信頼性の欠陥:Coinbase のグローバル取引サービスに自動化されたゾーンフェイルオーバーがない
Coinbase の大規模障害は、低遅延を優先する設計が単一可用性ゾーンへの依存を生み、自動化されたフェイルオーバー機能の欠如が 10 時間に及ぶサービス停止を招いたことを示している。
キーポイント
単一 AZ 依存による脆弱性
Coinbase は低遅延とスループットを確保するため、マッチングエンジンを AWS の単一の可用性ゾーン(AZ)内に配置する設計を採用しており、これが障害時の全社的停止の原因となった。
自動化フェイルオーバーの欠如
他社が地域障害時に自動で健全な領域へ切り替えた一方で、Coinbase は手動対応や外部依存に頼り、システムレベルでの自動フェイルオーバー機能が実装されていなかった。
設計トレードオフの限界
分散合意プロトコル(Raft)におけるネットワークホップの遅延を避けるため、物理的な近接性(コロケーション)を選んだ結果、可用性ゾーンの故障に対する耐性が著しく低下した。
自動化されたゾーンフェイルオーバーの欠如
Coinbase は可用性ゾーン間の自動フェイルオーバー機能を持たず、障害発生時に手動での緊急コード変更とノード再構築を余儀なくされました。
過去の教訓の無視とインフラの劣化
2025 年の AWS 障害後に改善策を検討したにもかかわらず、単一ゾーンの依存リスクが解消されず、10 年前の Uber よりもインフラ基盤が脆弱であると批判されています。
大規模事業における非専門的な運用
年間 5.2 兆ドルを扱う企業規模において、自動化されたフェイルオーバーがないことは極めて不十分であり、約 70 億ドルの金融活動が停止する結果となりました。
影響分析・編集コメントを表示
影響分析
この記事は、金融取引のような低遅延要件が高いシステムにおいて、パフォーマンス最適化のために可用性を犠牲にする設計判断が、いかに致命的なリスクとなり得るかを示唆しています。エンジニアリングリーダーやアーキテクトに対して、単一障害点(SPOF)の排除と、フェイルオーバー戦略の自動化の重要性を再認識させる重要な教訓となっています。
編集コメント
パフォーマンスと可用性のバランスは常に難しい課題ですが、Coinbase の事例は「設計上の妥協」がシステム全体の信頼性にどう影響するかを如実に示しています。
こんにちは、Pragmatic Engineer ニュースレターの特別無料号をお届けする Gergely です。毎号、シニアエンジニアやエンジニアリングリーダーの視点からビッグテックとスタートアップを取り上げています。今回は、先回の『The Pulse』号で取り上げた 4 つのトピックのうちの一つを扱います。フルサブスクライバーには、以下の記事が 2 週間前に配信されています。このメールを転送された方は、こちらから購読できます。
5 月 7 日(木)の夜、Coinbase の取引サービスがオフラインになり、約 10 時間 (!!) その状態が続きました。顧客は購入、売却、入金、受取、出金のいずれも行うことができませんでした。要するに、Coinbase の中核サービスが利用不可能になったのです。
この障害は、リージョン単位での AWS アウトタイムとタイミングを合わせて発生しました。しかし、他の企業でグローバルなアウトタイムが発生した例はありませんでした。私が観察したのは、Datadog などの一部のインフラ企業がいくつかのリージョンに問題があり、健全なリージョンへフェイルオーバーしているという報告程度です。
Coinbase は 400 億ドル規模の企業でありながら、顧客に対して回復状況を AWS のステータスページで確認するよう指示しました。これは、同社が単一の AWS ゾーンに完全に依存していることを明確に示しています。異例にも Coinbase はこの情報をステータスページから削除しましたが、私はその前にスクリーンショットを保存していました:
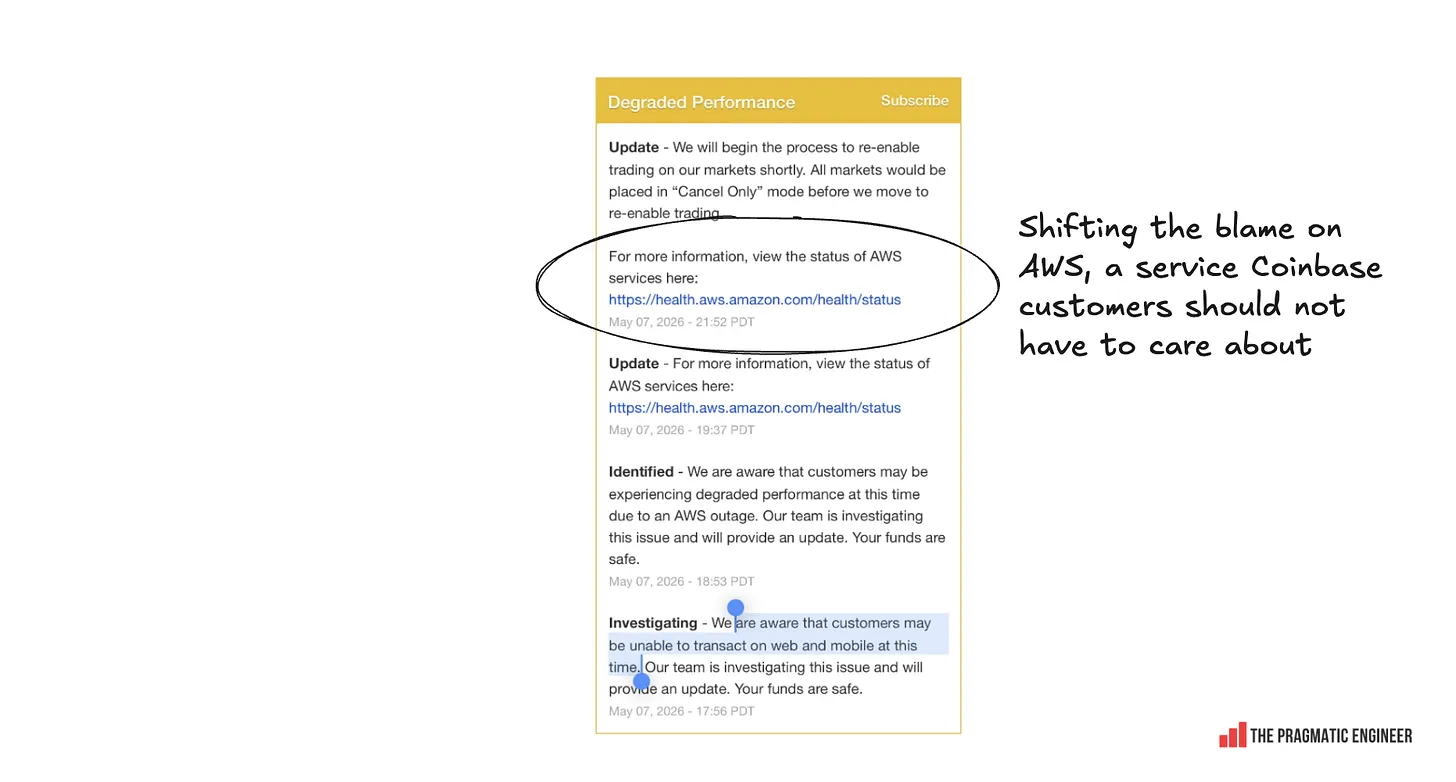 image公開された状況:Coinbase がアウトタイムの責任をクラウドプロバイダーに転嫁
image公開された状況:Coinbase がアウトタイムの責任をクラウドプロバイダーに転嫁
Coinbase は後に、確かに単一の可用性ゾーンへの依存関係があることを確認しました。そのポストモーテム(事後分析)によると:
「当社のマッチングエンジンは単一の建物に固定されていました。Coinbase Exchange のマッチングエンジンは、AWS クラスター配置グループ内で Raft ベースのレプリケートクラスタとして実行されています。この選択は意図的に行われたものです。深刻な市場のレイテンシとスループット要件を満たすマッチングエンジンが、投票クラスタメンバー間のゾーン間ネットワークホップを許容することはできません。分散合意の物理法則と、公平で流動的な注文帳を運用する経済性は、同じ答えを示しています。それはコロケーションです。」
可用性ゾーン(AZ)とリージョンの違いについての簡単な復習:
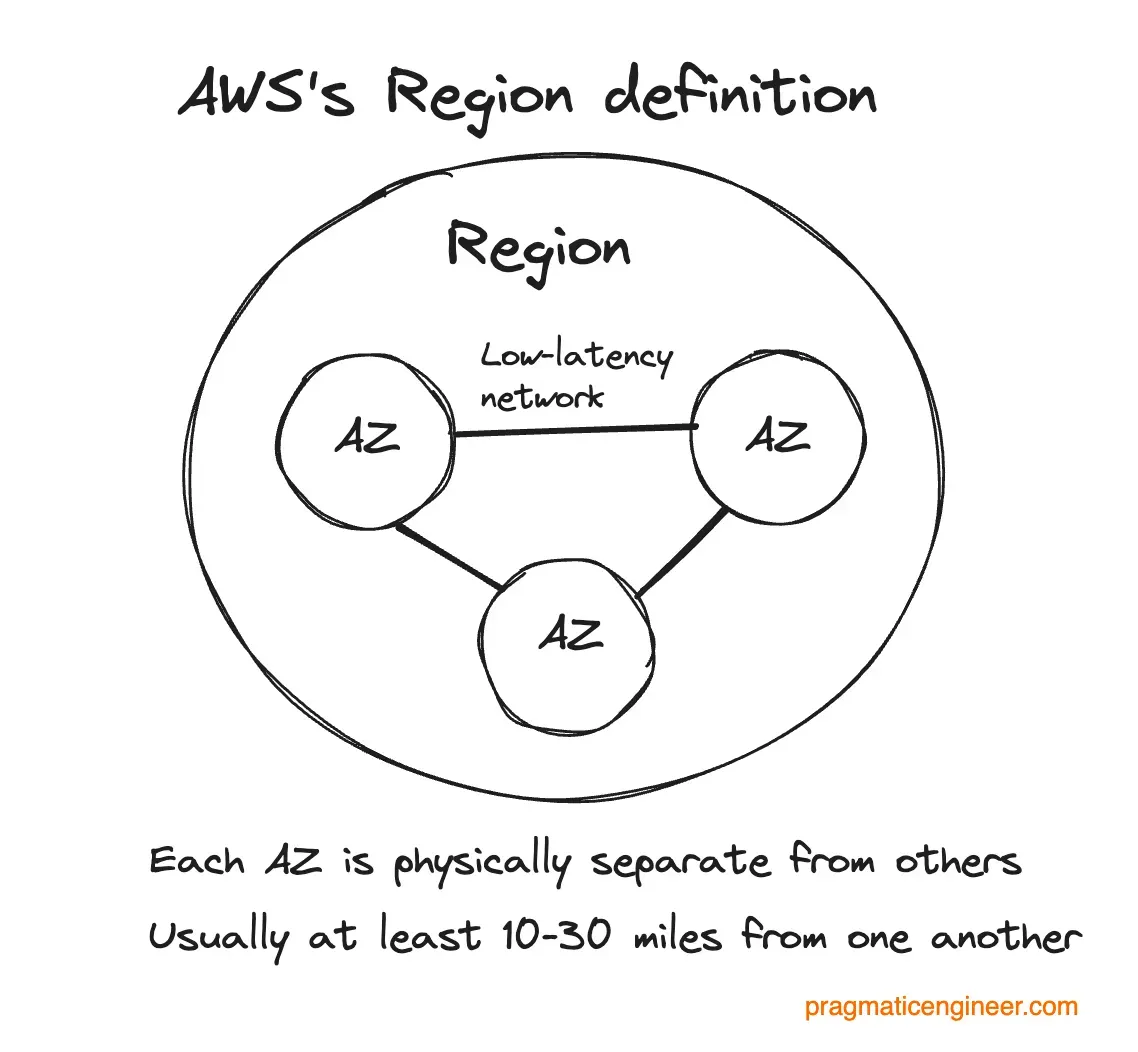
可用性ゾーン:1 つ以上のデータセンター(AWS の場合は通常複数のデータセンター)が互いに低レイテンシで接続できるほど近接して配置されたもの。異なる AZ にあるデータセンターは、それぞれ独立した耐障害性を備えている必要があります。同じ AZ 内ではそのような要件はありません。
リージョン:AWS においては、少なくとも 3 つの論理的に分離され、物理的に隔てられた可用性ゾーンで構成されており、通常は 10〜30 マイル離れています。極端な状況下であっても、これらが同時にダウンすることは稀です。
 image深掘りから、三つのクラウドプロバイダー、三つの障害、三つの異なる対応
image深掘りから、三つのクラウドプロバイダー、三つの障害、三つの異なる対応
Coinbase は、複数のアベイラビリティゾーン(AZ)(建物)で運用することは、製品に過度なレイテンシをもたらすと述べています。これは低レイテンシが求められる取引のような活動には理にかなっています。しかし、AZ がダウンした際にフェイルオーバーを準備しておくことについてはどうでしょうか?そもそも、AZ が高稼働率を保証されているわけではありません。
実は、Coinbase は AZ のフェイルオーバーの準備をしていませんでした。また、その事後分析(強調は私による)からも明らかです:
「我々は、別のアベイラビリティゾーンへ自動的にフェイルオーバーする能力を欠いていました。AWS が東部標準時 9 時 29 分に配置グループ内の EC2 インスタンスを終了させた際、5 つのマッチングエンジンノードのうち 3 つがダウンし、クォーラムを失いました。自動的なクロスゾーンフェイルオーバーは存在しませんでした。復旧には、インシデント発生中に緊急にコード変更をリリースして、クラスタノード 5 つすべてが解決可能であるという起動時の前提を取り除くこと、障害のある配置グループの外側に新しいノードグループを作成すること、そして慎重な手順で 3 対 5 のクォーラムを復元することが必要でした。これにより、市場の再開が可能となりました:まずキャンセルのみ許可モード、次にオークションモード、最後に完全取引モードです。」
Coinbase のような規模の事業において、自動フェイルオーバー機能がないことは信じられないほど未熟である。Coinbase は年間約 5.2 兆ドルの取引を扱い、時価総額は約 400 億ドルと評価されている。私の簡易計算によると、今回の停止により約 70 億ドル相当の金融活動が中断された。
2016 年当時、Uber の時価総額は Coinbase とほぼ同程度であり、年間約 400-500 億ドルを処理していた。Uber は東海岸と西海岸に 2 つのデータセンターを持ち、2 つのゾーンで運用されているかのように運営されていた。当時私は Uber で働いていたが、あるリージョンがダウンした場合に備え、別のデータセンター(別のリージョン)への定期的なフェイルオーバー訓練が行われていた。財務数値という点での Uber の事業規模は、Coinbase のほんの一部に過ぎない!
今回のインシデントにより、私の Coinbase のエンジニアリング文化に対する評価は低下した。CEO のブライアン・アームストロングが、AI のおかげで非技術チームが生産環境のコードをリリースできるようになったと自慢していることには、ほとんど喜劇的ださえ感じる。2016 年の Uber よりも、Coinbase のインフラの基礎が 2026 年においてさらに劣悪な状態にあるように見える中で、この点に焦点を当てるのは明らかに誤りである!
どうやら Coinbase は、過去のリージョン別 AWS 停止による被害から教訓を得ていないようだ。2025 年 10 月、同社は AWS の DynamoDB サービスの問題により、3 時間にわたるグローバル取引停止に直面した。その停止後、Coinbase のエンジニアリングチームは(強調は私による)次のように述べている:
「今後より万全に備えるために、私たちはあらゆる選択肢を検討しており、地域展開戦略の見直しを含む、これらの種類の障害の影響を軽減するための即時的かつ長期的な対策の実装を進めています。」
この地域展開戦略を見直す過程において、明らかに本事業の中核となる部分における単一ゾーン依存のリスクや、ゾーン間フェイルオーバーの欠如というリスクが見過ごされていたか、無視されていたことが明らかです。
The Pulse 誌の完全版をお読みください。
原文を表示
Hi, this is Gergely with a bonus, free issue of the Pragmatic Engineer Newsletter. In every issue, I cover Big Tech and startups through the lens of senior engineers and engineering leaders. Today, we cover one out of four topics from this past The Pulse issue. Full subscribers received the article below two weeks ago. If you’ve been forwarded this email, you can subscribe here.
On the evening of Thursday, 7 May, trading at Coinbase went offline and stayed that way for nearly 10 hours (!!). Customers could not buy, sell, deposit, receive, or withdraw. Basically, the core services of Coinbase were unavailable.
The outage coincided with a regional AWS outage. But no other company suffered a global outage; the most I observed was a few infra companies like Datadog noting that some regions had issues, and were failing over to a healthy region.
It’s weird that Coinbase – a $40B company! – told customers to monitor AWS’s status pages for recovery. This made it pretty clear that the company fully depends on a single AWS zone. Unusually, Coinbase deleted this information from its status page, but I got a screenshot first:
imageOut in the open: Coinbase shifts blame for outage to a cloud providerCoinbase later confirmed that it does indeed have a single-availability zone dependency. From its postmortem:
“Our matching engine was pinned to a single building. The Coinbase Exchange matching engine runs as a Raft-based replicated cluster inside an AWS Cluster Placement Group. We make this choice deliberately. A matching engine that meets the latency and throughput demands of a serious market cannot tolerate inter-zone network hops between voting cluster members. The physics of distributed consensus and the economics of running a fair, liquid order book point to the same answer, which is co-location.”
A quick recap on the difference between an availability zone (AZ) and region:
Availability zone: One or more data centers (in the case of AWS, it is usually several data centers) located close enough to have low latency between them. Data centers in different AZs must be independently resilient. In the same AZ, there is no such requirement.
Region: Within AWS, this consists of at least three isolated, physically separated AZs, usually 10-30 miles apart. It’s unlikely they’ll go down simultaneously, even in extreme circumstances.
imageFrom deepdive, Three Cloud Providers, Three Outages, Three Different ResponsesCoinbase is saying that running from more than one availability zone (AZ) (building) would introduce too much latency to their product. This makes sense for low-latency activities like trading. But what about preparing for a failover as and when the AZ goes down? After all, an AZ is not guaranteed to have high uptime!
Turns out, Coinbase did not prepare for a failover for an AZ. Also from its postmortem (emphasis mine):
“We lacked an automated ability to fail over to another availability zone. When AWS terminated EC2 instances inside our placement group at 9:29 PM ET, three of five matching-engine nodes went down and we lost quorum. There was no automated cross-zone failover. Recovery required an emergency code change shipped during the incident to remove a startup assumption that all five cluster nodes were resolvable, the creation of a new node group outside the impaired placement group, and a careful sequence to restore a 3-of-5 quorum. This allowed us to reopen markets: first cancel-only, then auction mode, and finally full trading.”
Having no automated failovers is incredibly amateurish for an operation of Coinbase’s scale. Coinbase moves about 5.2 trillion dollars per year, and is valued at around $40B. The outage interrupted around $7 billion-worth of financial activity, based on my napkin math.
Back in 2016, Uber was valued at roughly as much as Coinbase, and handled circa $40-50B yearly. It had two data centers on the east and west coasts, and operated more as if it ran out of two zones. I worked at Uber at the time and there were regular failover drills to another data center (another region), in preparation should a region go down. Uber’s business, in terms of the financial figures, was a fraction of Coinbase’s!
My impression of Coinbase’s engineering culture has sunk after this incident, and it’s almost comical that CEO Brian Armstrong is boasting that non-technical teams now ship production code, thanks to AI. This feels like the wrong thing to focus on when Coinbase’s infrastructure basics seem to be in far worse shape in 2026 than Uber’s were a decade ago in 2016!
It seems Coinbase did not learn lessons after getting burned by previous regional AWS outages. In October 2025, the company suffered a three-hour-long global trading outage due to issues with AWS’s DynamoDB service. Following that outage, Coinbase engineering said (emphasis mine):
“To be better prepared in the future, we are exploring all options, including reviewing our regional deployment strategy to implement immediate and long-term fixes to reduce the impact of these types of outages.”
That process of reviewing the regional deployment strategy evidently missed or ignored the risk of a single-zone dependency of the heart of the business, with no cross-zone failover.
Read the full The Pulse issue.
関連記事
Amazon、AIチップ販売でNvidiaに直接挑戦する方針
Amazonは自社開発のAIチップを販売することで、市場を支配するNvidiaに対してより直接的な競争を仕掛ける計画である。
機械のためにインターネットが再構築されている
TechCrunch AI は、AI や機械が効率的にアクセス・処理できるよう、現在のインターネットインフラを根本から再設計する動きについて報じています。
AWS データセンターネットワークにおける「フラット構造」が「ファットツリー」を代替する理由
Amazon Science は、従来の階層型データ構造である「ファットツリー」に代わり、より効率的なルーティングを実現する「フラット構造」の導入について解説している。この技術は、AWS のデータセンターネットワークのパフォーマンス向上に寄与する可能性がある。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み