LLM 研究論文:2026 年 1 月から 5 月のリスト
Sebastian Raschka が選定した 2026 年上半期の LLM 研究論文リストは、推論モデルや効率的な学習手法の進展を反映しており、実務家にとって重要な参照資料となる。
キーポイント
2026 年半期 research paper の選定基準と構成
著者が個人的に注目した論文を厳選し、アーキテクチャ、推論効率、エージェントシステムなど 10 のカテゴリに分類して整理している。
2026 年の主要な技術トレンド:ハイブリッドと状態空間
Transformer の単純な大規模化を超え、Nemotron 3 や Arcee Trinity に代表されるハイブリッドアーキテクチャや、Mamba-3 などの状態空間層への注目が高まっている。
推論・学習効率とエージェント機能の強化
テスト時計算(Reasoning)や RLVR(Reinforcement Learning from Verifiable Rewards)、そしてツール使用を伴うエージェントシステムの論文が特に重視されている。
実用インフラと評価基準の多様化
Diffusion Language Models や長文コンテキスト処理、さらにはモデル評価ベンチマークやサービングインフラに関する実践的な研究もリストに含まれている。
ハイブリッドアーキテクチャの主流化
Nemotron 3 Super や Qwen3.6 は、長文コンテキスト処理効率のためにアテンション層とMamba-2/Gated DeltaNetなどの状態空間モデル層を交互に組み合わせた設計を採用している。
Nemotron 3 シリーズの多様なサイズ展開
120B-A12B の大規模モデルに加え、ローカル推論向けの4B版「Nano」や、550B-A55Bの超大規模版「Ultra」も発表され、用途に応じた選択肢が広がっている。
次世代状態空間モデルへの期待
Mamba-3 や Gated DeltaNet-2 のような新バージョンが登場しており、今後のオープンウェイトLLM(Nemotron-4やQwen4など)での採用が注目されている。
重要な引用
This year, the list is again heavy on reasoning models, reinforcement learning, and efficient inference
There is a lot of work around hybrid architectures (for example, Nemotron 3, and Arcee Trinity), state space layers (Nemotron 3 and Mamba-3)
Even in the era of LLM-based web searching, having a specific context list is pretty useful
In 2026, long-context efficiency is king as more and more LLMs get plugged into agent harnesses (OpenClaw etc.), which requires working with longer and longer contexts.
One of the interesting aspects of Nemotron 3 is its hybrid-architecture design, meaning that it alternates between regular attention layers and Mamba-2 (state space model) layers to be more efficient at long contexts.
"Scaling Embeddings Outperforms Scaling Experts in Language Models"
影響分析・編集コメントを表示
影響分析
このリストは、2026 年半期の LLM 研究動向を要約しており、特にアーキテクチャの多様化と推論効率化の潮流を示している。研究者やエンジニアにとって、最新の技術トレンドを把握し、自らのプロジェクトに適用可能な知見を得るための重要な羅針盤となる。
編集コメント
2026 年の研究動向を先取りする貴重なリストであり、特にアーキテクチャの多様化と推論効率化の潮流を理解するのに役立ちます。
LLM 研究論文:2026 年リスト(1 月から 5 月)
ご存知の方も多いかと思いますが、私は長年にわたり、今後記事やプロジェクトで読み返したり引用したりしたい研究論文のリストを継続的に作成する習慣を持っています。
昨年は、1 月から 6 月をカバーするリストと、7 月から 12 月をカバーするリストという、整理された 2 つの論文リストを共有しました。
いくつかの読者から、これらのリストが非常に有用だとお声をいただきましたので、同様の精神で、2026 年後半分の新しいリストを作成しました。このリストには、2026 年 1 月から 5 月にかけてブックマークした論文が含まれています。
これは今年出版されたすべてのものを網羅する完全なリストとして扱わないでください。毎日多くの論文が出版されているため、それをすべて行うことは全く現実的ではありません。むしろ、これは私の自身の仕事にとって興味深く関連性のある論文に基づいて選別・編集された参照リストです。リストを整理する際に、タイトル、アブストラクト(抄録)、トピックの枠組みを注意深く確認しましたが、詳細に読んだのはその一部であることも認めざるを得ません。
そもそもなぜこれらのリストを作成するのかというと、記事や書籍の一部、コード例、講義に取り組む際によく、「どこかで関連する論文を見たはずだ」と思い出すのですが、それを再度見つけるのが意外にも面倒なことがあるからです。カテゴリ分けされた Markdown リストは、私にとってその問題を解決してくれるものであり、皆様にとっても有用であることを願っています。(LLM によるウェブ検索が主流となった時代であっても、特定の文脈を持つリストを持っていることは依然として非常に役立ちます。)
今年も、推論モデル、強化学習、効率的な推論に関する論文に重点を置いています。これは私が現在取り組んでいる分野に関連する論文をブックマークすることに偏っているためです。しかし、2025 年のリストと比較すると、エージェント・ハネス、ツール利用、長文コンテキスト、拡散言語モデル、実用的なサービングインフラストラクチャに関する論文もより多くブックマークしました。これは私が現在深く関与している分野であり、かつこの分野が向かっている方向だからです。
今回の研究論文リストのカテゴリーは以下の通りです。(プロのヒント:この記事のウェブ版では、左側の目次を使用して、あなたにとって最も関連性の高いセクションに直接ジャンプできます。)
アーキテクチャとモデル設計
効率的なトレーニングとスケーリング
推論効率と KV キャッシュ
スパースアテンションと長文コンテキスト
推論とテスト時計算量
強化学習と RLVR
エージェントシステムとツール利用
コーディングエージェントとソフトウェアエンジニアリング
拡散言語モデル
モデル評価とベンチマーク
- アーキテクチャとモデル設計
この最初のセクションでは、モデルアーキテクチャ、モデルリリースの技術報告書、および現在の LLM がなぜそのような姿をしているのかを説明する助けとなる論文を集めています。
2026 年到目前为止私が興味深く思っていることは、アーキテクチャに関する研究がトランスフォーマーを単に大きくするだけにとどまらないことです。以下を中心とした多くの研究があります:
ハイブリッドアーキテクチャ(例えば Nemotron 3 および Arcee Trinity)、
状態空間層(Nemotron 3 および Mamba-3)、
MoE の容量割当(スケーリング埋め込みがスケーリング専門家を上回る、およびステップ 3.5 Flash)、
活性化の挙動(スパイク、スパース、シンク)、
そして表現幾何学(言語統計における対称性がモデル表現の幾何学を形成する)。
これらすべての論文は非常に興味深く、だからこそ最初にブックマークしたのです。しかし、一つだけ必ず読むべきものを選ぶなら、おそらく「Nemotron 3 Super」でしょう。記事が極めて詳細であり(あえて冗談を言っているわけではありません)、すでに本番環境で稼働しているモデルで使用されている技術を記述しているからです。何より、そのサイズクラスでは最高クラスのモデルの一つだからです。
Nemotron 3 の興味深い側面の一つは、ハイブリッドアーキテクチャ設計です。これは、長文コンテキストにおいてより効率的に動作するために、通常のアテンション層と Mamba-2(状態空間モデル)層を交互に使用します。2026 年においては、長文コンテキストの効率が最重要であり、LLM がエージェントハネス(OpenClaw など)にますます組み込まれることで、より長いコンテキストを扱う必要性が高まっています。
とはいえ、120B-A12B は一般的な消費者向けハードウェアでのローカル推論にはやや大きすぎるかもしれません。しかし、Nemotron 3 Nano(4B)版も存在します。
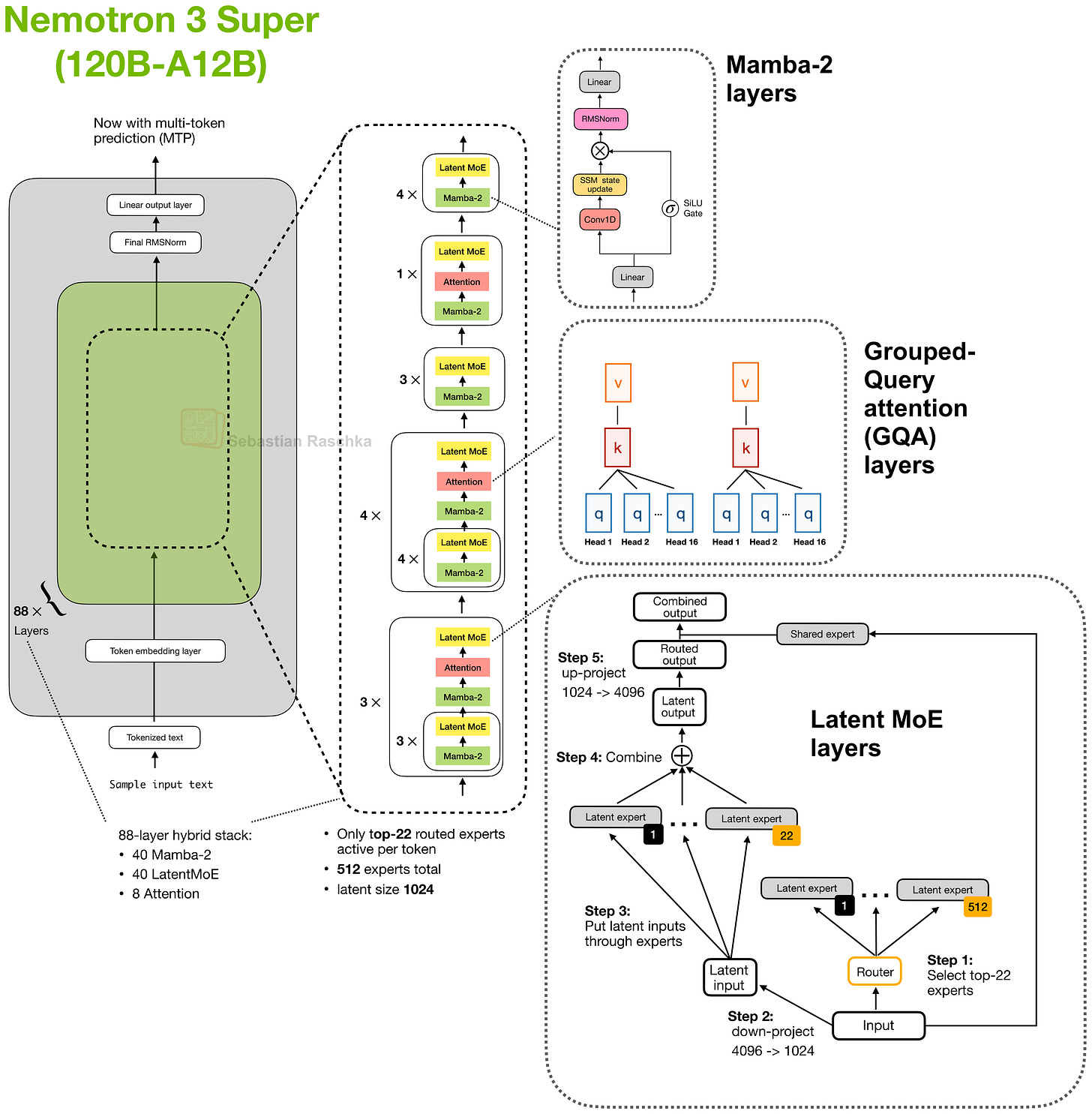
図 1: Mamba-2 層を使用したハイブリッドアーキテクチャである Nemotron-3 Super のアーキテクチャ。
なお、2 日前に Nvidia も本稿のスケールアップ版である Nemotron 3 Ultra (550B-A55B) をリリースしました。これは埋め込み次元と射影次元を拡張したものであり、それ以外の構成要素は同じビルディングブロックを使用しています。視覚的な概要に興味がある場合は、Substack Notes でこちらに投稿しました。
注意機構と代替層を交互に配置するこのハイブリッドアーキテクチャのトレンドは、今年比較的注目されている開発です。同様のハイブリッド設計を採用しているおそらく最も人気のあるオープンウェイト大規模言語モデル (LLM) シリーズは Qwen3.6 であり、これは非注意機構部分に Mamba-2 層ではなく Gated DeltaNet 層を使用しています。詳細については、これらのトピックについて以前書いた複数の Substack アーティクルの情報を統合した私の「Hybrid Attention」(https://sebastianraschka.com/llm-architecture-gallery/hybrid-attention/) の記事をご覧ください。
また、以下の論文リストをご覧いただくと、Mamba-3 や Gated DeltaNet-2 (つまり Mamba-2 および GatedDeltaNet のより新しいバージョン) が掲載されていることに気づかれるかもしれません。今後のオープンウェイト LLM(例えば Nemotron-4 や Qwen4?) でこれらの新技術がどのように活用されるか注目されます。
ハイブリッドアーキテクチャの設計について記述するほか、Nemotron-3 論文には推測的デコーディングにおけるマルチトークン予測、NVFP4 プリトレーニング対 BF16、合成 MMLU スタイルデータ、ポストトレーニング量子化レシピなどに関する多くの興味深いアブレーション研究も含まれていますが、これらを詳細に解説することは本概観の範囲外となります。
1 月 1 日、Deep Delta Learning、https://arxiv.org/abs/2601.00417
1 月 6 日、MiMo-V2-Flash Technical Report、https://arxiv.org/abs/2601.02780
1 月 13 日、Ministral 3、https://arxiv.org/abs/2601.08584
1 月 29 日、言語モデルにおけるスケーリング埋め込みはスケーリング専門家を上回る(Scaling Embeddings Outperforms Scaling Experts in Language Models)、https://arxiv.org/abs/2601.21204
1 月 30 日、LatentLens: LLM 内の高度に解釈可能な視覚トークンの解明(Revealing Highly Interpretable Visual Tokens in LLMs)、https://arxiv.org/abs/2602.00462
2 月 4 日、ERNIE 5.0 Technical Report、https://arxiv.org/abs/2602.04705
2 月 8 日、ViT-5: 2020 年代半ばのためのビジョントランスフォーマー(Vision Transformers for the Mid-2020s)、https://arxiv.org/abs/2602.08071(本記事の大部分は LLM に焦点を当てていますが、新しい主要なビジョントランスフォーマー設計を紹介せずにはいられませんでした。)
2 月 11 日、Step 3.5 Flash: 11B のアクティブパラメータでオープンフロンティアレベルの知能を実現(Open Frontier-Level Intelligence with 11B Active Parameters)、https://arxiv.org/abs/2602.10604
2 月 12 日、Nanbeige4.1-3B: 推論し、アライメントし、行動する小型汎用モデル(A Small General Model That Reasons, Aligns, and Acts)、https://arxiv.org/abs/2602.13367
2 月 16 日、言語統計における対称性がモデル表現の幾何学を形成する(Symmetry in Language Statistics Shapes the Geometry of Model Representations)、https://arxiv.org/abs/2602.15029
2 月 17 日、GLM-5: バイブコーディングからアジェンティックエンジニアリングへ(From Vibe Coding to Agentic Engineering)、https://arxiv.org/abs/2602.15763
2 月 18 日、Arcee Trinity Large Technical Report、https://www.arxiv.org/abs/2602.17004
3 月 4 日、スパイク、スパーシィ、そしてシンク:大規模活性化とアテンションシンクの解剖(The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks)、https://arxiv.org/abs/2603.05498
3 月 12 日、Tiny Aya: スケールと言語的多様性の深さを橋渡しする(Bridging Scale and Multilingual Depth)、https://arxiv.org/abs/2603.11510
3 月 15 日、アテンション残差(Attention Residuals)、https://arxiv.org/abs/2603.15031
3 月 16 日,Mamba-3:状態空間原理を用いた改善されたシーケンスモデリング,https://arxiv.org/abs/2603.15569
3 月 31 日,Attention to Mamba:クロスアーキテクチャ蒸留のためのレシピ,https://arxiv.org/abs/2604.14191
4 月 13 日,Nemotron 3 Super:エージェント推論用のオープンで効率的な混合専門家ハイブリッド Mamba-Transformer モデル,https://arxiv.org/abs/2604.12374
5 月 6 日,ZAYA1-8B 技術報告書,https://arxiv.org/abs/2605.05365
5 月 13 日,デルタアテンション残差(Delta Attention Residuals),https://arxiv.org/abs/2605.18855
5 月 21 日,Gated DeltaNet-2:線形アテンションにおける消去と書き込みの分離,https://arxiv.org/abs/2605.22791
5 月 25 日,MiniMax-M2 シリーズ:ミニマム活性化が最大の実世界知能を解き放つ,https://arxiv.org/abs/2605.26494
- 効率的なトレーニングとスケーリング
このセクションは、トレーニングシステム、適応手法、およびスケーリングレシピに関するものです。これらの論文はすべて(必ずしも)ゼロからの事前学習についてではありません。一部はファインチューニング、蒸留、テスト時トレーニングに焦点を当てており、あるいは制約のあるハードウェア上でトレーニングをより効果的に行う方法について扱っています。
続きを読む
原文を表示
LLM Research Papers: The 2026 List (January to May)
As some of you know, I have the long-running habit of keeping a running list of research papers I want to read, revisit, or cite in future articles and projects.
Last year, I shared two organized paper lists, one covering January to June and another one covering July to December.
Several readers told me that these lists were very useful, so, in a similar spirit, I prepared a new list for the first half of 2026. This one covers papers I bookmarked from January through May 2026.
Please do not treat this as a complete list of everything published this year. There are so many papers published every day that this would be totally infeasible. Instead, this is a curated reference list based on papers I found interesting or relevant for my own work. I went through the titles, abstracts, and topic framing carefully while organizing the list, but I have to admit that I also only read a subset of the papers in detail.
Why make these lists in the first place? When I work on an article, book section, code example, or lecture, I often remember that I saw a relevant paper somewhere, but finding it again can be surprisingly annoying. A categorized Markdown list solves that problem for me, and I hope it is useful to you as well. (Even in the era of LLM-based web searching, having a specific context list is pretty useful, still.)
This year, the list is again heavy on reasoning models, reinforcement learning, and efficient inference, because I am biased towards bookmarking papers that are related to things I am currently working on. However, compared with the 2025 lists, I also bookmarked more papers around agent harnesses, tool use, long context, diffusion language models, and practical serving infrastructure, because that’s what I am currently pretty involved in and where the field is headed.
The categories for this research paper list are as follows. (Pro tip: In the web version of this article, you can use the table of contents on the left to jump directly to the sections that are most relevant to you.)
Architecture and Model Design
Efficient Training and Scaling
Inference Efficiency and KV Cache
Sparse Attention and Long Context
Reasoning and Test-Time Compute
Reinforcement Learning and RLVR
Agent Systems and Tool Use
Coding Agents and Software Engineering
Diffusion Language Models
Model Evaluation and Benchmarks
- Architecture and Model Design
This first section collects papers on model architecture, model-release technical reports, and papers that help explain why current LLMs look the way they do.
One thing I find interesting about 2026 so far is that architecture work goes beyond making transformers larger. There is a lot of work around
hybrid architectures (for example, Nemotron 3, and Arcee Trinity),
state space layers (Nemotron 3 and Mamba-3),
MoE capacity allocation (Scaling Embeddings Outperforms Scaling Experts, and Step 3.5 Flash),
activation behavior (The Spike, the Sparse and the Sink),
and representation geometry (Symmetry in Language Statistics Shapes the Geometry of Model Representations).
All of these papers are quite interesting, which is why I bookmarked them in the first place. But if I had to pick one must-read, I’d probably be Nemotron 3 Super, because the article is super detailed (no pun intended), and it describes techniques used in a model that is already in production. And it’s one of the best models in its size class after all.
One of the interesting aspects of Nemotron 3 is its hybrid-architecture design, meaning that it alternates between regular attention layers and Mamba-2 (state space model) layers to be more efficient at long contexts. In 2026, long-context efficiency is king as more and more LLMs get plugged into agent harnesses (OpenClaw etc.), which requires working with longer and longer contexts.
That being said, 120B-A12B may be a bit too large for local inference on regular consumer hardware, but there is a Nemotron 3 Nano (4B) version as well.
Figure 1: Architecture of Nemotron-3 Super, which is a hybrid architecture using Mamba-2 layers.
Note that 2 days ago, Nvidia also released a scaled up-version of this, Nemotron 3 Ultra (550B-A55B), which scales the embedding and projection dimensions but otherwise uses the same building blocks. If you are interested in a visual, I posted about it on Substack Notes here.
This hybrid-architecture trend with alternating attention and alternative layers is a relatively popular development this year. The probably most popular open-weight LLM series that uses a similar hybrid design is probably Qwen3.6, which uses Gated DeltaNet layers instead of Mamba-2 layers for the non-attention portions. For more information, see my Hybrid Attention (https://sebastianraschka.com/llm-architecture-gallery/hybrid-attention/) write-up, which pools information from several of my previous substack articles where I wrote about these.
Also, in the paper list below, you may notice that there is now a Mamba-3 and Gated DeltaNet-2 (i.e., newer versions of Mamba-2 and GatedDeltaNet), and it will be interesting to see those in the upcoming open-weight LLMs (e.g., Nemotron-4 and Qwen4?).
Next to describing the hybrid-architecture design, the Nemotron-3 paper contains a whole lot of other interesting ablations, for example, around multi-token prediction for speculative decoding, NVFP4 pretraining versus BF16, synthetic MMLU-style data, and post-training quantization recipes, but covering these in detail would be out of scope for this overview.
1 Jan, Deep Delta Learning, https://arxiv.org/abs/2601.00417
6 Jan, MiMo-V2-Flash Technical Report, https://arxiv.org/abs/2601.02780
13 Jan, Ministral 3, https://arxiv.org/abs/2601.08584
29 Jan, Scaling Embeddings Outperforms Scaling Experts in Language Models, https://arxiv.org/abs/2601.21204
30 Jan, LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs, https://arxiv.org/abs/2602.00462
4 Feb, ERNIE 5.0 Technical Report, https://arxiv.org/abs/2602.04705
8 Feb, ViT-5: Vision Transformers for the Mid-2020s, https://arxiv.org/abs/2602.08071 (Most of this article is LLM-focused, but I couldn’t resist to include a new major vision transformer design.)
11 Feb, Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, https://arxiv.org/abs/2602.10604
12 Feb, Nanbeige4.1-3B: A Small General Model That Reasons, Aligns, and Acts, https://arxiv.org/abs/2602.13367
16 Feb, Symmetry in Language Statistics Shapes the Geometry of Model Representations, https://arxiv.org/abs/2602.15029
17 Feb, GLM-5: From Vibe Coding to Agentic Engineering, https://arxiv.org/abs/2602.15763
18 Feb, Arcee Trinity Large Technical Report, https://www.arxiv.org/abs/2602.17004
4 Mar, The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks, https://arxiv.org/abs/2603.05498
12 Mar, Tiny Aya: Bridging Scale and Multilingual Depth, https://arxiv.org/abs/2603.11510
15 Mar, Attention Residuals, https://arxiv.org/abs/2603.15031
16 Mar, Mamba-3: Improved Sequence Modeling Using State Space Principles, https://arxiv.org/abs/2603.15569
31 Mar, Attention to Mamba: A Recipe for Cross-Architecture Distillation, https://arxiv.org/abs/2604.14191
13 Apr, Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning, https://arxiv.org/abs/2604.12374
6 May, ZAYA1-8B Technical Report, https://arxiv.org/abs/2605.05365
13 May, Delta Attention Residuals, https://arxiv.org/abs/2605.18855
21 May, Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention, https://arxiv.org/abs/2605.22791
25 May, The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence, https://arxiv.org/abs/2605.26494
- Efficient Training and Scaling
This section is about training systems, adaptation methods, and scaling recipes. These papers are not (all) about pre-training from scratch. Some focus on fine-tuning, distillation, test-time training, or making training work better on constrained hardware.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み