レイルウェイ:エージェントネイティブクラウド — ジェイク・クーパー
Railway の創業者である Jake Cooper は、従来の Git やプルリクエストに依存しない「エージェントネイティブ」なクラウドインフラの構築と、自社ハードウェアによるコスト革命について語った。
キーポイント
エージェントネイティブなインフラへの転換
従来の Git やプルリクエストワークフローに依存しない、AI エージェントが直接デプロイ・管理を行うための新しいクラウドモデルを提唱している。
オンプレミスハードウェアによる経済的優位性
クラウドベンダーへの依存を減らし自社でデータセンターを運営することで、3 ヶ月での投資回収と 70% のマージンを達成し、ハードウェア資産価値が調達資金を上回っている。
スケーラビリティと運用効率の飛躍的向上
35 人のチームで 300 万ユーザー(週 10 万人の新規登録)を支援しており、Railpack や Nixpacks などの技術により開発者の参入障壁を極限まで下げている。
ハイブリッドクラウドと障害耐性の再構築
GCP アウトインシデントの教訓から、マルチゾーンメッシュリングとオンプレミス・クラウド間のバースト機能を強化し、ワークロードの可視性を独立させた。
エージェントネイティブクラウドのインフラ要件
AI エージェントは従来のソフトウェアとは異なり、バージョン管理、観測可能性、および 1000 倍のスケーラビリティを備えた計算・ストレージ・オーケストレーションを必要とする。
オンプレミスデータセンターとクラウドバーストのハイブリッド戦略
Railway は自社金属(オンプレミス)データセンターでコスト効率を最大化しつつ、需要が急増した際に他社クラウドへバーストする戦略を採用し、ベンチャーキャピタルよりも「データセンター債務」を活用して成長資金を調達している。
エージェント時代のソフトウェア開発ライフサイクル(SDLC)
プルリクエストの概念が衰退し、機能フラグ、段階的ロールアウト、シャドウトラフィック、そして「ペットではなくクローン可能な家畜」という新しいサーバーレスパラダイムが、AI エージェントによる自律的なインフラ管理と安全なデプロイに不可欠となる。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントがソフトウェア開発の中心となる未来において、インフラ設計のパラダイムシフトが必要であることを示唆しており、特に「プルリクエスト」や「静的なクラウドリソース」という概念の再考を迫る重要な視点を提供しています。また、自社ハードウェアによる経済的優位性の実証は、大規模 AI サービスのコスト構造に対する新たな解決策として業界全体に影響を与える可能性があります。
編集コメント
従来のクラウドベンダー依存モデルの限界と、AI エージェント時代におけるインフラの在り方を変える可能性を秘めた、非常に示唆に富むインタビューです。特に「プルリクエストの死」という表現は、開発ワークフローの根本的な変革を予感させる重要なシグナルと言えます。
2026 年 AI エンジニアリング調査に参加して、2,000 ドル以上のクレジットと AIE WF のチケットを獲得しよう!
これは、Railway が 5 月 19 日に大規模な GCP(Google Cloud Platform)の障害に見舞われる前に録画されたものです。同社はマルチ AZ(可用性ゾーン)、マルチゾーンメッシュリングを備え、Metal <> GCP <> AWS の間に HA(高可用性)ファイバー相互接続を有していましたが、ワークロードの検出可能性が意図せず依然として GCP に依存していたためです。すべての問題は事後分析(ポストモーテム)を経て解決されています。
Railway は当初、AI インフラストラクチャ企業として始まったわけではありません。
2020 年に設立されました。これは、エージェントがソフトウェアのデプロイに関する人々の思考のデフォルトとなった数年前のことです。元 Bloomberg や Uber で働いていた Jake Cooper が Railway を立ち上げました。その動機は単純な執念でした:本番環境に何かをリリースするための活性化エネルギー(activation energy)はほぼゼロであるべきだと。コードをプッシュすれば URL が得られ、反復できる。Docker ファイルも、Kubernetes マニフェストも、Ansible スクリプトの上にさらに Ansible スクリプトを重ねるようなものも不要です。
長年、これは地道な grind(苦しい作業)でした。Railway は最初の 18 ヶ月を費やして手動で最初の 100 名のユーザーを獲得し、Jake が第二のモニター上で Discord のサインアップをする一人ひとりに直接挨拶するほどでした。
src
本日、Railway は 1 億 2400 万ドルの資金調達を果たし、非常に急速に成長しています。35 人のチームが 300 万人の利用者をサポートしており、週あたり約 10 万件の新規登録者数を追加しています。彼らが所有するベアメタルデータセンターは、クラウドでのレンタルと比較して 3 ヶ月で投資回収が可能であり、70% の利益率により、必要に応じて積極的なクラウドバースト(需要に応じたリソースの拡張)を賄う資金源となっています。彼らが所有するサーバーは、RAM 価格の上昇に伴い実際には価値が上昇しており、つまり現在ではハードウェアの価値が調達した資本額を超えています。
週末に Railway のネットワークオーバーレイを再構築したり、ワークロードの大半を自社のベアメタルデータセンターに移行したりと、Jake Cooper はエージェントネイティブな世界のための新しいクラウドを構築しようとしています。このエピソードでは、Railway の創設者であり「指揮者」である彼が swyx と Alessio とともに、ソフトウェアインフラストラクチャの次の時代が単なる「より新しい Heroku」ではない理由や、人間には必要なかったエージェントに必要なもの、そして Git、PR(プルリクエスト)、CI/CD、静的なクラウドリソースという従来のデプロイメントループが書き換えに向かっているかもしれない理由について掘り下げていきます。
Railway のインフラストラクチャスタックについて深く掘り下げます。自社所有の金属(オンメタル)データセンター、3 ヶ月でのクラウド投資回収期間、クラウドバースティング、データセンター債務、Railpack、Nixpacks、Temporal、フィーチャーフラグ、Central Station、コンテンツアドレス型ファイルシステム、エージェント安全なプロダクションフォーク、そしてエージェントの世界では CLI がキャンバスよりも重要になる理由についてです。Jake はまた、Railway の創業者としての道のり、月 50 万ドルの損失を乗り越えて会社が生き残った理由、なぜ現在 35 人のスタッフで数百万人のユーザーにサービスを提供しているのか、そしてなぜ彼がプルリクエスト(Pull Request)の時代が終わろうとしていると考えているのかについても語ります。
議論されるトピック:
Railway が6年にも及ぶゆっくりとした grind から、週に10万人のユーザーを追加するスピードへどのように転換したか
Railway がエージェントを次世代の支配的なソフトウェア種としてどう捉えているか
なぜエージェントには、1000 倍のスケーラビリティにおけるバージョン管理、観測性(Observability)、計算リソース、ストレージ、そしてオーケストレーションが必要なのか
Railway の自社所有データセンターと3 ヶ月での投資回収に関する経済性
Railway が自社のインフラを拡張する際にクラウドバースティングをどのように活用しているか
なぜデータセンター債務は、インフラスタートアップにとってベンチャーキャピタルからの債務よりも優れたツールとなり得るのか
顧客のフィードバックやインシデントをクラスタリングするための Railway 内部システムである Central Station の役割
プラットフォームにおいて、責任ある開示と過剰なまでのコミュニケーションがなぜ重要なのか
エージェントにとってフィーチャーフラグ、段階的ロールアウト(Progressive Rollouts)、シャドウトラフィックがなぜ不可欠なのか
Temporal の強み、課題点、そしてワークフローがエージェントにとってなぜ重要なのか
Railpack、Nixpacks、Nix、および遅延読み込み型のコンテンツアドレス型ファイルシステムについて
「ペットではなく家畜(Cattle, not Pets)」という概念が、ペットをクローンできる場合どう変容し得るのか
なぜ Railway はハイパースケール企業を模倣するのではなく、ゼロから新しいクラウドを構築しているのか
ソロファウンダーの道、集中力、執筆活動、そして会社設立に対するジェイクの考え方
Railway:
ウェブサイト: https://railway.com/
X: https://x.com/Railway
Jake Cooper:
LinkedIn: https://www.linkedin.com/in/thejakecooper/
X: https://x.com/JustJake
タイムスタンプ
00:00:00 導入:Railway とは何か?
00:02:07 Railway へのジェイクの道
00:06:13 Railway の六年間の成長ストーリー
00:08:52 フリーティア後の事業再建
00:11:17 エージェントが次なるソフトウェアプラットフォームへ
00:13:29 Railway のインフラ哲学
00:15:42 ベアメタル、クラウド経済学、そして計算資源の逼迫
00:17:22 クラウドバースティングと 5 つのクラウド間ネットワーク
00:20:20 データセンター債務とインフラファイナンス
00:23:31 宇宙内のデータセンター
00:25:24 エージェントがインフラから必要とするもの
00:28:24 CLI、Canvas、そしてエージェントネイティブ UX
00:35:15 Central Station、インシデント、および責任ある開示
00:40:30 安全なロールアウト、SRE エージェント、およびプロダクションフォーク
00:45:00 AI SRE、仕様書、コード、およびテスト
00:48:24 自己複製インフラと新しいサーバーレス
00:53:18 Heroku、Temporal、そしてワークフローエンジン
01:04:07 Railpack、Nixpacks、そして遅延読み込みファイルシステム
01:06:01 コーディングエージェント、トークン使用量、およびロードマップの加速
01:10:56 プルリクエストは死にゆく
01:12:28 機能フラグとエージェント時代の SDLC
01:16:15 家畜、ペット、そしてクローンマシン
01:19:29 ソロファウンダーからの教訓
01:24:12 集中力、GPU、そして新しいクラウドの構築
01:28:20 クロージング・スレッド
なぜ Railway はハイパースケール企業を模倣するのではなく、ゼロから新しいクラウドを構築しているのか
多くのスタートアップが巨大なクラウドプロバイダー(AWS や Azure など)の API をラップしてサービスを提供しようとする中、Railway は根本的に異なるアプローチを取っています。彼らは既存のプラットフォームの制約に縛られることなく、エージェントや現代の開発ワークフローに最適化されたインフラストラクチャをゼロから設計・構築しています。
この決断は単なる技術的な選択ではありません。それは、現在のクラウドが「人間中心」の設計思想に基づいており、AI エージェントが自律的に動作するための要件を満たしていないという認識に基づいています。Railway は、エージェントが直接インフラと対話し、リソースを動的に割り当て、障害を検知して修復できるような環境を作ることを目指しています。
ソロファウンダーの道、集中力、執筆活動、そして会社設立に対するジェイクの考え方
Jake Cooper 氏は、Solo Founder(一人創業者)として Railway を立ち上げました。この道は孤独であり、常に決断を迫られますが、その分、ビジョンを曲げずに進むことができます。
彼は頻繁に執筆活動を行い、自身の考えや業界の動向を共有しています。これは単なるマーケティングではなく、思考を整理し、コミュニティと対話するための手段です。彼の文章からは、技術的な深さとビジネス戦略のバランスに対する深い洞察が感じられます。
会社設立においては、「何を作るか」よりも「なぜ作るのか」という問いに徹底的に向き合ってきました。この集中力が、Railway が他社とは異なる独自の道を歩む原動力となっています。
Railway:
ウェブサイト: https://railway.com/
X: https://x.com/Railway
Jake Cooper:
LinkedIn: https://www.linkedin.com/in/thejakecooper/
X: https://x.com/JustJake
タイムスタンプ
00:00:00 導入:Railway とは何か?
このセクションでは、Railway の基本理念と、なぜ従来のクラウドプラットフォームとは異なるのかについて解説します。Railway は、開発者がインフラの複雑さに悩まされることなく、コードをデプロイしてすぐに実行できるようにすることを目的としています。
00:02:07 Railway へのジェイクの道
Jake Cooper のキャリアと、なぜ彼が Railway を立ち上げるに至ったのかについて語ります。彼の背景には、従来の開発体験に対する不満と、より良い解決策を創りたいという強い意志がありました。
00:06:13 Railway の六年間の成長ストーリー
Railway が設立されてからの 6 年間の歩み、特にフリーミアムモデルから収益化への転換、そしてユーザー基盤の拡大について詳しく説明します。
00:08:52 フリーティア後の事業再建
無料プラン(Free Tier)を提供した後に直面した課題と、それを乗り越えて持続可能なビジネスモデルを構築するための戦略について語ります。
00:11:17 エージェントが次なるソフトウェアプラットフォームへ
AI エージェントがソフトウェア開発の中心となる未来において、Railway がどのような役割を果たす予定なのか、そしてなぜそれが次のプラットフォームになるのかについて議論します。
00:13:29 Railway のインフラ哲学
Railway が採用するインフラ設計の原則、特に「エージェントファースト」のアプローチと、その背後にある技術的・経済的な理由を解説します。
00:15:42 ベアメタル、クラウド経済学、そして計算資源の逼迫
ベアメタル(Bare Metal)サーバーの活用がなぜ重要なのか、クラウドコストの構造変化、そして計算資源(Compute)の不足という課題について深掘りします。
00:17:22 クラウドバースティングと 5 つのクラウド間ネットワーク
複数のクラウドプロバイダーをまたぐ「クラウドバースティング」技術と、Railway が構築した 5 つの主要クラウド間の高速ネットワークインフラについて説明します。
00:20:20 データセンター債務とインフラファイナンス
データセンターの建設や維持にかかる巨額の資本支出(CapEx)の問題、そしてそれをどう資金調達し、リスクを管理しているかについて語ります。
00:23:31 宇宙内のデータセンター
未来の可能性として、宇宙空間にデータセンターを構築するという大胆なアイデアと、その技術的・経済的な実現可能性について議論します。
00:25:24 エージェントがインフラから必要とするもの
AI エージェントが自律的に動作するために必要なインフラの特性、例えば低遅延、高い信頼性、そして自己修復能力などについて詳述します。
00:28:24 CLI、Canvas、そしてエージェントネイティブ UX
コマンドラインインターフェース(CLI)と Canvas(視覚的なワークフローエディタ)が、どのようにしてエージェントネイティブなユーザー体験(UX)を実現しているかについて解説します。
00:35:15 Central Station、インシデント、および責任ある開示
Railway の監視・管理システム「Central Station」の役割、インシデント対応のプロセス、そしてセキュリティ脆弱性に関する責任ある開示(Responsible Disclosure)の方針について語ります。
00:40:30 安全なロールアウト、SRE エージェント、およびプロダクションフォーク
本番環境への安全なリリース戦略、Site Reliability Engineering(SRE)エージェントの活用、そして問題発生時の迅速な復旧のための「プロダクションフォーク」技術について説明します。
00:45:00 AI SRE、仕様書、コード、およびテスト
AI による SRE の自動化、システム仕様の自動生成、コードの自己修正、そしてテストケースの自動作成など、AI がインフラ運用をどう変えるかについて議論します。
00:48:24 自己複製インフラと新しいサーバーレス
インフラが自己複製する仕組みと、従来のサーバーレスアーキテクチャを超えた「新しいサーバーレス」の概念について解説します。
00:53:18 Heroku、Temporal、そしてワークフローエンジン
Heroku の遺産や Temporal などのワークフローエンジンとの比較、そして Railway が独自に開発したワークフローエンジンの特徴について語ります。
01:04:07 Railpack、Nixpacks、そして遅延読み込みファイルシステム
アプリケーションのデプロイを簡素化する「Railpack」と「Nixpacks」の仕組み、そしてリソース効率を高めるための遅延読み込み(Lazy-Loaded)ファイルシステムについて説明します。
01:06:01 コーディングエージェント、トークン使用量、およびロードマップの加速
AI コーディングエージェントの利用が、トークンコストに与える影響と、それによって開発ロードマップがどのように加速されているかについて議論します。
01:10:56 プルリクエストは死にゆく
従来のプルリクエスト(Pull Request)ベースの開発ワークフローの限界と、AI エージェント時代における新しいコラボレーションモデルについて語ります。
01:12:28 機能フラグとエージェント時代の SDLC
ソフトウェア開発ライフサイクル(SDLC)において、機能フラグ(Feature Flags)がどのように進化し、エージェント主導の開発を可能にするかについて解説します。
01:16:15 家畜、ペット、そしてクローンマシン
サーバー管理における「家畜(Cattle)」と「ペット(Pets)」の概念、そして AI エージェントによる自動クローン生成(Cloning Machines)の可能性について議論します。
01:19:29 ソロファウンダーからの教訓
一人創業者として Railway を運営する中で得た経験や教訓、成功と失敗から学んだことについて語ります。
01:24:12 集中力、GPU、そして新しいクラウドの構築
限られたリソースの中でいかに集中力を維持し、GPU の活用を通じて新しいクラウドインフラを構築していくかについての洞察を提供します。
01:28:20 クロージング・スレッド
今回の議論のまとめと、Railway が目指す未来、そして開発者や AI エージェントにとっての展望について締めくくります。
transcript
Alessio [00:00:00]: みなさん、こんにちは。Latent Space Podcast へようこそ。Kernel Labs の創設者であるアレッシオです。今日は Latent Space の編集者である Swyx と一緒にいます。
Swyx [00:00:10]: やあ、やあ、やあ。今日は Railway のジェイク・クーパーをスタジオにお迎えしています。
Alessio [00:00:14]: Railway の指揮者です。
Swyx [00:00:15]: Railway での指揮者ですね。はい。
Alessio [00:00:16]: チューチュー。
Swyx [00:00:17]: それ、実際に名刺とかに載せているんですか?
Jake [00:00:20]: 一部のボランティアモデレーターを指揮者と呼んでいます。名刺は持っていません。まだそんなに大きくないですから。いつかは作るつもりです。Supermicro の方々から素敵な名刺をいただいたときは、「おや、これはかなり公式っぽい」と思いました。
Swyx [00:00:30]: 名刺が再び流行っていますね。
Jake [00:00:32]: 確かにクールで、ヒップです。指揮者という呼び方はいいと思います。社内での互いの呼び方をどうするか模索中です。中には「社内の人間に名前なんて必要ない」と言って、非常に恥ずかしいと感じる人もいれば、「何か呼び名をつけたい」と考える人もいます。まだ本当に良い案は出ていません。
Jake [00:00:55]: 「New Railcrews」や「Trainiacs」などいくつか提案されていますが、定着したものはまだありません。
Swyx [00:01:00]: Trainiac はいいですね。響きが良さそうです。Railwayians もいいかもしれません。ご存知ない方のために、まず Railway について簡潔に定義していただきましょう。
Jake [00:01:09]: Railway は、あらゆるものを配信するための最も簡単な方法です。キャンバスにアクセスするか、Claude と対話して、「Postgres インスタンスをデプロイする」「GitHub リポジトリをデプロイする」「このコードを実行する」と言うだけで、すぐに実行できます。
Swyx [00:01:22]: ランディングページには素敵なアニメーションがありますね。
Jake [00:01:24]: ありがとうございます。ちなみに、私の作品ではありません。もうデザイン関連の作業はさせてもらっていないんです。
Jake [00:01:25]: 私たちが目指しているのは、単にものをデプロイするだけでなく、時間をかけてアプリケーションを進化させることを極めて容易にすることです。現在のほとんどのツールは、エントロピーの上にさらにエントロピーを積み重ねています:Docker、Kubernetes、Ansible スクリプト、そしてこれら以外の多くのものです。もしソフトウェアのすべてのバージョン管理を行い、変更点をすべて追跡できれば、環境のクローン作成や並行宇宙へのフォーク、本番データの複製、あらゆるサービスの複製、変更の適用、検証、そしてステージング環境全体を再現することなく、それらを統合して戻すことが極めて容易になります。
The Railway Origin Story: From Uber Systems to a New Cloud
Swyx [00:02:07]: あなたの経歴を見ていました:Bloomberg、Uber。すぐに「この人が次世代の素晴らしいプラットフォーム・アズ・ア・サービス(PaaS)を立ち上げる」と思わせる要素はありませんでした。何が Railway への準備になったのですか?
Jake [00:02:21]: 深く掘り下げていくことへの好奇心が、前進する原動力でした。最初はフロントエンドの分野から始め、Wolfram Mathematica を扱ってそれを移植しました。その後、一時的に Bloomberg で働き、Uber へと移り、分散システムに取り組むようになりました。Jump Bikes のシステムを、Cadence(当時の Temporal)の上に構築された分散システムへ移行させたのです。
Swyx [00:02:44]: ちなみに、その件については賛否両論も含めてお話しできて嬉しいです。
Jake [00:02:48]: 全くその通りです。
Swyx [00:02:51]: では、Railway の物語を聞かせてください。
Jake [00:02:52]: それは常に、ある体験を求める継続的なステップでした。自転車に近づいてロックを解除し、摩擦なく動作させることでも、あるいは別の何事であっても、その体験を実現するために必要な深さは、その体験から導き出されるものです。私が行う仕事の多く、そしてチームが行う多くの仕事は、まさにその体験のためにあります。私たちは、どこまで深く潜る必要があるかには根本的にこだわりません。その体験を得るために、水泳プールの底まで泳ぎ切ります。
Jake [00:03:17]: 私は物理学の博士号を持っていません。電気電子工学とコンピュータサイエンス(EECS)の学位を取得しました。常に重要だったのは、次のステップをどう見つけるか、つまり「どのようにしてそこに到達するか」を考えることです。それが、Railway を立ち上げてその体験を実現し、最終的にはベアメタルデータセンターまで至る道へと繋がりました。先週も、その体験をより良くするためにカーネルにパッチを追加していました。なぜなら、もっと良くなる可能性が明確に見えるからです。
Swyx [00:03:49]: 今週は Linux カーネルへの他のパッチも?
Jake [00:03:51]: はい。メインストリーム(upstream)ではなく、私たちのフォーク版です。
Swyx [00:03:52]: それは自慢話ですね。Railpack? いいえ、これは違います。これは Railpack 上の OS ですか?
Jake [00:03:57]: いいえ、これは実際のカーネルパッチです。常に本質的に問うのは、「その体験を実現するために何をする必要があるか」です。そしてそれを解決します。どんなことでも解決可能です。
Swyx [00:04:10]: そのパッチをアップストリーム(上流)に送るのでしょうか、それとも他のユースケースには適合しないのですか?
Jake [00:04:13]: 可能性はあります。まず内部でその体験を確立する必要があります。これは、一部のエージェント機能向けに構築しているストレージレイヤーに関連しています。アップストリームでも役立つかもしれませんが、私たちにとっては内部的に非常に有用です。
オープンソース、フォーク、非決定性バージョン管理
Swyx [00:04:29]: 以前、オープンソースについて言及されました。オープンソースから始めて、そこからエージェントをコーディングすることで、そのフォーク(派生版)からより多くのことを実現できるという点について、どのようにお考えですか?
Jake [00:04:38]: GitHub の原罪は、それがほぼ壊れたポインタの連続であることです。あるものがあり、それをクローンすると、今度は全体がアップストリームから切り離されてしまいます。人々が非常に小さな部分を修正することをどうすれば容易にできるでしょうか?
Jake [00:04:51]: 私たちは Git を離散的な概念として捉えています:変更を加えてアップストリームにマージしたか、そうでないかのどちらかです。それがパーセンテージベースで、少し非決定性(確定的でない性質)を持ち、一般にロールアウトされるパーセンテージとしてユーザーがたどる変化のストリーム、そして最終的にすべてを巻き戻すような形だとしたらどうなるでしょうか?
Jake [00:05:13]: オープンソースのフィードバックプログラムがあり、テンプレートをデプロイできるようにしています。これは、人々がこれらのシャードを時間とともにバージョン管理することを容易にするためです。認証、権限付与、セキュリティに関する大きな問題を解決します。NPM には、「新しいパッケージは受け取らない」と定義する方法があります。理想的な最終状態は、最小の影響範囲でユーザーに段階的に展開し、継続してロールアップすることです。私たちの金銭や生活がかかっているため、JPMorgan はおそらくパッチラインの最後になるべきでしょう。
Jake [00:05:53]: Johnny Vibe Coder が壊れたパッチを入手しても問題ありません。システムにエントロピーが非常に多いため、いつかは現実と向き合わなければなりません。異なるレベルでテストする必要があります。
The Long Grind: First Users, Free Tier, and Making the Business Work
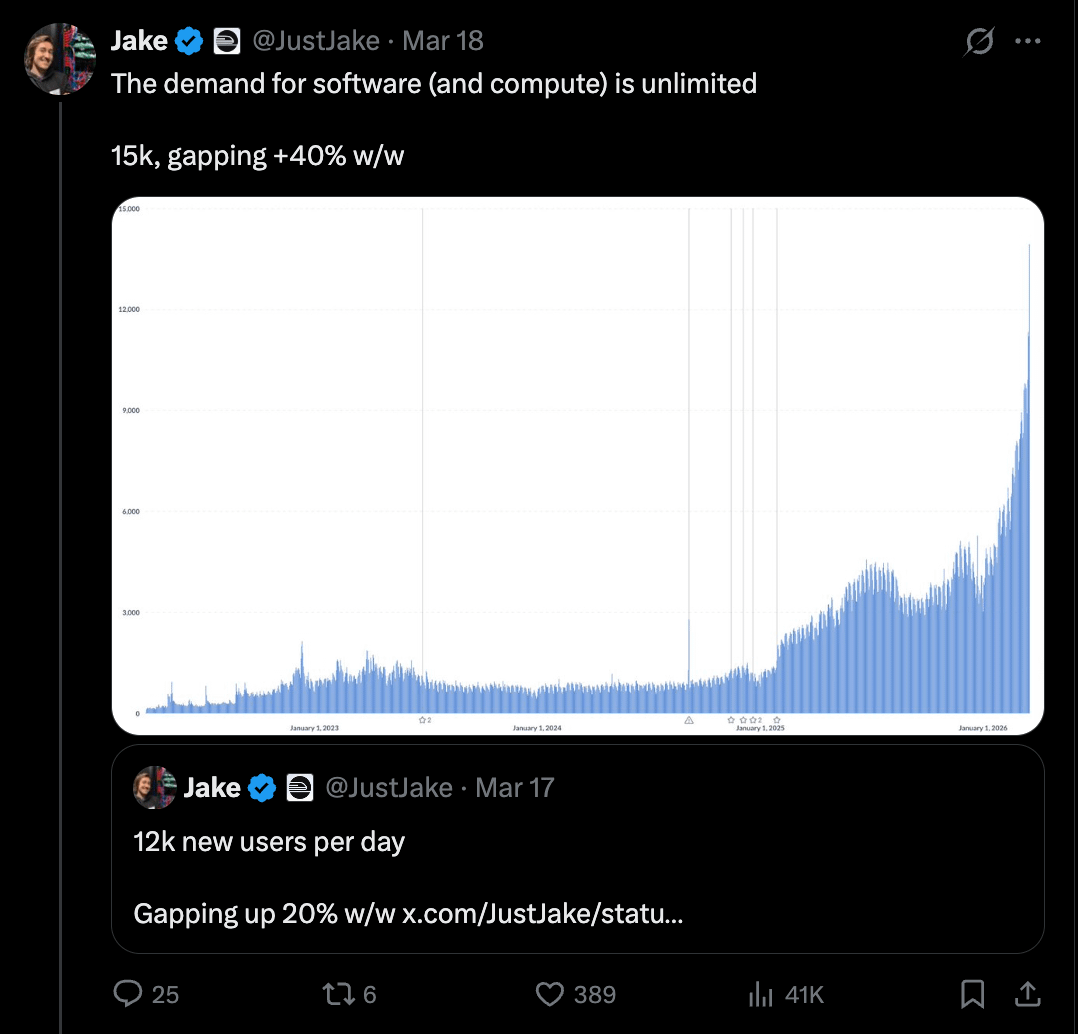
Swyx [00:06:13]: この素晴らしいチャートを表示したかったのですが、これはあなたの利用状況ですか?それとも日次登録者数ですか?
Jake [00:06:22]: 日次登録者数だと思います。
Swyx [00:06:24]: あなたは 6 年前に始めました。最初はゆっくりとした grind(苦しい努力)でしたが、今はロケット船に乗ったような状態です。「戦いを疑うな、諦めるな」と言いますね。会社にとって重要な転換点となった特定のポイントをいくつか挙げてみませんか?
Jake [00:06:40]: 最初は、どんなことがあっても最初の 100 人のユーザーを獲得することに尽きます。当時はウェブサイトとサポートリンクがあり、そのサポートリンクは Discord チャンネルでした。私は 2 つのモニターを準備し、片方は作業用、もう片方は Discord 用の通知オンにしていました。誰かが入ってくると、すぐに「やあ、どうしてる?」と声をかけるようにしていました。稀な出来事だったので、最初の 100 人のユーザーに再来してもらうことがスタートでした。
Jake [00:07:14]: その後、ユーザーがさまざまなことを求めてくるため、コンサルティングファクトリーを構築することになります。その上で実際に構築したい製品提供は何なのかと、取締役会に戻って問いかける必要があります。
Jake [00:07:28]: ベンチャーキャピタリスト(VC)は常に右上に伸びるチャートを望みますが、現実には必ずしもそのようなチャートが必要とは限りません。私たちにとって、機能を追加してユースケースを検証する拡大の時期と、「現在の体験が良いなら、どうすれば大幅に改善できるか」と問いかけ、機能を縮小する集約の時期がありました。もしかすると、私たちの理想顧客像(ICP)に合わなくなった機能を削除することもあるかもしれません。
Jake [00:07:57]: 2022 年から 2023 年にかけてのブームは、無料枠から生まれました。世界中の誰もがそれを利用していました。
Swyx [00:08:09]: Reddit のボットや Discord のボットもその多くでした。
Jake [00:08:12]: そして暗号資産マイナーもいます。誰でも登録できるインターネット上でオープンな製品を構築する場合、インターネットは多くの問題を抱えた恐ろしい場所です。ある時期には「いかに多くの人々にリーチするか」を考え、次の時期には「本当に重要で、この特定の事柄に熱狂している人々のための正確なユースケースをどう満たすか」を考えるようになります。
Jake [00:08:39]: その後、実際にビジネスを成立させるための 2 年間の期間がありました。無料枠の時代には、月間約 50 万ドルの赤字を出していました。
Swyx [00:08:59]: 銀行口座残高が 2,000 万ドルある中でです。
Jake [00:09:02]: はい、月間の収益が約 5 万ドルしかない 2,000 万ドルの銀行口座の中でです。これはひどいビジネスです。誰が投資したのか私にはわかりませんが、それでもその過程を乗り越え、「人々が愛する体験は提供できているが、ビジネスとして成立させなければならない」と言わなければなりません。
Jake [00:09:17]: 考え方には二つの流派があります。悪い利益率のままこのひどいビジネスを拡大し続けるか、あるいは立ち返ってビジネスを成立させるかです。私たちは常に超スリムなチームを望んできました。現在は 35 人で、非常に小規模です。
Swyx [00:09:36]: すでに 300 万人をサポートしているのですか?
Jake [00:09:38]: はい。現在、週に 10 万人のユーザーを追加しており、急速に成長しています。人数を増やすためだけに人員を増やしたり、問題に対してただ人を投入したりしたくはありません。システムを構築したいのです。拡大期にシステムを構築するのは難しいものです。なぜなら、人々が要求してきたり、何かが壊れたりして、システムに要素が追加されてしまうからです。
Jake [00:10:00]: 無料ユーザーをしばらく停止し、ビジネスモデルを再構築して機能を確認する必要がありました。ソフトウェアは重要であり、できるだけ多くの人に届けることを望んでいます。物理世界で何かを作ることは難しくなっているため、バーチャル世界で人々が簡単に創造し、その機会にアクセスできるようにすることが重要です。しかし、この旅路にはいくつかの段階があります。
Jake [00:10:30]: チャートを見ると凹んだ部分が見えます。2025 年から 2026 年にかけての推移を追うと、それは夏か冬の時期です。人々は家族と休暇に出かけます。
Swyx [00:10:50]: それほど影響があるのですか?
Jake [00:10:51]: はい。B2C 的な側面もあれば B2B 的な側面もあります。人々は常に何かをリリースしていますが、その後停止します。現在のアクティベーション曲線では、ビジネスユーザーが増えたため、平日にアクティブ化する人が多くなっており、時間とともに平滑化されています。
デプロイメントへの新しいインターフェースとしてのエージェント
Swyx [00:11:17]: AI 開発やエージェント開発を優先し始めた時期はありましたか?
Jake [00:11:24]: エージェント型(agentic)の機能をトップ・オブ・ファネル(最上部の段階)として優先してきました。過去半年の間、私たちは物事を構築・デプロイするためのメカニズムとしてエージェント型を深く優先しています。なぜなら、その成長曲線が非常に急峻であり、これが人々がソフトウェアを構築しデプロイする方法になると信じているからです。
Jake [00:11:42]: これがドットコム企業かどうかは本質的に重要ではありません。なぜなら、私たちは皆すでにインターネット上にいるからです。もしエージェントが多数のものを展開し、いずれ推論の壁にぶつかったとしても、その問題は解決します。今後 10 年間で支配的な種となるのは、私たちがアセンブリから C、C++、JavaScript、そして言葉へと移行してきたという事実です。このループを閉じる必要があります。
Swyx [00:12:13]: あなたがこれをドットコムと呼んだとき、ドメインの購入を指しているのか、それとも一般的なケースを指しているのですか?
Jake [00:12:17]: 私はドットコム・バブル期を指しています。その時代、人々がインターネットの重要性を理解したため企業は大幅に成長しましたが、その後ボトルネックや物理法則の根本的な限界、数学的整合性の欠如などに直面し、誰もが現実へと引き戻されました。しかし重要なのは、インターネットがあまりにも大きな影響力を持ったことです。十分に長い時間軸で事業を運営するならば、その行先が見える以上、これらの仕組みは結局構築すべきなのです。
Jake [00:12:45]: それが私が考えるエージェント関連の多くの課題のある場所です。並列で数千のエージェントを実行する段階に達したとき、推論コストはどうなるのか?計算リソースのコストはどうなるのか?どうすれば効率的にできるのか?これらをどう調整するのか?私たちは人間同士を調整することさえも課題を抱えており、そのための優れたツールすらまだ整っていません。今や、エージェント同士をどのように安全に調整し、変更のバージョン管理を行い、誰かが介入する必要があるタイミングをどう判断するかを考えなければなりません。そうしなければ、それは単なる割り込み製造工場になってしまいます。
Railway のインフラストラクチャに関する主張:ネットワーク、コンピューティング、ストレージ、そしてメタル
Swyx [00:13:19]: それではすぐに技術的な側面に入りましょう。あなたがたが実現していることの背後にある、Railway の中核となるインフラやアーキテクチャに関する信念とは何ですか?
Jake [00:13:29]: 私たちにとってプリミティブ(基本要素)は非常に重要です。ネットワーク、コンピューティング、ストレージ、そしてそれらを統制するオーケストレーションが必要です。これらの多くの要素に対する制御権を握る必要があります。私たちは、ワークロードを非常に特定の場所に配置するために高いレベルの制御を望んでいるため、実際には Kubernetes をあまり使用しないことについて多く語ってきました。
Jake [00:13:48]: その理由は、エージェントにおいてはメモリ再利用やその他のあらゆる点において非常に効率的でなければならないからです。そうでなければ、コスト構造が劇的に膨れ上がってしまいます。自らのサーバーをラックに積み上げ、独自のメタル(物理サーバー)を構築できることは、パフォーマンスとコストの両面で解放をもたらします。1,000 個のエージェントを並列実行するような体験も、巨額の費用がかかるものではありません。
Jake [00:14:13]: トークン使用量やコンピューティング使用量が急増しています。長期的には、これらの要素はもっと効率的になる必要があります。独自のメタルを構築することで、それらの体験を堅牢なものにするための十分なマージンを確保できます。これは、可能な限り多くの人々に差別化された体験を提供するためのすべてです。
Swyx [00:14:51]: あなたたはシンガポールにデータセンターを持っていますね。
Jake [00:14:53]: はい。現在では他のすべての地域にも 2 つずつあります。シンガポールには第 3 四半期に 2 つ目を追加する予定です。
Swyx [00:14:58]: それはどのようなものですか?私はデータセンターを構築したことがありません。Equinix に行って、「スロットが欲しい」と言うのですか?
Jake [00:15:05]: はい。Equinix です。基本的に「電力とケージ(専用区画)が欲しい」と言えば、「承知しました、こちらになります」と返されます。一定期間ケージをレンタルし、ラックやサーバーを配置してインターネットに接続するだけです。それがすべてです。
Swyx [00:15:36]: 残りのことはすべて自分で処理する必要がありますね。
Jake [00:15:37]: はい、残りのことはすべて自分たちで処理します。
Swyx [00:15:39]: クラウドが代わりにやってくれる場合とのコスト比較はどうなりますか?
Jake [00:15:43]: もしクラウド上でレンタルした場合、物理サーバー(メタル)に移行した際の投資回収期間は約 3 ヶ月です。
Swyx [00:15:50]: それは驚異的です。
Jake [00:15:51]: 正に狂気じみています。これは減価償却済みのハードウェアを 4 年間使用したのに匹敵します。ハイパースケイラー(大規模クラウド事業者)が大量の機器を購入しているため、計算リソースの逼迫(compute crunch)がこの先も頻繁に見られるようになるでしょう。私たちは Supermicro や Dell など、これらのマシンを構築する OEM メーカーや販売業者と直接連携しています。
Jake [00:16:11]: 上流工程では供給圧力が非常に強まっています。直近の資金調達ラウンドから現在に至るまで、サーバーへの資本投入を行ったにもかかわらず、私たちが調達した金額は、銀行預金残高にサーバーの価値(RAM 価格の上昇による評価額の上昇)を加えた金額よりも少ないのです。ハードウェアがこれほどまでに価値ある資産となったことは驚くべきことです。
Jake [00:16:50]: ハイパースケイラーを見渡すと、彼らは今年だけで約 800 億ドルの設備投資(CAPEX)を投入しました。来年はさらに増える見込みです。これは大規模なインフラ構築プロジェクトです。
原文を表示
Take the 2026 AI Engineering Survey and get >$2k in credits and AIE WF tickets!
This was recorded before Railway suffered a major GCP outage on May 19, despite being a multi-AZ, multi-zone mesh ring, with HA fiber interconnects between their Metal <> GCP <> AWS, because workload discoverability was unintentionally still tied to GCP. All has been resolved with a post-mortem.
Railway did not start as an AI infrastructure company.
It was founded in 2020 years before agents became the default way people thought about deploying software. Jake Cooper, formerly at Bloomberg and Uber, started Railway with a simple obsession: the activation energy to ship something to production should be near zero. Push code, get a URL, iterate. No Docker files, no Kubernetes manifests, no Ansible scripts stacked on Ansible scripts.
For years, this was a slow grind. Railway spent its first 18 months hand-acquiring its first 100 users with Jake personally greeting every Discord signup on a second monitor.
src
Today, Railway has raised $124m and is growing very fast. A 35-person team supports 3 million users, adding roughly 100,000 signups a week. Their bare metal data centers have a 3-month payback period vs. renting in the cloud, with 70% margins funding aggressive cloud bursting when needed. The servers they own have actually appreciated in value as RAM prices have climbed basically meaning the value of their hardware now exceeds the capital they've raised.
From rebuilding Railway’s network overlay over a weekend to moving the vast majority of workloads onto its own bare metal data centers, Jake Cooper is trying to build a new cloud for an agent-native world. In this episode, Railway’s founder and “conductor” joins swyx and Alessio to unpack why the next era of software infrastructure is not just “Heroku but newer,” what agents need that humans did not, and why the old deployment loop of Git, PRs, CI/CD, and static cloud resources may be heading for a rewrite.
We go deep on Railway’s infrastructure stack: own-metal data centers, three-month cloud payback periods, cloud bursting, data center debt, Railpack, Nixpacks, Temporal, feature flags, Central Station, content-addressable filesystems, agent-safe production forks, and why the CLI may become more important than the canvas in an agent world. Jake also shares the founder journey behind Railway, how the company survived losing $500K/month, why it now serves millions of users with only 35 people, and why he believes the pull request is dying.
We discuss:
How Railway went from a slow six-year grind to adding 100,000 users a week
How Railway thinks about agents as the next dominant software species
Why agents need version control, observability, compute, storage, and orchestration at 1000x scale
The economics of Railway’s own-metal data centers and three-month payback
How Railway uses cloud bursting while scaling its own infrastructure
Why data center debt can be a better tool than venture debt for infra startups
Central Station, Railway’s internal system for clustering customer feedback and incidents
Why responsible disclosure and over-communication matter for platforms
Why feature flags, progressive rollouts, and shadow traffic are essential for agents
Temporal’s strengths, pain points, and why workflows matter for agents
Railpack, Nixpacks, Nix, and lazy-loaded content-addressable filesystems
Why “cattle, not pets” may change if you can clone the pets
Why Railway is building a new cloud from scratch instead of copying hyperscalers
The solo founder path, focus, writing, and how Jake thinks about company building
Railway:
Website: https://railway.com/
X: https://x.com/Railway
Jake Cooper:
LinkedIn: https://www.linkedin.com/in/thejakecooper/
X: https://x.com/JustJake
Timestamps
00:00:00 Introduction: What Is Railway?
00:02:07 Jake’s Path to Railway
00:06:13 Railway’s Six-Year Growth Story
00:08:52 Rebuilding the Business After the Free Tier
00:11:17 Agents as the Next Software Platform
00:13:29 Railway’s Infrastructure Philosophy
00:15:42 Bare Metal, Cloud Economics, and the Compute Crunch
00:17:22 Cloud Bursting and Five-Cloud Networking
00:20:20 Data Center Debt and Infra Financing
00:23:31 Data Centers in Space
00:25:24 What Agents Need From Infrastructure
00:28:24 CLIs, Canvas, and Agent-Native UX
00:35:15 Central Station, Incidents, and Responsible Disclosure
00:40:30 Safe Rollouts, SRE Agents, and Production Forks
00:45:00 AI SRE, Specs, Code, and Tests
00:48:24 Self-Replicating Infrastructure and the New Serverless
00:53:18 Heroku, Temporal, and Workflow Engines
01:04:07 Railpack, Nixpacks, and Lazy-Loaded Filesystems
01:06:01 Coding Agents, Token Spend, and Roadmap Acceleration
01:10:56 The Pull Request Is Dying
01:12:28 Feature Flags and the Agent-Era SDLC
01:16:15 Cattle, Pets, and Cloning Machines
01:19:29 Solo Founder Lessons
01:24:12 Focus, GPUs, and Building a New Cloud
01:28:20 Closing Thoughts
Transcript
Alessio [00:00:00]: Hey, everyone. Welcome to the Latent Space Podcast. This is Alessio, founder of Kernel Labs, and I’m joined by Swyx, editor of Latent Space.
Swyx [00:00:10]: Hey, hey, hey. Today we’re in the studio with Jake Cooper of Railway.
Alessio [00:00:14]: Conductor of Railway.
Swyx [00:00:15]: Conductor at Railway. Yeah.
Alessio [00:00:16]: Choo-choo.
Swyx [00:00:17]: Do you actually have that anywhere, like on your business card?
Jake [00:00:20]: We call some of our volunteer moderators conductors. I don’t have a business card. We’re not that big yet. At some point I will. I got handed a nice business card from the Supermicro folks, and I was like, “Damn, this is pretty official.”
Swyx [00:00:30]: Business cards are coming back.
Jake [00:00:32]: They’re cool. They’re hip. The conductor thing is good. We’re trying to figure out what we want to call each other internally. Some people think it’s super cringe and say, “You don’t need a name for people internally.” Some people want to call each other something. We still don’t have a really good one.
Jake [00:00:55]: We’ve got New Railcrews, Trainiacs. Nothing has stuck yet.
Swyx [00:01:00]: I like Trainiac. Trainiac sounds good. Railwayians. For those who don’t know, what is Railway? Let’s give people a crisp definition up front.
Jake [00:01:09]: Railway is the easiest way to ship anything. You go to the canvas, or you talk with Claude, and you say, “Deploy a Postgres instance, deploy my GitHub repository, run this code,” and you’re off to the races.
Swyx [00:01:22]: You’ve got a nice animation on the landing page.
Jake [00:01:24]: Thank you. None of my work, by the way. They don’t let me touch the design stuff anymore.
Jake [00:01:25]: We want to make it trivially easy not just to deploy things, but to evolve applications over time. Most tooling right now stacks entropy on top of entropy: Docker, Kubernetes, Ansible scripts, and all these other things. If we can version all of your software and keep track of all the changes, then we can make it trivial to clone environments, fork into a parallel universe, get copies of production data, get copies of any services, make changes, validate them, and collapse them back in without reproducing everything across a staging environment.
The Railway Origin Story: From Uber Systems to a New Cloud
Swyx [00:02:07]: I was looking at your background: Bloomberg, Uber. Nothing immediately stands out as, “This guy is going to found the next great platform as a service.” What prepared you for Railway?
Jake [00:02:21]: It was curiosity to keep going deeper. I started out on front-end stuff, working on Wolfram Mathematica and porting it over. Then I briefly moved to Bloomberg, then toward Uber and distributed systems, taking the Jump Bikes systems and moving them to a distributed system built on top of Cadence, the pre-Temporal Temporal.
Swyx [00:02:44]: Which, by the way, I’m happy to talk about, pros and cons.
Jake [00:02:48]: Totally.
Swyx [00:02:51]: But let’s do the Railway story.
Jake [00:02:52]: It has been a continual step of wanting an experience. Whether it’s walking up to a bike, unlocking it, and having it work frictionlessly, or something else, the depth required to make that happen follows from the experience. A lot of the work I do, and a lot of the team does, is in service of that experience. We fundamentally don’t care how deep we have to go. We will swim to the bottom of the swimming pool to get the experience.
Jake [00:03:17]: I don’t have a physics PhD. I did an EECS degree. It has always been about figuring out the next step: how do we get there? That’s what led to starting Railway for that experience and then moving all the way to bare metal data centers. I was adding patches to the kernel this week to get the experience there because I can see how much better it can be.
Swyx [00:03:49]: Other patches to the Linux kernel this week?
Jake [00:03:51]: Yeah. Not upstream. Our fork.
Swyx [00:03:52]: That’s a flex. Railpack? No, this is different. This is the OS on top of Railpack?
Jake [00:03:57]: No, this is an actual kernel patch. It’s always literally: what do we have to do to get that experience? Then figure it out. Anything is figureoutable.
Swyx [00:04:10]: Would you send the patch upstream, or does it not fit other use cases?
Jake [00:04:13]: Maybe. We have to work out the experience internally. It has to do with the storage layer we’re building for some of the agentic stuff. Maybe it’ll be useful upstream, but it’s deeply useful for us internally.
Open Source, Forks, and Non-Deterministic Versioning
Swyx [00:04:29]: You mentioned open source before. How do you think about starting from open source, and then coding agents letting you do a lot more from forks of it?
Jake [00:04:38]: GitHub’s original sin is that it’s almost a series of broken pointers. You have this thing, then you clone it, and now you’ve lost the whole upstream. How do we make it trivial for people to modify really small pieces of it?
Jake [00:04:51]: We think of Git in a discrete sense: I’ve either made a change and merged upstream, or I haven’t. What would it look like if it were percentage-based, a little more non-deterministic, or a stream of changes that users traverse as a percentage rolled out in general and then rolled all the way up?
Jake [00:05:13]: We have the open-source kickback program and let you deploy templates because we want to make it trivial for people to version these shards over time. It solves a large problem around authentication, authorization, and security. NPM has a way to define, “Don’t take any new packages.” The ideal end state is that you roll out progressively to users with the minimum impact zone and continue rolling up. JPMorgan should probably be the last one on the patch line, for all our sakes, because our money and livelihoods are there.
Jake [00:05:53]: It’s okay if Johnny Vibe Coder gets a broken patch because there’s so much entropy in the system that the rubber has to meet the road at some point. You have to test at varying levels.
The Long Grind: First Users, Free Tier, and Making the Business Work
Swyx [00:06:13]: I wanted to pull up this glorious chart, which is your usage or number of daily signups?
Jake [00:06:22]: Daily signups, I think.
Swyx [00:06:24]: You started six years ago. It was a slow grind, and now you’re on a rocket ship. You say, “Don’t doubt your fight and don’t quit.” Maybe pick out certain points that were key inflections for the company.
Jake [00:06:40]: At the start, it’s about getting your first 100 users, hell or high water. We had a website and a support link. The support link was the Discord channel. I had notifications on with two monitors: the monitor I was working on and the other monitor with Discord. If anybody came in, I was immediately like, “Hey, how’s it going?” It was rare, so getting those first 100 users to come back was the start.
Jake [00:07:14]: Then you build a consultancy factory because users want all these things. You have to go back to the board and ask, “What is the actual product offering I want to build on top of this?”
Jake [00:07:28]: VCs want charts that always go up and to the right, but in reality you don’t necessarily want charts that look like that. For us, there have been periods of expansion where we add features to test use cases, and periods of compaction where we ask, “If the experience we have is good, how do we make it significantly better?” Maybe we strip out features that don’t fit our ICP anymore.
Jake [00:07:57]: The boom from 2022 to 2023 came from the free tier. Everybody under the sun was using it.
Swyx [00:08:09]: A lot of Reddit bots and Discord bots.
Jake [00:08:12]: And crypto miners. When you build an open product on the internet where anybody can sign up, the internet is a horrible place with so many things. You go through periods of asking, “How do I reach as many people as possible?” Then, “How do I fit the exact use case for the people who really matter and are really excited about this specific thing?”
Jake [00:08:39]: Then there was a two-year period of making the actual business work. During the free-tier era, we were losing about half a million dollars a month.
Swyx [00:08:59]: On a $20 million bank account.
Jake [00:09:02]: On a $20 million bank account with maybe $50,000 a month in revenue. That’s a horrible business. I don’t know how anybody invested. But you have to go through it and say, “We have an experience people love, but the business has to work.”
Jake [00:09:17]: There are two schools of thought. You can run the horrible business all the way up with bad margins, or you can go back and make it work. We’ve always wanted a super lean team. We’re 35 people right now. It’s very small.
Swyx [00:09:36]: Supporting three million already?
Jake [00:09:38]: Yeah. We’re adding 100,000 users a week right now, so it’s growing fast. We don’t want to add headcount for the sake of headcount or throw bodies at problems. We want to build systems. It’s hard to build systems during expansion because you’re adding things to the system because people are asking for them or things are breaking.
Jake [00:10:00]: We had to cut off the free users for a little while, rebuild the business, and make sure it worked. We want to reach as many people as possible because software is important. It’s become difficult to create things in the physical world, so it’s important to make it easy for people to build in the virtual world and have access to creation. But there are legs to that journey.
Jake [00:10:30]: You can see divots in the charts. If you follow between 2025 and 2026, it’s either summer or winter. People go on holiday with family.
Swyx [00:10:50]: It affects that much?
Jake [00:10:51]: Yeah. It’s kind of B2C and kind of B2B. People are shipping constantly, then they stop. Our activation curve now shows more people activating on weekdays because we have more business users, so it smooths out over time.
Agents as the New Interface to Deployment
Swyx [00:11:17]: Was there a point where you started prioritizing AI development or agent development?
Jake [00:11:24]: We’ve prioritized agentic as a top-of-funnel thing. Over the last six months, we’ve deeply prioritized agentic as a mechanism to build and deploy things because we believe the curve is so steep and that is how people will build and deploy software.
Jake [00:11:42]: It almost fundamentally doesn’t matter whether this is dot-com or not because we’re all on the internet anyway. If agents are going to deploy a bunch of things and we hit an inference wall at some point, we’ll fix those problems. The dominant species over the next 10 years is that we’ve moved from assembly to C to C++ to JavaScript to words. You’re going to need to close that loop.
Swyx [00:12:13]: When you say this is dot-com, did you mean buying the domain, or the general case?
Jake [00:12:17]: I mean the dot-com era, when companies had a huge run-up because people understood the internet was important. Then they hit bottlenecks, fundamental laws of physics, math didn’t work, and everybody came back down to earth. But it didn’t matter because the internet became so impactful. If you operate on a long enough time horizon, you should build these things anyway because you can see where it’s going.
Jake [00:12:45]: That’s where I think a lot of agent stuff is. You get to a point where you’re running thousands of agents in parallel. What is the inference cost? What is the compute cost? How do you make that efficient? How do you coordinate all this? We have issues coordinating humans; we don’t even have good tooling for that. Now we have to figure out how to get agents to coordinate, safely version changes, and know when to raise their hand for someone to intervene. Otherwise it becomes an interrupt factory.
Railway’s Infrastructure Thesis: Network, Compute, Storage, and Metal
Swyx [00:13:19]: Let’s go right into the technical side. What are the core infrastructure or architectural beliefs of Railway that allow you to do what you do?
Jake [00:13:29]: The primitives matter a lot for us. We need network, compute, storage, and orchestration around it. You need control over a lot of those things. We’ve talked a lot about how we don’t really use Kubernetes because we want higher-order control to place workloads in very specific places.
Jake [00:13:48]: The reason is that you have to be very efficient with agents: memory reuse and all these other things, or you’re going to massively blow up your cost structure. Being able to rack and stack your own servers and build your own metal unlocks performance and cost. Experiences where you’re running 1,000 agents in parallel are not massively cost prohibitive.
Jake [00:14:13]: Token use and compute use are blowing up. Over time, those things have to get a lot more efficient. You can get a lot of margin to make those experiences solid by building your own metal. That’s all in service of offering a differentiated experience to as many people as humanly possible.
Swyx [00:14:51]: You have a data center in Singapore.
Jake [00:14:53]: Yeah. We have two in every other region now. In Singapore, we’re adding a second one in Q3.
Swyx [00:14:58]: What’s it like? I’ve never built a data center. Do you go to Equinix and say, “I want some slots?”
Jake [00:15:05]: Yeah. Equinix. You basically go and say, “I want power and I want a cage.” They say, “Great, here’s what it’s going to be.” You rent the cage for a period of time, fill it with racks and servers, and hook up internet to it. That’s all the pieces.
Swyx [00:15:36]: Then you handle everything else.
Jake [00:15:37]: You handle everything else.
Swyx [00:15:39]: What’s the math versus clouds doing it for you?
Jake [00:15:43]: If we rented in the cloud, our payback period when we go to metal is about three months.
Swyx [00:15:50]: Which is crazy.
Jake [00:15:51]: It’s nuts. That’s four years of depreciated hardware. You’re going to see a lot of this compute crunch because hyperscalers are buying up a lot of stuff. We’re working directly with OEMs, resellers, and people building these machines: Supermicro, Dell, and others.
Jake [00:16:11]: Upstream, there’s a bunch of supply pressure. When we raised our last round, between deploying capital for servers and now, the amount of money we’ve raised is less than the amount of money we have in the bank plus the value of the servers because the servers have appreciated as RAM has gone up. It’s nuts how valuable hardware has become.
Jake [00:16:50]: If you look at hyperscalers, they deployed around $80 billion of capital expenditures this year, and next year will be more. That’s a massive infrastructure build-out.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み