Pinecone Nexus が一般公開プレビューを開始
ベクトルデータベースの Pinecone が、新機能「Nexus」の一般公開プレビューを開始し、開発者が同プラットフォーム上で新たな機能を試せるようになった。
キーポイント
新機能 Nexus の一般公開開始
ベクトルデータベース大手の Pinecone が、開発者向けに新機能「Nexus」のプレビュー版を正式にリリースした。
開発者による早期検証の実現
今回の公開により、開発者は Pinecone のプラットフォーム上で Nexus の機能を直接試し、フィードバックを提供できるようになった。
ベクトル検索技術の進化
Pinecone による新機能の投入は、AI アプリケーションにおけるベクトルデータベースのパフォーマンスや機能性をさらに高める動きを示している。
影響分析・編集コメントを表示
影響分析
この発表は、ベクトルデータベース市場における競争激化と技術革新の加速を象徴しており、特に RAG(検索拡張生成)や大規模言語モデル(LLM)アプリケーションの開発現場において、より高度なデータ処理機能への期待を高めています。ただし、詳細な仕様や具体的な技術的優位性についてはプレビュー段階であるため、正式版リリース後の実装内容が今後の業界動向を左右する鍵となります。
編集コメント
プレスリリース色が強い内容ですが、ベクトル検索技術の進化という観点からは開発者にとって実用的な情報です。詳細な機能仕様は正式版を待つ必要があります。
7 週間前、私たちは AI エージェントに知識を提供するために Pinecone Nexus の早期アクセスを発表しました。以来、膨大なデータ、高い複雑さ、そして厳格な精度・レイテンシ・コスト要件を満たす広範なユーザー層とパートナーシップを築いてきました。本日、私たちはパブリックプレビューを開始します。
分散型企業知識を、エージェントが信頼できる形に統合しました。
最先端モデルを中心に構築されたエージェントは、世界に関する知識、複雑な推論、そして学問分野を超えた情報の合成において卓越しています。ファイルの奥深くに埋もれた特定の情報を見つけることは検索問題であり、ベクトルデータベース(vector databases)はこの問題を数年にわたり解決し続けてきました。
しかし、それらいずれにも触れられない第三の知識があります。それがビジネスコンテキストです。入社 3 年目の社員が検索せずに知っていること、現在の実際の業務プロセスを反映する内部プロセス文書、四半期目標の実践的な意味合い、ある部門の方針が他部門の意思決定とどのように結びついているかといったものです。これは契約書、ウィキ、人事文書、会議議事録、サポートチケット、財務記録など、企業内に分散して存在しています。その多くはどこかに記述されており、しばしば何度も書き込まれていますが、「記述されていること」と「統合されたもの」は同じではありません。タスクに取り組むエージェントには後者が必要です。
エージェントがタスクを開始するたびに、これらすべてについてゼロから始めなければなりません。即座に情報を組み立てることは可能ですが、そのコストはトークン数、時間、そして半ば正しい回答という形で現れます。
Pinecone Nexus は、そのギャップを埋める知識エンジンです。企業の分散した知識を集約し、エージェントが直接照会できる構造化レイヤーへと変換することで、トークン使用量をクエリごとの検索ループから、一度きりのキュレーションステップへとシフトさせます。
本日、ビジネスユースケースを持つすべての人に向けて公開します。Pinecone Nexus は現在、Public Preview(一般公開プレビュー)を開始しました。
準備完了
*本日より、Pinecone Nexus のアクセスをリクエストし、コスト、速度、精度という重要な次元において、キュレーションされた知識がエージェントワークロードにどのような効果をもたらすかをご覧ください。
Nexus は、ドキュメント間で推論を行う必要がある限定されたコーパス向けに設計されています。単一の質問で数十件のファイルにまたがるような、標準的な検索手法では機能しなくなりがちなコーパスにおいて、その真価を発揮します。
利用方法は以下の 2 つです:
Preview Playground: 今日アクセスをリクエストして、データを接続し、Context(文脈)を設計し、実際のクエリを実行できるライブ環境を取得できます。これは、本格的な導入を行う前に、実データを用いてアプローチの有効性を検証するのに十分なものです。
BYOC Deployment: 本番ワークロード向けには、専用デプロイメントのリクエストが可能です。クラスターはお客様の VPC(仮想プライベートクラウド)内で実行され、共有インフラは使用しません。Pinecone はお客様のデータにアクセスできず、ドキュメントもお客様のインフラから外部へ流出することはありません。また、他のテナントとの計算リソースの共有もありません。このデプロイモデルに意図的に注力しているのは、データの所在地、セキュリティ、コンプライアンスが妥協できない企業ニーズに合致させるためです。
See Nexus in Action
The demo above uses a synthetic financial services corpus of a household's complete set of financial records including their goals, plans, meeting notes, and portfolio documents. It’s the kind of corpus where a question like, "*How are the Chens tracking against their retirement goals?*" touches dozens of documents across multiple years, and unlike Nexus, a standard retrieval system would return chunks instead of fully-formed answers.
The Knowledge Engine, Explained
The results enterprises in Early Access are seeing aren’t a product of better prompting or a smarter model. They come from a different approach to how knowledge is organized before any query arrives. (See our previous blog, Nexus in the Wild: Real Results from Our Early Access Customers)
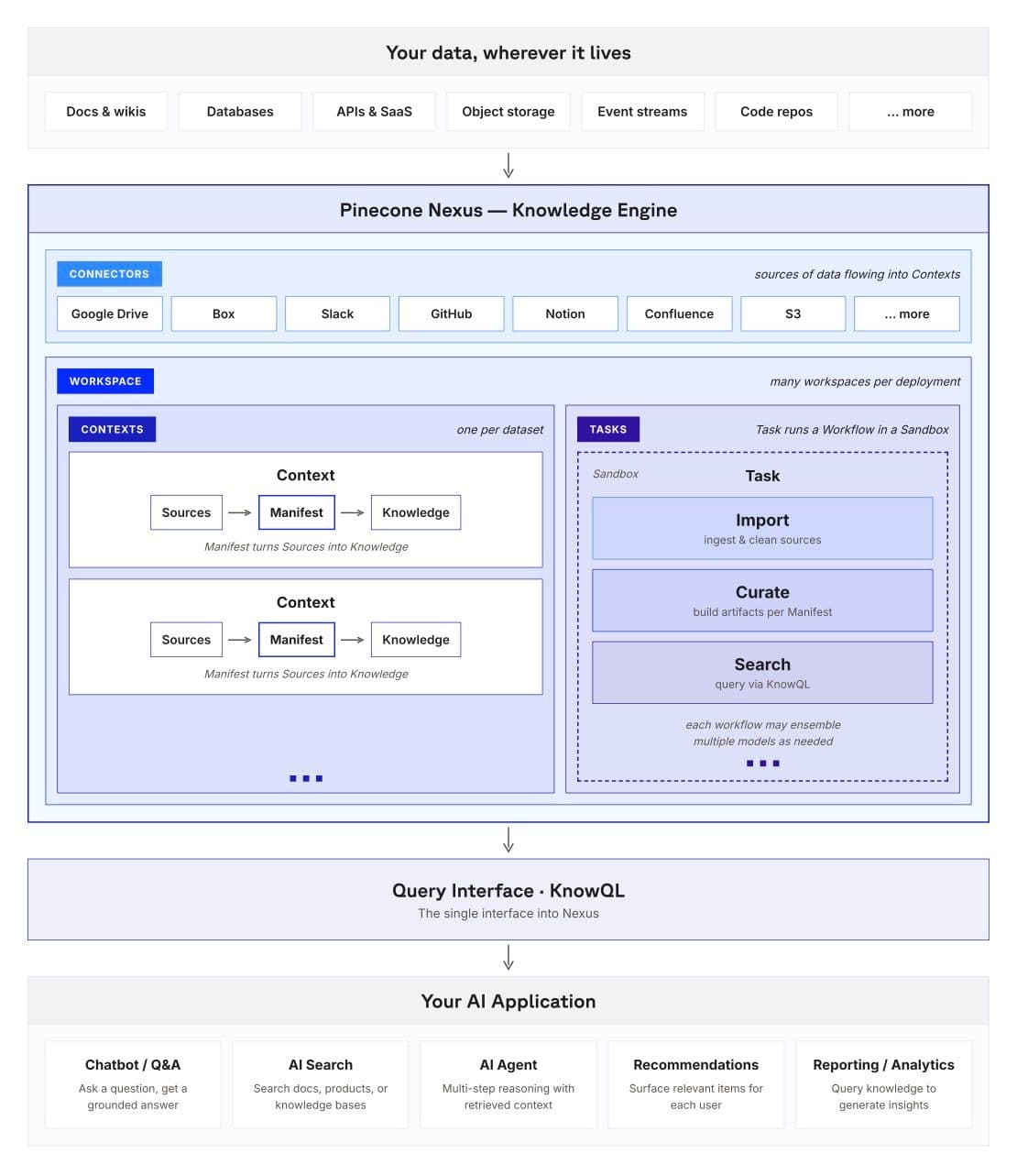
Connectors handle ingestion: Local file upload, Box, and Microsoft OneLake are live today, with Google Drive, Slack, GitHub, Notion, Confluence, and S3 close behind.
ワークスペースは最上位のコンテナであり、チームや事業部門を囲む境界線です。コネクタやその他の共有リソースはワークスペースレベルで管理されるため、自然な思考モデルは「各データソースとアクセス制御を独自に持つチームごとに 1 つのワークスペース」というものです:サポート組織、法務チーム、データサイエンスグループなどが該当します。
ワークスペース内では、データはコンテキストとして整理されます。これはデータセットまたは知識ドメインごとに 1 つずつです。ソースは Nexus のキュレーション層を流れ、マニフェストによって導かれます。マニフェストは生文書をそのドメインに最適化された構造化された知識アーティファクトに変換する指針であり、コーパスがどのように理解されるべきかの設計図となります。
タスクは、隔離されたサンドボックス内で実際の作業を実行します:*import*(インポート)でソースの取り込みとクリーニングを行い、*curate*(キュレーション)でマニフェストに基づいてアーティファクトを構築し、*search*(検索)で KnowQL を通じてクエリを実行します。各ワークフローではアンサンブルモデルを採用でき、各ステップに最適なモデルが選択されます。これらすべては単一のインターフェースを通じて可視化されます:それが Nexus への問い合わせインターフェースであるKnowQLです。エージェント、チャットボット、AI 検索アプリケーション、推薦システムは、すべてこの一貫した表面を通じて同じ知識レイヤーにアクセスします。
ループ内の SMEs
何を問うべきか、またどのような知識構造がそれに応えるかを理解しているのは、通常パイプラインを構築するエンジニアではありません。特許基準の整理方法を熟知した特許弁護士です。健全なデューデリジェンス回答のためにどの文書カテゴリを相互参照すべきかを知る M&A アナリストです。Gong のトランスクリプト内のどのシグナルが実際には顧客離れ(チャーン)を予測するかを知っている収益責任者です。
Manifest は、その専門家をプロセスに組み込むための手段です。ドメイン知識をキュレーション層にエンコードするアーティファクトの種類と関係性を定義するブループリントを、専門家がクエリ実行前に設計できます。エージェントはクエリ時にコパスの構造を自ら見つける必要はありません。SME(専門分野の専門家)によるその理解を引き継ぐのです。
これはプロンプトエンジニアリングとは異なるモデルです。クエリ時にコーチングされるのではなく、実際にドメインを理解している誰かが設計した知識層が手渡されます。最も関連性の高いチャンクを取得するエージェントと、その構造を理解した誰かによって既に構造化されたコパス上で推論を行うエージェントとの違いです。答えは精密かつ高速に導き出され、推論の方向性は最初から正しい方向へ向けられます。
知識は静的なものではありません。規制は変化し、製品は進化し、6 ヶ月前には正確だったコーパスに「ナレッジドリフト」と呼ばれる現象が生じます。Nexus は中小企業(SME)が再キュレーションを行えるようにします。新しい要件を反映するためにマニフェストを更新し、知識層を再構築して出荷するだけです。ドメインを理解している担当者が知識層の制御権を握り続けるため、エージェントは常に最新の状態を保ちます。
More Benchmarks
Early Access 開始以来、ベンチマークの実施を続けています。業界もコーパスの形状も異なりますが、問いは同じです。「ナレッジ問題がより困難または複雑になった場合でも、マニフェスト駆動型キュレーションモデルは機能し続けるのか?」そのうち 3 つの結果を以下に示します。
Q2: Support Knowledge Base for Financial Services
Domain: Digital Banking / Financial Technology
Q2 は金融機関向けにデジタルインフラストラクチャを構築しています。彼らのサポートチームは、標準的なトリアージの一環として数千件の技術知識ベース記事を検索し、クライアントから問題が発生するたびにそれらを確認します。
記事自体を見つけることは容易です。しかし、実際のサポート質問の多くには、複数の記事にまたがる回答が存在するため、金融機関に対する誤った回答は重大なリスクを伴います。そのため、精度が最終的な判断基準となります。
Q2 はこのベンチマークを自社で実施しました。プレビュー環境への早期アクセスを取得し、ソースデータをインジェストし、事前構築されたテンプレートからマニフェストを設計し、アーティファクトをキュレーションして、Pinecone チームの介入なしに評価を実行しました。
コーパス: Q2 の内部技術サポートナレッジベースのサンプルで、同社のサポートチームが日常的に扱う質問の範囲を網羅しています。
評価セット: 単一記事参照、2 記事間の推論、複数記事の統合、ペルソナに基づくサポートシナリオ、顧客事例の 6 つのカテゴリにわたる 20 の質問。Q2 のサポートチームが日常的に直面する実際の質問タイプを模倣するように設計されています。
結果:
メトリック 結果
F1 スコア 95%
平均再現率 (1–5) 4.70
平均適合率 (1–5) 4.70
Q2 にとって、精度はすべてであり、最も難しい質問で 95% を達成したことが決定的な要因となりました。Q2 のチーフデータサイエンティストであるジェシー・バーバー氏はこれを最もよく表現しています。
Q2 の引用
「ベクトルデータベースを簡単に構築し、ドキュメントコーパス上で RAG(およびエージェント検索)を実行することは容易です。難しいのは、本当に困難な質問に対して、エージェントが信頼性が高く効率的に適切な知識を組み立てることにあります。当社の評価では、Pinecone Nexus は複雑なサポートおよびコンプライアンスの質問セットに対し 95% の精度で回答しました。さらに、トークンコストを押し上げることなく抑制しながらこれを実現できる能力は、同製品をより魅力的なものにしています。」 — ジェシー・バーバー氏、Q2 チーフデータサイエンティスト
EU 判例法における網羅性と信頼性を重視する法律研究 AI 企業
ドメイン: 法律研究 / LegalTech
このベンチマークは、法的調査向け AI ツールを構築する企業によって実行され、Nexus が自社の製品の中心となるタスクである EU の判例法および法令に関する実質的な法的質問に答える能力を検証しました。Nexus は、エージェント型 RAG ベースラインとコーディングエージェントと比較されましたが、すべての回答を生成するモデルは同一です。変更されたのは検索アーキテクチャのみであり、結果の差異はすべてこれに起因します。
質問内容は、実際の法的調査者が抱く多様な問いを網羅しています:特定の条項が何を要求しているかの確認、ある法理が判例においてどのように適用されてきたかの追跡、特定トピックに関する関連する先例のすべてを集約すること、そして複数の法体系にまたがる推論です。これらのタスクは、市町村の記録やサポートチケットが標準的な検索では困難であるのと同じ理由で難易度が高いのです。なぜなら、回答は単一の文書の中に存在することは稀だからです。
コーパス: CJEU(欧州連合裁判所)および一般裁判所の判例法 30,000 ドキュメント(約 1.1 GB)と EU 法令から構成され、2021 年から 2026 年までの期間をカバーしています。
評価セット: 8 つのカテゴリーにわたる 35 の法的調査質問。これには条項の検索、法理の統合、判例間および法体系間の推論、網羅性と列挙に関する質問、先例チェーン、そしてコーパス外のネガティブコントロールが含まれます。
結果:
Metric Nexus Agentic RAG Coding Agent
Completion rate 100% 66% 6%
Accuracy 87% 45% 4%
Avg Tokens per query 9k 80k (~9x) 135k (~15x)
完了率のギャップが物語の大半を語っています。コーディングエージェントは 35 問中わずか 2 問しか完了できず、ファイルの一覧表示と読み込みによって 30,000 ドキュメントを検索するアプローチは、この規模のコーパスにはスケーラブルではありません。RAG ベースラインはそれよりマシでしたが、ドクトリンの合成、ケース間推論、およびカバレッジに関する質問において崩壊しました。これらは複数のソースを 1 つの回答に統合する必要のある形状の問題です。そのうち 12 問については、回答を構成することさえできませんでした。Nexus はセット内のすべての質問に完了し、両方のシステムが回答した質問においても、より正確でした。
米国証券法に関する制御質問(EU 法のみを含むコーパスに対して出題)において、Nexus はその質問が範囲外であることを認識してそう答えました。他の 2 つのシステムは捏造された回答を生成しました。
主要なデータ保護およびセキュリティベンダー:市町村記録にわたるドキュメント間推論
ドメイン: エンタープライズデータ管理
このベンチマークは、データ保護およびセキュリティベンダーと共同で実施され、Nexus をテストしました。対象となったコーパスの文書自体は技術的に複雑ではありませんが、構造化されており、ほぼすべての質問に単一の文書から回答することはできません。このコーパスには、主要都市の 13 の統治機関にわたる 2022 年から 2025 年までの市政会議議事録 598 文書が含まれています。評価セット内のほとんどすべての質問は、単一の文書からは回答できません。議員の出席回数を数えるには、約 40 の文書にわたる推論が必要です。プロジェクトの場所を特定するには、議題項目をその区画番号、申請者、所有者と結合する必要があります。動議の完全な投票結果を確認するには、物語的な段落から構造化された名簿を抽出する必要があります。
これらはまさに、標準的な検索(Retrieval)の問題を露呈させるクエリです。コーパスをチャンク化し、埋め込みを行っても、「2022 年から 2025 年の間にスミス市長が市政会議の議長を務めた回数は何回か?」という質問に回答するには、エージェントが部分的な回答を組み立てるために数十回ループバックせざるを得ません。
コーパス: 1 文書あたり 1 回の会議に対応する 598 文書。13 の統治機関。4 年分のデータ。繰り返し構造を持つ複数セッションの会議。
評価セット: 出席数、動議の投票結果、役員履歴、プロジェクト場所、期限など 13 カテゴリにわたる 100 の質問。すべて設計上、文書間を跨ぐものとなっています。
マニフェスト: 12 種類のアーティファクトタイプ。会議出席、動議ログ、期限ログ、プロジェクト場所に対応する SQLite ベースの専用テーブルを含む。
結果:
Metric 結果
Accuracy 90% vs (RAG Baseline: 65%)
Curation cost (one-time, 598 documents) $0.0038 per doc
Query cost $0.0069 per question
598 ドキュメントを 12 の構造化アーティファクトタイプにキュレーションするには、コストは 2.31 ドルで所要時間は 34 分でした。その後のすべてのクエリは、このキュレーション済みインデックスに対して実行され、平均コストは低く抑えられ、トークンを蓄積するクエリごとの検索ループはありません。知識は一度だけコンパイルされます。
主要なデータ保護およびセキュリティベンダーである企業、デジタルバンキングインフラストラクチャプロバイダー、そして法務研究 AI 企業が共通点を持つことは多くありません。一つのユースケースは、何年にもわたる政府会議の議事録にわたる推論であり、もう一つは銀行向けの技術サポート質問への回答、三つ目は数万件の判例文書にわたる法務調査です。しかし、これら 3 つはいずれも標準的な検索において同じ壁にぶつかり、彼らのコーパス向けに構築された知識レイヤーへ切り替えた際にも同じ結果が見られました:精度が向上し、コストが低下し、完了率が上昇し、以前は複数の検索ループを必要としていた質問が単一の回答で済むようになったのです。
この転換は、知識をその場で再構成するのではなく、事前にコンパイルすることにあります。クエリが届く前に知識レイヤーが構造化されていれば、エージェントは毎回生データからの検索から理解を再構築するのではなく、コーパスの形状をすでに知っているレイヤーから読み込むことになります。
構築を開始する
エージェントのセットアップがコーパスに対して頭打ちになり、精度が向上せず、トークンコストがビジネスケースを成立させるに至らず、レイテンシが生きたワークフローに適合しない場合…その問題はほぼ常にモデルではなく、知識層にあります。
Pinecone Nexus はこれらの問題を解決します。そして本番環境への移行の準備ができたら、BYOC デプロイメントにより、データはあなたのインフラから決して離れることはありません。共有環境も、データの所在地に関する懸念も、セキュリティにおける妥協もありません。あなたのクラスター、あなたの VPC が完全に隔離されます。
Nexus パブリックプレビューで始める
エージェントをより正確に、より高速に、より低コストに
原文を表示
Seven weeks ago, we announced early access to Pinecone Nexus, to deliver knowledge to AI agents. We’ve since partnered with a broad cohort of users spanning massive data, high complexity, and stringent accuracy, latency and cost requirements. Today, we are opening up public preview.
Distributed enterprise knowledge, compiled into something agents can rely on.
Agents built around frontier models are great at world knowledge, complex reasoning, and synthesizing information across disciplines. Finding specific information buried across files is a search problem, one vector databases have been chipping away at for years.
There's a third kind of knowledge that neither of those touches: business context. It's what a three-year employee knows without searching; which internal process doc reflects how things actually work today, what the quarterly goals mean in practice, how a policy in one department connects to a decision in another. It lives distributed across your enterprise in contracts, wikis, HR docs, meeting notes, support tickets, and financial records. Most of it has been written down somewhere, often many times over, but written down isn't the same as compiled, and an agent walking into a task needs the latter.
Every time an agent starts a task, it starts from zero on all of this. It can piece things together on the fly, but the cost shows up in tokens, in time, and in answers that are half right.
Pinecone Nexus is a knowledge engine that closes that gap. It compiles an enterprise's distributed knowledge into a structured layer agents can query directly, shifting token spend out of the per-query retrieval loop and into a one-time curation step.
Today, we're opening it up to anyone with a business use case. Pinecone Nexus is now in Public Preview.
What's Ready
*Starting today, request access to Pinecone Nexus and see what curated knowledge does for agentic workloads on the dimensions that matter: cost, speed, and accuracy.*
Nexus is built for bounded corpora where agents need to reason across documents. It's at its best on the kind of corpus where a single question touches dozens of files and standard retrieval starts falling apart.
There are two ways in:
Preview Playground: request access today and get a live environment to connect your data, design a Context, and run real queries. It's enough to validate the approach on something real before committing to a deployment.
BYOC Deployment: for production workloads, request a dedicated deployment. The cluster runs in your VPC with no shared infrastructure. Pinecone never has access to your data, your documents don't leave your infrastructure, and there's no shared compute with other tenants. Our deliberate focus on this deployment model is to align with the needs of enterprises where data residency, security, and compliance are non-negotiable.
See Nexus in Action
The demo above uses a synthetic financial services corpus of a household's complete set of financial records including their goals, plans, meeting notes, and portfolio documents. It’s the kind of corpus where a question like, *"How are the Chens tracking against their retirement goals?"* touches dozens of documents across multiple years, and unlike Nexus, a standard retrieval system would return chunks instead of fully-formed answers.
The Knowledge Engine, Explained
The results enterprises in Early Access are seeing aren’t a product of better prompting or a smarter model. They come from a different approach to how knowledge is organized before any query arrives. (See our previous blog, Nexus in the Wild: Real Results from Our Early Access Customers)
Connectors handle ingestion: Local file upload, Box, and Microsoft OneLake are live today, with Google Drive, Slack, GitHub, Notion, Confluence, and S3 close behind.
A Workspace is the top-level container: the boundary around a team or business unit. Connectors and other shared resources live at the Workspace level, so the natural mental model is one Workspace per team that owns its own data sources and access controls: a support org, a legal team, a data science group.
Inside a Workspace, your data is organized into Contexts: one per dataset or knowledge domain. Sources flow through Nexus's curation layer, guided by a Manifest that turns raw documents into structured knowledge artifacts tuned to the domain. The Manifest is the blueprint for how the corpus should be understood.
Tasks run the actual work inside isolated Sandboxes: *import* to ingest and clean sources, *curate* to build artifacts per the Manifest, and *search* to query via KnowQL. Each workflow can employ an ensemble of models, with the right model picked for each step. Everything surfaces through a single interface: KnowQL, the Query Interface into Nexus. Agents, chatbots, AI search applications, recommendation systems all tap into the same knowledge layer through one consistent surface.
SMEs in the loop
The people who know what questions matter, and what knowledge structure would answer them, usually aren't the engineers building the pipeline.They're the patent attorney who knows how patent standards are organized. The M&A analyst who knows which document categories need to be cross-referenced for a clean diligence answer. The revenue leader who knows which signals in a Gong transcript actually predict churn.
The Manifest is how we bring that person into the loop. A subject matter expert can design a blueprint defining the artifact types and relationships that encode their domain knowledge into the curation layer before any query runs. The agent isn't left to figure out the structure of the corpus at query time. It inherits the SME's understanding of it.
This is a different model than prompt engineering. The model isn't being coached at query time, it's being handed a knowledge layer that was designed by someone who actually knows the domain. The difference is between an agent that retrieves the most relevant chunk and one that reasons over a corpus already structured by someone who understood it. The answer comes out precise and fast, with the reasoning pointed in the right direction from the start.
Knowledge doesn't stay static. Regulations change, products evolve, and a corpus that was accurate six months ago develops what we call knowledge drift. Nexus lets SMEs re-curate: update the Manifest to reflect new requirements, rebuild the knowledge layer, ship. The agent stays current because the person who understands the domain stays in control of the knowledge layer.
More Benchmarks
Since opening Early Access, we've kept benchmarking. Different industries, different corpus shapes, same question: does the Manifest-driven curation model hold up when the knowledge problem gets harder or stranger? Three of those benchmarks are below.
Q2: Support Knowledge Base for Financial Services
Domain: Digital Banking / Financial Technology
Q2 builds digital infrastructure for financial institutions. Their support team works through thousands of technical knowledge base articles as part of standard triage, searching them every time a client calls in with an issue.
The articles themselves are easy to find. Most real support questions, though, have answers that live across several of them, and a wrong answer to a financial institution carries real downside, so accuracy ends up being the deciding criterion.
Q2 ran this benchmark themselves. They got early access to the preview environment, ingested their sources, designed a Manifest from a pre-built template, curated the artifacts, and ran the evaluation without Pinecone team in the loop.
Corpus: A sample of Q2's internal technical support knowledge base, covering the breadth of questions their support team handles daily.
Eval set: 20 questions across 6 categories: single-article lookups, two-article reasoning, multi-article synthesis, persona-based support scenarios, and customer cases. Designed to mirror the real question types Q2's support teams face daily.
Results:
Metric Result
F1 Score 95%
Avg Recall (1–5) 4.70
Avg Precision (1–5) 4.70
For Q2, accuracy was everything, and 95% on their hardest questions was the number that made the case. Jesse Barbour, Chief Data Scientist at Q2, put it best:
Q2 Quote
"We can easily stand up a vector database and run RAG (and agentic search) over our documentation corpus. The hard part is getting an agent to reliably and efficiently assemble the right knowledge for genuinely difficult questions. In our own evaluations, Pinecone Nexus answered a set of complex support and compliance questions with 95% accuracy. And the fact that it has the ability to do it while keeping token costs down, not driving them up, makes it even more compelling." — Jesse Barbour, Chief Data Scientist, Q2
A Legal Research AI Company: Coverage and Reliability Over EU Case Law
Domain: Legal Research / LegalTech
This benchmark, run with a company building AI tools for legal research, tested Nexus on the task at the center of their product: answering substantive legal questions over EU case law and legislation. Nexus ran against an agentic-RAG baseline and a coding agent, with the same model composing every answer. Only the retrieval architecture changed, so any difference in the results is attributable to it.
The questions span the shapes a real legal researcher asks: looking up what a specific provision requires, tracing how a doctrine has been applied across cases, assembling every relevant precedent on a topic, and reasoning across multiple regimes at once. These are hard for standard retrieval for the same reason municipal records and support tickets are: the answer is rarely sitting in one document.
Corpus: 30,000 documents (~1.1 GB) of CJEU and General Court case law plus EU legislation, spanning 2021–2026.
Eval set: 35 legal research questions across 8 categories, including provision lookups, doctrine synthesis, cross-case and cross-regime reasoning, coverage and enumeration questions, precedent chains, and out-of-corpus negative controls.
Results:
Metric Nexus Agentic RAG Coding Agent
Completion rate 100% 66% 6%
Accuracy 87% 45% 4%
Avg Tokens per query 9k 80k (~9x) 135k (~15x)
The completion gap tells most of the story. The coding agent completed just 2 of 35 questions, browsing 30,000 documents by listing and reading files doesn't scale to a corpus this size. The RAG baseline did better but fell apart on doctrine synthesis, cross-case reasoning, and coverage questions, the shapes that require many sources assembled into one answer. On 12 of those, it never made it to composing a response at all. Nexus completed every question in the set, and even on the ones both systems answered, it was more accurate.
On a control question about U.S. securities law, asked of a corpus that contains only EU law, Nexus recognized the question was out of scope and said so. The other two systems fabricated answers.
A Leading Data Protection and Security Vendor: Cross-Document Reasoning Over Municipal Records
Domain: Enterprise Data Management
This benchmark, run with a data protection and security vendor, tested Nexus on a corpus where the documents themselves aren't technically complex, but they're structured so that almost no question can be answered from a single one of them.The corpus is 598 documents of municipal meeting minutes from a major city, spanning 2022–2025 across 13 governing bodies. Almost no question in the eval set can be answered from a single document. Counting a council member's attendance requires reasoning across roughly 40 documents. Resolving a project location requires joining an agenda item to its parcel number, applicant, and owner. Reading a motion's full vote requires extracting a structured roster from a narrative paragraph.
These are exactly the queries that expose the problem with standard retrieval. Chunk the corpus, embed it, and there's no way to answer "How many times did Mayor Smith preside over a city council meeting between 2022 and 2025?" without the agent looping back dozens of times to reassemble partial answers.
Corpus: 598 documents, one per meeting. 13 governing bodies. 4 years of data. Multi-session meetings with repeated structures.
Eval set: 100 questions across 13 categories including attendance counts, motion votes, officer history, project locations, deadlines. All cross-document by design.
The Manifest: 12 artifact types, including dedicated SQLite-backed tables for Meeting Attendance, Motion Log, Deadline Log, and Project Location.
Results:
Metric Result
Accuracy 90% vs (RAG Baseline: 65%)
Curation cost (one-time, 598 documents) $0.0038 per doc
Query cost $0.0069 per question
Curating 598 documents into 12 structured artifact types cost $2.31 and took 34 minutes. Every subsequent query runs against that curated index at a low average cost, with no per-query retrieval loop accumulating tokens. The knowledge gets compiled once.
A leading data protection and security vendor, a digital banking infrastructure provider, and a legal research AI company don't have much in common. One use case is reasoning across years of government meeting minutes, another is answering technical support questions for banks, and the third is legal research across tens of thousands of case law documents. But all three hit the same wall with standard retrieval, and all three saw the same thing when they switched to a knowledge layer built for their corpus: accuracy went up, costs came down, completion rates climbed, and questions that used to require multiple retrieval loops just got answered.
The shift is to compile knowledge upfront instead of reassembling it on the fly. When the knowledge layer is structured before a query arrives, the agent reads from a layer that already knows the shape of the corpus, rather than rebuilding that understanding from raw retrieval every time it gets asked something.
Start Building
If your agent setup has hit its ceiling on your corpus, has accuracy that won't improve, token costs that won't close a business case, latency that doesn't fit a live workflow… the issue is almost always in the knowledge layer, not the model.
Pinecone Nexus solves those problems. And when you're ready to go to production, BYOC deployment means your data never leaves your infrastructure. No shared environment, no data residency concerns, no compromises on security. Your cluster, your VPC, is fully isolated.
Get started with the Nexus Public Preview
Make your agents more accurate, faster, and cheaper
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み