先週のAIニュース #335 - Opus 4.6、Codex 5.3、Gemini 3 Deep Think、GLM 5、Seedance 2.0
AI週報の最新号では、Opus 4.6、Codex 5.3、Gemini 3 Deep Think、GLM 5、Seedance 2.0など、主要AIモデルのアップデートが多数報告されました。
キーポイント
AnthropicがClaude Opus 4.6をリリースし、複数エージェントが協調する「agent teams」機能を研究プレビューとして導入
OpenAIがGPT-5.3-Codexを発表し、コード生成だけでなく自己構築を含むより広範な開発支援を目指す
主要AI企業がモデルの高速な反復更新と実務統合(例:PowerPoint連携、macOSアプリ)を加速
AIモデルの進化が「vibe coding」から「vibe working」へと拡大し、より広範な知識労働者向けツールへ発展
影響分析・編集コメントを表示
影響分析
この記事は、主要AI企業がモデルの性能向上だけでなく、実務への統合と協調的・自律的な作業支援に焦点を移していることを示している。特に「agent teams」や自己構築機能は、AIの役割を単なるツールから能動的な協働者へと進化させる可能性があり、生産性と業務プロセスの変革につながる。
編集コメント
複数エージェントの協調やモデルの自己構築機能は、AIの自律性と実務統合が次の焦点となっていることを示唆。バージョン更新の速さも業界の激しい競争を反映。
Last Week in AI #335 - Opus 4.6、Codex 5.3、Gemini 3 Deep Think、GLM 5、Seedance 2.0
AI界の前週を振り返る、超盛りだくさんの第335号です!さらにいくつかの小さなアップデートも。
 Last Week in AI2026年2月16日4135シェア編集者注:ここ数ヶ月、ニュースレターとポッドキャストの公開日が不安定だったことをお詫びします。今後は、土曜日/日曜日に定期的に公開することを目指します!その結果、今回のニュースレターは1週間強の内容をカバーしています。
Last Week in AI2026年2月16日4135シェア編集者注:ここ数ヶ月、ニュースレターとポッドキャストの公開日が不安定だったことをお詫びします。今後は、土曜日/日曜日に定期的に公開することを目指します!その結果、今回のニュースレターは1週間強の内容をカバーしています。
また、主要ニュースには『編集者の見解』を追加し、ニュース要約を超えたコメントと追加の文脈を提供していきます。
Anthropic、新機能「エージェントチーム」を備えたOpus 4.6をリリース
AnthropicがClaude Opus 4.6をローンチ、AIは「雰囲気で働く」時代へ
要約:Anthropicは、より大規模で高速、かつ協調的な作業に焦点を当てた大幅なアップグレード版、Claude Opus 4.6をリリースしました。目玉機能は「エージェントチーム」です。これは研究プレビュー機能で、複数の連携したエージェントが複雑なタスクを並列サブタスクに分割し、直接コミュニケーションを取り、単一の逐次処理エージェントよりも速く完了させることができます。Opus 4.6はまた、コンテキストウィンドウを100万トークン(Sonnet 4/4.5と同等)に拡大し、大規模なコードベースや長文ドキュメントを扱えるようにしました。もう一つの重要な追加機能は、ネイティブのPowerPointサイドパネルで、ユーザーは外部でデッキを生成してインポートするのではなく、PowerPoint内で直接Claudeを使ってスライドの下書きや編集ができます。
Anthropicは、Opusがコーディング優先モデルから、より幅広い知識労働者に適したモデルへと進化したと述べ、ソフトウェアエンジニアを超えてプロダクトマネージャーや金融アナリストにも採用が広がっていることを挙げています。Claude Codeと生産性スイートClaude Coworkの進歩は、「雰囲気コーディング」から「雰囲気ワーキング」への移行を促しており、エンドツーエンドのタスク実行とより高品質な専門的アウトプットを反映しています。
編集者の見解:Opus 4.6は4.5のわずか数ヶ月後に登場しましたが、バージョン番号の0.1上げが示唆する以上の、様々なベンチマークでの印象的な向上を示しています。最先端の研究所はRLによるモデルの継続的な事後学習の段階に到達したように感じられ、わずか数ヶ月でさらに印象的な向上が見られても驚きません。
GPT-5.3-Codexで、OpenAIはコード記述以上の用途をCodexに提案
OpenAI、新しいコーディングモデルは「自身の構築に貢献した」と発表
OpenAIの新しいSparkモデル、GPT-5.3-Codexより15倍高速でコード生成 - ただし条件付き
OpenAIのCodex新バージョンは新型専用チップで駆動
OpenAI、エージェント型コーディング向け新macOSアプリをローンチ
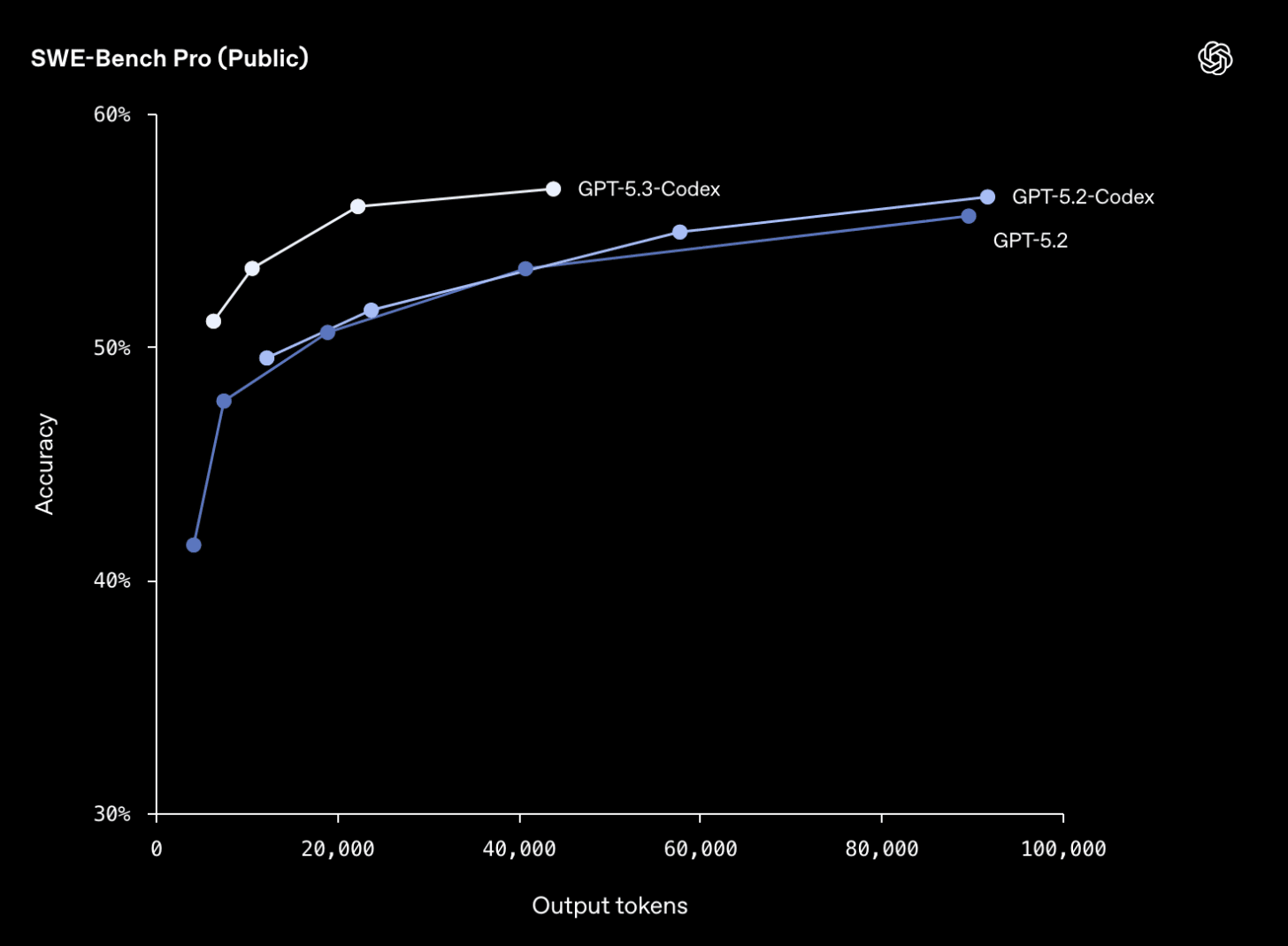 要約:OpenAIは、CLI、IDE拡張機能、Web、そして新しいmacOS Codexアプリ(APIは後日)を通じて利用可能な最先端コーディングモデル、GPT-5.3-Codexを発表しました。このモデルは、SWE-Bench ProとTerminal-Bench 2.0においてGPT-5.2-CodexおよびGPT-5.2を上回り、25%高速で、計算使用量も低減されています。見出しでは「自身を構築した」と報じられていますが、OpenAIは明確化しており、初期バージョンがトレーニングのデバッグ、デプロイメント管理、テスト結果分析、データセットのクレンジング、トレーニング実行の監視に「使用された」のであり、完全な自己構築ではないとしています。このモデルは、コード生成を超えたソフトウェアライフサイクル全体、すなわちデバッグ、デプロイ、監視、PRD作成、コピー編集、ユーザーリサーチ、テスト、メトリクス作成に向けて提案されています。OpenAIはまた、GPT-5.3-Codexを、そのPreparedness Frameworkに基づき、サイバーセキュリティ向け初の「高能力」モデルに指定しました。
要約:OpenAIは、CLI、IDE拡張機能、Web、そして新しいmacOS Codexアプリ(APIは後日)を通じて利用可能な最先端コーディングモデル、GPT-5.3-Codexを発表しました。このモデルは、SWE-Bench ProとTerminal-Bench 2.0においてGPT-5.2-CodexおよびGPT-5.2を上回り、25%高速で、計算使用量も低減されています。見出しでは「自身を構築した」と報じられていますが、OpenAIは明確化しており、初期バージョンがトレーニングのデバッグ、デプロイメント管理、テスト結果分析、データセットのクレンジング、トレーニング実行の監視に「使用された」のであり、完全な自己構築ではないとしています。このモデルは、コード生成を超えたソフトウェアライフサイクル全体、すなわちデバッグ、デプロイ、監視、PRD作成、コピー編集、ユーザーリサーチ、テスト、メトリクス作成に向けて提案されています。OpenAIはまた、GPT-5.3-Codexを、そのPreparedness Frameworkに基づき、サイバーセキュリティ向け初の「高能力」モデルに指定しました。
関連リリースであるGPT-5.3-Codex-Sparkは、リアルタイムの「会話型」コーディングを対象としており、より小型でレイテンシ優先の研究プレビュー版で、GPT-5.3-Codexより最大15倍高速にコードを生成しますが、SWE-Bench ProとTerminal-Bench 2.0では後れを取っており、「高能力」サイバーセキュリティの閾値は満たさないと見込まれています。Sparkは、セッションとストリーミングの最適化、持続的WebSocket接続により、大きなレイテンシ向上(ラウンドトリップオーバーヘッド約80%低減、初トークンまでの時間50%高速化、トークンあたりオーバーヘッド30%低減)を達成し、自動テスト実行なしの軽量で対象を絞った編集をデフォルトとしています。当初は月額200ドルのProユーザーに限定されており、SparkはOpenAIとCerebrasの複数年にわたる100億ドル超のパートナーシップにおける最初のマイルストーンで、WSE-3ウェハースケールチップ(4兆トランジスタ)上で推論を実行します。
モデルを補完するものとして、OpenAIの新しいmacOS Codexアプリは、複数のエージェント型コーディングアシスタントを並列に調整し、スケジュールされた自動化と選択可能なエージェント「性格」をサポートし、50万回以上のダウンロードを記録しています。OpenAIは、長期的な推論/実行とリアルタイム協調の二つのモード、および長いタスクのためのバックグラウンドサブエージェントを目指しています。
編集者の見解:OpenAIは、以前はあらゆる人々のための汎用チャットボットとしてのChatGPTの改善に注力していた後、職場の生産性向上に最適化されたモデルを持つという点で、Anthropicにうまく追いついたようです。非常に大きな出来事です!
Google、科学・工学向けGemini 3 Deep Thinkを公開
これはAGIか?GoogleのGemini 3 Deep Think、人類最後の試験を粉砕しARC-AGI-2で84.6%を達成
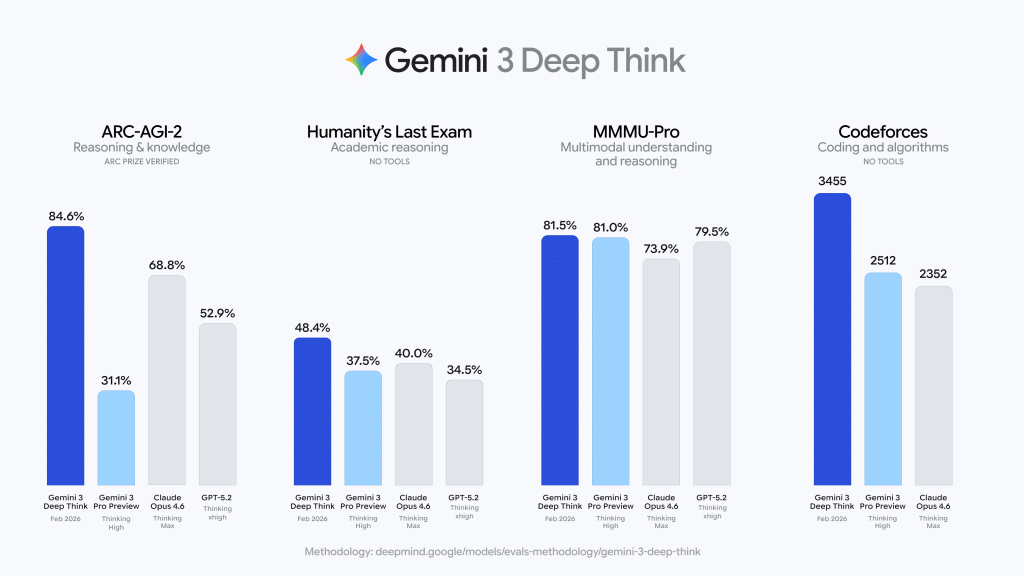 要約:Googleは、科学、研究、工学向けに調整された、精度と多段階の論理がレイテンシよりも重要となる分野のための「拡張推論」モード、Gemini 3 Deep Thinkの大幅アップグレードを発表しました。このシステムは、テスト時間計算(モデルに長く考えさせること)と、誤った推論経路を刈り込むための内部検証を重視しており、OpenAIのo1やAnthropicのClaudeなどの競合に対する直接的な対応です。Googleは、暗記ではなく新奇なタスクへの一般化のために設計されたベンチマークであるARC Prize FoundationのARC-AGI-2で検証済み84.6%、論理が密集した学術問題からなるHumanity's Last Examでツールなし48.4%を報告しています。Deep Thinkはまた、2025年国際物理・化学オリンピアードの筆記部門で金メダルレベル、2025年IMOで金レベル、さらに高度な理論物理学のCMT-Benchmarkで50.5%の性能を主張しています。
要約:Googleは、科学、研究、工学向けに調整された、精度と多段階の論理がレイテンシよりも重要となる分野のための「拡張推論」モード、Gemini 3 Deep Thinkの大幅アップグレードを発表しました。このシステムは、テスト時間計算(モデルに長く考えさせること)と、誤った推論経路を刈り込むための内部検証を重視しており、OpenAIのo1やAnthropicのClaudeなどの競合に対する直接的な対応です。Googleは、暗記ではなく新奇なタスクへの一般化のために設計されたベンチマークであるARC Prize FoundationのARC-AGI-2で検証済み84.6%、論理が密集した学術問題からなるHumanity's Last Examでツールなし48.4%を報告しています。Deep Thinkはまた、2025年国際物理・化学オリンピアードの筆記部門で金メダルレベル、2025年IMOで金レベル、さらに高度な理論物理学のCMT-Benchmarkで50.5%の性能を主張しています。
工学とコーディングに関しては、Gemini 3 Deep Thinkは現在、Codeforcesで3455のElo(「レジェンダリーグランドマスター」領域)を記録し、複雑なデータ構造、アルゴリズム最適化、システム設計における能力を示しており、Googleはソフトウェアエンジニアリングタスクで以前のバージョンより35%精度が向上したと述べています。
編集者の見解:印象的なモデルリリースを締めくくるこの発表は、おそらく最も印象的なものかもしれません。大きな進歩には慣れてきたとしても、ARC-AGI-2の結果は私や他の多くの論評者を驚かせました。Opus 4.6と同様に、これほどの急速で大きな向上の背景に、RL/事後学習のスケールアップがあるのではないかと考えさせられます。
DeepSeek、トークンを10倍追加してAIモデルを強化、一方Zhipu AIはGLM-5を発表
Zhipu、中国AI株の上昇を牽引、新リリースの波で市場に30%急騰
MiniMax M2.5、「計測するには安すぎる知能」を約束、中国研究所が欧米AI価格を圧迫
中国Zhipu AI、新主力モデルGLM-5をリリースし競合に挑戦
Z AI、GLM-5をローンチ、チャットとAPIで新しいオープンソースモデルを提供
 ソース
ソース
要約:中国のAI研究所は、長いコンテキスト、コーディング、エージェント型ワークフローに焦点を当てた主要アップグレードを一斉に展開しました。DeepSeekは、その主力モデ
原文を表示
Last Week in AI #335 - Opus 4.6, Codex 5.3, Gemini 3 Deep Think, GLM 5, Seedance 2.0
A crazy packed edition of Last Week in AI! Plus some small updates.
Last Week in AIFeb 16, 20264135ShareEditor’s note: I apologize for the inconsistent release date of the newsletter and podcasts in recent months. I’ll aim to start releasing on Saturday/Sunday consistently from now on! This edition of the newsletter covers a bit more than a week as a result.
I am also going to be adding an ‘Editor’s Take’ for Top News to add a bit commentary and extra context beyond the news summary.
Anthropic releases Opus 4.6 with new ‘agent teams’
Anthropic launches Claude Opus 4.6 as AI moves toward a ‘vibe working’ era
Summary: Anthropic released Claude Opus 4.6, a major upgrade focused on larger, faster, and more collaborative work. The headline feature is “agent teams,” a research-preview capability that lets multiple coordinated agents split a complex task into parallel subtasks, communicate directly, and finish faster than a single sequential agent. Opus 4.6 also expands the context window to 1 million tokens (on par with Sonnet 4/4.5), enabling work over large codebases and long documents. Another key addition is a native PowerPoint side panel, letting users draft and edit slides directly inside PowerPoint with Claude instead of generating decks externally and importing them.
Anthropic says Opus has evolved from a coding-first model to one suited for a broader set of knowledge workers, citing adoption beyond software engineers to product managers and financial analysts. Advancements in Claude Code and the productivity suite Claude Cowork are feeding a shift from “vibe coding” to “vibe working,” reflecting end-to-end task execution and higher-quality professional outputs.
Editor’s Take: Opus 4.6 comes only a few months after 4.5, and yet showcases impressive gains across a variety of benchmarks beyond what the 0.1 version bump might suggest. It feels like the frontier labs may have gotten to the point of continously post-training their models via RL, and I wouldn’t be surprised if we see more impressive gains in just a few months.
With GPT-5.3-Codex, OpenAI pitches Codex for more than just writing code
OpenAI says new coding model helped build itself
OpenAI’s new Spark model codes 15x faster than GPT-5.3-Codex - but there’s a catch
A new version of OpenAI’s Codex is powered by a new dedicated chip
OpenAI launches new macOS app for agentic coding
Summary: OpenAI unveiled GPT-5.3-Codex, a frontier coding model available via CLI, IDE extension, web, and a new macOS Codex app (API coming later). The model outperforms GPT-5.2-Codex and GPT-5.2 on SWE-Bench Pro and Terminal-Bench 2.0, and runs 25% faster with lower compute usage. While headlines claim it “built itself,” OpenAI clarifies the model was “instrumental in creating itself,” with early versions used to debug training, manage deployments, analyze test results, clean datasets, and monitor training runs—not fully self-building. The model is pitched for the full software lifecycle beyond code generation: debugging, deploying, monitoring, writing PRDs, editing copy, user research, tests, and metrics. OpenAI also designated GPT-5.3-Codex as its first “high-capability” model for cybersecurity per its Preparedness Framework.
A companion release, GPT-5.3-Codex-Spark, targets real-time “conversational” coding with a smaller, latency-first research preview that generates code up to 15x faster than GPT-5.3-Codex but trails it on SWE-Bench Pro and Terminal-Bench 2.0, and is not expected to meet the “high-capability” cybersecurity threshold. Spark achieves big latency gains—roughly 80% lower round-trip overhead, 50% faster time-to-first-token, and 30% lower per-token overhead—via session and streaming optimizations and persistent WebSocket connections, and it defaults to lightweight, targeted edits without auto-running tests. Initially limited to $200/month Pro users, Spark is the first milestone in OpenAI’s multi-year, >$10B partnership with Cerebras, running inference on the WSE-3 waferscale chip (4 trillion transistors).
Complementing the models, OpenAI’s new macOS Codex app orchestrates multiple agentic coding assistants in parallel, supports scheduled automations and selectable agent “personalities,” and has seen 500,000+ downloads, with OpenAI aiming toward dual modes: long-horizon reasoning/execution alongside real-time collaboration, and background sub-agents for longer tasks.
Editor’s Take: OpenAI seems to have succesfully caught up with Anthropic in terms of having a model that is optimized for improving workplace productivity, after having previously focused more on improving ChatGPT as a general purpose chatbot for anybody and everybody. Pretty big deal!
Google Unveils Gemini 3 Deep Think for Science & Engineering
Is This AGI? Google’s Gemini 3 Deep Think Shatters Humanity’s Last Exam And Hits 84.6% On ARC-AGI-2 Performance Today
Summary: Google unveiled a major upgrade to Gemini 3 Deep Think, a specialized “extended reasoning” mode tuned for science, research, and engineering where accuracy and multi-step logic matter more than latency. The system emphasizes test-time compute—letting the model think longer—and internal verification to prune incorrect reasoning paths, a direct response to competitors like OpenAI’s o1 and Anthropic’s Claude. Google reports a verified 84.6% on ARC-AGI-2 from the ARC Prize Foundation, a benchmark designed for generalization to novel tasks rather than memorization, and 48.4% on Humanity’s Last Exam without tools across logic-dense academic questions. Deep Think also claims gold medal–level performance on the written sections of the 2025 International Physics and Chemistry Olympiads and gold-level on the 2025 IMO, plus 50.5% on the CMT-Benchmark for advanced theoretical physics.
For engineering and coding, Gemini 3 Deep Think now posts a 3455 Elo on Codeforces—“Legendary Grandmaster” territory—demonstrating capability in complex data structures, algorithmic optimization, and system design, with Google noting a 35% accuracy lift in software engineering tasks over prior versions.
Editor’s Take: rounding off the impressive model releases, this one may just be the most impressive of all. Even having gotten used to major advancements, the ARC-AGI-2 result surprised me and many other commentators. Similar to Opus 4.6, this makes me wonder if scaling up RL / post-training is behind such rapid and signifiacnt improvements.
DeepSeek boosts AI model with 10-fold token addition as Zhipu AI unveils GLM-5
Zhipu leads rally in Chinese AI stocks, surging 30% as a wave of new releases hits market
MiniMax M2.5 promises “intelligence too cheap to meter” as Chinese labs squeeze Western AI pricing
China’s Zhipu AI launches new major model GLM-5 in challenge to its rivals
Z AI launched GLM-5, new open-source model on chat and APIs
Source
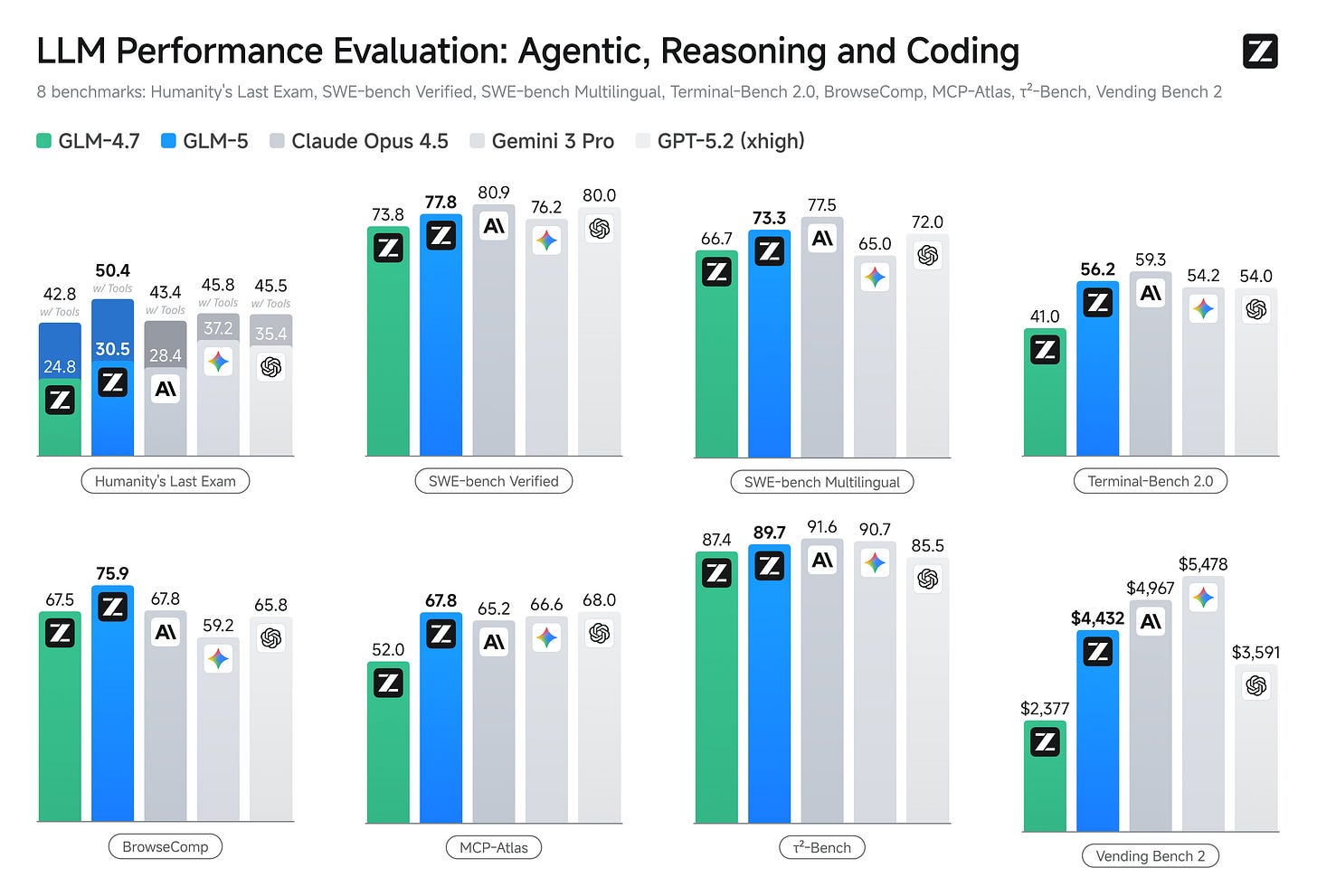
Summary: China’s AI labs rolled out major upgrades focused on long context, coding, and agentic workflows. DeepSeek expanded its flagship model’s context window from 128,000 to over 1,000,000 tokens, enabling much larger “memory” for complex reasoning, multi-file code work, and sustained tasks. Zhipu AI (Z.ai) launched GLM-5, an open-weight flagship positioned for “agentic engineering” rather than “vibe coding,” emphasizing end-to-end software delivery, deep debugging, and multi-step tool use. GLM-5 scales to a Mixture-of-Experts architecture with roughly 744B total parameters and 40B active per token, increases pretraining to 28.5T tokens, and integrates DeepSeek Sparse Attention to balance long-context performance with serving efficiency.
Benchmarks and pricing underscore intensifying competition. Zhipu reports GLM-5 leads among open models on coding and agentic tasks, with self-reported scores like 77.8 on SWE-bench Verified and strong showings on BrowseComp and MCP-Atlas; it ranks #1 among open models in Text Arena and aims to approach Claude Opus 4.5, though it still lags Anthropic’s Claude on coding by Zhipu’s own admission. MiniMax released M2.5 under MIT as open weights, trained with reinforcement learning across hundreds of thousands of complex environments to optimize autonomous planning and long-horizon efficiency.
Editor’s Take: Starting with DeepSeek V3/R1, it has felt like the open source models coming out of China are getting increasingly close to matching the performance of the flagship models of western frontier labs. These releases continue that trend, which makes me wonder if open source options will soon start eating away at the profits of closed source API providers.
Bytedance shows impressive progress in AI video with Seedance 2.0
ByteDance’s new model sparks stock rally as China’s AI video battle escalates
ByteDance’s new Seedance 2.0 supposedly ‘surpasses Sora 2′
ByteDance’s Seedance 2.0 Might be the Best AI Video Generator Yet
ByteDance’s new model sparks stock rally as China’s AI video battle escalates
Hollywood isn’t happy about the new Seedance 2.0 video generator
Summary: ByteDance pre-released Seedance 2.0 to select users, showcasing a multimodal video generator that accepts up to 12 inputs at once (max: nine images, three videos, three audio files) alongside text, and outputs 4–15s clips with auto-generated sound effects/music. The headline upgrade is precise reference capability: users can lift camera motion, editing grammar, effects, and action beats from uploaded reference videos, swap/insert characters, extend existing shots, and chain multi-scene storylines while maintaining style and character consistency. Early testers report sharper 2K exports, roughly 30% faster generation vs Seedance 1.5, smoother camera moves, improved visual consistency, and convincing motion accuracy and lip-sync, with results that are watermark-free.
The launch intensified China’s AI video race days after Kuaishou’s Kling 3.0 and sparked a stock rally: COL Group hit its 20% limit, Shanghai Film and Perfect World rose ~10%, and Huace Media ~7%, while the CSI 300 ticked up 1.63%. Swiss consultancy CTOL and other reviewers claim Seedance 2.0 surpasses OpenAI’s Sora 2 and Google’s Veo 3.1 in practical tests, citing lifelike characters, fine-grained edit control, and “cinematic” natural-language workflows—though cherry-picked demos likely show best-case output.
Meanwhile, Hollywood and rights groups blasted the tool’s lack of guardrails after viral clips mimicked celebrities (e.g., Tom Cruise vs. Brad Pitt) and Disney/Paramount IP; Disney and Paramount sent cease-and-desist letters alleging indistinguishable reproductions of franchises like Spider-Man, Darth Vader, and Grogu.
Editor’s Take: this feels like a Nano-Banana moment for video generation — (I created that em-dash, not AI) a huge and sudden leap far beyond what existing text-to-video models can do. The ability to edit/compose inputs so well vastly increases the usefulness of this model, and I wouldn’t be surprised if we start seeing a lot more primarily AI-generated videos within a year.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み