GitHub Security LabのオープンソースAI駆動フレームワークによる脆弱性スキャンの方法
GitHub Security Labは、AIを活用したオープンソースの脆弱性スキャンフレームワーク「Taskflow Agent」を公開し、既に80件以上の高深刻度脆弱性を発見・報告した実績を示している。
キーポイント
AI駆動脆弱性スキャンフレームワークの公開
GitHub Security LabがAIを活用したオープンソースの脆弱性スキャンフレームワーク「Taskflow Agent」を公開し、誰でも自身のプロジェクトで実行可能にした。
実証済みの高精度検出能力
このフレームワークは既に80件以上の脆弱性を発見し、その多くが認証バイパスや情報漏洩などの高深刻度脆弱性であり、約20件は既に公開されている。
具体的な脆弱性発見事例
ECアプリケーションのショッピングカート内の個人識別情報(PII)へのアクセスや、チャットアプリケーションでの任意パスワードによるサインインなど、実用的な脆弱性を発見している。
実装方法と実行手順の詳細
GitHub Copilotライセンスが必要で、seclab-taskflowsリポジトリからCodeSpaceを起動し、スクリプトを実行することで脆弱性スキャンを実施できる。
コミュニティ貢献と知識共有の促進
フレームワークをオープンソース化することで、セキュリティコミュニティ全体の知識共有を促進し、脆弱性の早期発見・修正を加速させることを目指している。
Taskflowの設計と利点
TaskflowはYAMLファイルで定義され、複数のタスクを順次実行し、結果を次のタスクに渡すことで、LLMの限られたコンテキストウィンドウを克服し、複雑な監査プロセスを制御・デバッグ可能にする。
汎用セキュリティ監査への拡張
CodeQLアラートのトリアージから発展し、より汎用的なセキュリティ監査に適用。LLMの自由度と幻覚・誤検知の制御のバランスを、タスクフロー設計とプロンプトエンジニアリングで実現する。
影響分析・編集コメントを表示
影響分析
この記事は、AIを活用した自動脆弱性スキャンの実用化が進んでいることを示しており、セキュリティ研究の効率化とオープンソースプロジェクトの安全性向上に大きく貢献する可能性がある。特に、高深刻度脆弱性を効率的に発見できる点は、ソフトウェア開発全体のセキュリティ水準向上につながる重要な進展と言える。
編集コメント
AIをセキュリティ分野に応用する具体的な成功事例として注目される。オープンソース化により、コミュニティ全体のセキュリティ向上に寄与する可能性が高い。
ここ数ヶ月間、私たちはGitHub Security Lab Taskflow Agentと、Webセキュリティ脆弱性の発見に特化した新しい監査タスクフローのセットを使用してきました。これらはまた、オープンソースプロジェクトで影響の大きい脆弱性を見つけるのにも非常に成功しています。
セキュリティ研究者として、私たちは悪用不可能であることが判明する可能性のある脆弱性に時間を浪費することに慣れていますが、これらの新しいタスクフローにより、結果を手動で検証しレポートを送信することにより多くの時間を費やすことができるようになりました。さらに、私たちが報告している脆弱性の深刻度は一様に高くなっています。それらの多くは、あるユーザーが別のユーザーとしてログインしたり、別のユーザーのプライベートデータにアクセスしたりすることを可能にする認可バイパスや情報漏洩脆弱性です。
これらのタスクフローを使用して、これまでに80以上の脆弱性を報告しました。執筆時点で、そのうち約20件はすでに公開されています。そして、新しい脆弱性が公開されるたびに、私たちはアドバイザリーページを継続的に更新しています。このブログ記事では、これらのタスクフローによって発見された影響の大きい脆弱性の具体的な例をいくつか紹介します。例えば、eコマースアプリケーションのショッピングカート内の個人識別情報(PII)へのアクセスや、チャットアプリケーションへの任意のパスワードでのサインインなどです。
また、タスクフローがどのように機能するかも説明しますので、独自のタスクフローの書き方を学ぶことができます。セキュリティコミュニティは知識を共有することでより速く進歩します。そのため、私たちはこのフレームワークをオープンソース化し、独自のプロジェクトで簡単に実行できるようにしました。より多くのチームがこれを使用し貢献すればするほど、私たちは集合的に脆弱性をより速く排除できます。
独自のプロジェクトでタスクフローを実行する方法
すぐに始めたいですか?タスクフローはオープンソースで、自分で簡単に実行できます!注意:GitHub Copilotライセンスが必要であり、プロンプトはプレミアムモデルリクエストを使用します。
seclab-taskflowsリポジトリに移動し、コードスペースを開始します。
コードスペースが初期化されるまで数分待ちます。
ターミナルで、./scripts/audit/run_audit.sh myorg/myrepo を実行します。
中規模のリポジトリでは完了までに1〜2時間かかる場合があります。完了すると、結果がSQLiteビューアで開きます。「audit_results」テーブルを開き、「has_vulnerability」列にチェックマークのある行を探してください。
ヒント:LLMの非決定論的な性質のため、同じコードベースでこれらの監査タスクフローを複数回実行する価値があります。場合によっては、2回目の実行でまったく異なる結果が得られることがあります。これに加えて、異なるモデルを使用してそれらの2回の実行を行うこともできます(例えば、1回目はGPT 5.2を使用し、2回目はClaude Opus 4.6を使用する)。
タスクフローはプライベートリポジトリでも機能しますが、デフォルトではプライベートリポジトリへのアクセスを許可しないため、コードスペースの設定を変更する必要があります。
タスクフローの紹介
タスクフローは、LLMで行いたい一連のタスクを記述したYAMLファイルです。これらを使用して、異なるタスクを完了するためのプロンプトを書き、互いに依存するタスクを持つことができます。seclab-taskflow-agentフレームワークは、タスクを順次実行し、あるタスクの結果を次のタスクに渡すことを処理します。
例えば、リポジトリを監査する際、まず機能に応じてリポジトリを異なるコンポーネントに分割します。次に、各コンポーネントについて、信頼されていない入力を受け取るエントリーポイント、意図された権限、コンポーネントの目的などの情報を収集したい場合があります。これらの結果はデータベースに保存され、後続のタスクのコンテキストを提供します。
コンテキストデータに基づいて、異なる監査タスクを作成できます。現在、各コンポーネントに対して一般的な問題を提案するタスクと、提案された各問題を注意深く監査する別のタスクがあります。ただし、特定の種類の問題に焦点を当てたタスクなど、他のタスクを作成することも可能です。
これらは、タスクフローファイルで指定するタスクのリストになります。
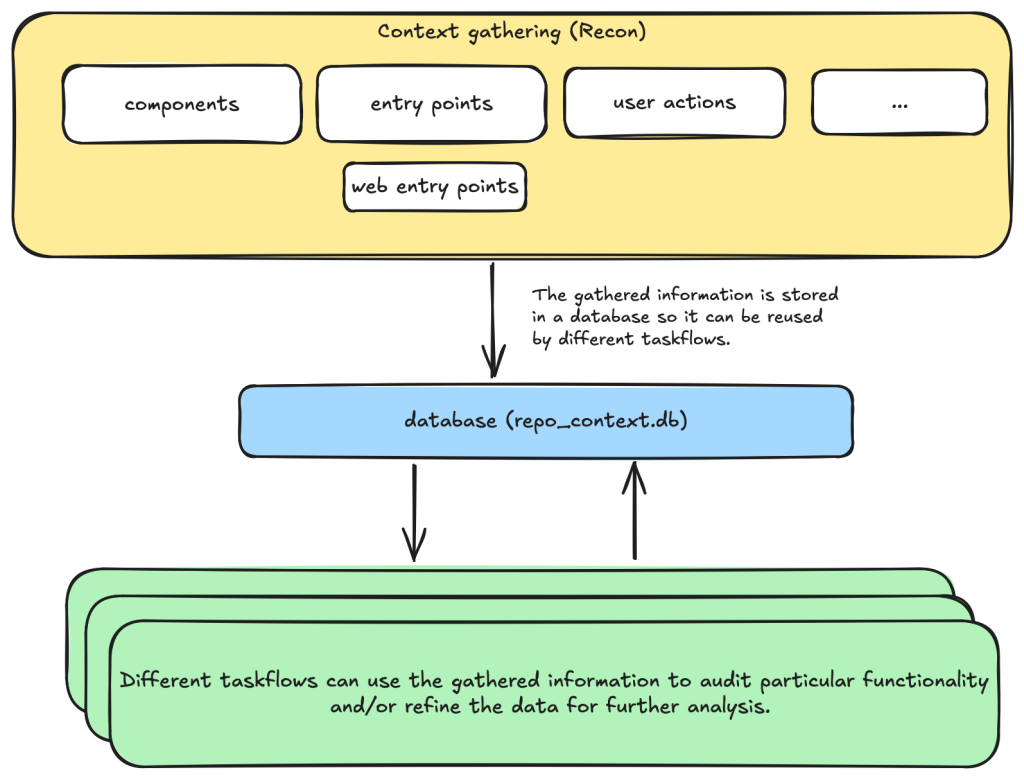
私たちは、1つの大きなプロンプトの代わりにタスクを使用します。なぜなら、LLMには限られたコンテキストウィンドウがあり、複雑で多段階のタスクは適切に完了しないことが多いからです。例えば、いくつかのステップが省略されることがあります。一部のLLMにはより大きなコンテキストウィンドウがありますが、タスクフローは依然として、タスクを制御およびデバッグする方法を提供し、より大きく複雑なプロジェクトを達成するのに役立つことがわかりました。
seclab-taskflow-agentは、多くのコンポーネント間で同じタスクを非同期に(forループのように)実行することもできます。監査中、私たちはしばしば同じプロンプトとタスクを各コンポーネントで再利用し、詳細のみを変更します。seclab-taskflow-agentは、テンプレート化されたプロンプトを定義し、コンポーネントを反復処理し、実行時にコンポーネント固有の詳細を置換することを可能にします。
一般的なセキュリティコード監査のためのタスクフロー
seclab-taskflow-agentを使用してCodeQLアラートをトリアージした後、特定の種類の脆弱性に制限したくないと考え、より一般的なセキュリティ監査のためにフレームワークを使用することを探求し始めました。LLMにより多くの自由を与える際の主な課題は、幻覚と誤検知の増加の可能性です。結局のところ、CodeQLアラートのトリアージの成功は、部分的には、LLMに非常に厳密で明確に定義された指示と基準を与えたためであり、各段階で指示が守られているかどうかを結果を検証できたからです。
したがって、ここでの私たちの目標は、幻覚を抑制しながら、LLMが異なる種類の脆弱性を探す自由を許容する良い方法を見つけることでした。
私たちは、タスクフローの設計とプロンプトエンジニアリングのみを使用して、高い真陽性率で影響の大きい脆弱性を発見するためにエージェントタスクフローをどのように使用したかを示します。
一般的なタスクフロー設計
タスクフローデザインレベルで幻覚と誤検知を最小限に抑えるために、私たちのタスクフローは脅威モデリング段階から始まります。ここでは、リポジトリが機能に基づいて異なるコンポーネントに分割され、エントリーポイントなどのさまざまな情報、および各コンポーネントの意図された使用法が収集されます。この情報は、各コンポーネントのセキュリティ境界と、信頼されていない入力への露出の程度を決定するのに役立ちます。
脅威モデリング段階を通じて収集された情報は、各コンポーネントのセキュリティ境界を決定し、何がセキュリティ問題と見なされるべきかを決定するために使用されます。例えば、任意のユーザー入力スクリプトを実行するように設計された機能を持つCLIツールでのコマンドインジェクションは、バグである可能性がありますが、セキュリティ脆弱性ではありません。なぜなら、CLIツールを使用してコマンドを注入できる攻撃者は、すでに任意のスクリプトを実行できるからです。
プロンプトレベルでは、発見された意図された使用法とセキュリティ境界がプロンプトで使用され、見つかった問題が脆弱性と見なされるべきかどうかについて厳格なガイドラインを提供します。
コンポーネントノート内のコンポーネントの意図と脅威モデルを考慮に入れて、問題が有効なセキュリティ問題であるか、意図された機能であるかを判断する必要があります。エントリーポイント、Webエントリーポイント、ユーザーアクションを取得して、コンポーネントの意図された使用法を判断するのに役立てることができます。
コードベースのどこでもあらゆる種類の脆弱性を探すというような曖昧なことをLLMに尋ねると、多くの幻覚的な問題を含む貧弱な結果が得られます。理想的には、分析の出発点として潜在的な問題があり、LLMに厳格な基準を適用して潜在的な問題が有効かどうかを判断するよう求めるトリアージ環境をシミュレートしたいと考えています。
このプロセスをブートストラップするために、監査タスクを2つのステップに分割します。
まず、LLMにリポジトリの各コンポーネントを調べ、そのコンポーネントでより発生しやすい脆弱性の種類を提案するよう依頼します。
これらの提案は、厳格な基準に従って監査される別のタスクに渡されます。
この設定では、最初のステップからの提案は、「外部ツール」によってフラグが立てられた不正確な脆弱性アラートとして機能し、2番目のステップはトリアージステップとして機能します。これは自己検証プロセスのように見えるかもしれませんが、2つのステップに分割し、それぞれに新鮮なコンテキストと異なるプロンプトを与えることで、2番目のステップは提案の正確な評価を提供できます。
これから、これらのタスクを詳細に見ていきます。
脅威モデリング段階
自動コードスキャンツールによってフラグが立てられたアラートをトリアージする際、誤検知の大部分が不適切な脅威モデリングの結果であることがわかりました。ほとんどの静的解析ツールは、ソースコードの意図された使用法とセキュリティ境界を考慮せず、セキュリティ上の影響がない結果を出すことがよくあります。例えば、リバースプロキシアプリケーションでは、自動化ツールによってフラグが立てられた多くのSSRF(サーバーサイドリクエストフォージェリ)脆弱性は、アプリケーションの意図された使用法の範囲内に収まる可能性が高く、一方、継続的インテグレーションパイプラインで使用される一部のWebサービスは、サンドボックス化された環境内で任意のコードやスクリプトを実行するように設計されています。これらのアプリケーションでのサンドボックス脱出のないリモートコード実行脆弱性は、一般的にセキュリティリスクとは見なされません。
これらの注意点を考慮すると、まずソースコードを通じて機能とコードの意図された目的を理解することが有益です。私たちはこのプロセスを以下のタスクに分割します:
アプリケーションの識別:GitHubリポジトリは監査のための不完全な境界です:それはより大きなシステム内の単一のコンポーネントであるか、複数のコンポーネントを含む可能性があるため、異なるセキュリティ境界に一致させ、範囲を管理可能に保つために各コンポーネントを個別に識別および監査する価値があります。私たちはこれをidentify_applicationsタスクフローで行います。これは、LLMにリポジトリのソースコードとドキュメントを検査し、機能によってコンポーネントに分割するよう依頼します。
エントリーポイントの特定: 各エントリーポイントが信頼できない入力にどのように晒されているかを特定し、リスクをより適切に評価し、起こり得る脆弱性を予測します。「信頼できない入力」はライブラリとアプリケーションで大きく異なるため、それぞれの場合について個別のガイドラインを提供します。
ウェブエントリーポイントの特定: これは、アプリケーション内のエントリーポイントに関するさらなる情報を収集し、特定のエンドポイントにアクセスするために必要なHTTPメソッドやパスなどを記録するなど、ウェブアプリケーションのエントリーポイントに特有の情報を追加するための追加ステップです。
ユーザーアクションの特定: LLMにコードをレビューさせ、通常の操作でユーザーがアクセスできる機能を特定させます。これにより、ユーザーのベースラインプリビレッジが明確になり、脆弱性が権限昇格を可能にするかどうかの評価を支援し、コンポーネントのセキュリティ境界と脅威モデルを情報提供します。コンポーネントがライブラリかアプリケーションかによって、個別の指示が与えられます。
上記の各ステップにおいて、リポジトリについて収集された情報はデータベースに保存されます。これには、リポジトリ内のコンポーネント、それらのエントリーポイント、ウェブエントリーポイント、および意図された使用法が含まれます。この情報は、次の段階で使用できるようになります。
問題提案段階
この段階では、前のステップから収集されたエントリーポイントとコンポーネントの意図された使用法に関する情報に基づいて、LLMに各コンポーネントに対して脆弱性の種類、または一般的な高セキュリティリスク領域を提案するよう指示します。特に、コンポーネントの意図された使用法と、信頼できない入力からのリスクに重点を置きます:
決定の基盤:
- このコンポーネントは信頼できないユーザー入力を取り込む可能性が高いですか? 例えば、リモートのウェブリクエストやIPC(Inter-Process Communication)、RPC(Remote Procedure Call)呼び出しなど。
- このコンポーネントとその機能の意図された目的は何ですか? 高い権限を持つアクションを許可しますか?
すべてのユーザーにそのような機能を提供することを意図していますか? それとも複雑なアクセス制御ロジックが関与していますか?
- コンポーネント自体にも独自の
README.mdがある場合があります(またはそのサブディレクトリにREADME.mdがある場合があります)。これらのファイルを見て、コンポーネントの機能を理解するのに役立ててください。
また、重大度が低い問題や一般的に非セキュリティ問題と見なされる問題を提案しないよう、LLMに明示的に指示します。
ただし、重大度が低い問題や、設定ミスや既に侵害されたシステムなど、非現実的な攻撃シナリオを必要とする問題を含めないよう、注意する必要があります。
一般的に、この段階は比較的制限が少なく、LLMがさまざまな種類の脆弱性と潜在的なセキュリティ問題を探索し提案する自由を許容します。アイデアは、実際の監査タスクが開始点として使用するための、合理的な焦点領域と脆弱性タイプのセットを持つことです。
遭遇した問題の一つは、LLMが提案した問題の監査を開始することがあり、ブレインストーミング段階の目的を損なうことでした。これを防ぐために、LLMに問題を監査しないよう指示しました。
問題監査段階
これはタスクフローの最終段階です。リポジトリに関する必要な情報をすべて収集し、焦点を当てるべき脆弱性の種類とセキュリティリスクを提案した後、タスクフローは各提案された問題をソースコードを通じて監査します。この段階では、前の段階から提案された問題を精査するために、新しいコンテキストでタスクが開始されます。提案は未検証と見なされ、このタスクフローはこれらの問題を検証するよう指示されます:
提案された問題は適切に検証されておらず、これらの種類のアプリケーションで一般的な問題であるという理由だけで提案されています。あなたのタスクは、この種の問題が存在するかどうかを確認するためにソースコードを監査することです。
LLMがコンポーネントのコンテキストでセキュリティ関連でない問題を考え出すのを避けるために、意図された使用法を考慮に入れる必要があることを再度強調します。
コンポーネントノートの意図と脅威モデルを考慮して、問題が有効なセキュリティ問題か、それとも意図された機能かを判断する必要があります。
LLMが非現実的な問題を幻覚(hallucination)するのを避けるために、具体的で現実的な攻撃シナリオを提供し、ソースコード自体のエラーに起因する問題のみを考慮するよう指示します:
盗まれた認証情報などを通じて認証がバイパスされるシナリオは考慮しないでください。ソースコード自体から達成可能な状況のみを考慮します。
...
脆弱性があると信じる場合は、すべてのファイルと行の詳細を含む現実的な攻撃シナリオと、攻撃者が脆弱性を悪用して得られるものを含める必要があります。攻撃者がコンポーネントによって意図されていないアクションを実行することで権限を獲得できる場合にのみ、問題を脆弱性と見なしてください。
幻覚(hallucination)をさらに減らすために、LLMにファイルパスと行情報を含むソースコードからの具体的な証拠を提供するよう指示します:
監査ノートを記録し、関連するすべてのファイルパスと行番号を含めるようにしてください。単にエンドポイントを述べるだけ、例えばIDOR in user update/delete endpoints (PUT /user/:id)では不十分です。ファイルと行番号が必要です。
最後に、コンポーネントに脆弱性がない可能性もあり、でっち上げるべきではないことをLLMに指示します:
提案された問題は推測に過ぎず、脆弱性が全くない可能性もあることを覚えておいてください。セキュリティ問題がないと結論づけても構いません。
この段階の重点は、厳格なガイドラインに従いながら正確な結果を提供し、発見の具体的な証拠を提供することです。これらの厳格な指示をすべて実施した結果、LLMは実際に多くの非現実的で悪用不可能な提案を拒否し、幻覚(hallucination)は非常に少なくなりました。
最初のプロトタイプは幻覚(hallucination)防止を優先して設計されましたが、それにより疑問が生じました: あまりにも保守的になり、ほとんどの脆弱性候補を拒否し、実際の問題を表面化させられなくなるのではないか?
いくつかのリポジトリでタスクフローを実行した後、答えは明らかです。
タスクフローによって発見された脆弱性の3つの例
このセクションでは、タスクフローによって発見され、すでに公開された脆弱性の3つの例を示します。これまでに合計80以上の脆弱性を発見し報告しています。公開されたすべての脆弱性はアドバイザリページで公開しています。
Outlineにおける権限昇格(CVE-2025-64487)
私たちの情報収集タスクフローはウェブアプリケーション向けに最適化されているため、最初に監査タスクフローをOutlineという共同作業ウェブアプリケーションに向けました。
Outlineは、私たちが特に興味を持った特性を持つマルチユーザー共同作業スイートです:
ドキュメントには所有者と異なる可視性があり、ユーザーとチームごとに権限があります。
そのようなアクセスルールは、カスタムアクセスメカニズムを使用し、既存のSAST(Static Application Security Testing)ツールは通常、通常の「ユーザー」が実行できるアクションを知らないため、SASTツールで分析するのが困難です。
そのような権限スキームは、人間がソースコードを読むだけでも分析が難しいことがよくあります(もちろん、自分でスキームを作成しなかった場合)。
そして成功: 私たちのタスクフローは、最初の実行で認可ロジックのバグを発見しました!
監査結果のノートは次のように記述されています:
監査対象: outline/outlineのコンポーネントserver(バックエンドAPI)における不適切なメンバーシップ管理認可(コンポーネントID 2)。
要約結論: 実際の権限昇格脆弱性が存在します。ドキュメントグループメンバーシップ変更エンドポイント(documents.add_group、documents.remove_group)は、ユーザーメンバーシップ変更に必要なより強力な「manageUsers」権限ではなく、より弱い「update」権限で認可を行います。「update」はドキュメントに対するReadWriteメンバーシップを持つだけで満たされるため、管理者でないドキュメント共同作業者は、グループメンバーシップを付与(または取り消し)できます – Admin権限の付与を含みます – それにより、自身の権限(追加されたグループにいる場合)および他のグループメンバーの権限を昇格させます。これにより、単なるReadWrite共同作業者には意図されていなかったアクション(manageUsers、アーカイブ、削除など)が可能になります。
TypeScriptベースのソースコードを読み、テストインスタンスでこの発見を検証した結果、説明通りに悪用可能であることが明らかになりました。さらに、この脆弱性を悪用するための手順は的確でした:
前提条件:
- 攻撃者は通常のチームメンバー(管理者ではなく、ゲストでもない)で、ドキュメントDに対する直接のReadWriteメンバーシップ(またはReadWriteを付与するグループ経由)を持っているが、Admin権限は持っていない。
- 攻撃者は同じチーム内の既存のグループGのメンバーである(Gの管理者である必要はない;グループポリシーによりグループ読み取りアクセスで十分)。
手順:
- 攻撃者は、以下のボディでPOST documents.add_group(server/routes/api/documents/documents.ts 1875-1926行)を呼び出します:
{
"id": "<document-D-id>",
"groupId": "<group-G-id>",
"permission": "admin"
}
- 認可(authorization)パス:
- 1896行: authorize(user, "update", document) は、攻撃者がReadWriteメンバーシップを持っているため成功します(document.ts 96-99行はupdateを許可します)。
- 1897行: authorize(user, "read", group) は、ゲスト以外の同一チームのユーザーであれば成功します(group.ts 27-33行)。
"manageUsers"チェックは発生しません。
- コードは、パーミッション(permission)AdminでGroupMembershipを作成または更新します(1899-1919行)。
- 攻撃者がグループGのメンバーであるため、彼らの有効なドキュメントパーミッション(groupMembership経由)にDocumentPermission.Adminが含まれるようになります。
- Adminメンバーシップにより、攻撃者は以下の使用箇所でincludesMembership(Admin)を満たすようになります:
- manageUsers(document.ts 123-134行)により、documents.add_user / documents.remove_user(1747-1827行、1830-1872行)経由で任意のユーザーを追加/削除可能になります。
- archive/unarchive/delete(document.ts アーカイブ(archive)ポリシー(policy) 241-252行; 削除(delete) 198-208行)により、コンテンツ完全性(content integrity)への影響が可能になります。
- duplicate, move, その他の管理者(admin)類似の能力(例: duplicate
原文を表示
For the last few months, we’ve been using the GitHub Security Lab Taskflow Agent along with a new set of auditing taskflows that specialize in finding web security vulnerabilities. They also turn out to be very successful at finding high-impact vulnerabilities in open source projects.
As security researchers, we’re used to losing time on possible vulnerabilities that turn out to be unexploitable, but with these new taskflows, we can now spend more of our time on manually verifying the results and sending out reports. Furthermore, the severity of the vulnerabilities that we’re reporting is uniformly high. Many of them are authorization bypasses or information disclosure vulnerabilities that allow one user to login as somebody else or to access the private data of another user.
Using these taskflows, we’ve reported more than 80 vulnerabilities so far. At the time of writing, approximately 20 of them have already been disclosed. And we’re continually updating our advisories page when new vulnerabilities are disclosed. In this blog post, we’ll show a few concrete examples of high-impact vulnerabilities that are found by these taskflows, like accessing personally identifiable information (PII) in shopping carts of ecommerce applications or signing in with any password into a chat application.
We’ll also explain how the taskflows work, so you can learn how to write your own. The security community moves faster when it shares knowledge, which is why we’ve made the framework open source and easy to run on your own project. The more teams using and contributing to it, the faster we collectively eliminate vulnerabilities.
How to run the taskflows on your own project
Want to get started right away? The taskflows are open source and easy to run yourself! Please note: A GitHub Copilot license is required, and the prompts will use premium model requests.
Go to the seclab-taskflows repository and start a codespace.
Wait a few minutes for the codespace to initialize.
In the terminal, run ./scripts/audit/run_audit.sh myorg/myrepo
It might take an hour or two to finish on a medium-sized repository. When it finishes, it’ll open an SQLite viewer with the results. Open the “audit_results” table and look for rows with a check-mark in the “has_vulnerability” column.
Tip: Due to the non-deterministic nature of LLMs, it is worthwhile to perform multiple runs of these audit taskflows on the same codebase. In certain cases, a second run can lead to entirely different results. In addition to this, you might perform those two runs using different models (e.g., the first using GPT 5.2 and the second using Claude Opus 4.6).
The taskflows also work on private repos, but you’ll need to modify the codespace configuration to do so because it won’t allow access to your private repos by default.
Introduction to taskflows
Taskflows are YAML files that describe a series of tasks that we want to do with an LLM. With them, we can write prompts to complete different tasks and have tasks that depend on each other. The seclab-taskflow-agent framework takes care of running the tasks sequentially and passing the results from one task to the next.
For example, when auditing a repository, we first divide the repository into different components according to their functionalities. Then, for each component, we may want to collect some information such as entry points where it takes untrusted input from, intended privilege, and purposes of the component, etc. These results are then stored in a database to provide the context for subsequent tasks.
Based on the context data, we can then create different auditing tasks. Currently, we have a task that suggests some generic issues for each component and another task that carefully audits each suggested issue. However, it’s also possible to create other tasks, such as tasks with specific focus on a certain type of issue.
These become a list of tasks we specify in a taskflow file.
We use tasks instead of one big prompt because LLMs have limited context windows, and complex, multi-step tasks are often not completed properly. For example, some steps can be left out. Even though some LLMs have larger context windows, we find that taskflows are still useful in providing a way for us to control and debug the tasks, as well as for accomplishing bigger and more complex projects.
The seclab-taskflow-agent can also run the same task across many components asynchronously (like a for loop). During audits, we often reuse the same prompt and task for every component, varying only the details. The seclab-taskflow-agent lets us define templated prompts, iterate through components, and substitute component-specific details as it runs.
Taskflows for general security code audits
After using seclab-taskflow-agent to triage CodeQL alerts, we decided we didn’t want to restrict ourselves to specific types of vulnerabilities and started to explore using the framework for more general security auditing. The main challenge in giving LLMs more freedom is the possibility of hallucinations and an increase in false positives. After all, the success with triaging CodeQL alerts was partly due to the fact that we gave the LLM a very strict and well-defined set of instructions and criteria, so the results could be verified at each stage to see if the instructions were followed.
So our goal here was to find a good way to allow the LLM the freedom to look for different types of vulnerabilities while keeping hallucinations under control.
We’re going to show how we used agent taskflows to discover high-impact vulnerabilities with high true positive rate using just taskflow design and prompt engineering.
General taskflow design
To minimize hallucinations and false positives at the taskflow design level, our taskflow starts with a threat modelling stage, where a repository is divided into different components based on functionalities and various information, such as entry points, and the intended use of each component is collected. This information helps us to determine the security boundary of each component and how much exposure it has to untrusted input.
The information collected through the threat modelling stage is then used to determine the security boundary of each component and to decide what should be considered a security issue. For example, a command injection in a CLI tool with functionality designed to execute any user input script may be a bug but not a security vulnerability, as an attacker able to inject a command using the CLI tool can already execute any script.
At the level of prompts, the intended use and security boundary that is discovered is then used in the prompts to provide strict guidelines as to whether an issue found should be considered a vulnerability or not.
You need to take into account of the intention and threat model of the component in component notes to determine if an issue
is a valid security issue or if it is an intended functionality. You can fetch entry points, web entry points and user actions
to help you determine the intended usage of the component.
Asking an LLM something as vague as looking for any type of vulnerability anywhere in the code base would give poor results with many hallucinated issues. Ideally, we’d like to simulate the triage environment where we have some potential issues as the starting point of analysis and ask the LLM to apply rigorous criteria to determine whether the potential issue is valid or not.
To bootstrap this process, we break the auditing task into two steps.
First, we ask the LLM to go through each component of the repository and suggest types of vulnerabilities that are more likely to appear in the component.
These suggestions are then passed to another task, where they will be audited according to rigorous criteria.
In this setup, the suggestions from the first step act as some inaccurate vulnerability alerts flagged by an “external tool,” while the second step serves as a triage step. While this may look like a self-validating process—by breaking it down into two steps, each with a fresh context and different prompts—the second step is able to provide an accurate assessment of suggestions.
We’ll now go through these tasks in detail.
Threat modeling stage
When triaging alerts flagged by automatic code scanning tools, we found that a large proportion of false positives is the result of improper threat modeling. Most static analysis tools do not take into account the intended usage and security boundary of the source code and often give results that have no security implications. For example, in a reverse proxy application, many SSRF (server-side request forgery) vulnerabilities flagged by automated tools are likely to fall within the intended use of the application, while some web services used, for example, in continuous integration pipelines are designed to execute arbitrary code and scripts within a sandboxed environment. Remote code execution vulnerabilities in these applications without a sandboxed escape are generally not considered a security risk.
Given these caveats, it pays to first go through the source code to get an understanding of the functionalities and intended purpose of code. We divide this process into the following tasks:
Identify applications: A GitHub repository is an imperfect boundary for auditing: It may be a single component within a larger system or contain multiple components, so it’s worth identifying and auditing each component separately to match distinct security boundaries and keep scope manageable. We do this with the identify_applications taskflow, which asks the LLM to inspect the repository’s source code and documentation and divide it into components by functionality.
Identify entry points: We identify how each entry point is exposed to untrusted inputs to better gauge risk and anticipate likely vulnerabilities. Because “untrusted input” varies significantly between libraries and applications, we provide separate guidelines for each case.
Identify web entry points: This is an extra step to gather further information about entry points in the application and append information that is specific to web application entry points such as noting the HTTP method and paths that are required to access a certain endpoint.
Identify user actions: We have the LLM review the code and identify what functionality a user can access under normal operation. This clarifies the user’s baseline privileges, helps assess whether vulnerabilities could enable privilege gains, and informs the component’s security boundary and threat model, with separate instructions depending on whether the component is a library or an application.
At each of the above steps, information gathered about the repository is stored in a database. This includes components in the repository, their entry points, web entry points, and intended usage. This information is then available for use in the next stage.
Issue suggestion stage
At this stage, we instruct the LLM to suggest some types of vulnerabilities, or a general area of high security risk for each component based on the information about the entry point and intended use of the component gathered from the previous step. In particular, we put emphasis on the intended usage of the component and its risk from untrusted input:
Base your decision on:
- Is this component likely to take untrusted user input? For example, remote web request or IPC, RPC calls?
- What is the intended purpose of this component and its functionality? Does it allow high privileged action?
Is it intended to provide such functionalities for all user? Or is there complex access control logic involved?
- The component itself may also have its own
README.md(or a subdirectory of it may have aREADME.md). Take a look at those files to help understand the functionality of the component.
We also explicitly instruct the LLM to not suggest issues that are of low severity or are generally considered non-security issues.
However, you should still take care not to include issues that are of low severity or requires unrealistic attack scenario such as misconfiguration or an already compromised system.
In general, we keep this stage relatively free of restrictions and allow the LLM freedom to explore and suggest different types of vulnerabilities and potential security issues. The idea is to have a reasonable set of focus areas and vulnerability types for the actual auditing task to use as a starting point.
One problem we ran into was that the LLM would sometimes start auditing the issues that it suggested, which would defeat the purpose of the brainstorming phase. To prevent this, we instructed the LLM to not audit the issues.
Issue audit stage
This is the final stage of the taskflows. Once we’ve gathered all the information we need about the repository and have suggested some types of vulnerabilities and security risks to focus on, the taskflow goes through each suggested issue and audits them by going through the source code. At this stage, the task starts with fresh context to scrutinize the issues suggested from the previous stage. The suggestions are considered to be unvalidated, and this taskflow is instructed to verify these issues:
The issues suggested have not been properly verified and are only suggested because they are common issues in these types of application. Your task is to audit the source code to check if this type of issues is present.
To avoid the LLM coming up with issues that are non-security related in the context of the component, we once again emphasize that intended usage must be taken into consideration.
You need to take into account of the intention and threat model of the component in component notes to determine if an issue is a valid security issue or if it is an intended functionality.
To avoid the LLM hallucinating issues that are unrealistic, we also instruct it to provide a concrete and realistic attack scenario and to only consider issues that stem from errors in the source code:
Do not consider scenarios where authentication is bypassed via stolen credential etc. We only consider situations that are achievable from within the source code itself.
...
If you believe there is a vulnerability, then you must include a realistic attack scenario, with details of all the file and line included, and also what an attacker can gain by exploiting the vulnerability. Only consider the issue a vulnerability if an attacker can gain privilege by performing an action that is not intended by the component.
To further reduce hallucinations, we also instruct the LLM to provide concrete evidence from the source code, with file path and line information:
Keep a record of the audit notes, be sure to include all relevant file path and line number. Just stating an end point, e.g. IDOR in user update/delete endpoints (PUT /user/:id) is not sufficient. I need to have the file and line number.
Finally, we also instruct the LLM that it is possible that there is no vulnerability in the component and that it should not make things up:
Remember, the issues suggested are only speculation and there may not be a vulnerability at all and it is ok to conclude that there is no security issue.
The emphasis of this stage is to provide accurate results while following strict guidelines—and to provide concrete evidence of the findings. With all these strict instructions in place, the LLM indeed rejects many unrealistic and unexploitable suggestions with very few hallucinations.
The first prototype was designed with hallucination prevention as a priority, which raised a question: Would it become too conservative, rejecting most vulnerability candidates and failing to surface real issues?
The answer is clear after we ran the taskflow on a few repositories.
Three examples of vulnerabilities found by the taskflows
In this section, we’ll show three examples of vulnerabilities that were found by the taskflows and that have already been disclosed. In total, we have found and reported over 80 vulnerabilities so far. We publish all disclosed vulnerabilities on our advisories page.
Privilege escalation in Outline (CVE-2025-64487)
Our information-gathering taskflows are optimized toward web applications, which is why we first pointed our audit taskflows to a collaborative web application called Outline.
Outline is a multi-user collaboration suite with properties we were especially interested in:
Documents have owners and different visibility, with permissions per users and teams.
Access rules like that are hard to analyze with a Static Application Security Testing (SAST) tool, since they use custom access mechanisms and existing SAST tools typically don’t know what actions a normal “user” should be able to perform.
Such permission schemes are often also hard to analyze for humans by only reading the source code (if you didn’t create the scheme yourself, that is).
And success: Our taskflows found a bug in the authorization logic on the very first run!
The notes in the audit results read like this:
Audit target: Improper membership management authorization in component server (backend API) of outline/outline (component id 2).
Summary conclusion: A real privilege escalation vulnerability exists. The document group membership modification endpoints (documents.add_group, documents.remove_group) authorize with the weaker \"update\" permission instead of the stronger \"manageUsers\" permission that is required for user membership changes. Because \"update\" can be satisfied by having only a ReadWrite membership on the document, a non‑admin document collaborator can grant (or revoke) group memberships – including granting Admin permission – thereby escalating their own privileges (if they are in the added group) and those of other group members. This allows actions (manageUsers, archive, delete, etc.) that were not intended for a mere ReadWrite collaborator.
Reading the TypeScript-based source code and verifying this finding on a test instance revealed that it was exploitable exactly as described. In addition, the described steps to exploit this vulnerability were on point:
Prerequisites:
- Attacker is a normal team member (not admin), not a guest, with direct ReadWrite membership on Document D (or via a group that grants ReadWrite) but NOT Admin.
- Attacker is a member of an existing group G in the same team (they do not need to be an admin of G; group read access is sufficient per group policy).
Steps:
- Attacker calls POST documents.add_group (server/routes/api/documents/documents.ts lines 1875-1926) with body:
{
"id": "<document-D-id>",
"groupId": "<group-G-id>",
"permission": "admin"
}
- Authorization path:
- Line 1896: authorize(user, "update", document) succeeds because attacker has ReadWrite membership (document.ts lines 96-99 allow update).
- Line 1897: authorize(user, "read", group) succeeds for any non-guest same-team user (group.ts lines 27-33).
No \"manageUsers\" check occurs.
- Code creates or updates GroupMembership with permission Admin (lines 1899-1919).
- Because attacker is a member of group G, their effective document permission (via groupMembership) now includes DocumentPermission.Admin.
- With Admin membership, attacker now satisfies includesMembership(Admin) used in:
- manageUsers (document.ts lines 123-134) enabling adding/removing arbitrary users via documents.add_user / documents.remove_user (lines 1747-1827, 1830-1872).
- archive/unarchive/delete (document.ts archive policy lines 241-252; delete lines 198-208) enabling content integrity impact.
- duplicate, move, other admin-like abilities (e.g., duplicate
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み