大規模言語モデルの金融市場への応用
The Gradient の記事は、LLM を金融時系列予測に適用する試みにおける根本的なデータ量の不足と市場の効率性による予測困難性を分析し、言語モデルの成功要因が金融市場には当てはまらないことを示唆している。
キーポイント
データ量の比較と限界
Hudson River Trading の試算によると、株式市場の年間トークン数は GPT-3 の学習データ量に匹敵するが、予測対象が単語から価格・リターンへと変わることで難易度が劇的に上昇する。
構造的違いによる予測困難性
言語には文法という明確な構造が存在し予測が可能だが、金融市場にはそれを支える類似の構造がなく、多数の参加者が信号を消去するため予測が極めて困難である。
ノイズ対シグナルの問題
市場データは本質的にノイズが多く、投資家の行動が必ずしも合理的またはファンダメンタルズに基づかないため、LLM が学習するパターンを抽出することが困難である。
金融データにおけるノイズと多様性
金融市場のデータには合理的でない取引や非定常的な変化が多く、言語データの進化速度とは異なる特性を持つため、単一の情報源に依存するリスクがある。
マルチモーダル学習による予測精度向上の可能性
価格時系列データとニュース、SNSのセンチメント、衛星画像などの異種データを統合したモデル構築により、非価格情報を活用したより高精度な予測が可能となる。
ファイナンスとAIにおける「残差化」戦略の共通点
両分野とも、市場全体や入力値そのものといった既知の構造(共通因子や恒等写像)を除去し、予測が困難な「革新部分(イノベーション)」に焦点を当てることで効率化を図る。
マルチタイムスケール予測の必要性
現在のトランスフォーマーモデルは1期間先の予測に限定されているが、金融市場では数秒から数ヶ月までの異なる時間軸での現象を同時に捉え、期待収益率の用語構造全体を予測する必要がある。
影響分析・編集コメントを表示
影響分析
この分析は、LLM を金融分野に安易に適用しようとする動きに対する重要な警鐘であり、単なるデータ量の比較だけでなく、ドメイン固有の構造的・行動経済学的な違いを考慮する必要性を浮き彫りにしています。業界全体として、生成 AI の能力限界を理解し、金融予測においては従来の統計的アプローチや新しいアーキテクチャの必要性を見直す契機となるでしょう。
編集コメント
生成 AI の金融応用への過度な期待を冷静に分析した、非常に示唆に富む記事です。技術の限界とドメイン固有の特性を理解することが、実装成功の鍵となります。
タイトル: LLMの金融市場への応用
2023年、AI革命は民間・上場企業双方への熱狂的な投資を駆り立て、人々の想像力を掻き立てた。ChatGPTのような変革的な消費者向け製品は、単語やその一部を表すトークンのシーケンスをモデル化することに優れた大規模言語モデル(LLM)によって支えられている[2]。驚くべきことに、次のトークンを予測する学習から構造的な理解が生まれ、エージェントは翻訳、質問応答、単純なユーザープロンプトからの人間らしい文章生成といったタスクを遂行できるようになる。
当然のことながら、クオンツトレーダーたちは問うた:これらのモデルを次の価格や取引予測に転用できるか?[1,9,10] つまり、単語のシーケンスではなく、価格や取引のシーケンスをモデル化できるか、ということだ。これは、生成AIと金融時系列モデリングの双方について多くを明らかにする興味深い研究分野であることがわかっている。ただし、これから先は少々マニアックになることをお断りしておく。
LLMは自己回帰学習器として知られている——つまり、シーケンス内の前のトークンや要素を使って次の要素やトークンを予測するものである。量的取引、例えば株式の統計的裁定取引のような戦略において、ほとんどの研究は自己回帰的構造の特定に関心がある。それは、将来の価格を最もよく予測するニュース、注文、または根本的な変化のシーケンスを見つけることを意味する。
問題が生じるのは、モデルを訓練するために利用可能なデータの量と情報内容においてである。2023年のNeurIPSカンファレンスで、高頻度取引会社のハドソン・リバー・トレーディングは、GPT-3の訓練に使用された入力トークン数と、株式市場データで年間利用可能な訓練可能トークン量との比較を発表した。HRTは、3,000の取引可能株式、1日当たり1銘柄10データポイント、年間252取引日、1取引日23,400秒と仮定すると、市場データとして年間1,770億の株式市場トークンが利用可能と推定した。GPT-3は5,000億トークンで訓練されており、それほど離れていない[6]。
しかし、取引の文脈では、トークンは音節や単語ではなく、価格やリターン、取引となる。前者の予測ははるかに難しい。言語には基礎となる言語構造(例:文法)が存在する[7]。人間が文の次の単語を予測することを想像するのは難しくないが、同じ人間が、一連の過去の取引が与えられたときに次のリターンを予測するのは極めて困難であるため、億万長者のデイトレーダーがいないのである。課題は、市場のあらゆるシグナルを競い合って消し去ってしまう非常に賢い人々が存在し、市場をほぼ効率的に(経済学者ラッセ・ペダーセンの言葉を借りれば「効率的に非効率的」に)し、したがって予測不可能にしていることだ。文をより予測困難にしようと積極的に試みる敵対者は存在しない——むしろ、著者は通常、自分の文を理解しやすく、したがってより予測可能にしようとする。
別の角度から見ると、金融データにはシグナルよりもはるかに多くのノイズが存在する。個人や機関は、合理的でなかったり、企業の根本的な変化に関連していない理由で取引している可能性がある。2021年のGameStop事件はその一例である。金融時系列もまた、新しい根本的な情報、規制の変化、通貨切り下げのような時折の大きなマクロ経済的シフトによって絶えず変化している。言語ははるかに遅いペースで、より長い時間軸で進化する。
一方で、AIからのアイデアが金融市場でうまく機能するだろうと信じる理由もある。金融への応用が期待されるAI研究の新興分野の一つがマルチモーダル学習である[5]。これは、例えば画像とテキスト入力の両方といった、異なるモダリティのデータを使用して統一モデルを構築することを目指す。OpenAIのDALL-E 2モデルでは、ユーザーがテキストを入力するとモデルが画像を生成する。金融では、マルチモーダルの取り組みは、技術的な時系列データ(価格、取引、出来高など)といった古典的な情報源と、ツイッター上のセンチメントやグラフィカルな相互作用、自然言語のニュース記事や企業報告書、商品中心の港の船舶活動の衛星画像といった異なるモードの代替データとを組み合わせるのに有用である可能性がある。ここでは、マルチモーダルAIを活用することで、これらすべての種類の非価格情報を組み込んで、うまく予測することが潜在的に可能となる。
「残差化」と呼ばれる別の戦略は、金融とAIの両方で重要な位置を占めているが、両分野で異なる役割を担っている。金融では、構造的「ファクター」モデルが、異なる資産にわたるリターンの同時観測を、共有成分(市場リターン、またはより一般的には市場全体に共通するファクターのリターン)と、各原資産に固有の特異的成分に分解する。市場およびファクターリターンは予測が難しく相互依存性を生み出すため、個々の資産レベルで予測を行う際に共通要素を取り除き、データ内の独立した観測値を最大化することはしばしば有益である。
トランスフォーマーなどの残差ネットワークアーキテクチャでは、入力Xの関数h(X)を学習したいが、恒等写像に対するh(X)の残差、すなわちh(X) – Xを学習する方が簡単かもしれないという類似の考え方がある。ここで、関数h(X)が恒等写像に近い場合、その残差はゼロに近くなり、したがって学習すべきことが少なくなり、より効率的に学習できる。どちらの場合も目標は、構造を利用して予測を洗練させることである:金融のケースでは、市場全体が示唆するものを超えた革新部分(イノベーション)の予測に焦点を当てるという考えであり、残差ネットワークの場合は恒等写像への革新部分の予測に焦点を当てる。
LLMの印象的な性能のための重要な要素は、コンテキストウィンドウとして知られる長期間にわたるトークン間の親和性や強度を見分ける能力である。金融市場では、長期間にわたって注意を集中させる能力により、マルチスケール現象の分析が可能になり、市場変化のいくつかの側面が非常に異なる時間軸で説明される。例えば、一方の極端として、根本的な情報(例:業績)は数か月かけて価格に取り込まれる可能性があり、技術的現象(例:モメンタム)は数日で実現する可能性があり、もう一方の極端として、微細構造現象(例:オーダーブックの不均衡)は数秒から数分の時間軸を持つ可能性がある。
これらすべての現象を捉えるには、コンテキストウィンドウ全体で複数の時間軸を分析することが必要である。しかし、金融では、複数の将来の時間軸にわたる予測も重要である。例えば、量的システムは、複数の時間軸で実現する複数の異なるアノマリーから利益を得るために取引しようとするかもしれない(例:微細構造イベントと業績イベントに同時に賭ける)。これは、株式の次の期間のリターンだけでなく、期待リターンの全期間構造または軌跡を予測することを必要とするが、現在のトランスフォーマー式予測モデルは将来の1期間しか見ていない。
LLMのもう一つの金融市場への応用は、合成データ生成かもしれない[4,8]。これはいくつかの方向性を取り得る。市場で観察される特性を模倣した模擬株価軌跡を生成することができ、上述の利用可能トークン数で強調されたように、金融市場データが他の情報源に比べて乏しいことを考えると、非常に有益である可能性がある。人工データは、例えばロボティクスで成功裏に適用されてきたメタ学習技術への扉を開く可能性がある。ロボット設定では、コントローラーは、高価な現実世界のロボット実験を使用して較正される前に、安価だが必ずしも正確ではない物理シミュレーターを使用して最初に訓練される。金融では、シミュレーターを使用して取引戦略を大まかに訓練し最適化することができる。モデルは、リスク回避や分散化のような高次の概念や、取引の価格影響を最小化するためにゆっくり取引するといった戦術的概念を学習する。その後、貴重な実市場データを使用して予測を微調整し、取引する最適な速度を正確に決定することができる。
金融市場の実務家たちは、
原文を表示
The AI revolution drove frenzied investment in both private and public companies and captured the public’s imagination in 2023. Transformational consumer products like ChatGPT are powered by Large Language Models (LLMs) that excel at modeling sequences of tokens that represent words or parts of words [2]. Amazingly, structural understanding emerges from learning next-token prediction, and agents are able to complete tasks such as translation, question answering and generating human-like prose from simple user prompts.
Not surprisingly, quantitative traders have asked: can we turn these models into the next price or trade prediction [1,9,10]? That is, rather than modeling sequences of words, can we model sequences of prices or trades. This turns out to be an interesting line of inquiry that reveals much about both generative AI and financial time series modeling. Be warned this will get wonky.
LLMs are known as autoregressive learners -- those using previous tokens or elements in a sequence to predict the next element or token. In quantitative trading, for example in strategies like statistical arbitrage in stocks, most research is concerned with identifying autoregressive structure. That means finding sequences of news or orders or fundamental changes that best predict future prices.
Where things break down is in the quantity and information content of available data to train the models. At the 2023 NeurIPS conference, Hudson River Trading, a high frequency trading firm, presented a comparison of the number of input tokens used to train GPT-3 with the amount of trainable tokens available in the stock market data per year HRT estimated that, with 3,000 tradable stocks, 10 data points per stock per day, 252 trading days per year, and 23400 seconds in a trading day, there are 177 billion stock market tokens per year available as market data. GPT-3 was trained on 500 billion tokens, so not far off [6].
But, in the trading context the tokens will be prices or returns or trades rather than syllables or words; the former is much more difficult to predict. Language has an underlying linguistic structure (e.g., grammar) [7]. It’s not hard to imagine a human predicting the next word in a sentence, however that same human would find it extremely challenging to predict the next return given a sequence of previous trades, hence the lack of billionaire day traders. The challenge is that there are very smart people competing away any signal in the market, making it almost efficient (“efficiently inefficient”, in the words of economist Lasse Pedersen) and hence unpredictable. No adversary actively tries to make sentences more difficult to predict — if anything, authors usually seek to make their sentences easy to understand and hence more predictable.
Looked at from another angle, there is much more noise than signal in financial data. Individuals and institutions are trading for reasons that might not be rational or tied to any fundamental change in a business. The GameStop episode in 2021 is one such example. Financial time series are also constantly changing with new fundamental information, regulatory changes, and occasional large macroeconomic shifts such as currency devaluations. Language evolves at a much slower pace and over longer time horizons.
On the other hand, there are reasons to believe that ideas from AI will work well in financial markets. One emerging area of AI research with promising applications to finance is multimodal learning [5], which aims to use different modalities of data, for example both images and textual inputs to build a unified model. With OpenAI’s DALL-E 2 model, a user can enter text and the model will generate an image. In finance, multi-modal efforts could be useful to combine information classical sources such as technical time series data (prices, trades, volumes, etc.) with alternative data in different modes like sentiment or graphical interactions on twitter, natural language news articles and corporate reports, or the satellite images of shipping activity in a commodity centric port. Here, leveraging multi-modal AI, one could potentially incorporate all these types of non-price information to predict well.
Another strategy called ‘residualization’ holds prominence in both finance and AI, though it assumes different roles in the two domains. In finance, structural `factor’ models break down the contemporaneous observations of returns across different assets into a shared component (the market return, or more generally returns of common, market-wide factors) and an idiosyncratic component unique to each underlying asset. Market and factor returns are difficult to predict and create interdependence, so it is often helpful to remove the common element when making predictions at the individual asset level and to maximize the number of independent observations in the data.
In residual network architectures such as transformers, there’s a similar idea that we want to learn a function h(X) of an input X, but it might be easier to learn the residual of h(X) to the identity map, i.e., h(X) – X. Here, if the function h(X) is close to identity, its residual will be close to zero, and hence there will be less to learn and learning can be done more efficiently. In both cases the goal is to exploit structure to refine predictions: in the finance case, the idea is to focus on predicting innovations beyond what is implied by the overall market, for residual networks the focus is on predicting innovations to the identity map.
A key ingredient for the impressive performance of LLMs work is their ability to discern affinities or strengths between tokens over long horizons known as context windows. In financial markets, the ability to focus attention across long horizons enables analysis of multi-scale phenomena, with some aspects of market changes explained across very different time horizons. For example, at one extreme, fundamental information (e.g., earnings) may be incorporated into prices over months, technical phenomena (e.g., momentum) might be realized over days, and, at the other extreme, microstructure phenomena (e.g., order book imbalance) might have a time horizon of seconds to minutes.
Capturing all of these phenomena involves analysis of multiple time horizons across the context window. However, in finance, prediction over multiple future time horizons is also important. For example, a quantitative system may seek to trade to profit from multiple different anomalies that are realized over multiple time horizons (e.g., simultaneously betting on a microstructure event and an earnings event). This requires predicting not just the next period return of the stock, but the entire term structure or trajectory of expected returns, while current transformer-style predictive models only look one period in the future.
Another financial market application of LLMs might be synthetic data creation [4,8]. This could take a few directions. Simulated stock price trajectories can be generated that mimic characteristics observed in the market and can be extremely beneficial given that financial market data is scarce relative to other sources as highlighted above in the number of tokens available. Artificial data could open the door for meta-learning techniques which have successfully been applied, for example, in robotics. In the robotic setting controllers are first trained using cheap but not necessarily accurate physics simulators, before being better calibrated using expensive real world experiments with robots. In finance the simulators could be used to coarsely train and optimize trading strategies. The model would learn high level concepts like risk aversion and diversification and tactical concepts such as trading slowly to minimize the price impact of a trade. Then precious real market data could be employed to fine-tune the predictions and determine precisely the optimal speed to trade.
Financial market practitioners are often interested in extreme events, the times when trading strategies are more likely to experience significant gains or losses. Generative models where it’s possible to sample from extreme scenarios could find use. However extreme events by definition occur rarely and hence determining the right parameters and sampling data from the corresponding distribution is fraught.
Despite the skepticism that LLMs will find use in quantitative trading, they might boost fundamental analysis. As AI models improve, it’s easy to imagine them helping analysts refine an investment thesis, uncover inconsistencies in management commentary or find latent relationships between tangential industries and businesses [3]. Essentially these models could provide a Charlie Munger for every investor.
The surprising thing about the current generative AI revolution is that it’s taken almost everyone – academic researchers, cutting edge technology firms and long-time observers – by surprise. The idea that building bigger and bigger models would lead to emergent capabilities like we see today was totally unexpected and still not fully understood.
The success of these AI models has supercharged the flow of human and financial capital into AI, which should in turn lead to even better and more capable models. So while the case for GPT-4 like models taking over quantitative trading is currently unlikely, we advocate keeping an open mind. Expecting the unexpected has been a profitable theme in the AI business.
“Applying Deep Neural Networks to Financial Time Series Forecasting” Allison Koenecke. 2022
“Attention is all you need.” A Vaswani, N Shazeer, N Parmar, J Uszkoreit, L Jones… Advances in Neural Information Processing Systems, 2017
“Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models” . Lopez-Lira, Alejandro and Tang, Yuehua, (April 6, 2023) Available at SSRN
“Generating Synthetic Data in Finance: Opportunities, Challenges and Pitfalls.” SA Assefa, D Dervovic, M Mahfouz, RE Tillman… - Proceedings of the First ACM International Conference …, 2020
“GPT-4V(ision) System Card.” OpenAI. September 2023
“Language models are few-shot learners.” T Brown, B Mann, N Ryder, M Subbiah, JD Kaplan… - Advances in Neural Information Processing Systems, 2020
“Sequence to Sequence Learning with Neural Networks.” I.Sutskever,O.Vinyals,and Q.V.Le in Advances in Neural Information Processing Systems, 2014, pp. 3104–3112.
“Synthetic Data Generation for Economists”. A Koenecke, H Varian - arXiv preprint arXiv:2011.01374, 2020
C. C. Moallemi, M. Wang. A reinforcement learning approach to optimal execution. Quantitative Finance, 22(6):1051–1069, March 2022.
C. Maglaras, C. C. Moallemi, M. Wang. A deep learning approach to estimating fill probabilities in a limit order book. Quantitative Finance, 22(11):1989–2003, October 2022.
For attribution in academic contexts or books, please cite this work as
Richard Dewey and Ciamac Moallemi, "Financial Market Applications of LLMs," The Gradient, 2024
@article{dewey2024financial, author = {Richard Dewey and Ciamac Moallemi}, title = {Financial Market Applications of LLMs}, journal = {The Gradient}, year = {2024}, howpublished = {\url{https://thegradient.pub/financial-market-applications-of-llms}, }
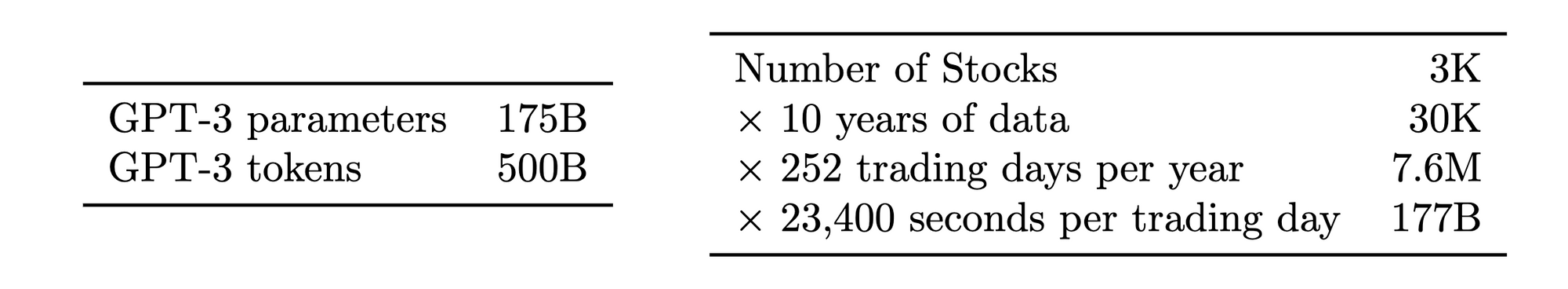

関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み