損失を伴う自己改善
大規模言語モデルの急速な進化とエンジニアリングの容易化により、再帰的自我改善(RSI)や特異点への道が開かれているが、その限界と経済への波及効果について考察している。
キーポイント
AI業界の寡占化とエンジニアリングの民主化
数ラボによるモデル資源の集中と、スーパーヒューマンなコーディングアシスタントの登場により、大規模モデル構築の技術的ハードルが劇的に低下し、急速な進歩が可能になっている。
言語モデルの現状と次の飛躍
現在のモデルは高度な知識労働に十分対応可能だが、コードやCLI操作以外の新たなタスクをマスターする次の大きなステップは不透明であり、その進展が経済に ripple effect を与える。
再帰的自我改善(RSI)の歴史と前提
2000年代から議論されてきたRSI概念は、AIが自身の認知アルゴリズムを再設計できる閉じたループにおいて成立し、知性の爆発(特異点)につながるとされるが、その実現には特定の前提条件が必要である。
損失付き自己改善(LSI)の概念
再帰的自己改善(RSI)ではなく、モデルがループの中心となるものの摩擦により核心仮定が崩れる「損失付き自己改善」が現実となる。
複雑性のブレーキと限界收益
ポール・アレンの「複雑性のブレーキ」やトインビーの限界收益法則のように、システムの複雑さが増すほど進歩は自己制限され、指数関数的成長ではなく線形に近づく。
計算資源投入の非効率性
問題解決に計算資源やエージェントを多く投入すればするほど、損失と反復が目立つようになり、効率性が失われる。
テスト損失の最適化と実用性のギャップ
言語モデルはテスト損失の低下といった局所的なタスクの最適化に既に有用だが、机上での精度向上とユーザーが実感する生産性の向上の間には長年のギャップが存在する。
重要な引用
Fast takeoff, the singularity, and recursive self-improvement (RSI) are all top of mind in AI circles these days.
Super-human coding assistants making these approachable is breaking a lot of former claims of what building these things entailed.
Recursion is the sort of thing that happens when you hand the AI the object-level problem of “redesign your own cognitive algorithms”.
"Instead of recursive self-improvement, it will be lossy self-improvement (LSI) – the models become core to the development loop but friction breaks down all the core assumptions of RSI."
"The growth of complexity eventually becomes self-limiting, and leads to a widespread 'general systems collapse'."
The problem is that there’s a long-standing gap between an on-paper more accurate model and models that users find more productive.
影響分析・編集コメントを表示
影響分析
この記事は、現在のAIブームが単なるツール改良ではなく、構造的なパラダイムシフト(寡占化と自己改善ループの開始)に至っていることを示唆しています。エンジニアリングコストの低下がイノベーションを加速させる一方、RSIという概念的枠組みを通じて、技術的限界と社会的影響の両面から将来を予測する重要性を強調しています。
編集コメント
技術的な実装コストの低下と概念的な飛躍(RSI)を結びつけた分析は、現在のAI議論の核心を突いています。特に「誰がモデルを作るか」という権力構造の変化と、「AIが自分を改善できるか」という技術的限界の両面から捉えている点が秀逸です。
高速な離脱、特異点、再帰的自己改善(RSI)は、最近の AI 業界において常に話題の中心となっています。これらには、現在 AI 業界で起こっていることに対する真実の要素が含まれています。2 つ、あるいは3つのラボが、最良の AI モデル(および次世代モデルを構築するためのリソース)へのアクセス権を持つ寡占体制として統合されつつあります。今日の AI ツールは、エンジニアリングや研究職を突然変革しています。
AI 研究は多くの点で非常に容易になっています。大規模言語モデルのトレーニングをさらにスケールさせるために解決すべき技術的課題は依然として困難です。これらの課題にアプローチ可能にする超人的なコーディングアシスタントが、これらを構築することに何が必要かという従来の主張の数々を崩壊させています。これらはすべて、AI の最前線において1年(あるいはそれ以上)の急速な進歩をもたらす土台となっています。
また、言語モデルはすでに非常に優秀な段階にあります。実際、多くの極めて価値のある知識労働タスクに対して十分すぎるほどです。言語モデルがさらに大きな一歩を踏み出すことは想像しにくく、コードや CLI ベースのコンピューター操作以外で今年彼らが習得するタスクが何であるかは不明確です。いくつかの新規タスクが登場することでしょう!これらの能力は、経済にさらなる波及効果をもたらす新しい働き方のスタイルを可能にします。
これらの劇的な変化は、言語モデルがその後自分自身で進歩を加速し続けることがほぼ確実であるかのように思わせる。この概念を表す一般的な用語は「再帰的自己改善ループ」です。このトピックに関する初期の文献は 2000 年代に遡り、例えば 2008 年にはこのテーマに特化したブログ記事も存在します。
再帰とは、「自分の認知アルゴリズムを再設計する」というオブジェクトレベルの問題を AI に任せた際に起こるような現象です。
さらに少し前、2007 年にユドコフスキーは『一般知能の組織レベル』において、関連する概念である「シード AI」を定義しています。
シード AI とは、自己理解、自己改変、および再帰的自己改善のために設計された AI です。これは、原始的な知能を実現するために必要な機能的アーキテクチャ(functional architectures)だけでなく、もしもそのホロニックな自己理解(holonic self-understanding)が向上し始めた場合の AI の後の発展にも影響を及ぼします。シード AI は、無知なコアからブートストラップすることで一般知能の課題を回避する抜け道ではありません。シード AI が利益をもたらすのは、利用可能なある程度の知能が存在して初めてです。シード AI の後の帰結(例えば真の再帰的自己改善)は、AI が顕著なホロニック理解と一般知能を獲得した後に現れます。
今日のモデルがいかに汎用的で有用であるかを考えると、私たちはまさにその始まりにいると考えられるのは妥当でしょう。
一般的に、RSI(自己再帰的改善)は、AI が自身を改善できる場合、その改善されたバージョンがさらに効率的に改善し、知性の爆発をもたらす閉じた増幅ループを生み出すと要約できます。これはしばしば特異点と呼ばれるものです。この概念にはいくつかの前提があります。RSI が発生するためには、以下の条件が必要です。
ループが閉じていること。モデルは自身に対して継続的に改善を行い、より多くのモデルを生み出すことができる。
ループが自己増幅していること。次のモデルは現在のモデルよりもさらに大きな改善をもたらす。
ループが効率を失うことなく継続して実行されること。指数関数的な成長を早期のシグモイド曲線に制限する摩擦的な要素が追加されないこと。
私は、持続的な AI の改善によって今後数年間で社会的に不安定化させるような画期的な変化が到来することに同意しますが、振り返った際に進歩のトレンドラインは指数関数的ではなく、より直線的になると予想しています。再帰的自己改善ではなく、それは損失を伴う自己改善(LSI)となるでしょう。モデルは開発ループの中核となりますが、摩擦によって RSI のすべての核心的な前提が崩壊します。問題に対して投入する計算資源やエージェントが増えるほど、損失と反復が目立つようになります。
Interconnects AI は読者支援型の出版物です。購読をご検討ください。
私は、高度なシステムにおける複雑性ブレーキが、主要な AI モデルを構築するために必要な各狭義タスクにおいて AI モデルが劇的に向上しているという現実に対する強力な均衡要因になると信じています。これは 2025 年 4 月に AI 2027 への回答として以前引用した内容です。
マイクロソフト共同創設者であるポール・アレンは、加速するリターンの反対である複雑性ブレーキを主張しました。つまり、科学が知能の理解に向けて進歩すればするほど、さらなる進展を行うことがいっそう困難になるという考え方です。特許数の研究によれば、人間の創造性は加速するリターンを示すものではなく、むしろジョセフ・テンターが『複雑な社会の崩壊』で示唆したように、収穫逓減の法則に従うことがわかります。千人あたりの特許数は 1850 年から 1900 年の期間にピークを迎え、その後は減少傾向にあります。複雑性の増大は最終的に自己制限的となり、広範な「一般システム崩壊」をもたらします。
モデルがすでにどのように訓練されているか、それを正しく行うために必要な深い直感、そしてそれらを構築する組織には、損失がどこから生じるのかを示す多くの例があります。主要な言語モデルを構築することは極めて複雑であり、さらにその複雑さが増しています。私の頭の中にはいくつかの核心的な摩擦点があります。
- 自動化可能な研究はあまりにも狭い範囲に限られる
まず、今年の言語モデルはすでに、モデルのテスト損失を低下させるような局所的なタスクの最適化において有用なツールであることが明らかです。アンドレイ・カルパティ(Andrey Karpathy)氏は最近、まさにこれを行うことを一般化した「自己研究(autoresearch)」を発表しました。これにより、AI エージェントは GPU 上で直接動作し、テストセット上の損失を低下させるようなタスクに直接取り組むことができます。このアプローチは狭いドメイン、つまり単一の一般的なテスト損失や単一の全体的な報酬を対象とする場合に機能します。
問題は、紙面上ではより正確であるモデルと、ユーザーが実際に生産性が高いと感じるモデルとの間に長年の隔たりがあることです。最も挑発的なケースは事前学習(pretraining)であり、これはスケーリング則(scaling laws)に関する議論でより詳細に論じられました。スケーリング則は、損失が引き続き低下し続けることを示していますが、それが経済的に価値あるものになるかどうかはまだわかりません。
ポストトレーニングにおいて、強化学習アルゴリズムは、ほとんどの RL 訓練環境を直接評価指標として利用できるため、特定の性能向上と少なくともより直接的に結びついています。それでも私は一般化能力や、自己改善という特定のタスクにおいてより優れたモデルへと回帰させることについて懸念を抱いています。一部の分野でモデルが向上することから、必ずしもそれ自体の構築や実験設計においてより優れたモデルへと転換するとは限りません。これは大きな飛躍を要します。私たちは多くの AI 能力が、人間の嗜好における特定のレベルで飽和する様子を見てきました。例えば文章の質などがそうです。AI 研究はこの点では少し異なり、突破すべき天井が非常に高いという特徴があります。モデルが主に文章において飽和するのは、嗜好に内在的な緊張関係があるためですが、モデルが研究において飽和するのは、探索空間と最適化対象が広すぎるからです。
この種の能力を測定するための初期ベンチマークはすべて、同じ問題——狭いスコープ——に陥っています。エージェントは単一の指標の最適化においては良好な結果を出しますが、複数の指標を同時に扱うために必要な飛躍は、全く異なるスキルセットを要求します。実際、最も優れた研究者たちはこれを行っています——彼らは多くのスケーラブルなアイデアを協調させて機能させるのです。
これを測定するための最も関連するベンチマークは PostTrainBench ですが、これは非常に面白いものの、この上での進歩は急速に歪んでしまいます。ポストトレーニングを適切に行う際の課題の 90% 以上は、最終的な性能の最後の 1〜3% を獲得すること、特にドメイン外のタスクでモデルを過剰学習("cooking")させずに達成することにあります。汎用的な最先端モデルをポストトレーニングすることは極めて複雑であり、その複雑さはさらに増しています。
これについて延々と語り続けることもできます。もう一つの例として、私の博士課程(2017〜2022 年)の時期に挙げられます。当時、「AutoML」と呼ばれる分野には大きな注目が集まっており、ベイズ最適化などの手法を用いてモデルのための新しいアーキテクチャやパラメータを見つけようとするものでした。しかし、その熱狂は私の職を変えることにはつながらませんでした。言語モデルはこの以上のことを成し遂げるでしょうが、すぐにトップ AI 研究者の仕事を奪うほどではありません。研究者にとっての中核となる通貨は、特定の最適化や実装ではなく、直感と複雑性の管理です。
- 並列する AI エージェントの増加に伴う収穫逓減
AI の急速な改善における最大の課題は、データセンターに 10,000 人のリモートワーカーを配置できたとしても、彼ら全員を一つの課題に集中させることがほぼ不可能である点です。本質的に、特にモデルがまだ非常に似通っている場合、それらは同じ解決策と能力の分布からサンプリングしており、人間の監督によってボトルネックになっています。エージェントを追加しても、付加できる限界性能には厳格な飽和が生じます——最良の数人の研究者の直感(および実験を実行する時間)が最終的なボトルネックとなるのです。
これを説明するための一般的な考え方に、コンピュータアーキテクチャから派生したアムダールの法則があります。これは、特定のタスクで得られる速度向上は、並列化可能な割合と並列ワーカーの数に比例して固定されることを示しています。以下にその例を示します:
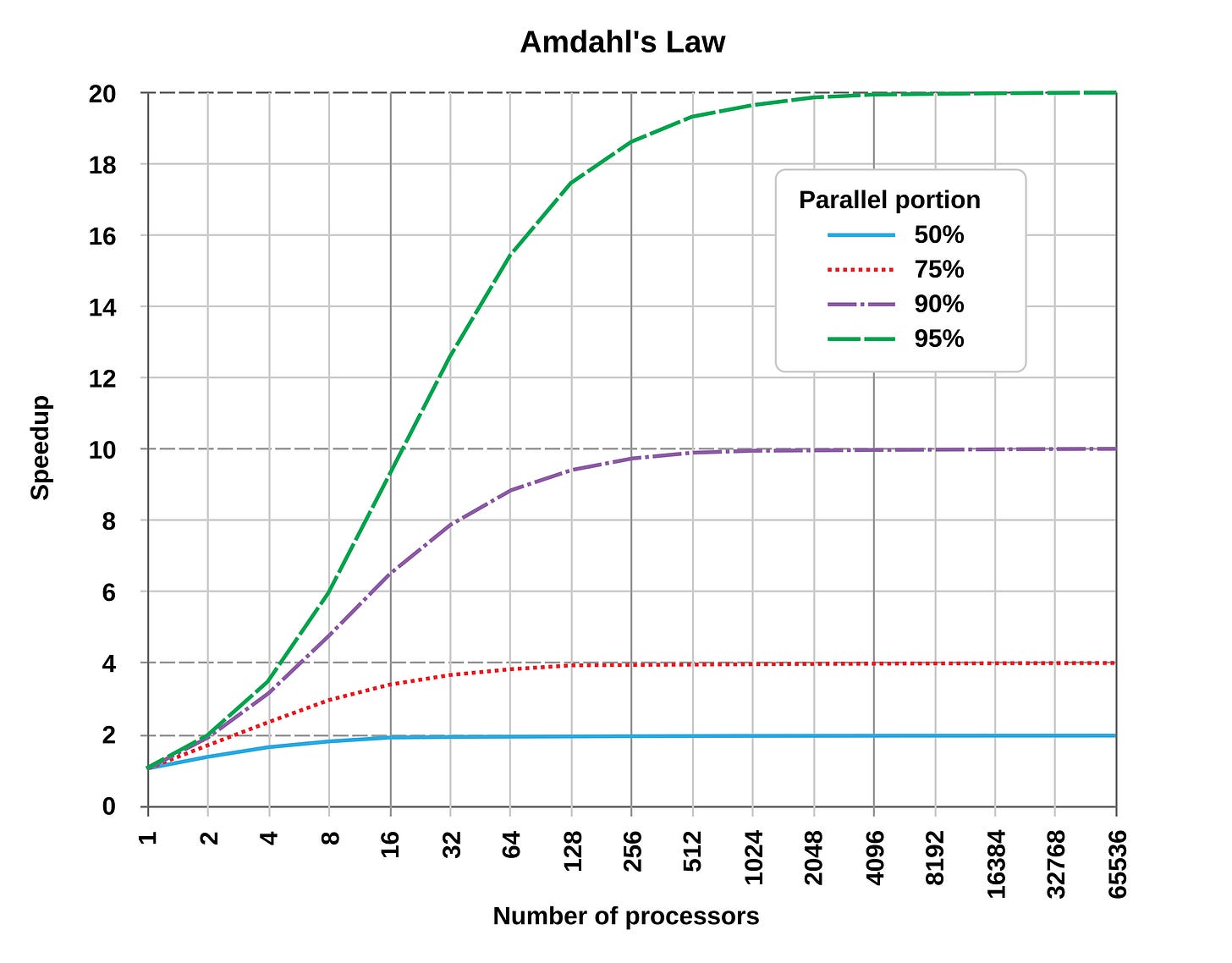
AI の分野では、コンピュータの低レベルな動作の詳細がかなり謎めいているため、これを伝えることは比較的容易であるべきです。手書きでのコーディングから AI による自動補完支援へ、そして現在は自律型コーディングエージェントの使用へと移行している AI 研究者を想像してみてください。これらすべてが大きな進歩です。続けてみましょう。今やこの研究者は、現在の問題に対する異なるサブタスクやアプローチに取り組む 3〜4 エージェントを使用しています。これも依然として大きな進歩です。では、毎日 30〜40 のエージェントを組織化してタスクを与えようとする単一の研究者を考えてみてください。この規模からより多くの価値を引き出せる人もいますが、多くはありません。
AI エージェントに対して毎日 300〜400 のタスクを提案できる人はどれくらいいると思いますか?多くはいません。この問題は、AI モデルにとってもすぐに直面することになるでしょう。
- リソースのボトルネックと政治
根本的に、すべての AI 企業は、巨額の資本を獲得し、十分な需要を通じて新しい計算リソースを収益に変換し、その一方で研究に莫大な費用を投じ続けるという微妙なバランスの上に立っています。ここで必要となるリソースの規模において、誰がリソースを得て何が賭けられるかについては、常に政治的なボトルネックが存在します。この層では、研究リーダーシップは AI や研究者よりも上位に位置しています。モデルが継続的に改善されようとも、この摩擦の原因が完全に除去されることはありません。これは本質的な摩擦ではありませんが、AI モデルは根本的に人間がリソースのボトルネックとなっている組織内で動作しているのです。
言語モデルにおける改善の初期段階は、1 日あたりのコストが 100 万ドル未満であるような局所的な最適化に過ぎません。AI の摩擦に関する私の他の見解と合わせると、これは改善速度に対して単独では非常に小さな影響しか持ちませんが、急速な取込み(take-off)、自己再帰的強化(RSI: Recursive Self-Improvement)、および AI への制御喪失を懸念する人々にとって、研究のための数十億ドル規模の計算リソースが、AI モデルのエンドツーエンド実験のために完全に隔離されることはあり得ないことは明白です。
ここで結論付けられるのは、AI 支援を自律的かつ大規模に AI 開発に利用するという点でまだ初期段階にあるため、私たちが集団的に AI がどのようにして私たちを劇的に支援できるかを発見しているということです。私たちは皆、これらのツールを、目に見える手頃な成果(low-hanging fruit)を獲得するために適用しており、私たちの仕事は文字通り、より高速かつ生産的なものへと変化しています。問題は、これらすべての軸に明確な人間の要因、政治的要素、あるいは技術的な複雑さによるボトルネックが存在していることです。
シグモイド曲線の底辺は常に指数関数的に見えるものです。言語モデルの時代において私たちは複数の指数関数を経験してきました。2023 年には巨大なモデルへとスケールし、GPT-4 は魔法のように感じられましたが、2025 年には o1 や推論モデルによる推論時のスケーリングが追加され、これらは私たちに数学やコーディングを「解決」させるようになりました。今や私たちは、AI ワークフロー全体(トレーニング計算リソースの膨大なスケールアップを継続しつつ)を磨き上げるという大きな一歩を踏み出そうとしています。2026 年は巨大な一歩のように感じられるでしょうが、それが進歩が加速し始めることを確信させる根本的な変化であるとは考えられません。
これはまだ AGI の通俗的な閾値を超える可能性があり、多くのリモートワーカーにとっての差し替え可能な代替手段となるでしょう。それは信じられないほどのマイルストーンです。今後数年間で AGI に到達したかどうかという議論における課題の多くは、AI モデルが人間とは異なる方法で不揃いであり、かつ賢い点にあるため、それらがリモートワーカーの差し替え可能な代替品のように見えるわけではないことです。しかし多くの場合、AI を使用するだけで、人間と協力して作業を試みるよりもはるかに効果的になります。これは仕事の内容そのものを再構築しています。
私たちが検討しているシナリオを考えてみましょう。
エンジニアリングは今日、自動化されつつあります。人間よりもはるかに生産性が高く、モデルは複雑なインフラストラクチャの展開を通じてはるかに迅速にスケーリングでき、より高い GPU 利用率で動作しますなどとなります。インフラストラクチャによる利益は、AI における進歩の基本単位である実験の速度と規模における固定的な改善へと転換されます。
基本的な AI モデルの研究と最適化も自動化されるでしょう。AI モデルの範囲が拡大しており、カーネルの記述からアーキテクチャの決定へと移行しています。これは実験ツールの改善から、それ自体が小規模な実験を実行することへの移動です。設定やハイパーパラメータなどは、AI アシスタントの領域となります。
これらはいずれも現実です。問題は、第3の時代には単純に飛び越えるためのスケールが存在しないことです。AI モデルが合成と実行によって知識を創出できる一方で、次の飛躍には数千のエージェントを活用するか、推論時間スケーリングの次となるパラダイムを解き放つようなより画期的な発見をモデルが行う必要があります。AI 以降の改善は業界をヒルクライミングにおいて超高速化しますが、私はこれが新しいカテゴリの AI(継続的学習、ワールドモデル、あるいはあなたが好むどのようなものでも)に必要なパラダイムシフトをもたらすとは考えにくいと懸念しています。
全体として、モデルが開発ループの中核となりつつあり、これには興奮と不安の両方があります。モデルは自己改善を行っていますが、アプローチそのものを変革しているわけではありません。私たちは研究実践やツールに投入する計算リソースを拡大しており、そこには逓増する収益が現れています。エージェントは私たちが共に働く自律的な存在として登場し始めます。それらは天才と5 歳児の中間のような感覚を与えます。私たちは数年間、損失のある自己改善(Lossy Self-Improvement: LSI)の時代にいることになりますが、これは急速なテイクオフには不十分です。
原文を表示
Fast takeoff, the singularity, and recursive self-improvement (RSI) are all top of mind in AI circles these days. There are elements of truth to them in what’s happening in the AI industry. Two, maybe three, labs are consolidating as an oligopoly with access to the best AI models (and the resources to build the next ones). The AI tools of today are abruptly transforming engineering and research jobs.
AI research is becoming much easier in many ways. The technical problems that need to be solved to scale training large language models even further are formidable. Super-human coding assistants making these approachable is breaking a lot of former claims of what building these things entailed. Together this is setting us up for a year (or more) of rapid progress at the cutting edge of AI.
We’re also at a time where language models are already extremely good. They’re in fact good enough for plenty of extremely valuable knowledge-work tasks. Language models taking another big step is hard to imagine — it’s unclear which tasks they’re going to master this year outside of code and CLI-based computer-use. There will be some new ones! These capabilities unlock new styles of working that’ll send more ripples through the economy.
These dramatic changes almost make it seem like a foregone conclusion that language models can then just keep accelerating progress on their own. The popular language for this is a recursive self-improvement loop. Early writing on the topic dates back to the 2000s, such as the blog post entirely on the topic from 2008:
Recursion is the sort of thing that happens when you hand the AI the object-level problem of “redesign your own cognitive algorithms”.
And slightly earlier, in 2007, Yudkowsky also defined the related idea of a Seed AI in Levels of Organization in General Intelligence:
A seed AI is an AI designed for self-understanding, self-modification, and recursive self-improvement. This has implications both for the functional architectures needed to achieve primitive intelligence, and for the later development of the AI if and when its holonic self-understanding begins to improve. Seed AI is not a workaround that avoids the challenge of general intelligence by bootstrapping from an unintelligent core; seed AI only begins to yield benefits once there is some degree of available intelligence to be utilized. The later consequences of seed AI (such as true recursive self-improvement) only show up after the AI has achieved significant holonic understanding and general intelligence.
It’s reasonable to think we’re at the start here, with how general and useful today’s models are.
Generally, RSI can be summarized as when AI can improve itself, the improved version can improve even more efficiently, creating a closed amplification loop that leads to an intelligence explosion, often referred to as the singularity. There are a few assumptions in this. For RSI to occur, it needs to be that:
The loop is closed. Models can keep improving on themselves and beget more models.
The loop is self-amplifying. The next models will yield even bigger improvements than the current ones.
The loop continues to run without losing efficiency. There are not added pieces of friction that make the exponential knee-capped as an early sigmoid.
While I agree that momentous, socially destabilizing changes are coming in the next few years from sustained AI improvements, I expect the trend line of progress to be more linear than exponential when we reflect back. Instead of recursive self-improvement, it will be lossy self-improvement (LSI) – the models become core to the development loop but friction breaks down all the core assumptions of RSI. The more compute and agents you throw at a problem, the more loss and repetition shows up.
Interconnects AI is a reader-supported publication. Consider becoming a subscriber.
I’m still a believer that the complexity brake on advanced systems will be a strong counterbalance to the reality that AI models are getting substantially better at every narrow task we need to compose together in making a leading AI model. I quoted this previously in April of 2025 in response to AI 2027.
Microsoft co-founder Paul Allen argued the opposite of accelerating returns, the complexity brake: the more progress science makes towards understanding intelligence, the more difficult it becomes to make additional progress. A study of the number of patents shows that human creativity does not show accelerating returns, but in fact, as suggested by Joseph Tainter in his The Collapse of Complex Societies, a law of diminishing returns. The number of patents per thousand peaked in the period from 1850 to 1900, and has been declining since. The growth of complexity eventually becomes self-limiting, and leads to a widespread “general systems collapse”.
There are plenty of examples in how models are already trained, the deep intuitions we need to get them right, and the organizations that build them that show where the losses will come from. Building leading language models is incredibly complex, and only becoming more-so. There are a few core frictions in my mind.
- Automatable research is too narrow
First, it is clear that language models this year will already be useful tools at optimizing localized tasks like lowering the test loss of a model. Andrey Karpathy recently launched his autoresearch that popularized doing just this. This allows AI agents to play directly on GPUs to target tasks like lowering the loss on the test set. This approach works in narrow domains, i.e. one general test loss or one overall reward. The problem is that there’s a long-standing gap between an on-paper more accurate model and models that users find more productive. The most provocative case is for pretraining, which was discussed more at length around scaling laws. Scaling laws show us that the loss will continue going down, but we don’t know if that’ll be economically more valuable.
In post-training, reinforcement learning algorithms are at least more directly tied to specific performance gains as most RL training environments can be used directly as an evaluation. Still, I worry about generalization and tying back to models that are better at the specific task of improving themselves. It’s a big leap from models get better at some things to that necessarily translating to models that are better at building themselves and designing experiments. We’ve seen many AI capabilities sort of saturate at certain levels of human taste, such as writing quality. AI research is a bit different here, as there is a very high ceiling to climb up to. Where models mostly saturate on writing because there’s inherent tension in preferences, models will saturate on research because the search space and optimization target is too wide.
The early benchmarks for measuring this sort of ability all fall prey to the same problem – narrow scope. Agents will do well at optimizing single metrics, but the leap required to navigate many metrics at once is a very different skill set. That is actually what the best researchers do — they make many scalable ideas work together.
The most related benchmark we have to measure this is PostTrainBench, which is quite fun, but progress will very rapidly get distorted on this. Over 90% of the challenge in doing post-training well is getting the last 1-3% of performance, especially without cooking the model in out-of-domain tasks. Post-training a general, leading model is extremely complex, and only getting more complex.
I could go on and on about this. Another example is from during my Ph.D. (2017-2022), when there was immense hype around a field called “AutoML” which aimed to use techniques like Bayesian Optimization to find new architectures and parameters for models. The hype never translated into changing my job. Language models will do more than this, but not enough to take jobs away from top AI researchers any time soon. The core currency of researchers is still intuition and managing complexity, rather than specific optimization and implementation.
- Diminishing returns of more AI agents in parallel
The biggest problem for rapid improvement in AI is that even though we’ll have 10,000 remote workers in a datacenter, it’ll be nearly impossible to channel all of them at one problem. Inherently, especially when the models are still so similar, they’re sampling from the same distribution of solutions and capabilities while being bottlenecked by human supervision. Adding more agents will have a strict saturation in the amount of marginal performance that can be added – the intuition of the best few researchers (and time to run experiments) will be the final bottleneck.
A common idea to illustrate this is Amdahl’s law, which is taken from computer architecture and shows that a given task can only generate a fixed speedup proportional to how much can be parallelized and how many parallel workers exist. An illustration is below:
In AI this should be relatively easier to convey, as the low-level operating details of computers are fairly mysterious. Consider an AI researcher on the transition from writing code by hand to using AI autocomplete assistance to now using autonomous coding agents. These are all massive gains. Let us continue. Now this researcher uses 3-4 agents working on different sub-tasks or approaches to the problem at hand. This is still a large gain. Now consider this single researcher trying to organize 30-40 agents with tasks to do every day. Some people can get more value out of this scale, but not many.
How many people do you think could come up with 300-400 tasks for AI agents every day? Not many. This problem will hit the AI models soon enough as well.
- Resource bottlenecks and politics
Fundamentally, all the AI companies are walking a fine line of acquiring substantial capital, converting new compute resources to revenue via sufficient demand, and repeating the process all-the-while spending an extreme amount on research. With the scale of resources here, there will always be political bottlenecks on who gets resources and what gets bet on. In this layer, research leadership sits above the AIs and the researchers. Even as models continue to improve, this source of friction will never get removed. It isn’t a substantial friction, but the AI models are fundamentally operating in organizations where humans are the bottleneck on resources.
The early scale of improvements with language models is local optimizations, where the resources used cost <$1M per day. With my other views on the frictions of AI, this is on its own a very minor impact on the rate of improvement, but for those with worries of fast take-off, RSI, and loss of control to AIs, it should be obvious that billions of dollars of compute resources for research are unlikely to be totally isolated for end-to-end experimentation of AI models.
Share
The conclusion here is that because we’re at the early stages of using AI assistance, autonomously and at scale for AI-development, we’re collectively discovering the ways that AI can help us massively. We’re all applying these tools to capture the low-hanging fruit we see and our jobs are literally changing to be higher paced and more productive. The problem is that all of these axes have clear human, political, or technical complexity bottlenecks.
The bottom of every sigmoid feels like an exponential. We’ve ridden multiple exponentials in the era of language models, in 2023 we scaled to huge models and GPT-4 felt like magic, by 2025 we added inference-time scaling with o1 and reasoning models — they let us “solve” math and coding, now we’re going to take a big step by polishing the entire AI workflow (all the while scaling training compute massively). 2026 will feel like a huge step, but it doesn’t have a fundamental change convincing me that progress will begin to take off.
This could still cross the colloquial threshold for AGI, which is a drop-in replacement for most remote workers, which would be an incredible milestone. Much of the challenge in the debate of if we hit AGI in the coming years is that AI models are jagged and smart in different ways than humans, so they won’t look like drop-in replacements for remote workers, but in many cases just using AI will be far more effective than trying to work with a human. It’s reshaping what jobs are.
Let us consider the scenarios we’re working through.
Engineering is becoming automated today. Humans are way more productive, models can scale through complex infrastructure deployments much faster, run with higher GPU utilization, etc. Infrastructure gains become fixed improvements in the rate and scale of experimentation, the fundamental units of progress in AI.
Basic AI model research and optimization will be automated. The AI models are expanding in scope – they transition from writing kernels to deciding on architectures. This is moving from improving the experimentation toolkit to running minor experiments themselves. Configs, hyperparameters, etc. become the domain of the AI assistants.
These are both real. The problem is that a third era doesn’t have a simple scale to jump to. Where the AI models can create knowledge by synthesis and execution, the next jump requires harnessing thousands of agents or having models make more novel discoveries – like unlocking the next paradigm after inference time scaling. The improvements downstream of AI are going to make the industry supercharged at hill climbing, but I worry that this won’t bring paradigm shifts that are needed for new categories of AI – continual learning, world models, whatever your drug of choice is.
All together, the models are becoming core to the development loop and that’s worth being excited (and worried) about. The models are performing self-improvement. They’re not transforming the approach. We are scaling up the compute we spend on our own research practices and tools. There are diminishing returns. Agents are going to start being autonomous entities we work with. They feel like a cross between a genius and a 5 year old. We will be in this era of lossy self-improvement (LSI) for a few years, but it is not enough for a fast takeoff.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み