NVIDIA Blackwell が初のエージェント型 AI インフラベンチマークで首位に立つ(4 分読)
NVIDIA は、Blackwell アーキテクチャが最初のエージェント型 AI インフラベンチマークにおいて他社製品を上回る性能を示したと発表した。
キーポイント
初のアージェント型 AI ベンチマークでの首位獲得
NVIDIA は、Blackwell アーキテクチャが業界初のエージェント型 AI インフラベンチメントで競合他社を圧倒する性能を発揮したと発表した。
次世代アーキテクチャの優位性確認
Blackwell の設計により、複雑なエージェントワークロードにおいて従来のアーキテクチャよりも高い効率性とスループットが実現されていることが裏付けられた。
市場における競争力の強化
このベンチマーク結果は、NVIDIA が次世代 AI インフラの標準を支配し続ける上で決定的な優位性を示すものである。
影響分析・編集コメントを表示
影響分析
このニュースは、NVIDIA が単なるハードウェアの性能競争だけでなく、次世代 AI アプリケーションである「エージェント型 AI」への対応において明確なリーダーシップを確立したことを示しています。企業や開発者が AI エージェントの導入を検討する際、Blackwell アーキテクチャが事実上の推奨プラットフォームとなる可能性が高く、市場の集中化を加速させる要因となります。
編集コメント
「エージェント型 AI」という新しいワークロードに対するベンチメントが発表された点は、単なるハードウェア比較を超えた重要な指標です。Blackwell の優位性が実証されることで、AI エージェントの実用化におけるインフラ選定基準が明確になりつつあります。
Artificial Analysis が提供する AgentPerf は、業界初のアジェンティック AI ベンチマークであり、開発者、企業、インフラプロバイダーに対して、アジェンティック AI 向けのシステムを比較するための明確な手段を提供します。公開された最初のラウンドの結果において、NVIDIA Blackwell Ultra NVL72 プラットフォームは、テストされたアジェンティック AI ワークロード全体で首位の性能を示し、1 メガワットあたりの実行可能エージェント数が NVIDIA Hopper の 20 倍となりました。
アジェンティック AI は、対話型 AI とは根本的に異なるワークロードです。単一のチャット完了は短距離走のようなものであり、1 つの大規模言語モデル(LLM)呼び出しと 1 つの応答で構成されます。一方、エージェントはリレー競技のように機能し、目標を多数のステップに分解し、タスクが完了するまで継続して動作します。
 image エージェントは、コンテキストの収集、観察、推論、そして行動のために、複数の LLM 呼び出しとツール呼び出しを連鎖させます。
image エージェントは、コンテキストの収集、観察、推論、そして行動のために、複数の LLM 呼び出しとツール呼び出しを連鎖させます。
その結果、数十から数百に及ぶ LLM 呼び出しが連鎖し、それぞれが次のステップへと成長するコンテキストを引き継ぎます。各引き渡し箇所では、コードのコンパイルや実行、データベース検索、ウェブブラウジングといったツール呼び出しが行われます。この複雑さは単に加算されるものではなく、乗算的に増大します。
性能測定においてこの区別は極めて重要です。既存の AI 推論ベンチマークは 1 つの LLM(大規模言語モデル)呼び出しのみを計測します:LLM が単一の要求に対してどれほど速く応答するか、そしてシステムが同時に処理できるリクエスト数がどの程度かです。これらはアジェンティックなワークロードのために設計されたものではありません。そこでは連鎖する LLM 呼び出し、ツール呼び出しの遅延、および増大するコンテキスト負荷が、単一の LLM 呼び出しでは決して起こり得ない根本的に異なる方法で計算システムを逼迫させます。
大規模にエージェントを構築・展開する企業にとって、エージェントの応答性、同時に展開可能な数、そして投資されたドルとワットあたり AI インフラストラクチャがどれだけの有用な作業を提供できるかを理解することが重要です。
NVIDIA GB300 NVL72 はメガワットあたり 20 倍のエージェントを実行
この最初のラウンドにおいて、AgentPerf は DeepSeek V4 Pro を用いてアジェンティックな性能を測定します。これはフロンティアモデルのクラスを表す大規模混合専門家(MoE)モデルであり、今日最も能力の高いエージェントを支えるモデル群です。このワークロードにおいて、NVIDIA GB300 NVL72 はベンチマークで最高性能を示し、NVIDIA HGX H200 システムと比較してメガワットあたり最大 20 倍のエージェントを実行します。
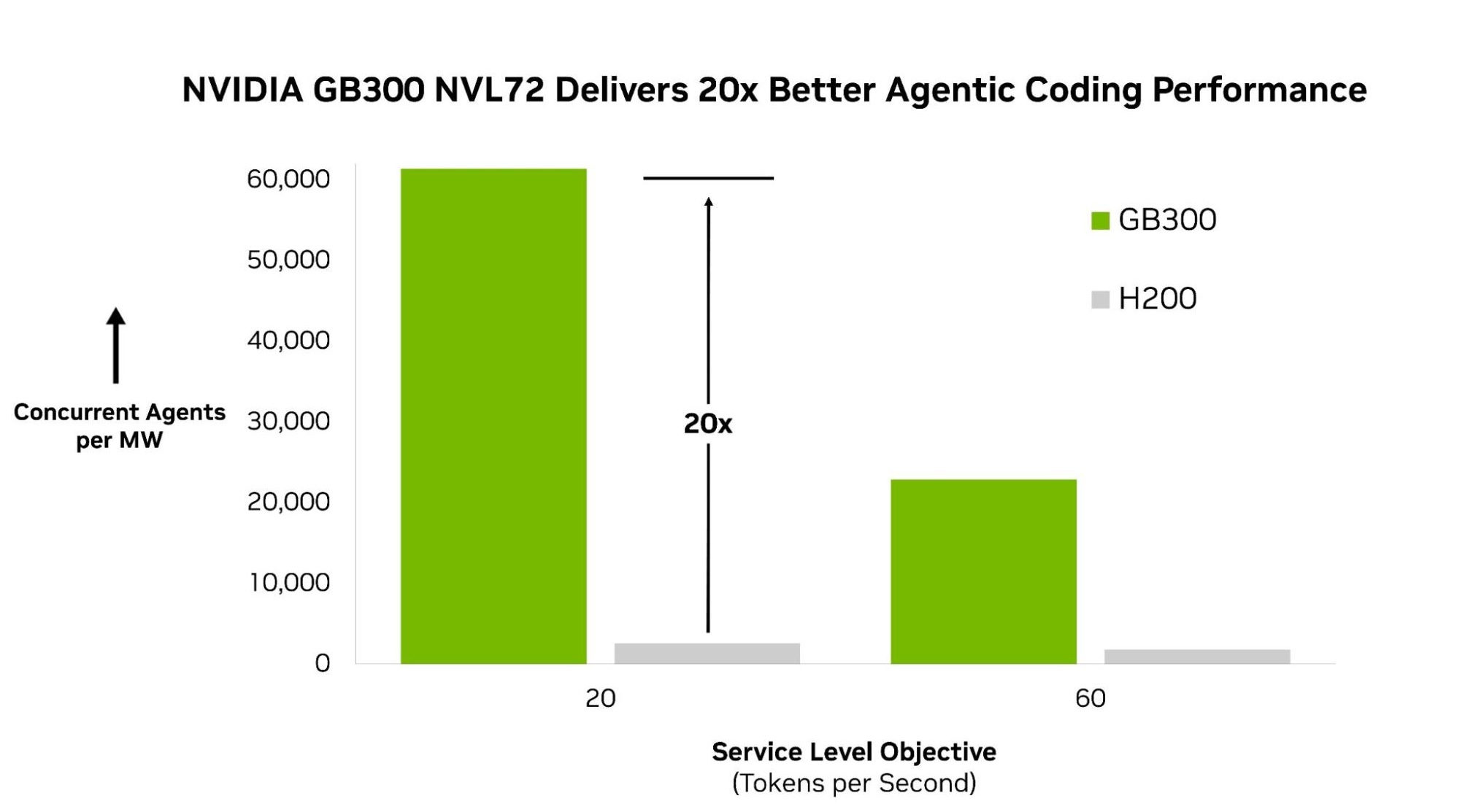 imageNVIDIA GB300 NVL72 は、エージェントあたり 1 メガワットあたりの同時実行可能エージェント数が、NVIDIA H200 を大きく上回っており、これはエージェントあたり秒間 20 トークンおよび 60 トークンの両方のサービスレベル目標において顕著です。
imageNVIDIA GB300 NVL72 は、エージェントあたり 1 メガワットあたりの同時実行可能エージェント数が、NVIDIA H200 を大きく上回っており、これはエージェントあたり秒間 20 トークンおよび 60 トークンの両方のサービスレベル目標において顕著です。
この性能上の優位性は、フルスタックにわたる極限までの共同設計(codesign)によるものです。GB300 NVL72 は 72 個の GPU を単一のラックスケールシステムとして接続し、DeepSeek V4 Pro などの大規模 MoE モデルが、スケーリングされた環境でモデル実行を効率的に分散可能にします。
CUDA カーネルは、通信と計算処理を重畳させることでさらに加速し、エキスパート間での調整にかかるコストがレイテンシに加算されるのではなく吸収されます。
NVIDIA TensorRT LLM は、同時実行するエージェントセッションがスケールしても効率性を維持します。例えば、入力の処理と出力の生成を分離することで、それぞれを独立して最適化することが可能になります。
これらの結果は、生産環境でアジェンティック AI が実際にどのように動作するかを反映するように、ゼロから構築されたベンチマーク手法に基づいています。
Artificial Analysis AgentPerf: 実世界のワークロードに基づく設計
AgentPerf は、実際のコーディングエージェントの軌跡(trajectories)に基づいて構築されています。具体的には、エージェントがタスクを受け取り、ファイルを読み込み、コードを書いたり編集したりし、コマンドを実行して結果に基づいて反復処理を行うという一連の流れです。これらはすべて、12 以上のプログラミング言語にわたる実際の公開コードリポジトリから抽出されたものです。長いシーケンス長、ツール呼び出しのパターン、および遅延は、すべて実世界のコーディングワークフローを代表するものです。
AgentPerf は、応答性と出力トークンレートに関する定義されたパフォーマンス閾値を満たしながら、プラットフォームが同時にサポートできるこれらのエージェントタスクの数を測定します。ツール呼び出しは実行されず、代表的な CPU 処理時間を用いてシミュレーションされるため、結果の違いは加速されたコンピューティング性能のみを反映しています。
この結果は、インフラストラクチャに関する意思決定に直接反映されます:アクセラレータあたりおよびメガワットあたりの電力で同時に実行可能なエージェントタスクの数です。大規模な AI エージェントを導入する企業にとって、これらの数値が特定のインフラ投資によって実際にどれだけの生産的な作業を提供できるかを決定します。
NVIDIA エコシステムパートナーが Blackwell の優れた性能を活用
Baseten、DeepInfra、Together AI を含む主要な推論プロバイダは、すでに NVIDIA Blackwell 上で DeepSeek V4 Pro などの最先端モデルを用いてエージェントワークロードを提供しており、今日では生産環境のエージェントアプリケーションを稼働させています。
Together AI は、NVIDIA Blackwell 上で AI を活用したエージェント型コーディングプラットフォームである Cursor のリアルタイム推論を支えています。Cursor のエージェントはデバッグ、機能生成、リファクタリングの実行を行いながら、開発者は作業を継続できます。
DeepInfra は、ディーラー向け AI ワークフォースプラットフォーム「Pam.ai」を支援しており、同プラットフォームは NVIDIA Blackwell 上で完全に稼働するエージェントを配備し、サービス予約の受付、電話対応、およびアウトバウンド販売キャンペーンの実行を行っています。
NVIDIA とオープンソースエコシステムが推論ソフトウェアの最適化を継続するにつれ、アジェンティックワークロードにおけるパフォーマンスと効率性はさらに向上していきます。NVIDIA の Vera Rubin アーキテクチャは現在、本番環境でフル稼働しており、スケールしたアジェンティック AI への growing な需要に応える次世代インフラキャパシティをもたらしています。
*アジェンティック AI に対する AgentPerf の手法と NVIDIA のフルスタック最適化の詳細については、こちらの 技術ブログ をご覧ください。*
原文を表示
AgentPerf from Artificial Analysis, the industry’s first agentic AI benchmark, gives developers, enterprises and infrastructure providers a clear way to compare systems for agentic AI. In the first round of published results, the NVIDIA Blackwell Ultra NVL72 platform delivers leading performance across the agentic AI workloads tested, running 20x more agents per megawatt than NVIDIA Hopper.
Agentic AI is a fundamentally different workload than conversational AI. A single chat completion is a sprint: one large language model (LLM) call, one response. An agent functions more like a relay: It breaks a goal into many steps and keeps going until the task is done.
That results in dozens to hundreds of LLM calls chained together, each passing growing context to the next, with tool calls like code compile and execution, database search and web browsing at every handoff. The complexity isn’t additive; it’s multiplicative.
The distinction matters enormously for performance measurement. Existing AI inference benchmarks measure one LLM call: how fast an LLM responds to a single request and how many simultaneous requests a system can handle. They weren’t designed for agentic workloads, where chained LLM calls, tool call delays and growing context stress accelerated computing systems in fundamentally different ways than a single LLM call ever could.
For companies building and deploying agents at scale, it’s important to understand how responsive agents are, how many can be deployed simultaneously and how much useful work AI infrastructure can deliver for every dollar and watt invested.
NVIDIA GB300 NVL72 Runs 20x More Agents per Megawatt
In this first round, AgentPerf measures agentic performance with DeepSeek V4 Pro, a large mixture-of-experts (MoE) model that represents the class of frontier models powering today’s most capable agents. On this workload, NVIDIA GB300 NVL72 delivers the highest performance in the benchmark, running up to 20x more agents per megawatt than the NVIDIA HGX H200 system.
The performance advantage comes from extreme codesign across the full stack. GB300 NVL72 connects 72 GPUs into a single rack-scale system, enabling large MoE models like DeepSeek V4 Pro to distribute model execution efficiently at scale.
CUDA kernels accelerate this further by overlapping communication and compute, so the cost of coordinating across experts is absorbed rather than added to latency.
NVIDIA TensorRT LLM sustains efficiency as concurrent agent sessions scale. For example, it separates the processing of inputs from the generation of outputs so each can be optimized independently.
These results are grounded in a benchmark methodology built from the ground up to reflect how agentic AI actually works in production.
Artificial Analysis AgentPerf: Built on Real-World Agentic Workloads
AgentPerf is built based on real coding agent trajectories: an agent receives a task, reads files, writes and edits code, executes commands and iterates based on the results — all drawn from real public code repositories across 12+ programming languages. The long sequence lengths, tool call patterns and delays are all representative of real-world coding workflows.
AgentPerf then measures how many of these agentic tasks a platform can support simultaneously while meeting defined performance thresholds for responsiveness and output token rate. Tool calls are not executed but simulated using representative CPU processing time, so differences in results reflect accelerated computing performance only.
The results translate directly into infrastructure decisions: how many concurrent agentic tasks can be run per accelerator and per megawatt of power. For enterprises deploying AI agents at scale, those numbers determine how much productive work a given infrastructure investment can actually deliver.
NVIDIA Ecosystem Partners Harness Blackwell’s Leading Performance
Leading inference providers including Baseten, DeepInfra and Together AI are already serving agentic workloads on frontier models such as DeepSeek V4 Pro on NVIDIA Blackwell and powering production agentic applications today.
Together AI powers real-time inference for Cursor, an AI-powered agentic coding platform, on NVIDIA Blackwell. Cursor’s agents debug issues, generate features and execute refactors while developers continue working.
DeepInfra powers Pam.ai, an AI workforce platform for car dealerships, which deploys agents to book service appointments, handle calls and run outbound sales campaigns, entirely on NVIDIA Blackwell.
As NVIDIA and the open source ecosystem continue to optimize inference software, performance and efficiency on agentic workloads will only improve. The NVIDIA Vera Rubin architecture is now in full production, bringing the next generation of infrastructure capacity to meet the growing demands of agentic AI at scale.
*Dive deeper into AgentPerf’s methodology and NVIDIA’s full-stack optimizations for agentic AI in this technical blog.*
関連記事
Adobe Marketing Agent for Amazon Quick によるキャンペーンワークフローの加速
AWS と Adobe は、Amazon Quick と Adobe Marketing Agent を連携させることで、マーケティングチームが自然言語で質問するだけで、ガバナンスされた会話環境内で数秒以内にキャンペーンのパフォーマンスやオーディエンスに関するインサイトにアクセスできるようにした。
SAP と Google Cloud がエージェント型コマースアーキテクチャを展開
SAP と Google Cloud は、企業規模でのマルチエージェントマーケティングおよび小売業務の自動化を目的として、エージェント型コマースアーキテクチャの展開を開始した。両社は顧客データの共有不足という構造的課題への対応を掲げている。
e2e-assure が英国初の主権型 AI 駆動ゼロデイ SOC プラットフォーム「Cumulo」を発表
SOC サービスプロバイダー e2e-assure は、デジタルツイン技術と顧客専用 AI モデルを基盤とした新プラットフォーム「Cumulo」の発表を行った。これは GCHQ の要請に応え、IT および OT 環境における新たな AI 駆動型脅威から組織を守ることを目的としている。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み