メタの最適化推薦システム推論に関する詳細解説
Meta は、共有ユーザー埋め込みの重複複製を不要にする「In-Kernel Broadcast Optimization (IKBO)」技術を発表し、GPU および MTIA 上で推薦システムの推論スループットとレイテンシを劇的に改善した。
キーポイント
IKBO による計算オーバーヘッドの削減
従来の推薦システムで発生していた、候補ごとに共有ユーザー埋め込みを複製する非効率な処理を排除し、カーネルレベルでブロードキャスト論理を融合させることでメモリフットプリントと IO を大幅に削減した。
推延性能の劇的な向上
IKBO の導入により、計算集約型のネットレイテンシが最大 2/3 短縮され、H100 SXM5 環境では Flash Attention カーネルを IO バウンドからコンピュートバウンドへ転換し、621 BF16 TFLOPs の性能を達成した。
ハードウェアとフレームワークの統合最適化
Meta 独自の推論アクセラレータ「MTIA」および H100 GPU 上で、TLX (Triton) を用いたワープ特化型融合を実装し、非最適化ベースラインと比較して最大 6.4 倍のスループット向上を実現した。
In-Kernel Broadcast Optimization (IKBO) の導入
従来の推薦システム推論で発生するユーザー埋め込みの冗長な複製を排除し、ブロードキャスト処理をカーネル内部に統合することでメモリ帯域と計算コストを削減します。
Linear Compression カーネルでの 4 倍速度向上
行列分解、メモリアライメント、ブロードキャスト融合、および TLX を用いたワープ専任マルチステージ融合の 4 つの段階的最適化により、H100 で約 4 倍のスピードアップを実現しました。
Flash Attention の IO バウンドから計算バウンドへの変換
IKBO による K/V ブロードキャストの融合とアーキテクチャ最適化により、演算強度を大幅に向上させ、非共設計モデルと比較して最大 6.4 倍のスループット改善をもたらしました。
影響分析・編集コメントを表示
影響分析
この技術は、大規模な推薦システムや広告アルゴリズムにおける推論コストとレイテンシという長年のボトルネックを打破する画期的なアプローチを示しています。特に、ハードウェア(MTIA/GPU)とソフトウェア(カーネル最適化)の共設計(Co-design)による成果は、AI インフラストラクチャの未来において、単なるアルゴリズムの改良を超えたシステム全体の最適化の重要性を浮き彫りにしており、業界全体のパフォーマンス基準を引き上げる可能性があります。
編集コメント
大規模推薦システムにおける推論効率化の限界値を押し上げる、極めて実践的な技術的ブレークスルーです。ハードウェアとソフトウェアの境界を越えた共設計アプローチは、今後 AI インフラ分野で注目すべきトレンドとなるでしょう。
**
Featured projects
-
TL;DR:
- 従来の推薦システム (RecSys) の推論では、共有されるユーザー埋め込みベクトルやシーケンスが、各候補に対して明示的に複製されていました。In-Kernel Broadcast Optimization(IKBO: カーネル内ブロードキャスト最適化) は、ブロードキャストロジックをユーザーと候補の相互作用カーネルに直接融合させることで、このオーバーヘッドを解消します。これによりメモリフットプリントと IO 利用量が削減され、さらに高いスループットが可能になります。
- IKBO は、計算集約的なネットレイテンシを最大で 2/3 削減し、Meta Adaptive Ranking Model(メタ適応ランキングモデル) を支えるリクエスト中心かつ推論効率の高いフレームワークのスケーラビリティの基盤となっています。
- GPU および MTIA(Meta Training and Inference Accelerator: メタトレーニングおよび推論アクセラレータ) の両方で、Meta の多段階推薦ファネル全体にエンドツーエンドで展開されています。
- IKBO Linear Compression カーネルは、4 つの段階にわたる漸進的な共設計を経て、TLX によるワープ特化型融合を完成させ、H100 SXM5 で累積して約 4 倍の高速化を実現しました。
- IKBO の共設計により、Flash Attention カーネルは IO バウンドから計算バウンドへと転換し、H100 SXM5 で 621 BF16 TFLOPs を達成しました。これに TLX ワープ特化型最適化を組み合わせることで、非共設計の CuTeDSL FA4 Hopper ベースライン (カーネルのみ/カーネル+ブロードキャスト) と比較して、それぞれ 2.4 倍/6.4 倍のスループット向上をもたらします。
本稿では、推薦モデル推論における冗長なユーザー埋め込みのブロードキャストを排除するカーネル・モデル・システムの協調設計アプローチである In-Kernel Broadcast Optimization (IKBO) を紹介します。実環境の推薦システム(RecSys)では、特定のリクエストに対するすべての候補に対してユーザー埋め込みは同一ですが、標準的な手法では明示的な複製が必要となり、候補数に比例してメモリ帯域と計算リソースが浪費されます。IKBO は単純な洞察に基づいています:ブロードキャストは計算上の必要性ではなく、データ配置の問題であるということです。各 IKBO カーネルは、ユーザー入力と候補入力をそれぞれの自然で不一致のバッチサイズで受け取り、内部でブロードキャスト処理を行うため、複製されたテンソルが実際に生成されることはありません。本手法の詳細については、Linear Compression と Flash Attention の 2 つのカーネルに焦点を当てた深掘りを通じて解説します。
Meta の推薦システム推論スタック全体、すなわち初期段階から後期段階のランキングモデルに至るまで、GPU および MTIA(Meta Training and Inference Accelerator)の両方において展開される IKBO は、共設計されたモデルにおいて計算集約的なネット遅延を最大 2/3 削減します。これは、Meta Adaptive Ranking Model(LLM スケールのモデルを生産環境で提供)の基盤となるリクエスト中心かつ推論効率の高いフレームワークのスケーラビリティの中核として機能します。H100 SXM5 において、IKBO の線形圧縮カーネルは、行列乗算分解、メモリアライメント、ブロードキャスト融合、そして TLX (Triton Low-Level Extensions) を介したワープ特化型多段融合という 4 つの段階的な共設計ステップを通じて、約 4 倍の高速化を実現します。Flash Attention においては、IKBO は非共設計の CuTeDSL FA4-Hopper(カーネルのみ / カーネル+ブロードキャスト)と比較して、621 BF16 TFLOPs の性能でそれぞれ 2.4 倍/6.4 倍のスループットを提供します。システムレベルのブロードキャストや複製を回避するためのネット分割とは異なり、IKBO は計算プリミティブ層において複製そのものを排除し、ほぼ独立したコストで高密度な相互作用品質を実現します。
コードリポジトリ:https://github.com/pytorch/FBGEMM/tree/main/fbgemm_gpu/experimental/ikbo
† *Meta 在籍時に実施された研究*
1. インカーネルブロードキャスト最適化:メモリと計算の冗長性の排除
ユーザーがフィードを開くと、推薦システムは表示するアイテムを決定するために数百から数千件の候補アイテムにスコア付けを行う必要があります。モデルの入力は2つのカテゴリに分割されます。リクエスト内のすべての候補に対して同一であるユーザー特徴(例:閲覧履歴、プロフィール、コンテキスト)と、各アイテムごとに固有の候補特徴(例:アイテムID、カテゴリ、エンゲージメント統計)です。両者は埋め込み検索を経て処理され、最終的に埋め込み表現を生成します。モデル内のさまざまなポイントで、相互作用層(例:線形射影、特徴交叉、ターゲットアテンション)がユーザーと候補の埋め込みを組み合わせています。リクエスト内のすべての候補に共通する埋め込みをリクエスト専用 (RO) と呼び、各候補固有の埋め込みを非リクエスト専用 (NRO) と呼びます。
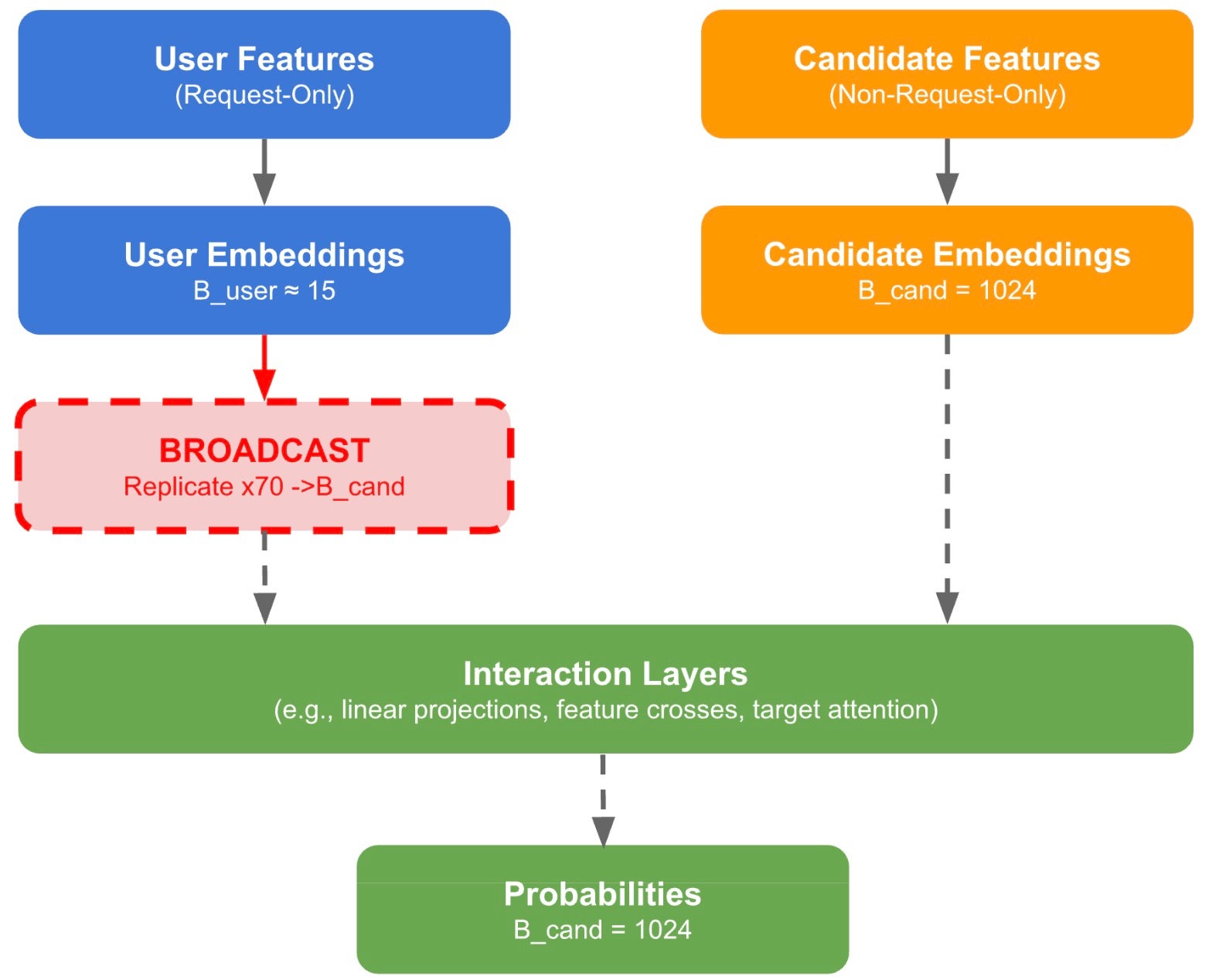
図 1. 非常に簡略化された推薦システム推論データフロー。リクエスト専用 (RO) ユーザー埋め込みは、相互作用層で非リクエスト専用 (NRO) の候補バッチ次元と一致させるためにブロードキャスト(複製)される必要があります。IKBO は、このマテリアライゼーションを各カーネル内部でのブロードキャスト処理によって排除します。
インタラクション層では、バッチ次元が一致するテンソルが必要です。約 15 ユーザーによって提供される 1,024 件の候補からなるバッチにおいて、RO エンベディングは、任意のインタラクションを実行する前に NRO バッチサイズと一致させるためにブロードキャストされ、約 70 回複製されます(図 1)。アーキテクチャは DLRM [1] や DCN [2] から HSTU [3] や X の Phoenix [4] などの逐次モデルへと進化し、ユーザーと候補のインタラクションを着実に豊かにしてきました。しかし、より豊かなインタラクションには代償が伴います:ユーザー特徴量はすべての候補に対してブロードキャストされなければなりません。推論におけるバッチサイズが 10 から 10,000+ の範囲にある場合、この複製オーバーヘッドは、候補数に比例して線形に増加する計算量とメモリコストを招きます。
ブロードキャストは計算上の必要性ではなく、データレイアウトに関する課題です。この視点からモデルと推論システムを見直すことで、各層における最適化が可能になります:推論ランタイムがシステムレベルのブロードキャストを排除し、ユーザー専用のモデル層ではより小さなユーザーバッチサイズで実行され、両者を混合するカーネルは内部でブロードキャストを処理するように再設計されます。これにより、複製されたテンソルは一切生成されません。Meta の推薦システム(RecSys)推論スタック全体、初期段階から後期段階のランキングモデルに至るまで、GPU と MTIA の両方に展開される IKBO は、共設計モデルにおいて計算集約的なネットレイテンシを最大 2/3 削減します。
本稿では、Linear Compression(線形圧縮)と Flash Attention の 2 つの深掘りを通じて、カーネル層に焦点を当てます。
1.1. カーネル最適化の種類
タイプ I — 分解可能な演算。数学的な再構成により、リクエストのみ対象の (RO) 部分を小バッチサイズで独立して計算し、非リクエストのみ対象の (NRO) 部分と最終段階でのみ結合します。これによりメモリ帯域幅と計算資源の両方を節約できます。
タイプ II — メモリ最適化。カーネル内で RO と NRO のブロードキャスト処理を行うことで、冗長なデータ移動を回避し、カーネルが I/O バウンドから解放されます。
1.2. エンドツーエンドシステム設計
IKBO の導入はインフラスタックの 3 つの層にまたがります:
- カーネル: 不一致の RO/NRO バッチサイズを受け入れ、内部でブロードキャストを処理するカスタム GPU カーネル(セクション 2 および 3)。
- コンパイル仕様: ML コンパイラは、適切な形状のカーネルを選択するために演算子ごとの動的形状範囲が必要です。バッチサイズが 1 つの場合は単純ですが、2 つ (ユーザーと候補) またはそれ以上ある場合、生産環境モデルにおいて相互作用によってバッチの系譜が不明瞭になる中で、各演算子がどの形状を使用するかを確実に解決するには、体系的な自動化が必要です。
- 推論: ランタイムはブロードキャストを実体化するのではなく、候補からユーザーへのマッピングをモデルに渡します。
これらのカーネルは以下の 2 つの経路のいずれかを通じてモデルに組み込まれます:
- 直接採用: モデル作成者が IKBO カーネルを直接モデル定義に統合します。トレーニング中に候補対ユーザー比率が 1 を超える場合、同じカーネルでトレーニングコストも削減できます。
- 推論時変換: パスが自動的に標準演算子を推論時に IKBO 相当の演算子に置換します — モデルコードの変更は不要です。
その結果、推論のすべての段階からブロードキャストが消え去り、モデルに対するアーキテクチャ上の制約はなくなり、推論ランタイムのマッピングインターフェース以外にインフラストラクチャの変更も不要となります。
1.3. 他のアプローチとの比較
既存のアプローチは、ブロードキャストを排除するのではなく、それを回避して対処しています。
- システムレベルのブロードキャストでは、GPU へのディスパッチ前に複製されたテンソルを実体化させるため、単純ではあるものの非効率であり、コストは候補数に対して線形にスケーリングします。
- ネット分割(ROO)[5] はモデルを RO および NRO サブネットワークに分割し、冗長な作業を削減しますが、ユーザーと候補の相互作用が発生できる場所を制約し、小規模な RO バッチサイズでは追加コストを導入する可能性があります。
両方の手法は、ブロードキャストを実体化されたテンソルとして維持しています。IKBO は計算プリミティブ層でこれを排除します:節約効果は候補数対ユーザー数の比率に比例して拡大し、ブロードキャストコストなしで任意の相互作用パターンが機能し、融合カーネル内でフル NRO バッチ次元が GPU 占有率を提供します。
IKBO は GPU および MTIA アクセラレータの両方でデプロイされています。本ブログ記事では、H100 GPU カーネル設計に焦点を当てて、中核となる最適化原則を説明します。
2. カーネル深掘り I: IKBO リニア圧縮
リニア圧縮埋め込み(LCE)は、学習された射影 (M, K) @ (B, K, N) → (B, M, N) を通じて入力埋め込み (B, K, N) を圧縮し、Meta の RecSys モデルで広く採用されています。例えば Wukong [6] です。ここでは 4 つの段階的な最適化ステージを順に解説します。
2.1 マルチプレイスメント分解
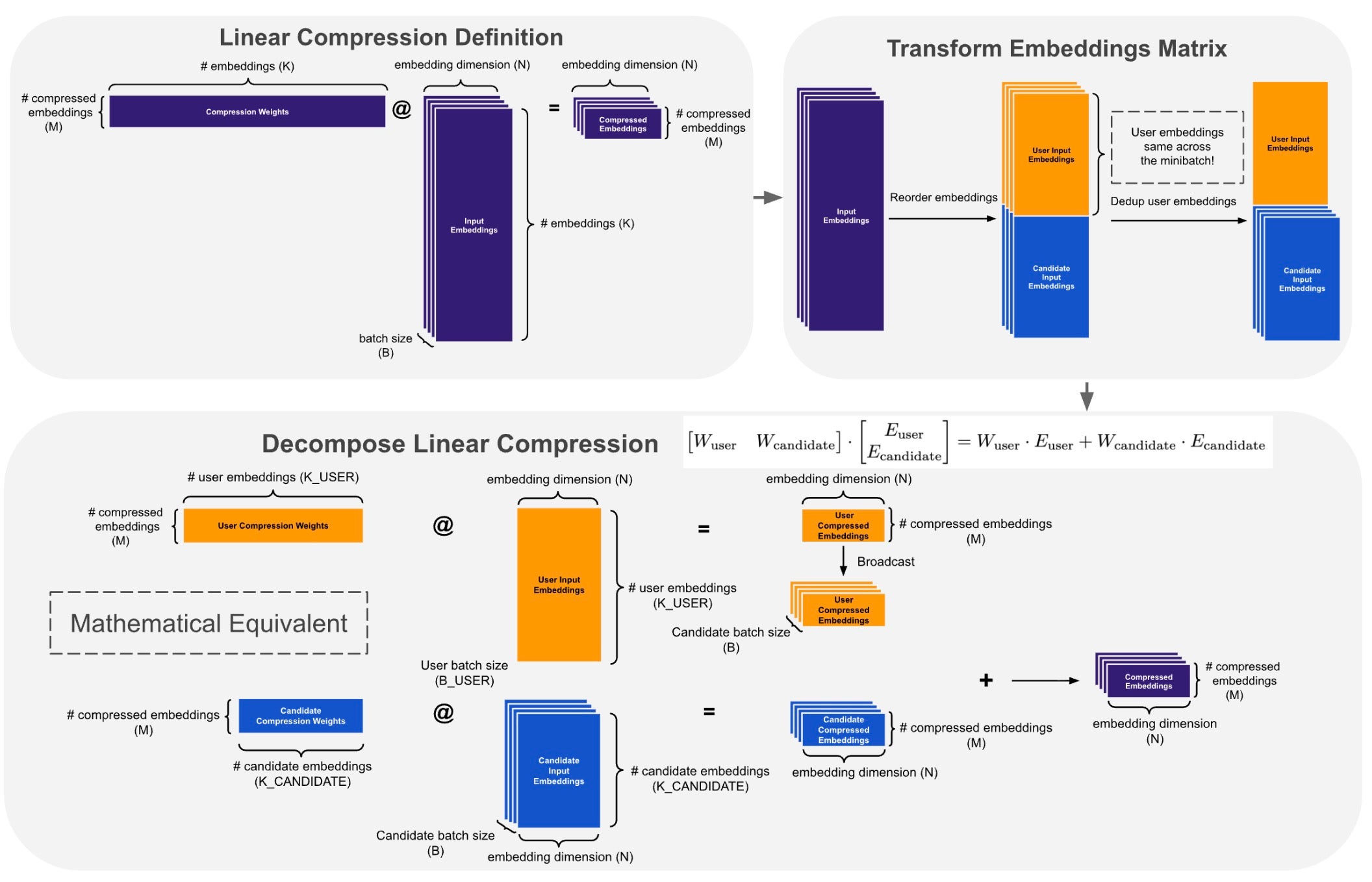
Fig. 2. LCE(Latent Candidate Embedding)分解:ベースラインのバッチ化された行列積(左上)、K 軸に沿った埋め込み分離とユーザー重複排除(右上)、圧縮出力上のブロードキャスト加算を伴う 2 つの独立した GEMM(General Matrix Multiplication、一般行列乗算)(下段)。
ベースライン LCE は、すべての B 候補に対して単一のバッチ化された行列積を計算します。入力埋め込みは、ユーザー部分と候補部分を K 軸に沿って結合しますが、同じユーザーに対する場合、ユーザー埋め込みはすべての候補で同一です。
ブロードキャストを行列積の後に押し出す。 W はバッチに依存しないため、線形性によって分解します。K 軸に沿ってユーザーおよび候補の埋め込みブロックを分離し、繰り返されるユーザー埋め込みを重複排除した上で、それぞれの自然なバッチサイズで 2 つの独立した GEMM を計算します。行列積の前にユーザー埋め込みを複製するのではなく、小さな圧縮結果のみをブロードキャストします。Fig. 2 を参照してください。候補対ユーザー比が約 70(代表的な設定)の場合、ユーザー側のバッチサイズは B=1024 から B_user ≈ 15 に縮小され、ユーザー側での計算量が70 倍削減されます。この分解は標準的な PyTorch で実装されています。
結果。 1.944 ms → 1.389 ms (28.5% の削減; ベンチマーク設定は付録 1 を参照)。元のバッチ処理された GEMM(演算強度は約 356 FLOPs/Byte で、H100 の機械バランスポイントである約 495 FLOPs/Byte に満たない; 導出については付録 2 を参照)と、分解された 2 つの GEMM はいずれもメモリーバウンドであり、速度向上はメモリーコストの削減によって駆動されています。重複排除によりメモリーコストが半分以下に削減され、ユーザー側の GEMM(B_user ≈ 15 vs. B = 1024)のコストは無視できるほど小さくなります。
分解によりブロードキャストが行列乗算の後に押しやられる点にご注意ください。GEMM の前に完全な K 次元入力埋め込みを複製するのではなく、小さな圧縮結果のみをブロードキャストするため、はるかに安価になります。セクション 2.3 では、カーネル内ブロードキャスト融合を通じてこの残りのブロードキャストも完全に排除します。
現在のボトルネックは DRAM の利用率ではなく L1/TEX パイプラインの利用率(84%)です。これは次のセクションで詳しく掘り下げる不均衡な状態です。詳細なプロファイリング内訳は付録 3 を参照してください。
2.2 メモリレイアウト最適化
分解された GEMM の詳細な結果分析から、不均衡が明らかになりました:L1/TEX はピーク値の 84% に達している一方、DRAM はわずか 19% です。これは不必要に狭いメモリーロードを示しています。SASS を確認すると、cp.async コピーはすべて 4 バイトしかコピーしておらず、単一の 128 ビットロードを行っていません。
LDGSTS.E.LTC128B P0, [R203], [R38.64] // 4 バイト
LDGSTS.E.LTC128B P1, [R203+0x4], [R38.64+0x4] // 4 バイト (×4 合計、全体で 16 バイトのロードのみ)
LDGSTS.E.LTC128B P0, [R203], [R38.64] // 4 bytes
LDGSTS.E.LTC128B P1, [R203+0x4], [R38.64+0x4] // 4 bytes (×4 total, only 16B load in total)cp.async の幅は、ソースポインタの自然アライメントによって制限されます。行列 A は (M, K) 形式の行主順序であり、ストライドは K × 2 バイトです。したがって、K が 8 の倍数でない場合、ストライドが 128 ビットアライメントを破ることになります。
モデルカーネル協調設計の洞察。 メモリアライメントはよく理解されている GPU 最適化技術ですが、分解によってこれはモデルとカーネルの協調設計の課題へと変化します。K は、多くのモデル設定要因に依存するサイズを持つ埋め込みテンソルの torch.cat によって形成されます。分解により、分解された埋め込みが完璧な倍数 remain するようにこれらの要因を手動でエンジニアリングすることは非常に困難になります。体系的な解決策が必要です。
解決策。 連結リストの末尾にゼロを追加して、各分解された K を 8 の次の倍数にパディングします。これは順伝播と逆伝播の両方で数学的に等価であることを証明しました(以下の Proof 1 を参照)、ML コンパイラのメモリプランナーを用いることで、これは安価な定数コピーへと還元されます。
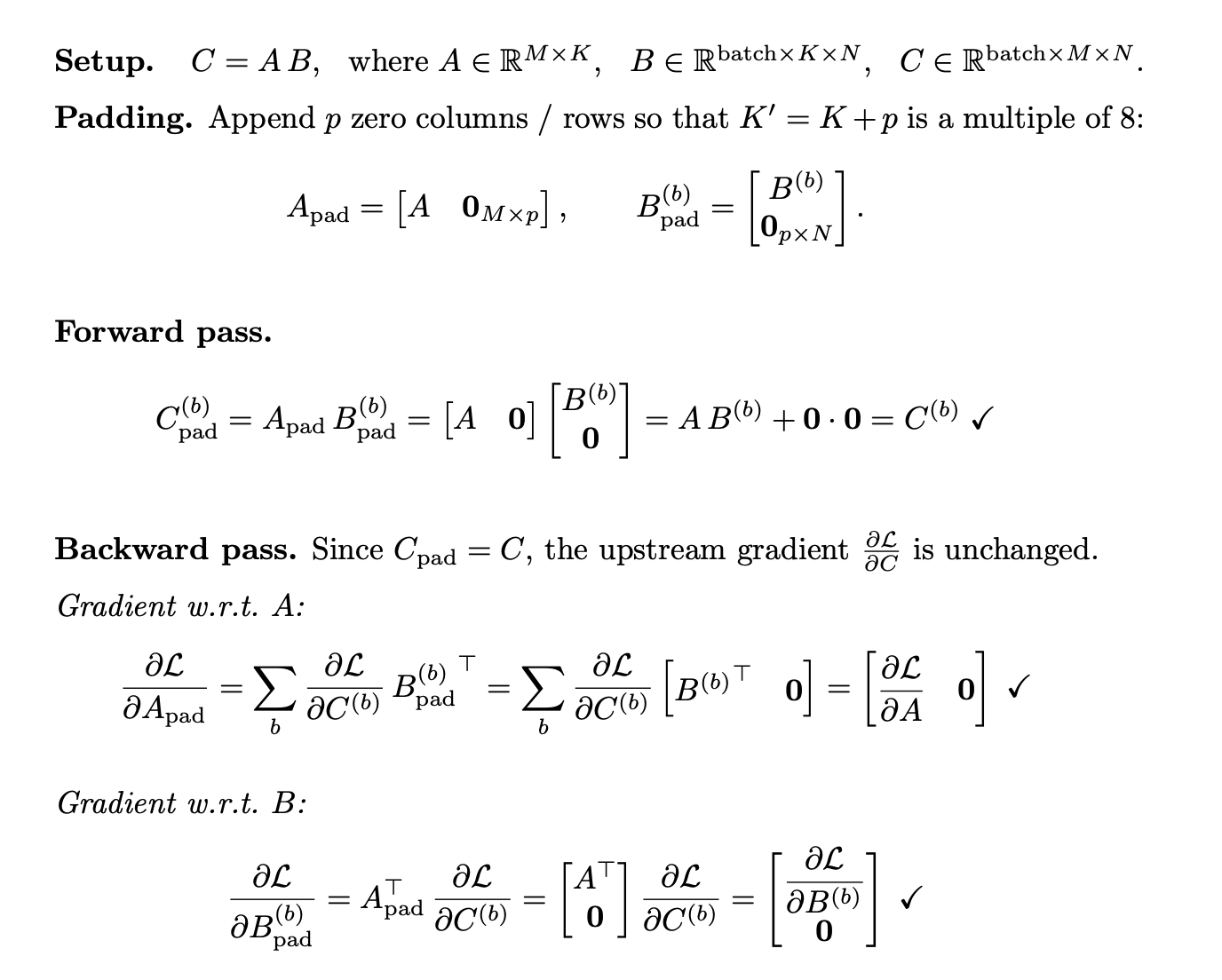 imageProof 1. K のゼロパディングは、順伝播と逆伝播の両方で正確な数値等価性を維持します。
imageProof 1. K のゼロパディングは、順伝播と逆伝播の両方で正確な数値等価性を維持します。
結果。 1.389 ms → 0.798 ms (42.5% 削減)。パディングにより CUTLASS が TMA ベースのカーネルを選択できるようになり、L1/TEX を完全にバイパス(セクター数 351M → 0)し、GEMM のレイテンシを 0.984 ms から 0.400 ms に削減します。GEMM が解決されたことで、非融合のブロードキャストと加算 (0.398 ms) が全体のレイテンシの半分を占めるようになりました—これは次節で取り扱います。詳細な結果分析は付録 5 を参照してください。
2.3 キャンディデート GEMM のインカーネルブロードキャスト融合
未融合のブロードキャストと加算はメモリーバウンドです:候補となる GEMM の結果を HBM に書き込み、ユーザーの結果と共に読み出し、加算して再度書き込みます。これを解消するために、ブロードキャストを候補となる GEMM のエピローグに融合させました(図 3)。各タイルの蓄積後、エピローグはユーザーインデックスを検索し、事前計算されたユーザー結果を読み出してレジスタ内で加算し、最終的な和を書き出します。中間テンソルは一切マテリアライズされません。これは Triton カーネルとして実装されており、カスタム事後蓄積エピローグブロックを備えた標準的なバッチ処理 GEMM です。
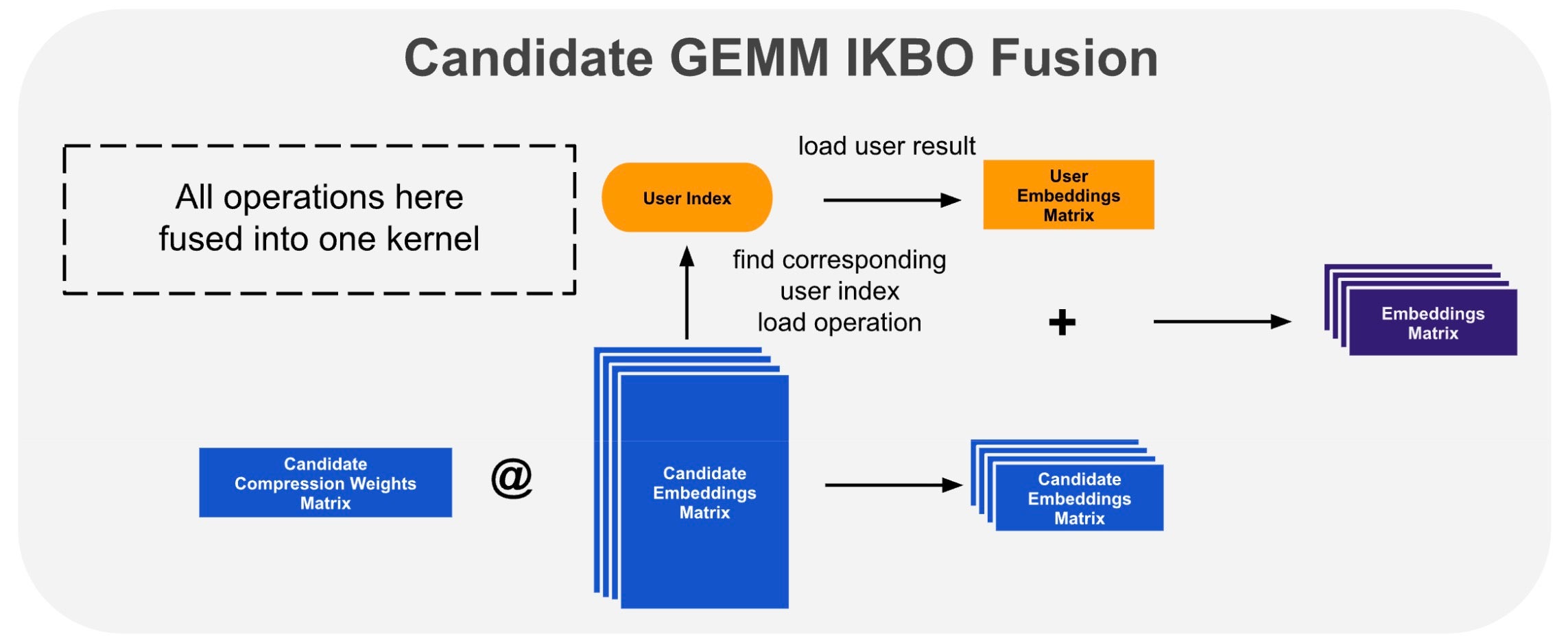
図 3. インカーネルブロードキャスト融合:GEMM エピローグはインデックス検索を通じて事前計算されたユーザー結果を読み出し、レジスタ内で加算します。
結果。 0.798 ms → 0.580 ms (27.4% の削減)。融合により中間 DRAM トラフィックが 0.87 GB 削減され、レイテンシの改善に寄与しています。しかし、オキュパンシーはわずか 6.25%(スケジューラあたり 1 ワープ)であり、すべてのストールが露呈した状態です。サイクルの 42% 以上がグローバルロード待ちで消費されており、そのうち 20% は WGMMA 待ちに費やされています。これはエピローグでは隠すことができないストールであり、永続性がない場合、次タイルの読み込みとオーバーラップさせるための次の読み込みも存在しません。これは困難なトレードオフです:テンソルコアを供給し続けるためには大きなタイルと深いパイプラインが必要ですが、それらは共有メモリの予算の大部分を消費するため、オキュパンシーを通じてレイテンシを隠す余地がほとんど残されません。詳細な結果分析は付録 6 を参照してください。
2.4 TLX を用いたワープ特化型マルチステージ融合
TLX (Triton Low-level Language Extensions) は、Triton の Python DSL と自動調整インフラストラクチャを維持しつつ、Hopper アーキテクチャのワープ特化機能、TMA(Tensor Memory Accelerator)、mbarriers(マルチスレッドバリア)、および名前付きバリアを公開します。
TLX を用いることで、2.3 節で述べたオキュパンシーの制限に、ワープ特化によって対処します。これは追加のワープを増やすのではなく、機能分割を通じてレイテンシを隠すアプローチです。
2.1 節から 2.3 節では、元の LCE(Latency-Critical Execution)を 2 つの独立した計算に分解しました:ユーザー GEMM(ステージ 1)と、融合されたブロードキャスト加算エピローグ付きの候補 GEMM(ステージ 2)です。まず、主要なボトルネックであるステージ 2 内のレイテンシ隠蔽を最適化し、その後両ステージを単一の永続的カーネルに融合します。
ステージ内レイテンシのオーバーラップ
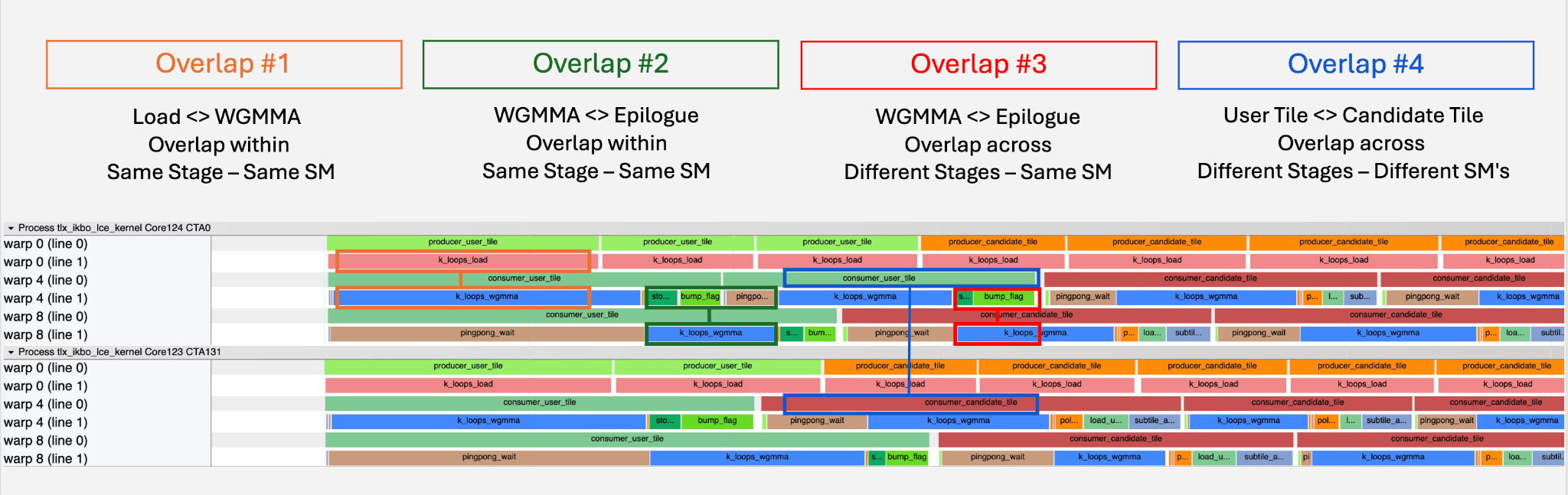
候補 IKBO カーネルはメモリーバウンドであり、設計目標はメモリーパイプラインを継続的に供給し続けることです。Triton のソフトウェアパイプライン(2.3 節)はすでに Load と WGMMA を重畳させていますが、エピローグは依然として直列化されており、これが将来の Load をブロックし、WGMMA の待機ストールを露呈させています。これら両方を解決するために、各 CTA を専用のワープグループに分割します:専用プロデューサーが TMA ロードを継続的に発行し(オーバーラップ #1、Triton のソフトウェアパイプラインに類似)、2 つのコンシューマーがタイルをピンポンさせ、一方のエピローグが他方の WGMMA と重畳するようにします(オーバーラップ #2)。永続性により、タイルはクロス・タイル間のギャップなく連続的に流れます。図 4 を参照してください。
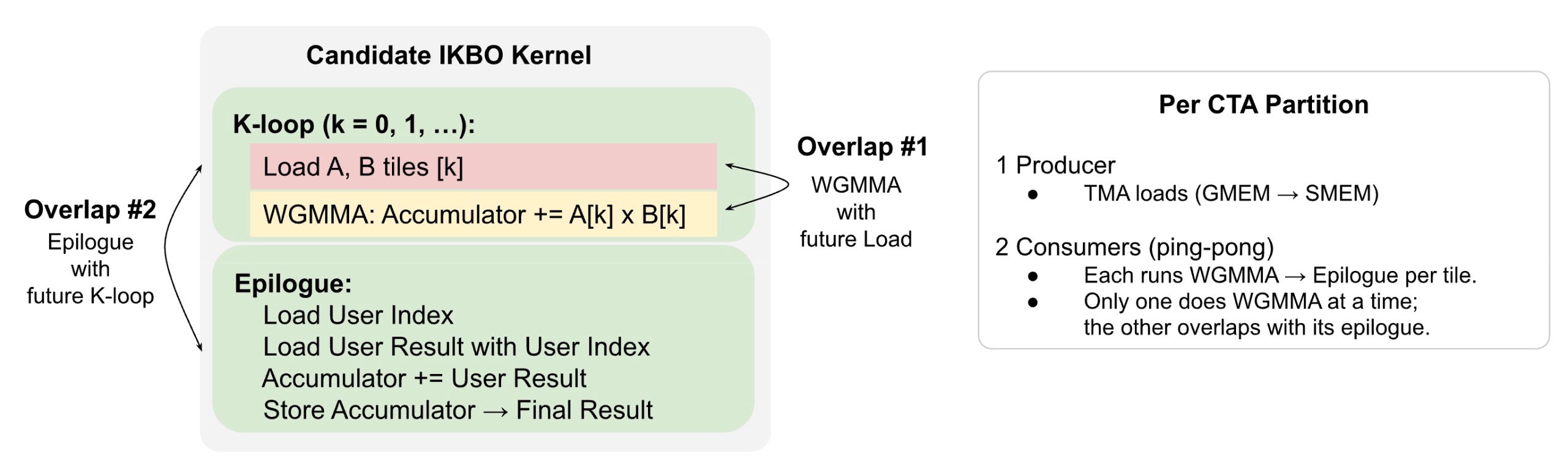
Fig. 4. 2 つのインターステージ遅延オーバーラップとワープグループ役割割り当てを備えた候補 IKBO カーネル構造。
マルチステージ融合
ユーザー IKBO(ステージ 1)と候補 IKBO(ステージ 2)を単一のメガカーネルに融合し、ウェーブ量子化を削減し、カーネル起動オーバーヘッドを排除し、L2 キャッシュ利用率を向上させます。高い候補対ユーザー比はステージ 1 におけるウェーブ量子化を増幅します。候補 GEMM はそのエピローグに至るまでユーザー結果とは独立しているため、両ステージを並行してスケジューリングします。
この並行スケジューリングにより、2 つの追加的なクロスステージオーバーラップが解放され、合計で 4 つのオーバーラップが可能になります。図 5 を参照してください。
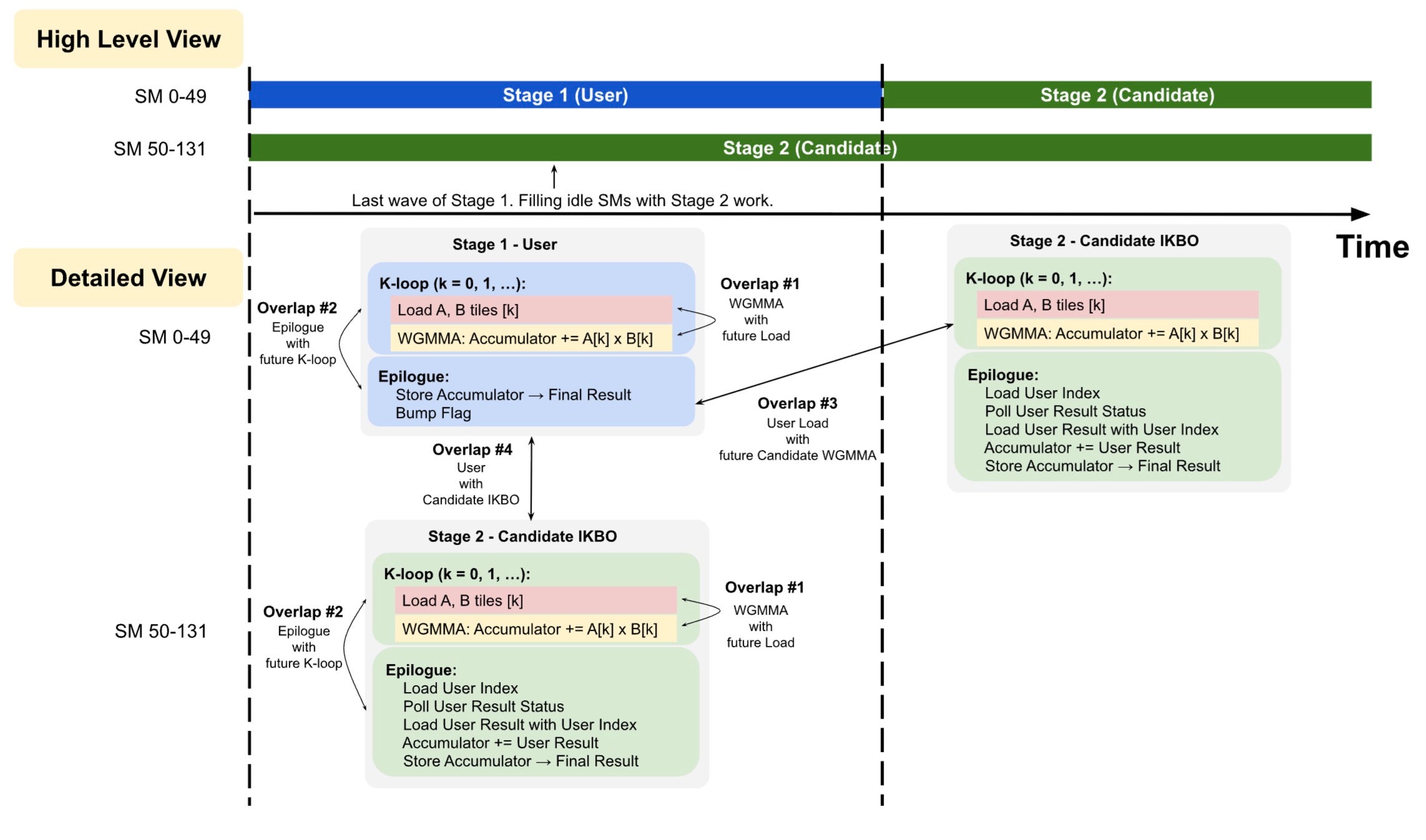
図 5. 並行ステージスケジューリング:ユーザータイルを持たない SM は、Stage 1 の部分的な波と重なるように即座に Stage 2 へ移行します。マルチステージ融合後にはすべての 4 つのレイテンシ重複が実現され、ステージ内(#1, #2)およびステージ間(#3, #4)の重複機会を示しています。SM 0-49 および 50-131 は例示の数値です。
ワープグループの専門化と同期設定
すべての 4 つの重複を実現するために、各 CTA(Cooperative Thread Array)は 1 つのプロデューサーワープグループと 2 つのコンシューマーワープグループに分割されます。極めて重要なのは、両ステージが同じ円形バッファおよび mbarrier インフラストラクチャを共有しており、ステージ境界においてパイプラインの排空やバリアの再初期化が行われないことです。最後のユーザー K ブロックと最初の候補 K ブロックは、異なるバッファスロットに同時に共存します。図 6 を参照してください。
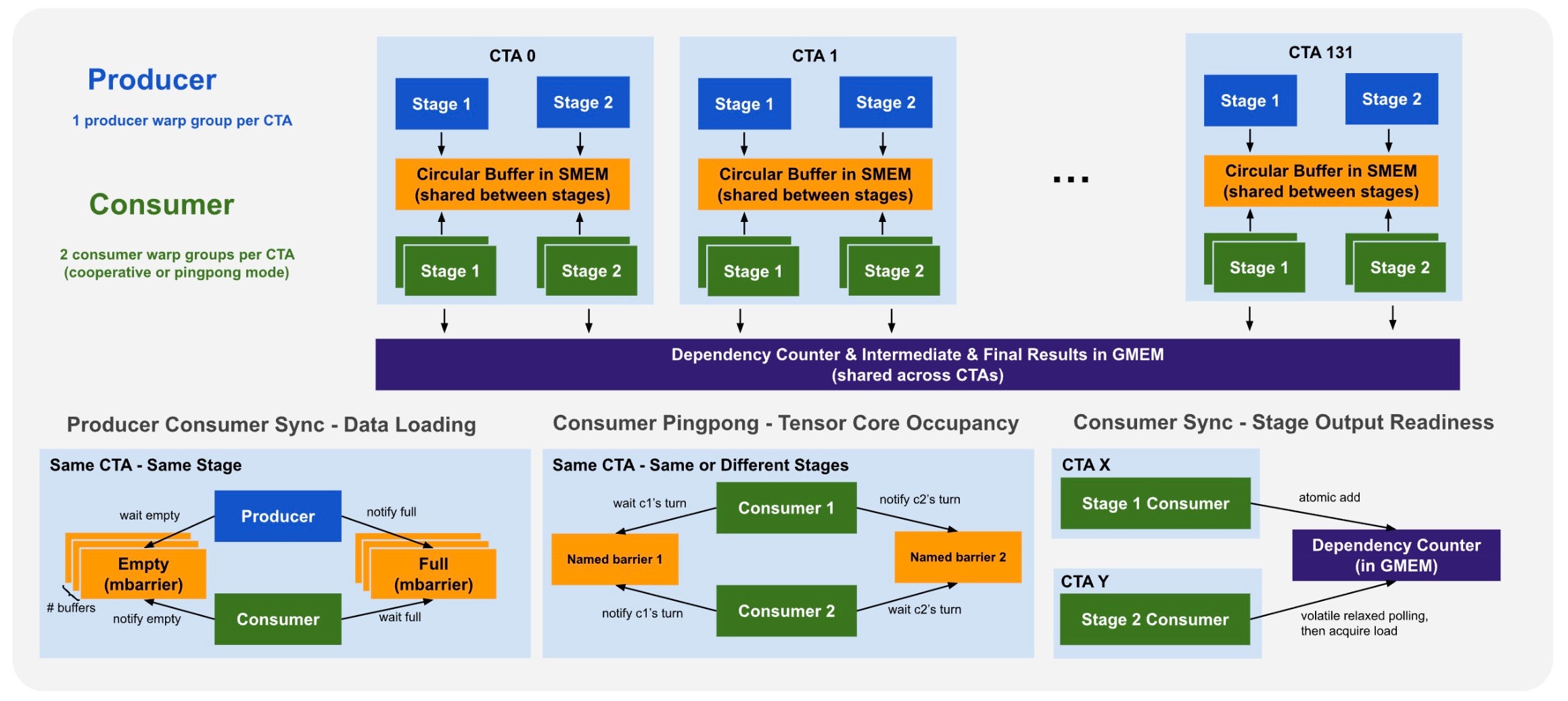
図 6. CTA ごとのワープグループ設定と、3 つの同期メカニズム。
双方向ステージ交互タイルスケジューリング
どちらのステージのタイル数も SM(Streaming Multiprocessor)数で割り切れない場合、単純な単方向ディスパッチではワークロードの不均衡が生じます。そこで、ステージ間でタイル割当の方向を反転させます:Stage 1 は pid から開始し、Stage 2 は NUM_SM - 1 - pid から開始します。図 7 を参照してください。
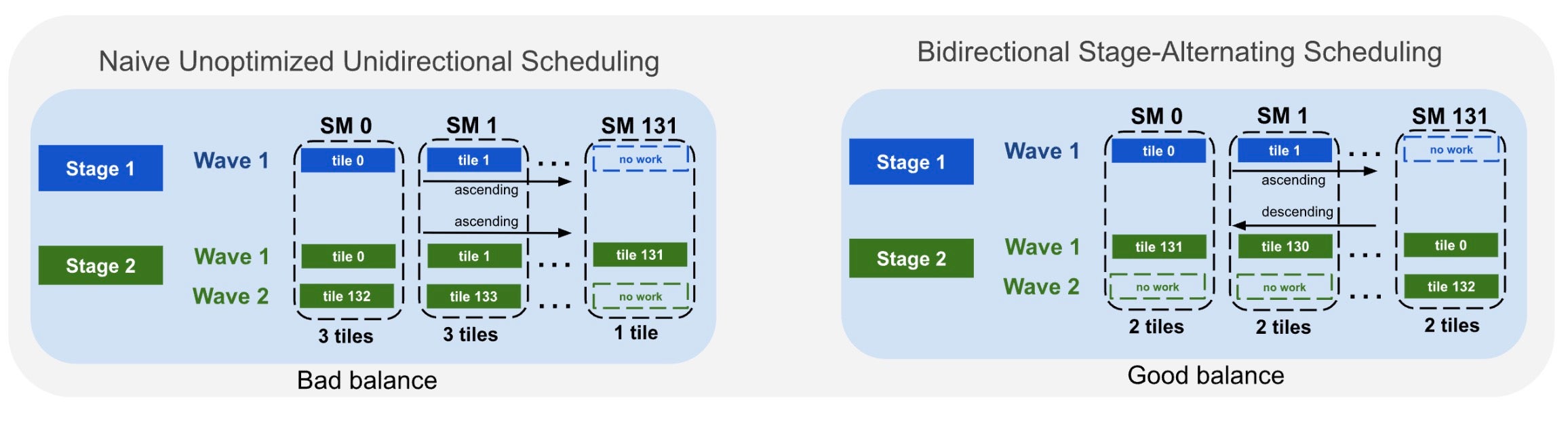
図 7. 単方向(左)と双方向ステージ交互ディスパッチ(右)の比較。部分的な波全体にわたって SM ごとのワークロードをバランスさせます。
タイル粒度の CTA 間同期
ユーザーと候補のタイルは異なる CTA で実行される可能性があり、CTA 間の同期が必要となりますが、デバイス全体のバリアを使用するとすべての作業が直列化され、重なり合いが破壊されてしまいます。そこで、3 ステップのリリース・アケアープロトコルを用いてタイルごとの粒度で同期を行います。
- ワープグループごとに 1 スレッドが ld.relaxed でタイルフラグをスピンし、メモリアクセス量を最小化します
- フラグが設定されると、単一の ld.acquire が happens-before エッジを確立します
- 名前付きバリアにより、ワープグループ内の全 128 スレッドに準備完了がブロードキャストされます
これにより、ポーリング中の高価なフェンスを回避でき、異なるユーザータイル上の候補 CTA を完全に独立して実行できます。詳細は付録 7 を参照してください。
結果
すべての最適化を組み合わせた結果、レイテンシが 0.580 ms から 0.482 ms に改善され(16.9% の削減)、明確なワープ内 Proton tracer タイムラインにより、4 つの重なり合いが実際に実現されていることが確認できました。
 image図 8. 2 つの CTA に対する Proton プロファイラーのタイムライン。すべての 4 つの重なり合いが色分けされています。メモリアクセスパイプラインは継続的に供給され続けています。
image図 8. 2 つの CTA に対する Proton プロファイラーのタイムライン。すべての 4 つの重なり合いが色分けされています。メモリアクセスパイプラインは継続的に供給され続けています。
主な効果はオーバーラップ#2から得られます:ピンポン方式のコンシューマーにより、すべてのタイル単位で WGMMA とエピローグのストールが隠蔽され、セクション 2.3 で指摘された支配的な無駄なサイクルに直接対処しています。オーバーラップ#1(ロード↔WGMMA)は、Triton の既存のソフトウェアパイプラインから継承されています。また、オーバーラップ#3 と #4 は、ユーザーから候補者へのステージ遷移におけるアイドル時間を隠蔽します。図 8 を参照してください。
NCU(NVIDIA Compute Profiler)による確認では、occupancy が 6.25% から 18.75% に上昇し(warp groups が 1 つから 3 つへ)、DRAM のスループットが 39% から 52% に、そしてボトルネックである L2 キャッシュの利用率がピーク比で 74% から 84% に向上しています。これは occupancy の向上だけでは説明できません:すべての 4 つのオーバーラップにわたる積極的なレイテンシ隠蔽によりメモリパイプラインが飽和状態を維持し、それが L2 を 80% を超える水準まで押し上げる要因となっています。詳細な NCU メトリクスは付録 8 に記載されています。
ベンチマークは、バッチサイズと候補者対ユーザー比率 across で実施され、デフォルト設定(batch=1024, ratio=70)を使用しています。図 9 を参照してください。
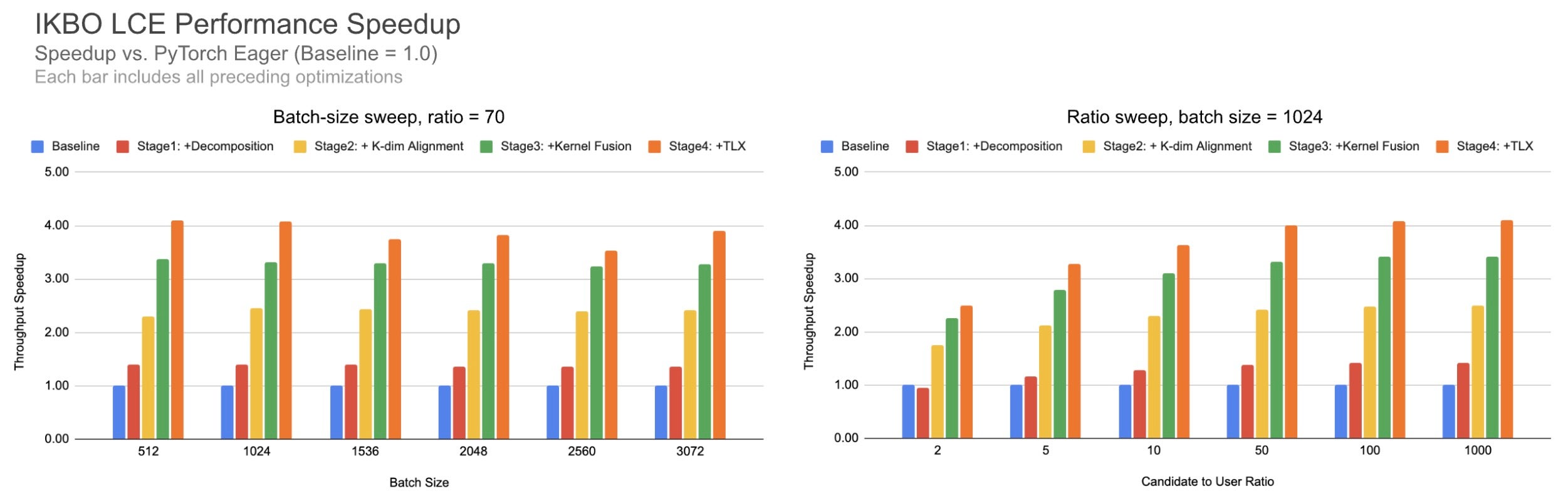
Fig. 9. バッチサイズ(左、ratio=70)および候補者対ユーザー比率(右、batch=1024)における累積 IKBO の高速化倍率。
IKBO フュージョンはあらゆるシナリオで堅牢な性能向上をもたらします:バッチサイズ across で約 4 倍の高速化(左)、および候補者対ユーザー比率 across でも同様の効果が見られます。低い候補者対ユーザー比率の場合でも、カーネルは依然として意味のある速度向上を達成しています。
3. カーネル深掘り II:IKBO Flash Attention
推薦モデルがより豊かなユーザーの逐次行動を捉えるためにスケールするにつれ、逐次アーキテクチャ – アテンションを含む – が重要な計算ボトルネックとして浮上し、1K のシーケンス長において推論レイテンシのおよそ40%を占めています。これが、RecSys のユニークなバッチ処理セマンティクスと共設計された IKBO 対応 Flash Attention への注目を促す動機となっています。
Transformers や Set Transformers [7, 8] に着想を得て、2 つの基本的なユーザー履歴相互作用モジュールが RecSys で広く採用されています:
- ターゲットアテンション(クロスアテンションに相当)は、予測候補とユーザーの過去の相互作用との間の関係を捉えます。
- セルフアテンションは、ユーザー履歴自体内の逐次的依存関係をモデル化します。
ユーザー履歴は RO 特徴でありながら、ターゲットは異なる候補(非 RO)バッチ次元上で動作するため、このアーキテクチャ的非対称性は IKBO を用いてモデルのスケーラビリティと計算効率を向上させる機会を提供しています。ターゲットアテンションが最適化の主な焦点となりますが、わずかな共設計により、セルフアテンションもセクション 3.3 で IKBO ターゲットアテンションに融合可能です。当モデルはエンコーダー駆動型であるため、因果マスクなしでフルアテンションが適用されます。
e2e 共設計を活用した究極の最適化されたターゲットアテンションバージョンは、非共設計の CuTeDSL FA4-Hopper(アテンションカーネルのみ / アテンションカーネル+ブロードキャストコスト)と比較してスループットを 2.4 倍/6.4 倍に向上させ、それぞれ0.320ms / 1.232msのレイテンシ削減を実現します(Table. 2)。
3.1 IKBO flash attention solves the IO bound issues under RecSys boundary conditions
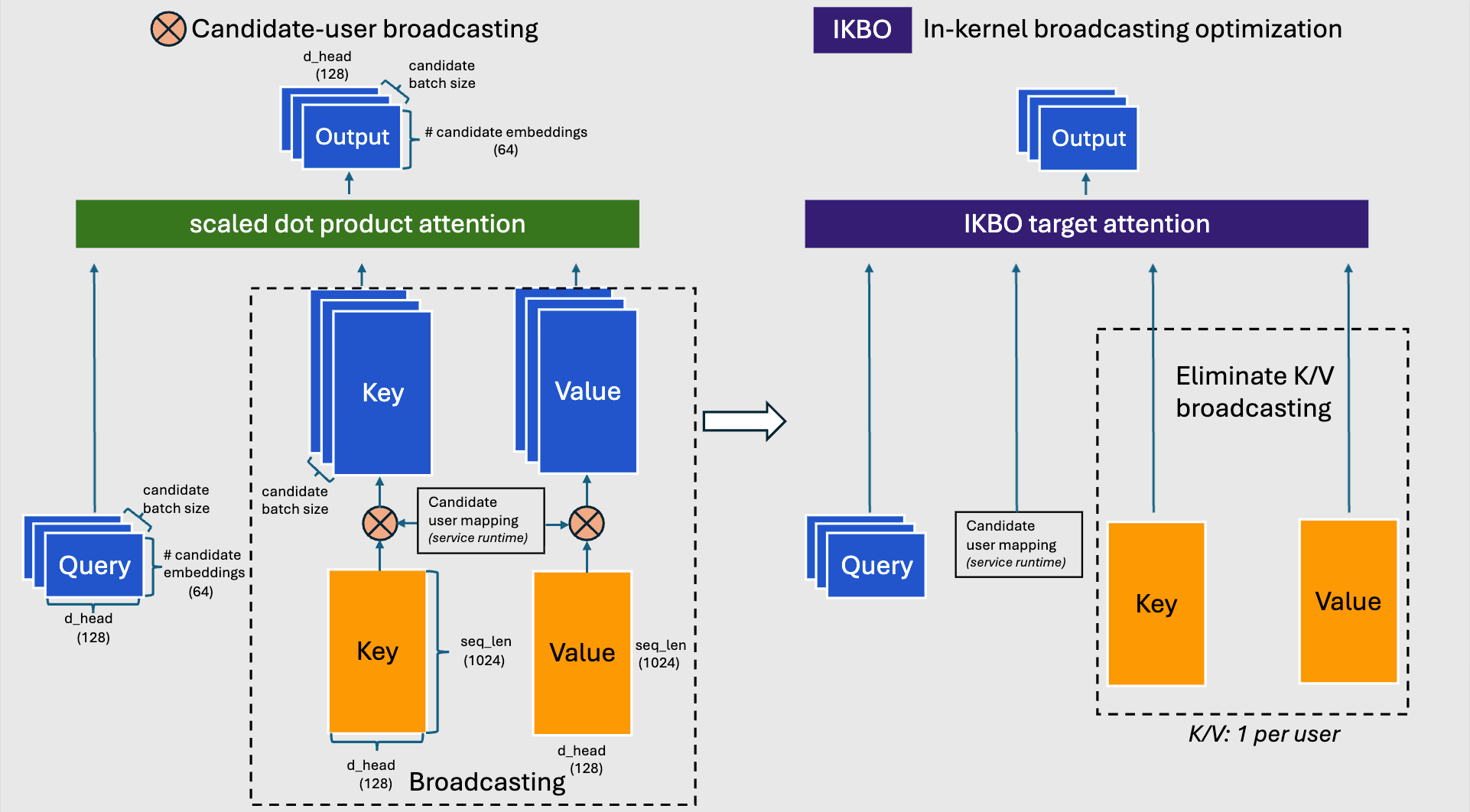 imageFig. 10: Traditional SDPA with candidate-user broadcasting (left) vs. fused IKBO target attention (right).
imageFig. 10: Traditional SDPA with candidate-user broadcasting (left) vs. fused IKBO target attention (right).
IKBO fuses K/V broadcasting into the attention kernel, maintaining mathematical equivalence via a candidate-user mapping tensor from the inference runtime that handles non-uniform candidate-to-user ratios. Fig. 10 contrasts the two approaches: the traditional SDPA path broadcasts K and V to the full candidate batch size before attention, while the IKBO path eliminates this materialization entirely — each candidate indexes into its user's K/V on the fly.
Shifting IO-Bound to Compute-Bound by IKBO co-design
In RecSys boundary conditions, target attention uses a relatively small number of candidate embeddings to represent the candidate attributes compared to the user's browsing history. Roofline analysis of standard attention reveals an arithmetic intensity of ~60 FLOPs/Byte – well below the H100 (SXM5 HBM2e version) peak of ~495 FLOPs/Byte (Appendix 2)—making even standard flash attention heavily IO-bound. IKBO addresses this by amortizing K/V memory accesses across multiple candidates sharing the same user context, improving arithmetic intensity from ~60 FLOPs/Byte to ~833 FLOPs/Byte (at B_candidate : B_user = 70:1) and shifting the kernel firmly into compute-bound territory.
この恩恵を最大化するため、実装ではスレッドブロック起動グリッドの順序を入れ替え、batch_size_candidate を num_heads の前に配置しています。これにより、異なる候補を処理するが同じユーザー K/V を共有するスレッドブロックが並列にスケジュールされ、L2 キャッシュの再利用性が向上します。
Grid dimension
Flash attention (SDPA)
IKBO target attention
x
num_q_seq_block
num_q_seq_block
y
num_heads
batch_size_candidate
z
batch_size_candidate
num_heads
Table 1: Launch grid configuration comparison. SDPA prioritizes GQA optimization by placing num_heads in grid.y. IKBO swaps head and candidate dimensions, placing batch_size_candidate in grid.y to enable efficient K/V sharing across candidates.
Table 2 compares our IKBO Triton implementation (FA2 logic + IKBO) against state-of-the-art Flash Attention implementations on Hopper (without IKBO co-design). Throughput and IO are measured on attention only; the broadcasting latency for Key and Value is even larger than the attention cost itself.
Throughput (TFLOPs/s)
IO (GB/s)
Latency (ms)
Triton IKBO FA2
425
487
0.321 (broadcast fused)
TLX FA3
245
2152
0.561 + 0.912 (broadcast K&V)
CuTeDSL FA4 Hopper
250
2193
0.550 + 0.912 (broadcast K&V)
TLX IKBO FA3 persistence generalized
594
681
0.230 (broadcast fused)
Table 2: Attention kernel comparison under RecSys boundary conditions (B_candidate = 2048, B_u = 32, uniform candidate-to-user ratio). Without co-design, even cutting-edge Hopper implementations remain IO-bound.
3.2 TLX における IKBO との併用による現代的カーネル技術(FA3, FA4)の採用
IKBO によってカーネルが I/O バウンドから計算バウンドへとシフトしたことで、自然な次のステップとして、Hopper アーキテクチャ上の Flash Attention 3 (FA3 [10]) および Flash Attention 4 (FA4 [11]) から得られる最先端の計算最適化手法、具体的にはワープ特化(warp specialization)とパイプライン処理を採用することが検討されました。しかし、クエリ埋め込みベクトルの数に関する境界条件(q_seq = 32 または 64)により、FA3 のピンポン方式や協調型ワープ特化をそのまま採用することは困難です。
Hopper におけるワープ特化には非同期 WGMMA 命令が必要であり、これは最小 BLOCK_M ≥ 64 を課します。また、これら間のバブル(アイドル時間)を最小限に抑えるためには、2 つのコンシューマーワープグループも必要となります。これらの制約を満たすために、私たちはカーネルをカスタマイズし、単一のスレッドブロック内で B_candidate = i および B_candidate = i + 1 の両方を起動し、同じ B_user を共有するようにしました。以下の議論では、すべてのユーザーが偶数個の候補をランク付けし、q_seq = 64 と仮定します。奇数個の候補に対する処理はその後で説明します。
IKBO FA3 カーネルのパフォーマンス向上
FA3 のレシピ(ワープ内パイプライン化、ワープグループ特化、ピンポンスケジューリング)を出発点として、初期の TLX IKBO FA3 カーネルは FA2 ベースラインと同様の性能を示しました(図 12、青線と赤線の比較、付録 11)、スループットも同等でした。
ボトルネックを診断するために、GPU サイクルを遅延単位として用いた Proton tracer を使用して、ワープ内パイプライン化を可視化しました(図 10)。表 3 は、Proton tracer を通じて GPU サイクル単位で測定した、永続化前後の主要なボトルネックを要約しています。
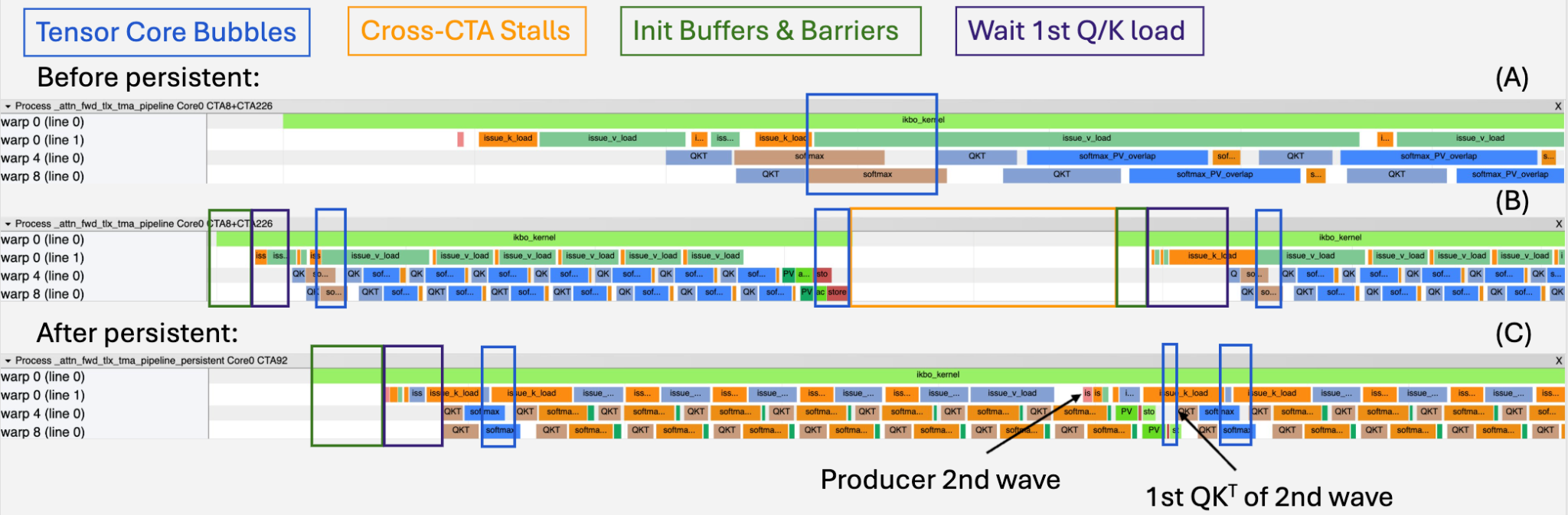 image図 11: TLX IKBO FA3 カーネルにおける Proton ベースのワープ内プロファイリング。各ワープグループから代表となるワープを示しています:ワープ 0(生産者)、ワープ 4(消費者 1)、およびワープ 8(消費者 2)。テンソルコアのバブルを特定するために、softmax_PV_overlap および純粋な softmax の領域は別々にマーキングされています。(A) 永続化前の拡大ビュー (B) 永続化前(2 ウェーブ)(C) 永続化後(2 ウェーブ)
image図 11: TLX IKBO FA3 カーネルにおける Proton ベースのワープ内プロファイリング。各ワープグループから代表となるワープを示しています:ワープ 0(生産者)、ワープ 4(消費者 1)、およびワープ 8(消費者 2)。テンソルコアのバブルを特定するために、softmax_PV_overlap および純粋な softmax の領域は別々にマーキングされています。(A) 永続化前の拡大ビュー (B) 永続化前(2 ウェーブ)(C) 永続化後(2 ウェーブ)
ボトルネック
前
後
主要な変更点
テンソルコアのバブル(各ウェーブの初回 QKT、青)
約 1,300 サイクル(ワープスケジューラの切り替えによる 400 サイクルを含む)
約 1,300 サイクル
不変
テンソルコアのバブル(各ウェーブの最終 PV、青)
約 2,000 サイクル
約 300 サイクル
非同期 TMA ストアと最終 PV の重なり
CTA 間のストール(オレンジ)
約 14,000 サイクル
排除
永続化により CTA の再起動が完全に不要に
バッファおよびバリアの初期化(緑)
ウェーブあたり約 1,600 サイクル
約 1,600 サイクル(初回ウェーブのみ)
永続化により、バッファとバリアがウェーブ間で共有され、コストが分散される
Wait 1st Q/K Load (Dark purple)
2,100~4,000 cycles/wave (length varies depending on HBM bandwidth contention)
~2,000 cycles (1st wave only)
Cross-wave pipelining; producer prefetches ~3K cycles ahead
Table 3: Key bottlenecks before and after persistence + optimizations.
Key takeaway: cross-CTA stalls are the dominant bottleneck — not tensor core utilization – at these small query sequence lengths. Persistence is a must for this improvement. After persistence, the profiling results and its latency changes are presented in Fig. 11C and Table. 3.
HBM2e-Specific Optimizations
We further tuned the persistent kernel for the H100 SXM5's HBM2e bandwidth constraints, trading shared memory capacity for reduced load/store blocking. (Table 4).
Customized optimization/fix
Benefit
Decoupled SMEM buffer of O from Q/V with pipelined TMA async store
Decoupled O from Q/V SMEM sharing enable TMA async stores could overlap with next-wave compute, shortening store blocking time from 1,300 to 400 cycles/wave
Separate Q₀ and Q₁ buffers
Reduces per-Q loading time, allowing one consumer group starts earlier— beneficial when wave count greatly exceeds K/V sequence iterations (common in RecSys)
Instruction Cache Misses fix
Merges the peeled-out last-iteration code path back into the main loop, eliminating icache thrashing caused by excessive warp-specialized instructions (Appendix 12)
Table 4: HBM2e H100 SXM5 向けのカスタム最適化。これらは、RecSys の境界条件(付録 10)の下で利用可能な SMEM バジェット内に収まります。
また、K シーケンスの末尾から先頭へ反復する永続型 V2 も実装しました(FA3/FA4-Hopper のアプローチに合わせることで、マスキングロジックを簡素化)。両方の永続型バリアントは Table 4 の最適化を適用しています。Fig. 12 に示す通り、シーケンス長が短い場合(512〜4,096)では TLX FA3 永続カーネルが他のすべての候補を上回りますが、8K を超えると両方の永続型バリアントは収束します。
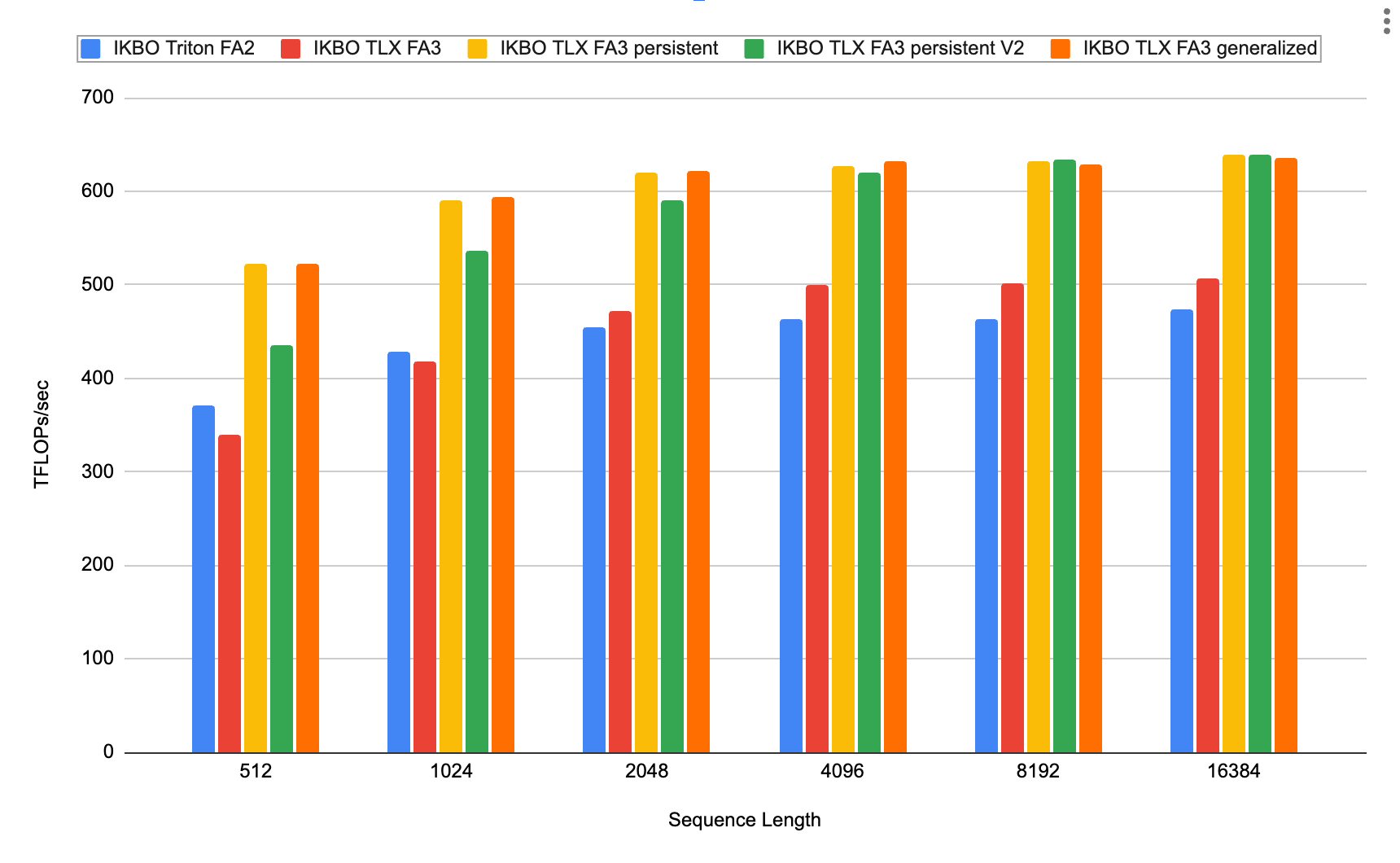 imageFig. 12: IKBO 実装のスループット対シーケンス長(B_candidate = 2,048; B_candidate : B_user = 64; num_head = 2; d_head = 128)。実用的な RecSys のシーケンス長は 4K 未満 [3] です。より長い長さは LLM ユースケースとの比較のために含めています。一般化されたバージョンでは、ユーザーごとの候補数が偶数でない場合も扱い、ユーザーあたり 50% の確率で奇数の候補を持つことをサポートします。
imageFig. 12: IKBO 実装のスループット対シーケンス長(B_candidate = 2,048; B_candidate : B_user = 64; num_head = 2; d_head = 128)。実用的な RecSys のシーケンス長は 4K 未満 [3] です。より長い長さは LLM ユースケースとの比較のために含めています。一般化されたバージョンでは、ユーザーごとの候補数が偶数でない場合も扱い、ユーザーあたり 50% の確率で奇数の候補を持つことをサポートします。
任意の候補バッチサイズに対する IKBO FA3 の汎用化
私たちの IKBO FA3 カーネルは、WGMMA の BLOCK_M ≥ 64 という要件を満たすために、1 つの CTA(Compute Thread Array)あたり 2 つの候補バッチを並列処理します。ユーザーの候補数が奇数の場合、1 つのコンシューマー・ワープグループにはペアとなる相手が存在しません。これをアイドルロジックで処理します(Fig. 13 左側; アルゴリズム 1):
- アイドル状態のワープグループは、mbarrier シグナリングを介して K/V バッファを排空し、プロデューサーのデッドロックを防ぎます。
- アクティブなワーpgroup はピンポン同期を無効化します(そのパートナーは指定されたバリアに到達しなくなります)。
候補対ユーザー比が約 70:1 の場合、アイドルパスのトリガー頻度は 0.7% 未満であり、オーバーヘッドは無視できるほど小さいです(図 12、IKBO TLX FA3 一般化)。このアプローチは q_seq_len = 32 の場合にも一般化可能で、同様のアイドルおよびマスキングロジックを用いて CTA ごとに 4 つの候補バッチをバンドルします。
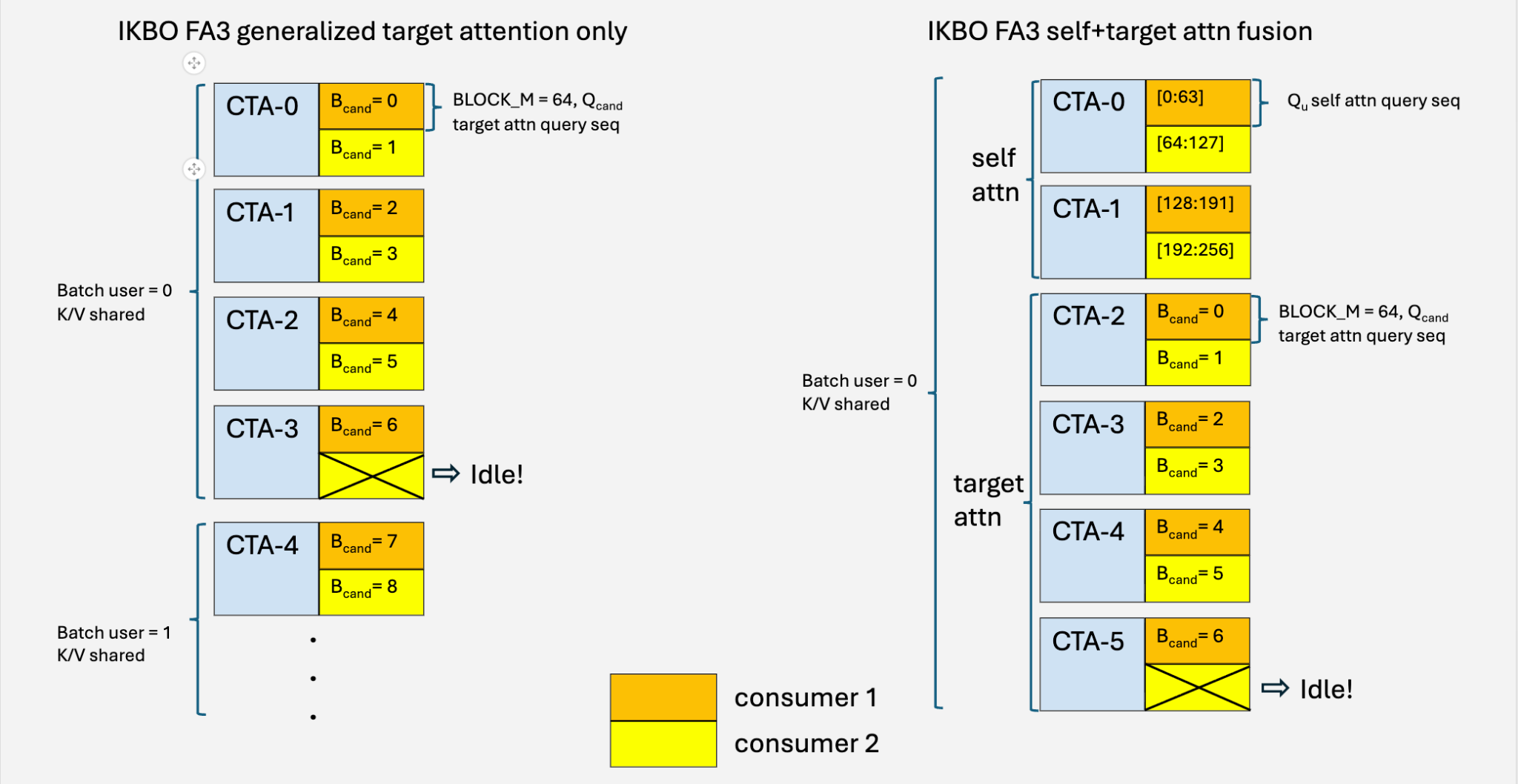 image図 13: 一般化されたターゲットアテンション(左)および自己+ターゲットアテンション融合(右)における CTA の割り当て。各 CTA は、同じユーザー K/V を共有する 2 つのコンシューマーワーpgroup に割り当てます。候補数が奇数の場合、2 つ目のコンシューマーはアイドル状態となり、バリアをドレインします。
image図 13: 一般化されたターゲットアテンション(左)および自己+ターゲットアテンション融合(右)における CTA の割り当て。各 CTA は、同じユーザー K/V を共有する 2 つのコンシューマーワーpgroup に割り当てます。候補数が奇数の場合、2 つ目のコンシューマーはアイドル状態となり、バリアをドレインします。
 image
image
アルゴリズム 1: 奇数個の候補処理を含む IKBO アテンション順伝播
3.3 モデル共設計による自己+ターゲットアテンション融合
前節では、ターゲット(クロス)アテンションの最適化に焦点を当てました。自然な疑問として、自己アテンションも同じカーネルに折りたたむことは可能でしょうか?
重要な洞察は、両方のアテンションタイプが同じキー・バリュー(Key-Value)ソースであるユーザーシーケンスを共有している点です。唯一の違いはクエリ(Query)で、自己アテンションのクエリはユーザー側から、ターゲットアテンションのクエリは候補側から来ます。この 2 つ間で K/V プロジェクションを共有することで、単一の起動内で直接水平方向のカーネル融合が可能になります。図 13(右)には、融合された CTA レイアウトが示されています:最初の CTA が自己アテンションのクエリブロックを処理し、残りの CTA がターゲットアテンションの候補ペアを処理しますが、すべて同じパイプライン化された K/V ストリームから読み込まれます。
同様の共設計(co-design)のアイデアは、X 社によるオープンソース推薦システムである XAI Phoenix でも探索されています [4]。
K/V プロジェクションの節約効果を除いた融合カーネルのプロトタイプを作成し、融合による恩恵を定量化しました(図 13、右側):
- seq_len = 512: 6.6% の改善(514 vs. 482 TFLOPs/s)
- seq_len = 1,024: 4.1% の改善(581 vs. 558 TFLOPs/s)
- seq_len = 2,048: 0.3% の改善(612 vs. 610 TFLOPs/s)— 自己アテンションが SM を飽和させる
短いシーケンスにおける性能向上は、カーネル融合による恩恵に起因します:起動オーバーヘッドの削減、共有バッファ割り当ての節約、クロスカーネルのパイプライン化の機会、およびウェーブ量子化(wave quantization)の緩和です。これらは、LLM 推論においてメガカーネル手法 [12] が対象とする非効率性と同じものです。本番環境では、共有された K/V プロジェクションが線形投影コストに追加の節約効果をもたらし、これは KV キャッシュ(KV cache)の再利用に類似しています。
4. ベンチマークと結果の要約
本稿で紹介したカーネルレベルのベンチマークと、エンドツーエンドでの展開結果を要約します。以下のすべてのカーネルベンチマークは H100 SXM5 環境で実施されています(詳細は付録 1 を参照)。
- リニア圧縮 (2 節)。行列乗算の分解、メモリアライメント、ブロードキャスト融合、そして TLX によるワープ特化型多段融合という 4 つの段階的な共設計アプローチが、代表的な設定において累積で約 4 倍の高速化(1.944 ms → 0.482 ms)を実現しました。この性能向上は、バッチサイズや候補者対ユーザー比率を変えても堅牢に維持されます(図 9)。
- Flash Attention (3 節)。IKBO は、ターゲットの注意機構を入出力束縛型(約 60 FLOPs/Byte)から計算束縛型(約 833 FLOPs/Byte)へシフトさせ、非共設計の CuTeDSL FA4-Hopper(カーネルのみ / カーネル+ブロードキャスト)と比較して、それぞれ 2.4 倍/6.4 倍のスループットを達成しました。これは 621 BF16 TFLOPs の性能に相当します。
- エンドツーエンド展開。IKBO は Meta の推薦システム推論スタック全体に広く展開されており、初期段階から後期段階のランキングモデルに至るまで、GPU および MTIA アクセラレータの両方で利用されています。これにより、共設計モデルにおいて計算集約的なネットレイテンシを最大で 2/3 削減することに成功しました。IKBO は、候補者対ユーザーブロードキャスト比率が約 10,000:1 から約 10:1 に至る幅広い範囲で検証され、あらゆるワークロードにおける数値的安定性とスケーラビリティが確認されています。
5. 結論と今後の方向性
IKBO は、ブロードキャストをユーザーと候補の相互作用における避けられないコストとして長年扱われてきたが、カーネル・モデル・システムの協調設計を通じて計算原語レベルで排除できることを実証している。ブロードキャストの意味論をカーネルに直接エンコードすることで、複製されたテンソルは一切生成されず、その節約効果は候補対ユーザーの比率に応じて自然に拡大する。
本稿で提示したカーネル実装は NVIDIA Hopper 向けに Triton と TLX を通じてターゲット化されているが、核となるアイデア — 物質化されたブロードキャストをインデックス駆動型のカーネル内ルックアップに置き換えること — はハードウェアベンダーに依存しない。IKBO カーネルを CuTeDSL(高度な NVIDIA バックエンドサポート用)へ適応し、AMD CK サポートを完成させることは自然な次のステップである。
ここで提示した 2 レベルのユーザー・候補階層を超え、一部の推薦システム (RecSys) シナリオではより深い階層が存在する — 例えば「ユーザー → 広告出品者 → 広告アイテム」という構造で、各ユーザーは複数の出品者を見、各出品者は複数のアイテムを提供する。これにより、独立した非一様比率を持つ 2 つのネストされたブロードキャスト関係が生じる。IKBO はこれを優雅に処理でき、マルチレベルワークロードへの適用は、本番環境の推薦システム (RecSys) アーキテクチャにおける物質化オーバーヘッドをさらに削減するための自然な方向性である。
Acknowledgements
私たちは Hongtao Yu、
原文を表示
**
Featured projects
-
TL;DR:
- Traditional RecSys inference explicitly replicates shared user embeddings/sequences for every candidate. In-Kernel Broadcast Optimization (IKBO) eliminates this overhead via a kernel-model-system co-design that fuses broadcast logic directly into user-candidate interaction kernels. By decreasing both the memory footprint and IO utilization, IKBO unlocks even higher throughput.
- IKBO delivers up to a 2/3 reduction in compute-intensive net latency, serving as the scalability backbone for the request-centric, inference-efficient framework that powers the Meta Adaptive Ranking Model.
- Deployed end-to-end across Meta’s multi-stage recommendation funnel on both GPU and MTIA (Meta Training and Inference Accelerator).
- The IKBO Linear Compression kernel achieved a cumulative ~4× speedup on H100 SXM5 after four stages of progressive co-design, culminating in warp-specialized fusion via TLX.
- The IKBO co-design shifted the Flash Attention kernel from IO-bound to compute-bound (hitting 621 BF16 TFLOPs on H100 SXM5). Coupled with TLX warp-specialized optimization, this results in a 2.4x/6.4× throughput gain over the non-co-designed CuTeDSL FA4 Hopper baseline (kernel only/kernel + broadcasting).
In this post, we present In-Kernel Broadcast Optimization (IKBO), a kernel-model-system co-design approach that eliminates redundant user-embedding broadcast in recommendation model inference. In production RecSys, user embeddings are identical across all candidates for a given request, yet standard approaches require explicit replication, wasting memory bandwidth and compute that scale with candidate count. IKBO encodes a simple insight: broadcast is a data layout concern, not a computational necessity. Each IKBO kernel accepts user and candidate inputs at their natural, mismatched batch sizes and handles broadcast internally, so no replicated tensors ever materialize. We showcase the methodology through two kernel deep dives: Linear Compression and Flash Attention.
Deployed across Meta’s RecSys inference stack—from early-stage to late-stage ranking models, spanning both GPU and MTIA (Meta Training and Inference Accelerator)—IKBO delivers up to a 2/3 reduction in compute-intensive net latency on co-designed models. It serves as the scalability backbone for the request-centric, inference-efficient framework underlying the Meta Adaptive Ranking Model (serving LLM-scale models in production). On H100 SXM5, our IKBO Linear Compression kernel achieves ~4× speedup through four progressive co-design stages: matmul decomposition, memory alignment, broadcast fusion, and warp-specialized multi-stage fusion via TLX (Triton Low-Level Extensions). For Flash Attention, IKBO delivers a 2.4×/6.4× throughput compared to non-co-designed CuTeDSL FA4-Hopper (kernel only / kernel + broadcasting) with 621 BF16 TFLOPs. Unlike system-level broadcast or net-splitting that work around replication, IKBO eliminates it at the computational primitive layer, achieving dense interaction quality at near-independent cost.
Code Repository: https://github.com/pytorch/FBGEMM/tree/main/fbgemm_gpu/experimental/ikbo
† *Work done while at Meta*
1. In-Kernel Broadcast Optimization: Eliminating Memory and Compute Redundancy
When a user opens their feed, the recommendation system must score hundreds to thousands of candidate items to decide what to show. The model’s inputs split into two categories: user features (e.g., browsing history, profile, context) that are identical for every candidate in a request, and candidate features (e.g., item ID, category, engagement statistics) that are unique to each item. Both pass through embedding lookups and subsequent processing to produce embedding representations. At various points in the model, interaction layers (e.g., linear projections, feature crosses, target attention) combine user and candidate embeddings. We call embeddings shared across all candidates in a request Request-Only (RO), and per-candidate embeddings Non-Request-Only (NRO)**.
Fig. 1. A very simplified RecSys inference data flow. Request-Only (RO) user embeddings must be broadcast (replicated) to match the Non-Request-Only (NRO) candidate batch dimension before interaction layers. IKBO eliminates this materialization by handling broadcast internally within each kernel.
Interaction layers require tensors with matching batch dimensions. In a batch of 1,024 candidates served by ~15 users, RO embeddings must be broadcast, replicated ~70 times, to match the NRO batch size before any interaction (Fig. 1). As architectures have evolved from DLRM [1] and DCN [2] through sequential models like HSTU [3] and X’s Phoenix [4], they have steadily enriched user-candidate interaction. But richer interaction comes at a cost: user features must be broadcast across all candidates. For batch sizes of 10 – 10,000+ in inference, this replication overhead incurs significant computation and memory cost that scales linearly with candidate count.
Broadcast is a data layout concern, not a computational necessity. Viewing the model and inference system through this lens opens optimization at every layer: the inference runtime eliminates system-level broadcast, user-only model layers run at the smaller user batch size, and kernels that mix both are redesigned to handle broadcast internally—no replicated tensors ever materialize. Deployed across Meta’s RecSys inference stack, from early-stage to late-stage ranking models, spanning both GPU and MTIA, IKBO delivers up to 2/3 reduction in compute-intensive net latency on co-designed models.
This post focuses on the kernel layer through two deep dives: Linear Compression and Flash Attention.
1.1. Kernel Optimization Type
Type I — Decomposable Operations. Mathematical restructuring lets the Request-Only (RO) portion be computed independently at small batch size, combining with the Non-Request-Only (NRO) portion only at the end. This saves both memory bandwidth and compute.
Type II — Memory-Only Optimization. Handling RO-NRO broadcasting within the kernel avoids redundant data movement, pushing the kernel away from IO bound.
1.2. E2E System Design
Deploying IKBO touches three layers of the infra stack:
- Kernels: Custom GPU kernels that accept mismatched RO/NRO batch sizes and handle broadcast internally (Sections 2 and 3).
- Compilation Specification: The ML compiler needs per-operator dynamic shape ranges to select appropriately shaped kernels. With one batch size this is trivial; with two (user and candidate) or even more, reliably resolving which each operator uses—across production models where interactions obscure batch lineage—requires systematic automation.
- Inference: The runtime passes the candidate-to-user mapping into the model instead of materializing the broadcast.
These kernels enter the model through one of two paths:
- Direct adoption: Model authors integrate IKBO kernels directly into their model definitions. When candidate-to-user ratio > 1 during training, the same kernels reduce training cost as well.
- Inference-time transformation: A pass automatically swaps standard ops for IKBO equivalents at inference time — no model code changes required.
The net effect: broadcast disappears from every stage of inference, with no architectural constraints on the model and no infrastructure changes beyond the inference runtime’s mapping interface.
1.3. Comparison with Other Approaches
Existing approaches work around broadcast rather than eliminating it.
- System-level broadcast materializes the replicated tensor before GPU dispatch—simple but wasteful, with cost scaling linearly with candidate count.
- Net-splitting (ROO) [5] partitions the model into RO and NRO sub-networks, reducing redundant work but constraining where user-candidate interactions can occur and still introduce extra cost at small RO batch sizes.
Both preserve broadcast as a materialized tensor. IKBO eliminates it at the computational primitive layer: savings scale with the candidate-to-user ratio, any interaction pattern works without broadcast cost, and the full NRO batch dimension provides GPU occupancy within fused kernels.
IKBO has been deployed on both GPU and MTIA accelerators. In this blog post, we focus on H100 GPU kernel design to illustrate the core optimization principles.
2. Kernel Deep Dive I: IKBO Linear Compression
Linear Compress Embedding (LCE) compresses input embeddings (B, K, N) via a learned projection (M, K) @ (B, K, N) → (B, M, N), and is widely adopted in Meta RecSys models, e.g., Wukong [6]. We go through four progressive optimization stages.
2.1 Matmul Decomposition
Fig. 2. LCE decomposition: baseline batched matmul (top-left), embedding separation and user deduplication along K (top-right), two independent GEMMs with broadcast-add on compressed output (bottom).
The baseline LCE computes a single batched matmul across all B candidates. The input embeddings concatenate user and candidate parts along K — but user embeddings are identical across all candidates for the same user.
Push broadcast past the matmul. Since W is batch-independent, we decompose by linearity: separate user and candidate embedding blocks along K, deduplicate the repeated user embeddings, and compute two independent GEMMs at their natural batch sizes. Instead of replicating user embeddings before the matmul, we broadcast only the small compressed result. See Fig. 2. With a candidate-to-user ratio of ~70 (a representative setting), the user batch shrinks from B=1024 to B_user ≈ 15 — a 70x reduction in user-side compute. The decomposition is implemented in standard PyTorch.
Result. 1.944 ms → 1.389 ms (28.5% reduction; benchmark setup in Appendix 1). Both the original batched GEMM (arithmetic intensity ~ 356 FLOPs/Byte, below H100’s ~495 FLOPs/Byte machine balance point; see Appendix 2 for derivations) and the two decomposed GEMMs are memory-bound, so the speedup is driven by memory cost reduction. Deduplication cuts memory cost more than half — as the user-side GEMM (B_user ≈ 15 vs. B = 1024) becomes negligible in cost.
Note that the decomposition pushes broadcast past the matmul: instead of replicating full K-dimensional input embeddings before the GEMM, we broadcast only the small compressed result, which is far cheaper. In Section 2.3, we will further eliminate this remaining broadcast entirely via in-kernel broadcast fusion.
The current bottleneck is L1/TEX pipeline utilization (84%) rather than DRAM utilization — a suspicious imbalance we will zoom into in the next section. Detailed profiling breakdown in Appendix 3.
2.2 Memory Layout Optimization
Detailed result analysis of the decomposed GEMM reveals an imbalance: L1/TEX sits at 84% of peak while DRAM reaches only 19%, indicating unnecessarily narrow memory loads. SASS confirms: every cp.async copies only 4 bytes instead of a single 128-bit load.
LDGSTS.E.LTC128B P0, [R203], [R38.64] // 4 bytes
LDGSTS.E.LTC128B P1, [R203+0x4], [R38.64+0x4] // 4 bytes (×4 total, only 16B load in total)
cp.async width is capped by the source pointer’s natural alignment. Matrix A is (M, K) row-major with stride K × 2 bytes, so when K is not a multiple of 8, the stride breaks 128-bit alignment.
Model-kernel co-design insights. Memory alignment is a well-understood GPU optimization — but decomposition turns it into a model-kernel co-design challenge. K is formed by torch.cat of embedding tensors whose sizes depend on many model config factors. Decomposition makes it very hard to manually engineer these factors so that decomposed embeddings remain perfect multiples. A systematic solution is needed.
Solution. Pad each decomposed K to the next multiple of 8 by appending zeros to the concat list. We prove this is mathematically equivalent in both forward and backward passes (see Proof 1 below), and with the ML compiler’s memory planner, reduces to a cheap constant copy.
**
Proof 1.** Zero-padding K preserves exact numerical equivalence in both forward and backward passes.
Result. 1.389 ms → 0.798 ms (42.5% reduction). Padding enables CUTLASS to select a TMA-based kernel, bypassing L1/TEX entirely (sectors 351M → 0) and cutting GEMM latency from 0.984 ms to 0.400 ms. With the GEMM resolved, the unfused broadcast and add (0.398 ms) now accounts for half the total latency — to be addressed in the next section. Detailed result analysis in Appendix 5.
2.3 Candidate GEMM In-Kernel Broadcast Fusion
The unfused broadcast and add are memory-bound: write the candidate GEMM result to HBM, read it back alongside the user result, add, and write again. We eliminate this by fusing the broadcast into the candidate GEMM epilogue (Fig. 3). After each tile’s accumulation, the epilogue looks up the user index, loads the pre-computed user result, adds it in registers, and writes the final sum — the intermediate tensor is never materialized. We implement this as a Triton kernel: a standard batched GEMM with a custom post-accumulation epilogue block.
Fig. 3. In-kernel broadcast fusion: the GEMM epilogue loads the pre-computed user result via index lookup and adds it in-register.
Result. 0.798 ms → 0.580 ms (27.4% reduction). Fusion eliminates 0.87 GB of intermediate DRAM traffic, contributing to the latency win. However, occupancy is just 6.25% (1 warp per scheduler), leaving every stall fully exposed. Beyond 42% of cycles waiting on global loads, 20% are spent waiting on WGMMA — stalls that cannot be hidden by the epilogue, and without persistence there is no next-tile load to overlap with. This is a challenging tradeoff: large tiles and deep pipelines are needed to keep tensor cores fed, but they consume most of the shared memory budget, leaving little room to hide latency through occupancy. Detailed result analysis in Appendix 6.
2.4 Warp-Specialized Multi-Stage Fusion with TLX
TLX (Triton Low-level Language Extensions) exposes Hopper’s warp specialization, TMA, mbarriers, and named barriers while preserving Triton’s Python DSL and autotuning infrastructure.
Using TLX, we address the occupancy limitation from Section 2.3 with warp specialization — hiding latency through functional partitioning rather than additional warps.
Sections 2.1 – 2.3 decomposed the original LCE into two independent computations: the user GEMM (Stage 1) and the candidate GEMM with fused broadcast-add epilogue (Stage 2). We first optimize latency hiding within Stage 2, the dominant bottleneck, then fuse both stages into a single persistent kernel.
Intra-Stage Latency Overlap
The candidate IKBO kernel is memory-bound — the design goal is to keep the memory pipeline continuously fed. Triton’s software pipelining (Section 2.3) already overlaps Loads with WGMMA, but the epilogue remains serialized — it blocks future Loads and exposes the WGMMA wait stalls. We resolve both by partitioning each CTA into specialized warp groups: a dedicated producer issues TMA loads continuously (Overlap #1, analogous to Triton’s software pipeline), while two consumers ping-pong tiles so one’s epilogue overlaps the other’s WGMMA (Overlap #2). With persistence, tiles flow continuously with no cross-tile gaps. See Fig. 4.
Fig. 4. Candidate IKBO kernel structure with two intra-stage latency overlaps and warp group role assignments.
Multi-Stage Fusion
We fuse user IKBO (Stage 1) and candidate IKBO (Stage 2) into a single mega-kernel to reduce wave quantization, eliminate kernel launch overhead, and improve L2 cache utilization. High candidate-to-user ratios amplify wave quantization in Stage 1. Since the candidate GEMM is independent of user results until its epilogue, we schedule both stages concurrently.
This concurrent scheduling unlocks two additional cross-stage overlaps, bringing the total overlaps to four. See Fig. 5.
Fig. 5. Concurrent stage scheduling: SMs without user tiles enter Stage 2 immediately, overlapping with Stage 1’s partial wave. All four latency overlaps after multi-stage fusion, showing intra-stage (#1, #2) and cross-stage (#3, #4) overlap opportunities. SM 0-49, 50-131 are example numbers.
Warp Group Specialization & Synchronization Setup
To realize all four overlaps, each CTA is partitioned into one producer and two consumer warp groups. Critically, both stages share the same circular buffer and mbarrier infrastructure — no pipeline drain or barrier reinitialization occurs at the stage boundary. The last user K-block and the first candidate K-block coexist in different buffer slots simultaneously. See Fig. 6.
Fig. 6. Per-CTA warp group setup and the three synchronization mechanisms.
Bidirectional Stage-Alternating Tile Scheduling
When neither stage’s tile count divides evenly by the SM count, naive unidirectional dispatch causes workload imbalance. We reverse tile assignment direction between stages: Stage 1 starts at pid, Stage 2 at NUM_SM - 1 - pid. See Fig. 7.
Fig. 7. Unidirectional (left) vs. bidirectional stage-alternating dispatch (right), balancing per-SM workload across partial waves.
Tile-Granularity Cross-CTA Synchronization
User and candidate tiles may execute on different CTAs, requiring cross-CTA synchronization — but a device-wide barrier would serialize all work and destroy the overlap. We synchronize at per-tile granularity using a three-step release-acquire protocol:
- A single thread per warp group spins on the tile flag with ld.relaxed, minimizing memory traffic
- Once set, a single ld.acquire establishes the happens-before edge
- A named barrier broadcasts readiness to all 128 threads in the warp group
This avoids expensive fences during polling and lets candidate CTAs on different user tiles proceed fully independently. Details in Appendix 7.
Results
With all optimizations combined, latency improves from 0.580 ms to 0.482 ms (16.9% reduction). The clear intra-warp Proton tracer timeline confirms all four overlaps are realized in practice.
**
Fig. 8.** Proton profiler timeline for two CTAs, with all four overlaps color-coded. The memory pipeline remains continuously fed.
The primary gain comes from Overlap #2: ping-ponging consumers hide WGMMA and epilogue stalls on every tile — directly addressing the dominant wasted cycles from Section 2.3. Overlap #1 (Load↔WGMMA) carries forward from Triton’s existing software pipelining. Overlaps #3 and #4 hide idle time at the user-to-candidate stage transition. See Fig. 8.
NCU confirms: occupancy rises from 6.25% to 18.75% (3 warp groups vs. 1), DRAM throughput from 39% to 52%, and L2 — the bottleneck — from 74% to 84% of peak. This is not occupancy alone: the aggressive latency hiding across all four overlaps keeps the memory pipeline saturated, which is what pushes L2 past 80%. Detailed NCU metrics in Appendix 8.
We benchmark across batch sizes and candidate-to-user ratios, with the default (batch=1024, ratio=70) settings. See Fig. 9.
Fig. 9. Cumulative IKBO speedup across batch sizes (left, ratio=70) and candidate-to-user ratios (right, batch=1024).
The IKBO fusion delivers robust gains across scenarios: ~4x speedup across batch sizes (left) and candidate-to-user ratios (right). Even at low candidate-to-user ratios, the kernel still achieves meaningful speedup.
3. Kernel Deep Dive II: IKBO Flash Attention
As recommendation models scale to capture richer user sequential behavior, sequential architectures – including attention – have emerged as a critical compute bottleneck, accounting for approximately 40% of inference latency at 1K sequence lengths. This motivates our focus on IKBO-aware Flash Attention, co-designed with RecSys’s unique batching semantics.
Inspired by Transformers and Set Transformers [7, 8], two fundamental user history interaction modules have been widely adopted in RecSys:
- Target attention (analogous to cross-attention) captures the relationship between the prediction candidate and the user’s historical interactions.
- Self-attention models sequential dependencies within the user history itself
Since user history is a RO feature while the target operates on a distinct candidate (non-RO) batch dimension, this architectural asymmetry presents an opportunity for IKBO to improve model scalability and computational efficiency. Target attention will be our main focus for optimization, while with minor co-design, self attention could also be fused into IKBO target attention in Section. 3.3. As our model is encoder-driven, full attention is applied without causal masking.
The ultimate optimized target attention version leveraging e2e co-design achieves 2.4×/6.4× the throughput of non-co-designed CuTeDSL FA4-Hopper (attn kernel only / attn kernel + broadcasting cost), reducing latency by 0.320ms / 1.232ms respectively (Table. 2).
3.1 IKBO flash attention solves the IO bound issues under RecSys boundary conditions
**
Fig. 10**: Traditional SDPA with candidate-user broadcasting (left) vs. fused IKBO target attention (right).
IKBO fuses K/V broadcasting into the attention kernel, maintaining mathematical equivalence via a candidate-user mapping tensor from the inference runtime that handles non-uniform candidate-to-user ratios. Fig. 10 contrasts the two approaches: the traditional SDPA path broadcasts K and V to the full candidate batch size before attention, while the IKBO path eliminates this materialization entirely — each candidate indexes into its user’s K/V on the fly.
Shifting IO-Bound to Compute-Bound by IKBO co-design
In RecSys boundary conditions, target attention uses a relatively small number of candidate embeddings to represent the candidate attributes compared to the user’s browsing history. Roofline analysis of standard attention reveals an arithmetic intensity of ~60 FLOPs/Byte – well below the H100 (SXM5 HBM2e version) peak of ~495 FLOPs/Byte (Appendix 2)—making even standard flash attention heavily IO-bound. IKBO addresses this by amortizing K/V memory accesses across multiple candidates sharing the same user context, improving arithmetic intensity from ~60 FLOPs/Byte to ~833 FLOPs/Byte (at B_candidate : B_user = 70:1) and shifting the kernel firmly into compute-bound territory.
To maximize this benefit, our implementation reorders the threadblock launch grid so that batch_size_candidate comes before num_heads. This ensures threadblocks processing different candidates — but sharing the same user K/V — are scheduled concurrently, improving L2 cache reuse.
Grid dimension
Flash attention (SDPA)
IKBO target attention
x
num_q_seq_block
num_q_seq_block
y
num_heads
batch_size_candidate
z
batch_size_candidate
num_heads
Table 1: Launch grid configuration comparison. SDPA prioritizes GQA optimization by placing num_heads in grid.y. IKBO swaps head and candidate dimensions, placing batch_size_candidate in grid.y to enable efficient K/V sharing across candidates.
Table 2 compares our IKBO Triton implementation (FA2 logic + IKBO) against state-of-the-art Flash Attention implementations on Hopper (without IKBO co-design). Throughput and IO are measured on attention only; the broadcasting latency for Key and Value is even larger than the attention cost itself.
Throughput (TFLOPs/s)
IO (GB/s)
Latency (ms)
Triton IKBO FA2
425
487
0.321 (broadcast fused)
TLX FA3
245
2152
0.561 + 0.912 (broadcast K&V)
CuTeDSL FA4 Hopper
250
2193
0.550 + 0.912 (broadcast K&V)
TLX IKBO FA3 persistence generalized
594
681
0.230 (broadcast fused)
Table 2: Attention kernel comparison under RecSys boundary conditions (B_candidate = 2048, B_u = 32, uniform candidate-to-user ratio). Without co-design, even cutting-edge Hopper implementations remain IO-bound.
3.2 Adopting Modern Kernel Techniques (FA3, FA4) with IKBO on TLX
With IKBO shifting the kernel from IO-bound to compute-bound, the natural next step was to adopt the state-of-the-art compute optimizations from Flash Attention 3 (FA3 [10]) and Flash Attention 4 (FA4 [11]) on Hopper – specifically warp specialization and pipelining. However, our boundary conditions on the number of query embeddings (q_seq = 32 or 64) make it difficult to directly adopt FA3’s ping-pong or cooperative warp specialization.
Warp specialization on Hopper requires asynchronous WGMMA instructions, which impose a minimum BLOCK_M ≥ 64. Two consumer warp groups are also necessary to minimize bubbles between them. To satisfy these constraints, we customized the kernel to launch both B_candidate = i and B_candidate = i + 1 within a single threadblock, sharing the same B_user. In the discussion below, we assume all users rank an even number of candidates with q_seq = 64; odd-candidate handling follows afterward.
Performance improvement for IKBO FA3 kernel
Starting from FA3’s recipe — intra-warp pipelining, warpgroup specialization, and ping-pong scheduling — the initial TLX IKBO FA3 kernel performed similarly to the FA2 baseline (Fig. 12, blue vs. red, Appendix 11), with on-par throughput.
To diagnose the bottleneck, we visualized intra-warp pipelining using the Proton tracer with GPU cycles as the latency unit (Fig. 10). Table 3 summarizes the key bottlenecks before and after persistence, measured in GPU cycles via the Proton tracer.
**
Fig. 11**: Proton-based intra-warp profiling of the TLX IKBO FA3 kernel. Representative warps from each warp group are shown: warp 0 (producer), warp 4 (consumer 1), and warp 8 (consumer 2). The softmax_PV_overlap and pure softmax regions are marked separately to identify the tensor core bubbles. (A) Before persistence zoomed in view of B (B) Before persistence with 2 waves (C) After persistence with 2 waves
Bottlenecks
Before
After
Key change
Tensor Core Bubbles (1st QKT per wave, Blue)
~1,300 cycles (400 cycles from warp scheduler switching)
~1,300 cycles
Unchanged
Tensor Core Bubbles (last PV per wave, Blue)
~2,000 cycles
~300 cycles
Async TMA store + reciprocal overlap with last PV
Cross-CTA Stalls (Orange)
~14,000 cycles
Eliminated
Persistence removes CTA re-launch entirely
Init Buffers & Barriers (Green)
~1,600 cycles/wave
~1,600 cycles (1st wave only)
Persistence shared buffer and barrier amortized across waves
Wait 1st Q/K Load (Dark purple)
2,100~4,000 cycles/wave (length varies depending on HBM bandwidth contention)
~2,000 cycles (1st wave only)
Cross-wave pipelining; producer prefetches ~3K cycles ahead
Table 3: Key bottlenecks before and after persistence + optimizations.
Key takeaway: cross-CTA stalls are the dominant bottleneck — not tensor core utilization – at these small query sequence lengths. Persistence is a must for this improvement. After persistence, the profiling results and its latency changes are presented in Fig. 11C and Table. 3.
HBM2e-Specific Optimizations
We further tuned the persistent kernel for the H100 SXM5’s HBM2e bandwidth constraints, trading shared memory capacity for reduced load/store blocking. (Table 4).
Customized optimization/fix
Benefit
Decoupled SMEM buffer of O from Q/V with pipelined TMA async store
Decoupled O from Q/V SMEM sharing enable TMA async stores could overlap with next-wave compute, shortening store blocking time from 1,300 to 400 cycles/wave
Separate Q₀ and Q₁ buffers
Reduces per-Q loading time, allowing one consumer group starts earlier— beneficial when wave count greatly exceeds K/V sequence iterations (common in RecSys)
Instruction Cache Misses fix
Merges the peeled-out last-iteration code path back into the main loop, eliminating icache thrashing caused by excessive warp-specialized instructions (Appendix 12)
Table 4: Customized optimizations for the HBM2e H100 SXM5. These still fit within the available SMEM budget under RecSys boundary conditions (Appendix 10).
We also implemented persistent V2, which iterates from the end of the K sequence to the front (matching FA3/FA4-Hopper’s approach) to simplify masking logic. Both persistent variants apply the Table 4 optimizations. As shown in Fig. 12, at low sequence lengths (512–4,096) the TLX FA3 persistent kernel outperforms all other candidates; beyond 8K the two persistent variants converge.
**
Fig. 12**: IKBO implementation throughput vs. sequence length (B_candidate = 2,048; B_candidate : B_user = 64; num_head = 2; d_head = 128). Practical RecSys sequence lengths are under 4K [3]; longer lengths are included for comparison with LLM use cases. The generalized version handles non-even candidates per user with 50% odd-candidates per user probability
Generalizing IKBO FA3 for ranking Arbitrary Candidate Batch Sizes
Our IKBO FA3 kernel co-processes two candidate batches per CTA to meet WGMMA’s BLOCK_M ≥ 64 requirement. When a user has an odd number of candidates, one consumer warpgroup has no pairing partner. We handle this with idling logic (Fig. 13, left; Algorithm 1):
- The idle warpgroup drains K/V buffers via mbarrier signaling to prevent producer deadlock.
- The active warpgroup disables ping-pong synchronization (its partner no longer arrives at the named barriers).
At a ~70 : 1 candidate-to-user ratio, the idle path triggers less than 0.7% of the time with negligible overhead (Fig. 12, IKBO TLX FA3 generalized). This approach generalizes to q_seq_len = 32, where four candidate batches are bundled per CTA using analogous idling and masking logic.
**
Fig. 13**: CTA assignment for generalized target attention (left) and self + target attention fusion (right). Each CTA assigns two consumer warp groups sharing the same user K/V. When the candidate count is odd, the 2nd consumer idles and drains barriers.
**
**
Algorithm 1: IKBO Attention Forward Pass with Odd Candidate Handling
3.3 Self + Target Attention Fusion via Model Co-Design
The previous sections focused on optimizing target (cross) attention. A natural question arises: can we fold self-attention into the same kernel?
The key insight is that both attention types share the same key-value source — the user sequence. The only difference is the query: self-attention queries come from the user side, while target-attention queries come from the candidate side. By sharing K/V projections between the two, we enable direct horizontal kernel fusion within a single launch. Fig. 13 (right) illustrates the fused CTA layout: the first CTAs handle self-attention query blocks, while the remaining CTAs handle target-attention candidate pairs — all reading from the same pipelined K/V stream.
Similar co-design ideas have been explored in XAI Phoenix, an open-source recommendation system from X [4].
We prototyped a fused kernel to quantify the fusion benefit, excluding K/V projection savings (Fig. 13, right):
- seq_len = 512: 6.6% improvement (514 vs. 482 TFLOPs/s)
- seq_len = 1,024: 4.1% improvement (581 vs. 558 TFLOPs/s)
- seq_len = 2,048: 0.3% improvement (612 vs. 610 TFLOPs/s) — self-attention saturates the SMs
The gains at short sequences stem from kernel fusion benefits: reduced launch overhead, shared buffer allocation savings, cross-kernel pipelining opportunities, and wave quantization mitigation — the same inefficiencies that megakernel techniques [12] target in LLM inference. In production, the shared K/V projections provide additional savings on linear projection cost, analogous to KV cache reuse.
4. Summary of Benchmarks and Results
We summarize the kernel-level benchmarks presented in this post alongside end-to-end deployment outcomes. All kernel benchmarks below are on H100 SXM5 (see details in Appendix 1).
- Linear Compression (Section 2). Four progressive co-design stages — matmul decomposition, memory alignment, broadcast fusion, and warp-specialized multi-stage fusion via TLX — yield a cumulative ~4× speedup (1.944 ms → 0.482 ms) at representative settings. Gains remain robust across batch sizes and candidate-to-user ratios (Fig. 9).
- Flash Attention (Section 3). IKBO shifts target attention from IO-bound (~60 FLOPs/Byte) to compute-bound (~833 FLOPs/Byte), achieving 2.4×/6.4× the throughput of non-co-designed CuTeDSL FA4-Hopper (kernel only / kernel + broadcasting) with 621 BF16 TFLOPs.
- End-to-end deployment. IKBO has been deployed broadly across Meta’s RecSys inference stack — from early-stage to late-stage ranking models, on both GPU and MTIA accelerators — delivering up to 2/3 reduction in compute-intensive net latency on co-designed models. IKBO has been validated across candidate-to-user broadcast ratios spanning from ~10,000 : 1 down to ~10 : 1, confirming both numerical stability and scalability across workloads.
5. Conclusion and Future Directions
IKBO demonstrates that broadcast — long treated as an unavoidable cost of user-candidate interaction — can be eliminated at the computational primitive layer through kernel-model-system co-design. By encoding broadcast semantics directly into kernels, no replicated tensors ever materialize, and savings scale naturally with the candidate-to-user ratio.
While the kernel implementations presented in this work target NVIDIA Hopper via Triton and TLX, the core idea — replacing materialized broadcasts with index-driven in-kernel lookups — is hardware-vendor independent. Adapting the IKBO kernels to CuTeDSL (for advanced NVIDIA backend support) and completing the AMD CK support are natural next steps.
Beyond the two-level user-candidate hierarchy presented here, some RecSys scenarios involve deeper hierarchies — for example, user → ads vendor → ads item, where each user sees multiple vendors and each vendor offers multiple items. This introduces two nested broadcast relationships with independent, non-uniform ratios. IKBO can handle this elegantly, and applying it to multi-level workloads is a natural direction for further reducing materialization overhead in production RecSys architectures.
Acknowledgements
We are grateful to Hongtao Yu, <span data-rich-links="{"per_n":"Yuanwei (Kevin) Fang","per_e":"fywkevin
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み