Gemma 4とオープンモデルの成功要因
2026年の飽和したオープンモデル市場において、ベンチマークだけでなくライセンスやツールリング、ファインチューニング容易性など多角的な評価基準を提示し、エージェント時代におけるオープンモデルの真価とビジネス活用への課題を分析している。
キーポイント
オープンモデル市場の飽和と評価難しさ
2026年現在、LlamaやQwenなど多数のオープンモデルが競合しており、単なるリリースではなく、既存モデルとの比較や「ダークマター」的な潜在能力の解明が課題となっている。
エージェント時代におけるモデル単体の評価
ツールやハルネスに依存しない「モデル単体」の能力測定が重要であり、クローズドモデルとは異なる評価軸(エージェントワークフローでの実証など)が必要だと指摘している。
投資判断のための6つの評価指標
パフォーマンス、国産性(プロベナンス)、ライセンス、リリース時のツールリング整備度、ファインチューニング容易性、そしてこれら総合した実用性を投資判断の基準として提示している。
新アーキテクチャにおけるツールリングの不安定性
ハイブリッドモデル(Gated DeltaNetやMamba層など)はリリース当初、ツールリングが未熟で「そのままでは動作しない」ことが多く、エコシステムが安定するまでに数週間を要する場合がある。
特定ユースケースへの適応容易性が開モデルの成功鍵
大規模MoEモデルから小規模モデルまで用途は多様だが、重要なのは「特定のユースケースにどのように適応(ファインチューニング)しやすいか」という実用的な問題である。
ファインチューナビリティに関する体系的な研究の必要性
現在、どのモデルがファインチューニング可能かは業界内の暗黙知に過ぎないため、オープンエコシステムを支えるために、ベースモデルやポストトレーニングモデルの特性理解と事前学習レシピの最適化に関する体系的な研究領域が必要である。
Apache 2.0ライセンスの採用による採用促進
Googleが標準的なApache 2.0オープンソースライセンスを採用したことで、強力でオープンなLLMの採用が大幅に促進されることが期待される。
重要な引用
The potential of open models feels like a dark matter, a potential we know is huge, but few clear recipes and examples for how to unlock it are out there.
When a new Claude Opus or GPT drops, spending a few hours with them in my agentic workflows is genuinely a good vibe test. For open models, putting them through this test is a category error.
The list of factors I’d use to assess a new open-weight model I’m considering investing in includes: Model performance (and size), Country of origin, Model license, Tooling at release, Model fine-tunability.
"The core problem is that some of these are immediately available at release... but others such as tooling take day(s) to week(s) to stabilize, and others are open research questions — with no group systematically monitoring fine-tunability."
"All of this is lead-in for the most important question for open models — how easy is it to adapt to specific use-cases?"
"Gemma 4’s success is going to be entirely determined by ease of use, to a point where a 5-10% swing on benchmarks wouldn’t matter at all."
影響分析・編集コメントを表示
影響分析
本記事は、オープンソースLLM市場が単なる「性能競争」から「実装・運用・法務を含む総合評価」へシフトしつつあることを示唆しており、開発者やエンタープライズユーザーにとってモデル選定のフレームワークを提供する重要な示唆を含んでいる。特にエージェント時代における「ツール非依存のモデル評価」という視点は、今後のオープンモデル開発と採用戦略に大きな影響を与える可能性がある。
編集コメント
オープンモデルの選定基準が「性能」から「エコシステムと運用コスト」へシフトしている現状を明確に示しており、実務的なモデル選定ガイドラインとして有用である。
多くのモデルリリースに関するブログ記事を書いてきた中で、特に 2026 年において、クローズドモデルに対してオープンモデルがリリースされた際のレビューは、非常に難しいものとなっています。ここ数年はオープンモデルが極めて少なかったため、Llama 3 がリリースされた際も、多くの人々はまだ Llama 2 の研究を行っており、アップデートを入手できたことに大変満足していました。Qwen 3 がリリースされた際には、ちょうど Llama 4 の失敗事件があり、Qwen 2.5 における RL(強化学習)の研究を行う新しい研究コミュニティが形成されつつあったため、アップグレードすることは自明の理でした。
今日、オープンモデルがリリースされる際、それは Qwen 3.5、Kimi K2.5、GLM 5、MiniMax M2.5、GPT-OSS、Arcee Large、Nemotron 3、Olmo 3 などと競合しています。この領域は既に多くの存在で満たされていますが、なおも隠された機会に満ちているように感じられます。オープンモデルの潜在能力は暗黒物質のようであり、その規模が巨大であることは確かなのですが、それを解き放つための明確なレシピや事例はまだほとんどありません。エージェント型 AI(Agentic AI)や OpenClaw、そしてこの領域で進行中のあらゆる取り組みは、Claude や Codex といった既存のモデルを代替するのではなく、それらを補完するためにオープンモデルにおける大規模な実験を促すものとなるでしょう。
特にオープンモデルにおいては、リリース時のベンチマークは極めて不完全な物語に過ぎません。ある意味ではこれは興奮を呼びますが、新しいオープンモデルははるかに高い分散性と驚きをもたらす能力を持っていますが、同時に、オープンモデルを中心にビジネスや優れた AI 体験を構築することが、クローズドな代替案よりも困難であるという構造的な理由も示唆しています。新しい Claude Opus や GPT が登場した際、私のエージェントワークフローで数時間それらと向き合うことは、本質的に良い雰囲気テストとなります。しかし、オープンモデルに対してこのテストを行うことは、カテゴリの誤りです。
エージェントの時代におけるオープンモデルについて言えるもう一つの点は、これらが統合(integration)、ハーンセス(harnesses)、およびツールに関する議論から抜け出し、単なるモデル自体が持つ能力が具体的に何であるかを地面に近いレベルで私たちに示してくれることです。もちろん、検索機能のような一部の機能をテストするには何らかのツールが必要ですが、モデル単体の進歩のペースを正確に測定できることは、体系的に不透明な AI 空間に対する歓迎すべき簡略化です。
私が投資を検討している新しいオープンウェイトモデル(open-weight model)を評価するために用いる要因のリストには以下が含まれます:
モデル性能(およびサイズ)— 私が関心を持つベンチマークでのこのモデルのパフォーマンスと、同サイズの他のモデルとの比較。
発行国 — 一部の企業は出自に深くこだわり、そのモデルが中国で構築されたかどうかを気にします。
モデルライセンス — モデルの使用に法的承認が必要な場合、中堅・大企業における採用は遅くなります。
リリース時のツールサポート — 多くのモデルは、アーキテクチャやツールの限界に挑戦する結果として、vLLM、Transformers、SGLANG などの人気ソフトウェアにおいて、不完全な実装、あるいは少なくとも大幅に遅い実装を伴ってリリースされます。
モデルのファインチューニング性 — 実際に使用しようとした際、与えられたモデルを自らのユースケースに合わせて修正することが容易か困難かを指します。
核心的な問題は、これらの要素の一部(例えば一般性能、ライセンス、起源など)はリリース直後に即座に確認可能である一方、ツールサポートのようなものは安定化までに数日から数週間を要し、さらに他の要素は未解決の研究課題であり、ファインチューニング性を体系的に監視する組織が存在しないことです。
オープンモデルの初期時代、Llama 2 や 3、Qwen の v3.5 以前の時期には、アーキテクチャは比較的単純で、モデルは箱から出してすぐに動作することが多かったです。これは一部、Llama、Qwen、Mistral などの開発チームによる極めて困難な努力の結果でした。また、新しいモデルが実際に扱いにくいものであるという事実も一因です。Qwen 3.5 や Nemotron 3 のように、ハイブリッドモデル(ゲート付きデルタネットまたは Mamba レイヤーを含む)の場合、リリース時のツールサポートは非常に荒削りな状態です。「すぐに動作するはず」と期待される機能でも、実際にはそうならないことがよくあります。
私は、同様のアーキテクチャを持つ Olmo Hybrid をリリースして以来、この分野を注視してきました。Qwen 3.5 は、RL(強化学習)研究のためにすべてのオープンソースツールが協調して動作する必要がある場面で、ようやくうまく機能し始めています。これはリリースからわずか 1.5 ヶ月後のことです。これは、モデルの挙動を理解するために本格的に投資を始めるための第一歩です。もちろん、他の企業や研究者は、より多くのエンジニアリングリソースを投入したり、部分的にクローズドなソフトウェアに依存したりすることで、これらのモデルへの取り組みを先行して開始しました。完全にオープンで分散型のエコシステムが、新しいモデル上で動き出すには長い時間がかかります。
これらすべては、オープンモデルにとって最も重要な問いへとつながる導入部分です——それは「特定のユースケースに適応させることがどれほど容易か」という問いです。これはモデルのサイズによって異なる問題となります。大規模な MoE(Mixture of Experts:エキスパート混合)オープンウェイトモデルは、ドメイン内で複雑な機能が必要な Cursor などのエンティティによって利用される可能性があります。例えば、Kimi K2.5 をベースにトレーニングされた Composer 2 がその一例です。一方、他のアプリケーションは、GPT-OSS 20B(Open Source Software:オープンソースソフトウェア)を基盤とした Chroma の Context-1 モデルのように、はるかに小規模なモデル上で構築することも可能です。
「どのモデルがファインチューニング可能か」という問いは、業界のエンジニアたちにとってほぼ既知の背景知識です。この分野には、オープンエコシステムモデルを支えるための活発な研究領域が存在すべきです。最初のステップは、異なるベースモデルやポストトレーニング済みモデルの特徴を理解し、それらがどのような性質を持っているかを把握することです。2 つ目のステップは、オープンモデル向けに事前学習(pretraining)のレシピを調整し、より柔軟性を持たせることです。
Interconnects AI は読者支援型の出版物です。購読をご検討ください。
ATOM プロジェクトやその他の Interconnects の取り組みにおいて、オープンエコシステムにおける採用動向の測定に多大な努力を払ってきました。モデルが初めて公開されてからその展開には長い時間がかかるものであり、その理由は適応性にあります。現在、Qwen がリリースを通じて着実に強固さを増している中で確かなことは、業界全体で技術スタッフが Qwen モデルとの作業に慣れ親しんでいるということです。無数の研究手法やデータセットが Qwen との互換性を確保するために調整されました。他のモデルファミリーがこの段階に至るには忍耐が必要ですが、多くのオープンモデル開発者がその忍耐を持てるかどうかは疑問です。
これが私たちが Gemma 4 に至る背景です。Gemma 4 は Google の最新オープンモデルです。Gemma 3 は 2025 年 3 月、1 年以上前にリリースされましたが、やや過小評価されている傾向があります。現在の Gemma 4 は 4 つのサイズで提供されており、総パラメータ数が 1000 億を超える大規模な MoE モデルも噂されていますが、まだ正式にはリリースされていません。現在利用可能なモデルは、約 5B の密型(dense)、8B の密型、26B 総パラメータで 4B アクティブな MoE、そして 31B の密型のサイズです。
私が最も興奮しているのは、ついに標準的な Apache 2.0 オープンソースライセンスを採用したことです。これにより、採用が劇的に加速するでしょう。強力なオープンウェイト大規模言語モデル(LLM)に対するより良いライセンスの基準は、過去 1〜2 年の間に主に中国のオープンモデルラボによって設定され、現在では米国の企業もそれに追随しています。もし恐ろしい Llama のライセンスや Gemma の利用規約が、業界が強力なオープンモデルをリリースすることに対して神経質になっていた時期(約 18 ヶ月)の一時的な動向に過ぎなかったとしたら、私は個人的にとても喜ぶでしょう。
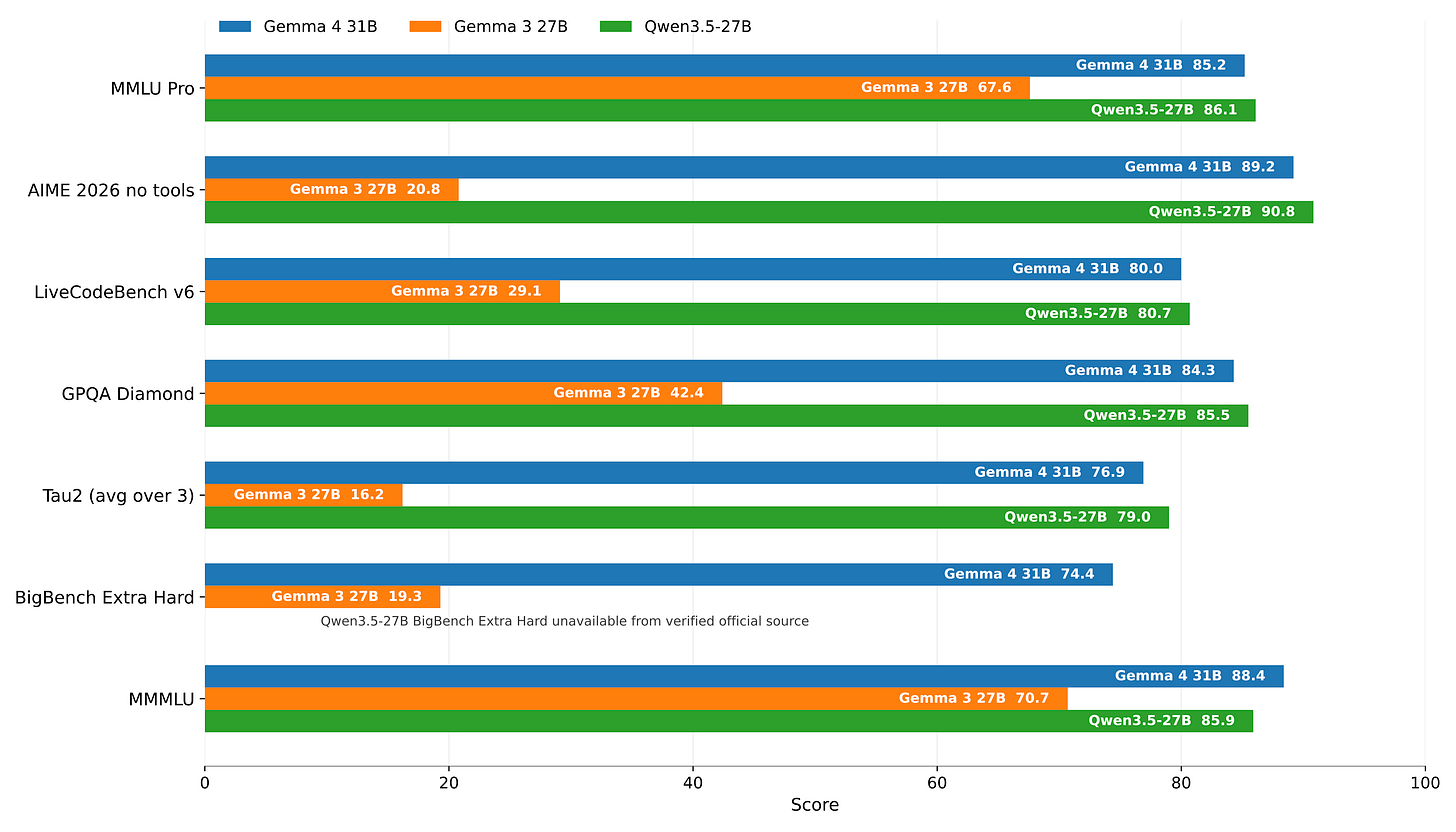
Gemma 4 のスコアは非常に堅牢で、小規模モデルは驚異的なベンチマークスコアを示しています(特に LMArena などの一般ドメインにおいて)。また、31B モデルは直近の Qwen 3.5 27B と互角であり、これはそのクラスにおけるリーダー的存在です。約 30B のサイズ範囲は極めて重要で、研究者だけでなく、実際のユースケースでモデルを展開したい企業にとってもアクセスしやすい規模です。7B モデルスケールが試作や研究のデフォルトであるのに対し、30B モデルはオープンモデルが特定のワークフローにおいて実質的な価値を引き出せるかどうかを確認するためのデフォルトとなります。これは、知能性、低価格、下流トレーニングへの扱いやすさなど、優れたバランスを備えています。
出典:Sebastian Raschka, Ahead of AI
これは、私がオープンモデルに対して前述した採用基準に戻り、より大きな問い——Gemma 4 が圧倒的な成功を収めると思うか——へと繋がります。過去の Gemma モデルは、ツールリングの問題や、ファインチューニング時の性能低下に悩まされてきました。
Gemma 4 の成否は、使いやすさによって完全に決定されます。ベンチマークでの数%〜10%程度の差が全く問題にならないほどです。それは十分に強力であり、小さく、適切なライセンスを持ち、米国由来であるため、多くの企業がこれを採用するでしょう。
私は、Gemma 4 がここでより良く機能することを慎重に楽観視しています。アメリカで構築されたオープンモデルを取り巻く風向きが変わりつつあります。私たちは GPT-OSS が荒れた立ち上げを経て圧倒的な成功を収めた様子を目撃しました。Reflection, Arcee, Nemotron, Gemma, Olmo といった名前やその仲間たちを取り巻く集合的なエネルギーは、オープンモデルを中心に新たなスタックを構築する需要が実証されていることを示しています。モデルを含むすべてのものに対する所有権をより多く望む人々によって、経済全体に AI スタックへの投資資金が投入されるでしょう。
ATOM プロジェクトを立ち上げてから 240 日が経過し、議論は次の段階へと移行しています。2025 年の夏は危機的瞬間であり、米国の AI シーンは AGI を構築した後にオープンモデルについて考え始める余裕はないと認識しました。この二つの市場は異なる領域を捉え、並行して進展していきます。現在、米国ではより多くの企業が強力なモデルを公開しているため、これらのモデルが使いやすく、理解しやすく、価値創造の基盤となりやすいようエコシステムを改善する必要があります。私が一貫して更新してきた採用曲線において新たな転換点を築くことは困難な作業ですが、まさにそれが取り組むべき課題です。ぜひ一緒に取り組みましょう。
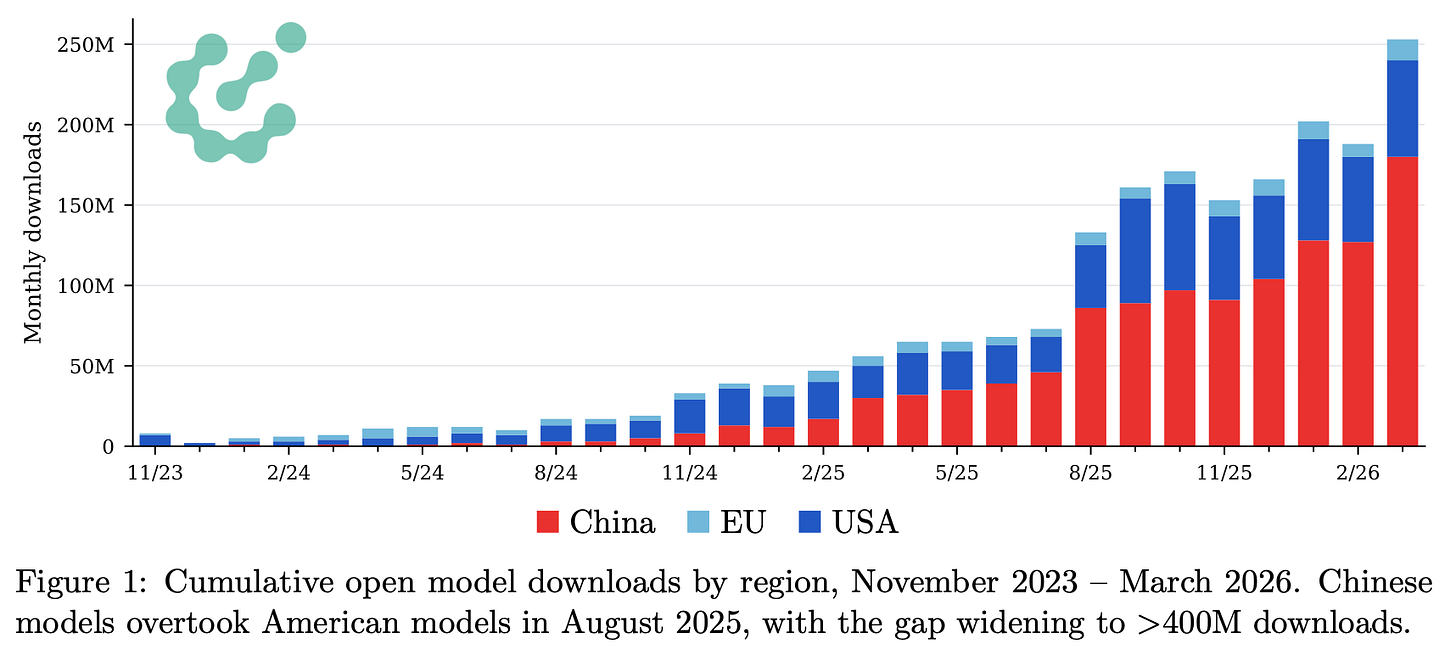
詳細データは近日公開予定です!まずは一部をチラ見せします:
原文を表示
Having written a lot of model release blog posts, there’s something much harder about reviewing open models when they drop relative to closed models, especially in 2026. In recent years, there were so few open models, so when Llama 3 was released most people were still doing research on Llama 2 and super happy to get an update. When Qwen 3 was released, the Llama 4 fiasco had just gone down, and a whole research community was emerging to study RL on Qwen 2.5 — it was a no brainer to upgrade.
Today, when an open model releases, it’s competing with Qwen 3.5, Kimi K2.5, GLM 5, MiniMax M2.5, GPT-OSS, Arcee Large, Nemotron 3, Olmo 3, and others. The space is populated, but still feels full of hidden opportunity. The potential of open models feels like a dark matter, a potential we know is huge, but few clear recipes and examples for how to unlock it are out there. Agentic AI, OpenClaw, and everything brewing in that space is going to spur mass experimentation in open models to complement the likes of Claude and Codex, not replace them.
Especially with open models, the benchmarks at release are an extremely incomplete story. In some ways this is exciting, as new open models have a much higher variance and ability to surprise, but it also points at some structural reasons that make building businesses and great AI experiences around open models harder than the closed alternatives. When a new Claude Opus or GPT drops, spending a few hours with them in my agentic workflows is genuinely a good vibe test. For open models, putting them through this test is a category error.
Something else to be said about open models in the era of agents is that they get out of the debate of integration, harnesses, and tools and let us see close to the ground on what exactly is the ability of just a model. Of course, we can’t test some things like search abilities without some tool, but being able to measure exactly the pace of progress of the model alone is a welcome simplification to a systematically opaque AI space.
Share
The list of factors I’d use to assess a new open-weight model I’m considering investing in includes:
Model performance (and size) — how this model performs on benchmarks I care about and how it compares to other models of a similar size.
Country of origin — some businesses care deeply about provenance, and if a model was built in China or not.
Model license — if a model needs legal approval for use, uptake will be slower at mid-sized and large companies.
Tooling at release — many models release with half-broken, or at least substantially slower, implementations in popular software like vLLM, Transformers, SGLANG, etc due to pushing the envelope of architectures or tools.
Model fine-tunability — how easy or hard it is to modify the given model to your use-case when you actually try and use it.
The core problem is that some of these are immediately available at release, e.g. general performance, license, origin, etc. but others such as tooling take day(s) to week(s) to stabilize, and others are open research questions — with no group systematically monitoring fine-tunability.
In the early era of open models, the days of Llama 2 or 3 and Qwen pre v3.5, the architectures were fairly simple and the models tended to work out of the box. Some of this was due to the extremely hard work of the Llama, Qwen, Mistral, etc. developer teams. Some is due to the new models being genuinely harder to work with. When it comes to something like Qwen 3.5 or Nemotron 3, with hybrid models (either gated delta net or mamba layers), the tooling is very rough at release. Things you would expect to “just work” often don’t.
I’ve been following this area closely since we released Olmo Hybrid with a similar architecture, and Qwen 3.5 is just starting to work well in the various open-source tools that need to all play nice together for RL research. That’s 1.5 months after the release date! This is just to start really investing more into understanding the behavior of the models. Of course, others started working on these models sooner by investing more engineering resources or relying on partially closed software. The fully open and distributed ecosystem takes a long time to get going on some new models.
All of this is lead-in for the most important question for open models — how easy is it to adapt to specific use-cases? This is a different problem for different model sizes. Large MoE open-weight models may be used by entities like Cursor who need complex capabilities in their domain, e.g. Composer 2 trained on Kimi K2.5. Other applications can be built on much smaller models, such as Chroma’s Context-1 model for agentic search, built on GPT-OSS 20B.
The question of “which models are fine-tunable” is largely background knowledge known by engineers across the industry. There should be a thriving research area here to support the open ecosystem model. The first step is to understand characteristics of different base and post-trained models to understand what they look like. The second step is to tune pretraining recipes for open models so they’re more flexible.
Interconnects AI is a reader-supported publication. Consider becoming a subscriber.
For The ATOM Project and other Interconnects endeavors, we’ve put in substantial effort to measuring adoption trends in the open ecosystem. Everything takes a long time to unfold after a model is first publicly available — and adaptability is why. What we know for sure now, when Qwen has been going from strength to strength with its releases, is that technical staff across the industry has gotten comfortable working with Qwen models. Countless research methods and datasets were made to work with Qwen. It’ll take patience for any other model family to get to this point — a patience I’m not sure many open model builders have.
This takes us to Gemma 4, Google’s latest open models. Gemma 3 was released more than a year ago, in March of 2025, and is a bit underrated. Gemma 4 comes in 4 sizes for now, with a bigger, MoE model of over 100B total parameters rumored but not released yet. The models we have today come in sizes of ~5B dense, 8B dense, 26B total 4B active MoE, and 31B dense.
I’m most excited that they’re finally adopting a standard Apache 2.0 open source license. This’ll massively boost adoption. The standard of better licenses for strong open-weight LLMs was set by mostly Chinese open model labs in the last 1-2 years, and now U.S. companies are following suit. I will personally be so happy if the horrible Llama licenses and Gemma terms of service were an ~18-month transient dynamic of the industry being nervous about releasing strong open models.
The Gemma 4 scores look very solid, the small models have incredible benchmark scores (especially in general domains like LMArena) and the 31B model rivals the recent Qwen 3.5 27B, which is the leading member of that class. The ~30B size range is an important one, as it’s accessible both to researchers and to enterprises looking to deploy the model in real use-cases. Where the 7B model scale is the default for tinkering and research, a 30B model is the default for seeing if an open model can unlock substantial value in your specific workflow — a good mix of intelligence, low price, tractability for downstream training, etc.
Source: Sebastian Raschka, Ahead of AI
This takes us back to the above adoption criteria I mentioned for open models and the bigger question — do I think Gemma 4 will be an overwhelming success? Previous Gemma models have been plagued by tooling issues and poorer performance when being finetuned.
Gemma 4’s success is going to be entirely determined by ease of use, to a point where a 5-10% swing on benchmarks wouldn’t matter at all. It’s strong enough, small enough, with the right license, and from the U.S., so many companies are going to slot it in.
I’m cautiously optimistic that Gemma 4 is going to work better here. Winds are shifting for open models built in America. We saw GPT-OSS go through a bumpy launch to become an overwhelming success. There’s a collective energy around the likes of Reflection, Arcee, Nemotron, Gemma, Olmo, and peers that show substantial demand for building new stacks around open models. There’s capital to be spent on AI stacks across the economy by those who want more ownership of everything, including the model.
After launching The ATOM Project 240 days ago, the conversation is shifting into the next stage. Summer of 2025 was a crisis moment where the U.S. AI scene realized it can’t wait and figure out open models after building AGI. The two markets will capture different areas and proceed in parallel. Now that more companies in the U.S. are releasing strong models, we need to improve the ecosystem so that these models are easy to use, understand, and build value around. It’s the hard work to build another inflection point in these adoption plots I’ve been updating consistently, but that’s the work to be done. Join me in it.
More data coming soon! Here’s a sneak peek:
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み