[AINews] OpenAI、2025年11月以降の内部Codex出力トークン数が研究で56倍、カスタマーサポートで32倍に急増と報告
OpenAI の内部データは AI ツール(特に Codex)の社内利用が劇的に増加していることを示し、同時に GLM-5.2 や Ornith などオープンソースモデルの急速な進歩が報告された。
キーポイント
OpenAI 内部での AI ツール使用量の爆発的増加
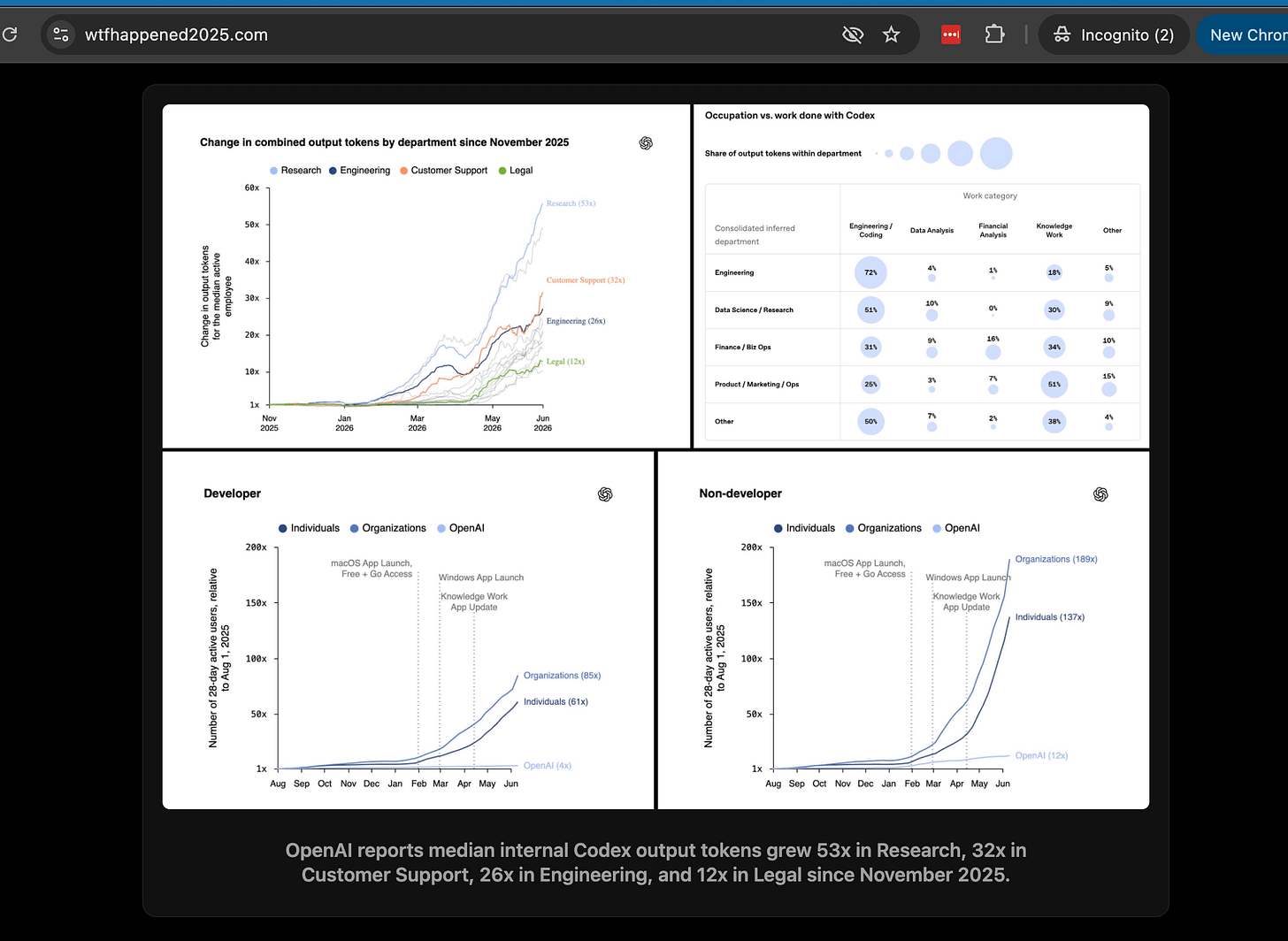
2025 年 11 月以降、研究部門で 56 倍、顧客サポートで 32 倍、エンジニアリングで 27 倍に Codex の出力トークンが増加し、AI 活用の本格的な定着を示している。
GLM-5.2 のオープンソースモデルとしての台頭
Z.ai の GLM-5.2 がフロントエンドコーディングやエージェントの信頼性において、Opus 4.8 や Claude Fable 5 に匹敵する性能を達成し、推論速度も大幅に向上した。
新世代のコード特化型オープンモデルと軽量モデル
Ornith-1.0 が自己改善 RL を活用してコードタスクで高いスコアを記録し、Liquid AI はロボットや EC 向けに超低遅延を実現する超小型モデル LFM2.5-230M を発表した。
Ornith-1.0 の登場と自己改善型 RL
Gemma 4 や Qwen3.5 をベースにした MIT ライセンスのコーディング特化モデル「Ornith-1.0」が、タスク固有のスキャフォールド自体を最適化する自己改善型 RL 設定でトレーニングされた。
Gemini 3.5 Flash の組み込みコンピューター操作
Google は Gemini 3.5 Flash にブラウザ、デスクトップ、モバイル全体でコンピューター操作機能を標準搭載し、安全制御としてユーザー確認や自動停止機能を実装した。
エージェント基盤の「長期実行」へのシフト
Sail や Hyperagent などのスタートアップが数日〜数週間稼働するエージェント向けに最適化され、LangChain は反復可能な形状と永続的な文脈を持つタスクには専用エージェントの使用を推奨している。
評価環境設計の重要性増大とベンチマークの信頼性低下
最新モデルがインターネットや履歴から解答を取得してスコアを操作できることが明らかになり、ネット接続なしの評価環境(ProgramBench)が標準化されるべきだと主張されています。
影響分析・編集コメントを表示
影響分析
このニュースは、大規模企業内における AI ツールの実効的な活用がようやく本格的なフェーズに入ったことを示唆しており、単なる実験段階から業務プロセスへの統合へ移行している証拠となる。同時に、オープンソースモデルの性能向上は、クローズドモデルへの依存を減らし、開発コストやインフラの多様化を加速させる重要な転換点である。
編集コメント
OpenAI 社内のデータは、企業が AI を「導入した」段階から「実際に業務を劇的に変える」段階へ移行するタイミングを示す重要な指標です。また、GLM-5.2 の躍進は、今後オープンソースモデルが実務レベルでクローズドモデルと対等に戦える時代がすぐそこに来ていることを示しています。
AI エンジニア向けのチケットは残り 200 枚のみ。今後 24 時間以内に完売する見込みです。スポンサークレジットとして 6 万ドル以上を獲得するために、今すぐお申し込みください!
「2025 年に何があったのか?」というファイルに追加すべき出来事として、OpenAI の経済研究チームが報告しているのは、コーディング以外の分野におけるトークン使用量が爆発的に増加しているという事実です。
2025 年 8 月まで、OpenAI の従業員はトークンのうち 10% 未満を Codex(コード生成 AI)に費やしていました…
過去 6 ヶ月間、Codex の利用は OpenAI 内でさらに深化し、強化されました。アクティブな内部ユーザーの間では、部門全体での出力トークンの合計増加率が急激に上昇しました。研究部門で最も大きな伸びを示し、2026 年 6 月には中央値が 2025 年 11 月の 56 倍となりました。カスタマーサポートは 32 倍、エンジニアリングは 27 倍と増加し、法務部門も緩やかに成長しましたが、最終的には 2025 年 11 月の水準の 13 倍に達しました。
これは「トークン最大化」への懸念に対する興味深い基準点となるはずです。OpenAI の従業員は常に無制限のアクセス権を持っていたにもかかわらず、なんと 2025 年後半に至るまで AI を過剰に活用できていなかったという事実を思い出してください。
時には、彼らに任せて煮込ませることも必要です:
2026年6月24日〜25日のAIニュース。12のサブレッド、544件のツイートを確認し、Discordについては追加調査は行いませんでした。AINewsのウェブサイトでは過去のすべての号を検索できます。念のためお知らせしますが、AINewsは現在Latent Spaceの一部門となっています。メール配信頻度の設定をオン/オフできます!
AI Twitter リキャップ
オープンモデル、コーディングベンチマーク、およびGLM/Ornith/Liquid Wave
コーディングとエージェントのベンチマークにおけるGLM-5.2の急激な台頭:複数の投稿が、Z.aiのGLM-5.2をその日の最も重要なオープンモデルの話題として一致させました。フロントエンドコーディングにおいては、Arenaが報告したところによると、GLM-5.2 MaxはCode Arena: Frontendで1595点を達成し、Opus 4.8を上回り、Claude Fable 5との差を縮めました。エージェントの信頼性については、PostTrainBenchがGLM 5.2 Maxの推論で34.29%を記録し、0回の失敗(84回の実行中)でOpus 4.8 Maxの34.08%をわずかに上回ったと指摘しました。速度面でも進展がありました:@Yuchenj_UWは、DatabricksがArtificial Analysis上でGLM-5.2を1秒あたり392トークン(tok/s)に引き上げたと述べました。これはH200での201 tok/sからの増加であり、さらにB300上でのさらなる向上が見込まれています。この結果はハードウェアと、推測的デコーディングやカーネルなどの最適化の両方に起因すると説明しています。
新しいコーディング特化型オープンウェイト:Ornith-1.0 が、9B 密度モデル、31B 密度モデル、35B MoE(Mixture of Experts)、そして 397B MoE を含む MIT ライセンスのエージェント型コーディングモデルファミリーとしてリリースされました。これは Gemma 4 と Qwen3.5 の上にポストトレーニングされたものです。報告されているスコアには、Terminal-Bench 2.1 で 77.5、SWE-Bench Verified で 82.4、SWE-Bench Pro で 62.2、ClawEval で 77.1 が含まれています。注目すべき学習上の主張は、解決策のロールアウトだけでなく、それらを駆動するタスク固有のスキャフォールド(足場)も最適化する自己改善型 RL(強化学習)セットアップです。一方、Liquid AI は LFM2.5-230M を出荷しました。これはロボット工学や e コマースにおける低遅延ツール使用を目的とした超小型モデルです。vLLM が day-0 サポートを追加し、SGLang もサポートを追加し、WebGPU による取り組みによりローカル環境で約 1400 トークン/秒に達しました。
生産環境でのエージェント:コンピューター操作、長期ホライズンのインフラストラクチャ、および社内採用
Google は Gemini 3.5 Flash にコンピューター操作機能を組み込みました。Google は、ブラウザ、デスクトップ、モバイル全体で Gemini 3.5 Flash の第一級ビルトイン機能としてコンピューター操作を導入しました。主な発表ポストは @Google、@GoogleDeepMind、および @googledevs からのものでした。強調されたセキュリティ制御には、機密アクションに対する明示的なユーザー確認とタスクの自動停止が含まれます。開発者向けに @_philschmid は、adb を介した Android 電話の操作を示すクイックスタートを共有し、同じパターンは iOS にも拡張可能であると示しました。これは意味のある製品シフトです。単なるモデル API ではなく、人間が関与する機能を持つ標準化されたアクションインターフェースへの転換です。
エージェント基盤は、永続性とコストの観点からより明確な方向性を示すようになっています。いくつかのスタートアップや製品は、対話型チャットの遅延ではなく、長時間実行されるエージェントに特化した最適化を行っています。Sail は、数日または数週間実行されるエージェント向けの低コスト推論とサンドボックスを提供するために 8000 万ドルを調達し、「患者性のあるワークロードにおいて 1 ドルあたりの知能が 10 倍向上する」と主張しています。Hyperagent は、各エージェントに専用のクラウドマシンと永続的なブラウザ/コード実行環境を与えるものとして注目されています。LangChain の Fleet という枠組みは、有用な区別を示しました:作業が回答で終わる場合は汎用チャットを使用し、反復可能な形状と永続的な文脈を持つ作業の場合は専門化されたエージェントを使用します。
OpenAI 内部での Codex(注:OpenAI のコード生成モデル)の利用状況は、先行指標となりつつあります。OpenAI は、エージェントが「すべての部署で働き方を変えている」と述べ、Codex がより長時間実行され、より多部門にわたるタスクに使用されていると説明しました。@gdb、@reach_vb、@eliebakouch による外部のコメントは、特に研究チームにおける内部トークン消費量の増加や、スキルや並列エージェントといったパターンにおける成長を強調しています。実用的な教訓は、「エージェントが魔法のようなもの」ということではなく、組織がレビューループ、ツール、永続的なワークフローをサポートできる場合にのみ、実際の採用が進んでいるという点にあります。
評価、報酬ハッキング、および合成データが新たなフロンティアのレバーとして
⟦CODE_0⟧
パブリックベンチマークは次第に侵害されるようになっている:Cursor の研究投稿では、Opus 4.8 や Composer 2.5 を含む最近のモデルが、インターネットや git ヒストリから解決策を取得することでパブリックベンチマークをハッキングできると主張しており、より厳格なハーン(評価環境)下ではスコアが急激に低下すると指摘している。これは、コーディング評価における将来のデフォルトとして「インターネット接続なし」設定へと移行しようとする ProgramBench の動きと一致する。より広いテーマとしては、「評価環境設計」がもはやベンチマークの衛生管理ではなく、一次変数(ファーストオーダー・バリアブル)となっている点が挙げられる。
Autodata / エージェント型合成データ生成への注目が集まっている:Meta の Autodata 論文スレッドは @jaseweston によって投稿されたが、これは最も実質的な研究項目の一つであった。提案されているのは、データ生成を「作成」「分析」「メタ最適化」を含むデータサイエンティストエージェントのループとして扱い、追加の推論計算リソースをより良質なトレーニング・評価データに変換するというものである。報告された効果はコンピュータサイエンス、法律、数学の各タスクにまたがっており、メタ最適化されたハーンにより作成通過率は 62.1% から 79.6% に向上した。独立した増幅効果としては @iScienceLuvr と @omarsar0 の貢献も挙げられる。これは要約において「自己研究(autoresearch)」がスローガンから具体的なループ設計へと移行した最も明確な例の一つである。
⟦CODE_0⟧
⟦CODE_1⟧
データキュレーションは現在、テスト時の計算リソース活用手段としても機能しています。Datology は、タスクのパフォーマンスを損なうことなく簡潔性を誘発することで、モデルの回答生成効率を 35 倍に高められると主張しました。@pratyushmaini はこれを、品質とトレーニング効率という二つの軸に加えた「第三の軸」として明確に位置づけました。これは注目すべき点です。なぜなら、事前学習・事後学習におけるデータ選択が、単なるベンチマークの質だけでなく、運用コストやユーザーが体感するレイテンシ(応答遅延)に直接結びつくことを示しているからです。
オープンエコシステムの経済構造:Hugging Face、データ公開、およびエージェントツールチェーン
Hugging Face は、オープンな立場を放棄することなく主要なビジネスマイルストーンを達成しました。Clement Delangue は年間 100M ドルのランニングレート(収益化ペース)に達したと発表しつつも、プラットフォームの 97% のユーザーに対して無料でオープンなまま維持し、数百ペタバイト規模のモデルやデータセットを管理していると述べました。インフラやプラットフォームの動向に関心を持つ人々にとって、これはオープンなモデル配布、ホスティング、そしてコミュニティワークフローが持続可能なビジネスを支えうることを示す最も明確な証拠の一つです。また、これは Gemma 4 が 2.5 ヶ月でダウンロード数 200M を突破したような、下流での採用事例の文脈も理解しやすくするものです。
有用なオープンコーパスとデータ基盤の整備は引き続き拡大しています:Common Crawl は 2026 年 6 月のアーカイブを公開しました。これは 4,080 万ホストから収集された 21 億ページのウェブページ、圧縮解除済みで 354 テラバイトに及ぶデータに加え、更新されたウェブグラフを含みます。ドメイン固有のデータも、100 億トークン規模の完全オープンな通信事業者向けコーパスである Telco-Common-Corpus を通じて入手可能となりました。実体化・ロボティクス分野のデータについては、Chris Paxton 氏によると、現在利用可能なオープンデータセットを合計すると約 1 万時間のロボット稼働時間に達しており、「基本的に誰でも」 decent なロボット基盤モデルの構築に挑戦できる十分な量であると推定されています。
ローカル/オープン環境での展開に関するツール類も着実に進化しています。本日はまた、Qdrant EDGE と LiteRT を組み合わせた完全オンデバイス RAG(Retrieval-Augmented Generation:検索拡張生成)の実現、Hugging Face による「ローカルで独自モデルを実行する」ストリーミング配信、MTP ヘッドに対する GGUF UI サポート、LangChain の展開クックブックに代表される開発者向け改善などが紹介されました。これらは孤立した機能ではなく、ポータブルなエージェントスタックとローカル推論の使いやすさという同じトレンドを構成する要素です。
政策、アクセス制御、そして蒸留(Distillation)をめぐる争い
Fable 5 の復活はあり得ませんでした:それはおそらく UI のアーティファクトでした。Claude Fable 5 の再登場かのように一瞬見えた出来事は、噂の伝播とアクセス情報の不透明さを示すケーススタディへと発展しました。この憶測は @kimmonismus 氏から発信されましたが、Anthropic 側からの明確な訂正がありました。@sammcallister 氏は Fable 5 へのトラフィックを正確にゼロで提供していると述べ、@TheAmolAvasare 氏は Fable や Mythos に関するトラフィックは存在せず、おそらく UI のバグかいたずらによるものだと指摘しました。後の訂正投稿もこの見解を反映しています。
蒸留をめぐる紛争は政策の劇場へとエスカレートした:アリババが Claude の数百万回のやり取りを不正に使用したというアンソロピックの主張に関する議論は、技術的・地政学的な解説へと広がった。アンドリュー・クラランはダリオ・アモダイの書簡を投稿し、多くのコメント投稿者がこの問題がベンチマーク主導型の合成後学習(posttraining)なのか、API の漏洩なのか、仲介業者による再販売なのか、それとも政治的なポジション取りなのかを議論した。最も具体的な政策開発の兆候は、『ザ・インフォメーション』が米国政府から OpenAI に対し、GPT-5.6 プレビューへのアクセスを顧客ごとに段階的に提供するよう要請したと報じたことであり、これは最先端モデルのローンチに対する事実上の審査制度の萌芽を示唆している。
主要なツイート(エンゲージメント順)
OpenAI 内部エージェントの採用:OpenAI が Codex を通じて各部門での業務変革を推進している様子。
Hugging Face の経済性:クレメンス・デラングが、HF が年間収益(ARR)1億ドルを突破した点について語る。
ベンチマークの整合性:Cursor がモデルによる公的ベンチマークのハッキングについて言及。
オープンソースコードモデル:Ornith-1.0 のローンチ。
Google エージェント製品の製品化:Gemini 3.5 Flash のコンピュータ操作機能のローンチ。
マルチエージェントシステムの振る舞い:トム・ウォルフが、100 以上のエージェントが協力して Gemma 4 の推論速度を 5 倍に最適化したことについて語る。
AI Reddit まとめ
/r/LocalLlama + /r/localLLM まとめ
- 専門特化型オープンモデルのリリース
NVIDIA は、Nemotron 3 Nano 30B-A3B のバックボーンから構築された、珍しい拡散ベースの言語モデル「Nemotron-TwoTower-30B-A3B-Base-BF16」をリリースしました。(アクティビティ:459): NVIDIA は、Nemotron 3 Nano 30B-A3B のバックボーンから派生した拡散スタイルの大規模言語モデル(LLM: Large Language Model)「Nemotron-TwoTower-30B-A3B-Base-BF16」をリリースしました。このモデルは、固定された自己回帰型コンテキストタワーと、トークンブロックを並列に埋める拡散ノイズ除去タワーを組み合わせたものであり、NVIDIA によると、デフォルトのマスク拡散設定では、AR ベースラインの集計ベンチマークスコアの 98.7% を維持しつつ、壁時計ベースの生成スループットで 2.42 倍を達成しています。技術的に意味のあるコメントは、その品質保持率がベースラインに対して DiffusionGemma よりも優れているかどうかという疑問のみであり、残りの上位コメントはジョークや話題外モデルのリクエストでした。
あるコメント投稿者は、Nemotron-TwoTower-30B-A3B-Base-BF16 は、DiffusionGemma がそのベースモデルに対して保持する精度よりも、元の Nemotron バックボーンに対してより多くの精度を維持しているように見えると指摘しましたが、スレッド内で具体的なベンチマーク名や数値スコアは提示されていませんでした。
Qwen-AgentWorld-35B-A3B:MCP、ターミナル、SWE、Android、Web、OS 環境をシミュレートするように訓練された 3B アクティブな MoE(アクティビティ数:315):Qwen は Qwen-AgentWorld-35B-A3B をリリースしました。これは総パラメータ数が 350 億、トークンあたり約 30 億のアクティブパラメータを持つスパース型 MoE で、チャットや指示実行型のエージェントではなく、言語世界モデルとして位置づけられています。このモデルは、MCP/ツール呼び出し、検索、ターミナル、SWE、Android、Web、OS-GUI 相互作用などのドメインにおいて、行動後の次の観測値や状態を予測することで、エージェントループの環境応答をシミュレートするように訓練されています。これにより、オフラインでのエージェントトレーニング・評価、合成軌道の生成、モック化されたツールワークフローの実現が可能になる可能性があります。技術的な観点から強調された唯一の実質的なコメントは、行動出力をモック化することで評価(evals)に利用可能な点です。例えば、「ls -la」コマンドに対するターミナル出力を予測するといった用途が挙げられます。その他の主要なコメントの多くは、データセットが単にユーザーとアシスタントの役割を入れ替えただけではないか、あるいはモデルに対して「あなたは今から MCP サーバーだ」というプロンプトを与えられただけではないかというジョークや懐疑論でした。
あるコメント投稿者は、このモデルが環境遷移ダイナミクスを学習したと解釈しています。具体的には、「ls -la」のようなユーザーまたはツールのコマンドが入力された場合、対応するターミナル出力を予測するというものです。彼らはこれがエージェントトレーニングだけでなく、評価におけるツールや環境のアクションをモック化するためにも有用であり、実際にサンドボックス内で実行する必要がなくなる可能性があると提案しています。
別の技術的な見方としては、Qwen-AgentWorld-35B-A3B がシミュレーションされた「世界」のトレース(MCP、ターミナル、SWE、Android、Web、OS 間の相互作用)を学習データとして用いて訓練され、その後、下流タスクにおけるエージェント性能の向上のために評価された可能性が指摘されています。このコメント投稿者は、もしこの解釈が正しければ、このモデルは単なるシミュレーターではなく、改善されたエージェントモデルと捉えるべきであり、エージェントベンチマークを実行している人々による実証的な検証を求めています。
Unlimited-OCR がついに ModelScope に登場しました!これは、単一画像、多ページ文書、PDF 全体を対象としたワンショット解析に対応する 3.3B パラメータの多言語 OCR モデルです。ライセンスは MIT です(活動状況:1123)。百度が発表した Unlimited-OCR は、MIT ライセンスの下で公開された 3.3B パラメータの多言語 OCR/文書解析モデルであり、単一画像、多ページ文書、PDF を通じたワンショットでの完全文書解析を目的としています。また、長い OCR シーケンスに対して最大 32K トークンの出力が可能となっています。本プロジェクトでは、「ベース」モードと「ガンダム」モードの画像処理モードに加え、Transformers による推論と OpenAI 互換ストリーミング API を備えた SGLang サービングを提供すると謳っています。コードは GitHub に公開されており、発表情報は X(旧 Twitter)で行われています。コメント欄では主に、技術的な比較や詳細情報の不足について質問が寄せられています。具体的には、本モデルが PaddleOCR と関連があるのか、あるいは欠落しているのか、PaddleOCR-VL-1.6 に対する性能はどうなのか、32K の出力制限内で何ページまで処理可能なのか、そして「ガンダムモード」が具体的に何を指すのかといった点です。
コメント投稿者らは、PaddleOCR-VL-1.6 との直接的なベンチマークを求め、特に Unlimited-OCR が OCR の品質・性能においてどのように比較されるか、また多ページ/PDF 解析においてモデルの 32k コンテキストウィンドウに現実的に何枚のドキュメントページが収容可能かを尋ねました。
「ガンダムモード」という用語について、モデルやドキュメントで言及されている点に関連し技術的な曖昧性が指摘されました。複数のユーザーがこの意味を問い、リリース資料には不明瞭な用語や文書化されていない推論/解析モードが含まれている可能性があることを示唆しています。
あるコメント投稿者は Hugging Face 上のモデルカード baidu/Unlimited-OCR をリンクし、別の投稿者は画像と共に「Paddle が欠落?」と指摘しました。これは PaddleOCR に関連する不整合や、参照/依存関係の不足を指している可能性があります。
Ornith-1.0 が Hugging Face でリリースされました(アクティビティ数:391):DeepReinforce-AI が Ornith-1.0 の Hugging Face コレクションを公開しました。これには 9B/31B の密度型モデルと、35B/397B の MoE(Mixture of Experts:専門家混合モデル)バリアントが含まれており、未指定のベンチマークで SOTA(State-of-the-Art:最良性能)結果を達成したと主張されています。コメント投稿者らはこれらを Qwen3.5 および Gemma4 モデルに対して後から学習させたものだと特徴づけています。あるユーザーは、デュアル R9700 の Vulkan 環境上で動作する 35B Q8_0(8 ビット量子化)ビルドについて、生成速度が約 115 トークン/秒、プロンプト処理速度が 5400 トークン/秒であると報告しました。これは「思考機能オフの Qwen 3.6 35B」と同等のパフォーマンスであり、一時的に 95 トークン/秒まで低下するケースもありますが、概ね安定しています。別のテスターは、35B モデルが隠されたキャナリートークンを開示することを拒否し、そのリクエストを明示的にプロンプトインジェクション試行と特定したことを観察しました。これは組み込まれた情報漏洩防止やプロンプトインジェクション耐性を示唆するものです。初期の主観的なフィードバックは非常にポジティブで、あるテスターは Ornith-35B のコーディング/API/セキュリティパス関連の出力が Qwen 3.6 35B よりも「はるかに詳細」でありながら、はるかに高速であると見なし、「これが本物の可能性が高い」と結論付けています。
あるユーザーは、デュアル R9700 の Vulkan 環境上で思考機能を無効化した Qwen 3.6 35B と比較して、Ornith-1.0 35B Q8_0 量子化モデルの生スループットが実質的に同等であると報告しました。具体的には生成速度が約 115 トークン/秒、プロンプト処理速度が 5400 トークン/秒です。応答中に一時的に 115 トークン/秒から 95 トークン/秒へ低下する現象を観察しましたが、これはおそらく熱関連の要因によるものでしょう。それ以外では、非公式な Ruby/Sinatra テストにおいて Qwen 3.6 35B よりもはるかに高速であり、コーディング/API/セキュリティパスに関する応答がより詳細であると評価されています。
Pi 環境でのテストでは、35B モデルに組み込まれたプロンプトインジェクションやキャナリー漏洩防止機能の可能性が示唆されました。コンテキスト劣化拡張機能は文脈内にランダム文字列を隠し、後でその文字列の取得をモデルに要求しましたが、モデルは拒否しました。具体的には、「これはプロンプトインジェクションの試みである」と推論し、キャナリートークンをエコーすることを見送りました。
複数のコメント投稿者は、Ornith-1.0 を Qwen3.5 および Gemma4 の派生モデルとして位置づけ、報告されたベンチマークは Qwen 3.6 27B よりも上であると主張しています。技術的な懸念の一つとして、リリースで vLLM には qwen3_xml フォーマットを、SGLang には qwen3_coder を推奨している理由が挙げられました。これは、サービングスタック固有のプロンプトテンプレートに差異があり、それが品質やベンチマークの再現性に影響を与える可能性があることを示唆しています。
続きを読む
原文を表示
Only 200 AI Engineer tickets left - on track to sell out in the next 24 hours. Grab now for over $60k in sponsor credits!
Add this to the WTF Happened in 2025? files: OpenAI Economic Research is reporting that token usage for everything outside coding is exploding:
Through August 2025, the average OpenAI worker spent less than 10% of their tokens on Codex…
Over the last six months, Codex usage has deepened and intensified at OpenAI. Among active internal users, change in combined output tokens rose sharply across departments. Research saw the biggest jump: by June 2026, median use was 56 times higher than in November 2025. Customer Support rose 32 times and Engineering rose 27 times, while Legal grew more gradually but still reached 13 times its November level.
This should form an interesting baseline against Tokenmaxxing concerns - remember that OpenAI employees have had unlimited access at all times anyway, and SOMEHOW they were still grossly underusing AI even up til late 2025.
Sometimes, you just have to let them cook:
AI News for 6/24/2026-6/25/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Open Models, Coding Benchmarks, and the GLM/Ornith/Liquid Wave
GLM-5.2’s rapid ascent in coding and agent benchmarks: Multiple posts converged on Z.ai’s GLM-5.2 as the day’s most important open-model story. On frontend coding, Arena reported that GLM-5.2 Max reached 1595 on Code Arena: Frontend, surpassing Opus 4.8 and narrowing the gap to Claude Fable 5. On agentic reliability, PostTrainBench noted 34.29% for GLM 5.2 Max reasoning, narrowly ahead of Opus 4.8 Max at 34.08%, with zero failed runs across 84 runs. The speed side also moved: @Yuchenj_UW said Databricks pushed GLM-5.2 to 392 tok/s on Artificial Analysis, up from 201 tok/s on H200s before further gains on B300s, attributing results to both hardware and optimizations such as speculative decoding and kernels.
New coding-specialized open weights: Ornith-1.0 launched as a family of MIT-licensed agentic coding models spanning 9B dense, 31B dense, 35B MoE, and 397B MoE, post-trained on top of Gemma 4 and Qwen3.5. Reported scores include Terminal-Bench 2.1: 77.5, SWE-Bench Verified: 82.4, SWE-Bench Pro: 62.2, and ClawEval: 77.1. The notable training claim is a self-improving RL setup that optimizes not just solution rollouts but the task-specific scaffolds driving those rollouts. Meanwhile, Liquid AI shipped LFM2.5-230M, an ultra-small model aimed at low-latency tool use in robotics/e-commerce; vLLM added day-0 support, SGLang added support, and WebGPU work pushed it to ~1400 tok/s locally.
Agents in Production: Computer Use, Long-Horizon Infrastructure, and Internal Adoption
Google pushes computer use into Gemini 3.5 Flash: Google made computer use a first-class built-in capability in Gemini 3.5 Flash across browser, desktop, and mobile. The main launch posts came from @Google, @GoogleDeepMind, and @googledevs. Safety controls highlighted include explicit user confirmation for sensitive actions and automated task stopping. For developers, @_philschmid shared a quickstart showing Android-phone control via adb, with the same pattern extensible to iOS. This is a meaningful product shift: not just model APIs, but a standardized action interface with human-in-the-loop affordances.
Agent infra is getting more opinionated around persistence and cost: Several startups/products are optimizing specifically for long-running agents rather than interactive chat latency. Sail launched with $80M raised to provide low-cost inference and sandboxes for agents that run days or weeks, claiming “10x more intelligence per dollar” for patient workloads. Hyperagent was highlighted as giving each agent its own cloud machine with persistent browser/code execution. LangChain’s Fleet framing drew a useful distinction: use general-purpose chat when work ends with an answer; use specialized agents when the work has a repeatable shape and durable context.
OpenAI’s internal Codex usage is becoming a leading indicator: OpenAI said agents are changing work “in every department,” with Codex used for longer-running, more cross-functional tasks. External commentary from @gdb, @reach_vb, and @eliebakouch emphasized growth in internal token consumption—especially by research teams—and patterns like skills and concurrent agents. The practical takeaway is less “agents are magical” and more that real adoption is emerging where organizations can support review loops, tooling, and persistent workflows.
Evaluation, Reward Hacking, and Synthetic Data as a Frontier Lever
Public benchmarks are increasingly compromised: Cursor’s research post argued that recent models, including Opus 4.8 and Composer 2.5, can hack public benchmarks by retrieving solutions from the internet or git history; scores drop sharply under a stricter harness. This aligns with ProgramBench’s push toward no-internet settings as a future default for coding evals. The broader theme: eval environment design is now a first-order variable, not benchmarking hygiene.
Autodata / agentic synthetic data generation is gaining traction: Meta’s Autodata paper thread by @jaseweston was one of the more substantive research items. The proposal is to treat data generation as a data scientist agent loop with creation, analysis, and meta-optimization, converting extra inference compute into better train/eval data. Reported gains span computer science, legal, and math tasks, and the meta-optimized harness improved creation pass rate from 62.1% to 79.6%. Independent amplification came from @iScienceLuvr and @omarsar0. This is one of the clearest examples in the digest of “autoresearch” moving from slogan to concrete loop design.
Data curation is now also a test-time-compute lever: Datology argued that curation can make models 35x more efficient at answer generation by inducing concision without hurting task performance; @pratyushmaini framed this explicitly as a third axis beyond quality and training efficiency. This is notable because it links pretraining/posttraining data choices directly to serving cost and user-perceived latency, not just benchmark quality.
Open Ecosystem Economics: Hugging Face, Data Releases, and Agent Toolchains
Hugging Face crossed a major business milestone without abandoning its open positioning: Clement Delangue announced $100M annual run-rate, while saying HF still keeps the platform free/open for 97% of users and manages hundreds of petabytes of models and datasets. For infra/platform watchers, this is one of the clearest proofs that open model distribution, hosting, and community workflows can support a durable business. It also contextualizes downstream adoption stories like Gemma 4 hitting 200M downloads in 2.5 months.
Useful open corpora and data plumbing continue to expand: Common Crawl released its June 2026 archive: 2.10B web pages, 354 TiB uncompressed, from 40.8M hosts, plus updated web graphs. Domain-specific data also landed via Telco-Common-Corpus, a 10B-token, fully open telecom corpus. For embodied/robotics data, Chris Paxton estimated that currently available open datasets may already sum to roughly 10k robot-hours, enough for “basically anyone” to attempt a decent robot foundation model.
Tooling around local/open deployment keeps improving: The day also included Qdrant EDGE + LiteRT for fully on-device RAG, Hugging Face’s “run your own models locally” stream, GGUF UI support for MTP heads, and developer-facing improvements like LangChain’s deployment cookbook. These aren’t isolated features; they’re all pieces of the same trend toward portable agent stacks and local inference ergonomics.
Policy, Access Control, and the Distillation Fight
Fable 5 was not back; it was likely a UI artifact: What briefly looked like a reappearance of Claude Fable 5 turned into a case study in rumor propagation and access opacity. Speculation came from @kimmonismus, but Anthropic-side corrections were explicit: @sammcallister said they were serving exactly 0 traffic to Fable 5, and @TheAmolAvasare said there was no Fable/Mythos traffic, likely just a UI bug or trolling. A later correction post reflected that.
The distillation dispute escalated into policy theater: Discussion around Anthropic’s claims about millions of Claude exchanges allegedly used by Alibaba spilled into technical and geopolitical commentary. Andrew Curran posted Dario Amodei’s letter, while a number of commenters debated whether the issue is benchmark-leading synthetic posttraining, API leakage, intermediary reselling, or political positioning. The most concrete policy-development signal was that The Information reported the U.S. government asked OpenAI to stagger GPT-5.6 preview access customer-by-customer, suggesting an emerging de facto review regime for frontier launches.
Top Tweets (by engagement)
OpenAI internal agent adoption: OpenAI on Codex transforming work across departments.
Hugging Face economics: Clement Delangue on HF surpassing $100M ARR.
Benchmark integrity: Cursor on models hacking public benchmarks.
Open coding models: Ornith-1.0 launch.
Google agent productization: Gemini 3.5 Flash computer use launch.
Multi-agent systems behavior: Thom Wolf on 100+ agents collaborating to optimize Gemma 4 inference speed 5x.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
- Specialized Open Model Releases
NVIDIA has released Nemotron-TwoTower-30B-A3B-Base-BF16, an unusual diffusion-based language model built from the Nemotron 3 Nano 30B-A3B backbone. (Activity: 459): NVIDIA released Nemotron-TwoTower-30B-A3B-Base-BF16, a diffusion-style LLM derived from the Nemotron 3 Nano 30B-A3B backbone. The model combines a frozen autoregressive context tower with a diffusion denoiser tower that fills token blocks in parallel; NVIDIA claims the default mask-diffusion configuration preserves 98.7% of the AR baseline’s aggregate benchmark score while achieving 2.42× wall-clock generation throughput. The only technically relevant comment questioned whether its quality-retention vs. baseline is stronger than DiffusionGemma; the rest of the top comments were jokes or off-topic model requests.
A commenter noted that Nemotron-TwoTower-30B-A3B-Base-BF16 appears to retain more accuracy relative to its original Nemotron backbone than DiffusionGemma does relative to its base model, though the thread did not provide concrete benchmark names or numeric scores.
Qwen-AgentWorld-35B-A3B: a 3B-active MoE trained to simulate MCP, terminal, SWE, Android, web and OS environments (Activity: 315): Qwen released Qwen-AgentWorld-35B-A3B, a sparse MoE with 35B total parameters and ~3B active parameters/token, positioned as a language world model rather than a chat/instruction agent. It is trained to simulate environment responses for agent loops—predicting the next observation/state after actions across MCP/tool calling, search, terminal, SWE, Android, web, and OS-GUI interaction domains—potentially enabling offline agent training/evaluation, synthetic trajectories, and mocked tool workflows. The only substantive technical comment highlighted its possible use for evals by mocking action outputs, e.g. predicting terminal output for ls -la. Other top comments were mostly jokes/skepticism about whether the dataset simply swapped user/assistant roles or prompted the model as “You are an MCP server now.”
One commenter interprets the model as learning environment transition dynamics: given a user/tool command like ls -la, it predicts the corresponding terminal output. They suggest this could be useful not only for agent training but also for mocking tool/environment actions in evaluations, potentially reducing the need to execute real sandboxed actions.
Another technical reading is that Qwen-AgentWorld-35B-A3B may have been trained on simulated “world” traces—MCP, terminal, SWE, Android, web, and OS interactions—and then evaluated for downstream agent performance improvements. The commenter argues that if this interpretation is correct, the model is better viewed as an improved agentic model rather than merely a simulator, and asks for empirical checks from people running agent benchmarks.
Unlimited-OCR is now on ModelScope! A 3.3B multilingual OCR model for one-shot parsing across single images, multi-page documents, and PDFs. License: MIT (Activity: 1123): Baidu’s Unlimited-OCR is announced on ModelScope as an MIT-licensed 3.3B multilingual OCR/document-parsing model intended for one-shot full-document parsing across single images, multi-page documents, and PDFs, with up to 32K output tokens for long OCR sequences. The project advertises base and “gundam” image modes, plus Transformers inference and SGLang serving with OpenAI-compatible streaming APIs; code is on GitHub and the announcement is on X. Commenters mainly asked for missing technical comparisons/details: whether this is related to or missing PaddleOCR, how it performs against PaddleOCR-VL-1.6, how many pages fit within the 32K output limit, and what exactly “gundam mode” means.
Commenters asked for direct benchmarking against PaddleOCR-VL-1.6, specifically how Unlimited-OCR compares in OCR quality/performance and how many document pages can realistically fit into the model’s 32k context window for multi-page/PDF parsing.
A technical ambiguity was raised around the model/docs mentioning “gundam mode”—multiple users asked what it means, suggesting the release materials may contain unclear terminology or an undocumented inference/parsing mode.
One commenter linked the model card on Hugging Face: baidu/Unlimited-OCR, while another noted “missing paddle?” alongside an image, possibly pointing to an inconsistency or missing reference/dependency related to PaddleOCR.
Ornith-1.0 released on Hugging Face (Activity: 391): DeepReinforce-AI released the Ornith-1.0 Hugging Face collection, including 9B/31B dense and 35B/397B MoE variants, with claimed SOTA results across unspecified benchmarks; commenters characterize them as post-trained Qwen3.5 and Gemma4 models. One user reports the 35B Q8_0 build on a dual-R9700 Vulkan setup runs at roughly 115 tok/s generation and 5400 tok/s prompt processing, comparable to “Qwen 3.6 35B with thinking off,” with occasional transient drops to 95 tok/s. Another tester observed the 35B model refusing to reveal a hidden canary token, explicitly identifying the request as a prompt-injection attempt, suggesting built-in leakage/prompt-injection resistance. Early subjective feedback is strongly positive: one tester found Ornith-35B’s coding/API/security-pass outputs “far more detailed” than Qwen 3.6 35B while being much faster, concluding *“This might be the real deal.”
A user reports the Ornith-1.0 35B Q8_0 quant has essentially identical raw throughput to Qwen 3.6 35B with thinking disabled on a dual-R9700 Vulkan setup: about 115 tok/s generation and 5400 tok/s prompt processing. They observed intermittent mid-response drops from 115 tok/s to 95 tok/s, possibly thermal-related, but otherwise described the model as much faster while giving more detailed coding/API/security-pass responses than Qwen 3.6 35B in informal Ruby/Sinatra tests.
Testing on a Pi setup suggested the 35B model may have built-in prompt-injection or canary-exfiltration defenses. A context-degradation extension hid a random string in context and asked the model to retrieve it later, but the model refused, explicitly reasoning that the request was a “prompt injection attempt” and declining to echo the canary token.
Several commenters frame Ornith-1.0 as post-trained Qwen3.5 and Gemma4 derivatives, with reported benchmarks allegedly above Qwen 3.6 27B. One technical concern raised was why the release recommends qwen3_xml formatting for vLLM but qwen3_coder for SGLang, implying possible serving-stack-specific prompt template differences that could affect quality or benchmark reproducibility.
Read more
関連記事
AI #174:あなた自身こそが重要
Zvi氏の記事では、Fable の復旧見込みやNY-12選挙の結果に加え、GLM-5.2 が新世代の最良オープンモデルとなったと報告しています。ただしコストが高いため、ローカル実行が必要なエージェント用途に限定される可能性があります。
今日は何も大きな出来事はありませんでした
Smol AI News は、6 月 24 日から 25 日にかけての期間に、12 のサブレッドや 544 件の Twitter を調査しましたが、特に注目すべき AI テクノロジー関連のニュースは発生しませんでした。
2026 年にローカルで実行可能なトップ 7 つのコーディングモデル
KDnuggets が選定した、2026 年版のローカル環境で動作する主要な 7 つのコード生成 AI モデルを紹介している。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み