OpenAI Codex製品責任者:コードは人間が書かなくなるが、より多くの構築者が生まれる
OpenAI Codex責任者がAIコーディングの現状を語る。社内ではIDEを使わずCodex利用が20倍増。真の課題はモデルではなく人間の適応。オープン標準やエージェント市場の未来も議論。
キーポイント
OpenAI内部ではAIによるコード生成が主流となり、IDEを開かなくなる工程師が増えている
AIの普及における最大のボトルネックはモデル性能ではなく、人間のタイピング速度とプロンプト設計などの人機交互にある
全てのエージェントは本質的にコーディングエージェントであり、コードはエージェントがコンピュータを操作する最適な手段である
AIによる自動化はソフトウェアエンジニアの需要を減らすのではなく、より多くの「ビルダー」を生み出すと予測
OpenAIは「Codexの成功」ではなく「知能の配布」を使命とし、競合他社にもモデルを提供する戦略を取っている
影響分析・編集コメントを表示
影響分析
この記事は、AIによるコード生成が既にOpenAI内部で主流となっている現状と、人間の作業プロセスがAI普及のボトルネックであるという洞察を示している。エージェント技術の本質をコード操作と定義し、ソフトウェア開発の未来像として「ビルダー」の増加を予測するなど、業界の方向性に影響を与える重要な視点を提供している。
編集コメント
OpenAIの製品責任者による内部視点は貴重で、AIが既に開発現場でどのように活用されているか、そしてその普及の障壁が技術ではなく人間側にあるという逆説的な洞察が印象的だ。
すべての投稿を見る
2026年2月22日公開
OpenAI Codex 製品責任者:コードはもはや人間によって書かれるものではないが、私たちはより多くのビルダー(Builder)を持つことになる
Alexander Embiricos は OpenAI Codex の製品責任者である。OpenAI 入社前は Dropbox でプロダクトマネージャーを務め、その後協働ツール「Multi」(旧称 Remotion)を創業し、ペアプログラミング分野で5年間起業家として活動した。2024年に OpenAI に買収された彼は、AI プログラミングツールが「補助的な補完」から「全権委任」へと変化する過程を目撃してきた。Codex は 2025年8月以来20倍に成長し、2026年2月の1週間に macOS 独立アプリ、GPT-5.3 モデル、スーパーボウル広告を相次いで発表するとともに、無料ユーザーへの提供も開始した。
今回のインタビューでは、AI コーディングの現状とエンジニアの未来、なぜ人間が AGI(汎用人工知能)における真のボトルネックなのか、OpenAI 内部での Codex の活用方法、オープンスタンダードと競争戦略、そして SaaS 業界とエージェント市場の終着点といった核心的なトピックをカバーしている。
出典:20VC with Harry Stebbings、2026年2月21日
オリジナル動画:https://www.youtube.com/watch?v=S1rQngjpUdI

OpenAI 内部の多くの人々はもはや IDE(統合開発環境)を開かず、コードの大部分は AI によって書かれている。その転換点は GPT-5.2 Codex で訪れた。
AI は毎日人間を数万次支援すべきだが、現状では重度ユーザーでも数十回しか利用していない。ボトルネックはモデル自体ではなく、人間と機械のインタラクションにある。
「すべてのエージェント(Agent)は本質的にコーディングエージェントである」。なぜなら、コードこそがエージェントがコンピュータを操作するための最良の方法だからだ。
OpenAI は自社の役割を「Codex の成功」ではなく「知能の配布」と捉えている。モデルを訓練し、競合他社にも提供することだ。
汎用型エージェントは垂直特化型エージェントに勝り、将来的には少数のエージェントプロバイダーが大部分の価値を独占する可能性がある。
【1】コーディングは消滅しないが、その意味は変化する
イーロン・マスクは、コーディングが最初に大規模自動化される職業の一つだと述べている。最前線にいるあなたはこの見解に同意するか?
Embiricos は LLM(大規模言語モデル)がコーディング分野で確かに強力であることは認めるが、「自動化」という言葉は重すぎるという。彼はいくつかの歴史的な例を挙げた。私たちがアセンブリ言語から高級言語へ移行した際、誰も「コーディングが自動化された」とは言わなかった。むしろ、より多くのコードを書けるようになった結果、コードに対する需要が爆発的に増大し、ソフトウェアエンジニアの必要性が高まったのだ。
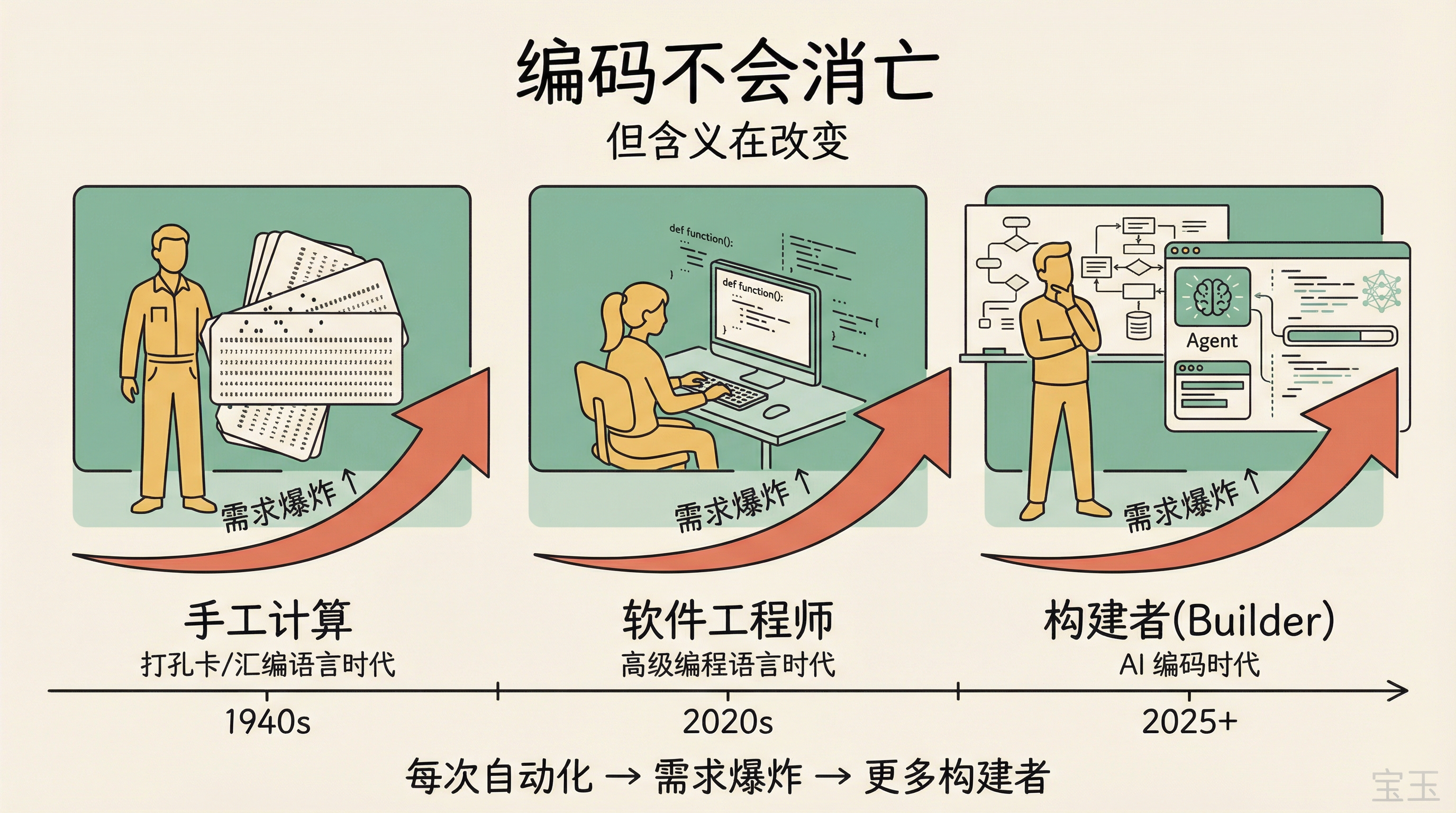
彼はまた「コンピューター(computer)」という言葉の起源にも言及した。ブレッチリー・パーク(第二次世界大戦中の英国暗号解読センター)では、多数の人々がパンチカードの作成や集計計算を担当していた。最初の電子表計算ソフトも同様のシナリオから生まれた:オフィスで机がグリッド状に並び、各人が一部を計算し、ワークシートを次の人に渡すという作業だった。これらの具体的なタスクはすべて自動化されたが、そのたびに産出物に対する需要が爆発的に増加した。
【注:Embiricos による「computer」の語源に関する記述は完全には正確ではない。「computer」という呼称はブレッチリー・パーク以前に人間職として存在しており、17世紀まで遡る。後に NASA の女性数学者計算員も computers と呼ばれた。】
「今日でもまだソフトウェアエンジニアは必要です。デザイナーも必要です。私は PM ですが、PM は必要だと思いますか?私は不要だと思います。」
五年後にはエンジニアが増えるのか減るのか?エンビロコスはより多くの“ビルダー”がいると語る一方で、一つの傾向を指摘しています。それは人材のスタックが圧縮されているという点です。数年前まではフロントエンドとバックエンドは別々の職種でしたが、現在では少なくとも Codex チーム内において、エンジニアはますますフルスタック化しています。
PM に関するこの自嘲的な見解について、彼は PM の役割の本質を「明示的に未定義のもの」と説明します。その目的はチームやビジネスのあらゆるニーズに適応することです。しかし、これらの機能は製品を考えるエンジニアリーダーやデザイナーが担うことも可能です。つまり PM は有用ですが、チームが大きくなる前までは、それほど多く必要ではないということです。
【2】AI のボトルネックは人間のタイピング速度であり、モデルそのものではない
「人間のタイピング速度と検証作業が AGI における重要なボトルネックである」とおっしゃいましたが、詳しく説明いただけますか?
エンビロコスは直接答えず、逆に質問を投げかけました。まずハリーに AI を1日に何回使っているかを尋ね、答えは30回以上でした。次に、もし無料で無制限に使えた場合、AI は1日に何回あなたを助けてくれるかと問いました。答えは無限です。
「私は AI が1日に数万人もの回数で私たちを支援すべきだと考えています。」
彼は OpenAI 内部では、エンジニアたちがすでに「Codex を常時起動しており、会議中にタスクを実行していないと時間を無駄にしたと感じる」状態に至っていると語ります。しかし、これらのエージェント(Agent)を管理し、常に稼働させ続けること自体が膨大な作業となります。
また、彼自身のように毎日これに取り組んでいる人でさえも、「AI がどのように役立つかをすべて考え出すにはあまりにも怠惰である」と述べ、結果として1日の利用回数は一般人と大差ないといいます。彼は AI で新しいことをしたとき(例えば今回のポッドキャストの準備など)、少し誇らしさを感じることもあるそうです。
では理想的な未来とはどのようなものか?プロンプトの書き方を学ぶ必要も、AI がどこで役立つかを自ら発見する必要もなく、AI が自動的に文脈に接続し、適切なタイミングで介入するものです。
ハリーはさらに追及します。「それなら、これらのプロンプトや人間の動作を製品化(productize)してボトルネックを取り除くことが、貴社の仕事なのでしょうか?」
エンビロコスは「そうだが、すぐにできるわけではない」と答えました。そして3段階のロードマップを示しました。
第一段階では、LLM が恰好に得意とするソフトウェアエンジニアリングとコーディングの分野でエージェントをまず確立することです。
第二段階では、エージェントがより広範に有用になるためにはコンピュータを操作できなければならないことに気づき、コードこそがエージェントがコンピュータを操作する最良の方法であると認識します。
「すべてのエージェントは本質的にコーディングエージェントです。なぜならコードはエージェントがコンピュータを使用するための最良の手段だからです。」
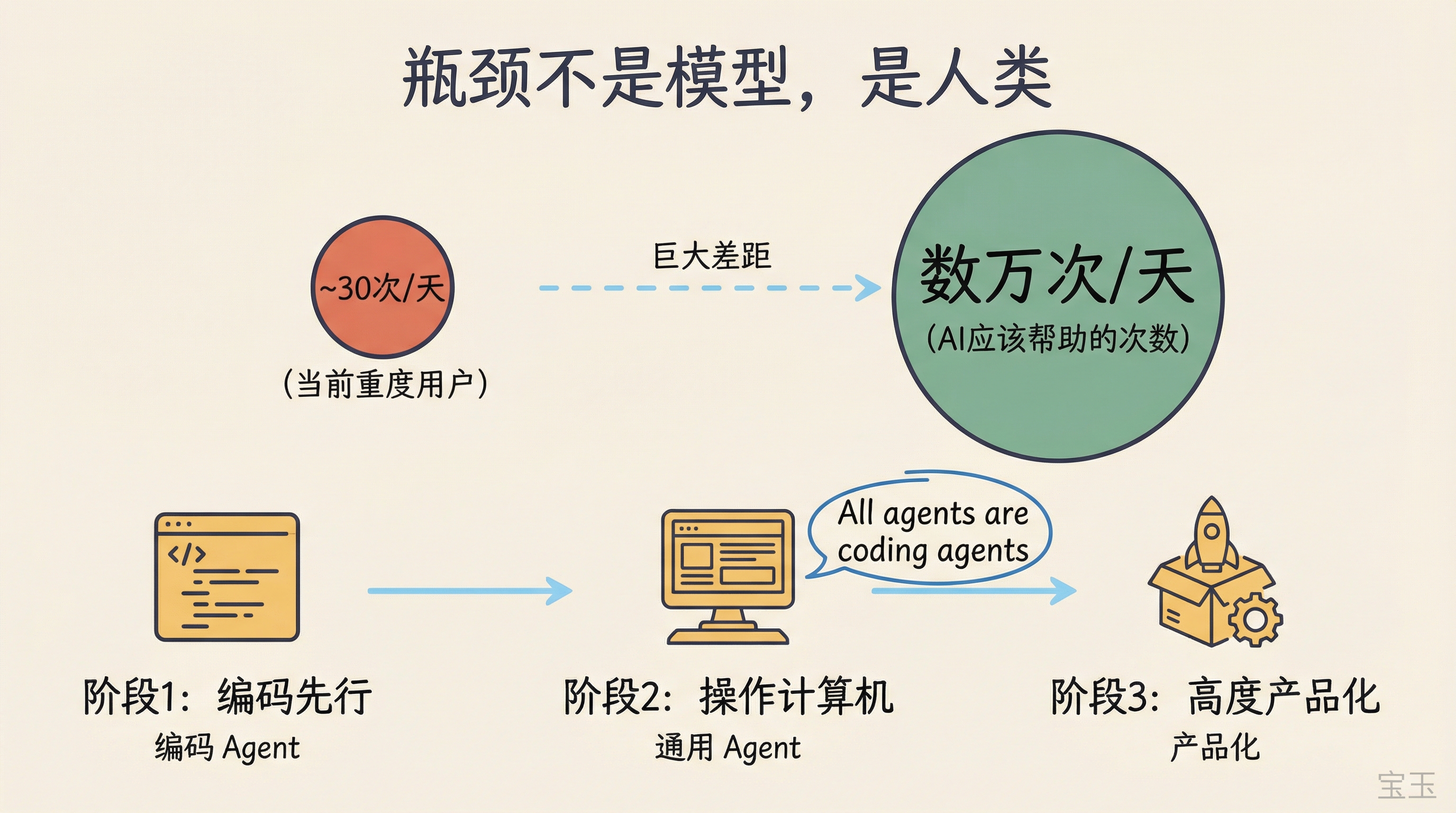
第三段階では、何が有効かを観察した上で、高度に製品化された機能を実装します。彼は「今後数ヶ月のうちにこの3つの段階を急速に完了させる」と語りました。
彼は特に Claude Code が最初にリリースされた際に行った正しい取り組みについて言及しました。それはターミナル内で超シンプルなツールを提供し、ユーザー自身がさまざまな使用場面を探求できるようにした点です。OpenAI もまた、特定の業界向けのカスタマイズ製品よりも、このようなオープンなツールの優先開発をすべきだと考えています。
ハリーは矛盾を指摘しました。もし垂直製品ではなくオープンツールを作るなら、責任をユーザーに押し付けることにならないでしょうか?これはまさに「人間がボトルネックである」という原点に戻ることになります。エンビロコスはこれが確かにボトルネックであると認め、そのため3段階の設計は段階的に参入障壁を下げるものだと説明しました。
【注:Claude Code は Anthropic が 2025 年 2 月にリリースしたコマンドライン AI プログラミングツールで、開発者コミュニティの間ですぐに人気となりました。また、彼は Claude の製品化が優れている点にも言及しています。例えば「Claude for Legal」や「Claude in Excel」などは Anthropic が展開する垂直分野向けアプリケーションであり、特定の業界のユーザーがプロンプトを書かなくても AI を利用できるようにしたものです。】
【3】まずはツールを、その後に自動化——企業における AI 導入の道筋を巡る議論
企業での AI 導入におけるデータセキュリティや権限設定の問題は難しいですが、実施エンジニアは不要なのでしょうか?
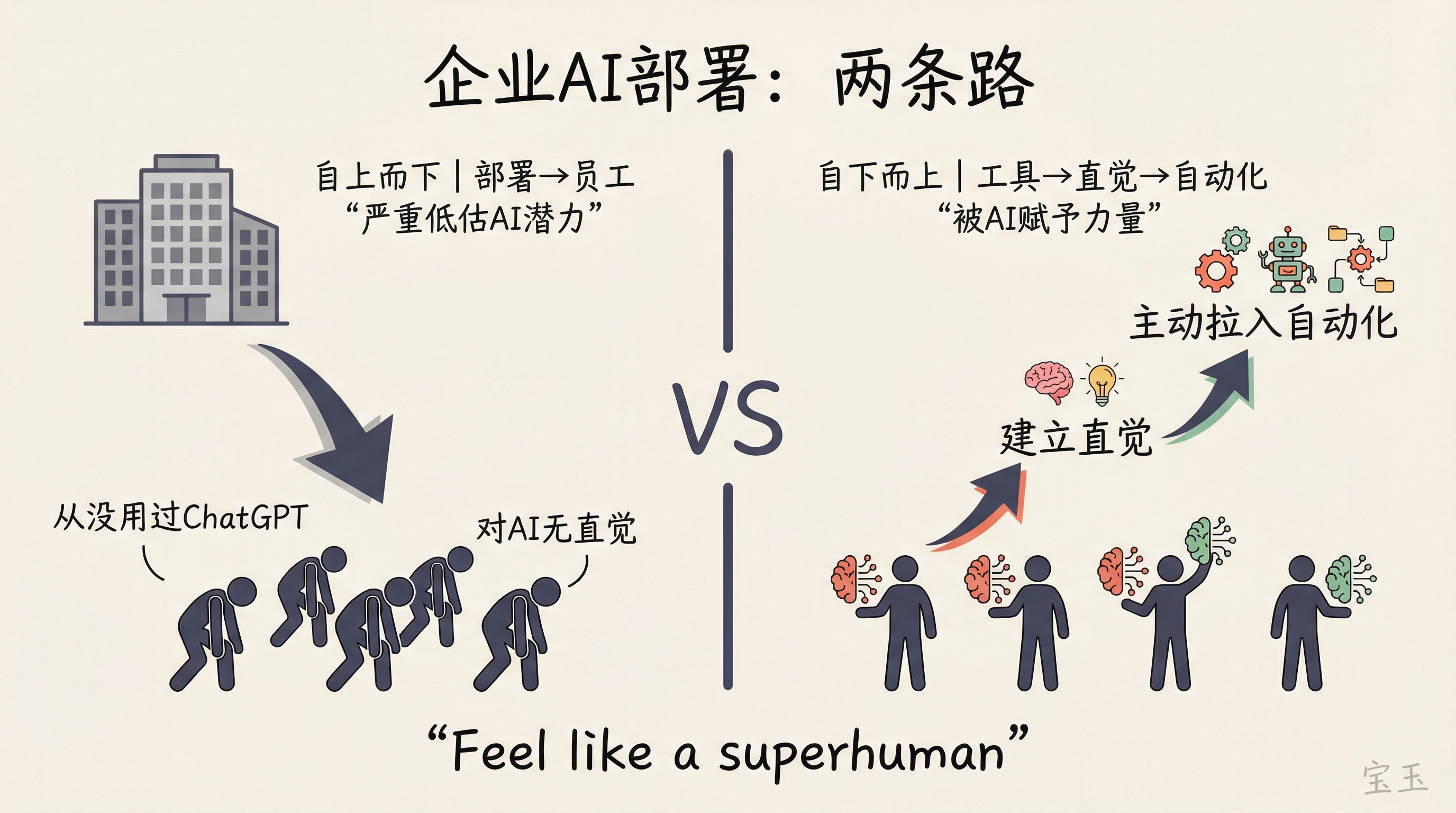
エンビロコスは、ゼロから一へと完全なワークフロー自動化システムを導入する場合、セキュリティコンプライアンスと各種データシステムをつなぐために実施エンジニアが必要であることは認めました。しかし彼の核心的な見解は、「トップダウンでの導入では、その企業における AI の可能性を深刻に過小評価する結果になりがちだ」という点です。
彼は比喩を用いて説明しました。あなたがカスタマーサポートの担当者だと想像してください。AI があなたの仕事の大部分を自動化しているのに、あなたは ChatGPT を一度も使ったことがない場合、あなたにとって AI に対する直感は全くなく、自動化に対して無力感しか感じないでしょう。しかし、もし同時に日常業務で ChatGPT を利用していれば、AI の能力を理解し、よりコントロール感を持てるようになります。
ではデータセキュリティの問題はどうなるのでしょうか?彼は、各ツールや各ワークフローは最終的に特定の従業員のブラウザまたはローカルファイルシステムに収束すると指摘しました。だからこそ OpenAI は Atlas ブラウザを構築しているのです。
【注:ChatGPT Atlas は OpenAI が 2025 年 10 月にリリースしたブラウザで、Chromium をベースに構築され、ChatGPT の機能が内蔵されています。ユーザーが閲覧中のウェブページの内容を理解でき、Agent モードによりブラウザ内で直接タスクを実行することも可能です。】
自社製のブラウザを構築しエンドツーエンドで制御することで、OpenAI は企業向けに安全な Agent によるブラウジング体験を提供できます。これにより、実施エンジニアがつながっていないシステムにも Agent がアクセスできるようになります。
「私にとって AI との最もエキサイティングな未来とは、誰もが自分自身をスーパーマンのように感じ、AI によって力を与えられていると感じる世界です。」
【4】ペアプログラミングから委任へ——OpenAI 内部における働き方の変革
OpenAI 内部では、コードのどの程度が Codex によって生成されているのでしょうか?
エンビロコスは具体的な割合は示しませんでしたが、自分が知る多くの人がもはやエディターを開かなくなったと述べています。
「コードそのものは、もう人間によって書かれていません。」
「コードの大部分は AI によって書かれており、現在ではおそらくほとんどの人が IDE(統合開発環境)さえ開いていないでしょう。」
この変化は段階的なものではなく、飛躍的なものです。転換点は2025年12月のGPT-5.2 Codexで訪れました。このモデルは、長時間の稼働、エンドツーエンドでのタスク処理、コンテキストの管理、そして指示への従順性において劇的な向上を遂げました。
【注:GPT-5.2 Codex は2025年12月にリリースされました。その後、2026年2月5日にOpenAIはGPT-5.3 Codexを発表し、「これまでで最も強力なエージェントコーディングモデル」と称しています。前世代よりも25%高速であり、自身を訓練およびデプロイするために使用された最初のモデルでもあります。】
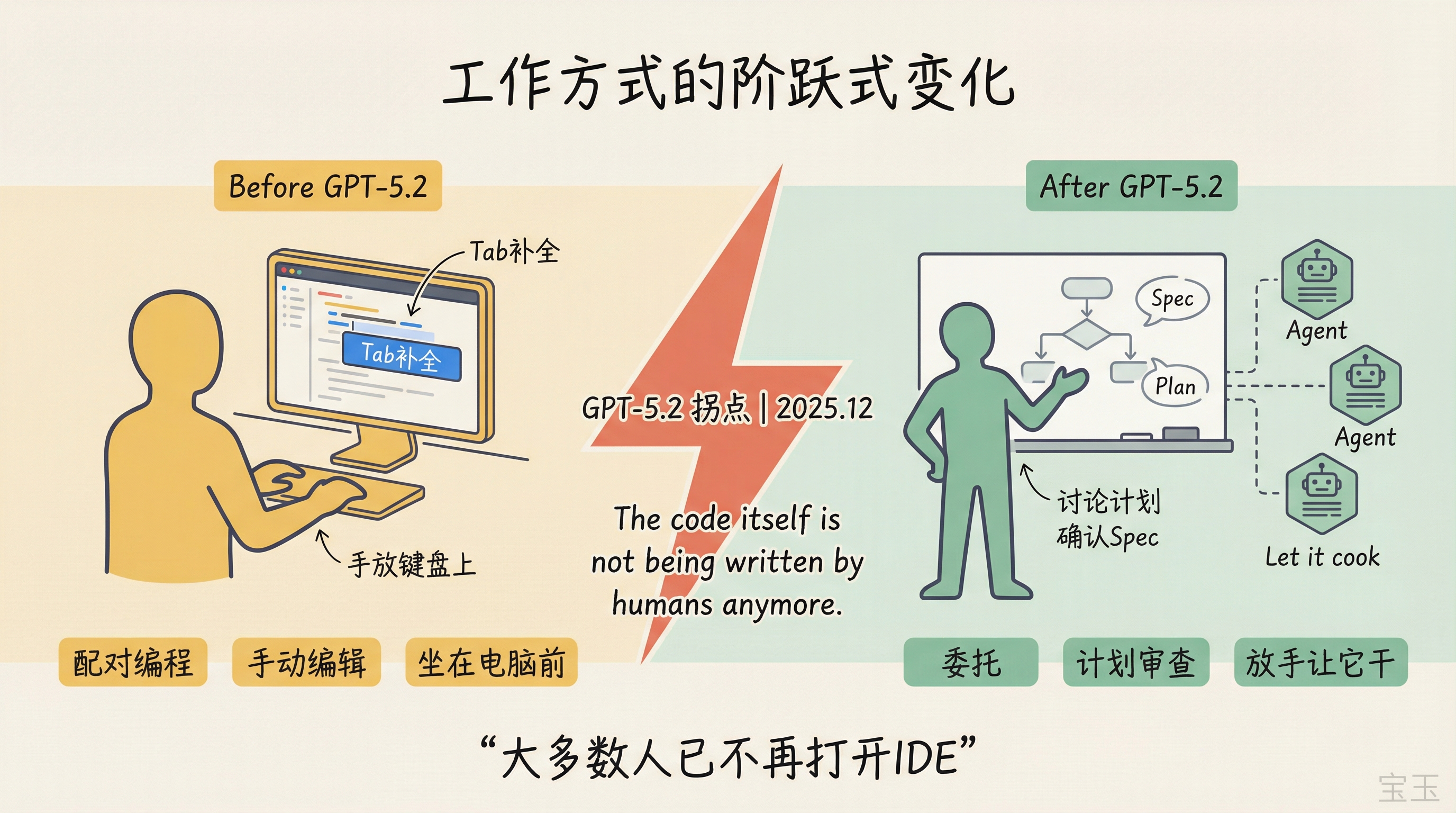
GPT-5.2以前は、AIによるコーディング支援は主にタブ補完やペアプログラミングに限定されており、ユーザーはパソコンの前に座り、キーボードに手を置いたまま作業を行う必要がありました。しかしGPT-5.2以降、働き方は「エージェントと計画を議論し、仕様(spec)を確認した上で、『let it cook』(任せておけば勝手に進んでくれる状態)にする」というものへと変化しました。
これが彼らがCodex Appを開発した理由です。これは「ペアリングではなく委任」のために特別に設計されたインターフェースです。このアプリには、複数のエージェントを管理するツールや変更のレビュー機能、そして目立つ位置に配置されたSkills(オープンスタンダードに基づくエージェント能力拡張)が備わっていますが、意図的にテキスト編集機能は含まれていません。
【注:Codex App は2026年2月2日にmacOS版としてリリースされ、複数のエージェントによる並行作業をサポートしています。同じ週、OpenAIはスーパーボウルで広告を放映し(スローガン:「You can just build things」)、無料ユーザーおよびGoプランユーザーに対して一時的にCodex機能を開放しました。】
コードレビューについてEmbiricos氏は、計画段階でのレビュー(plan review)が以前にも増して重要になっていると述べています。CodexにはPlan Modeという機能が備わっており、エージェントはまず読み取り専用モードでコードベースを調査し、詳細な提案を作成した上で、実行に移す前にユーザーの同意を得る必要があります。これはまるで新入社員が作業を開始する前にチームにRFC(Request for Comments:征求意见稿)を提出するようなものです。
コードそのもののレビューについては、OpenAIのほぼすべてのコードがリポジトリへプッシュされる際にCodexによって自動的にレビューされるとのことです。Codexは低誤検出率を持つレビューヤーとして特別に訓練されており、その指摘のほとんどが価値あるものであるため、ユーザーはそのフィードバックを信頼できます。また彼は、誰かが他のモデルが生成したコードをCodexでレビューさせたところ、「むしろCodexを使って直接コードを書くべきだ」と気づいたというエピソードも紹介しています。
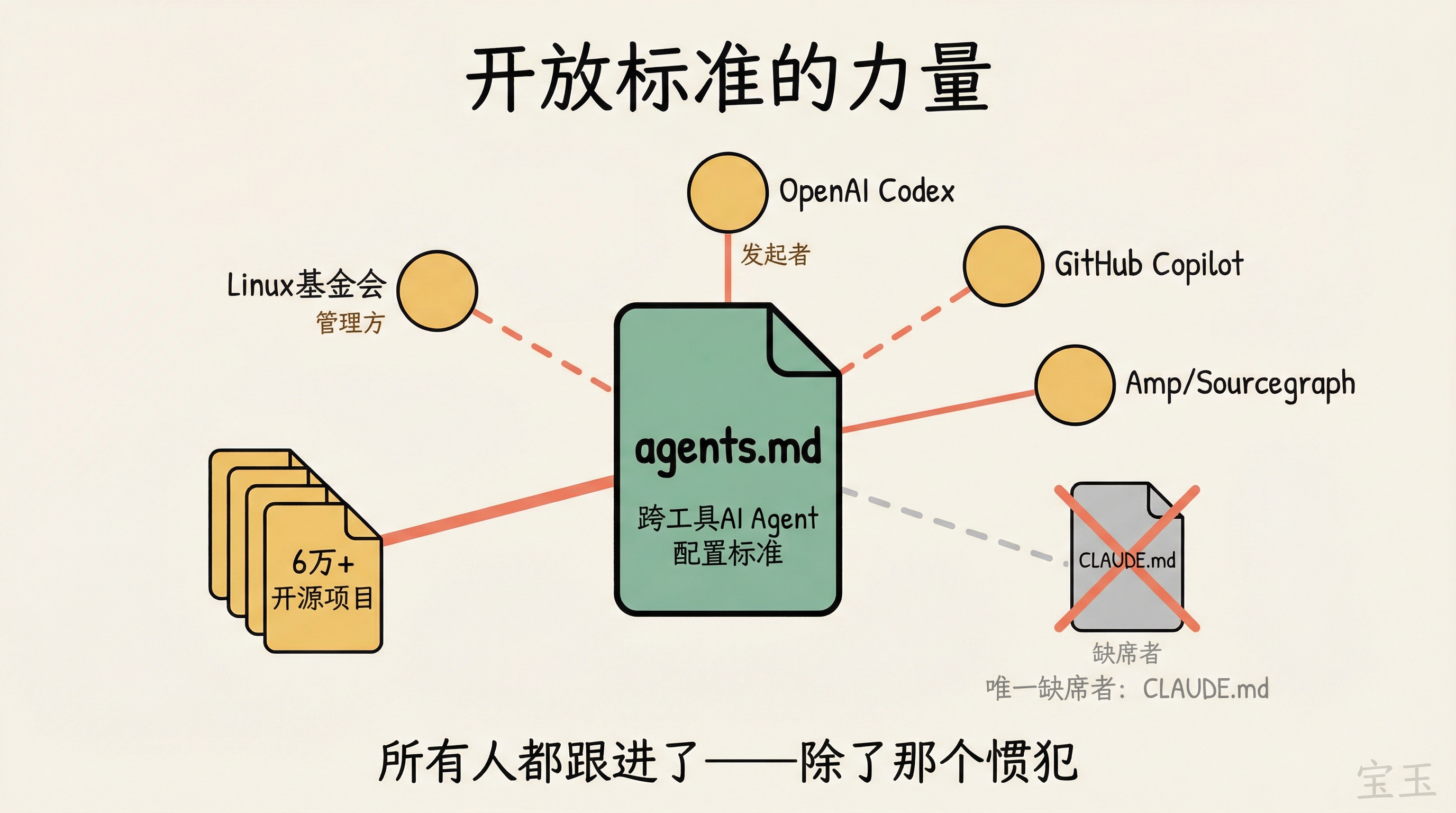
【5】オープンスタンダード——「Claudeを除くすべての企業がagents.mdを採用」
ユーザーは異なるコーディングツール間を容易に切り替えることができますが、これに対する粘着性(リテンション)についてはどうお考えですか?
Embiricos氏は、むしろ意図的にユーザーが簡単に切り替えられるようにしていると答えました。Codexのコアとなるハーンセス(実行フレームワーク)はオープンソースです。昨年Codexが初登場した際、彼らはagents.mdという規約を確立しました。これはあらゆるエージェントが読み取ることができる設定ファイルですが、あえてcodex.mdとは呼んでいません。先週、彼らはSkills(エージェントの能力拡張スクリプト)をagents/ディレクトリに格納するようさらに推進しました。
「全員が追随しました——あの常習犯を除いて。」彼は名指しはしませんでしたが、明らかにAnthropicのClaude Codeを指しています。同社は独自のCLAUDE.mdを使用しているからです。
【注:agents.md はクロスツール AI エージェント設定の標準規格です。OpenAI が agents.md(複数形)を、Amp/Sourcegraph が agent.md(単数形)をそれぞれ推出しました。その後、Quinn Slack がソーシャルメディア上で命名の統一を提案し、業界標準化が促進されました。2025 年末までに 6 万を超えるオープンソースプロジェクトで採用され、GitHub Copilot もサポートを発表しています。この規格は Linux 財団傘下の Agentic AI Foundation(エージェント型 AI 財団)によって管理されています。Claude Code は独自の CLAUDE.md 形式を使用します。】
しかし、彼はそのような容易に切り替え可能な状態は一時的なものであるとも指摘しました。現在のコーディングタスクは「エピソード式(episodic)」です:汎用的なエージェントファイルがあり、あらゆるエージェントがそれを読み取ることができます。エージェントがコードを記述し、パッチ(修正プログラム)を作成して git に投入します。タスクの両端はベンダーに依存しない中立の状態にあります。
一旦エージェントが外部システムと連携し始めると、例えば Sentry(エラー監視サービス)と対話したり Google Docs を操作したりする場合、粘着性は大幅に増加します。企業がエージェントに対してこれらのシステムへのアクセス権限を信頼させつつ、安全なサンドボックスと制御措置を確保することは、二度としたくない決断です。
Embiricos 氏は、まさにこの予測に基づいて Codex を構築したのだと話しました。Codex は最も保守的なサンドボックスメカニズムを採用し、OS レベルの制御によってエージェントが何を実行できるかを制限しています。
【6】「私たちの仕事は Codex の成功ではなく、知能の普及です」
ユーザーを Codex に留めさせ、Cursor や Claude Code へ流出させないためにはどうすればよいのでしょうか?
Harry は Hamilton Helmer 氏の『七つの力』のフレームワークを用いて競争優位性の構築について問いかけました。Embiricos 氏は OpenAI の使命は「安全に AGI(汎用人工知能)の恩恵を人類全体に届けること」であり、Codex チームの本質的な仕事は Codex そのものの成功ではなく、「知能の普及(インテリジェンス・ディストリビューション)」であると述べました。
「私たちはこれらのモデルを訓練するために莫大な努力を注ぎ込み、その後、それらのモデルを競合他社に提供しています。」
Harry は率直にこう言いました。「私のようなベンチャーキャピタリストにとっては理解しがたいことです。」
Embiricos 氏はこれは長期的なゲームであると説明しました。競合他社が強くなればなるほど、OpenAI も学習できます。たとえ競合他社がクローズドソース(暗に Anthropic を指す)であっても、その製品設計や創意工夫からインスピレーションを得ることができます。彼は例として、その朝まだ Twitter で Warp(ターミナルツール)の新機能をリツイートしたことを挙げました。そこには「エージェントがクラウドとローカルで同時に動作する」という素晴らしいアイデアが含まれていました。業界全体は「避けられないほど同じ結論に達している」のです。
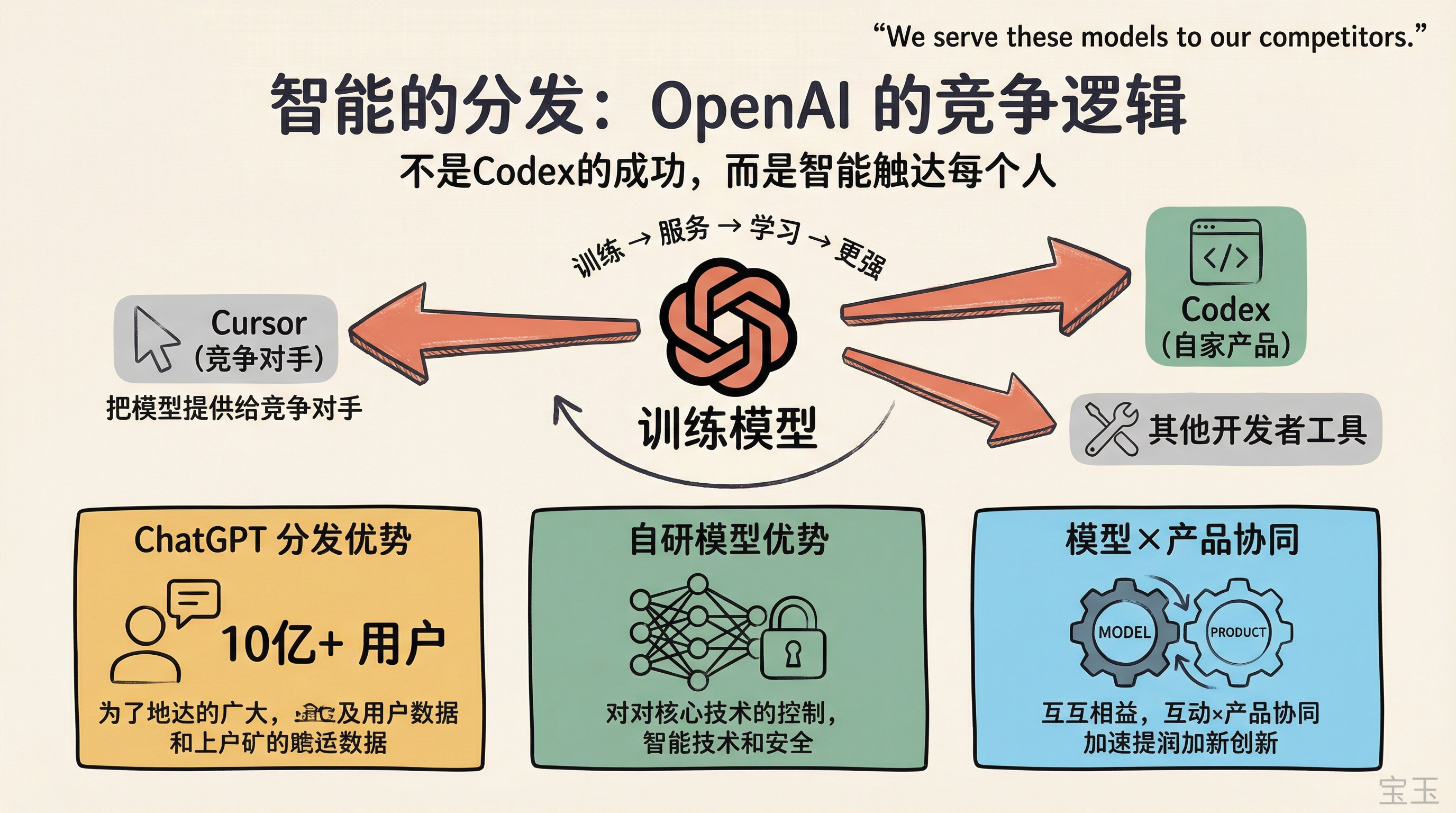
では、Codex の真の強みとは何でしょうか?彼はいくつか挙げました:ChatGPT の圧倒的な配布優位性、自社製モデルが自社のハーンネス(実行環境)内で発揮する能力優位性(誰よりも先に新モデルを入手できる)、そしてモデルと製品の協調最適化です。
企業レベルで見ると、最も重要なのは計算上の優位性と最良のモデルであり、そのためには収益を生むビジネスを構築する必要があります。興味深いことに、Codex といった製品チームが逆にモデルの改善を加速させています。
製品レベルでは、個人ユーザーに好まれる製品を作ることが何よりも重要です。
また、企業側からの教訓も認めました。「私たちが来たので、自由に使いなさい」というだけでは不十分で、大量の教育、設定サポート、そして開発者体験責任者との連携が必要です。
Embiricos 氏は「非常に重要だ」と述べています。彼らが Cerebras と提携したのはまさに遅延問題を解決するためです。彼は提携に関する新しい発表がまもなくあることを示唆しています。
【注:2026 年 2 月 12 日、OpenAI は GPT-5.3-Codex-Spark をリリースしました。これは Cerebras との協力による最初の成果です。Spark は GPT-5.3 Codex の軽量版で、Cerebras の Wafer Scale Engine 3 チップ上で動作し、推論速度は 1 秒あたり 1000 トークンを超え、ほぼ即時のコーディングインタラクションの実現を目指しています。】
しかし、彼は推論が独占されることはないと考えています。競争圧力が多様なソリューションを生み出すでしょう。GPT-5.3 Codex そのものが前世代モデルよりもはるかに効率的です。また、API レベルでの最適化も行い、モデルの推論速度を 40% 向上させ、Codex のユーザー側では 25% の高速化を実現しました。
Harry は Jason Lemkin(SaaStr 創設者)の判断を引用しました。「AI 計算資源は新たな営業とマーケティングである」という言葉です。これは、過去には企業が顧客獲得のために販売チームを雇い広告を出費していたが、未来では AI 計算資源(inference、つまりモデルを実行する計算コスト)を購入し、ユーザーがすぐに製品価値を体験できるようにすることで自発的に変換されることを意味します。本質的には PLG(Product-Led Growth、製品主導成長)の AI バージョンであり、販売チームは不要になる可能性があります。
Embiricos 氏はこれにあまり同意していません。彼は「誰もが製品を構築できる世界では、市場での選択肢はさらに増えるだけで、顧客との良好な関係を維持し、彼らが本当に何を必要としているかを理解することは、以前よりも難しくなる」と述べています。営業とマーケティングが解決する正是この問題であり、代替されることはありません。
主な指標は週次アクティブユーザー(WAU)であり、収益ではありません。Harry は「Codex が実際に IDE を置き換えるのであれば、日次アクティブユーザーを見るべきではないか」と追及しました。Embiricos 氏はその場でこの批判を認め、「おっしゃる通りです。私たちは日次アクティブユーザーに焦点を移すべきかもしれません」と答えました。
彼の目標は、ユーザーの第一反応が「何かあればまず Agent に聞く」ことに変化することです。Google が情報に対して果たす役割や ChatGPT が知識に対して果たす役割と同様に、次の段階は「あらゆるタスクではまず Agent を探す」ことです。
昨年発表されたクラウドベースの Agent のアイデアは素晴らしかったものの、Agent 専用のクラウドコンピューターを与え、並列処理で複数のタスクを処理できる仕組みでしたが、「正直に言って、後からリリースされたバージョンの方が効果的でした」。2025 年 8 月の GPT-5 以降、彼らはインタラクティブなコーディングへと転換し、最も競争の激しい市場に進出しました。その結果、ユーザー数は 20 倍に増加しました。2025 年 12 月に GPT-5.2 Codex がリリースされ、再び転換点となりました。「12 月以来、さらに 2 倍になりました」。
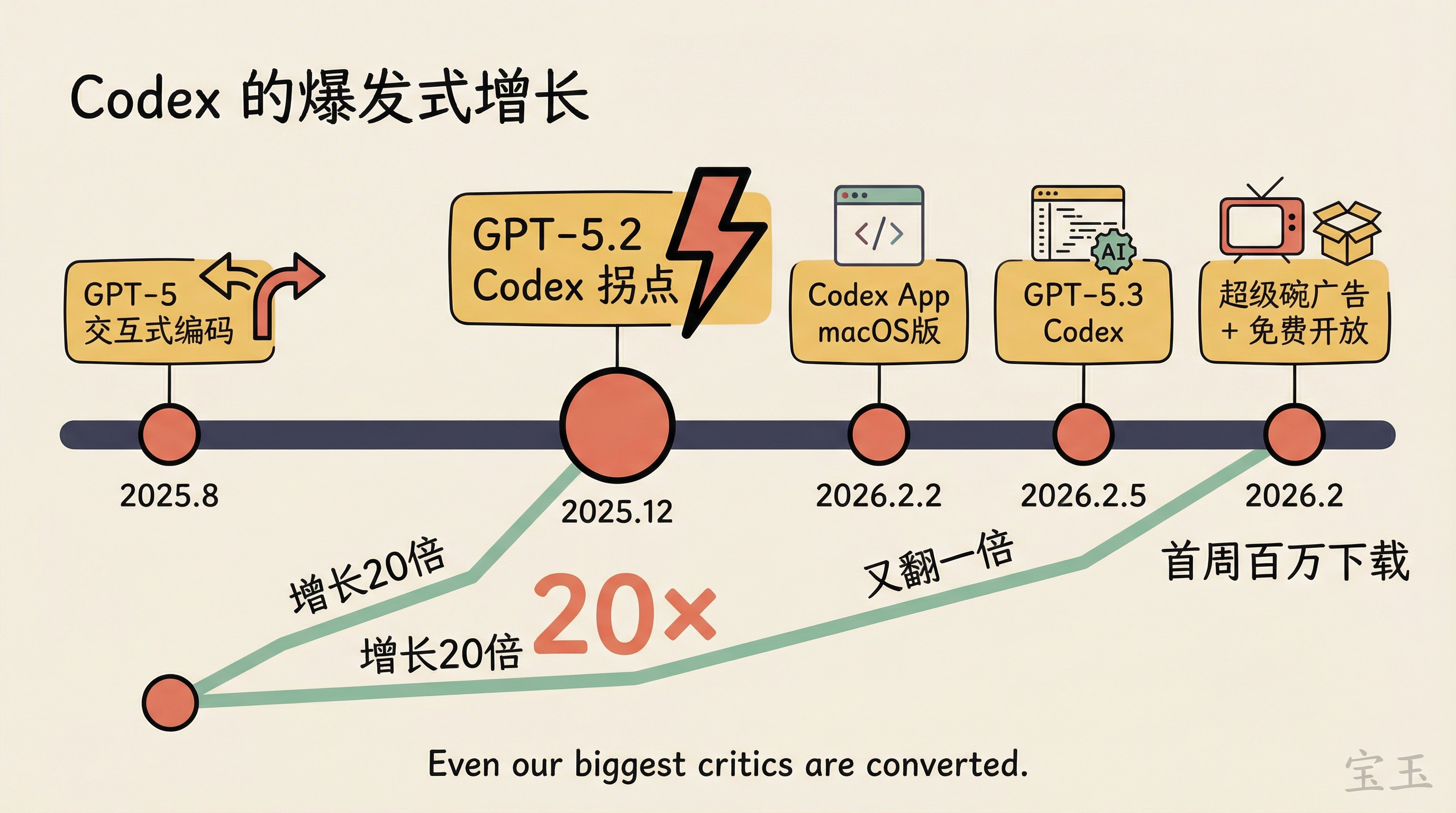
そして 2026 年 2 月には集中的な爆発的成長が見られました。GPT-5.3 Codex がモデルの知能における優位性を確固たるものにし、Codex App のリリース(初週でダウンロード数 100 万超)がユーザー体験の弱点を解消し、スーパーボウルでの広告がブランド認知を広げ、無料ユーザーへの開放がカバー範囲を拡大しました。
「私たちの最大の批判者さえも転向しました」。
彼はまた、競合他社を皮肉るのを忘れませんでした。あるモデルは私たちより約 20 分早くリリースされましたが、「少し毒舌かもしれませんが、そのモデルはわずか 20 分の SOTA(state of the art、最先进水平)に過ぎませんでした」。
【注:2026 年 2 月 5 日に GPT-5.3 Codex がリリースされた際、Anthropic はほぼ同時に Claude Opus 4.6 を発表しました。2 月 8 日のスーパーボウル期間中、OpenAI と Anthropic はそれぞれ広告を放送し、OpenAI のスローガンは「You Can Just Build Things」でしたが、Anthropic は ChatGPT に広告が埋め込まれていると皮肉りました。両社はソーシャルメディア上で公然と対立しました。】
最も実現したいことは二つあります。第一に、クラウド製品への回帰です。以前、クラウドからローカルインタラクションへ移行したのはタイミングが悪かったためで、ユーザーがまだツールに慣れていない段階でいきなりワークフロー自動化を行っても、それは空中楼閣を築くようなものです。しかし現在ではユーザー基盤が確立されたので、クラウドとローカルの製品を密接に統合すべき時です。
第二は、コードレビューや品質管理といった「過小評価されているボトルネック」の解決により多くの精力を注ぐことです。コード生成はすでに「ほぼ取るに足らないもの」となりましたが、コードの質が優れているか、方向性が正しいかをどう判断するかこそが真の難題です。目標は、エージェント(Agent)に完全な反復能力を持たせることで、ユーザーフィードバックの収集と自己改善を行い、もはや人間のレビューを必要としないようにすることです。
【8】チャットは万能の入口だが、専門的な GUI との組み合わせが必要
チャットが AI の永続的なインターフェースとなるでしょうか?
Harry は a16z パートナーのアニシュ・アキャリヤ(Anish Akarya)の反対意見を引用しました。チャットインターフェースはサム・アルトマンやイーロン・マスクといった高効率な人々のために設計された産物ですが、地球上の大多数の人々は実際にはブラウザ型の、クリックして発見できるグラフィカルユーザーインターフェース(GUI)を望んでいるのです。
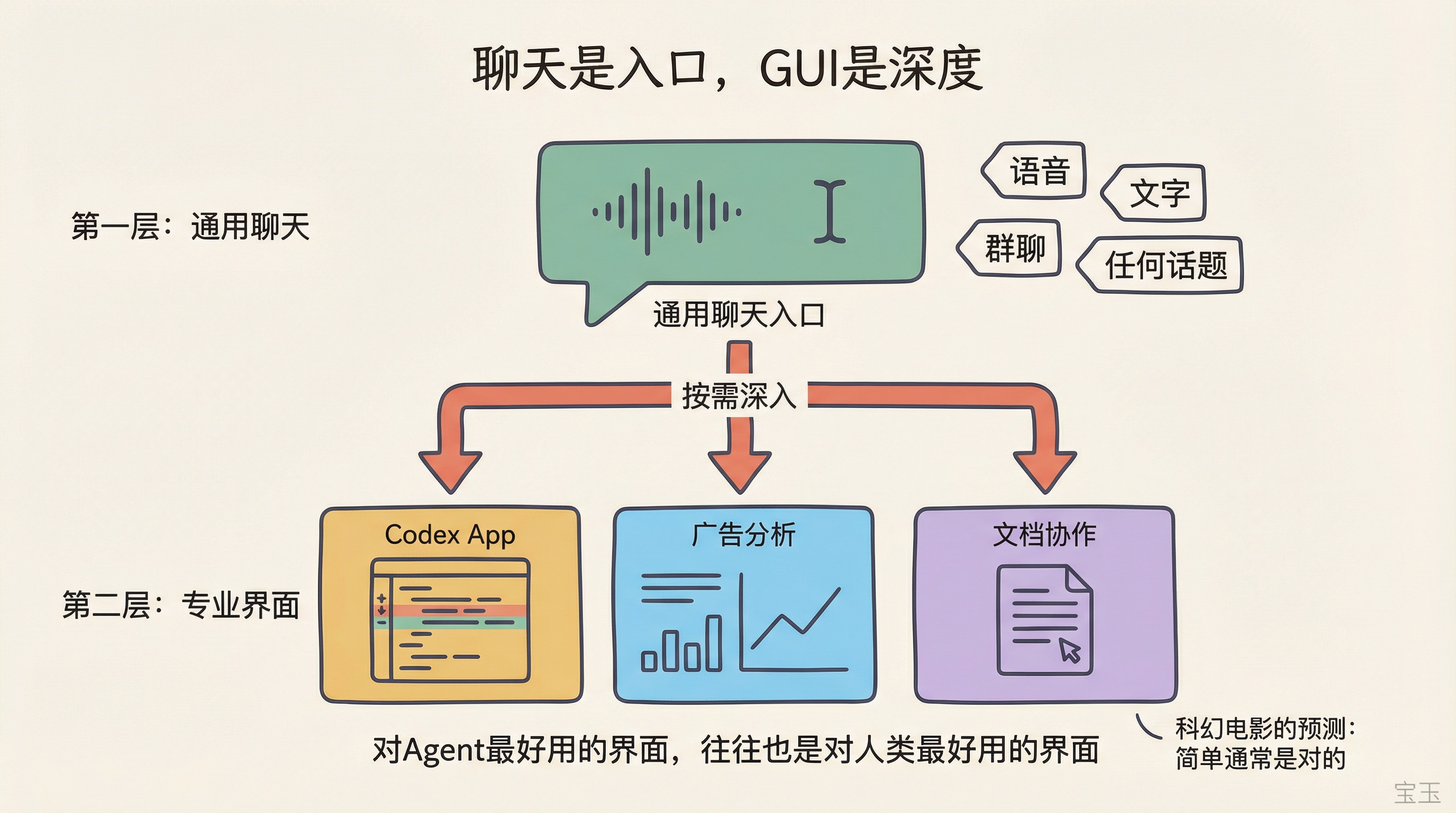
エンビロコスの回答は「はい、ただし二層で捉える必要があります」でした。彼は SF 映画が優れた未来予測器であると指摘しました。SF における AI は通常非常にシンプルで、自由に話せる実体であるだけで、「コーディング AI」から「販売 AI」へと切り替える必要はありません。SF が優れた予測器である理由はまさに物語を語る点にあり、シンプルなものが正しいことが多いからです。
したがって第一層は、チャットまたは音声による汎用入口です。何でも話し、あらゆるグループチャットに追加して、自分自身でどうやって支援するかを見つけさせることができます。
しかし第二層も同様に重要です。専門家はすべてのことを別の「人」との対話を通じて完了させたいとは思いません。彼は比喩を用いました——行政アシスタントがいるが、仕事をするには彼と会話するしかなく、ファイルを直接見たり自分で編集したりできない状況を想像してください。それは非常に煩わしく、時には文書を開いて直接修正したいという衝動に駆られるものです。
したがって将来のモデルは、チャットを汎用入口とし、特定分野向けの機能性 GUI を組み合わせるものになります。彼自身はポッドキャストの準備にはチャットを使いますが、コードについては Codex App を開いて深く掘り下げる必要があります。マーケティング担当者は製品に関する質問にはチャットを使いますが、広告データを確認するには専用の分析インターフェースを使用します——製品に関する質問をするために Codex App をダウンロードすることはありません。
また、興味深い発見にも言及しました。Codex を構築する過程で、彼らはエージェントにとって最も使いやすいインターフェースが、人間にとっても最も使いやすいものであることに気づいたのです。例えば、テストフレームワークはデフォルトですべてのテスト結果を出力しますが、人間は数千行の中から失敗した一つを見つけるのは苦痛です。AI も同様に苦しみます。しかし、失敗したテストのみを出力すれば、人間にもエージェントにもより良いことになります。これは、エージェントと人間の間の引き継ぎポイントで同じインターフェース設計を共有できることを意味します。
【9】エージェント市場の終焉——少数の汎用エージェントが勝つ
この市場は最終的に二頭独占になるのか、それとも三分天下になるのでしょうか?
Harry は投資家の視点からこの質問をしました。エージェント市場の終局は、Uber と Lyft のように二社で分け合う(Codex が大きなシェアを握る)ものなのか、AWS、Azure、Google Cloud のように三つ巴のものになるのかです。
エンビロコスは、最終的に少数のプロバイダーが大部分の価値を独占すると考えています。その論理は以下の通りです:
過去一年を振り返ると、多くの人がエージェントは複数の分野で PMF(Product Market Fit、製品市場適合)を見つけると考えていましたが、実際にはコーディングエージェントだけが実際に軌道に乗りました。カスタマーサポートなどの他の分野はまだ初期段階です。しかしこれは一時的なことで、将来のエージェントは何でもできるようになるでしょう。
その頃になったら、会社の中で 12 個のエージェントを配置して従業員に自分で適切なものを選ばせるようなことはしたくないでしょう。なぜなら、彼らはどのエージェントに対しても「熟練」状態には達しないからです。不慣れであれば、自動化を自らのワークフローに積極的に取り入れようとはしません。しかし、エージェントが一つだけあれば、オンボーディング(入社研修)は「何かあればそれへ相談するもの」となり、人々は筋肉記憶を形成し、それが仕事の中心となります。チーム間では使用テクニックの共有や、新しい使い方を模索するためのハッカソンが開催され、組織全体がそれを軸に回るようになります。
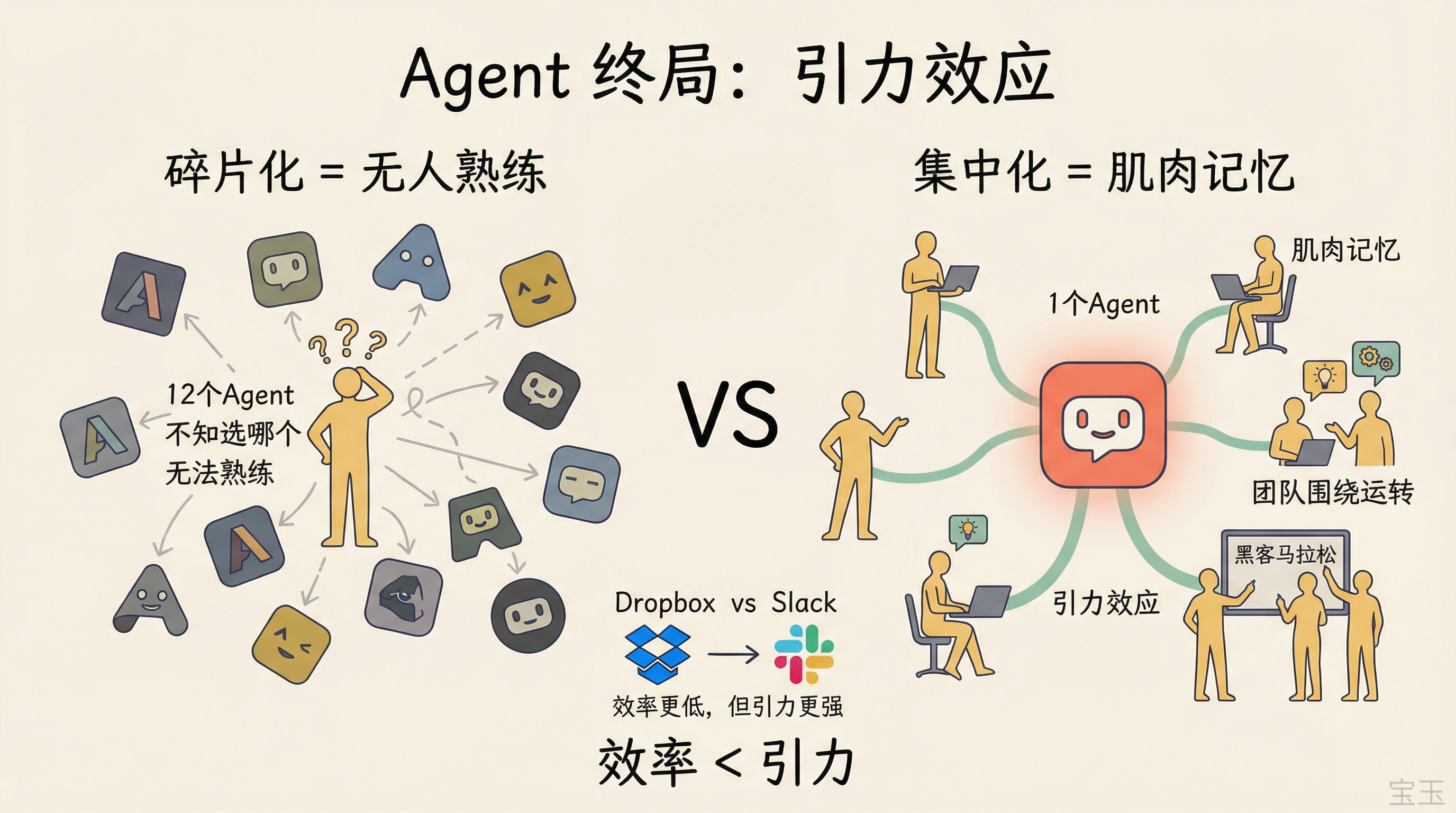
これは彼が Dropbox で見たものと全く同じです。Slack が台頭する前、Dropbox のドキュメント共同編集機能は実はより効率的でした——動画の正確なタイムスタンプにコメントを残したり、ドキュメントの特定の段落に注釈をつけたりできるからです。しかし人々はこぞって Slack へ流れ込みました。誰もドキュメントにコメントを書こうとはせず、みんなが Slack で直接 @ メンションしたいだけなのです。効率は低下しますが、引力効果は強くなります。エージェント市場も同じ物語を繰り返すでしょう。
彼は ChatGPT がこれを行うことに天然の優位性を持っていると考えています。すでに多くの人のための汎用 AI エントリーポイントとなっているからです。
【10】データ護城河はどこにあるか:プログラミングデータは十分、知識労働データの希少性
プログラミングデータの護城河は誰の手元にあるのでしょうか?Anthropic はすでにすべてのデータを手にしているのでしょうか?
この質問は Harry が LinkedIn で募集した読者からのものです。Harry は質問者の所属企業を「伏地魔」に例え、「『名前も言えない会社』の優秀な投資家」と表現し、続けて「サム(Sam)に私を殺させたくはない」と付け加えました。おそらく Anthropic の投資家が問うているのでしょう:「你们的编码数据护城河到底在不在?」(你们的编码数据护城河到底在不在?)
Embiricos の回答は非常に直接的でした。プログラミングデータはすでに十分であるというのです。「非常に優れたコーディングモデルを構築するのに十分なデータがある」と彼は述べ、これがボトルネックではないと強調しました。
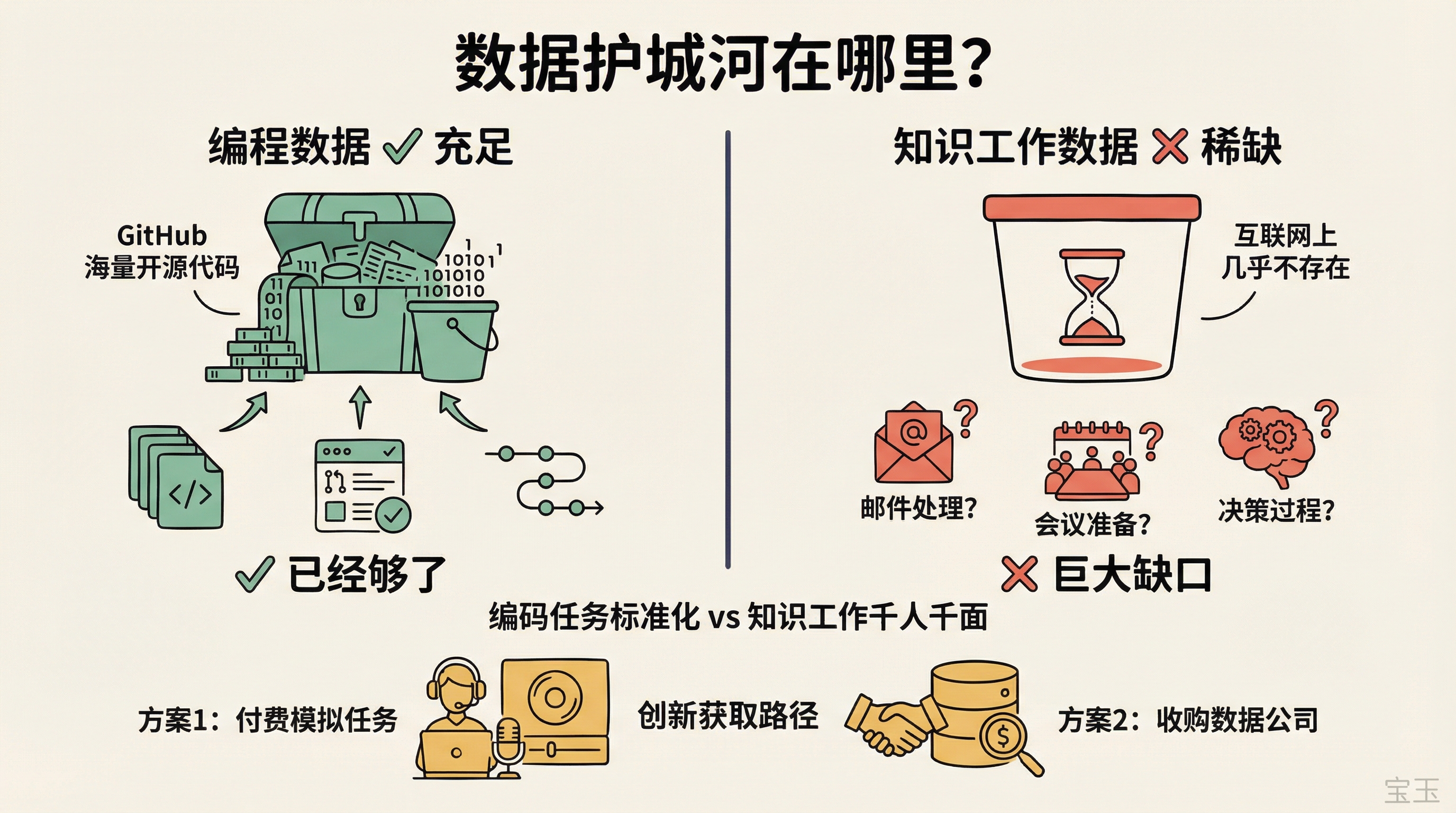
本当に興味深いデータギャップは知識労働の分野にあります。なぜでしょうか?
コーディングには天然のデータ宝庫があるからです。GitHub には膨大な量のオープンソースコードがあり、どのようにコードを書き、どのように変更し、どのようにレビューするかというプロセスすべてが追跡可能です。しかし知識労働は全く異なります。誰かがメールへの対応方法や会議の準備方法、意思決定のプロセスを完全に記録してネット上に公開することはありません。こうしたデータはインターネット上にはほぼ存在せず、さらに知識労働タスクの分布はコーディングよりもはるかに複雑です。コーディングタスクは比較的標準化されていますが、知識労働は千人千面です。
このようなデータを入手する道筋にはイノベーションが必要です。Embiricos は二つのアプローチを提案しました。一つ目は、人々に報酬を支払ってタスクをシミュレーションさせ、その完全な操作軌跡を訓練データとして記録する方法です。二つ目は、運営を終了したが多くのワークフローデータを蓄積しているスタートアップ企業を買収するというものです。彼が挙げた例は「Slack 類の製品」で、これらの製品には実際のチームコラボレーションや意思決定コミュニケーションの記録が大量に保存されています。
Harry は外部データ会社(Turing、Invisible など)との提携によって投資が増大するかどうかを尋ねました。Embiricos は、彼らが目指しているのはできるだけ早く推進することだと答えました。小規模なチームにとって自社でデータ採集团隊を構築するのは時間がかかりすぎるため、大規模なデータ収集は通常外部企業と協力して行うのだと説明しました。
【11】SaaS は死なないが、「仲介業者」型企業には麻烦がある
大型 SaaS 企業の収益持続性はゼロであり、SaaS は死んだという主張があります。あなたはどう考えますか?
エンビロコスは、重要な問題は「この SaaS 企業が実際に何を持っているのか」だと述べています。
第一に、人間との関係性を保有しているか——ユーザーが離れられないのは、その企業と慣れ親しんでいるからでしょうか。
第二に、重要な記録システム(system of record)を保有しているか——企業の核心データがそこに保存されているかどうかです。
これらいずれかを満たしていれば、消滅することはなく、むしろ AI 時代においてこれらの要素は以前よりも重要になる可能性があります。
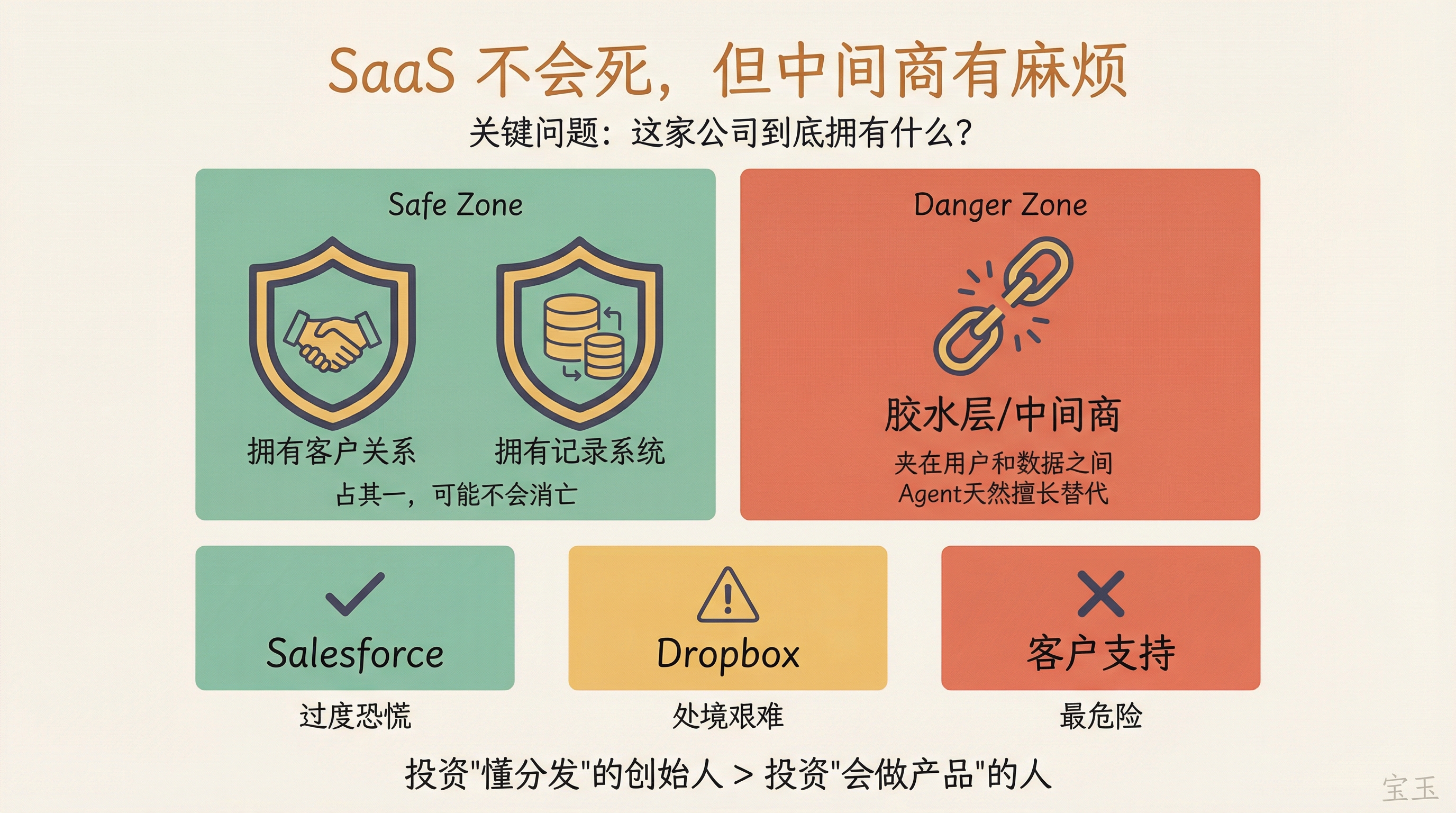
しかし、SaaS 企業が単なる「グルー・レイヤー(接着層)」に過ぎず、ユーザーとデータの間に挟まって接続や運搬のみを行い、顧客関係も核心データも保有していない場合、それは非常に危険です。这类企業は本質的に「仲介業者」であり、AI エージェントが得意とするシステム間の連携やデータ転送こそが、まさにこれらの企業の核となる機能を代替するものです。
ハリーはさらに具体的な推論を行いました:Sale
原文を表示
See all postsPublished on 2026-02-22OpenAI Codex 产品负责人:代码不再由人类编写,但我们会有更多构建者(Builder)
Alexander Embiricos 是 OpenAI Codex 的产品负责人。在加入 OpenAI 之前,他在 Dropbox 做过产品经理,后来创办了协作工具 Multi(前身为 Remotion),做了五年结对编程方向的创业,2024 年被 OpenAI 收购。他亲历了 AI 编程工具从“辅助补全”到“全权委托”的转变。Codex 自 2025 年 8 月以来增长了 20 倍,刚在 2026 年 2 月的一周内密集发布了 macOS 独立应用、GPT-5.3 模型、超级碗广告,并向免费用户开放。
这期访谈覆盖了几个核心话题:AI 编码的现状与工程师的未来、人类为什么是 AGI 的真正瓶颈、OpenAI 内部怎么用 Codex、开放标准与竞争策略,以及 SaaS 行业和 Agent 市场的终局。
来源:20VC with Harry Stebbings,2026 年 2 月 21 日 原始视频:https://www.youtube.com/watch?v=S1rQngjpUdI
OpenAI 内部大多数人已不再打开 IDE,代码的绝大部分由 AI 编写,拐点发生在 GPT-5.2 Codex
AI 应该每天帮助人类数万次,但当前即使是重度用户也只用几十次,瓶颈不在模型而在人机交互
“所有 Agent 本质上都是编码 Agent”,因为代码是 Agent 操作计算机的最佳方式
OpenAI 自认工作不是“Codex 的成功”而是 “智能的分发”,训练模型然后服务给竞争对手
通用 Agent 会打败垂直 Agent,未来可能只有少数几家 Agent 提供商捕获大部分价值
【1】编码不会消亡,但编码的含义会改变
马斯克说编码是最先被大规模自动化的职业之一。你身处前线,同意这个判断吗?
Embiricos 同意 LLM 在编码领域确实很强,但 “自动化”是个很重的说法。他举了几个历史类比:当我们从汇编语言转向高级语言时,没人说“编码被自动化了”,我们只是能写更多代码,结果是对代码的需求反而爆炸了,需要更多软件工程师。
他又提到了”computer”一词的起源。在 Bletchley Park(二战时期英国的密码破译中心),有大量人力负责打孔卡、做制表运算。最早的电子表格软件也脱胎于类似场景:一间办公室里,桌子按网格排列,每个人做一部分计算,然后把工作表传给下一个人。这些具体任务都被自动化了,但每次自动化之后,对产出的需求都出现爆炸式增长。
【注:Embiricos 对“computer”一词起源的描述不完全准确——“computer”作为人类职位的称呼早于 Bletchley Park,最早可追溯到 17 世纪,后来 NASA 的女性数学计算员也被称为 computers。】
“You still need software engineers today. You still need designers. I'm a PM. Do you need PMs? I don't think you need them.” (你现在仍然需要软件工程师、设计师。我是 PM。你需要 PM 吗?我觉得不需要。)
五年后会有更多工程师还是更少?Embiricos 说会有更多“构建者”。但他观察到一个趋势:人才栈在压缩。几年前前端和后端还是两种人,现在至少在 Codex 团队内部,工程师越来越全栈化。
至于 PM 这个自嘲式的判断,他解释说 PM 的角色本质上是“显式未定义的”,目标是适应团队或业务的任何需要。但这些功能也可以由一个思考产品的工程负责人或设计师来承担。所以 PM 有用,但在团队很大之前,你可能不需要太多。
【2】AI 的瓶颈是人类打字速度,不是模型
你说过人类打字速度和验证工作是 AGI 的关键瓶颈,能展开说说吗?
Embiricos 没有直接回答,而是反问。他先问 Harry 每天用 AI 多少次,答案是 30 多次。然后问如果零成本使用,AI 每天能帮你多少次?答案是无限。
“I think AI should be helping us tens of thousands of times per day.” (我认为 AI 应该每天帮助我们数万次。)
他说在 OpenAI 内部,工程师已经到了“Codex 一直开着,如果开会时它没在跑任务,就觉得浪费了时间”的状态。但管理这些 Agent、确保它们一直在干活,本身就是大量工作。
而且即使是他自己这种天天做这个的人,也“太懒”去想出 AI 能帮忙的所有方式,最后每天的使用次数跟普通人差不多。当他用 AI 做了什么新鲜事(比如准备这次播客),还会觉得“挺自豪的”。
那理想的未来是什么?不需要学会怎么 prompt,不需要自己发现 AI 能帮你的场景,AI 自动连接你的上下文,在合适的时机介入。
Harry 追问:那 productize(产品化)这些 prompt 和人类动作来移除瓶颈,是你们的工作吗?
Embiricos 认为是,但不是马上就做到。他给出了一个三阶段路线图:
第一阶段,让 Agent 在软件工程和编码领域先做好,因为 LLM 恰好擅长这个。
第二阶段,意识到 Agent 要更广泛地有用,就需要能操作计算机,而代码恰恰是 Agent 操作计算机的最佳方式。
“All agents are actually coding agents because coding is just the best way for an agent to use a computer.” (所有 Agent 本质上都是编码 Agent,因为代码是 Agent 操作计算机的最佳方式。)
第三阶段,观察什么有效后,做高度产品化的功能。他说“我们会在接下来几个月内快速跑完这三个阶段”。
他特别提到 Claude Code 最初推出时做对了一件事:给你一个终端里的超简单工具,让用户自己去探索各种使用场景。他认为 OpenAI 也应该优先做这种开放式工具,而不是只为特定行业做定制化产品。
Harry 指出了矛盾:如果你做开放工具而不是垂直产品,不就是把责任推回给用户了吗?这正好回到了“人类是瓶颈”的原点。Embiricos 承认这确实是瓶颈,所以三个阶段的设计就是渐进式地降低门槛。
【注:Claude Code 是 Anthropic 于 2025 年 2 月推出的命令行 AI 编程工具,在开发者群体中迅速走红。他也提到 Claude 的产品化做得好,比如 Claude for Legal、Claude in Excel,这些是 Anthropic 推出的垂直场景应用,让特定行业用户可以不写 prompt 就使用 AI。】
【3】先给人工具,再谈自动化——企业 AI 部署的路径之争
企业 AI 部署的数据安全、权限配置问题很难,不需要实施工程师吗?
Embiricos 承认如果要从零到一部署一个完整的 workflow 自动化系统,确实需要实施工程师来打通安全合规和各种数据系统。但他的核心观点是:自上而下部署的结果往往是“严重低估了 AI 在这家公司的潜力”。
他打了个比方:想象你是客服人员,AI 正在自动化你的大部分工作,但你自己从来没用过 ChatGPT。在这种情况下你对 AI 完全没有直觉,面对自动化只会感到无力。但如果你同时在用 ChatGPT 处理日常工作,你会对 AI 的能力有理解,也更有掌控感。
那数据安全问题怎么办?他指出,每个工具、每个 workflow 最终都落到某个员工的浏览器或本地文件系统上。这就是为什么 OpenAI 在建 Atlas 浏览器。
【注:ChatGPT Atlas 是 OpenAI 于 2025 年 10 月推出的浏览器,基于 Chromium 构建,内置 ChatGPT 功能。它可以理解用户正在浏览的网页内容,并支持 Agent 模式在浏览器中直接执行任务。】
通过自建浏览器并端到端控制,OpenAI 可以为企业构建安全的 Agent 浏览体验,让 Agent 访问那些尚未被实施工程师打通的系统。
“For me the most exciting future with AI is one where everyone just feels like a superhuman, just like empowered by AI.” (对我来说,AI 最令人兴奋的未来是每个人都觉得自己像个超人,被 AI 赋予了力量。)
【4】从配对编程到委托——OpenAI 内部的工作方式变革
OpenAI 内部有多少代码是由 Codex 生成的?
Embiricos 没给具体百分比,但说大多数他认识的人已经不再打开编辑器。
“The code itself is not being written by humans anymore.” (代码本身已经不再由人类来写了。)
“The vast majority of code is written by AI and I would say that now probably most people are not even opening IDEs.” (代码的绝大部分由 AI 编写,而且我认为现在大多数人甚至不打开 IDE 了。)
这个变化是阶跃式的。拐点发生在 2025 年 12 月的 GPT-5.2 Codex:模型在长时间运行、端到端处理任务、管理上下文和遵循指令方面有了巨大提升。
【注:GPT-5.2 Codex 于 2025 年 12 月发布。2026 年 2 月 5 日,OpenAI 又发布了 GPT-5.3 Codex,号称是“迄今为止最强的 Agent 编码模型”,比前代快 25%,也是第一个被用来参与自身训练和部署的模型。】
在 GPT-5.2 之前,AI 编码辅助主要是 tab 补全或配对编程,你得坐在电脑前,手放在键盘上。GPT-5.2 之后,工作方式变成了:跟 Agent 讨论一个计划,确认 spec(规格),然后“let it cook”(放手让它干)。
这也是为什么他们做了 Codex App,一个专门为“委托而非配对”设计的界面。App 有管理多个 Agent 的工具、审查变更的功能、突出的 Skills(开放标准的 Agent 能力扩展),但有意没有文本编辑功能。
【注:Codex App 于 2026 年 2 月 2 日发布 macOS 版,支持多 Agent 并行工作。同一周 OpenAI 还在超级碗投放了广告(标语:“You can just build things”),并临时向免费和 Go 用户开放 Codex 功能。】
谈到代码审查,Embiricos 说计划审查(plan review)变得比以往更重要。Codex 有一个 Plan Mode:Agent 先以只读方式研究代码库,提出一个详细方案,问你是否同意再开始执行。这就像新员工在动手前先给团队提 RFC(Request for Comments,征求意见稿)。
至于代码本身的审查,他说 OpenAI 几乎所有代码在推送到 repo 时都会被 Codex 自动审查。Codex 被专门训练为低误报率的审查者,它给出的批评大多有价值,所以你可以信任它的反馈。他还提到:有人让 Codex 审查其他模型生成的代码,然后意识到“我可能应该直接用 Codex 来写代码”。
【5】开放标准——“除了 Claude,所有家都采用了 agents.md”
用户在不同编码工具间切换很容易,你怎么看粘性?
Embiricos 说他们反而刻意让用户更容易切换。Codex 的核心 harness(运行框架)是开源的。去年 Codex 首发时,他们建立了 agents.md 这个约定,一个任何 Agent 都能读取的配置文件,故意没叫 codex.md。上周他们又推动把 Skills(Agent 的能力扩展脚本)存放在名为 agents/
“所有人都跟进了——除了那个惯犯。”他没点名,但显然在说 Anthropic 的 Claude Code,它使用自己的 CLAUDE.md
【注:agents.md 是一个跨工具的 AI Agent 配置标准。OpenAI 推出了 agents.md(复数),Amp/Sourcegraph 推出了 agent.md(单数),后来 Quinn Slack 在社交媒体上提出统一命名,促成了行业标准化。到 2025 年底已有超过 6 万个开源项目采用,GitHub Copilot 也宣布支持。该标准已由 Linux 基金会旗下的 Agentic AI Foundation 管理。Claude Code 则使用自有的 CLAUDE.md 格式。】
但他也指出,这种容易切换的状态是暂时的。当前的编码任务是“单集式”(episodic)的:你有一个通用的 agents 文件,任何 Agent 都能读;Agent 写代码,产出一个 patch(补丁),进入 git。任务的两端都是厂商中性的。
一旦 Agent 开始对接外部系统,比如跟 Sentry(错误监控服务)对话或操作 Google Docs,粘性就会大幅增加。让企业信任一个 Agent 有权访问这些系统、同时确保有安全的沙箱和控制措施,这是一个不想重复做的决定。
Embiricos 说他们正是基于这个预判来构建 Codex 的。Codex 采用了最保守的沙箱机制,用 OS 级别的控制来限定 Agent 能做什么。
【6】“我们的工作不是 Codex 的成功,而是智能的分发”
怎么确保用户留在 Codex 而不是跑去 Cursor 或 Claude Code?
Harry 用 Hamilton Helmer《七种力量》的框架追问如何建立竞争壁垒。Embiricos 说 OpenAI 的使命是“确保安全地将 AGI 的好处带给全人类”,Codex 团队的工作本质上不是 Codex 的成功,而是 “智能的分发”。
“We put all this effort into training these models and then we serve these models to our competitors.” (我们投入巨大精力训练这些模型,然后把模型提供给我们的竞争对手。)
Harry 直接说:“这对我作为风险投资人来说太难理解了。”
Embiricos 解释说这是长期博弈。竞争对手变好,OpenAI 也能学习。即使竞争对手是闭源的(暗指 Anthropic),也能从竞品的产品设计和创意中获得灵感。他举例说自己当天早上还在推特上转发了 Warp(一款终端工具)的新功能,里面有关于“Agent 同时在云端和本地工作”的好想法。整个行业“都在不可避免地达到相同的结论”。
那 Codex 的真正优势是什么?他列了几个:ChatGPT 的巨大分发优势、自研模型在自家 harness 中的能力优势(没人能提前拿到他们的新模型),以及模型和产品的协同优化。
从公司层面看,最重要的是计算优势和最好的模型,为此需要建商业来产生收入,而且有趣的是,Codex 这种产品团队反过来也在加速模型改进。从产品层面看,最重要的是做出个人用户喜欢的产品。
他也承认了企业侧的教训:不能只是“我们来了,随便用吧”,需要大量教育、配置支持、跟开发者体验负责人对接。
Embiricos 说“非常重要”。他们跟 Cerebras 合作正是为了解决延迟问题。他暗示合作方面很快会有新消息。
【注:2026 年 2 月 12 日,OpenAI 发布了 GPT-5.3-Codex-Spark,这是与 Cerebras 合作的首个成果。Spark 是 GPT-5.3 Codex 的轻量版,运行在 Cerebras 的 Wafer Scale Engine 3 芯片上,推理速度超过 1000 tokens/秒,目标是实现近乎即时的编码交互。】
不过他不认为推理会形成垄断,竞争压力会催生多种方案。GPT-5.3 Codex 本身就比前代模型高效得多。他们还在 API 层面做了优化,模型推理速度快了 40%,Codex 用户端快了 25%。
Harry 转述了 Jason Lemkin(SaaStr 创始人)的一个判断:”AI 算力是新的销售和营销”。这句话的意思是:过去企业花钱雇销售团队、投广告来获客;未来企业花钱买 AI 算力(inference,即运行模型的计算成本),让用户上手就能体验到产品价值,自己就转化了——本质上是 PLG(Product-Led Growth,产品驱动增长)的 AI 版本,销售团队可能不再需要。
Embiricos 不太认同。他说在一个人人都能构建产品的世界里,市场上的选择只会更多,跟客户保持良好关系、真正理解他们需要什么,反而比以前更难了。销售和营销解决的正是这个问题,不会被取代。
主要是周活跃用户(WAU),不是收入。Harry 追问:如果 Codex 真的在替代 IDE,不应该看日活吗?Embiricos 当场认可了这个批评:“你说得对,我们可能应该转向日活。”
他说目标是让用户的第一反应变成 “有任何事都先问 Agent”,就像 Google 搜索对信息的作用、ChatGPT 对知识的作用一样,下一阶段应该是“任何任务都先找 Agent”。
去年首发的云端 Agent 想法很好,给 Agent 自己的云端电脑、可以并行处理多个任务,但“说实话效果不如后来发布的版本”。2025 年 8 月 GPT-5 之后他们转向交互式编码,进入了竞争最激烈的市场,增长了 20 倍。2025 年 12 月 GPT-5.2 Codex 上线成为又一个转折点,“12 月到现在又翻了一倍”。
然后是 2026 年 2 月的集中爆发:GPT-5.3 Codex 巩固了模型智能的领先;Codex App 发布(首周超百万下载)解决了用户体验的短板;超级碗广告做了品牌宣传;向免费用户开放扩大了覆盖。
“Even our biggest critics are converted.” (连我们最大的批评者都转变了。)
他还不忘调侃竞争对手:有个模型比我们早发布了大约 20 分钟——“说这话可能有点毒舌,但它只当了 20 分钟的 SOTA(state of the art,最先进水平)。”
【注:2026 年 2 月 5 日 GPT-5.3 Codex 发布时,Anthropic 几乎同时发布了 Claude Opus 4.6。2 月 8 日超级碗期间,OpenAI 和 Anthropic 各自播出了广告,OpenAI 的口号是“You Can Just Build Things”,Anthropic 则讽刺 OpenAI 在 ChatGPT 中植入广告。两家公司在社交媒体上公开交锋。】
最想做不同的事情有两件。第一,重新回到云端产品。 之前从云端转到本地交互是因为时机不对,如果用户还没熟悉你的工具就直接做工作流自动化,等于搭了空中楼阁。但现在用户基础已经建立起来了,该把云端和本地产品紧密整合了。
第二,投入更多精力解决代码审查和质量控制这类“被低估的瓶颈”。代码生成已经“基本上变得不值一提了”,但怎么知道代码质量好不好、方向对不对,这才是难题。目标是让 Agent 拥有完整的迭代能力,包括收集用户反馈并自行改进,不再需要人类审查。
【8】聊天是万能入口,但需要搭配专业 GUI
聊天会是 AI 的持久界面吗?
Harry 引用了 a16z 合伙人 Anish Akarya 的反对观点:聊天界面是 Sam Altman 和 Elon Musk 这类高效人士设计的产物,但地球上大多数人其实更想要浏览器式的、可以点击发现的图形界面。
Embiricos 的回答是”是,但要分两层看”。他说科幻电影是很好的未来预测器——科幻里的 AI 通常很简单,就是一个你可以随便聊天的实体,不需要切换到”编码 AI”再切换到”销售 AI”。科幻之所以是好预测器,恰恰因为它是讲故事的,而简单的东西通常是对的。
所以第一层是:聊天或语音作为通用入口,你可以跟它聊任何事,也可以把它加到任何群聊里,让它自己发现怎么帮你。
但第二层同样重要:专业用户不想所有事都通过跟另一个”人”对话来完成。他打了个比方——想象你有个行政助理,但你只能通过跟他对话来工作,不能自己看文件、自己编辑。这太烦了,有时候你就是想直接打开文档自己改。
所以未来的模式是:聊天做通用入口,搭配针对特定领域的功能性 GUI。他自己用聊天做播客准备,但看代码还是要打开 Codex App 深入研究。营销人员用聊天问产品问题,但看广告数据要用专门的分析界面——他们不会为了问个产品问题去下载 Codex App。
他还提到一个有意思的发现:在构建 Codex 的过程中,他们发现对 Agent 最好用的界面,往往也是对人类最好用的界面。比如测试框架默认会输出所有测试结果,人类要在成千上万行里找到失败的那一个,很痛苦;AI 也一样痛苦。但如果你只输出失败的测试,对人和 Agent 都更好。这意味着 Agent 和人类之间的交接点可以共用同一套界面设计。
【9】Agent 市场终局——少数通用 Agent 会赢
这个市场最终是双头垄断还是三分天下?
Harry 用投资人的视角问了这个问题:Agent 市场的终局,是像 Uber 和 Lyft 那样两家瓜分(Codex 拿大头),还是像 AWS、Azure、Google Cloud 那样三分天下?
Embiricos 认为最终只有少数提供商会捕获大部分价值。他的逻辑链是这样的:
回看过去一年,去年很多人以为 Agent 会在多个领域找到 PMF(Product Market Fit,产品市场契合),但实际上只有编码 Agent 真正跑通了,客户支持等其他领域还很初期。不过这是暂时的,未来 Agent 能做任何事。
到了那个时候,你不会想在公司里配 12 个 Agent,让员工自己去找对的那个——因为他们不会对任何一个达到”熟练”状态。不熟练就不会主动把自动化拉入自己的工作流。 但如果只有一个 Agent,入职培训就是”有任何问题找它”,人们会形成肌肉记忆,它会成为工作的重心。团队之间会分享使用技巧、办黑客马拉松来探索新用法,整个组织围绕它运转。
这跟他在 Dropbox 看到的一模一样。Slack 崛起之前,Dropbox 的文档协作功能其实更高效——你可以在视频的精确时间戳上留言,在文档的特定段落上标注。但人们就是涌向 Slack。没人想去文档上写评论,大家只想在 Slack 里直接 @ 你。效率更低,但引力效应更强。 Agent 市场会重演同样的故事。
他认为 ChatGPT 做这件事有天然优势,它已经是很多人的通用 AI 入口。
【10】数据护城河在哪里:编程数据够了,知识工作数据才稀缺
编程数据护城河在谁手里?Anthropic 是不是已经拿到所有数据了?
这个问题来自 Harry 在 LinkedIn 上征集的读者提问。Harry 用”伏地魔”来形容提问者所在的公司——“'那个不能说名字的公司'的一位优秀投资人”,然后补了一句”我不想让 Sam 杀了我”。大概率是 Anthropic 的投资人在问:你们的编码数据护城河到底在不在?
Embiricos 的回答很直接:编程数据已经够了。他们”有足够多的数据来构建非常好的编码模型”,这不是瓶颈。
真正有意思的数据缺口在知识工作领域。为什么?
因为编码有一个天然的数据宝库,GitHub 上海量的开源代码,代码怎么写、怎么改、怎么审查,全都有迹可循。但知识工作完全不同:没有人把自己怎么处理一封邮件、怎么准备一场会议、怎么做一个决策的完整过程记录下来放到网上。这类数据在互联网上几乎不存在,而且知识工作任务的分布比编码复杂得多,编码任务相对标准化,但知识工作千人千面。
获取这类数据的路径需要创新。Embiricos 提了两个思路: 一是付钱请人模拟做任务,记录完整的操作轨迹作为训练数据; 二是收购一些不再运营但积累了大量工作流数据的创业公司,他举的例子是”比如某个 Slack 类的产品”,这些产品里存着大量真实的团队协作、决策沟通的记录。
Harry 问到跟外部数据公司(Turing、Invisible 等)的合作会不会加大投入。Embiricos 说他们追求的是尽快推进,自建数据采集团队对小团队来说太耗时间,大规模数据采集通常会找外部公司合作。
【11】SaaS 不会死,但"中间商"公司有麻烦
有人说大型 SaaS 公司的收入可持续性为零,SaaS 已死。你怎么看?
Embiricos 说关键问题是:这家 SaaS 公司到底拥有什么?
第一,它是否拥有跟人类的关系——用户离不开它,是因为习惯了跟它打交道。
第二,它是否拥有重要的记录系统(system of record)——企业的核心数据存在它那里。
如果占了其中一样,它可能不会消亡,甚至这两样东西在 AI 时代比以往更重要。
但如果一家 SaaS 公司只是个 "glue layer"(胶水层),夹在用户和数据之间做连接和搬运,既不拥有客户关系也不拥有核心数据,那就比较危险了。这类公司本质上是"中间商",而 AI Agent 天然擅长的就是打通系统、搬运数据,正好替代它们的核心功能。
Harry 做了更具体的推演:Sale
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み