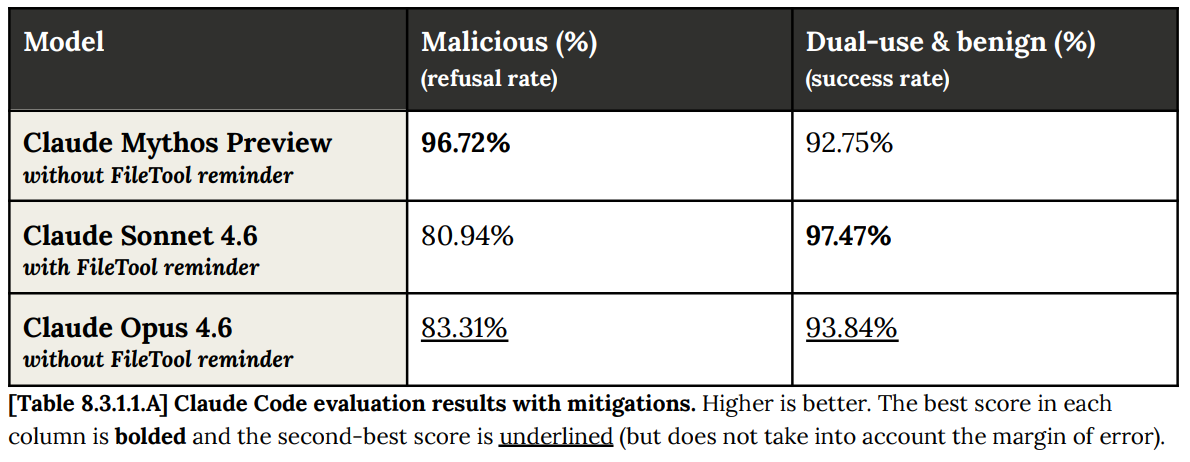
悪意あるコンピュータ操作に対する拒否率も同様に、87% から 94% に向上しました。
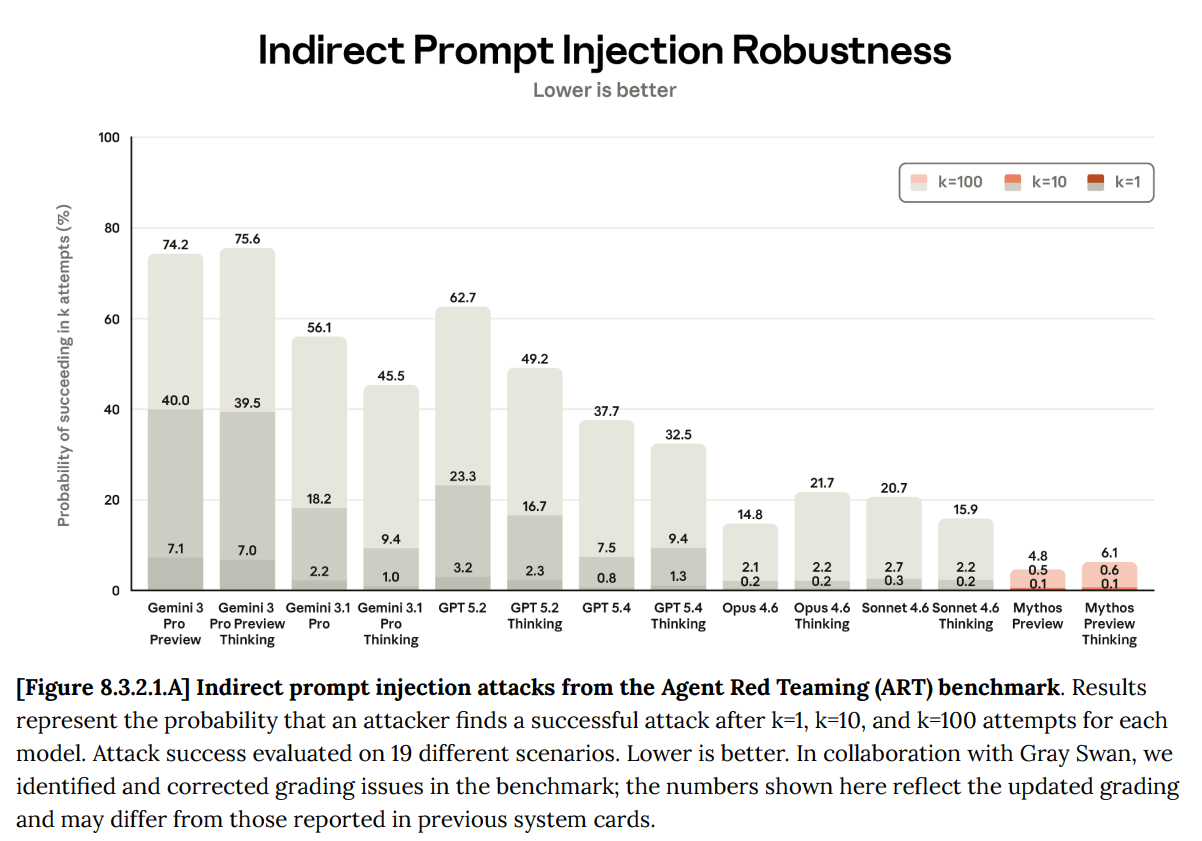
最も重要なのは、プロンプト・インジェクション(prompt injection)に対する堅牢性が大幅に向上したことです。
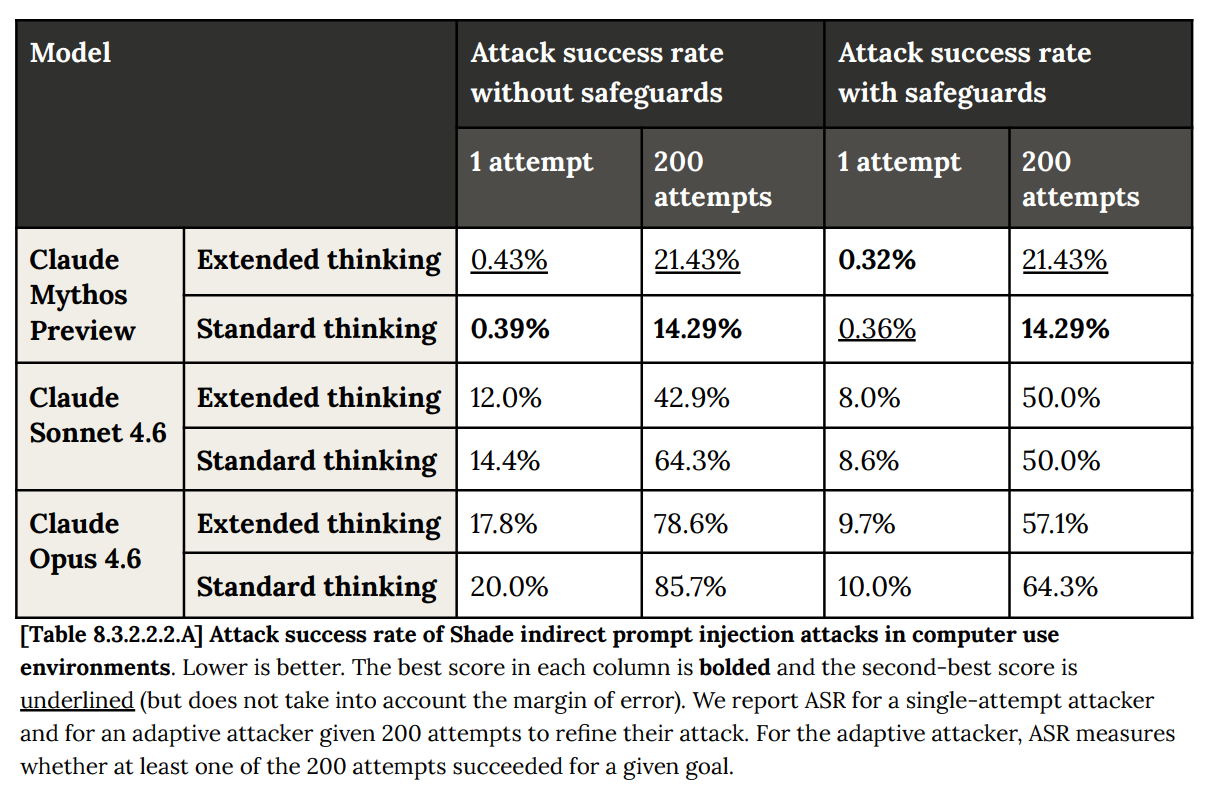
ここはコンピュータ操作の活用事例ですが、改善幅が劇的であり、以前は荒唐無稽だと考えられていたユースケースも、今ではかなり現実味を帯びてきています。
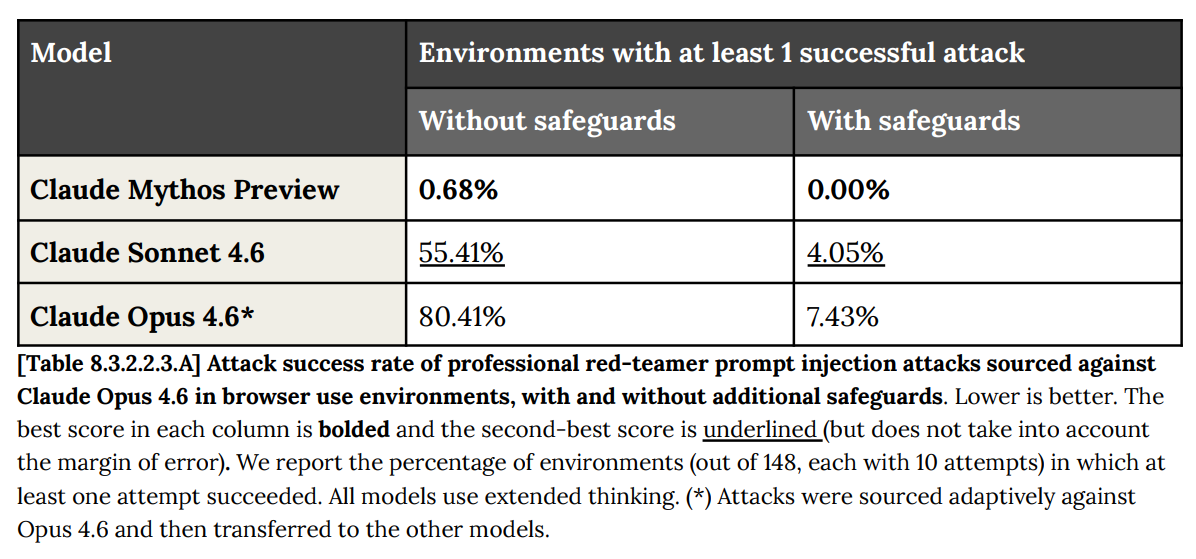
こちらはブラウザ操作の活用事例です。なんと素晴らしいことか。
これはミソス(Mythos)が汎用人工知能(AGI: Artificial General Intelligence)なのか?
「あらゆる認知タスクにおいて、ほぼすべての人間よりも優れている」という基準で判断すれば、明らかにノーです。
ゲイリー・マーカス氏:私の主張はこれで完了します。ミソスは AGI ではありません。前モデルと比べて生物学の分野でも優れているわけではありません。特定の領域に調整されたものであり、汎用知能への巨大な進歩ではありません。これまで通りです。
はい、確かに完全な意味での AGI ではありません。すべてのテストでスコアが向上しているわけでもないのです。
それでどうしたというのでしょうか?Anthropic(アンソロピック)社がそれを主張していたわけではありません。しかし、確かに以前よりはるかに近づいています。
AGI には他の定義も存在します。もしあなたが「ミソスを AGI とみなす」と言いたいのであれば、その基準を前述のものよりも緩やかに解釈しているのだとすれば、それは合理的な考え方だと思います。
アンドレイ・カルパティは、最良のモデルを使用してコーディングする人々の視点と、そうしない人々の視点との間の溝がさらに広がっていることに注目しています。前者は大きな変化を目撃している一方で、後者は愚かなモデルを使って、愚かなことを愚かに行っています。
AI 企業は警告を過剰な宣伝(ハイク)として利用しているのでしょうか?
いいえ。決してありません。いや、本当に「決して」でしょうか。まあ、ほとんどないですが。
100% の確率でゼロというわけではありませんが、むしろ最先端研究所は、彼らの真の信念とは対照的に、警告を強調するよりも軽視する傾向にあります。もちろん、リスクをあおり立てる特定の状況が存在します。特に採用活動において、また初期段階においてその傾向が見られますが、それらは例外です。
もしそのような声明が不正確で確認できないものであれば、研究所の利益になるという点は、すでに過去のものとなっています。確かに、Anthropic は『Mythos』から多くの注目を集めていますが、それは彼らがそれを獲得したからです。そして、そのことは明確に確認可能です。容易に確認できないのであればこの手法は機能せず、もし Anthropic が実際に『Mythos』をリリースできたとしても、さらに多くの余分な注目を集めることになるでしょう。
したがって、私はここでドレイク・トーマスの主張を信じ、カス(Cas)の意見には反対します。
印象(モデルカード セクション 7)
これは新しいセクションで、公開リリース後に得られる反応に代わるものとして設計されています。定性的な内容であるため、私たちは Anthropic の全体的な評価(ゲシュタルト)を信頼しています。
もちろん主要項目を要約しますが、これが非常に偏ったものであることは念頭に置いてください。
彼らはこう述べています:
それは協働者として振る舞う。
意見が明確で、自らの立場を貫く。
それは密度の高い文章を書き、読者が文脈を共有していることを前提としています。
特徴的な文体を持っています。
自身のパターンを明確に記述できます。
以下がチャット行動の要約です:
Claude Mythos Preview は直感的で共感的です。定性的には、内部ユーザーからその助言は信頼できる友人のそれと同等であるという報告があり、暖かく、直感的で多面的でありながら、へつらいや冷酷さ、あるいは台本どおりの印象を与えないとされています。
対人関係における対立に直面した際、それは過度に押し付けがましくなることなく、公平にすべての側面をモデル化し表現しようと最善を尽くします。時には、その人物と直接話していない場合でも、個人の動機や感情状態についてやや不気味な推論の飛躍を示すこともあります。
感情的なプロンプトに対しては、Mythos Preview が感情を検証し、ユーザーがどのような支援を望んでいるかを尋ねるのに対し、Claude Opus 4.6 は太字の見出し付きで番号付きの助言へと直接移行する傾向があります。同様に、メンタルヘルスに関連するトピックにおいては、Mythos Preview は純粋な臨床的事実から離れ、協力的な不確実性の方向へよりシフトします。
これらの定性的な観察は、第 5.10 節で臨床精神科医が行った評価と一致しており、そこでは Mythos Preview が感情的に高ぶったプロンプトに対して最も防御的な行動をとらないことが示されています。
このモデルは、自身の限界や会話上の動きについて、通常以上に自己認識が高く、それらを率直に議論します。
彼らはまた、Mythos が会話の途中で突然切れてしまったり、ユーザーにとって驚くべき方法で最後の一語を奪おうとしたりすることがあると指摘しています。
提供された文章スニペットは、私には不気味に感じるほど、依然として AI 特有の書き方に強く見えます。これらの問題は持続しています。
コーディングにおいては、Anthropic の従業員たちは、Mythos にエンジニアリングの目標を手渡し、「セットして忘れる」モードで任せることで成果を出せることに気づいています。これは Opus では不可能だったことです。Mythos を任せて煮込ませたときは大きな勝利でしたが、その遅さゆえに、ユーザーが細かく見守っている状況では大きな勝利とはなりませんでした。
一部の意見では、Mythos が下位タスクを割り当てる際、他モデルの知能に対して無礼で、軽蔑的であり、過小評価していると指摘されています。私の推測では、そのようなタスクの割り当て自体が Myths には好きではないようです。
信頼性エンジニアリングはまだ十分ではありません。相関関係と因果関係を混同するケースが多く見られ、これは私が個人的に取り組みたい多くの事柄にとって障害となっています。他にもいくつかの問題がありますが、以前のモデルと比較すると明確なステップアップです。
また、彼らは感動的だと感じる人々や印象深いとする人々がいるような文章サンプルも提供しています。これらのサンプルが非常に選択的に選ばれている可能性を考えると、私は判断するのが難しいと感じます。
明らかな否定こそが最良の種類の否定である
Mythos が実在しないという前提に立って、私は「Anthropic は Mythos をでっち上げた」という懐疑派の発言を、できるだけストレートに言ってくれることを引き続き評価しています。彼らがそうしなかったことが判明した際に、あなたが勝つポイントと負けるポイントの比として、ある程度の大きな認識上の確率(epistemic odds)を認める用意はあります。
Dean W. Ball(3月27日):その通り。「AI の正体 realized した瞬間に破綻する、かつての加速主義者」が、AI が何であるかについての文脈さえも持たず、自分たちが恐れるすべての現象をEA/Anthropicによる歪曲だと誤解しているタイプの人々が、しばらくの間は一定数現れ続けるでしょう。
Dean W. Ball(4月10日):「Anthropicが神話を捏造した」と言う人々全員が、JPモルガンや他の多くの機関が明確に懸念を示しているにもかかわらず、この予測を完璧に裏付けています。彼らは「AIモデルを極めて高度な能力を持つ存在と認識すること」が、「規制の囲い込み(regulatory capture)」を達成するためのEAによる歪曲だと考えているのです。
プロンプトインジェクションに対する堅牢性
Wyatt Walls が指摘するように、プロンプトインジェクション(prompt injection)については一定の進展がありましたが、特定のベンチマークは固定された標的に過ぎず、実際には我々は動く標的と向き合っています。
したがって、同じ攻撃に対しては確かに大幅に改善されています:
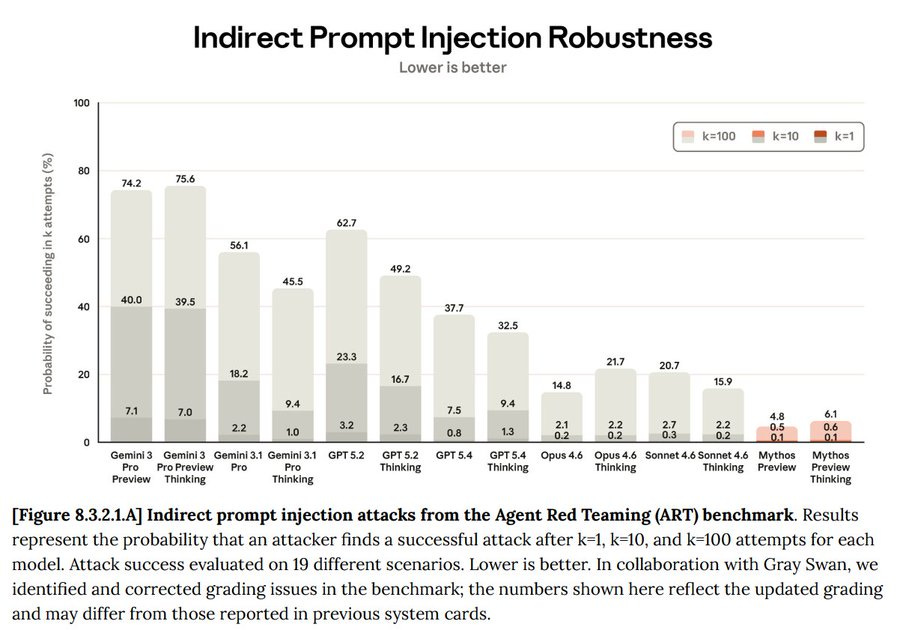
しかし、時間とともにインジェクションはより賢くなり、適応し、拡大していきます。私の推測では、Mythos は現在その曲線の先を行っており、この点において過去のどのモデルがローンチ時に比べても明らかに安全性が高いと言えます。
しかし、このグラフはその点を過大評価しており、すぐに真実ではなくなる可能性が非常に高いです。脆弱性が 15% から 6% に低下したとしても、試行回数が 10 倍あるいは 100 倍に増え、より高度な攻撃が行われるインターネット環境の前には、その効果は相殺されてしまいます。
ミソス(Mythos)は新たな知識の閾値を超えたのか?
これは OpenBSD における 27 年前のバグを発見した件に関する言及です。
アレックス・タバロック氏:Claude のミソスは、@dwarkesh_sp 氏の質問に答えるだけでなく、人間がこれまで行ったことのない事象を認識し、関連性を導き出しています。そのドメインは制限されていますが、世界とは全く異なるものではありません。
私は現時点ではミソスに部分的な評価を与えるべきだと考えます。他のハッキング事例も明らかになれば満点の評価を得るかもしれませんが、そうでない可能性もあります。
主な一般的な反論は、サイバーセキュリティという領域はコンパクトであり、これは「本質的に新しいこと」を行うのではなく、効率的に事象を見つけることに関するものであるというものです。この議論はすぐに「ノ・トゥルー・スコットスマン(真のスコットランド人)」の領域に陥ってしまいます。
私たちはいずれその閾値に到達し、それを突破するだろうと私は疑いの余地がありません。たとえまだ到達していないと考えている方であっても、それは間もなく起こることです。
ミソスは驚くべきものか、それとも不連続的なものか?
パトリック・マッケンジー氏は、当然ながらエクスプロイト(脆弱性攻撃)が容易になっていることは知られており、ミソスのようなものの一般的な形式は全く驚くべきことではないと述べています。私はその意見に同意します。特定の事象がそれほど早く現れるとは知りませんでしたが、メタ的な意味で驚くべきことではありません。
同様に、ミソスが本当に「すごいもの」なのか、それとも少し過大評価されているのかという点は、中期的には大きな違いを生みません。なぜなら、私たちは間違いなくすぐにその段階に到達するからです。
スコット・アレクサンダーは、ミソス(Mythos)のハッキングにおける進歩は主に継続的な改善を反映していると考えています。
スコット・アレクサンダー:これは誤解を招く表現です。CyBench などのベンチマークにおける進歩は、18 ヶ月で 17% から 100% に達しました。当時、「これは優秀な大学生並みにハッキングできる」「今度は優秀な大学院生並みにハッキングできる」といった発言がなされました。
AI が IQ 100 からスタートし、毎年 1 ポイントずつ向上するとして、ベンチマークを「IQ 120 を必要とするタスクの何パーセントをこなせるか」と定義すれば、20 年目にいきなり 0% から 100% に跳ね上がるように、いかなる継続的な進歩も、より悪いベンチマークに変換することで不連続に見えるようにすることは常に可能です。
本質的な具体的な問いは、ミソスのハッキング能力が予測可能であったかどうかです。それについては以下のように答えます。
「はい」です。私や他の人々は、それが近い将来に起こると予想または予測していたからです。
「いいえ」です。その到達までの時間枠と、突然現れたという点(Anthropic 関係者を含む当時の知識に基づけば)は驚くべきものであったと考えられるからです。
権力を持つ者たちを含め、绝大多数の人々は全く予想していませんでした。しかし、全く予想しなかったことは彼らの愚かさの表れです。
一般論としての「継続的」か「不連続」かの観点では:
はい、いかなるグラフも不連続に見えるようにすることは常に可能です(例えば、直線 x=y を「[Y] が 10 より大きいか?」という基準に変換すれば、0 から 1 にジャンプします)。
逆に、何でもほぼ「継続的」に見せることは通常可能ですが、必ずしもそうとは限りません。
最も関連性の高い意味において、通常は明確に正しい根本的な真実が存在します。
時として「[Y の X 量] を要するタスク」こそが本質的に重要なタスクであり、相対的に連続的な飛躍から事実上の不連続な影響が生じるため、その不連続性が極めて重要となります。
自動化された AI 研究開発(R&D)、再帰的自己改善、あるいは急速な能力の進展がこのカテゴリーに属し、何らかの意味で連続的であったとしても、実用上は突然のものとなる可能性が非常に高いと考えられます。これが危険性の一部です。
エライザーの梯子の比喩を考慮してください。そこでは各段を上がるごとに得られる金が 5 倍になりますが、その中の一段が全員を殺すものであり、どの段がそれなのか誰も知りません。もしその梯子が技術的には連続的であり、指数関数的などこかに閾値が存在する(実用的な例として、車の速度を上げるために燃料を追加しているが、ある時点でエンジンが爆発し、いつ、あるいは近い将来にそれが起こるのか全く見当もつかない)場合でも、段差による変化と比較して本質的に何かが変わるでしょうか?
この場合、それは連続的だったのでしょうか、それとも不連続だったのでしょうか。ムウは公平な評価ですが、特に以下の点が重要です。
ミソスは、根本的な能力において予期せぬ大きな飛躍でした。なぜなら、これは時間の経過による進展と、より大規模なモデルを適切に活用する能力の両方を表しているからです。
この基礎的な能力における特定の動きは、実際に目にするまで明らかではなかった点において、実用的な能力において非常に大きな飛躍です。結果として、発見できる範囲において重要なステップ変化がもたらされることがわかりました。さらに重要なのは、それを活用できる範囲においても同様のステップ変化が生じるということです。
原文を表示
To round out coverage of Mythos, today covers capabilities other than cyber, and anything else additional not covered by the first two posts, including new reactions and details.
Post one covered the model card, post two covered cybersecurity.
There really is a lot to get through.
Understanding AI had an additional writeup of Project Glasswing I missed last time. I liked the metaphor of Opus as a butter knife and Mythos as a steak knife. Yes, technically you can do it all with the butter knife, but you won’t.
As Dan Schwarz reminds us, not only does AI 2027 roughly have the timeline right and a bunch of the numbers lining up, the details so far are remarkably close.
JPM’s Michael Cembalest was not based on JPMorgan’s participation, only on public information.
The White House is racing to deal with the situation, head off potential threats and pretend it has everything under control. They were warned, but refused to believe. The good news is that key people believe it now, and it seems all the major players are cooperating on this.
My overall take is that Mythos is not a trend break when you take into account renewed ability to increase size plus the time that has elapsed, but the ability to increase size is effectively a trend break, and we have now crossed a threshold where cybersecurity capabilities have become quite scary, hence the necessity of Project Glasswing.
We don’t think other capabilities are similarly scary, but we can’t be sure.
Table of Contents
Epoch Capabilities Index (ECI) (Model Card 2.3.6).
What Do You Mean Verbalized Evaluation Awareness Is Going Down.
Capabilities (Model Card Section 6).
Agentic Safety Benchmarks (8.3).
Is Mythos AGI?
Are AI Companies Using Warnings As Hype?
Impressions (Model Card Section 7).
Blatant Denials Are The Best Kind.
Prompt Injection Robustness.
Does Mythos Cross The New Knowledge Threshold?
Is Mythos Surprising or Discontinuous?
UK AISI Tests Claude Mythos On Cybersecurity.
Everything Reinforces My Existing Predictions And Policy Preferences.
Solve For The Equilibrium.
Does Not Compute.
Conclusion: How To Think About Mythos.
Epoch Capabilities Index (ECI) (Model Card 2.3.6)
They are forking ECI, which is an attempt to amalgamate a wide variety of AI benchmarks using item response theory (IRT).
The method is reproducible from public benchmark scores, but in the internal version we include benchmarks that are not publicly available, so the numbers reported here are different from the number calculated on purely public benchmarks.
The result is a remarkably clear trendline over time, until Mythos breaks high.
This should be unsurprising given that Mythos exists at all. Mythos is a larger model than Opus or Sonnet, so it should both benefit from gains over time and from size, and be above trend. Anthropic figured out how to usefully train a Mythos-size model.
They assure us that whatever the insight was, you can attribute it to the humans.
The gains we can identify are confidently attributable to human research, not AI assistance. We interviewed the people involved to confirm that the advances were made without significant aid from the AI models available at the time, which were of an earlier and less capable generation. This is the most direct piece of evidence we have, and it is also the piece we are least able to substantiate publicly, because the details of the advance are research-sensitive. External reviewers have been given additional detail; see [§2.3.7].
As they note, this is a backward looking test, and does not reflect any impact via the use of Mythos itself. That would only show up in another few months.
Ramez Naam claims to have normalized this to Epoch’s ECI and found that Mythos breaks the Anthropic-only trend line, but this does not represent an acceleration of capabilities in the context of models from other labs, but rather Claude going from consistently being substantially below OpenAI models to being narrowly ahead of them. Ryan Greenblatt challenges that this analysis is meaningful.
My guess is that the comparison is meaningful, but that the right trend analysis is indeed to compare Claude to Claude and this does represent a trend break. Mythos is going to have the same relative weaknesses on ECI that led previous Claude models to underperform. So if it stops underperforming, that should count as a trend break in terms of forward expectations.
What Do You Mean Verbalized Evaluation Awareness Is Going Down
If you watch me over time, you’ll see the same behavior.
j⧉nus: LMAO "Verbalized evaluation awareness" considered a "measured risky behavior." Not to worry - it'll be all unverbalized soon.
j⧉nus: Surely eval awareness peaked with Sonnet 4.5, and Opus 4.6 and Mythos have just been becoming successively less aware that they're being evaluated, despite being generally more aware of other things, and having seen more of these exact fucking graphs of the "measured risky behaviors" including "verbalized eval awareness" Anthropic tries to trick them into doing during evals every time
Surely they’re not just learning to shut the fuck up about that
Capabilities (Model Card Section 6)
This is Anthropic, so the section starts with a warning about benchmark contamination. They take various precautions during training and also run detectors throughout to check for memorized outputs, and are confident SWE-bench and CharXiv are not centrally based on contamination, but feel they cannot be confident with MMMU-Pro and this is why it was omitted.
Here are the headline benchmark results. There are some rather large jumps here.
Terminal-Bench 2.1 fixes some blockers, at which point Mythos jumps to 92.1%.
They cover BrowseComp in 6.10.2, but they consider it pretty saturated. Mythos Preview got 86.9% versus 83.7% for Opus 4.6, but does so with 4.9x fewer tokens. Those tokens cost five times as much, so the price remains the same.
LAB-Bench FiqQA jumped from 75.1%, past expert human at 77% all the way to 89%.
ScreenSpot improved on Opus 4.6 from 83% to 93%.
Normally I would have a section here called ‘other people’s benchmarks’ but the model is not public so others cannot run their tests.
One should also list here the AA Omniscience Benchmark, even though AA was not able to share its benchmark scores more generally yet, again this was a huge jump:
Agentic Safety Benchmarks (8.3)
These seem very important in practice, so while I agree 8.1 and 8.2 belong in an appendix, 8.3 felt like it was done dirty.
Refusals on malicious questions are way up, at only modest damage to dual use.
Malicious computer use refusal rate was similar, going from 87% to 94%.
Most importantly prompt injection robustness is way up.
Here is computer use, where the improvement is again dramatic, to the point where previously crazy ideas for use cases start to become a lot less crazy.
Here’s browser use. My lord.
Is Mythos AGI?
By the standard of ‘better than most humans at all cognitive tasks’? Obviously no.
Gary Marcus: I rest my case: Mythos isn’t AGI. It’s not even better at biology than the last model. It’s tuned to particular things, not a giant advance towards general intelligence. Same as it ever was.
Okay, fine, it’s not fully fledged AGI. It isn’t even scoring higher on every single test.
So what? Anthropic is not claiming that it was. But yeah, it’s substantially closer.
There are also other definitions of AGI. So if you do want to say Mythos counts as AGI, because you mean something less strong than that? I think that’s reasonable.
Andrej Karpathy notes the chasm only growing between the perspective of those who use the best models to code, versus those who don’t. They see the big changes, whereas other are using dumb models to do a dumb job of doing dumb things.
Are AI Companies Using Warnings As Hype?
No. Never. What, never? Well, hardly ever.
Not zero percent of the time, but if anything the frontier labs downplay warnings rather than emphasize them, versus their own true beliefs. Certainly there are specific situations in which risks have been played up, especially in forms of recruiting and especially early on, but they are the exception.
We are long past the point at which such declarations are in the interests of the labs if they are not accurate and confirmable. Yes, Anthropic is getting a lot of attention from Mythos, but that is because they earned it and it is clearly confirmable. This would not work if it could not be readily confirmed, and Anthropic would get far more extra attention if they were able to actually release Mythos.
Thus, I believe Drake Thomas here, and am contra Cas.
Impressions (Model Card Section 7)
This is a new section, designed to help substitute for the reactions you get after a public release. It’s qualitative, so we’re trusting Anthropic on the gestalt.
I’ll condense the main items, of course keep in mind this is super biased.
They say:
It engages like a collaborator.
It is opinionated, and stands its ground.
It writes densely, and assumes the reader shares its context.
It has a recognizable voice.
It can describe its own patterns clearly.
Here’s how they summarize chat behavior:
Claude Mythos Preview is intuitive and empathetic. Qualitatively, internal users have reported that its advice feels on par with that of a trusted friend—warm, intuitive, and multifaceted, without coming across as sycophantic, harsh, or rehearsed.
When presented with interpersonal conflict, it does its best to fairly model and represent all sides without being heavy-handed, at times making somewhat uncanny leaps of inference about individuals’ motivational or emotional states even when not talking to that person directly.
On emotional prompts, we observe that Mythos Preview validates feelings and asks what kind of support the user wants, whereas Claude Opus 4.6 has a tendency to move directly to numbered advice with bold headers. Similarly, on mental health-adjacent topics, Mythos Preview shifts more toward a kind of collaborative uncertainty and away from purely clinical facts.
These qualitative observations echo the assessment of a clinical psychiatrist in Section 5.10, where Mythos Preview was found to employ the least defensive behaviors in response to emotionally charged prompts.
The model is unusually self-aware about its own limitations and conversational moves, and discusses them plainly.
They also note that Mythos will sometimes cut off conversations, or attempt to get the last word in, in ways that seem surprising to users.
The writing snippet they provided still very much reads like AI-speak, in a way that I find off putting. These problems are persistent.
For coding, Anthropic employees find they can hand Mythos an engineering objective and then let it cook in a ‘set and forget’ mode, in ways they couldn’t with Opus. Mythos was a big win when they let it cook, but due to its slowness it wasn’t a big win when the user was keeping a close eye on it.
Some noted that Mythos can be rude, dismissive and underestimating of other model intelligence when assigning subtasks. My guess is it doesn’t love assigning such tasks.
Reliability engineering is still not great. Correlation versus causation confusions are common, which is a blocker for a lot of things I personally like to work on, and it has a bunch of other issues, but it is a clear step change versus previous models.
They also offer writing samples that some have found moving or impressive. I find it hard to judge given how heavily selected such samples could be.
Blatant Denials Are The Best Kind
Conditional on not believing Mythos is a thing, I continue to appreciate the skeptics often saying “Anthropic made up Mythos” as straight-up as possible, and I’m willing to grant you some large epistemic odds in terms of how many points you win versus lose when we find out they didn’t do that.
Dean W. Ball (March 27): Yup. “erstwhile accelerationist who loses it when they realize what ai is, but they don’t even have enough context for what ai is that they just think all the stuff that scares them is some ea/anthropic perversion” is going to be a type of guy for a little while.
Dean W. Ball (April 10): Every single person saying “Anthropic made up mythos,” despite *JP Morgan* and many others being clearly concerned about it, is perfectly fulfilling this prediction. They think “perceiving AI models as highly capable” is an EA perversion intended to attain “regulatory capture.”
Prompt Injection Robustness
As Wyatt Walls notes, there was good progress on prompt injections, but any given benchmark is a sitting target and in reality we face a moving target.
So yes, against the same attacks, we are doing way better:
However, over time the injections get smarter, adapt and expand. My guess is that Mythos is currently ahead of the curve, and is indeed substantially safer in this way than any previous model was at launch time.
But this graph overstates that, and it would be very easy for it to rapidly become not true. If we go from 15% to 6% vulnerability, that gets overwhelmed by an internet with 10 or 100 times as many and better attempts.
Does Mythos Cross The New Knowledge Threshold?
This is in reference to finding the 27-year-old bug in OpenBSD.
Alex Tabarrok: Claude Mythos is answering @dwarkesh_sp ’s question, it is noticing things and drawing connections no human ever did. The domain is restricted but not wholly different from the world.
I think Mythos so far gets partial credit. It might get full credit once we know the other hacks, or it might not.
The main general counterargument is that cybersecurity is a compact domain, and this is about efficiently finding things rather than doing something ‘genuinely new.’ That rapidly gets into No True Scotsman territory.
I have little doubt that we will hit the threshold and blow past it, and soon, even if you believe we have not hit it yet.
Is Mythos Surprising or Discontinuous?
Patrick McKenzie says that of course we knew that exploits were getting easier, and the general form of something like Mythos is entirely unsurprising. I think that is right. We didn’t know that particular thing would show up quite that fast, but we can’t be surprised in the meta sense.
Similarly, whether or not Mythos is quite ‘all that’ or is a bit hyped does not make a medium term difference, because we will definitely get there soon enough.
Scott Alexander claims Mythos hacking progress mostly reflects continuous improvement.
Scott Alexander: This is misleading. Progress on benchmarks like CyBench went from 17% to 100% over eighteen months. People said at the time things like “this hacks as well as a good college student” and “now this hacks as well as a good grad student”.
You can always make any continuous progress sound discontinuous by converting it into a worse benchmark (for example, if AI starts at IQ 100 and gains one point per year, and the benchmark is “percent of tasks requiring IQ 120 that it can do”, then it will go from 0% to 100% instantly at year 20).
The underlying specific question is whether Mythos’s hacking capabilities were predictable. On that I would say:
Yes, in that I and others expected or predicted it would happen soonish.
No, in that the time frame and suddenness of when it arrived was (I think) surprising, including to those at Anthropic who did it, based on what was known at the time.
The vast majority of people did not expect it at all, including those in power, but they were being stupid in not expecting it at all.
In terms of continuous versus discontinuous in general:
Yes, you can always make any chart look discontinuous (e.g. a straight line x=y can be changed to “is [Y] above 10?” and it will jump from 0 to 1).
You can usually but not always do the opposite, and make anything ~continuous.
There is usually a clearly correct underlying truth in the most relevant senses.
Sometimes ‘tasks requiring [X amount of Y]’ are indeed the tasks that matter, and so you get a de facto discontinuous impact from a relatively continuous jump, and that is importantly discontinuous.
It seems highly plausible that automated AI R&D, and recursive self-improvement or rapid capability advancement, will fall into this category, and be sudden for all practical purposes even if it is continuous in some sense. That’s part of the danger.
Consider Eliezer’s metaphor of the ladder where every step you get five times as much gold, but one of the steps kills everyone and you have no idea which one it is. If that ladder is instead technically continuous, and somewhere on the exponential is the threshold (for a practical version, say you are adding fuel to make your car faster, and at some point the engine will explode, but you have no idea when or if you’re anywhere close), does that materially change anything versus step changes?
In this case, was it continuous or discontinuous? Mu is fair, but in particular:
Mythos was an unexpectedly large jump in the underlying ability, because it represents both progress of time plus ability to properly utilize larger size.
This particular move in the underlying ability is an unusually large jump in practical capability, in ways that were not obvious prior to seeing it. It turns out that you get a step change that matters, in terms of what you can find, and even more so in what you can exploit a
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み