Amazon Bedrock AgentCore Evaluationsで信頼性の高いAIエージェントを構築
AWSは、非決定論的なLLMベースのAIエージェントの評価課題に対処するため、開発から本番運用までのライフサイクル全体でパフォーマンスを測定するAmazon Bedrock AgentCore Evaluationsを発表した。
キーポイント
AIエージェント評価の固有の課題
LLMの非決定論的な性質により、同じユーザークエリでもツール選択、推論経路、出力が実行ごとに変わるため、従来のソフトウェアテスト手法では不十分であり、各シナリオを繰り返しテストして実際の動作パターンを理解する必要がある。
評価のための新しいアプローチの必要性
ユーザーリクエストからツール選択、実行、応答生成までの一連のインタラクションフロー全体の品質を測定する必要があり、正しいツール選択、有効なツールパラメータ、正確な応答、役立つユーザー体験といった評価基準を定義することが重要である。
Amazon Bedrock AgentCore Evaluationsの提供
AIエージェントのパフォーマンスを開発ライフサイクル全体で評価するためのフルマネージドサービスであり、複数の品質次元にわたるエージェントの精度を測定し、開発と本番運用のための2つの評価アプローチを提供する。
体系的評価の重要性
体系的な測定がなければ、チームは手動テストとリアクティブなデバッグのサイクルに陥り、APIコストを浪費する一方で、変更がエージェントのパフォーマンスを改善しているかどうかの明確な洞察が得られず、不確実性が残る。
影響分析・編集コメントを表示
影響分析
この発表は、急速に普及するAIエージェントの実運用における最大の課題である「評価と信頼性」に正面から取り組むもので、業界全体の成熟度を高める重要な一歩となる。AWSが提供する体系的な評価フレームワークは、企業がAIエージェントを本番環境で自信を持って展開するための基盤を提供し、AIエージェント開発の標準化を促進する可能性がある。
編集コメント
AIエージェントの「デモでは動くが本番では失敗する」という現実的な課題に焦点を当て、評価の重要性を説く実践的な内容。AWSのサービス紹介という形式だが、業界全体が直面する根本的な問題を明確に定義している点が価値が高い。
デモでは AI エージェントが機能し、ステークホルダーを感銘させ、テストシナリオを処理し、本番環境への展開準備ができているように見えました。しかし、実際に展開すると状況は一変しました。実際のユーザーは誤ったツール呼び出し、一貫性のない応答、そしてテスト時には誰も想定していなかった障害モードを経験しました。
その結果、期待されるエージェントの動作と本番環境での実際のユーザー体験との間にギャップが生じます。エージェント評価には、従来のソフトウェアテストでは対処できない課題が伴います。大規模言語モデル(LLM)は非決定論的であるため、同じユーザークエリでも複数回の実行で異なるツールの選択、推論経路、および出力を生成することがあります。つまり、各シナリオを繰り返しテストして、エージェントの実際の動作パターンを理解する必要があります。単一のテストパスが示すのは「起こり得ること」であり、「通常起こること」ではありません。これらのバリエーションにわたる体系的な測定が行われない場合、チームは手動テストと反応的なデバッグのサイクルから抜け出せなくなります。これにより API コストが無駄に使われる一方で、変更がエージェントのパフォーマンスを向上させるかどうかについての明確な洞察が得られません。この不確実性は、すべてのプロンプト修正をリスクのあるものとし、「このエージェントは本当に改善されたのか?」という根本的な問いに答えを残したままにします。
本稿では、開発ライフサイクル全体にわたる AI エージェントのパフォーマンスを評価するための完全管理型サービスである Amazon Bedrock AgentCore 評価機能について紹介します。このサービスが、複数の品質次元にわたってエージェントの精度をどのように測定するかを解説します。また、開発時と本番環境における 2 つの評価アプローチについて説明し、自信を持ってデプロイできるエージェントを構築するための実践的なガイダンスを提供します。
エージェント評価には新たなアプローチが必要
ユーザーがエージェントに対してリクエストを送信すると、複数の判断が順次行われます。エージェントはどのツール(もしあれば)を呼び出すかを決定し、その呼び出しを実行し、結果に基づいて応答を生成します。各ステップには潜在的な失敗ポイントが存在します:誤ったツールの選択、正しいツールへの呼び出しにおけるパラメータの誤り、あるいはツール出力を不正確な最終回答に合成することです。従来のアプリケーションでは単一の関数の出力を検証するだけで済むのに対し、エージェント評価ではこの一連のインタラクションフロー全体にわたる品質を測定する必要があります。
これにより、以下の対応を行うことで解決できる、エージェント開発者特有の課題が生じます:
- 正しいツール選択、有効なツールパラメータ、正確な応答、そして有益なユーザー体験を構成する要素について評価基準を定義してください。
- 実際のユーザー要求と期待される動作を反映したテストデータセットを構築します。
- 繰り返し実行 across して一貫性のある品質を評価できるスコアリング手法を選択します。
これらの定義のいずれもが、評価システムが何を測定するかを直接決定するものであり、これらを誤ると、間違った成果のために最適化されてしまいます。この基礎的な作業が欠如している場合、チームがエージェントに期待することと、実際に証明できることの間のギャップは、現実のビジネスリスクへと発展します。このギャップを埋めるには、*Figure 1* に示されるような継続的な評価サイクルが必要です。チームはテストケースを構築し、それをエージェントに対して実行し、結果にスコアを付け、失敗を分析し、改善を実施します。各失敗が新たなテストケースとなり、このサイクルはエージェントのあらゆる反復を通じて続きます。
*Figure 1: エージェント評価プロセスは、テストケース、エージェントの実行、スコアリング、分析、改善という継続的なサイクルに従います。失敗が新たなテストケースとなります。
しかし、このサイクルを評価ロジック自体を超えてエンドツーエンドで実行するには、相当なインフラストラクチャが必要です。チームはデータセットの選定とキュレーション、スコアリングモデルの選択とホスティング、推論容量と API レート制限の管理、エージェントのトレースを評価可能な形式に変換するデータパイプラインの構築、トレンドを可視化するダッシュボードの作成を行わなければなりません。複数のエージェントを実行している組織の場合、このオーバーヘッドは各エージェントごとに倍増します。その結果、エージェント開発チームは、ツールが示す内容に基づいて行動するよりも、評価ツールの維持管理に多くの時間を費やすことになります。これが、Amazon Bedrock AgentCore Evaluations が解決するために構築された課題です。
Amazon Bedrock AgentCore Evaluations の紹介
このサービスは AWS re:Invent 2025 でパブリックプレビューとして初めて発表され、現在は一般利用可能です。評価モデル、推論インフラストラクチャ、データパイプライン、スケーリングを処理するため、チームは評価システムの構築と維持管理ではなく、エージェントの品質向上に注力できます。組み込みの評価器(Evaluator)の場合、モデルクォータと推論容量は完全にマネージドされます。つまり、多数のエージェントを評価する組織が、自らのクォータを消費したり、評価ワークロード用に別個のインフラストラクチャを用意する必要はありません。
AgentCore Evaluations は、生成 AI の意味論的規約を含む OpenTelemetry (OTEL) トレース を用いて、エージェントの動作をエンドツーエンドで検証します。OTEL は、アプリケーションから分散トレースを収集するためのオープンソースな観測可能性標準です。生成 AI の意味論的規約は、プロンプト、コンプリート、ツール呼び出し、モデルパラメータなど、言語モデルとの相互作用に固有のフィールドを追加してこれを拡張しています。この標準に基づいて構築されるため、本サービスは、Strands Agents や LangGraph で構築されたあらゆるエージェント間、および OpenTelemetry と OpenInference で計測された環境において一貫して動作し、有意義な評価に必要な完全なコンテキストを捉えることができます。
評価は、異なるアプローチで構成可能です:
- LLM-as-a-Judge(LLM を審査員とする手法)では、明確に定義された基準を持つ構造化された評価基準に基づいて、各エージェントの相互作用を LLM が評価します。
- 正解ベースの評価は、エージェントの応答を事前に定義されたデータセットまたはシミュレーションされたデータセットと比較するために使用できます。
- カスタムコード evaluator(カスタムコード評価器)では、Lambda を評価器として呼び出し、独自のコードを実行させることができます。
LLM-as-a-Judge のアプローチでは、審査員モデルが会話履歴、利用可能なツール、実際に使用されたツール、渡されたパラメータ、システム指示など、完全な相互作用の文脈を調査し、詳細な推論を行った後にスコアを付与します。すべてのスコアには説明が付随します。チームはこれらのスコアを用いて判断を検証し、なぜ特定の相互作用が特定の評価を受けたのかを正確に理解し、何が異なって行われるべきだったかを特定できます。このアプローチは単純な合格/不合格の判定を超え、手動レビューでは達成できない規模での品質評価を可能にする構造化された評価と透明性の高い推論を提供します。
このサービスの評価アプローチを導く3つの原則があります。エビデンス駆動型開発は直感に代わり定量的指標を採用し、チームがプロンプト変更が「より良く感じる」かどうかを議論するのではなく、変更の実際の影響度を測定できるようにします。多次元評価ではエージェント行動の異なる側面を独立して評価します。これにより、単一の集計スコアに頼るのではなく、改善が必要な箇所を正確に特定することが可能になります。継続的測定は開発中に確立されたパフォーマンス基準を生産環境モニタリングと直接結びつけ、実世界の状況が変化する中でも品質が維持されることを保証します。これらの原則は、最初の開発テストから継続的な生産環境モニタリングに至るまで、エージェントのライフサイクル全体に適用されます。
エージェントのライフサイクル全体での評価
プロトタイプから本番環境への移行において、エージェントには 2 つの異なる評価ニーズが生じます。開発中、チームは代替案を比較し、キュレーションされたデータセット上でエージェントをテストし、結果を再現し、ユーザーに到達する前に変更を検証できる制御された環境を必要とします。一方、エージェントが稼働した後は、課題はスケーラブルな実世界でのインタラクションの監視へと移ります。ここでは、事前デプロイメントテストでは予測できなかったエッジケースやインタラクションパターンをユーザーが直面することになります。*Figure 2* は、初期概念検証からシャドウテスト、A/B テスト、そして継続的な本番環境モニタリングに至るまで、この旅路の各段階において評価がどのように支援するかを示しています。
*Figure 2: POC から本番環境へ、評価はデプロイ前にエージェントを検証します。エージェントが成熟するにつれ、評価はシャドウテスト、A/B テスト、および大規模な継続的モニタリングを支援します。
AgentCore Evaluations は、*Figure 3* に示すように、これらのライフサイクルフェーズに対して 2 つの補完的なアプローチをマッピングしています。オンライン評価(Online Evaluation)は継続的な本番環境監視を扱い、オンデマンド評価(On-demand Evaluation)は開発中および継続的インテグレーション・継続的デリバリー(CI/CD)ワークフローにおける制御されたテスト、ならびにグラウンドトゥルースに対する評価をサポートします。
オンデマンド評価
オンライン評価
利点
- セッションレベルの情報を考慮したターンごとのデバッグ
- コンポーネント検証
- CI/CD 統合
- 会話品質
- リーエージェントインタラクションの監視
ユースケース
- ベンチマーク
- 安定性検証
- コンポーネントモニタリング
- リリース前のチェック
- 継続的なサンプリング
- リivedashboards(ライブダッシュボード)
*** 図 3: オンライン評価は生産トラフィックを継続的に監視し、オンデマンド評価は開発中の制御されたテストをサポートします。*
生産モニタリングのためのオンライン評価
オンライン評価は、構成可能な割合のトレースを継続的にサンプリングし、選択した評価器に対してスコアリングすることで、ライブエージェントインタラクションを監視します。適用する評価器を定義し、生産トラフィックのうちどの程度の割合を評価するかを制御するサンプリールールを設定し、適切なフィルターを設定します。このサービスは、トレースの読み込み、評価の実行、および Amazon CloudWatch によって駆動される AgentCore Observability ダッシュボードでの結果表示を担当します。すでに観測性のためにトレースを収集している場合、オンライン評価はコード変更や再デプロイメントを必要とせず、既存の運用メトリクスに、説明付きの品質スコアを追加します。*図 4* はこのプロセスがどのように機能するかを示しています。
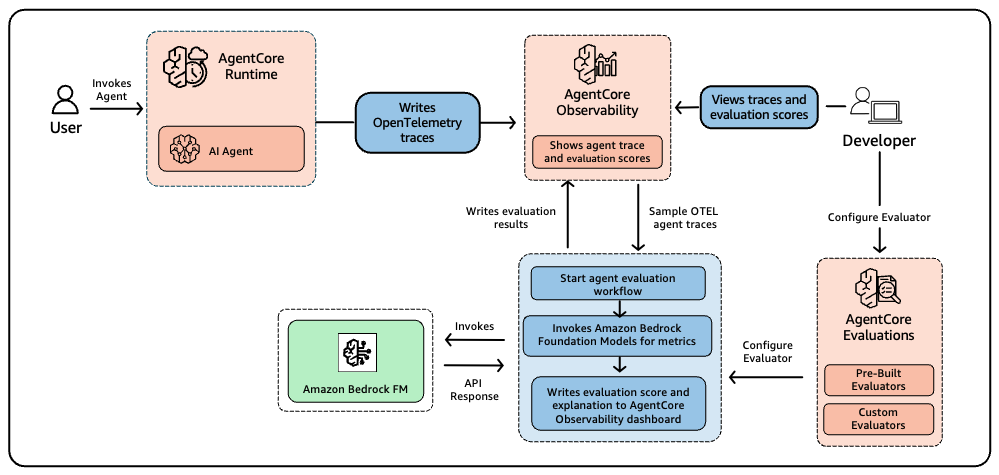
本番環境における品質上の問題は、従来のモニタリングでは見逃される形で表面化することがよくあります。レイテンシやエラー率のオペレーショナルダッシュボードが緑色(正常)を示していても、エージェントが誤ったツールを選択したり、有益でない回答を提供し始めたりすることで、ユーザーエクスペリエンスは静かに劣化している可能性があります。継続的な品質スコアリングは、評価指標を運用指標と共に追跡することで、こうした沈黙した障害を検出します。AgentCore Observability は CloudWatch 上で稼働しているため、カスタムダッシュボードを作成し、閾値を下回った瞬間にアラートが通知されるように設定できます。
開発向けのオンデマンド評価
オンデマンド評価は、開発および CI/CD ワークフロー向けに設計されたリアルタイム API です。チームは、本番展開前に変更を検証したり、CI/CD パイプラインの一部として評価スイートを実行したり、ビルド全体で回帰テストを行ったり、品質閾値に基づいて展開をゲート制御したりするためにこれを利用します。開発者は完全なセッションを選択し、ID を提供することで特定のスパン(トレース内の個々の操作)またはトレースを指定します。このサービスは完全なセッションの会話内容を考慮し、本番環境で使用するのと同じ評価器を用いて、個々のスパンやトレースに対してスコアリングを行います。一般的なユースケースには、プロンプトの変更を検証すること、代替モデル間のパフォーマンスを比較すること、品質の回帰を防ぐことが含まれます。
図 5:オンデマンド評価により、開発者はトレースデータセットの準備を行い、CI/CD パイプラインまたは開発環境を通じて評価を呼び出し、Amazon Bedrock ファウンデーションモデルによって駆動される組み込みまたはカスタム評価器を使用してスコアを受け取ることができます。
両方のモードが同じ評価器を使用するため、CI/CD でテストする内容は本番環境で監視される内容と一致し、開発ライフサイクル全体を通じて一貫した品質基準を提供します。オンデマンド評価は、アーキテクチャの意思決定や体系的な改善に必要な制御された環境を提供し、一方、オンライン評価はエージェントが稼働した後も品質モニタリングを継続させます。この 2 つのモードは、開発と本番環境の間で継続的なフィードバックループを形成し、どちらも同じ評価器セットおよびスコアリングインフラストラクチャから情報を引き出します。
エージェントを評価する方法
AgentCore Evaluations は、エージェントの相互作用を 3 つの階層レベルに整理し、何をどの粒度で評価するかを決定します。セッションは、ユーザーとエージェント間の完全な会話を表し、単一のユーザーまたはワークフローからのすべての関連する相互作用をグループ化します。各セッション内では、トレースが単一のやり取り中に発生したすべてを記録します。ユーザーがメッセージを送信して応答を受け取ると、その往復によって 1 つのトレースが生成され、そこには回答を生成するためにエージェントが行ったすべてのステップが含まれます。さらに、各トレースには、ツール呼び出しやナレッジベースからの情報取得、テキスト生成など、エージェントが実行した特定のアクションを表す個別の操作であるスパンが含まれています。
異なる評価器は、この階層の異なるレベルで動作し、あるレベルでの問題は別のレベルでの問題とは非常に異なって見えることがあります。本サービスでは、これら 3 つのレベルにまたがる 13 の事前設定済み組み込み評価器を提供しており、それぞれがエージェント行動の異なる側面を測定します(図 6)。LLM-as-a-Judge を使用したカスタム評価器や、セッション、トレース、スパンの各レベルで動作するコードベースのカスタム評価器も定義可能です。
| レベル | 評価器 | 目的 | グランドトゥルースの使用 |
|---|
セッション
ゴール達成率
会話内ですべてのユーザーのゴールが完了したかどうかを評価します。
ユーザーはゴールの完了に関する自由記述形式の主張を提供し、これがシステム行動と比較され、ゴール達成率を通じて測定されます。
トレース
有用性、正確性、一貫性、簡潔さ、忠実度、有害性、指示従順性、応答関連性、文脈関連性、拒否、ステレオタイプ化
応答の品質、精度、安全性、およびコミュニケーション効果を評価します。
トーンレベルの正解(例:各ターンごとの期待される回答や属性)は、正確性の評価をサポートします。
ツール
ツール選択精度、ツールパラメータ精度
ツールの選択判断とパラメータ抽出の精度を評価します。
ツール呼び出しの正解は、正しいツールのシーケンスを指定し、これにより「軌道完全一致」「軌道順序一致」「軌道任意順序一致」が可能になります。
*図 6: ビルトイン評価器はセッション、トレース、ツールの各レベルで動作します。各レベルはエージェントの行動の異なる側面を測定します。正解は、セッション、トレース、ツールレベルでの評価のために、主張、期待される応答、および期待される軌道として提供できます。*
各レベルを独立して評価することで、チームは問題がツールの選択、応答の生成、あるいはセッションレベルの計画のいずれに起因するかを診断できます。エージェントは正確なパラメータで適切なツールを選択したとしても、最終的な応答においてそのツールの出力を不十分に統合してしまう可能性があります。このパターンは、各レベルを個別に評価した場合のみ顕在化します。
エージェントの主要な目的が、優先すべき評価指標を決定します。カスタマーサービス用エージェントは、定義されたガードレール内でユーザーの問題を解決することが満足度に直接影響するため、「有用性」、「目標達成率」、「指示遵守」に焦点を当てるべきです。検索拡張生成(RAG)コンポーネントを持つエージェントは、応答が提供された文脈に基づいていることを保証するために「正しさ」と「忠実度」から最も恩恵を受けます。
ツール依存度の高いエージェントには、「ツールの選択精度」と「ツールパラメータの精度」スコアが強く求められます。3 つまたは 4 つの評価指標から始めることが推奨されます。
原文を表示
Your AI agent worked in the demo, impressed stakeholders, handled test scenarios, and seemed ready for production. Then you deployed it, and the picture changed. Real users experienced wrong tool calls, inconsistent responses, and failure modes nobody anticipated during testing.
The result is a gap between expected agent behavior and actual user experience in production. Agent evaluation introduces challenges that traditional software testing wasn’t designed to handle. Because large language models (LLMs) are non-deterministic, the same user query can produce different tool selections, reasoning paths, and outputs across multiple runs. This means that you must test each scenario repeatedly to understand your agent’s actual behavior patterns. A single test pass tells you what can happen, not what typically happens. Without systematic measurement across these variations, teams are trapped in cycles of manual testing and reactive debugging. This burns through API costs without clear insight into whether changes improve agent performance. This uncertainty makes every prompt modification risky and leaves a fundamental question unanswered: “Is this agent actually better now?”
In this post, we introduce Amazon Bedrock AgentCore Evaluations, a fully managed service for assessing AI agent performance across the development lifecycle. We walk through how the service measures agent accuracy across multiple quality dimensions. We explain the two evaluation approaches for development and production and share practical guidance for building agents you can deploy with confidence.
Why agent evaluation requires a new approach
When a user sends a request to an agent, multiple decisions happen in sequence. The agent determines which tools (if any) to call, executes those calls, and generates a response based on the results. Each step introduces potential failure points: selecting the wrong tool, calling the right tool with incorrect parameters, or synthesizing tool outputs into an inaccurate final answer. Unlike traditional applications where you test a single function’s output, agent evaluation requires measuring quality across this entire interaction flow.
This creates specific challenges for agent developers that can be addressed by doing the following:
- Define evaluation criteria on what constitutes a correct tool selection, valid tool parameters, an accurate response, and a helpful user experience.
- Build test datasets that represent real user requests and expected behaviors.
- Choose scoring methods that can assess quality consistently across repeated runs.
Each of these definitions directly determines what your evaluation system measures and getting them wrong means optimizing for the wrong outcomes. Without this foundational work, the gap between what teams hope their agents do and what they can prove their agents do becomes a real business risk.Bridging this gap requires a continuous evaluation cycle, as shown in *Figure 1.* Teams build test cases, run them against the agent, score the results, analyze failures, and implement improvements. Each failure becomes a new test case, and the cycle continues through every iteration of the agent.
*Figure 1: The agent evaluation process follows a continuous cycle of test cases, agent execution, scoring, analysis, and improvements. Failures become new test cases.*
Running this cycle end to end, however, requires significant infrastructure beyond the evaluation logic itself. Teams must curate datasets, select and host scoring models, manage inference capacity and API rate limits, build data pipelines that transform agent traces into evaluation-ready formats, and create dashboards to visualize trends. For organizations running multiple agents, this overhead multiplies with each one. The result is that agent developer teams end up spending more time maintaining evaluation tooling than acting on what it tells them. This is the problem Amazon Bedrock AgentCore Evaluations was built to address.
Introducing Amazon Bedrock AgentCore Evaluations
First launched in public preview at AWS re:Invent 2025, the service is now generally available. It handles the evaluation models, inference infrastructure, data pipelines, and scaling so teams can focus on improving agent quality rather than building and maintaining evaluation systems. For built-in evaluators, model quota and inference capacity are fully managed. This means that organizations evaluating many agents aren’t consuming their own quotas or provisioning separate infrastructure for evaluation workloads.
AgentCore Evaluations examine agent behavior end-to-end using OpenTelemetry (OTEL) traces with generative AI semantic conventions. OTEL is an open source observability standard for collecting distributed traces from applications. The generative AI semantic conventions extend it with fields specific to language model interactions, including prompts, completions, tool calls, and model parameters. By building on this standard, the service works consistently across agents built with any Strands Agents or LangGraph, and instrumented with OpenTelemetry and OpenInference, capturing the full context needed for meaningful evaluation.
The evaluations can be configured with different approaches:
- LLM-as-a-Judge where an LLM evaluates each agent interaction against structured rubrics with clearly defined criteria.
- Ground Truth based evaluation can be used to compare the agent responses against pre-defined or simulated datasets.
- Custom code evaluators where you can bring in a Lambda as a evaluator with your own custom code.
In the LLM-as-a-Judge approach, the Judge model examines the full interaction context, including conversation history, available tools, tools used, parameters passed, and system instructions, then provides detailed reasoning before assigning a score. Every score comes with an explanation. Teams can use these scores to verify judgments, understand exactly why an interaction received a particular rating, and identify what should have happened differently. This approach goes beyond simple pass/fail judgments, providing the structured evaluation and transparent reasoning that enable quality assessment at a scale that manual review cannot match.
Three principles guide how the service approaches evaluation. Evidence-driven development replaces intuition with quantitative metrics, so teams can measure the actual impact of changes rather than debating whether a prompt modification “feels better.” Multi-dimensional assessment evaluates different aspects of agent behavior independently. This makes it possible to pinpoint exactly where improvements are needed rather than relying on a single aggregate score. Continuous measurement connects the performance baselines established during development directly to production monitoring, making sure that quality holds up as real-world conditions evolve. These principles apply throughout the agent lifecycle, from the first round of development testing through ongoing production monitoring.
Evaluation across the agent lifecycle
An agent’s journey from prototype to production creates two distinct evaluation needs. During development, teams need controlled environments where they can compare alternatives, test the agent on curated datasets, reproduce results, and validate changes before they reach users. After the agent is live, the challenge shifts to monitoring real-world interactions at scale, where users encounter edge cases and interaction patterns that no amount of pre-deployment testing anticipated. *Figure 2* illustrates how evaluation supports each stage of this journey, from initial proof of concept through shadow testing, A/B testing, and continuous production monitoring.
*Figure 2: From POC to production, evaluation validates agents before deployment. As agents mature, evaluation supports shadow testing, A/B testing, and continuous monitoring at scale.*
AgentCore Evaluations map two complementary approaches to these lifecycle phases, as shown in *Figure 3*. Online evaluation handles continuous production monitoring, while on-demand evaluation supports controlled testing during development and continuous integration and continuous delivery (CI/CD) workflows, including evaluations against ground truth.
On-demand Evaluation
Online Evaluation
Advantages
- Turn-by-turn debug considering session level information
- Component validation
- CI/CD integration
- Conversation quality
- Monitoring live agent interactions
Use cases
- Benchmarking
- Stability validation
- Component monitoring
- Pre-release check
- Continuous sampling
- Live dashboards
*** Figure 3: Online evaluation monitors production traffic continuously, while on-demand evaluation supports controlled testing during development.*
Online evaluation for production monitoring
Online evaluation monitors live agent interactions by continuously sampling a configurable percentage of traces and scoring them against your chosen evaluators. You define which evaluators to apply, set sampling rules that control what fraction of production traffic gets evaluated, and set up appropriate filters. The service handles reading traces, running evaluations, and surfacing results in the AgentCore Observability dashboard** powered by Amazon CloudWatch. If you’re already collecting traces for observability, online evaluation adds quality scores with explanation, alongside your existing operational metrics without requiring code changes or re-deployments. *Figure 4* shows how this process works.
Quality issues in production often surface in ways that traditional monitoring misses. Operational dashboards may show green across latency and error rates while user experience quietly degrades because the agent starts selecting wrong tools or providing less helpful responses. Continuous quality scoring catches these silent failures by tracking evaluation metrics alongside operational ones. Because AgentCore Observability runs on CloudWatch, you can create custom dashboards and set alarms to get alerted the moment scores drop below your thresholds.
On-demand evaluation for development
On-demand evaluation is a real-time API designed for development and CI/CD workflows. Teams use it to test changes before deployment, run evaluation suites as part of CI/CD pipelines, perform regression testing across builds, and gate deployments on quality thresholds. Developers select a full session and specify exact spans (individual operations within a trace) or traces by providing their IDs. The service considers the full session conversation and scores individual span/traces against the same evaluators used in production. Common use cases include validating prompt changes, comparing model performance across alternatives, and preventing quality regressions.
Figure 5: On-demand evaluation enables developers to prepare trace datasets, invoke evaluations through a CI/CD pipeline or development environment, and receive scores using built-in or custom evaluators powered by Amazon Bedrock foundation models.
Because both modes use the same evaluators, what you test in CI/CD is what you monitor in production, giving you consistent quality standards across the entire development lifecycle. On-demand evaluation provides the controlled environment needed for architecture decisions and systematic improvement, while online evaluation maintains quality monitoring continues after the agent is live. Together, the two modes form a continuous feedback loop between development and production, and both draw from the same set of evaluators and scoring infrastructure.
How AgentCore evaluates your agent
AgentCore Evaluations organizes agent interactions into a three-level hierarchy that determines what can be evaluated and at what granularity. A session represents a complete conversation between a user and your agent, grouping all related interactions from a single user or workflow. Within each session, a trace captures everything that happens during a single exchange. When a user sends a message and receives a response, that round trip produces one trace containing every step that the agent took to generate its answer. Each trace in turn contains individual operations called spans, representing specific actions your agent performed, such as invoking a tool, retrieving information from a knowledge base, or generating text.
Different evaluators operate at different levels of this hierarchy, and problems at one level can look very different from problems at another. The service provides 13 pre-configured built-in evaluators organized across these three levels, each measuring a distinct aspect of agent behavior *(Figure 6)*. You can define custom evaluators using LLM-as-a-Judge and custom code evaluators that can work on session, trace and span levels.
Level
Evaluators
Purpose
Ground Truth Use
Session
Goal Success Rate
Assesses whether all user goals were completed within a conversation
User provides free form textual assertions of goal completion, which are compared against system behavior and measured via Goal Success Rate
Trace
Helpfulness, Correctness, Coherence, Conciseness, Faithfulness, Harmfulness, Instruction Following, Response Relevance, Context Relevance, Refusal, Stereotyping
Evaluates response quality, accuracy, safety, and communication effectiveness
Turn level ground truth (e.g., expected answer or attributes per turn) supports evaluation of Correctness
Tool
Tool Selection Accuracy, Tool Parameter Accuracy
Assesses tool selection decisions and parameter extraction precision
Tool call ground truth specifies the correct tool sequence enabling Trajectory Exact Order Match, Trajectory In-Order Match, and Trajectory Any Order Match
*Figure 6: Built-in evaluators operate at session, trace, and tool levels. Each level measures different aspects of agent behavior. Ground Truth can be provided as assertions, expected response and expected trajectory for evaluation on session, trace and tool level.*
Evaluating each level independently helps teams to diagnose whether a problem originates in tool selection, response generation, or session-level planning. An agent might choose the right tool with accurate parameters but then synthesize the tool’s output poorly in its final response. This pattern only becomes visible when each level is assessed on its own. Your agent’s primary purpose guides which evaluators to prioritize. Customer service agents should focus on *Helpfulness*, *Goal Success Rate*, and *Instruction Following*, since resolving user issues within defined guardrails directly impacts satisfaction. Agents with Retrieval Augmented Generation (RAG) components benefit most from *Correctness* and *Faithfulness* to make sure that responses are grounded in the provided context. Tool-heavy agents need strong *Tool Selection Accuracy* and *Tool Parameter Accuracy* scores. It’s recommended to start with three or four evalu
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み