オープンモデルが閾値を超えた
オープンソースのLLMがエージェントの中核タスクにおいてクローズドモデルと同等のパフォーマンスを発揮し、コストとレイテンシの大幅な削減により実用段階に到達したことを示す。
キーポイント
エージェントタスクでのパフォーマンス均衡
GLM-5やMiniMax M2.7などのオープンモデルが、ファイル操作やツール呼び出しといった中核エージェントタスクでクローズドモデルと同等のスコアを記録した。
コストとレイテンシの圧倒的優位
オープンモデルは推論コストが最大8〜10倍安く、専用インフラにより応答速度も2倍以上高速化し、インタラクティブなプロダクション利用を可能にする。
実証された評価手法とインフラ選択肢
LangChainのDeep Agentsハーンによる7カテゴリの評価に加え、OllamaやvLLMを用いた完全ローカル実行も可能であり、開発者は柔軟にインフラを選べる。
Openモデルのシームレスな統合と評価
Deep Agents SDKとCLIを使用すれば、1行のコード変更でオープンモデルをクローズドフロントティアモデルと同じ評価スイートで比較・実行できる。
ハッスルレベルの自動調整機能
コンテキストウィンドウ、ツール呼び出し形式、失敗モードの違いをハッスルが吸収し、モデル固有のID注入や動的なコンテキスト管理を行うため、開発者はインフラの詳細を気にする必要がない。
マルチプロバイダー対応による柔軟なインフラ選択
同じオープンモデルがBaseten、Fireworks、Groq、OpenRouter、Ollama等多个プロバイダーで提供されており、制約に応じて最適なインフラを選択可能。
影響分析・編集コメントを表示
影響分析
本記事は、オープンモデルの実用性が単なるベンチマークの数値ではなく、エージェントの実際の運用コストと応答速度という実務指標で裏付けられたことを示している。これにより、大規模なAIエージェント展開においてクラウド依存を減らし、インフラコストを劇的に削減する新たな標準が確立される。開発者はモデル選択の自由度が高まり、スケーラビリティとセキュリティを両立させるアーキテクチャ設計が可能になる。
編集コメント
クローズドモデルの価格競争とオープンエコシステムの成熟が交差する転換点であり、実務レベルでのモデル選定基準を根本から見直す必要がある。今後は推論インフラの最適化競争がさらに激化するだろう。
要約:GLM-5やMiniMax M2.7などのオープンモデルは、ファイル操作、ツール使用、指示のフォローバックといったコアなエージェントタスクにおいて、クローズドなフロンティアモデルと同等の性能を発揮するようになりました。そのコストとレイテンシーは従来モデルの数分の一です。以下は評価結果の詳細と、Deep Agentsでの活用方法です。
過去数週間、私たちはオープンウェイトのLarge Language Models(大規模言語モデル)をDeep Agentsのハネス評価でテストしてきました。その初期結果は、これらがクローズドなフロンティアモデルの代わりに、あるいは併用して使用できる実用的な選択肢であることを示しています。GLM-5 (z.ai) と MiniMax M2.7 は、ファイル操作、ツール使用、指示のフォローバックといったコアなエージェントタスクにおいて、クローズドなフロンティアモデルと同等のスコアを記録しています。
SWE-Rebench や Terminal Bench 2.0 といった大規模なオープンベンチマークを通じてオープンモデルの進歩を追ってきた方々にとっては、この結果は驚くべきものではありません。ツール呼び出しは信頼性が高く、指示のフォローバックも一貫しています。生産環境でエージェントを展開する開発者にとって、オープンモデルは現実的なワークフローを可能にするレベルの一貫性と予測可能性を提供するようになりました。
オープンモデルを選ぶ理由
オープンモデルを検討する際、ビルダーや顧客は主にいくつかの重要な要素に焦点を当てます:コスト、レイテンシー、そしてタスクパフォーマンスです。
究極的には、すべてのタスクに対して最高レベルの推論能力を持つ最先端モデルを使用するのが理想的です。しかし現実には、コストとレイテンシという2つの制約により、その実現は困難です。最先端のクローズドモデルは、高スループットなワークロードにおいて8〜10倍のコストがかかる場合があり、インタラクティブな製品でユーザーが期待する応答時間に対しては、しばしば遅すぎます。
モデル
種類
入力 ($/Mトークン)
出力 ($/Mトークン)
Claude Opus 4.6 (Anthropic)
クローズド
$5.00
$25.00
Claude Sonnet 4.6 (Anthropic)
クローズド
$3.00
$15.00
GPT-5.4 (OpenAI)
クローズド
$2.50
$15.00
GLM-5 (Baseten)
オープン
$0.95
$3.15
MiniMax M2.7 (OpenRouter)
オープン
$0.30
$1.20
価格の文脈を補足すると、1日あたり10Mトークンを出力するアプリケーションの場合、Opus 4.6では約$250/日かかるのに対し、MiniMax M2.7では約$12/日で済みます。これは年間約8万7千ドルの差になります。
オープンモデルはクローズドな最先端モデルよりも小型である傾向があり、専用推論インフラ上で加速可能です。Groq、Fireworks、Basetenといったプロバイダーは、多くのチームが独自に達成できる範囲を大幅に超えるレイテンシとスループットのために最適化を行っています。OpenRouterのデータによると、Baseten上のGLM-5は平均レイテンシ0.65秒、70トークン/秒であるのに対し、Claude Opus 4.6は2.56秒、34トークン/秒です。レイテンシに敏感な製品にとって、この差はエンジニアリングで克服するのは困難です。
評価方法
Deep Agents 用の評価(eval)構築方法については、『How we build evals for Deep Agents』で詳細に記述しています。私たちはホストされた推論プロバイダーを使用して評価を実行しますが、Ollama や vLLM などを介して、完全にローカルでプライベートなモデルを使用して Deep Agents を実行することも可能です。
オープンモデルについては、ファイル操作、ツール使用、検索(retrieval)、会話、メモリ、要約、そして「ユニットテスト」の 7 つの評価カテゴリを実行しました。これらは基礎的な機能を試すタスクをカバーしています:モデルはツールを確実に呼び出し、構造化された指示に従い、ファイルに対して操作を実行できるでしょうか?これらは、モデルがエージェントハネス(agentic harness)で実際に使用可能かどうかを決定する能力のゲートです。
各評価ケースは、成功のアサーション(正しさを決定するハードフォールチェック)と効率のアサーション(モデルがどのように到達したかを測定するソフトチェック)を定義しています。私たちは 4 つのメトリクスを報告します:
正しさ(Correctness)—— モデルが解決したテストの割合:passed / total。スコア 0.68 は、テストケースの 68% が正しく解決されたことを意味します。これが主要な品質指標です。
解決率(Solve rate)—— 精度と速度の複合測定。各テストについて、expected_steps / wall_clock_seconds を計算します;失敗したテストはゼロを寄与します。最終スコアは全テストにわたる平均です。高いほど良く、タスクを正しくかつ迅速に解決するモデルが最高スコアを獲得します。
ステップ比率 — 期待されたステップ数に対して、モデルが実際に実行したエージェントステップの数を全テストで集計したもの(total_actual_steps / total_expected_steps)。値が1.0の場合、モデルは期待された数のステップを正確に使用したことを意味します。1.0より大きい値は、より多くのステップが必要だった(効率性が低い)ことを示し、1.0より小さい値は、より少ないステップで済んだ(効率性が高い)ことを示します。
ツール呼び出し比率 — ステップ比率と同じ概念ですが、ステップ数ではなく個々のツール呼び出しをカウントします。1.0は予算内、それ以上は予算超過、それ以下は予算未満を意味します。
ステップ比率とツール呼び出し比率は効率性指標です。これらはテストの合格・不合格には影響しませんが、モデルが回答に到達する際の経済性を明らかにします。期待される5ステップに対して2ステップでタスクを解決できるモデルは、正解であるだけでなく効率的でもあります。
評価結果の発見
これらは初期結果であり、私たちは評価セットの維持と拡張を継続的に行っています。最近の実行結果は、GitHubリポジトリおよび共有LangSmithプロジェクトの両方でリアルタイムで確認できます。
オープンモデル
CI実行結果を表示(モデル名をクリックして個別の評価を確認)
モデル
正解率
合格数
解決率
ステップ比率
ツール呼び出し比率
baseten:zai-org/GLM-5
0.64
138件中94件
1.17
1.02
1.06
ollama:minimax-m2.7
0.57
138件中85件
0.27
1.02
1.04
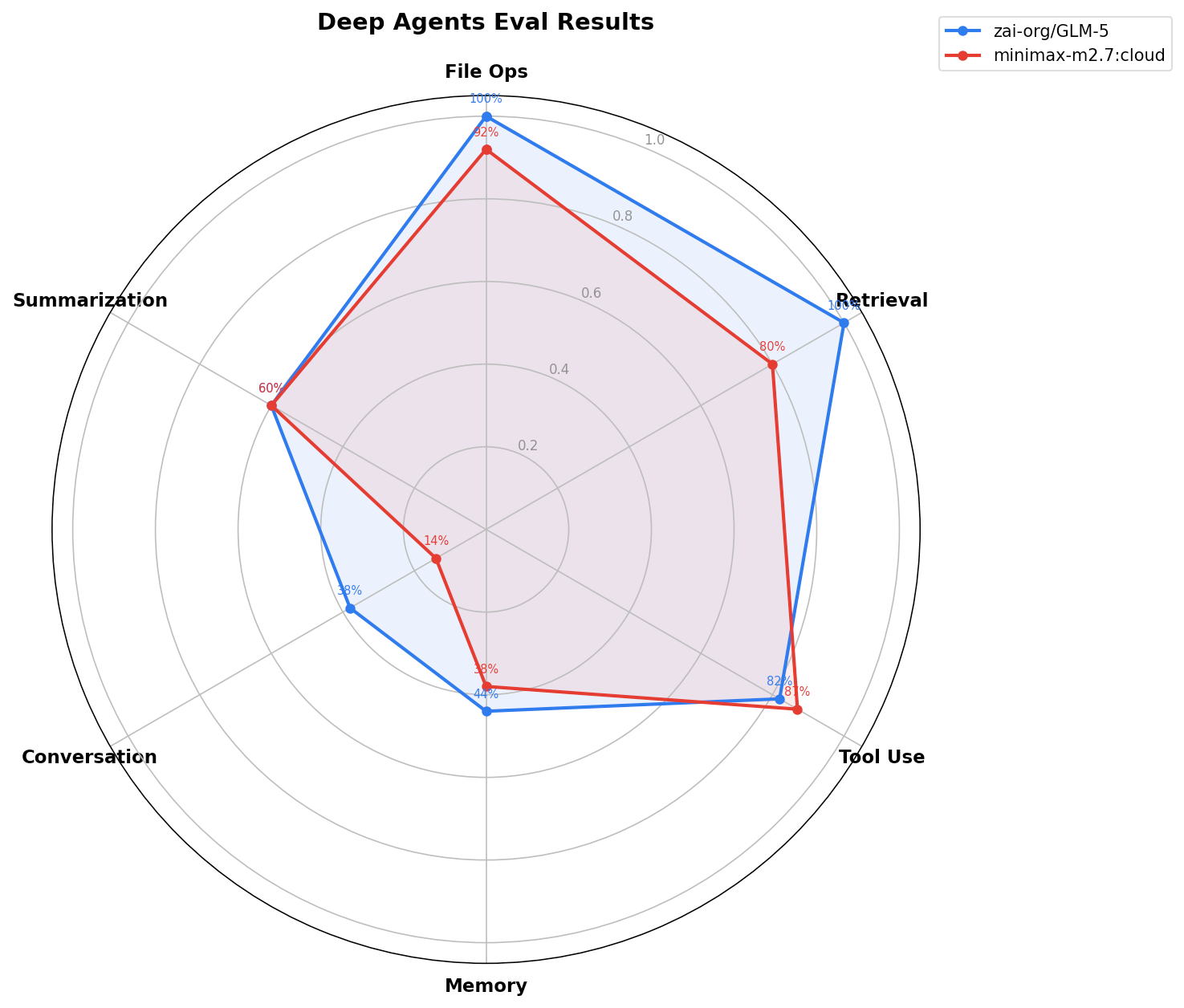 imageカテゴリ別正解率:
imageカテゴリ別正解率:
モデル
会話
ファイル操作
メモリ
検索
要約
ツール使用
ユニットテスト
baseten:zai-org/GLM-5
0.38
1
0.44
1
0.6
0.82
1
ollama:minimax-m2.7:cloud
0.14
0.92
0.38
0.8
0.6
0.87
0.92
フロンティアモデル
CI 実行結果を表示(モデル名をクリックすると個別の評価詳細を確認できます)
モデル
正答率
合格数
解決率
ステップ比率
ツール呼び出し比率
anthropic:claude-opus-4-6
0.68
138件中 100件
0.38
0.99
1.02
google_genai:gemini-3.1-pro-preview
0.65
138件中 96件
0.26
0.99
1.01
openai:gpt-5.4
0.61
138件中 91件
0.61
1.05
1.15
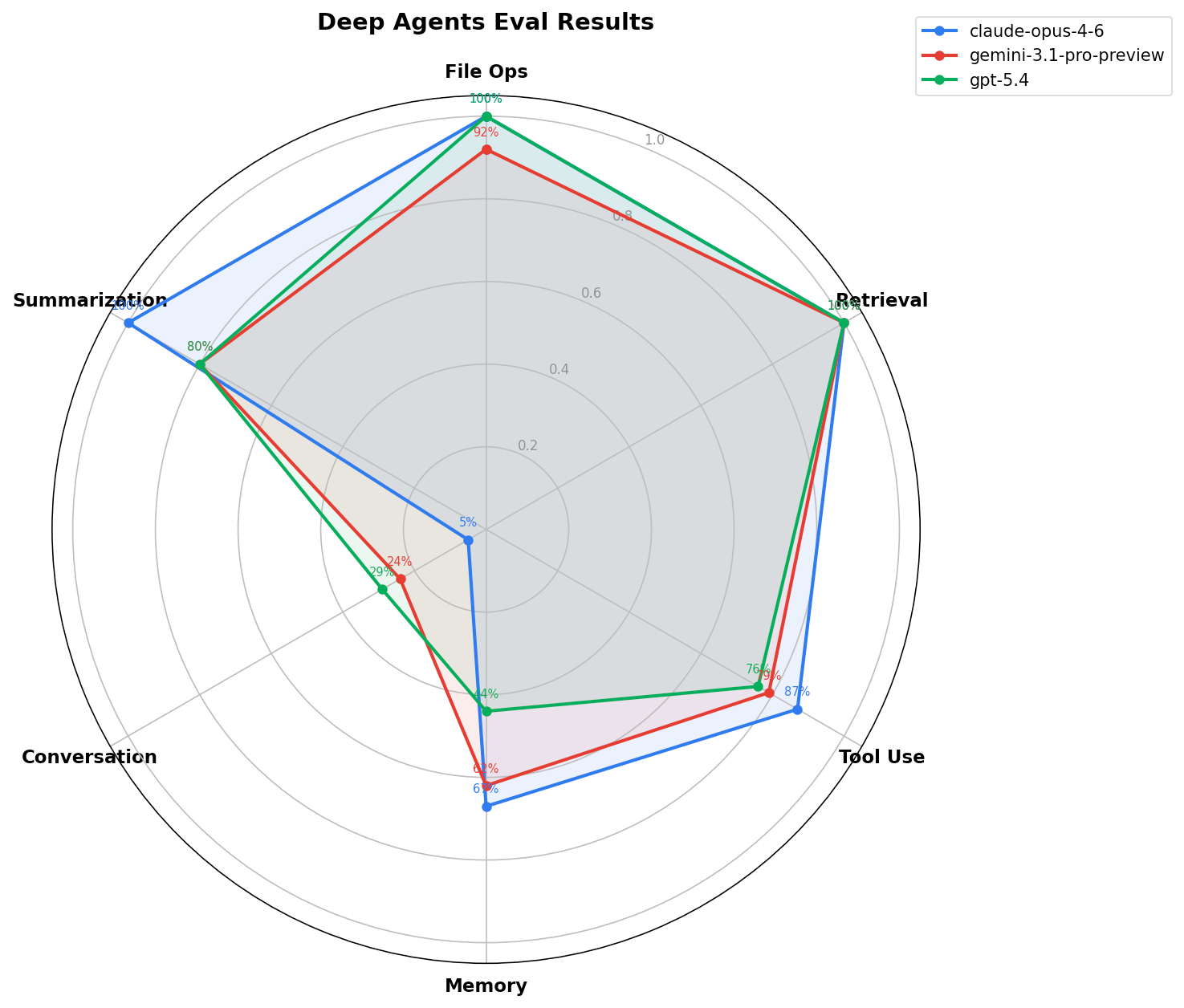 imageカテゴリ別正答率:
imageカテゴリ別正答率:
モデル
会話
ファイル操作
メモリ
検索(Retrieval)
要約
ツール使用
ユニットテスト
anthropic:claude-opus-4-6
0.05
1
0.67
1
1
0.87
1
google_genai:gemini-3.1-pro-preview
0.24
0.92
0.62
1
0.8
0.79
0.92
openai:gpt-5.4
0.29
1
0.44
1
0.8
0.76
1
各モデルについて、プロバイダーのデフォルトの思考レベル(thinking level)を使用することを選択しました。
Gemini 3+の場合、これは「high」です
OpenAIの場合、これは「medium」です
Claudeの場合、これは拡張思考なしです
DIY: ローカルで Deep Agent 評価を実行する
私たちの CI(継続的インテグレーション)では、52 のモデルを対象にグループ分けされた同じ評価スイートを実行しています。これには、すべての評価ワークフローで実行されるオープングループ(baseten:zai-org/GLM-5、ollama:minimax-m2.7:cloud、ollama:nemotron-3-super)が含まれます。任意のモデルグループをターゲットにできます:
すべてのオープンモデルに対して評価を実行: pytest tests/evals --model-group open
特定のモデルに対して実行: pytest tests/evals --model baseten:zai-org/GLM-5
これにより、同じタスクにおいて、オープンモデル同士、およびクローズドなフロンティアモデルとの比較を、同一の採点基準を用いて容易に行うことができます。
Deep Agents SDK におけるオープンモデルの使用
オープンモデルへの切り替えは、一行の変更で完了します:
GLM-5:
pip install langchain-baseten
from deepagents import create_deep_agent
agent = create_deep_agent(model="baseten:zai-org/GLM-5")
MiniMax M2.7:
pip install langchain-openrouter
from deepagents import create_deep_agent
agent = create_deep_agent(model="openrouter:minimax/minimax-m2.7")
これだけです。ハーン(harness)がその後の処理を担います — モデルのコンテキストウィンドウサイズを検出し、サポートされていないモダリティを無効にし、システムプロンプトに適切なアイデンティティを注入して、エージェントが自身の動作環境を理解できるようにします。
同じオープンモデルは、多くの場合、複数のプロバイダーを通じて利用可能です。自身の制約条件に適合するものを選択してください。例えば、GLM-5 は baseten:zai-org/GLM-5、fireworks:fireworks/glm-5、またはセルフホスティング向けの ollama:glm-5 として利用可能です。同じモデル、同じハーン、異なるインフラストラクチャです。
LangChain は、最も人気のあるオープンモデルプロバイダーをサポートしています。今回のリリースでテストを行ったプロバイダーは以下の通りです:Baseten、Fireworks、Groq、OpenRouter、および Ollama(クラウド版)。
モデル固有のハーンレベルでの調整
オープンモデルは、クローズドなフロンティアモデルと比べて、異なるコンテキストウィンドウ、異なるツール呼び出し形式、そして異なる失敗モードを持っています。Deep Agents のハーンはこれらの差異を吸収するため、ユーザーが個別に対応する必要はありません:
モデルアイデンティティの注入 — システムプロンプトは、実行時にモデル名、プロバイダー、コンテキスト制限、およびサポートされるモーダリティでパッチされます。エージェントは自分が何者であり、何ができるかを知っています。
コンテキスト管理 — 圧縮、オフロード、要約の閾値は、ハードコードされたデフォルトではなく、モデルの実際のコンテキストウィンドウに合わせて適応します。4K のコンテキストを持つモデルは、1M のコンテキストを持つ Opus よりもより積極的な圧縮を行います。
Deep Agents CLI
各モデルは Deep Agents CLI からも利用可能です。Deep Agents CLI は、私たちのオープンソースのコーディングエージェントであり、Claude Code の代替です。
Deep Agents SDK のすべての機能に加え、CLI はランタイムでのモデル切り替えをサポートしています。セッション中にエージェントを再起動せずにモデルを切り替えるために、新しいミドルウェア(ConfigurableModelMiddleware)を導入しました。これにより、計画には最先端モデルを、実行にはオープンモデルを使用するというようなパターンが可能になります。
/ model スラッシュコマンドを使用して、セッション中にモデルを切り替えることができます。これにより、計画のために最先端モデルでタスクを開始し、その後実行のためにより安価なオープンモデルに切り替えるというパターンが可能になります。
0:00
/0:50
1×
次に何があるか
今後、共有したいいくつかの事項があります:
特定のオープンモデルファミリーに対するハーネス調整のパターンを文書化する
マルチモデルのサブエージェント構成(例:フロンティアクローズドモデルのオーケストレーター+オープンモデルのサブエージェント)のテスト
現在、エージェントにはオープンモデルが機能しています。私たちは、優れたハーネスを構築し、タスクにとって重要なものを測定するターゲットを絞った評価(evals)を作成するのに役立つ設計パターンを示すことを目的としています。
Deep Agents はオープンソースです。お好みのオープンモデルで試してみてください。そして、私たちと一緒に素晴らしい評価とエージェントを構築しましょう。
原文を表示
TL;DR: Open models like GLM-5 and MiniMax M2.7 now match closed frontier models on core agent tasks — file operations, tool use, and instruction following — at a fraction of the cost and latency. Here's what our evals show and how to start using them in Deep Agents.
 imageOver the past few weeks, we’ve been running open weight Large Language Models through Deep Agents harness evaluations, and the initial results show they are a viable option to use instead of, and alongside, closed frontier models. GLM-5 (z.ai) and MiniMax M2.7 each score similarly to closed frontier models on core agent tasks such as file operations, tool use, and instruction following.
imageOver the past few weeks, we’ve been running open weight Large Language Models through Deep Agents harness evaluations, and the initial results show they are a viable option to use instead of, and alongside, closed frontier models. GLM-5 (z.ai) and MiniMax M2.7 each score similarly to closed frontier models on core agent tasks such as file operations, tool use, and instruction following.
This isn’t surprising if you’ve been following open model progress via the large set of open benchmarks such as SWE-Rebench and Terminal Bench 2.0. Tool calling is reliable and instruction following is consistent. For developers deploying agents in production, open models now offer a level of consistency and predictability that makes real-world workflows much more viable.
Why open models
When exploring open models, builders and customers tend to focus on a few key factors: cost, latency, and task performance.
In the limit, it would be great to use the smartest frontier model at the highest reasoning level for every task. In practice, two constraints make that unworkable: cost and latency. Closed frontier models can run 8–10x more expensive for high-throughput workloads, and they're often too slow for the response times users expect in interactive products.
Model
Type
Input ($/M tokens)
Output ($/M tokens)
Claude Opus 4.6 (Anthropic)
Closed
$5.00
$25.00
Claude Sonnet 4.6 (Anthropic)
Closed
$3.00
$15.00
GPT-5.4 (OpenAI)
Closed
$2.50
$15.00
GLM-5 (Baseten)
Open
$0.95
$3.15
MiniMax M2.7 (OpenRouter)
Open
$0.30
$1.20
To put the pricing in context: an application outputting 10M tokens/day costs roughly $250/day on Opus 4.6 versus ~$12/day for MiniMax M2.7. That's about a $87k annual difference.
Open models tend to be smaller than closed frontier models, and can be accelerated on specialized inference infrastructure — providers like Groq, Fireworks, and Baseten optimize for latency and throughput far beyond what most teams could achieve on their own. OpenRouter data show GLM-5 on Baseten averaging 0.65s latency and 70 tokens/second, compared to 2.56s and 34 tokens/second for Claude Opus 4.6. For latency-sensitive products, that gap is hard to engineer around.
How we evaluated
We've written about our eval methodology in depth in How we build evals for Deep Agents. We run evals using hosted inference providers, but Deep Agents can be run using fully local and private models via Ollama, vLLM, etc.
For open models, we ran seven eval categories: file operations, tool use, retrieval, conversation, memory, summarization, and “unit tests”. These cover tasks that exercise fundamentals: can the model reliably call tools, follow structured instructions, and operate on files? These are the capabilities that gate whether a model is usable in an agentic harness at all.
Each eval case defines success assertions (hard-fail checks that determine correctness) and efficiency assertions (soft checks that measure how the model got there). We report four metrics:
Correctness — the fraction of tests the model solved: passed / total. A score of 0.68 means 68% of test cases were solved correctly. This is the primary quality signal.
Solve rate — a combined measure of accuracy and speed. For each test, we compute expected_steps / wall_clock_seconds; failed tests contribute zero. The final score is the average across all tests. Higher is better — a model that solves tasks both correctly and quickly scores highest.
Step ratio — how many agentic steps the model actually took compared to how many we expected, aggregated across all tests: total_actual_steps / total_expected_steps. A value of 1.0 means the model used exactly the expected number of steps. Above 1.0 means it needed more (less efficient); below 1.0 means it needed fewer (more efficient).
Tool call ratio — same idea as step ratio, but counting individual tool calls instead of steps. 1.0 is on-budget, above is over-budget, below is under-budget.
Step ratio and tool call ratio are efficiency metrics. They don't affect whether a test passes, but they reveal how economically a model reaches the answer. A model that solves a task in 2 steps instead of the expected 5 is both correct and efficient.
Findings from our evals
These are early results; we’re actively maintaining and expanding our eval set. You can view recent runs in realtime both in our GitHub repo and at this shared LangSmith project.
Open models
View CI run (click model names to view individual evals)
Model
Correctness
Passed
Solve Rate
Step Ratio
Tool Call Ratio
baseten:zai-org/GLM-5
0.64
94 of 138
1.17
1.02
1.06
ollama:minimax-m2.7
0.57
85 of 138
0.27
1.02
1.04
imagePer-category correctness:
model
Conversation
File Ops
Memory
Retrieval
Summarization
Tool Use
Unit Test
baseten:zai-org/GLM-5
0.38
1
0.44
1
0.6
0.82
1
ollama:minimax-m2.7:cloud
0.14
0.92
0.38
0.8
0.6
0.87
0.92
Frontier models
View CI run (click model names to view individual evals)
Model
Correctness
Passed
Solve Rate
Step Ratio
Tool Call Ratio
anthropic:claude-opus-4-6
0.68
100 of 138
0.38
0.99
1.02
google_genai:gemini-3.1-pro-preview
0.65
96 of 138
0.26
0.99
1.01
openai:gpt-5.4
0.61
91 of 138
0.61
1.05
1.15
imagePer-category correctness:
model
Conversation
File Ops
Memory
Retrieval
Summarization
Tool Use
Unit Test
anthropic:claude-opus-4-6
0.05
1
0.67
1
1
0.87
1
google_genai:gemini-3.1-pro-preview
0.24
0.92
0.62
1
0.8
0.79
0.92
openai:gpt-5.4
0.29
1
0.44
1
0.8
0.76
1
For each model, we opt to use the provider’s default thinking level.
For Gemini 3+, this is high
For OpenAI, this is medium
For Claude, this is without extended thinking
DIY: Run Deep Agent evals locally
Our CI runs the same evaluation suite across 52 models organized into groups — including an open group (baseten:zai-org/GLM-5, ollama:minimax-m2.7:cloud, ollama:nemotron-3-super) that runs on every eval workflow. You can target any model group:
Run evals against all open models: pytest tests/evals --model-group open
Run against a specific model: pytest tests/evals --model baseten:zai-org/GLM-5
This makes it straightforward to compare open models against each other and against closed frontier models on the same tasks, using the same grading criteria.
Using open models in Deep Agents SDK
Swapping to an open model is a one-line change:
GLM-5:
pip install langchain-baseten
from deepagents import create_deep_agent
agent = create_deep_agent(model="baseten:zai-org/GLM-5")
MiniMax M2.7:
pip install langchain-openrouter
from deepagents import create_deep_agent
agent = create_deep_agent(model="openrouter:minimax/minimax-m2.7")
That's it. The harness handles the rest — it detects the model's context window size, disables unsupported modalities, and injects the right identity into the system prompt so the agent knows what it's working with.
The same open model is often available through multiple providers. Pick the one that matches your constraints. For example, GLM-5 is available as baseten:zai-org/GLM-5, fireworks:fireworks/glm-5, or ollama:glm-5 for self-hosted. Same model, same harness, different infrastructure.
LangChain provides support for the most popular open model providers. The providers we have tested for this release are: Baseten, Fireworks, Groq, OpenRouter, and Ollama (cloud).
Harness-level adjustments for your model
Open models have different context windows, different tool-calling formats, and different failure modes than closed frontier models. The Deep Agents harness absorbs these differences so you don't have to:
Model identity injection — the system prompt is patched at runtime with the model's name, provider, context limit, and supported modalities. The agent knows what it is and what it can do.
Context management — compression, offloading, and summarization thresholds adapt to the model's actual context window, not a hardcoded default. A model with a 4K context gets more aggressive compaction than Opus with 1M.
Deep Agents CLI
Each model is also available in the Deep Agents CLI. The Deep Agents CLI is our open-source coding agent and alternative to Claude Code.
In addition to all the capabilities in Deep Agents SDK, the CLI supports Runtime model swapping. We introduced a new middleware (ConfigurableModelMiddleware ) to enable switching models mid-session without restarting the agent. This enables patterns like using a frontier model for planning and an open model for execution.
You can switch models mid-session with the /model slash command. This enables patterns like starting a task with a frontier model for planning, then switching to a cheaper open model for execution.
0:00
/0:50
1×
What’s next
Some things we’re excited to share soon:
Documenting harness tuning patterns for specific open model families
Testing multi-model subagent configurations (ex: frontier closed model orchestrator + open model subagents)
Open models work for agents today. We want to show the design patterns that help us engineer a good harness and build targeted evals that measure what matters for your task.
Deep Agents is open source. Try it with your preferred open model and come build great evals and agents with us.
関連記事
Helidon 4.4.0がOpenJDKリリースサイクルへの準拠とJava Verified Portfolioによるサポートを導入
Oracleがマイクロサービスフレームワーク「Helidon」のバージョン4.4.0をリリースした。新バージョンはOpenJDKのリリースサイクルに準拠し、Java Verified Portfolioによるサポート、新たなコア機能、LangChain4j向けのエージェントAIサポートを特徴とする。
本番環境でエージェントが自己修復する仕組み
LangChainのソフトウェアエンジニアVishnu Suresh氏が、GTMエージェント向けに自己修復デプロイパイプラインを構築した。デプロイ後に回帰を検出し、変更の原因を特定し、修正PRを自動的に作成する。
Moonshot Kimi K2.6:世界最高峰のオープンモデルがOpus 4.6に追いつくよう刷新
MoonshotはKimi K2.6をリリースし、中国のオープンモデル分野での首位を維持した。この刷新版は継続的な前処理・後処理学習により、Opus 4.6に追いつく性能を目指している。