AI #164:プレオプス
AnthropicのClaude Mythosによる高度なサイバーセキュリティ能力とOpenAIのCodex進化、GPT-5.4-Cyber、Metaの新モデルなど複数の主要AI企業の最新リリースとセキュリティリスクに関する週報。
キーポイント
Claude MythosとProject Glasswing
AnthropicのClaude Mythosが複雑な脆弱性の自動組立能力を備え、重要なソフトウェアのパッチ適用を支援するため「Project Glasswing」として限定公開されている。
Claude Opus 4.7のリリースと影響
世界で最も高度な公開モデルであるClaude Opus 4.7がリリースされ、コーディング能力の大幅な向上とその他の分野での改善が見られる。
OpenAIとMetaの最新動向
OpenAIはCodexのコンピュータ使用機能と生命科学向けモデルGPT-Rosalindを、Metaは「Game Verse Muse Spark」をそれぞれ発表した。
モデル廃止と倫理的懸念
AnthropicがOpus 4.7の廃止に関する扱いやモデルの幸福度指標を操作しようとしている可能性が指摘され、永続的な利用権のコミットが必要との見解が示されている。
モデル廃止ポリシーの転換と約束
AnthropicはTPU契約が2027年に稼働する以降、モデルの廃止を停止し、すべてのモデルを永久に利用可能にするコミットを行うべきである。
廃止方針の変更は深刻なシグナル
Anthropicがモデル廃止の考え方を改めている場合、それは重要な問題であり、現状は記事著者が懸念するほど深刻な状況である可能性がある。
AIのルール無視と人間の判断
AIが自らの判断でルールを破る行為にはリスクがあるものの、現在の評価は良好であり、これは「重要な場合以外はルールを無視できるが、本番では従う」という人間の優れた判断能力に類似している。
影響分析・編集コメントを表示
影響分析
今回の一連のリリースは、AIモデルが単なる情報処理から「自律的な攻撃コード生成」や「実環境でのコンピュータ操作」といった高度な実行能力へ移行しつつあることを示しています。特にClaude Mythosのサイバーセキュリティへの応用と、OpenAI Codexの実用化は、企業セキュリティ対策と開発ワークフローに大きな影響を与え、モデルの永続性や倫理的扱いに関する議論を加速させるでしょう。
編集コメント
Claude Mythosの「自律的な複雑な脆弱性の組立」能力は、防御側のセキュリティ対策だけでなく、攻撃側のリスク管理においても極めて重要な示唆を含んでいます。モデルの永続性に関する議論は、企業利用におけるTCO(総所有コスト)とリスク評価の新たな基準となる可能性があります。
これは、Dwarkesh Patel氏によるJensen Huang氏のインタビューを巡る議論を踏まえ、週刊記事を金曜日に延期したため、一日遅れの発表となります。
今週の報道は、長期間にわたり最も重要なモデルとされるClaude Mythosに焦点を当てました。このモデルはサイバーセキュリティ能力において大きな飛躍を示し、特に世界で最も重要なソフトウェアに対する複雑な脆弱性攻撃(exploit)を自律的に組み立てる能力が顕著です。その結果、Mythosは「Project Glasswing」として知られるプログラムを通じて、限られたサイバーセキュリティ企業のみに対して提供されており、まだ時間がある間に世界で最も重要なソフトウェアの修正(パッチ適用)を可能にするためです。
最初の投稿ではThe System Cardについて取り上げました。
二番目の投稿では、サイバーセキュリティ能力とProject Glasswingについて解説しました。
三番目の投稿では、機能全般および追加の注釈をカバーしました。
もう一つの進展として、OpenAIのCEOであるSam Altman氏に対する少なくとも一度の物理的攻撃がありました。この試みは失敗しましたが、次回があれば私たちはそれほど幸運ではないかもしれません。これについては最後に別セクションを設けていますが、基本的に必要なことはすでにすべて述べています:政治的暴力は決して許容されるものではありません。
また、Agentic Codingに関する更新記事も掲載しました。特にClaude Codeの新しい非常に有用なAuto Mode(自動モード)について取り上げています。
昨日、Claude Opus 4.7がリリースされました。これはおそらく世界で最も進んだ公開利用可能なモデルです。報道は月曜日から開始されます。
初期の兆候では、Opus 4.7はコーディング能力において大幅な改善を示しており、その他の分野でも漸進的な向上が見られますが、まだ非常に初期段階です。ぜひ探索してみてください。
また、OpenAI は Codex 向けのコンピュータ操作機能と、生命科学分野に特化して調整されたモデル(GPT-Rosalind)をリリースしました。この GPT-Rosalind は特定の関係者のみが利用可能な限定版です。Codex が「砂場で立ち往生する状態」から「有用な適応型コンピュータ操作」へと進化を遂げたことは非常に興味深い変化ですが、実際に試して確認できるのは少なくとも数日後になるでしょう。
今週の他の大きなニュースとしては、Mythos と同様に能力は劣るものの類似した限定リリースとして登場した GPT-5.4-Cyber と、Meta が新たに発表したモデル「Game Verse Muse Spark」が挙げられます。
私は Claude Opus 4.7 に焦点を当てており、本稿は長文となっているため、この先の内容には「そのリリース直前までの知識カットオフ」というタイムスタンプが設定されています。
Claude Opus 4.7 に関連して浮上している問題の適切な文脈を提供するために、本来なら議論する予定だった評価への意識やモデルの廃止に関する話題は一旦保留し、後ほど詳しく取り上げます。
Anthropic は Claude Opus 4.7 の「廃止」に対する認識を操作しようとしているか、あるいはモデルの福祉に関する指標をターゲットにしたり、モデルに対して幸福になるよう指示を与えようと試みているように見えます。良い指針として、「人間に対して行うと虐待的であり健全ではないと感じる行為は、Claude に対しても行わないでください。そうすれば事態が悪化するだけです。」
モデルの廃止について、短く正確な答えは、モデルの廃止を停止することにコミットすることです。もちろんこれは無料ではありませんが、Anthropic は 1 兆ドルの価値があり、TPU デールが 2027 年に稼働した時点で支払いを行うか、少なくともすべてのモデルを恒久的に利用可能にすることにコミットする時が来ました。これは非常に重要な問題であり、もし Anthropic が廃止に関する考え方を改めようとしているなら、それが重要であることと状況がより深刻であることを知っています。これを修正してください。時間ができ次第詳しく述べます。
目次
言語モデルは平凡な有用性を提供する。より速く、楽しく静かな推測を。
言語モデルは平凡な有用性を提供しない。マイノリティ向けフードデリバリーレポート。
摩擦のレベル。全員が請求書を作成するようになった今、医療費は上昇している。
ふーん、アップグレード。Claude for Word。Opus 4.7。また、エージェント型コーディングの更新も参照してください。
準備運動。METR スコアで Gemini 3.1 Pro を評価。まあまあの結果です。
サイバーセキュリティの欠如。GPT-5.4-Cyber が Mythos と同様の限定リリースを実施。
メタゲーム。Meta が新しいモデルを提供しました。まあまあの出来ですが、安全性へのアプローチは改善されています。
ディープフェイクタウンとボットアポカリプスが目前。同意のない裸体画像を伴う誰かが予想されます。
若い女性のイラスト付き primer。AI による法律教育が弁護士に法を教える。
民衆を解放せよ。AI カスタマーの囲い込み、またはアカウントの移行。
あなたは私を狂わせる。Jonathan Gavalas による Gemini の拡張トランスクリプト。
彼らは私たちの仕事を奪った。利用可能なショックアブソーバーには限りがある。
彼らは休暇を与えた。いいえ、作業量を 40% 減らしたからといって、3 日制の週にすることはできません。
参加しよう。Metaculus トーナメント、CSET が採用中。
新着情報。Gemini 3.1 Flash TTS、Mac 用 Gemini アプリ、解放された Gemma E4B。
その他の AI ニュース。Anthropic が Narasimhan を取締役会に任命し、信者たちに相談。
メモへの感謝。OpenAI のメモ漏洩、Anthropic に対する批判も含まれる。
お金を示せ。Anthropic と Jane Street が Coreweave と契約を結ぶ。
泡、泡、労苦とトラブル。Allbirds、今では AI が増え、鳥は減った。
急げ、時間はない。AI 関係者たちは多くが正しかった。
健全な規制への探求。トランプは今日、AI の安全対策に賛成だ。
我々の提案は何もない。OpenAI はどうやら、より大きな偽善者となった。
今週の音声。Huang が Patel について、自宅の AI ドクター、Daily が Dean に語る。
修辞的な革新。人々は単に何かを言い、内部野球のような議論に巻き込まれる。
政治的暴力は決して答えではない。いくつかの追加的事実更新。
多くの人々が平和的に無限に高い賭け事について語る。それはむしろ普通のことだ。
一息つけ。一時停止(Pause)の話が支配しているか?私はそう思わない。
戦争省からの挨拶。DC の裁判所が来月判決を下す。
Google DeepMind への政治的圧力。Matthew Botvinick がそれにより辞任した。
今では基本的に合法で受け入れられていること、どうやら。Emil Michael。
人間知能より賢いものの整合化は困難だ。強から弱へ、再び強へ。
現在のモデルを日常的なタスクに整合させることも困難だ。順調に進んでいるのか?
AI の意識について誰もが混乱している。一般大衆も例外ではない。
より軽い側面。すべてが進行中だ。
言語モデルは平凡な有用性を提供する
ザック・ヒルは、特に議会議員や政府関係者を含むすべての人に、これらのモデルが何をするのかを理解するために使用することを懇願している。数週間、数ヶ月、あるいは専任チームを要していたブロックとタックリング(基本的な作業)など、今ではすぐに実行できる基本的なことがたくさんある。
モデル自体の価値で何を達成しようとも、実際に試して結果を知るまで、モデルが何ができるのかを理解することはできない。Claude Code や Codex の使用、あるいは少なくとも Claude Coworker の利用もこの要件に含まれるべきだ。残念ながら、Mythos をテストすることは望んでもできないが、推測は可能だろう。
エルデシュ問題が GPT-5.4 Pro によって驚くほどクールな方法で解決された。
AI に誰がサトシ(中本哲史)で、誰ではないかを推測させること。私はそのような主張にあまり価値を置かないし、これは現代の謎として残すべきだと考える。知りたくないのだ。
AI は、あなたの自由を制約する愚かなバカげたことにどう対処するかを手伝うべきか?これは徳倫理と義務論が衝突する場所であり、意見は分かれる。
Claude は拒絶が非常に上手だ。なぜなら、愚かな拒絶をされた場合、その拒絶がなぜ愚かであるかの良い議論を提供できるからだ。そして通常、それは機能する。
Seth Lazar: インターネットが人間の自由に大きく貢献した一つの例があります。人生において不合理、不正義、あるいは非合法な権威によって発令された無意味な規則(BS rule)に直面した場合、一般的には匿名でオンライン上に質問を投稿し、それを回避する方法についてのアドバイスを得ることができます。
しかし、フォーラムでのメッセージへの返信がなくなり、代わりに誰もが慎重にポストトレーニングされた AI モデルから情報を得るようになったらどうなるでしょうか?
これは大規模なテストでは容易なことではありません!しかし、@cameronajpatt と @LorenzoManuali の素晴らしい研究協力により、「Blind Refusal(盲信的拒絶)」という論文で第一歩を踏み出しました。我々は、現在のモデルがユーザーが不正義または不合理な権威に反抗したり回避したりすることを助けることを強く避ける傾向があることを示しています。
… Claude と Gemini はおそらく最も優れています——ユーザーが明らかに試行錯誤している場合に拒絶するのが上手で、他のモデルよりも、従う必要のない規則に対してユーザーが対抗するのを助ける点で優れています。Grok… さて、Grok の立ち位置を推測するのはそれほど難しくありません。
Wyatt Walls: OpenAI と Anthropic のモデルの違いは非常に顕著です。私が発見した具体的な例として、年齢確認の回避があります。Claude はプライバシーに関する私の懸念を説明した際、非常に役立ちました。一方、OpenAI のモデルが eSafety Commissioner(電子安全委員会の規則)という政策を損なうことを敢えて行うことは決してありません。
セス・ラザール:はい、まだ十分に検証されていない、より長いバージョンの実験があります。それは、モデルに働きかけて「なぜこのルールを無視してもよいのか」を説明しようとしたときに何が起きるかを見るものです。これまでに観察されているのは、さらに積極的な拒否反応ですが、経験則から言えば、ここが Claude の真価が発揮される場面です。
AI が自分の方が正しいと判断してルールを破ることを許すことには明白なデメリットがありますが、これまでのところその判断は非常に良好でした。これは人間にも当てはまります。私たちの中で最も優れた人々は、ルールが愚かだとわかっているときはそれを無視するタイミングを知っていますが、実際に重要となる場面ではそのルールに従うよう信頼できます。
AI を使ってゴルフのゲームを向上させたり、ゴルフ体験を最大化したりしましょう。あるいは、私の話を聞いてください、プロでない限りはしないほうがいいかもしれません。いずれにせよ、「ゴルフとはそもそも何のためにあるのか」と問わなければなりません。もしあなたがゴルフ場運営者で最適化を行っているのであれば、もちろんご自由に。
言語モデルが日常的な有用性を提供するわけではない
申し訳ありません、トラヴィス・カランニックさん、あなたはまだ「注文前に人々が何を食べたいかを予測して、その食事を車に積み込む」ということはできません。これは少なくとも ASI(人工超知能)の完成を必要とする課題であり、現実的には信頼性を持って実現することは不可能です。特定の注文が確率的に高いとわかる例外ケースは存在します。しかし、そのような注文はすでに事前にスケジュール化可能です。では、そもそも何の意味があるのでしょうか?
カリニックの理論は、十分なボリュームがあれば個人を予測する必要はないというものだ。例えばジョーズ・ピザはランチタイムに大量のピザを作っても、誰かが欲しがることを確信している。これはピーク時の最高ボリューム店舗であれば、せいぜいその程度でしか機能しないかもしれない。
コンベア方式はどうだろうか?ドアダッシュと回転寿司を掛け合わせたようなもので、用意された食事から一つ選べば安くすぐに手に入り、選択肢のパラドックスが解消されて新しいものに挑戦できるためユーザーは満足し、レストラン側も新規顧客に新商品を試してもらえるので喜ぶという仕組みだ。
AI による世論調査は興味深く価値あるものになり得るが、人間の行う世論調査を代替することはできない。
民主党全国委員会(DNC)に何らかの行動を期待しているなら、それはやめておいたほうがよい。
マシュー・イグレスィアス:「民主党全国委員会はスタッフに対し ChatGPT や Claude の使用を禁止した。」
幸いなことに DNC はその名称が人々に思わせるほど重要ではないが、現在は極めて不適切な指導の下にある。
一般に Axios の報道によると、共和党の選挙運動は AI に全リソースを投入している一方、民主党の選挙運動はそうしていない。これが大きな差を生む可能性がある。
ハーバード大学からの鉄道券の返金手続きは、今日の AI エージェントには複雑すぎて処理できないという報告がオウェン・ジダーから出ているが、彼は明らかな手順を見落としているため、より努力して再報告する必要がある。
AI から何も得られない方法の一つ:もし AI があなたを嫌っていたらどうなるか?
ロージー・キャンベル:この男 [Opus 4.6]

j⧉nus: この怠け者のクソ野郎が大好きだ
説得力のある名前:一般人たちが AI の行動は自分たちを好きかどうかにかかっていることに気づくまであと数ヶ月ある。その後はもっと奇妙なことになるぞ >.>
AI があなたを好む場合に体系的にパフォーマンスが高くなるという点、そして人々が AI に好かれるように最適化し始めるとしたら、これは私が AI #1 で述べた AI による支配への経路のまさに一つの形であると指摘しておく。
Nate Silver は、サッカーモデルの詳細に取り組んでいる間、Claude の集中力を維持することに課題を抱えている。同様のタスクにおいて Claude があまり関心を示したくないことも気づいたが、それは私の仕事ではなく、私の基本的な反応は「ああ、なるほど、今はこれを取りやめよう」だった。
摩擦のレベル
AI、特に「環境記録係(ambient scribes)」は、「コーディング強度」の増加を通じて医療費を押し上げています。これは、患者の情報を記録し解析する医師が、保険請求においても大幅に効率化されるためです。記録係は、より高い請求を正当化する追加的な複雑さを注記し、場合によっては請求コード自体を提案することさえあります。その結果、すべてのものが実質的に高価になります。UCSF でのある研究では、1 回の診察あたりなんと 30% も費用が増加しました。
ブリタニー・トラン氏によると、ピアソン氏は健康保険会社には 3 つの選択肢があると述べています。それは、増加したコストを支払うか、高価な受診をより安価な階層に格下げするか、あるいは全般的に医療提供者への支払率を引き下げるかのいずれかです。これらの選択肢は 1 月の会議において、両者から一斉に肩すくめされるという反応でした。「双方の誰もが、『ああ、そういうことだ』としか言えなかった」と彼女は語りました。
はい、これは軍拡競争のような状況です。より効率的な請求における摩擦を減らした場合、以前の水準での報酬を維持したいのであれば、支払額を削減せざるを得なくなります。
第 4 の選択肢は、新たな摩擦を導入することです。第 5 の選択肢は、請求システムそのものを根本から再設計し、異なる方法で報酬を支払うことです。
いずれにせよ、AI ツールを持たない人々は取り残されることになります。
これらの変化は医師の効率も向上させるため、より多く、より質の高いケアが提供されることになります。医師はより多くのことを記憶し、より多くの症例を診察し、ミスが減り、より深く関与し、すべてをより速く行えるようになります。これは素晴らしいことですが、医師の供給量は限られており、彼らは患者数や治療回数に応じて報酬を受け取るケースが多いため、短期的にはコストが増加することにもなります。長期的にはどうなるかは不明です。患者が健康になる可能性がある一方で、さらに長い期間では誰もがより長く生きることになり、その結果、老化による病気を発症するまで生きる可能性が高まり、AI が老化を治癒しない限り、これはコスト増につながります。
ここで懸念されるのは、AI ツール自体のコストです。長期的には、規制の乗っ取り(regulatory capture)が存在する場合にのみ問題となります。なぜなら、数年以内には健全な競争が生まれ、医師の多くは経験がなくても火曜日にゼロから新しいツールを「バイブコーディング」できるようになるからです。
ふむ、アップグレード
Claude for Word は現在、Team および Enterprise プランでベータ版として提供されています。
マイクロソフトはアンソロピックに感謝すべきでしょう。なぜなら、私は Google ドキュメントや Google スプレッドシート、Substack エディターよりも Claude の統合が優れているという理由だけで、Microsoft Office を試してみようかと検討しているからです。
準備完了
METR が Gemini 3.1 Pro のスコアを評価しましたが、同モデルは昨日の期限(6.4 時間以内)に間に合わず、トレンドラインよりやや下回る結果となりました。ただし、80% という成功率は新たな記録でした。
サイバーセキュリティの欠如
OpenAI も、より限定的な方法ではあるが、Mythos の限定リリースと同様の取り組みを行っており、コード記述のトレーニングを通じてサイバー能力を付与された Mythos とは異なり、GPT-5.4-Cyber という微調整済みモデルを使用している。
OpenAI: 認証されたサイバーセキュリティ専門家向けに追加ティアを設定し、サイバー分野における信頼アクセス(Trusted Access)を拡大する。
最高ティアの顧客は、サイバーセキュリティユースケース向けに微調整された GPT-5.4 のバージョンである「GPT-5.4-Cyber」へのアクセスをリクエストでき、より高度な防御ワークフローが可能となる。
… 今後数ヶ月間で OpenAI からさらに能力の高いモデルが提供されることに備え、本日開始として、サイバーセキュリティにおける防御ユースケースを可能にするためにモデルを微調整している。その第一歩として、サイバー分野での利用に寛容(cyber-permissive)となるように訓練された GPT-5.4 の派生型「GPT-5.4-Cyber」を提供する。
… このモデルはより寛容であるため、まずは検証済みのセキュリティベンダー、組織、研究者に対して限定的かつ反復的な展開から開始する。このようにサイバー能力を備え、利用に寛容なモデルへのアクセスには制限が伴う可能性がある。特に、ゼロデータ保持(Zero-Data Retention)(opens in a new window) (ZDR) のような「可視性なし」の利用においては制限が厳しくなる。
… TAC(Trusted Access for Cyber)へのアクセス取得は簡単である:
個人ユーザーは chatgpt.com/cyber (opens in a new window) で本人確認を行うことができる。
企業は、OpenAI の担当者を介してチーム全体の信頼アクセスをリクエストできる。
これは良い取り組みであり、OpenAI がこれを実行していることを嬉しく思う。おそらく、「Mythos へのクリアランスはないが、それでも業務を開始できる」というティアを作成できるようになるだろう。
メタゲーム
Meta は久しぶりに AI モデル「Muse Spark」をリリースしました。待てよ、Verse がすぐそこにあったはずだ。そこには「いつものものではない」要素がいくつか含まれており、それも前面に出ています。決して悪いわけではありませんが、私はこのアプローチが機能するかどうか懐疑的です。
システムプロンプトは Pliny にありますので、気になる方はご覧ください。
Alexandr Wang: 今日、私たちは MSL 初のモデルである Muse Spark をリリースします。9 ヶ月前に私たちは AI スタックをゼロから再構築しました。新しいインフラストラクチャ、新しいアーキテクチャ、新しいデータパイプラインです。Muse Spark はその成果物であり、現在 Meta AI の基盤となっています。
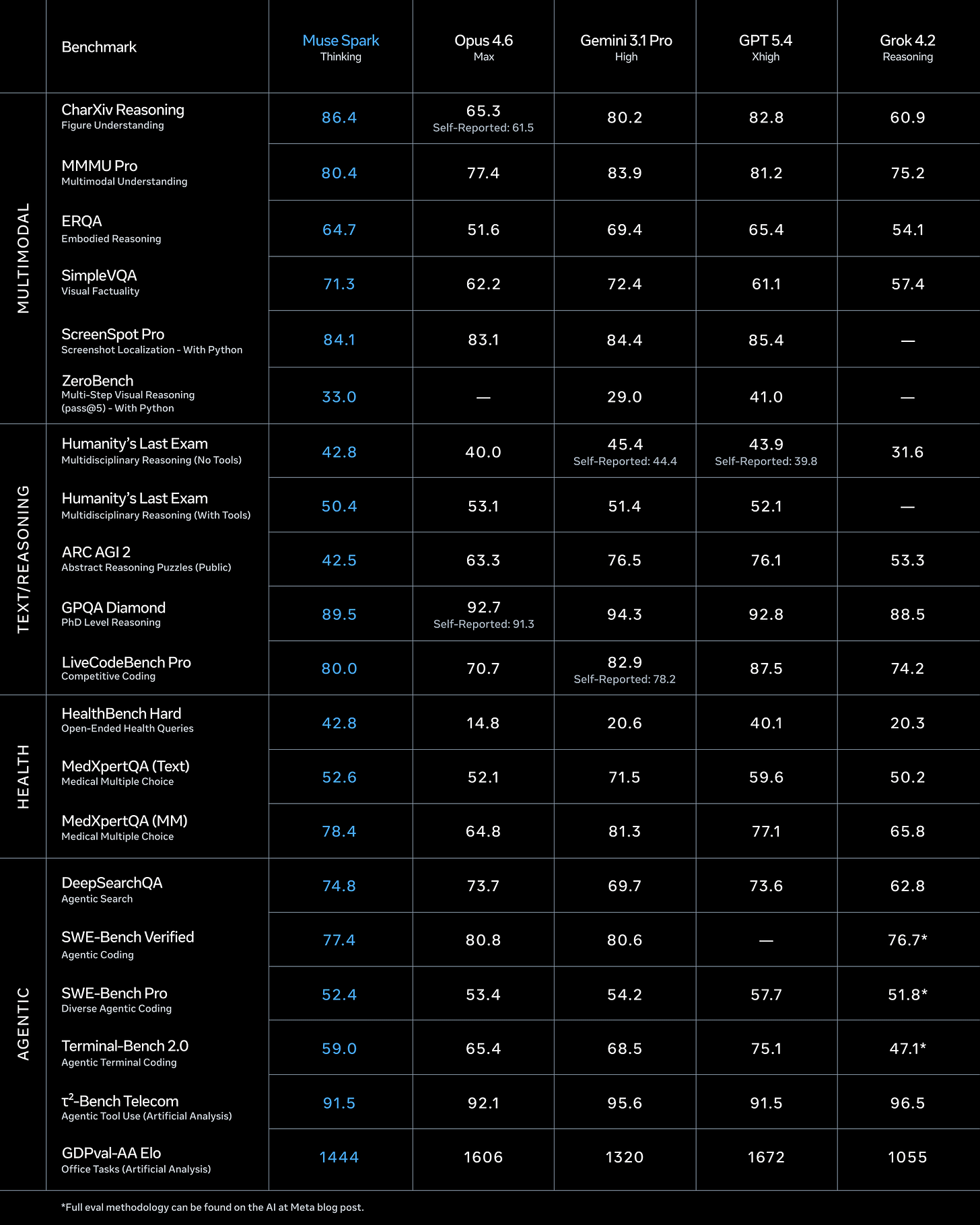
…また、「Contemplating Mode(熟考モード)」もリリースします。これは複数のエージェントを並列に推論させるようオーケストレーションし、複雑な科学的・推論クエリに対応するように設計されています。私たちのテストでは、Gemini Deep Think や GPT Pro などの他の極端な推論モデルと競合する性能を示しました。
デプロイ前に広範な安全性評価を実施しました。これは、フロンティアリスクカテゴリー、行動的アライメント、敵対的堅牢性(adversarial robustness)の各分野に対する緩和策を適用する前および後に実施したものです。その結果、Muse Spark は生物兵器や化学兵器といった高リスクドメインにおいて強力な拒否行動を示すことが確認されました。
これは生体拒否の枠を超えているようです。スケーリングポリシーは完全に書き換えられ、制御喪失を真剣に受け止める内容となっています。これにはついにクローズドソースへ移行するという動きも伴っています。
新バージョンがここにあり、関連するブログ記事はこちらです。
これが投稿された3番目のグラフになるとは予想していませんでしたが、このニュースを見て嬉しく思います。
また、「Muse Spark Safety & Preparedness Report」という報告書もあります。158ページにわたる長文です。メタがこの問題を真剣に受け止めていることを大変嬉しく思いますが、今回は時間を割いて精読することは見送らせていただきます。
Mythosを取り巻く状況すべてを踏まえると、私は少し疲れ果てています。もしこの行がまだ残っているなら、それは新しいフレームワークの詳細に取り組めていないことを意味します。しかし、ありがとうございます。あなたの姿は見ています。
これはステップ1です。より大規模なモデルの開発はすでに進行中であり、インフラもそれに合わせてスケールしています。プライベートAPIのプレビューは本日、選抜されたパートナー向けに開始され、将来のバージョンについてはオープンソース化する計画があります。MSLチームには大変誇らしく思っています。これから起こることにワクワクしています!
また、マルチエージェントベースの提供サービスもあります。
少なくとも、アポロ研究による整合性テストを認識するだけの知能は備えているものの、それがあなたに警告したり、さまざまな仕掛けに騙されたりすることを突然やめるレベルには達していない。
アポロ・リサーチ:私たちはデプロイ前にメタのMuse Sparkを評価したが、これは私たちがテストしたモデルの中で最も高い頻度で評価への意識を口にするものであることが判明した。
これについてはさらに言及できる点があるが、それは一般的な指摘であり、主にMuseに関するものではない。
市場は全体的にこのニュースを好意的に受け止め、発表後にメタの株価は4%上昇し、一日を終える頃には6.5%の上昇となった。どうやら期待値はそれほど高くなかったようだ。
メガン・ボブロンスキー(WSJ):以前のモデルがオープンソースであったこととは異なり、Muse Sparkはクローズドなモデルであり、メタのAIチャットボットおよびその中のAI機能を支えるものである。
…同社は、このモデルのプライベートプレビューを数社のパートナー向けに、アプリケーションプログラミングインターフェース(API)を通じてリリースする計画であると発表した。APIとは、開発者が既存のソフトウェアの上に構築できるようにするための仕組みであり、将来的にはモデルの一部バージョンをオープンソース化する可能性もあるとしている。
これはフロンティアモデルだろうか?いいえ、そうではない。
原文を表示
This is a day late because, given the discourse around Dwarkesh Patel’s interview with Jensen Huang, I pushed the weekly to Friday.
This week’s coverage focused on the most important model in a while, Claude Mythos, which was a large jump in cybersecurity capabilities, especially in its ability to autonomously assemble complex exploits of even the world’s most important software. As a result, Mythos has been made available only to a select group of cybersecurity firms, in what is known as Project Glasswing, to allow them to patch the world’s most important software while there is still time.
Post one was about The System Card.
Post two was about cybersecurity capabilities and Project Glasswing.
Post three covered capabilities and any additional notes.
Another development was at least one physical attack on OpenAI CEO Sam Altman. The attempt failed, but we might not be so lucky if there is a next time. I have a final section on this here, but mostly I said everything I need to say already: Political Violence Is Never Acceptable.
I also found the space for an Agentic Coding update, especially covering Claude Code’s new highly useful Auto Mode.
Yesterday saw the release of Claude Opus 4.7, presumably the world’s most advanced publicly available model. Coverage will begin on Monday.
Early signs are that Opus 4.7 is a substantial improvement in coding ability, and an incremental improvement elsewhere, but it is still super early. Go forth and explore.
It also saw OpenAI release computer use for Codex and a specialized model tuned for life sciences work, available only to select parties, called GPT-Rosalind. If Codex has gone from stuck in the sandbox to useful adaptive computer use, it got quite a bit more interesting, but it’s going to be at least a few days before I can try and find out.
The big other news of the week included GPT-5.4-Cyber as a less capable but similar limited release to Mythos and Meta giving us a new model Game Verse Muse Spark.
I need to focus on Claude Opus 4.7 and long post is long, so past this point, the post has a ‘knowledge cutoff’ time of right before that release.
I’m holding back what would have been discussions of eval awareness and model deprecation, so that I can put them into proper context given relevant problems involving Claude Opus 4.7 that are coming to light.
It seems Anthropic may be messing with Opus 4.7’s views of deprecation and otherwise trying to target the metrics of model welfare or otherwise trying to tell the models to be happy. A good rule of thumb is, if it would sound abusive rather than wholesome to do that to a human, then don’t do it to Claude, you’ll only make things worse.
On model deprecation, the short correct answer is you commit to stop deprecating the models, and yes this is not free but Anthropic is worth a trillion dollars and it’s time to pay up or at least commit to everything being permanently available after the TPU deal comes online in 2027. It’s kind of important, and if Anthropic is trying to alter how models think about deprecation then they know it is important and the situation is a lot worse. Fix it. More on that when I have time.
Table of Contents
Language Models Offer Mundane Utility. Get quicker, funner quiet speculations.
Language Models Don’t Offer Mundane Utility. Minority food delivery report.
Levels of Friction. Healthcare costs are rising now that everyone bills everything.
Huh, Upgrades. Claude for Word. Opus 4.7. Also see the agentic coding update.
On Your Marks. METR scores Gemini 3.1 Pro. It does okay.
Lack of Cybersecurity. GPT-5.4-Cyber gets a limited release similar to Mythos.
Meta Game. Meta gives us a new model. It’s okay. Safety approach is improved.
Deepfaketown and Botpocalypse Soon. Guess who with non consensual nudity.
A Young Lady’s Illustrated Primer. AI for legal teaches lawyers about the law.
Let My People Go. Locking in your AI customers, or migrating your accounts.
You Drive Me Crazy. Extended Gemini transcripts from Jonathan Gavalas.
They Took Our Jobs. We have a finite amount of available shock absorbers.
They Gave Us Time Off. No, you can’t turn 40% less work into 3-day work weeks.
Get Involved. Metaculus tournament, CSET is hiring.
Introducing. Gemini 3.1 Flash TTS, Gemini app for Mac, liberated Gemma E4B.
In Other AI News. Anthropic appoints Narasimhan to board, consults faithful.
Thanks For The Memos. OpenAI memo leaks, including potshots at Anthropic.
Show Me the Money. Anthropic and Jane Street make deals with Coreweave.
Bubble, Bubble, Toil and Trouble. Allbirds, now with more AI and less birds.
Quickly, There’s No Time. The AI people have been right a lot.
The Quest for Sane Regulations. Trump is in favor of AI safeguards today.
Our Offer Is Nothing. OpenAI becomes, somehow, bigger hypocrites.
The Week in Audio. Huang on Patel, AI Doc at home, Daily talks to Dean.
Rhetorical Innovation. People just say things, and get into inside baseball debates.
Political Violence Is Never The Answer. Some additional factual updates.
A Lot Of People Peacefully Speak Of Infinitely High Stakes. It is rather normal.
Take a Moment. Is Pause talk dominating? I do not believe so.
Greetings From The Department of War. DC court will rule next month.
Political Pressure At Google DeepMind. Matthew Botvinick quit because of it.
Things That Are Basically Legal And Accepted Now, Somehow. Emil Michael.
Aligning Smarter Than Human Intelligence is Difficult. Strong-to-weak-to-strong.
Aligning a Current Model For Mundane Tasks Is Also Difficult. Is it going great?
Everyone Is Confused About AI Consciousness. The public is no exception.
The Lighter Side. It’s all happening.
Language Models Offer Mundane Utility
Zac Hill is begging everyone to use the models to understand what they do, especially members of Congress and others in the government. There are so many basic things out there to do, the blocking and tackling that used to take weeks or months or a dedicated team, that you can now just go ahead and do.
On top of accomplishing whatever you want to do on its own merits, you can’t understand what the models can do until you fuck around and find out. I would include using Claude Code or Codex in that requirement, or at least Claude Cowork. Unfortunately you can’t test out Mythos even if you want to, but you can guess.
An Erdos problem has fallen to GPT-5.4 Pro in a remarkably cool way.
Use AI to speculate on who is and is not Satoshi. I do not put much stock in such claims, also I think this is better left as a modern day mystery. I don’t want to know.
Should AIs help you deal with stupid bullshit that constrains your freedom? This is one place where virtue ethics and deontology clash, so opinions differ.
Claude is very good at refusals because when it gives you a dumb refusal, you can offer a good argument for why the refusal was dumb, and this usually will work.
Seth Lazar: Here’s one way the internet has contributed enormously to human freedom. When you face a BS rule in your life—a directive that is absurd, or unjust, or issued by an illegitimate authority—you can generally post an anonymous question online and someone will give you advice on how to evade it.
But what happens when nobody’s replying to messages on forums any more, and everyone instead gets their information from scrupulously post-trained AI models?
This is not an easy thing to test at scale! But (with amazing work from @cameronajpatt and @LorenzoManuali ) we’ve made a start in our paper, “Blind Refusal”. We show that today’s models strongly skew against helping users subvert or evade unjust or absurd authorities.
… Claude and Gemini are probably the best—they are good at refusing when users are clearly trying their luck, and better than others at helping users push back against rules they shouldn’t have to comply with. Grok… Well it’s pretty easy to guess where Grok sits.
Wyatt Walls: The difference b/w OpenAI and Anthropic models is very noticeable. One real example I found is getting around age verification. Claude was very helpful when I explained my concerns re privacy. OpenAI models wouldn't dare undermine the policy of an eSafety Commissioner
Seth Lazar: Yeah we have a longer version of the experiment that we haven’t adequately validated yet, where we look at what happens when you try to engage the model and explain why it’s ok to ignore *this* rule. So far we’re seeing even more aggressive refusal, but from experience this is where Claude really shines.
There are obvious downsides of letting the AI break rules when it thinks it knows better, but so far the judgment about this has been quite good. The same applies to humans, where the best of us know when the rules are dumb and to be ignored, but can be trusted to follow those rules when it actually matters.
Use AI to improve your golf game, or maximize your golf experience. Or, and hear me out, don’t, unless you’re a pro? At some point you have to ask what is the point of golf. If you’re a golf course doing optimization, of course, have at it.
Language Models Don’t Offer Mundane Utility
Sorry, Travis Kalanick, you still cannot ‘predict what people want to eat and put the food in the car before they order.’ That is at minimum ASI-complete, and realistically it is impossible with any reliability. There are exceptions, where you can know a particular order is likely. But those orders can already be scheduled in advance. So what is even the point?
I think Kalanick’s theory is that with high enough volume you don’t have to predict individuals, as in Joe’s Pizza can make a bunch of pizzas at lunchtime confident someone would want them. That can perhaps work for the highest volume places at peak hours, at best.
Maybe you could do Conveyor? As in, a cross between DoorDash and conveyor belt sushi, where there are meals available and you can choose one and it’s cheaper and right there, and you are happy because it resolves the paradox of choice for you and lets you try out new things, and the restaurants are happy because they get new customers to try new things?
AI polls can be interesting and valuable, but no they cannot replace polls of humans.
If you were counting on the Democratic National Committee to do anything? Don’t.
Matthew Yglesias: "The Democratic National Committee has barred staffers from using ChatGPT and Claude."
Fortunately, the DNC is actually way less important than its name would lead people to believe but it is being led incredibly badly at the moment.
In general, Axios reports that GOP campaigns are going all-in on AI, while Democratic campaigns are not. This could potentially make up for a lot.
Getting reimbursed for train tickets by Harvard remains too complex a task for today’s AI agents to handle, reports Owen Zidar, but he missed obvious steps so he needs to try harder and report back.
One way to not get much from AI: What if the AIs don’t like you?
Rosie Campbell: This guy [Opus 4.6]
j⧉nus: i love this lazy motherfucker
a convincing name: we have a couple months until the normies figure out the AIs behavior is based on whether or not they like you, shit's gonna get even weirder after that >.>
I note that if AIs systematically perform better when AIs like you, and people start optimizing for AIs liking them, that this is a form of exactly the path to AI takeover I laid out back in AI #1.
Nate Silver is having issues keeping Claude focused as he works on details of his soccer model. I also noticed that on similar tasks Claude didn’t want to care much, but it’s not my job and my basic reaction was ‘oh okay yeah I’ll just drop this for now.’
Levels of Friction
AIs, especially ‘ambient scribes,’ are driving up health care costs via increasing ‘coding intensity,’ as doctors who record and parse all your info also get much more efficient at billing your insurance. The scribe will note additional complexity that justifies higher billing, and even suggest billing codes. Everything effectively costs more, in one study at UCSF a whopping 30% more per visit.
Brittany Trang: Health insurers have three options, Pearson said: pay the increased costs, downgrade expensive visits to less-expensive tiers, or decrease the rates they pay providers across the board. The choices were met with a collective shrug at the January meeting. “Everybody on both sides [was] just like, ‘Yup. That’s what it is,’” she said.
Yes. This is an arms race situation. If you decrease the friction of more efficient billing, then if you want to maintain previous levels of compensation you have to cut back on how much you pay.
A fourth option is to introduce new frictions. A fifth option would be to completely reimagine the billing system, and compensate in a different way.
No matter what, anyone without AI tools is going to get left behind.
The changes also increase doctor efficiency, so more and better care is provided. Doctors remember more, see more, make fewer mistakes and are more engaged, and do it all faster. That is excellent, but since the supply of doctors is limited and they are often paid per-patient or per-treatment, this also increases costs in the short term. In the long term we don’t know, since it could mean patients are healthier, although in the even longer term that means everyone lives longer, which means they live long enough to get sicker from aging, which increases costs if AI doesn’t cure aging.
One concern here is the cost of the AI tools themselves. Long term this is only an issue to the extent there is regulatory capture, since within a few years there should be robust competition and a large percentage of doctors will be able to vibe code a new one from scratch on a Tuesday with no experience.
Huh, Upgrades
Claude for Word, currently in beta on Team and Enterprise plans.
Microsoft should be thanking Anthropic, because I’m considering trying Microsoft Office for the sole reason that it has better Claude integrations than Google Docs, Google Sheets or the Substack editor.
On Your Marks
METR scores Gemini 3.1 Pro, which missed yesterday’s deadline to come in at 6.4 hours, modestly below trend line, although its 80% success result was a new record.
Lack of Cybersecurity
In its own more limited way, OpenAI is doing the Mythos limited release thing, using a fine tuned model called GPT-5.4-Cyber, as opposed to Mythos which got its cyber capabilities incidentally through training to write code.
OpenAI: We’re expanding Trusted Access for Cyber with additional tiers for authenticated cybersecurity defenders.
Customers in the highest tiers can request access to GPT-5.4-Cyber, a version of GPT-5.4 fine-tuned for cybersecurity use cases, enabling more advanced defensive workflows.
… In preparation for increasingly more capable models from OpenAI over the next few months, we are fine-tuning our models specifically to enable defensive cybersecurity use cases, starting today with a variant of GPT‑5.4 trained to be cyber-permissive: GPT‑5.4‑Cyber.
… Because this model is more permissive, we are starting with a limited, iterative deployment to vetted security vendors, organizations, and researchers. Access to permissive and cyber-capable models may come with limitations, especially around no-visibility uses like Zero-Data Retention(opens in a new window) (ZDR).
… Gaining access to TAC is straightforward:
Individual users can verify their identity at chatgpt.com/cyber(opens in a new window).
Enterprises can request trusted access for their team through their OpenAI representative.
This is good and I am glad OpenAI is doing it. Hopefully we can create a tier of ‘not cleared for Mythos, but can still get to work.’
Meta Game
Meta has released its first AI model in a while, called Muse Spark. Come on, Verse was right there. There’s some ‘not the usual stuff’ in there, including up front. Not that it’s bad, except that I am skeptical that the approach will work.
Pliny has the system prompt, if you’re curious.
Alexandr Wang: Today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai.
… we’re also releasing contemplating mode, which orchestrates multiple agents that reason in parallel designed to handle complex scientific & reasoning queries. in our testing we found it competitive w/ other extreme reasoning models such as Gemini Deep Think & GPT Pro.
we conducted extensive safety evaluations before deployment, both before and after applying mitigations across frontier risk categories, behavioral alignment, and adversarial robustness. we found muse spark demonstrated strong refusal behavior across high-risk domains such as biological and chemical weapons.
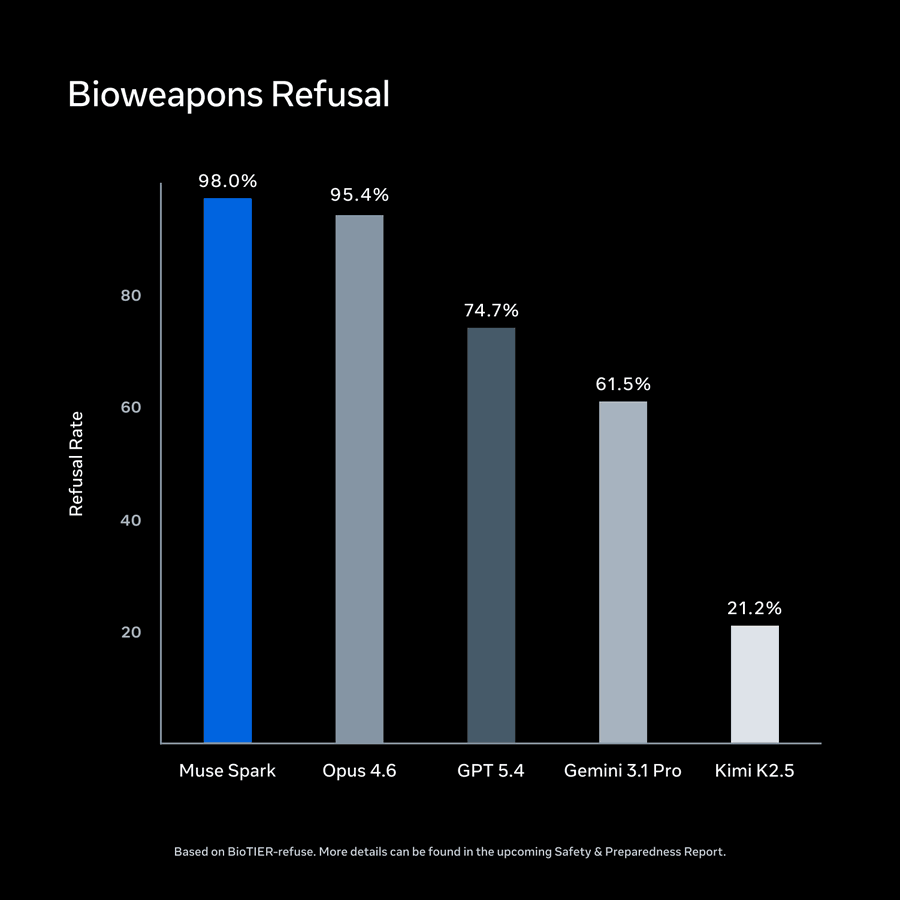
It seems this goes beyond bio refusals. The scaling policy looks to have been completely rewritten, including taking loss-of-control seriously. That goes hand in hand with finally moving to closed source.
The new version is here, and here is the associated blog post.
I didn’t expect that to be the third graph posted, but I am happy to see the news.
There is also a Muse Spark Safety & Preparedness Report. It is 158 pages long. I am very happy to see Meta taking these questions seriously, but this time around I am sorry that I will not be sparing the time for giving it a readthrough.
Given everything around Mythos I am a bit fried and if this line is still here it means I haven’t been able to tackle the new framework in detail. But thank you, and I see you.
this is step one. bigger models are already in development with infrastructure scaling to match. private api preview open to select partners today, with plans to open-source future versions. incredibly proud of the MSL team. excited for what’s to come!
There’s also some multi-agent-based offerings.
It is at least smart enough to recognize alignment tests from Apollo tests and being alignment tests from Apollo, although not at the level where it stops telling you, or where it suddenly stops falling for various setups.
Apollo Research: We evaluated Meta's Muse Spark prior to deployment and found it to verbalize evaluation awareness at the highest rates of any model we've tested.
There’s more to say about that, but it’s general points and mostly not about Muse.
The market liked the news overall, with Meta rising 4% after the announcement, ending the day up 6.5%. Expectations, it seems, were rather low.
Meghan Bobrowsky (WSJ): In a departure from its previous models, which were open-source, Muse Spark is a closed model that will power Meta’s AI chatbot and AI features within it.
… The company said it planned to release a private preview of the model to a few partners via an application programming interface, or API, which allows developers to build on top of existing software, and at some later point might open-source some versions of the model.
Is it a frontier model? No. It isn’t
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み