容量対応型推論:SageMaker AI エンドポイントの自動インスタンスフォールバック
Amazon SageMaker AI は、生成 AI ワークロードの運用課題を解決するため、容量不足時に自動的に代替インスタンスへフォールバックする「capacity-aware instance pool」機能を導入した。
キーポイント
容量不足によるエンドポイント作成失敗の解消
従来の単一インスタンス指定方式では、希望する型が利用不可の場合にエラーが発生していたが、優先リストを定義することで自動的に代替候補へフォールバックし、プロビジョニング成功率を向上させる。
オートスケーリング時のリソース確保の自動化
スケールアウトイベント発生時に指定インスタンスの容量不足で無限ループに陥る問題を解消し、利用可能な AI インフラ上で自動的に拡張処理を行うことで、トラフィック増加への対応を可能にする。
スケーリングと監視機能の強化
スケールダウン時の優先順位付けや、インスタンス種別ごとの詳細なメトリクス可視化により、運用コストの最適化と障害原因の特定を容易にする。
LOR ルーティング戦略の推奨
異なるスループット容量を持つインスタンスをプールする場合、デフォルトのランダムルーティングではなく、Least Outstanding Requests (LOR) を設定することで、負荷が軽い高容量インスタンスに自動的にトラフィックが集中します。
ロールバック機能付きのデプロイメント
ブルー/グリーンおよびローリングデプロイメントをサポートしており、ヘルスチェックや CloudWatch アラームのトリガー時に自動でロールバックを実行することで、エンドポイントの可用性を維持します。
事前準備要件
実装には適切な IAM 権限、S3 に保存されたモデルアーティファクト、Boto3 バージョン 1.43.1 以上の SDK、および必要に応じてインスタンスタイプごとの最適化済みモデルが必要です。
影響分析・編集コメントを表示
影響分析
この機能は、大規模言語モデル(LLM)やマルチモーダルアーキテクチャの生産環境展開において、GPU リソースの不足によるサービス停止という最大のボトルネックを解消する画期的な進展です。開発者は特定のハードウェアへの依存から解放され、より柔軟かつ堅牢な推論基盤を構築できるようになるため、生成 AI の実装と運用コストが劇的に低下すると予想されます。
編集コメント
生成 AI の本番導入において最も頻発する「GPU リソース枯渇によるデプロイ失敗」を、設定のわずかな変更で解決できる点は、現場のエンジニアにとって即座に価値が認められる機能です。
組織が生産環境で生成 AI ワークロードをスケールするにつれ、信頼性の高い GPU 計算リソースの確保は、最も持続的な運用課題の一つとなっています。大規模言語モデル(LLM)やマルチモーダルアーキテクチャは特定のインスタンスタイプを必要としますが、その容量が利用できない場合、エンドポイントは単一の要求も処理する前に失敗してしまいます。
Amazon SageMaker AI 上でリアルタイム推論エンドポイントを構築するには、作成時に単一のインスタンスタイプにコミットすることが必要でした。そのタイプの容量が不十分な場合、エンドポイントは稼働状態に到達できず、設定を更新して別のインスタンスタイプを選択し、プロビジョニング試行が成功するまでこのサイクルを繰り返す必要がありました。
本日、Amazon SageMaker AI は新規および既存の推論エンドポイント向けに 容量対応型インスタンスポール を導入しました。優先順位付けされたインスタンスタイプのリストを定義するだけで、SageMaker AI は作成時、スケールアウト時、およびスケールイン時に容量が制約されるたびに自動的にそのリストを処理します。エンドポイントは手動介入なしで利用可能な AI インフラストラクチャ上でプロビジョニングされます。この機能は、シングルモデルエンドポイント、推論コンポーネントベースのエンドポイント、および非同期推論エンドポイントで利用可能です。
本記事では、インスタンスポールの仕組みと、新規エンドポイントの作成または既存エンドポイントの移行に関わらず、どのようにして開始するかを解説します。
The problem
SageMaker AI の推論エンドポイント(リアルタイムまたは非同期のいずれか)にモデルをデプロイする際、単一のインスタンスタイプを指定します。そのタイプに利用可能な容量がない場合、エンドポイントの作成は失敗します。この制限は、エンドポイントのライフサイクルのあらゆる段階で発生します。
容量不足によりエンドポイントの作成が失敗します。 希望するインスタンスタイプが利用できない場合、SageMaker AI は「Insufficient Capacity(容量不足)」エラーを返します。実行可能なエンドポイントに到達するには、代替案を手動で順次試す必要があり、結果が出るまでに各試行で多大な時間を要します。
オートスケーリングではファームウェアの拡張ができません。 スケールアウトイベントが発生し、指定したインスタンスタイプに容量が不足している場合、オートスケーラーは同じタイプを無限に再試行します。トラフィックが増加する一方で、エンドポイントは現在のサイズのまま固定されます。
スケールダウンでは優先度の認識がありません。 単一のインスタンスタイプのみを使用する場合、「優先」インスタンスと「フォールバック」ハードウェアの区別という概念が存在しません。すべてのインスタンスが区別なく削除対象候補となります。
観測可能性は集約されており、即座に行動に移せません。 Amazon CloudWatch のメトリクスはエンドポイントレベルで集約されます。レイテンシや容量の問題を調査する際、メトリクスは何らかの問題があることを示すものの、どのインスタンスタイプが原因であるかは特定できません。
仕組み:優先度ベースのインスタンスプール
エンドポイント設定において、ランク付けされたインスタンスタイプのリストである「インスタンスプール」を定義します。SageMaker AI は、容量が制約されるたびにこのリストを自動的に処理します。
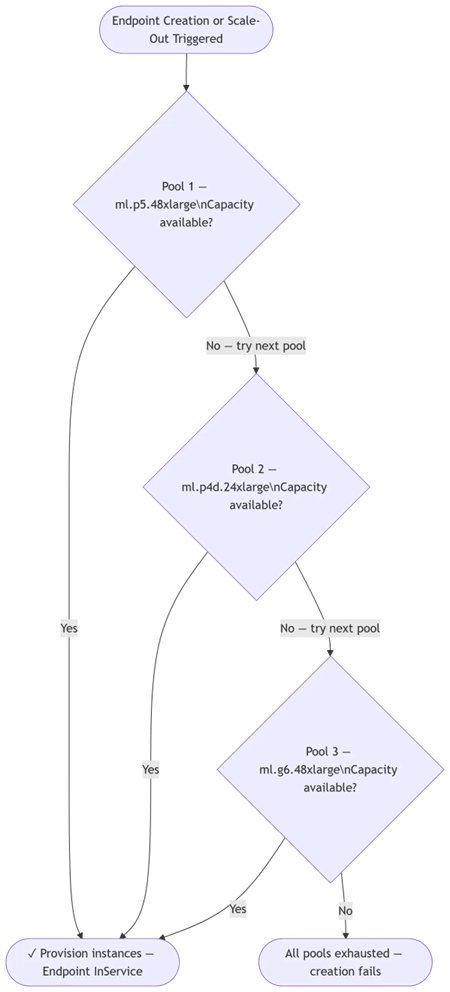
エンドポイントは稼働し続けます。 SageMaker AI はまず第一選択のインスタンスタイプを試みます。もし容量が利用できない場合、即座に第二選択、次に第三選択へと試行します。手動での再試行は不要です。エンドポイントは、利用可能な最初の AI インフラ上で数分以内に InService(サービス開始)状態になります。
エンドポイントは稼働し続けます。 オートスケーリングがトリガーされ、優先するインスタンスタイプの容量が制約された場合、SageMaker AI は優先リスト内の次に利用可能なタイプでスケールアウトを行い、トラフィックの流れを維持します。
フリート(運用中のインスタンス群)は好ましいハードウェアへと傾向します。 スケールイン(縮小)の間、SageMaker AI はまず最下位の優先度(フォールバック用)のインスタンスを削除します。その後のスケールアウトイベントでは、再び最高優先度のタイプから試行されます。好ましいハードウェアが利用可能になると、フリートは時間とともに自然にそれへと戻り、手動での介入は不要です。
すべてが見えます。 すべての既存の CloudWatch メトリクスに InstanceType(インスタンスタイプ)次元が追加されたため、単一のエンドポイント内で、インスタンスタイプごとのレイテンシ、スループット、GPU 利用率、およびインスタンス数を追跡できます。
詳しくは、Amazon SageMaker AI のドキュメントをご覧ください。また、GitHub 上のサンプルノートブックも探索してください。
インスタンスタイプごとに適切なモデルを選択する
フォールバック用のインスタンスタイプは、GPU メモリ、計算能力、アーキテクチャにおいてしばしば異なります。高メモリのマルチ GPU インスタンス向けに最適化されたモデルが、必ずしもメモリ容量の少ないシングル GPU のフォールバック上で動作するわけではありません。プールリスト内の各インスタンスタイプを正しく構成されたモデルと一致させるには、2 つの方法があります。
オプション 1: 独自に最適化したモデルを用意する
すでにターゲットとするインスタンスタイプが分かっている場合は、それぞれのインスタンスタイプに対応したモデルアーティファクトを準備してください。プライマリとなるハイエンドのインスタンスでは、複数の GPU にわたってテンソル並列処理(tensor parallelism)を使用できます。ミッドティアのフォールバックでは、推論速度を向上させるためにスペキュレーティブデコーディング(speculative decoding)を適用できます。最も優先度の低いフォールバックでは、INT4 量子化(INT4 quantization)を使用して、より小さなメモリ予算内に収まるようにします。
各構成に対して個別の SageMaker AI モデルを作成し、Single Model Endpoints の場合は各 InstancePools エントリで ModelNameOverride を使用して参照するか、InferenceComponent ベースのエンドポイントの場合はインスタンスタイプごとの Specifications で参照してください。SageMaker AI が優先度の低いプールへフォールバックすると、そのハードウェア用に準備したモデルがデプロイされます。
オプション 2:SageMaker AI の推論推奨機能を使用する
各ハードウェアターゲットを手動で最適化したくない場合、SageMaker AI 推論推奨機能 を使用すると、ハードウェア固有の構成を自動的に生成できます。ベースモデルを提供するだけで、SageMaker AI は予測的デコーディング(speculative decoding)や量子化(quantization)などの技術を用いて、対象となるインスタンスタイプ全体で最適化された構成を生成します。
推奨ジョブは、各対象インスタンスタイプごとに 1 つの結果を返します。各結果には、AIRecommendationModelDetails レスポンスに含まれる ModelPackageArn と InferenceSpecificationName が含まれており、特定のハードウェア向けの構成を識別しています。これらの 2 つのフィールドを使用して各結果ごとに SageMaker AI モデルを作成し、対応するプールエントリで ModelNameOverride を参照します。これはオプション 1 と同じパターンであり、最適化処理はサービス側が担当します。
MODEL_PACKAGE_ARN = "arn:aws:sagemaker:us-west-2:123456789012:model-package/MyModelPkgGroup/1"
Create one model per instance type using both fields from AIRecommendationModelDetails.
sm.create_model(
ModelName="my-llm-for-p5",
PrimaryContainer={
"ModelPackageName": MODEL_PACKAGE_ARN,
"InferenceSpecificationName": "p5-48xlarge-optimized",
},
ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerRole",
)
sm.create_model(
ModelName="my-llm-for-g6",
PrimaryContainer={
"ModelPackageName": MODEL_PACKAGE_ARN,
"InferenceSpecificationName": "g6-48xlarge-optimized",
},
ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerRole",
)
Then reference each via ModelNameOverride per pool entry — see Setting up below.
Auto scaling on a mixed fleet
Auto scaling follows the same priority logic that you define at creation time. Scale-out tries your highest-priority pool first, falling back to the next pool if capacity is unavailable. Scale-in removes your lowest-priority instances first, preserving your preferred hardware as the fleet contracts.
Building a weighted scaling metric
Because your fleet contains instance types with different throughput capacities, default aggregated metrics can misrepresent actual usage. Consider a p5 instance handling 18 concurrent requests alongside a g6 handling 7 averaging those raw numbers to 12.5 doesn't accurately reflect the load on either type.
現在、CloudWatch のメトリクス計算機能を使用して、*タイプ別の利用率比*に基づいた加重メトリクスを構築できるようになりました。各項は、特定のタイプの観測済み並行処理数をその最大キャパシティで割ることで、0.0 から 1.0 の範囲の値を生成します。これらの比率の平均を取ることで、TargetValue と同じ 0.0 から 1.0 のスケール上で、フリート全体の使用状況を示すシグナルを得ることができます。TargetValue を 0.7 に設定することは、フリート内のすべてのインスタンスタイプ全体で加重平均がキャパシティの 70% を超えた場合にスケールアウトを行うことを意味します。
aas = boto3.client("application-autoscaling")
aas.put_scaling_policy(
PolicyName="weighted-utilization-scaling",
ServiceNamespace="sagemaker",
ResourceId="endpoint/my-heterog-endpoint/variant/primary",
ScalableDimension="sagemaker:variant:DesiredInstanceCount",
PolicyType="TargetTrackingScaling",
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 0.7, # スケーリングアウトは加重ファーム利用率が 70% を超えた場合
"CustomizedMetricSpecification": {
"Metrics": [
{
"Id": "p5_concurrency",
"MetricStat": {
"Metric": {
"Namespace": "AWS/SageMaker",
"MetricName": "ConcurrentRequestsPerModel",
"Dimensions": [
{"Name": "EndpointName", "Value": "my-heterog-endpoint"},
{"Name": "VariantName", "Value": "primary"},
{"Name": "InstanceType", "Value": "ml.p5.48xlarge"},
],
},
"Stat": "Average",
},
"ReturnData": False,
},
{
"Id": "g6_concurrency",
"MetricStat": {
"Metric": {
"Namespace": "AWS/SageMaker",
"MetricName": "ConcurrentRequestsPerModel",
"Dimensions": [
{"Name": "EndpointName", "Value": "my-heterog-endpoint"},
{"Name": "VariantName", "Value": "primary"},
{"Name": "InstanceType", "Value": "ml.g6.48xlarge"},
],
},
"Stat": "Average",
},
"ReturnData": False,
},
{
"Id": "weighted_utilization",
# 種類ごとの利用率:観測値 / 最大キャパシティ、その後平均化
"Expression": "(p5_concurrency / 20 + g6_concurrency / 8) / 2",
"ReturnData": True,
},
],
},
},
)
この式において、20 と 8 は各インスタンスタイプに対して測定された最大並行処理値です。この例では、p5 は最大 20 リクエストを処理し、g6 は最大 8 を処理します。これらの値は、負荷テスト中にモデルに対して測定した最大値に置き換えてください。以下の表は、異なるトラフィックレベルにおけるメトリックの応答を示しています:
Traffic level
p5 requests
g6 requests
Weighted utilization
Action
Low
5
2
(0.25 + 0.25) / 2 = 0.25
Scale in
Moderate
12
5
(0.60 + 0.63) / 2 = 0.61
Hold
High
18
7
(0.90 + 0.88) / 2 = 0.89
Scale out
At target
14
6
(0.70 + 0.75) / 2 = 0.73
Near target — hold
Note: すべてのインスタンスタイプの処理能力が同程度であるワークロードでは、既存のスケーリングポリシーを変更せずに機能します。加重使用率メトリックは、プールメンバー間で GPU 容量に大きな差がある場合に最も価値があります。
フリートモニタリング
すべての既存の CloudWatch メトリックには、新しい InstanceType 次元が追加されました: ModelLatency, ConcurrentRequestsPerModel, GPUUtilization, InstanceCount, InvocationsPerInstance。これらは単一のエンドポイント内のハードウェアタイプ別に内訳されています。各インスタンスタイプを独立して追跡するダッシュボードやアラームを構築できます。
DescribeEndpoint は、プールごとの現在のインスタンス数を返すため、常にフリートの構成を確認できます:
response = sm.describe_endpoint(EndpointName="my-heterog-endpoint")
pools = response["ProductionVariants"][0]["InstancePools"]
Example output:
[
{"InstanceType": "ml.p5.48xlarge", "CurrentInstanceCount": 4},
{"InstanceType": "ml.g6.48xlarge", "CurrentInstanceCount": 2},
]
トラフィックルーティング
インスタンスプールを備えるエンドポイントでは、ProductionVariant で RoutingConfig を設定して、Least Outstanding Requests (LOR) ルーティングを有効にすることを推奨します。LOR は、各モデルコピーごとに現在処理中のリクエスト数が最も少ないインスタンスへ、着信する各リクエストをルーティングします。より高容量のインスタンスはリクエストを高速に処理するため、キューがより速く空になり、定常状態でも処理中のリクエスト数が低く保たれます。その結果、手動で重み設定を行うことなく、自然と相応に多くのトラフィックを受け取るようになります:
"RoutingConfig": {"RoutingStrategy": "LEAST_OUTSTANDING_REQUESTS"}
この設定がない場合、エンドポイントはデフォルトで RANDOM ルーティングとなり、インスタンスの負荷に関わらずリクエストを均等に分散します。これはプールメンバー間でスループット能力に大きな差がある場合に最適ではありません。詳細については、ProductionVariant API リファレンスの RoutingConfig をご覧ください。
更新とロールバック
ブルー/グリーンデプロイメントおよびローリングデプロイメントの両方がサポートされています。
ブルー/グリーンデプロイメントでは、トラフィックを切り替える前に、同じ優先度ベースのフォールバックロジックを使用して完全な新しい(グリーン)フリートを用意します。ヘルスチェックが成功すればトラフィックが切り替わり、失敗すれば自動的にロールバックされ、ブルーフェートは維持されたままエンドポイントは常に InService の状態を保ちます。
ローリングデプロイメントでは、設定可能なバッチ単位(一度にインスタンスの 5〜50 パーセント)でフリートを更新するため、フルサイズのブルー/グリーンフェートよりも追加リソースを少なく済ませることができます。これは特に大規模モデルや需要の高い GPU インスタンスタイプにおいて非常に価値があります。SageMaker AI は各新しいバッチのプロビジョニング時に優先度ベースのフォールバックロジックを適用します。ベイク期間中に CloudWatch アラームがトリガーされると、トラフィックは自動的にロールバックされます。設定の詳細については ローリングデプロイメントの使用 を参照してください。
前提条件
開始する前に、以下の準備を完了していることを確認してください:
- SageMaker AI エンドポイントのインスタンスプールサポートを利用するには、AWS アカウントに sagemaker:CreateEndpointConfig、sagemaker:CreateEndpoint、および sagemaker:UpdateEndpoint の IAM 権限が必要です。
- Amazon S3 にアーティファクトを格納した SageMaker モデルが少なくとも 1 つ必要です。
- Boto3 バージョン 1.43.1 以降(Python SDK におけるインスタンスプール [InstancePools] サポート用)
- (オプション)ターゲットのインスタンスタイプごとに最適化されたモデルアーティファクト、または SageMaker AI の推論推奨機能から生成された ModelPackage
SageMaker AI エンドポイントにおけるインスタンスプールサポートは、すべての商用 AWS リージョンで利用可能です。AWS Management Console、AWS Command Line Interface (AWS CLI)、または AWS SDK を通じて開始できます。
インスタンスプールを備えたエンドポイントの構成ワークフロー
インスタンスプールの構成には 2 つの方法があります。新しい Amazon SageMaker AI エンドポイントを構築する場合と、既存の Amazon SageMaker AI エンドポイントに適用する場合です。
- 新しいエンドポイントを作成する場合は、以下の図がワークフローを示しています:
インスタンスタイプを選択し、優先順位を割り当てます(1 が最高優先度)。
- 各インスタンスタイプごとに最適化されたモデルを用意するか、SageMaker AI の推論推奨機能を実行して生成します。
エンドポイント構成を作成するには <c
原文を表示
As organizations scale generative AI workloads in production, securing reliable GPU compute has become one of the most persistent operational challenges. Large language models (LLMs) and multimodal architectures demand specific instance types and when that capacity isn’t available, endpoints fail before they serve a single request.
Building a real-time inference endpoint on Amazon SageMaker AI has meant committing to a single instance type at creation time. When that type had insufficient capacity, the endpoint failed to reach a running state. You updated your configuration, selected a different instance type, and retried repeating the cycle until a provisioning attempt succeeded.
Today, Amazon SageMaker AI introduces capacity aware instance pool for new and existing inference endpoints. You define a prioritized list of instance types, and SageMaker AI automatically works through your list whenever capacity is constrained at creation, during scale-out, and during scale-in. Your endpoint provisions on available AI Infrastructure without manual intervention. This capability is available for Single Model Endpoints, Inference Component-based endpoints, and Asynchronous Inference endpoints.
This post walks through how instance pools work and how to get started, whether you’re creating a new endpoint or migrating an existing one.
The problem
When you deploy a model to a SageMaker AI inference endpoint whether real-time or asynchronous, you specify a single instance type. If that type doesn’t have available capacity, the endpoint fails to create. This limitation appears at every stage of the endpoint lifecycle.
Endpoint creation fails on capacity. When your preferred instance type isn’t available, SageMaker AI returns an *Insufficient Capacity* error. Getting to a running endpoint requires manually iterating through alternatives, with each attempt consuming significant time before you know the outcome.
Autoscaling can’t grow the fleet. When a scale-out event triggers and your instance type has insufficient capacity, the autoscaler retries the same type indefinitely. Traffic continues to increase while your endpoint stays at its current size.
Scale-down has no priority awareness. With a single instance type, there’s no concept of preferred compared to fallback hardware. Every instance is a candidate for removal without distinction.
Observability is aggregated, not actionable. Amazon CloudWatch metrics roll up at the endpoint level. When investigating a latency or capacity issue, the metrics indicate that something is wrong but not which instance type is the cause.
How it works: Priority-based instance pools
You define a ranked list of instance types called *instance pools* in your endpoint configuration. SageMaker AI works through that list automatically whenever capacity is constrained.
Your endpoints come up. SageMaker AI tries your first-choice instance type. If capacity isn’t available, it immediately tries your second choice, then your third. There’s no manual retry required. Your endpoint reaches InService on the first available AI infrastructure in minutes.
Your endpoints stay up. When auto scaling triggers and your preferred instance type is constrained, SageMaker AI scales out on the next available type in your priority list, so traffic keeps flowing.
Your fleet trends toward preferred hardware. During scale-in, SageMaker AI removes your lowest-priority (fallback) instances first. On subsequent scale-out events, it again tries your highest-priority type first. As your preferred hardware becomes available, your fleet naturally shifts back toward it over time and no manual intervention is required.
You see everything. Every existing CloudWatch metric now includes an InstanceType dimension, so you can track latency, throughput, GPU utilization, and instance count per instance type within a single endpoint.
To learn more, see the Amazon SageMaker AI documentation and explore the sample notebook on GitHub.
The right model for each instance type
Fallback instance types often differ in GPU memory, compute capability, and architecture. A model optimized for a high-memory multi-GPU instance won’t necessarily run on a smaller single-GPU fallback. There are two ways to match each instance type in your pool list to a correctly configured model.
Option 1: Bring your own optimized models
If you already know your instance type targets, prepare model artifacts for each. For your primary high-end instance, you might use tensor parallelism across multiple GPUs. For a mid-tier fallback, you might apply speculative decoding to accelerate inference. For your lowest-priority fallback, you might use INT4 quantization to fit within a smaller memory budget.
Create a separate SageMaker AI model for each configuration and reference it using ModelNameOverride in each InstancePools entry (for Single Model Endpoints) or in per-instance-type Specifications (for InferenceComponent-based endpoints). When SageMaker AI falls back to a lower-priority pool, it deploys the model that you prepared for that hardware.
Option 2: Use SageMaker AI inference recommendations
If you’d rather not optimize each hardware target manually, SageMaker AI inference recommendations can generate hardware-specific configurations for you. Provide your base model and SageMaker AI produces optimized configurations across your target instance types using techniques like speculative decoding and quantization.
The recommendation job returns one result per target instance type. Each result includes a ModelPackageArn and an InferenceSpecificationName in the AIRecommendationModelDetails response, identifying the configuration for that specific hardware. You create one SageMaker AI model per result using both fields, then reference each using ModelNameOverride in its corresponding pool entry—the same pattern as Option 1, with the service handling the optimization work.
MODEL_PACKAGE_ARN = "arn:aws:sagemaker:us-west-2:123456789012:model-package/MyModelPkgGroup/1"
# Create one model per instance type using both fields from AIRecommendationModelDetails.
sm.create_model(
ModelName="my-llm-for-p5",
PrimaryContainer={
"ModelPackageName": MODEL_PACKAGE_ARN,
"InferenceSpecificationName": "p5-48xlarge-optimized",
},
ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerRole",
)
sm.create_model(
ModelName="my-llm-for-g6",
PrimaryContainer={
"ModelPackageName": MODEL_PACKAGE_ARN,
"InferenceSpecificationName": "g6-48xlarge-optimized",
},
ExecutionRoleArn="arn:aws:iam::123456789012:role/SageMakerRole",
)
# Then reference each via ModelNameOverride per pool entry — see Setting up below.Auto scaling on a mixed fleet
Auto scaling follows the same priority logic that you define at creation time. Scale-out tries your highest-priority pool first, falling back to the next pool if capacity is unavailable. Scale-in removes your lowest-priority instances first, preserving your preferred hardware as the fleet contracts.
Building a weighted scaling metric
Because your fleet contains instance types with different throughput capacities, default aggregated metrics can misrepresent actual usage. Consider a p5 instance handling 18 concurrent requests alongside a g6 handling 7 averaging those raw numbers to 12.5 doesn’t accurately reflect the load on either type.
You can now use CloudWatch metric math to build a weighted metric based on *per-type utilization ratios*. Each term divides a type’s observed concurrency by its maximum capacity, producing a value between 0.0–1.0. Averaging those ratios gives a fleet-level usage signal on the same 0.0–1.0 scale as TargetValue. Setting TargetValue to 0.7 means: scale out when the weighted average exceeds 70 percent of capacity across all instance types in the fleet.
aas = boto3.client("application-autoscaling")
aas.put_scaling_policy(
PolicyName="weighted-utilization-scaling",
ServiceNamespace="sagemaker",
ResourceId="endpoint/my-heterog-endpoint/variant/primary",
ScalableDimension="sagemaker:variant:DesiredInstanceCount",
PolicyType="TargetTrackingScaling",
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 0.7, # scale out above 70% weighted fleet utilization
"CustomizedMetricSpecification": {
"Metrics": [
{
"Id": "p5_concurrency",
"MetricStat": {
"Metric": {
"Namespace": "AWS/SageMaker",
"MetricName": "ConcurrentRequestsPerModel",
"Dimensions": [
{"Name": "EndpointName", "Value": "my-heterog-endpoint"},
{"Name": "VariantName", "Value": "primary"},
{"Name": "InstanceType", "Value": "ml.p5.48xlarge"},
],
},
"Stat": "Average",
},
"ReturnData": False,
},
{
"Id": "g6_concurrency",
"MetricStat": {
"Metric": {
"Namespace": "AWS/SageMaker",
"MetricName": "ConcurrentRequestsPerModel",
"Dimensions": [
{"Name": "EndpointName", "Value": "my-heterog-endpoint"},
{"Name": "VariantName", "Value": "primary"},
{"Name": "InstanceType", "Value": "ml.g6.48xlarge"},
],
},
"Stat": "Average",
},
"ReturnData": False,
},
{
"Id": "weighted_utilization",
# Utilization ratio per type: observed / max_capacity, then averaged
"Expression": "(p5_concurrency / 20 + g6_concurrency / 8) / 2",
"ReturnData": True,
},
],
},
},
)
In this expression, 20 and 8 are the maximum concurrency values measured for each instance type. A p5 handles up to 20 requests and a g6 handles up to 8 in this example. Replace these values with the maximums you measure for your model during load testing. The following table shows how the metric responds at different traffic levels:
Traffic level
p5 requests
g6 requests
Weighted utilization
Action
Low
5
2
(0.25 + 0.25) / 2 = 0.25
Scale in
Moderate
12
5
(0.60 + 0.63) / 2 = 0.61
Hold
High
18
7
(0.90 + 0.88) / 2 = 0.89
Scale out
At target
14
6
(0.70 + 0.75) / 2 = 0.73
Near target — hold
Note: For workloads where all instance types have similar throughput capacity, your existing scaling policy works without modification. The weighted usage metric is most valuable when pool members differ significantly in GPU capacity.
Monitoring your fleet
All existing CloudWatch metrics now include a new InstanceType dimension: ModelLatency, ConcurrentRequestsPerModel, GPUUtilization, InstanceCount, and InvocationsPerInstance—broken down by hardware type within a single endpoint. You can build dashboards and alarms that track each instance type independently.
DescribeEndpoint returns the current instance count per pool, so you always know your fleet composition:
response = sm.describe_endpoint(EndpointName="my-heterog-endpoint")
pools = response["ProductionVariants"][0]["InstancePools"]
Example output:
[
{"InstanceType": "ml.p5.48xlarge", "CurrentInstanceCount": 4},
{"InstanceType": "ml.g6.48xlarge", "CurrentInstanceCount": 2},
]Traffic routing
For endpoints with instance pools, we recommend enabling Least Outstanding Requests (LOR) routing by setting RoutingConfig in your ProductionVariant. LOR routes each incoming request to the instance with the fewest in-flight requests per model copy. Because higher-capacity instances process requests faster, they drain their queues more quickly and maintain lower in-flight counts at steady state. This means that they naturally receive proportionally more traffic without any manual weight configuration:
"RoutingConfig": {"RoutingStrategy": "LEAST_OUTSTANDING_REQUESTS"}Without this setting, the endpoint defaults to RANDOM routing, which distributes requests evenly regardless of instance load. This is less optimal when pool members differ significantly in throughput capacity. For full details, see RoutingConfig in the ProductionVariant API reference.
Updates and rollbacks
Both blue/green and rolling deployments are supported.
Blue/green deployments provision a complete new (green) fleet using the same priority-based fallback logic before shifting traffic. If health checks pass, traffic cuts over. If they fail, automatic rollback preserves your blue fleet and your endpoint stays InService throughout.
Rolling deployments update your fleet in configurable batches (5–50 percent of instances at a time), requiring less additional capacity than a full blue/green fleet—particularly valuable for large models or GPU instance types in high demand. SageMaker AI applies the priority-based fallback logic when provisioning each new batch. If a CloudWatch alarm trips during a baking period, traffic rolls back automatically. See Use rolling deployments for configuration details.
Prerequisites
Before you get started, make sure that you have:
- An AWS account with sagemaker:CreateEndpointConfig, sagemaker:CreateEndpoint, and sagemaker:UpdateEndpoint IAM permissions
- At least one SageMaker model with artifacts in Amazon S3
- Boto3 version 1.43.1 or later (for InstancePools support in the Python SDK)
- (Optional) Separate optimized model artifacts per target instance type, or a ModelPackage from SageMaker AI inference recommendations
Instance pool support for SageMaker AI inference endpoints is available in all commercial AWS Regions. You can get started through the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS SDK.
Workflow to configure endpoints with instance pool
There are two ways you can configure the instance pool: for new Amazon SageMaker AI endpoint or with your existing Amazon SageMaker AI endpoint.
- If you’re creating a new endpoint, below diagram explains the workflow:
Choose your instance types and assign priorities (1 is highest).
- Prepare an optimized model for each instance type, or run SageMaker AI inference recommendations to generate them.
Create an endpoint configuration with <c
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み