交通流円滑化のための強化学習の拡張:100台の自動運転車による高速道路展開
バークレー AI リサーチは、100 台の自律走行車を実際の渋滞に投入し、強化学習による分散制御で交通流を滑らかにする実証実験に成功した。
キーポイント
大規模実環境での強化学習導入
シミュレーションから実際のラッシュアワーの高速道路へ、100 台の自律走行車を投入し、強化学習アルゴリズムによる交通制御を実証した。
「幽霊渋滞」の解消メカニズム
人間の運転反応の遅れが原因で増幅する「停止・発進波(幽霊渋滞)」を、AI が先読みして速度を調整することで抑制し、エネルギー効率と安全性を向上させた。
分散型かつ低コストな実装
高価なインフラや中央集権的な制御を必要とせず、既存の車両に搭載可能な標準レーダーセンサーを活用した分散型アプローチを採用している。
I-24 データに基づくシミュレーションによる訓練
テネシー州ナッシュビル近郊の I-24 で収集した実験データを用いて、現実的な交通ダイナミクスを再現するシミュレーション環境を構築し、そこで停止・発進波を緩和する戦略を学習させた。
分散型制御のための限定的なセンサー観測
AV は自車の速度、先行車との相対速度、および車間距離という局所的な情報のみを用いて加速や目標速度を決定するため、追加インフラなしで既存車両に分散導入が可能である。
多目的最適化のための報酬関数設計
停止・発進波の抑制、エネルギー効率の向上、安全性、乗車快適性、および人間の運転規範への適合という複数の目標をバランスよく達成するよう報酬関数が設計されている。
動的ギャップ閾値と公平性の確保
エネルギー最適化のみを優先すると停止行動に陥るため、安全な運転を保証する動的最小・最大ギャップ閾値を導入し、後続の人間運転車の燃料消費もペナルティ対象として selfish な学習を防ぎました。
影響分析・編集コメントを表示
影響分析
この研究は、自律走行技術が単なる「運転代行」から「社会インフラ最適化ツール」へと進化することを示す重要な転換点です。大規模実環境での成功は、強化学習の安全性と信頼性を裏付けるものであり、将来的には都市全体の交通渋滞解消や脱炭素化に直接寄与する可能性を秘めています。
編集コメント
シミュレーションの域を超え、実社会で 100 台規模の実証に成功した点は画期的です。特に「インフラ不要・分散制御」というアプローチは、普及の障壁を大幅に下げる現実解と言えます。
我々は、ラッシュアワーの高速道路交通に100台の強化学習(RL)制御車両を投入し、渋滞を緩和し、全ての車両の燃料消費を削減しました。我々の目標は、「ストップ・アンド・ゴー」波、つまり通常は明確な原因がないにもかかわらず発生し、渋滞と多大なエネルギー浪費を引き起こす、苛立たしい減速と加速の連鎖に取り組むことです。効率的な交通流円滑化制御器を訓練するため、RLエージェントが相互作用する高速なデータ駆動型シミュレーションを構築し、人間のドライバーの周囲で安全に運転しながらスループットを維持し、エネルギー効率を最大化することを学習させました。
全体として、適切に制御された自動運転車(AV)がわずかな割合存在するだけで、道路上の全てのドライバーの交通流と燃料効率を大幅に改善できることが分かりました。さらに、訓練された制御器は、分散型で動作し、標準的なレーダーセンサーに依存する、ほとんどの現代車両に導入可能なように設計されています。我々の最新の論文では、この100台実験において、シミュレーションから実環境へのRL制御器の大規模導入に伴う課題を探求しています。
ファントム渋滞の課題
 高速道路の車列を後方へと移動するストップ・アンド・ゴー波。
高速道路の車列を後方へと移動するストップ・アンド・ゴー波。
車を運転するなら、ストップ・アンド・ゴー波による苛立ちを経験したことがきっとあるでしょう。それは、どこからともなく現れ、突然解消する、一見説明のつかない交通の減速です。これらの波は、交通流の中で増幅される、我々の運転行動の小さな変動によって引き起こされることがよくあります。我々は自然に、前を走る車両に基づいて速度を調整します。車間距離が開けば、追いつくために加速します。前の車がブレーキを踏めば、我々も減速します。しかし、ゼロではない反応時間のため、我々は前の車よりもほんの少し強くブレーキを踏むかもしれません。その後ろのドライバーも同じことをし、これが増幅し続けます。時間が経つにつれて、取るに足らない減速として始まったものが、車列のさらに後方で完全な停止へと変わります。これらの波は交通流の中で後方へ移動し、頻繁な加速によるエネルギー効率の大幅な低下、それに伴うCO2排出量と事故リスクの増加を引き起こします。
そしてこれは孤立した現象ではありません!これらの波は、交通密度が臨界値を超えた場合、混雑した道路ではどこにでも存在します。では、この問題にどう対処すればよいのでしょうか?ランプメータリングや可変速度制限のような従来のアプローチは交通流を管理しようと試みますが、しばしば高価なインフラと集中型の調整を必要とします。より拡張性のあるアプローチは、運転行動をリアルタイムで動的に調整できるAVを利用することです。しかし、単に人間のドライバーの中にAVを挿入するだけでは不十分です。AVは、交通を誰にとってもより良くする、より賢い方法で運転しなければなりません。そこでRLの出番となります。
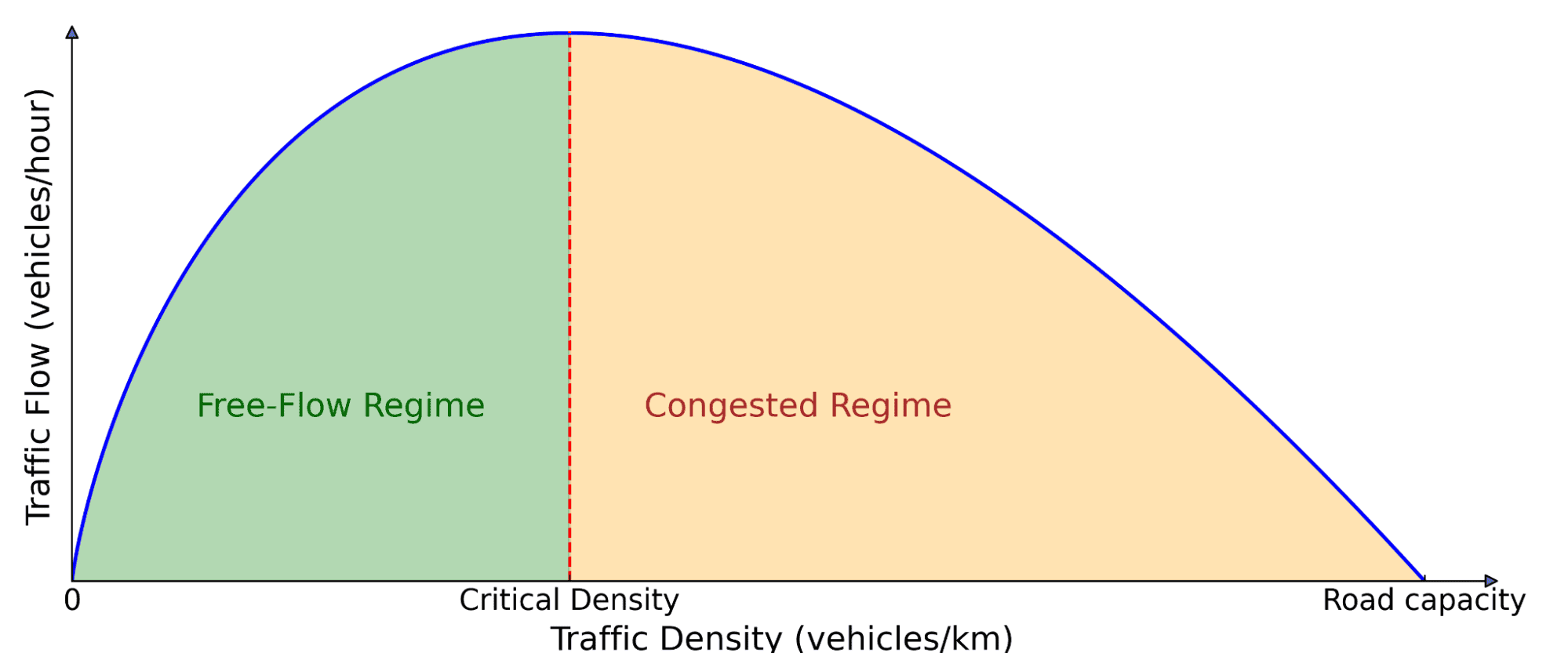 交通流の基本図。道路上の車の数(密度)は、どれだけの交通が前方に移動しているか(流量)に影響します。密度が低い場合、より多くの車を追加すると、より多くの車両が通過できるため、流量は増加します。しかし、臨界値を超えると、車両は互いに邪魔し始め、渋滞を引き起こします。そこでは車を追加すると、実際には全体の動きが遅くなります。
交通流の基本図。道路上の車の数(密度)は、どれだけの交通が前方に移動しているか(流量)に影響します。密度が低い場合、より多くの車を追加すると、より多くの車両が通過できるため、流量は増加します。しかし、臨界値を超えると、車両は互いに邪魔し始め、渋滞を引き起こします。そこでは車を追加すると、実際には全体の動きが遅くなります。
波を平滑化するAVのための強化学習
RLは、エージェントが環境との相互作用を通じて報酬信号を最大化することを学習する強力な制御手法です。エージェントは試行錯誤を通じて経験を収集し、失敗から学び、時間とともに改善します。我々の場合、環境は混合自律交通シナリオであり、AVはストップ・アンド・ゴー波を減衰させ、自身と近くの人間が運転する車両の両方の燃料消費を削減する運転戦略を学習します。
これらのRLエージェントを訓練するには、高速道路のストップ・アンド・ゴー行動を再現できる、現実的な交通ダイナミクスを持つ高速なシミュレーションが必要です。これを実現するため、我々はテネシー州ナッシュビル近くの州間高速道路24号線(I-24)で収集した実験データを活用し、車両が高速道路の軌跡を再生し、その後方を走るAVが平滑化することを学習する不安定な交通を生み出すシミュレーションを構築しました。
いくつかのストップ・アンド・ゴー波を示す高速道路軌跡を再生するシミュレーション。
我々は導入を念頭に置いてAVを設計し、自身と前の車両に関する基本的なセンサー情報のみを使用して動作できることを確認しました。観測情報は、AVの速度、先行車両の速度、およびそれらの間の車間距離で構成されます。これらの入力が与えられると、RLエージェントはAVに対して瞬間的な加速度または目標速度を指示します。これらの局所的な測定値のみを使用する主な利点は、RL制御器が追加のインフラを必要とせず、分散型でほとんどの現代車両に導入できることです。
最も難しい部分は、最大化したときに、我々がAVに達成させたい異なる目的と一致する報酬関数を設計することです:
波の平滑化:ストップ・アンド・ゴーの振動を減らす。
エネルギー効率:AVだけでなく、全ての車両の燃料消費を下げる。
安全性:合理的な車間距離を確保し、急ブレーキを避ける。
乗り心地:攻撃的な加速と減速を避ける。
人間の運転規範への準拠:周囲のドライバーを不快にさせない「普通の」運転行動を確保する。
これらの目的を一緒にバランスさせることは困難です。なぜなら、各項に対する適切な係数を見つけなければならないからです。例えば、燃料消費の最小化が報酬を支配すると、RL制御のAVは、それがエネルギー最適であるために、高速道路の真ん中で停止することを学習します。これを防ぐため、燃料効率を最適化しながら安全で合理的な行動を確保するために、動的な最小および最大車間距離の閾値を導入しました。また、AVの後方を走る人間が運転する車両の燃料消費に対してペナルティを課し、周囲の交通を犠牲にしてAV自身のエネルギー節約を最適化するような利己的な行動を学習することを抑制しました。全体として、我々はエネルギー節約と、合理的で安全な運転行動とのバランスを取ることを目指しています。
シミュレーション結果
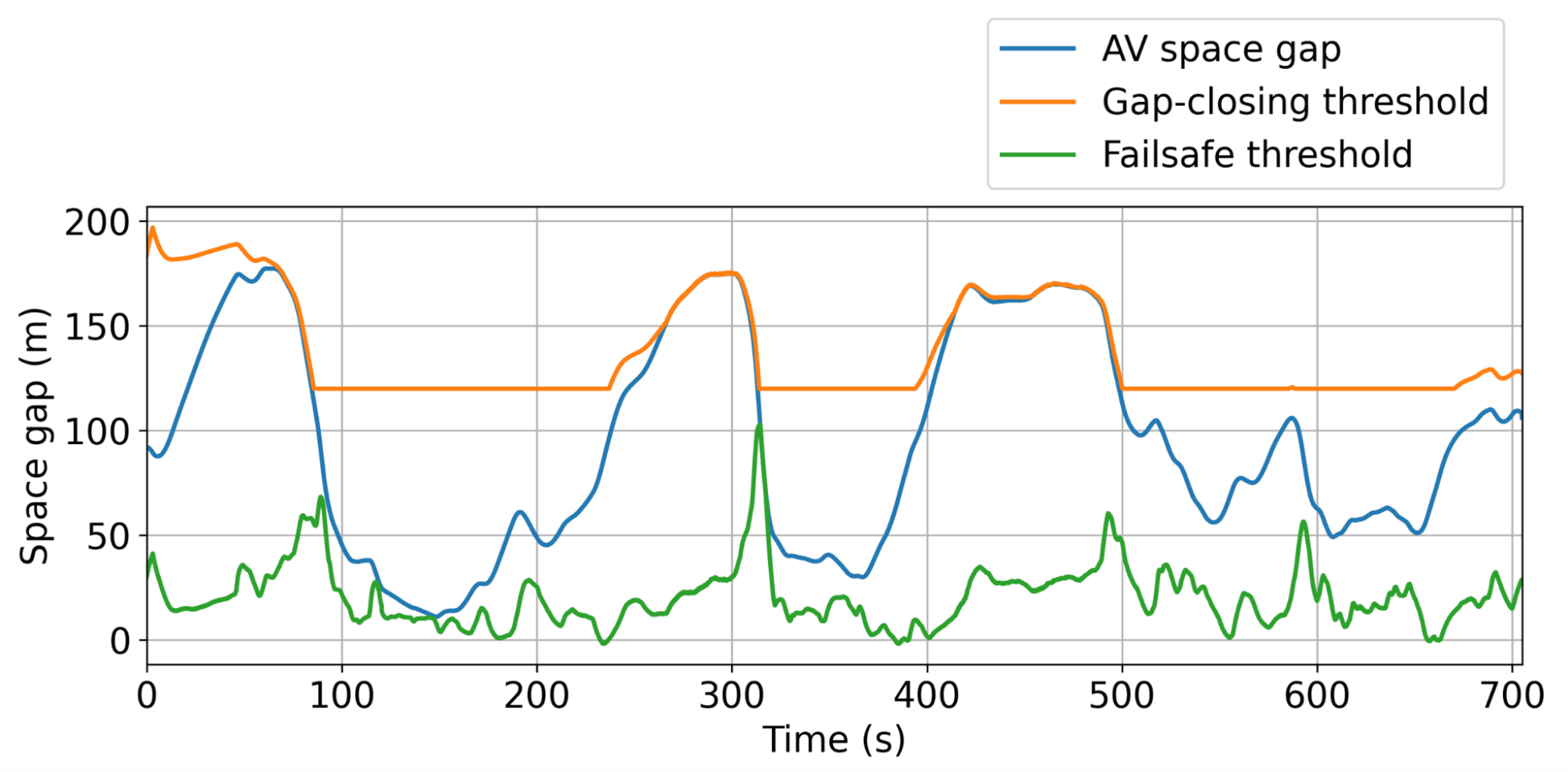 動的な最小および最大車間距離閾値の説明。AVはこの範囲内で自由に動作し、可能な限り効率的に交通を平滑化できます。
動的な最小および最大車間距離閾値の説明。AVはこの範囲内で自由に動作し、可能な限り効率的に交通を平滑化できます。
AVが学習する典型的な行動は、人間のドライバーよりもわずかに大きな車間距離を維持することです。これにより、起こりうる急激な交通の減速をより効果的に吸収できます。シミュレーションでは、このアプローチにより、最も混雑したシナリオにおいて、道路上のAVが5%未満であっても、全ての道路利用者の燃料消費が最大20%削減されました。そしてこれらのAVは特別な車両である必要はありません!それらは、我々が大規模にテストした、スマートなアダプティブ・クルーズ・コントロール(ACC)を搭載した標準的な市販車でよいのです。
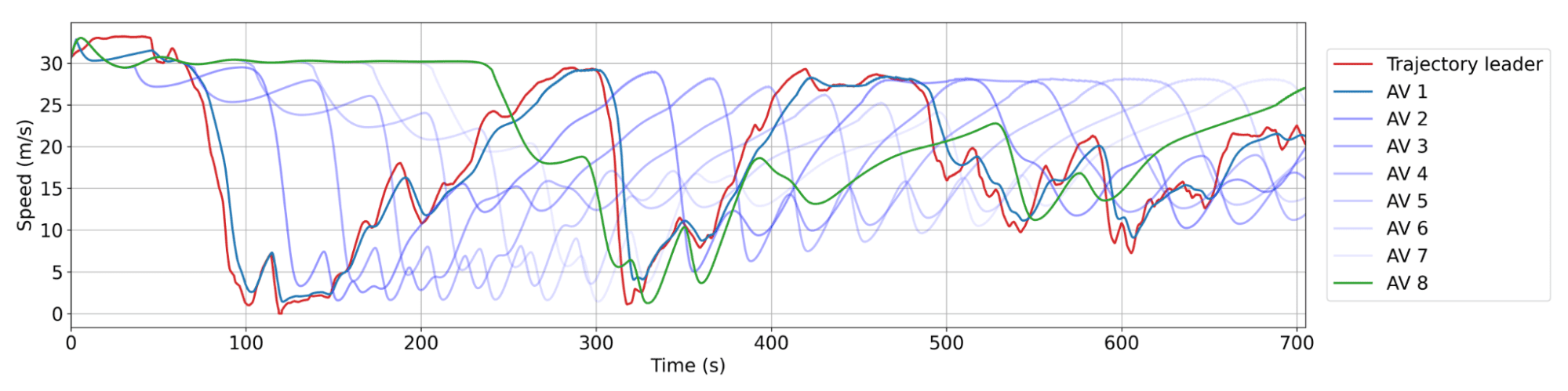 RL制御AVの平滑化行動。赤:データセットからの人間の軌跡。青:隊列をなす連続したAV。AV 1は人間の軌跡の直後を走ります。AVの間には通常20〜25台の人間が運転する車両がいます。各AVは、先行車両ほどには減速せず、また加速もしません。これにより、時間とともに波の振幅が減少し、エネルギー節約につながります。
RL制御AVの平滑化行動。赤:データセットからの人間の軌跡。青:隊列をなす連続したAV。AV 1は人間の軌跡の直後を走ります。AVの間には通常20〜25台の人間が運転する車両がいます。各AVは、先行車両ほどには減速せず、また加速もしません。これにより、時間とともに波の振幅が減少し、エネルギー節約につながります。
100台AV実地試験:RLの大規模導入
実験週間に運用センターに駐車された我々の100台の車両。
有望なシミュレーション結果を受けて、当然の次のステップは、シミュレーションから高速道路へのギャップを埋めることでした。我々は訓練済みのRL制御器を取得し、数日間にわたるピーク交通時間帯にI-24で100台の車両に導入しました。MegaVanderTestと呼んだこの大規模実験は、これまでで最大の混合自律交通平滑化実験です。
実環境でRL制御器を導入する前に、我々はシミュレーションで広範囲に訓練と評価を行い、ハードウェア上で検証しました。全体として、導入に向けたステップは以下を含みました:
データ駆動型シミュレーションでの訓練:我々は、高速道路交通データを
原文を表示
We deployed 100 reinforcement learning (RL)-controlled cars into rush-hour highway traffic to smooth congestion and reduce fuel consumption for everyone. Our goal is to tackle "stop-and-go" waves, those frustrating slowdowns and speedups that usually have no clear cause but lead to congestion and significant energy waste. To train efficient flow-smoothing controllers, we built fast, data-driven simulations that RL agents interact with, learning to maximize energy efficiency while maintaining throughput and operating safely around human drivers.
Overall, a small proportion of well-controlled autonomous vehicles (AVs) is enough to significantly improve traffic flow and fuel efficiency for all drivers on the road. Moreover, the trained controllers are designed to be deployable on most modern vehicles, operating in a decentralized manner and relying on standard radar sensors. In our latest paper, we explore the challenges of deploying RL controllers on a large-scale, from simulation to the field, during this 100-car experiment.
The challenges of phantom jams
A stop-and-go wave moving backwards through highway traffic.
If you drive, you’ve surely experienced the frustration of stop-and-go waves, those seemingly inexplicable traffic slowdowns that appear out of nowhere and then suddenly clear up. These waves are often caused by small fluctuations in our driving behavior that get amplified through the flow of traffic. We naturally adjust our speed based on the vehicle in front of us. If the gap opens, we speed up to keep up. If they brake, we also slow down. But due to our nonzero reaction time, we might brake just a bit harder than the vehicle in front. The next driver behind us does the same, and this keeps amplifying. Over time, what started as an insignificant slowdown turns into a full stop further back in traffic. These waves move backward through the traffic stream, leading to significant drops in energy efficiency due to frequent accelerations, accompanied by increased CO2 emissions and accident risk.
And this isn’t an isolated phenomenon! These waves are ubiquitous on busy roads when the traffic density exceeds a critical threshold. So how can we address this problem? Traditional approaches like ramp metering and variable speed limits attempt to manage traffic flow, but they often require costly infrastructure and centralized coordination. A more scalable approach is to use AVs, which can dynamically adjust their driving behavior in real-time. However, simply inserting AVs among human drivers isn’t enough: they must also drive in a smarter way that makes traffic better for everyone, which is where RL comes in.
Fundamental diagram of traffic flow. The number of cars on the road (density) affects how much traffic is moving forward (flow). At low density, adding more cars increases flow because more vehicles can pass through. But beyond a critical threshold, cars start blocking each other, leading to congestion, where adding more cars actually slows down overall movement.
Reinforcement learning for wave-smoothing AVs
RL is a powerful control approach where an agent learns to maximize a reward signal through interactions with an environment. The agent collects experience through trial and error, learns from its mistakes, and improves over time. In our case, the environment is a mixed-autonomy traffic scenario, where AVs learn driving strategies to dampen stop-and-go waves and reduce fuel consumption for both themselves and nearby human-driven vehicles.
Training these RL agents requires fast simulations with realistic traffic dynamics that can replicate highway stop-and-go behavior. To achieve this, we leveraged experimental data collected on Interstate 24 (I-24) near Nashville, Tennessee, and used it to build simulations where vehicles replay highway trajectories, creating unstable traffic that AVs driving behind them learn to smooth out.
Simulation replaying a highway trajectory that exhibits several stop-and-go waves.
We designed the AVs with deployment in mind, ensuring that they can operate using only basic sensor information about themselves and the vehicle in front. The observations consist of the AV’s speed, the speed of the leading vehicle, and the space gap between them. Given these inputs, the RL agent then prescribes either an instantaneous acceleration or a desired speed for the AV. The key advantage of using only these local measurements is that the RL controllers can be deployed on most modern vehicles in a decentralized way, without requiring additional infrastructure.
The most challenging part is designing a reward function that, when maximized, aligns with the different objectives that we desire the AVs to achieve:
Wave smoothing: Reduce stop-and-go oscillations.
Energy efficiency: Lower fuel consumption for all vehicles, not just AVs.
Safety: Ensure reasonable following distances and avoid abrupt braking.
Driving comfort: Avoid aggressive accelerations and decelerations.
Adherence to human driving norms: Ensure a “normal” driving behavior that doesn’t make surrounding drivers uncomfortable.
Balancing these objectives together is difficult, as suitable coefficients for each term must be found. For instance, if minimizing fuel consumption dominates the reward, RL AVs learn to come to a stop in the middle of the highway because that is energy optimal. To prevent this, we introduced dynamic minimum and maximum gap thresholds to ensure safe and reasonable behavior while optimizing fuel efficiency. We also penalized the fuel consumption of human-driven vehicles behind the AV to discourage it from learning a selfish behavior that optimizes energy savings for the AV at the expense of surrounding traffic. Overall, we aim to strike a balance between energy savings and having a reasonable and safe driving behavior.
Simulation results
Illustration of the dynamic minimum and maximum gap thresholds, within which the AV can operate freely to smooth traffic as efficiently as possible.
The typical behavior learned by the AVs is to maintain slightly larger gaps than human drivers, allowing them to absorb upcoming, possibly abrupt, traffic slowdowns more effectively. In simulation, this approach resulted in significant fuel savings of up to 20% across all road users in the most congested scenarios, with fewer than 5% of AVs on the road. And these AVs don’t have to be special vehicles! They can simply be standard consumer cars equipped with a smart adaptive cruise control (ACC), which is what we tested at scale.
Smoothing behavior of RL AVs. Red: a human trajectory from the dataset. Blue: successive AVs in the platoon, where AV 1 is the closest behind the human trajectory. There is typically between 20 and 25 human vehicles between AVs. Each AV doesn’t slow down as much or accelerate as fast as its leader, leading to decreasing wave amplitude over time and thus energy savings.
100 AV field test: deploying RL at scale
Our 100 cars parked at our operational center during the experiment week.
Given the promising simulation results, the natural next step was to bridge the gap from simulation to the highway. We took the trained RL controllers and deployed them on 100 vehicles on the I-24 during peak traffic hours over several days. This large-scale experiment, which we called the MegaVanderTest, is the largest mixed-autonomy traffic-smoothing experiment ever conducted.
Before deploying RL controllers in the field, we trained and evaluated them extensively in simulation and validated them on the hardware. Overall, the steps towards deployment involved:
Training in data-driven simulations: We used highway traffic data from I-24 to create a training environment with realistic wave dynamics, then validate the trained agent’s performance and robustness in a variety of new traffic scenarios.
Deployment on hardware: After being validated in robotics software, the trained controller is uploaded onto the car and is able to control the set speed of the vehicle. We operate through the vehicle’s on-board cruise control, which acts as a lower-level safety controller.
Modular control framework: One key challenge during the test was not having access to the leading vehicle information sensors. To overcome this, the RL controller was integrated into a hierarchical system, the MegaController, which combines a speed planner guide that accounts for downstream traffic conditions, with the RL controller as the final decision maker.
Validation on hardware: The RL agents were designed to operate in an environment where most vehicles were human-driven, requiring robust policies that adapt to unpredictable behavior. We verify this by driving the RL-controlled vehicles on the road under careful human supervision, making changes to the control based on feedback.
Once validated, the RL controllers were deployed on 100 cars and driven on I-24 during morning rush hour. Surrounding traffic was unaware of the experiment, ensuring unbiased driver behavior. Data was collected during the experiment from dozens of overhead cameras placed along the highway, which led to the extraction of millions of individual vehicle trajectories through a computer vision pipeline. Metrics computed on these trajectories indicate a trend of reduced fuel consumption around AVs, as expected from simulation results and previous smaller validation deployments. For instance, we can observe that the closer people are driving behind our AVs, the less fuel they appear to consume on average (which is calculated using a calibrated energy model):
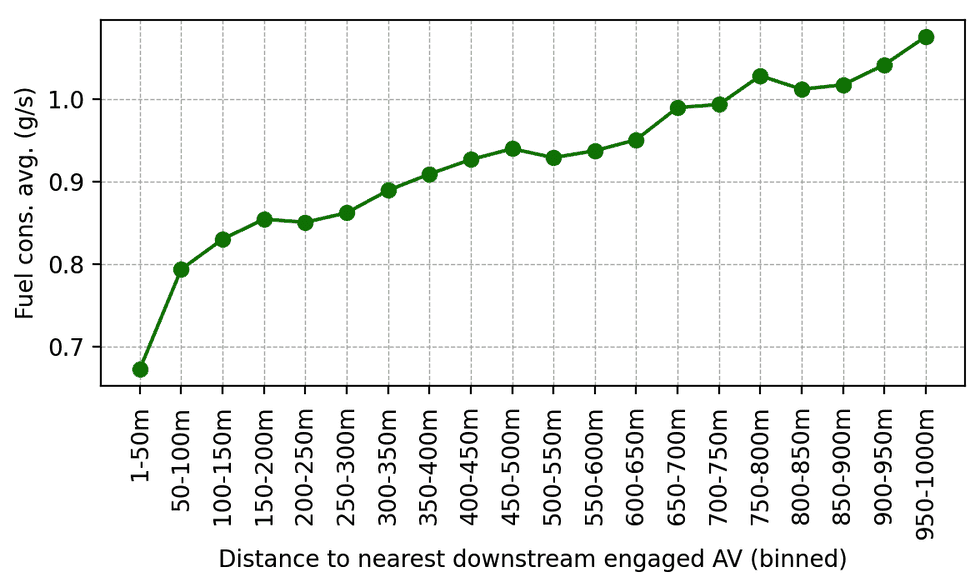 Average fuel consumption as a function of distance behind the nearest engaged RL-controlled AV in the downstream traffic. As human drivers get further away behind AVs, their average fuel consumption increases.
Average fuel consumption as a function of distance behind the nearest engaged RL-controlled AV in the downstream traffic. As human drivers get further away behind AVs, their average fuel consumption increases.
Another way to measure the impact is to measure the variance of the speeds and accelerations: the lower the variance, the less amplitude the waves should have, which is what we observe from the field test data. Overall, although getting precise measurements from a large amount of camera video data is complicated, we observe a trend of 15 to 20% of energy savings around our controlled cars.
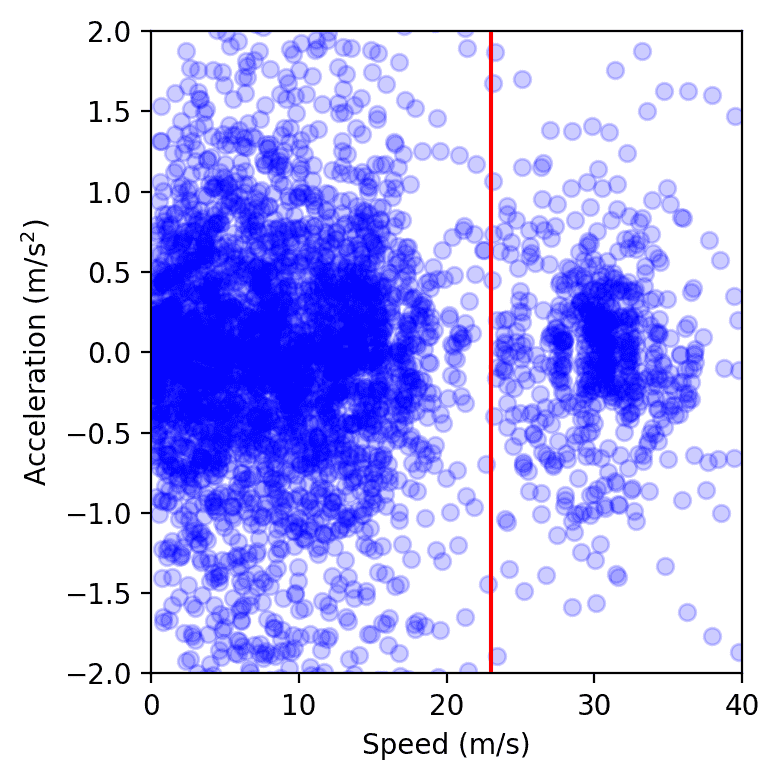 Data points from all vehicles on the highway over a single day of the experiment, plotted in speed-acceleration space. The cluster to the left of the red line represents congestion, while the one on the right corresponds to free flow. We observe that the congestion cluster is smaller when AVs are present, as measured by computing the area of a soft convex envelope or by fitting a Gaussian kernel.
Data points from all vehicles on the highway over a single day of the experiment, plotted in speed-acceleration space. The cluster to the left of the red line represents congestion, while the one on the right corresponds to free flow. We observe that the congestion cluster is smaller when AVs are present, as measured by computing the area of a soft convex envelope or by fitting a Gaussian kernel.
The 100-car field operational test was decentralized, with no explicit cooperation or communication between AVs, reflective of current autonomy deployment, and bringing us one step closer to smoother, more energy-efficient highways. Yet, there is still vast potential for improvement. Scaling up simulations to be faster and more accurate with better human-driving models is crucial for bridging the simulation-to-reality gap. Equipping AVs with additional traffic data, whether through advanced sensors or centralized planning, could further improve the performance of the controllers. For instance, while multi-agent RL is promising for improving cooperative control strategies, it remains an open question how enabling explicit communication between AVs over 5G networks could further improve stability and further mitigate stop-and-go waves. Crucially, our controllers integrate seamlessly with existing adaptive cruise control (ACC) sys
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み