Amazon Bedrock AgentCore を活用したタンパク質研究コパイロットの構築方法
AWS は、Strands Agents SDK と Amazon Bedrock AgentCore を活用し、タンパク質研究のための自然言語クエリ対応コパイロットを構築する具体的な実装例とアーキテクチャを提供した。
キーポイント
多機能型エージェントの構成
Strands Agents SDK を用いて、自然言語のパース、ベクトル類似度検索、AI による要約という 3 つの専門ツールを単一のエージェント内で統合する手法を示している。
高性能な推論基盤の構築
タンパク質構造解析に特化したカスタム ML モデル(ESM-C 300M)を SageMaker AI サーバーレスエンドポイントでデプロイし、冷間起動時間を最小化する構成を採用している。
高度なデータ検索機能
Amazon Aurora PostgreSQL-Compatible Edition に格納されたペプチドエンベディングに対し、pgvector を使用してメタデータフィルタリングを併用した高速なベクトル類似度検索を実現している。
実用的な研究支援インターフェース
研究者が専門知識に頼らずとも自然言語で「デングウイルスペプチド LPAIVREAI に似た 10 個を検索」などのクエリを実行し、構造化された結果と科学的要約を得られるコパイロットを構築可能である。
サーバーレスエンドポイントの構成
PyTorch CPU 推論コンテナを使用し、6144 MB のメモリと最大並列処理数 5 でサーバーレス設定されたエンドポイントをデプロイしています。
ベクトル検索基盤の構築
ペプチドの埋め込み値は、pgvector 拡張機能を備えた Amazon Aurora PostgreSQL Serverless v2 に保存され、効率的な検索を可能にしています。
ベクトル検索とメタデータフィルターの統合
PostgreSQLのJSONBカラムに保存された生物学的メタデータ(種、宿主など)を用いて、コサイン類似度に基づくベクトル検索結果を絞り込むハイブリッド検索が可能。
影響分析・編集コメントを表示
影響分析
この記事は、AWS の最新機能である AgentCore と Strands SDK を活用した具体的な業界特化型アプリケーション(バイオインフォマティクス)の実装例を示しており、汎用的な LLM アプリケーションから、専門領域における実用価値の高いエージェントへの移行を促す重要な示唆を含んでいます。特に、カスタム ML モデルの高速デプロイとベクトル検索の統合は、大規模データ処理が必要な研究分野において即座に適用可能なアーキテクチャとして注目されます。
編集コメント
AWS は、単なるツール紹介に留まらず、バイオインフォマティクスという複雑なドメインにおいて、最新の AI エージェント技術をどう組み合わせて実用化するかを具体的に示しています。専門家の知見が必要な分野での自動化は、研究スピードの劇的な向上に寄与する可能性が高いです。
タンパク質研究者は、構造的に類似した候補を見つけるために数千のペプチド配列を手動で検索するという時間のかかる課題に直面しています。これは遅く、エラーが発生しやすく、結果を解釈するには深い専門知識が必要です。タンパク質研究のコパイロットを構築することで、大規模データセット全体で構造的に類似したペプチドを検索する方法を変革できます — 自然言語クエリ、自動埋め込み生成、AI による結果要約を単一の会話型インターフェースで実現します。
この投稿では、3 つの機能を組み合わせた会話型のタンパク質研究アシスタントの構築方法を示します:
-構造的な検索パラメータを抽出するための自然言語クエリ解析。
-専門的な言語モデルを使用したタンパク質埋め込みに対するベクトル類似度検索。
-検索結果の AI 生成による科学的要約。
このシステムは、Strands Agents SDK を使用して 1 つのエージェント内で 3 つの専門ツールをオーケストレーションし、Amazon Bedrock AgentCore にデプロイして本番環境で提供され、ペプチド埋め込みは Amazon Aurora PostgreSQL-Compatible Edition の pgvector に保存されます。
この投稿を終える頃には、以下を実行する方法を示すエンドツーエンドのエージェントアプリケーションを構築していることになります:
- 「デングウイルスペプチド LPAIVREAI に類似する 10 のペプチドを検索」などの自然言語ユーザー入力を、Strands Agents SDK のツール使用パターンを用いて構造化されたツールパラメータに変換します。
- 結合された重み付きのカスタム機械学習モデル(ESM-C 300M)を、Amazon SageMaker AI サーバーレスエンドポイントとしてデプロイし、高速なコールドスタートを実現します。
- Amazon Aurora PostgreSQL 上の pgvector を用いたベクトル類似度検索とメタデータフィルタリングを、単一のクエリ内で統合します。
- ネストされた LLM エージェントを含む複数の専門ツールを、単一の Bedrock AgentCore ランタイム内でオーケストレーションし、検索結果の科学的要約を生成します。
前提条件
本記事の手順を追うためには、以下の準備が必要です:
- Amazon Bedrock の基盤モデル(Anthropic Claude Sonnet 4.6)へのアクセス権限を持つ AWS アカウント。
- Python 3.12 以降。
- 適切な認証情報を設定した AWS Command Line Interface (AWS CLI)。
- Amazon Bedrock、Amazon SageMaker AI、Amazon Aurora、Amazon Elastic Container Service (Amazon ECS)、および AWS CodeBuild に対する IAM 権限。
- bedrock-agentcore-starter-toolkit のインストール(pip install bedrock-agentcore-starter-toolkit)。
- IEDB ウイルスエピトープデータセット。
推定デプロイ時間:30〜45 分。コスト見積もりについては、Bedrock、SageMaker AI、Aurora Serverless v2、および AWS Fargate の AWS プライシングページをご確認ください。
ソリューションの概要
このコパイロットは、1 つの Strands エージェントが 3 つの専門ツールを調整して研究ワークフロー全体を処理する「ツール使用」パターンに従います。研究者が自然言語でクエリを入力すると、エージェントはそのクエリを構造化されたパラメータに解析し、タンパク質埋め込み(protein embeddings)を用いて類似ペプチドを検索し、科学的な文脈を付与して結果を要約します。
以下の図はアーキテクチャを示しています:
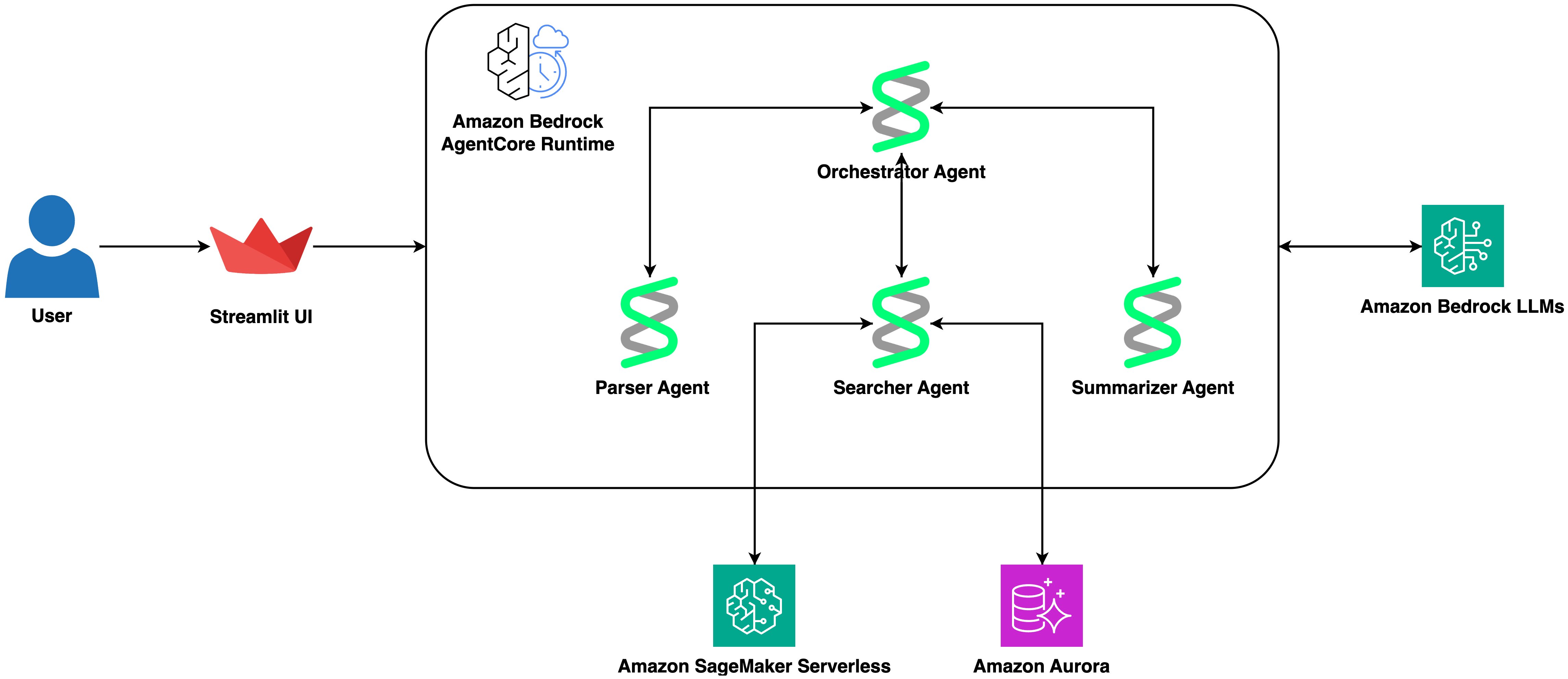
このアーキテクチャには 5 つのコンポーネントがあります:
- AWS Fargate で実行されている Streamlit フロントエンドが会話型インターフェースを提供します。これは AgentCore ランタイムへクエリを送信し、結果をダウンロード可能なテーブルを含む構造化形式で表示します。
- Amazon Bedrock AgentCore ランタイム内で動作する 1 つの Strands エージェントがワークフローをオーケストレーションします。このエージェントは Bedrock Converse API を介して Anthropic Claude Sonnet 4.6 を使用し、@tool デコレータで定義された 3 つのツールにアクセス可能です。
- パーサーツール:自然言語クエリから構造化された検索パラメータ(配列、種別フィルター、結果制限)を抽出するために、専用の Strands エージェント(LLM-as-parser パターン)を利用します。
- サーチャーツール:ESM-C 300M を実行する Amazon SageMaker AI サーバーレスエンドポイントを通じてタンパク質の埋め込みベクトルを生成し、Amazon Aurora PostgreSQL の pgvector とコサイン類似度検索を実行します。
- サマライザーツール:もう一つの専用の Strands エージェントを使用して検索結果を分析し、さらなる調査のための提案を含む簡潔な科学的要約を生成します。
この単一ランタイム・マルチツール設計は、関心の分離を明確に保ちつつデプロイをシンプルに維持します。各ツールは固有の機能をカプセル化しており、オーケストレーターエージェントがユーザーのクエリに基づいていつどのようにそれらを呼び出すかを決定します。
ESM-C 300M を用いたタンパク質エンベディング
類似性検索の中核を担うのは、EvolutionaryScale(ESM ベース)から提供されるタンパク質言語モデル「ESM-C 300M」です。このモデルは、アミノ酸配列の構造的および機能的な特性を捉えた 960 次元のエンベディング(埋め込み表現)を生成します。生物学的機能が類似する 2 つのペプチドは、ベクトル空間上で近接したエンベディングを生成するため、アラインメント(配列対照合わせ)を必要とせずに類似性検索が可能となります。
ESM-C 300M は、Amazon SageMaker AI のサーバーレスエンドポイントとしてデプロイされており、アイドル時にはスケールゼロとなり、呼び出し間もコストが発生しません。モデルの重みは推論時に HuggingFace からダウンロードする必要がないよう、デプロイアーティファクトにバンドルされています。これは、コールドスタート遅延が問題となるサーバーレスエンドポイントにおいて極めて重要な対策です。
推論ハンドラーはモデルアーキテクチャを直接構築し、事前パッケージ化された重みを読み込みます:
from esm.models.esmc import ESMC
from esm.tokenization import get_esmc_model_tokenizers
def model_fn(model_dir):
weights_path = os.path.join(model_dir, "weights", "esmc_300m.pt")
model = ESMC(
d_model=960,
n_heads=15,
n_layers=30,
tokenizer=get_esmc_model_tokenizers(),
use_flash_attn=False,
)
state_dict = torch.load(weights_path, map_location="cpu")
model.load_state_dict(state_dict)
model.eval()
return model予測ハンドラー(predict_fn)はタンパク質配列を受け取り、それを符号化して平均プーリングされたエンベディングを返します。
def predict_fn(input_data, model):
sequence = input_data["sequence"]
protein = ESMProtein(sequence=sequence)
protein_tensor = model.encode(protein)
logits_output = model.logits(
protein_tensor, LogitsConfig(sequence=True, return_embeddings=True)
)
embeddings = logits_output.embeddings
mean_embeddings = embeddings[:, 1:-1, :].mean(dim=1)
return mean_embeddings[0].detach().cpu().tolist()
The endpoint is deployed as a serverless configuration with 6144 MB memory and a max concurrency of 5, using the PyTorch 2.6.0 CPU inference container. The model packaging script downloads weights once via from_pretrained, saves the state dict, and bundles it with the inference code into a model.tar.gz with the required code/ directory structure for SageMaker AI.
Vector search with Aurora PostgreSQL and pgvector
Peptide embeddings are stored in Amazon Aurora PostgreSQL-Compatible Edition Serverless v2 with the pgvector extension. The database schema is straightforward:
CREATE TABLE peptides (
id SERIAL PRIMARY KEY,
sequence TEXT NOT NULL,
embedding vector(960),
properties JSONB,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX peptides_embedding_idx
ON peptides USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
プロパティの JSONB カラムには、生物学的メタデータ(種、由来生物、由来分子、エピトープ位置など)が格納されており、ベクトル検索とメタデータフィルタリングを組み合わせることが可能です。例えば、「デングウイルスの LPAIVREAI に類似するペプチドを検索」というクエリは、埋め込みカラムに対するコサイン類似度検索と、properties->>'species' に対するフィルタリングの両方をトリガーします。
データ読み込みパイプラインは IEDB ウイルスエピトープデータセットから読み取り、SageMaker AI エンドポイント(Amazon SageMaker AI endpoint)を介して各ペプチド配列の埋め込みベクトルを生成し、Amazon RDS Data API を使用してデータベースに挿入します。初期ロードでは 1,000 個の線形ペプチドがサンプリングされます:
def import_peptides(df):
for i, row in tqdm(df.iterrows(), total=len(df)):
sequence = row["Epitope_Name"]
embedding = get_embedding(sequence) # SageMaker AI endpoint call
properties = {
"species": row["Epitope_Species"],
"source_organism": row["Epitope_Source Organism"],
"source_molecule": row["Epitope_Source Molecule"],
# ... additional metadata
}
run_statement(
"INSERT INTO peptides (sequence, embedding, properties) "
"VALUES (:sequence, :embedding::vector, :properties::jsonb)",
params=[...]
)データベースへのアクセスは、Amazon Relational Database Service (Amazon RDS) Data API を通じて行われるため、エージェントランタイムがデータベースに直接ネットワーク接続する必要はありません。HTTPS 経由で通信するため、AgentCore のデプロイにおけるネットワーク要件が簡素化されます。
Strands Agents SDK を用いたエージェントの構築
Strands Agents SDK は、ツール使用型エージェントを構築するための明確な抽象化を提供します。各ツールは @tool で装飾された Python 関数であり、エージェントは関数のドキュストリング(docstring)と型ヒントから自動的に LLM 向けのツール説明を生成します。
ツール定義
パーサーツールは、構造化された出力抽出器として機能する専用の Strands エージェントに委譲します:
from strands import Agent, tool
from strands.models import BedrockModel
parser_agent = Agent(
model=BedrockModel(model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-east-1", streaming=False),
system_prompt="""あなたはペプチドクエリパーサーです。自然言語のクエリから構造化された検索パラメータを抽出してください。有効な JSON オブジェクトのみを返してください。"""
)
@tool
def parse_peptide_query(query: str) -> str:
"""自然言語によるペプチドクエリを構造化された検索パラメータに変換します。
Args:
query: ペプチドに関するユーザーの自然言語クエリ。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms など) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
戻り値:
シーケンス、種別、制限などの抽出されたパラメータを含む JSON 文字列。
"""
result = parser_agent(f"このクエリを解析してください: {query}")
parsed = json.loads(str(result))
return json.dumps(parsed)
検索ツールは、SageMaker AI の埋め込み生成と pgvector による類似度検索を組み合わせています:
@tool
def search_similar_peptides(sequence: str, species: str = "", limit: int = 20) -> str:
"""ESM 埋め込みを使用して、指定されたシーケンスに類似するペプチドを検索します。
Args:
sequence: ペプチドのアミノ酸配列(例:"LPAIVREAI")。
species: オプションの種別フィルター(例:"デングウイルス")。
limit: 返す結果の最大数。
Returns:
類似ペプチドとそのプロパティを含むリストを格納した JSON 文字列。
"""
# SageMaker AI から埋め込みを取得
resp = sagemaker_client.invoke_endpoint(
EndpointName=endpoint, ContentType="application/json",
Body=json.dumps({"sequence": sequence}))
embedding = json.loads(resp["Body"].read().decode())["embedding"]
# オプションのメタデータフィルター付きベクトル類似度検索
sql = "SELECT sequence, properties, "
sql += "(embedding :query_embedding::vector) AS cosine_distance "
sql += "FROM peptides"
if species:
sql += " WHERE properties->>'species' = :species"
sql += " ORDER BY cosine_distance LIMIT :limit"
results = run_sql(sql, params)
return json.dumps({"results": peptides, "count": len(peptides)})
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms など) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
翻訳全文
戻り値:
検索結果の簡潔な科学的要約。
"""
results = json.loads(search_results_json)
summary = summarizer_agent(f"Original query: {original_query}"
f"Results: {results}")
return str(summary)
オーケストレーターエージェント
オーケストレーターはすべての要素を結びつけます。ユーザーのクエリを受け取り、どのツールを呼び出し、どのような順序で実行するかを決定します:
SYSTEM_PROMPT = """あなたはペプチド研究アシスタントです。あなたには3 つのツールがあります:
- parse_peptide_query - 自然言語によるクエリを構造化されたパラメータに解析する
- search_similar_peptides - ESM エンベディング(埋め込み表現)を使用して類似ペプチドを検索する
- summarize_results - 科学的知見を用いて検索結果を要約する
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms など) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
すべてのユーザークエリに対して、以下のワークフローに従ってください:
- まず、parse_peptide_query を使用して配列とパラメータを抽出します
- 次に、抽出した配列を使用して search_similar_peptides を実行します
- 最後に、summarize_results を使用して洞察を提供します
必ず 3 つのステップをすべて完了してください。"""
strands_agent = Agent(
model=BedrockModel(model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-east-1", streaming=False),
tools=[parse_peptide_query, search_similar_peptides, summarize_results],
system_prompt=SYSTEM_PROMPT
)
この設計は「エージェントをツールとして使用する」パターンを採用しています。パーサーとサマライザー自体が Strands エージェントですが、@tool デコレータでラップされ、オーケストレーターに対して呼び出し可能なツールとして公開されます。オーケストレーターはこれらのツールが内部で LLM(大規模言語モデル)を使用していることを知らず、また気にする必要もありません。オーケストレーターはそれらを関数として呼び出すだけです。これにより、オーケストレーションロジックをクリーンに保ちつつ、必要な箇所では各ツールが LLM の能力を活用できるようになります。
Amazon Bedrock AgentCore へのデプロイメント
Amazon Bedrock AgentCore は、AI エージェントのホスティング用の管理ランタイムを提供します。エージェントコードは AWS CodeBuild を通じて構築・デプロイされるコンテナ化された環境で実行されます。ローカルでの Docker インストールは不要です。
エージェントのエントリーポイント
AgentCore ランタイムは、ペイロードとコンテキストを受け取るエントリーポイント関数を期待します:
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
@app.entrypoint
def invoke(payload, context):
query = payload.get("query") or payload.get("prompt")
result = strands_agent(query)
return {
"status": "success",
"original_query": query,
"parsed_query": _tool_outputs.get("parsed_query", {}),
"search_results": _tool_outputs.get("search_results", []),
"summary": _tool_outputs.get("summary", str(result)),
"session_id": context.session_id
}
if __name__ == '__main__':
app.run()
The entrypoint captures tool outputs in a shared dictionary so that the response includes structured data (parsed query, search results table, summary text) instead of the agent’s final text output alone. This structured response is what the Streamlit frontend uses to render tables and expandable sections.
Infrastructure as code
The deployment uses AWS CloudFormation for all infrastructure. The VPC stack creates private subnets with NAT gateways and VPC endpoints for Amazon Bedrock, Amazon RDS Data API, and AWS Secrets Manager — helping to ensure the agent runtime can reach all required services without traversing the public internet.
Amazon Aurora PostgreSQL-Compatible Edition Serverless v2 database will be required with automatic scaling from 0.5 to 4 ACUs (1–8 GB RAM). An AWS Lambda-backed custom resource initializes the pgvector extension and creates the peptides table during stack creation:
DBCluster:
Type: AWS::RDS::DBCluster
Properties:
Engine: aurora-postgresql
EnableHttpEndpoint: true # Amazon RDS Data API
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 4
Deploy the solution
The solution requires the following components, deployed in order:
**
Warning:** Complete the deployment steps in order. Skipping steps may result in deployment failures.
- VPC and networking — Private subnets with NAT gateways and VPC endpoints for Amazon Bedrock, the Amazon RDS Data API, and AWS Secrets Manager, so the agent runtime can reach all required services without traversing the public internet.
- Aurora PostgreSQL database — An Amazon Aurora PostgreSQL-Compatible Edition Serverless v2 cluster with the pgvector extension enabled and the peptides table initialized via a Lambda-backed AWS CloudFormation custom resource.
- SageMaker AI endpoint — A serverless endpoint running ESM-C 300M with 6144 MB memory and a max concurrency of 5, using the PyTorch 2.6.0 CPU inference container.
- Peptide data — The IEDB virus epitope dataset is loaded into the database by generating embeddings for each sequence via the SageMaker AI endpoint and inserting them using the Amazon RDS Data API.
- AgentCore runtime and Streamlit UI — The Strands agent is deployed to an Amazon Bedrock AgentCore runtime via AWS CodeBuild (no local Docker required), and the Streamlit frontend is deployed to AWS Fargate.
Streamlit フロントエンド
フロントエンドは軽量な Streamli です。
原文を表示
Protein researchers face a time-consuming challenge: manually searching through thousands of peptide sequences to find structurally similar candidates is slow, error-prone, and requires deep domain expertise to interpret results. Building a protein research copilot can transform how researchers search for structurally similar peptides across large datasets — enabling natural language queries, automated embedding generation, and AI-powered result summarization in a single conversational interface.
This post shows you how to build a conversational protein research assistant that combines three capabilities:
- Natural language query parsing to extract structured search parameters.
- Vector similarity search over protein embeddings using a specialized language model.
- AI-generated scientific summaries of search results.
The system uses the Strands Agents SDK to orchestrate three specialized tools within one agent, deploys to Amazon Bedrock AgentCore for production serving, and stores peptide embeddings in Amazon Aurora PostgreSQL-Compatible Edition with pgvector.
By the end of this post, you will have built an end-to-end agent application that demonstrates how to:
- Parse natural language user input like “Find 10 similar peptides to the dengue virus peptide LPAIVREAI”, into structured tool parameters using the Strands Agents SDK’s tool-use pattern.
- Deploy a custom ML model (ESM-C 300M) as Amazon SageMaker AI serverless endpoint with bundled weights for fast cold starts.
- Combine vector similarity search (pgvector on Amazon Aurora PostgreSQL) with metadata filtering in a single query.
- Orchestrate multiple specialized tools — including nested LLM agents — within a single Bedrock AgentCore runtime and generate scientific summaries of search results.
Prerequisites
To follow along with this post, you need:
- An AWS account with access to Amazon Bedrock foundation models (Anthropic Claude Sonnet 4.6).
- Python 3.12 or later.
- The AWS Command Line Interface (AWS CLI) configured with appropriate credentials.
- IAM permissions for Amazon Bedrock, Amazon SageMaker AI, Amazon Aurora, Amazon Elastic Container Service (Amazon ECS), and AWS CodeBuild.
- bedrock-agentcore-starter-toolkit installed (pip install bedrock-agentcore-starter-toolkit).
- The IEDB virus epitope dataset.
- Estimated deployment time: 30–45 minutes; review the AWS pricing pages for Bedrock, SageMaker AI, Aurora Serverless v2, and AWS Fargate for cost estimates.
Solution overview
The copilot follows a tool-use pattern where a single Strands agent orchestrates three specialized tools to handle the complete research workflow. When a researcher submits a natural language query, the agent parses it into structured parameters, searches for similar peptides using protein embeddings, and summarizes the results with scientific context.
The following diagram illustrates the architecture:
This architecture has five components:
- A Streamlit frontend running on AWS Fargate provides the conversational interface. It sends queries to the AgentCore runtime and displays results in a structured format with downloadable tables.
- A Strands agent running inside a single Amazon Bedrock AgentCore runtime orchestrates the workflow. The agent uses Anthropic Claude Sonnet 4.6 via the Bedrock Converse API and has access to three tools defined with the @tool decorator.
- A parser tool that uses a dedicated Strands agent (LLM-as-parser pattern) to extract structured search parameters — sequence, species filter, result limit — from natural language queries.
- A searcher tool that generates protein embeddings via Amazon SageMaker AI serverless endpoint running ESM-C 300M, then performs cosine similarity search against Amazon Aurora PostgreSQL with pgvector.
- A summarizer tool that uses another dedicated Strands agent to analyze search results and produce concise scientific summaries with suggestions for further investigation.
This single-runtime, multi-tool design keeps the deployment simple while maintaining clear separation of concerns. Each tool encapsulates a distinct capability, and the orchestrator agent decides when and how to invoke them based on the user’s query.
Protein embeddings with ESM-C 300M
The core of the similarity search is ESM-C 300M, a protein language model from EvolutionaryScale (Built with ESM) that produces 960-dimensional embeddings capturing structural and functional properties of amino acid sequences. Two peptides with similar biological function produce embeddings that are close in vector space, enabling similarity search without requiring sequence alignment.
ESM-C 300M is deployed as an Amazon SageMaker AI serverless endpoint, which scales to zero when idle and incurs no cost between invocations. The model weights are bundled into the deployment artifact to avoid downloading from HuggingFace at inference time — critical for serverless endpoints where cold start latency matters.
The inference handler constructs the model architecture directly and loads pre-packaged weights:
from esm.models.esmc import ESMC
from esm.tokenization import get_esmc_model_tokenizers
def model_fn(model_dir):
weights_path = os.path.join(model_dir, "weights", "esmc_300m.pt")
model = ESMC(
d_model=960,
n_heads=15,
n_layers=30,
tokenizer=get_esmc_model_tokenizers(),
use_flash_attn=False,
)
state_dict = torch.load(weights_path, map_location="cpu")
model.load_state_dict(state_dict)
model.eval()
return modelThe predict_fn handler takes a protein sequence, encodes it, and returns the mean-pooled embedding:
def predict_fn(input_data, model):
sequence = input_data["sequence"]
protein = ESMProtein(sequence=sequence)
protein_tensor = model.encode(protein)
logits_output = model.logits(
protein_tensor, LogitsConfig(sequence=True, return_embeddings=True)
)
embeddings = logits_output.embeddings
mean_embeddings = embeddings[:, 1:-1, :].mean(dim=1)
return mean_embeddings[0].detach().cpu().tolist()The endpoint is deployed as a serverless configuration with 6144 MB memory and a max concurrency of 5, using the PyTorch 2.6.0 CPU inference container. The model packaging script downloads weights once via from_pretrained, saves the state dict, and bundles it with the inference code into a model.tar.gz with the required code/ directory structure for SageMaker AI.
Vector search with Aurora PostgreSQL and pgvector
Peptide embeddings are stored in Amazon Aurora PostgreSQL-Compatible Edition Serverless v2 with the pgvector extension. The database schema is straightforward:
CREATE TABLE peptides (
id SERIAL PRIMARY KEY,
sequence TEXT NOT NULL,
embedding vector(960),
properties JSONB,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE INDEX peptides_embedding_idx
ON peptides USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);The properties JSONB column stores biological metadata — species, source organism, source molecule, epitope positions — enabling combined vector and metadata filtering. For example, a query like “Find peptides similar to LPAIVREAI from dengue virus” triggers both a cosine similarity search on the embedding column and a filter on properties->>'species'.
The data loading pipeline reads from the IEDB virus epitope dataset, generates embeddings for each peptide sequence via the SageMaker AI endpoint, and inserts them into the database using the Amazon RDS Data API. The initial load samples 1,000 linear peptides:
def import_peptides(df):
for i, row in tqdm(df.iterrows(), total=len(df)):
sequence = row["Epitope_Name"]
embedding = get_embedding(sequence) # SageMaker AI endpoint call
properties = {
"species": row["Epitope_Species"],
"source_organism": row["Epitope_Source Organism"],
"source_molecule": row["Epitope_Source Molecule"],
# ... additional metadata
}
run_statement(
"INSERT INTO peptides (sequence, embedding, properties) "
"VALUES (:sequence, :embedding::vector, :properties::jsonb)",
params=[...]
)Database access goes through the Amazon Relational Database Service (Amazon RDS) Data API, which means the agent runtime does not need direct network connectivity to the database — it communicates over HTTPS, simplifying the networking requirements for AgentCore deployment.
Building the agent with Strands Agents SDK
The Strands Agents SDK provides a clean abstraction for building tool-using agents. Each tool is a Python function decorated with @tool, and the agent automatically generates tool descriptions for the LLM from the function’s docstring and type hints.
Tool definitions
The parser tool delegates to a dedicated Strands agent that acts as a structured output extractor:
from strands import Agent, tool
from strands.models import BedrockModel
parser_agent = Agent(
model=BedrockModel(model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-east-1", streaming=False),
system_prompt="""You are a peptide query parser. Extract structured search
parameters from natural language queries. Return ONLY a valid JSON object."""
)
@tool
def parse_peptide_query(query: str) -> str:
"""Parse a natural language peptide query into structured search parameters.
Args:
query: The user's natural language query about peptides.
Returns:
JSON string with extracted parameters like sequence, species, limit.
"""
result = parser_agent(f"Parse this query: {query}")
parsed = json.loads(str(result))
return json.dumps(parsed)The searcher tool combines SageMaker AI embedding generation with pgvector similarity search:
@tool
def search_similar_peptides(sequence: str, species: str = "", limit: int = 20) -> str:
"""Search for peptides similar to the given sequence using ESM embeddings.
Args:
sequence: The peptide amino acid sequence (e.g., "LPAIVREAI").
species: Optional species filter (e.g., "Dengue virus").
limit: Maximum number of results to return.
Returns:
JSON string with list of similar peptides and their properties.
"""
# Get embedding from SageMaker AI
resp = sagemaker_client.invoke_endpoint(
EndpointName=endpoint, ContentType="application/json",
Body=json.dumps({"sequence": sequence}))
embedding = json.loads(resp["Body"].read().decode())["embedding"]
# Vector similarity search with optional metadata filter
sql = "SELECT sequence, properties, "
sql += "(embedding :query_embedding::vector) AS cosine_distance "
sql += "FROM peptides"
if species:
sql += " WHERE properties->>'species' = :species"
sql += " ORDER BY cosine_distance LIMIT :limit"
results = run_sql(sql, params)
return json.dumps({"results": peptides, "count": len(peptides)})The summarizer tool uses another dedicated Strands agent for scientific analysis:
summarizer_agent = Agent(
model=BedrockModel(model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-east-1", streaming=False),
system_prompt="""You are a peptide research expert providing concise,
high-level summaries. Analyze search results and provide a brief,
insightful summary focusing on key findings and ideas for further
investigation."""
)
@tool
def summarize_results(original_query: str, search_results_json: str) -> str:
"""Summarize peptide search results with scientific insights.
Args:
original_query: The original user query.
search_results_json: JSON string of search results.
Returns:
A concise scientific summary of the search results.
"""
results = json.loads(search_results_json)
summary = summarizer_agent(f"Original query: {original_query}"
f"Results: {results}")
return str(summary)Orchestrator agent
The orchestrator ties everything together. It receives the user’s query and decides which tools to call and in what order:
SYSTEM_PROMPT = """You are a peptide research assistant. You have three tools:
1. parse_peptide_query - Parse a natural language query into structured parameters
2. search_similar_peptides - Search for similar peptides using ESM embeddings
3. summarize_results - Summarize search results with scientific insights
For every user query, follow this workflow:
1. First, use parse_peptide_query to extract the sequence and parameters
2. Then, use search_similar_peptides with the extracted sequence
3. Finally, use summarize_results to provide insights
Always complete the three steps."""
strands_agent = Agent(
model=BedrockModel(model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-east-1", streaming=False),
tools=[parse_peptide_query, search_similar_peptides, summarize_results],
system_prompt=SYSTEM_PROMPT
)This design uses the “agents-as-tools” pattern: the parser and summarizer are themselves Strands agents, but they are wrapped in @tool decorators and exposed to the orchestrator as callable tools. The orchestrator does not know or care that these tools internally use LLMs — it calls them as functions. This keeps the orchestration logic clean while allowing each tool to leverage LLM capabilities where needed.
Deploying to Amazon Bedrock AgentCore
Amazon Bedrock AgentCore provides a managed runtime for hosting AI agents. The agent code runs in a containerized environment built and deployed via AWS CodeBuild — no local Docker installation is required.
Agent entrypoint
The AgentCore runtime expects an entrypoint function that receives a payload and context:
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
@app.entrypoint
def invoke(payload, context):
query = payload.get("query") or payload.get("prompt")
result = strands_agent(query)
return {
"status": "success",
"original_query": query,
"parsed_query": _tool_outputs.get("parsed_query", {}),
"search_results": _tool_outputs.get("search_results", []),
"summary": _tool_outputs.get("summary", str(result)),
"session_id": context.session_id
}
if __name__ == '__main__':
app.run()The entrypoint captures tool outputs in a shared dictionary so that the response includes structured data (parsed query, search results table, summary text) instead of the agent’s final text output alone. This structured response is what the Streamlit frontend uses to render tables and expandable sections.
Infrastructure as code
The deployment uses AWS CloudFormation for all infrastructure. The VPC stack creates private subnets with NAT gateways and VPC endpoints for Amazon Bedrock, Amazon RDS Data API, and AWS Secrets Manager — helping to ensure the agent runtime can reach all required services without traversing the public internet.
Amazon Aurora PostgreSQL-Compatible Edition Serverless v2 database will be required with automatic scaling from 0.5 to 4 ACUs (1–8 GB RAM). An AWS Lambda-backed custom resource initializes the pgvector extension and creates the peptides table during stack creation:
DBCluster:
Type: AWS::RDS::DBCluster
Properties:
Engine: aurora-postgresql
EnableHttpEndpoint: true # Amazon RDS Data API
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 4Deploy the solution
The solution requires the following components, deployed in order:
Warning: Complete the deployment steps in order. Skipping steps may result in deployment failures.
- VPC and networking — Private subnets with NAT gateways and VPC endpoints for Amazon Bedrock, the Amazon RDS Data API, and AWS Secrets Manager, so the agent runtime can reach all required services without traversing the public internet.
- Aurora PostgreSQL database — An Amazon Aurora PostgreSQL-Compatible Edition Serverless v2 cluster with the pgvector extension enabled and the peptides table initialized via a Lambda-backed AWS CloudFormation custom resource.
- SageMaker AI endpoint — A serverless endpoint running ESM-C 300M with 6144 MB memory and a max concurrency of 5, using the PyTorch 2.6.0 CPU inference container.
- Peptide data — The IEDB virus epitope dataset is loaded into the database by generating embeddings for each sequence via the SageMaker AI endpoint and inserting them using the Amazon RDS Data API.
- AgentCore runtime and Streamlit UI — The Strands agent is deployed to an Amazon Bedrock AgentCore runtime via AWS CodeBuild (no local Docker required), and the Streamlit frontend is deployed to AWS Fargate.
Streamlit frontend
The frontend is a lightweight Streamli
関連記事
SageMaker AIモデルとMLflowを用いたStrandsエージェントの構築
AWSは、エンタープライズ向けにSageMaker AIとMLflowを組み合わせてAIエージェントを構築する手法を提供。これにより、モデルの選定、コスト最適化、コンプライアンス対応、既存セキュリティアーキテクチャとの統合など、管理型サービスでは不足しがちな詳細な制御と運用要件を満たす。
世界を埋め込む:大規模な航空画像のための多モーダル AI による検索可能化
AWS は、保険や不動産など地理空間データを必要とする業界向けに、自然言語で航空画像を検索できる基盤を提供する。従来の手動検査や個別モデル訓練の代わりに、多モーダル埋め込みとベクトル検索を活用し、一度インデックス化すれば効率的な検索を可能にする技術を発表した。
Amazon Bedrock AgentCore の新機能:広範な知識と継続的学習を備えたエージェント構築が可能に
AWS は Amazon Bedrock AgentCore に新機能を追加し、 SharePoint などの外部ドキュメントへのアクセスやフィードバックの活用を通じて、エージェントが本来持つ能力を発揮できるようにした。これにより、顧客対応や研究支援などにおいて、より高度な推論と計画が可能となる。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み