Qwen-Scope:知能の解読と可能性の開拓(9 分間読み)
Qwen-Scope は Qwen3 および Qwen3.5 シリーズの内部メカニズムを解明し、制御可能な推論やモデル最適化を可能にする解釈可能性ツールキットである。
キーポイント
Qwen-Scope の本質と目的
Qwen3 および Qwen3.5 シリーズ用に特別にトレーニングされた解釈可能性(Interpretability)ツールキットであり、モデルの内部動作メカニズムを可視化する。
制御可能な推論の実現
内部状態を理解することで、出力を細かく制御できる「controllable inference」が可能となり、特定のタスクやスタイルへの最適化が容易になる。
データ処理とモデル開発の支援
データの分類・合成、トレーニングプロセスの最適化、および評価用サンプル分布の分析を通じて、モデル開発ライフサイクル全体を支援する機能を持つ。
影響分析・編集コメントを表示
影響分析
このツールキットは、大規模言語モデルの「ブラックボックス」問題を解決し、より透明性のある AI 開発を促進する可能性があります。特に Qwen シリーズの高度な機能を最大限に引き出し、制御可能な推論を実現することで、実務におけるモデルの信頼性と効率性を高める役割を果たすと期待されます。
編集コメント
モデルの内部挙動を可視化するツールは、信頼性のある AI 構築に不可欠ですが、今回の発表は Qwen シリーズ特有の機能強化に焦点が当たっており、汎用性の高い新技術というよりはエコシステム深化の文脈で捉えるべきです。
 imageHUGGING FACEMODELSCOPETECHNICAL REPORT
imageHUGGING FACEMODELSCOPETECHNICAL REPORT
解釈可能性研究は、大規模言語モデル(LLM)の振る舞いを理解し、パフォーマンス最適化に役立ち、より制御可能なモデル出力を実現するための重要な分野として台頭しています。本日、私たちは Qwen3 および Qwen3.5 シリーズモデルを基盤とした解釈可能性ツールキット「Qwen-Scope」をご紹介できることを嬉しく思います。具体的には、Qwen の隠れ層(hidden layers)内にスパース自己符号化器(Sparse Autoencoders: SAEs)を挿入し訓練を行いました。スパース性制約を課すことで、SAEs はモデルの密な隠れ表現を、スパースで分離可能かつ解釈可能な特徴量に分解します。Qwen-Scope は Qwen の振る舞いの背後にある内部メカニズムを明らかにするだけでなく、モデル最適化の可能性も秘めています。応用シナリオには、制御可能な推論、データ分類および合成、モデル訓練および最適化、評価サンプル分布分析などが含まれます。
- Qwen-Scope の主な特徴:推論(Inference):明示的な自然言語指示を必要とせず、推論結果に対するターゲット制御を可能にします。
- データ:データ分類のための特徴量収集には少量のシードデータのみで十分であり、データ依存性を大幅に削減します。さらに、非アクティブな特徴情報を利用してターゲットデータを構築することで、ロングテール能力を強化できます。
- 学習(Training):コードスイッチングや反復生成といった低品質な問題を分析し、異常に活性化された特徴量を特定します。これにより、教師あり微調整(SFT)および強化学習(RL)段階におけるモデルトレーニングが支援され、望ましくない応答の頻度を効果的に削減できます。
- 評価(Evaluation):異なるサンプルやベンチマークデータセット全体での特徴量活性化パターンを計算し、評価の冗長性を共同で評価します。これにより、ベンチマークの選択が導かれ、評価対象となる能力のカバレッジが向上し、評価コストが削減されます。
見落としがちな点
この Qwen-Scope オープンソースプロジェクトで公開された重みは、7 つの大規模言語モデル(LLM)を対象としており、Qwen3 および Qwen3.5 シリーズの密集型モデルと MoE モデルの両方を網羅し、合計 14 セットの SAE を含んでいます。
広範な特徴カバレッジ、強力な意味的有意性、安定したトレーニングを確保するため、対応するモデルの事前学習データから 0.5B トークンをサンプリングして SAE の訓練を行いました。
名前バックボーンタイプSAE 幅展開係数L0
密集型
SAE-Res-Qwen3-1.7B-Base-W32K-L0_50base32K1650
SAE-Res-Qwen3-1.7B-Base-W32K-L0_100base32K16100
SAE-Res-Qwen3-8B-Base-W64K-L0_50base64K1650
SAE-Res-Qwen3-8B-Base-W64K-L0_100base64K16100
SAE-Res-Qwen3.5-2B-Base-W32K-L0_50base32K1650
SAE-Res-Qwen3.5-2B-Base-W32K-L0_100base32K16100
SAE-Res-Qwen3.5-9B-Base-W64K-L0_50base64K1650
SAE-Res-Qwen3.5-9B-Base-W64K-L0_100base64K16100
SAE-Res-Qwen3.5-27B-W80K-L0_50instruct80K1650
SAE-Res-Qwen3.5-27B-W80K-L0_100instruct80K16100
MoE(Mixture of Experts:専門家混合モデル)
SAE-Res-Qwen3-30B-A3B-Base-W32K-L0_50base32K1650
SAE-Res-Qwen3-30B-A3B-Base-W128K-L0_100base128K64100
SAE-Res-Qwen3.5-35B-A3B-Base-W32K-L0_50base32K1650
SAE-Res-Qwen3.5-35B-A3B-Base-W128K-L0_100base128K64100
アプリケーション
Qwen-Scope は、Qwen シリーズモデルの分析と開発を支援します。このセクションでは、推論(inference)、評価(evaluation)、データ(data)、トレーニング(training)の 4 つの次元におけるその有用性を紹介します。詳細については、技術レポート をご参照ください。
推論:モデル挙動と制御可能な出力の分析
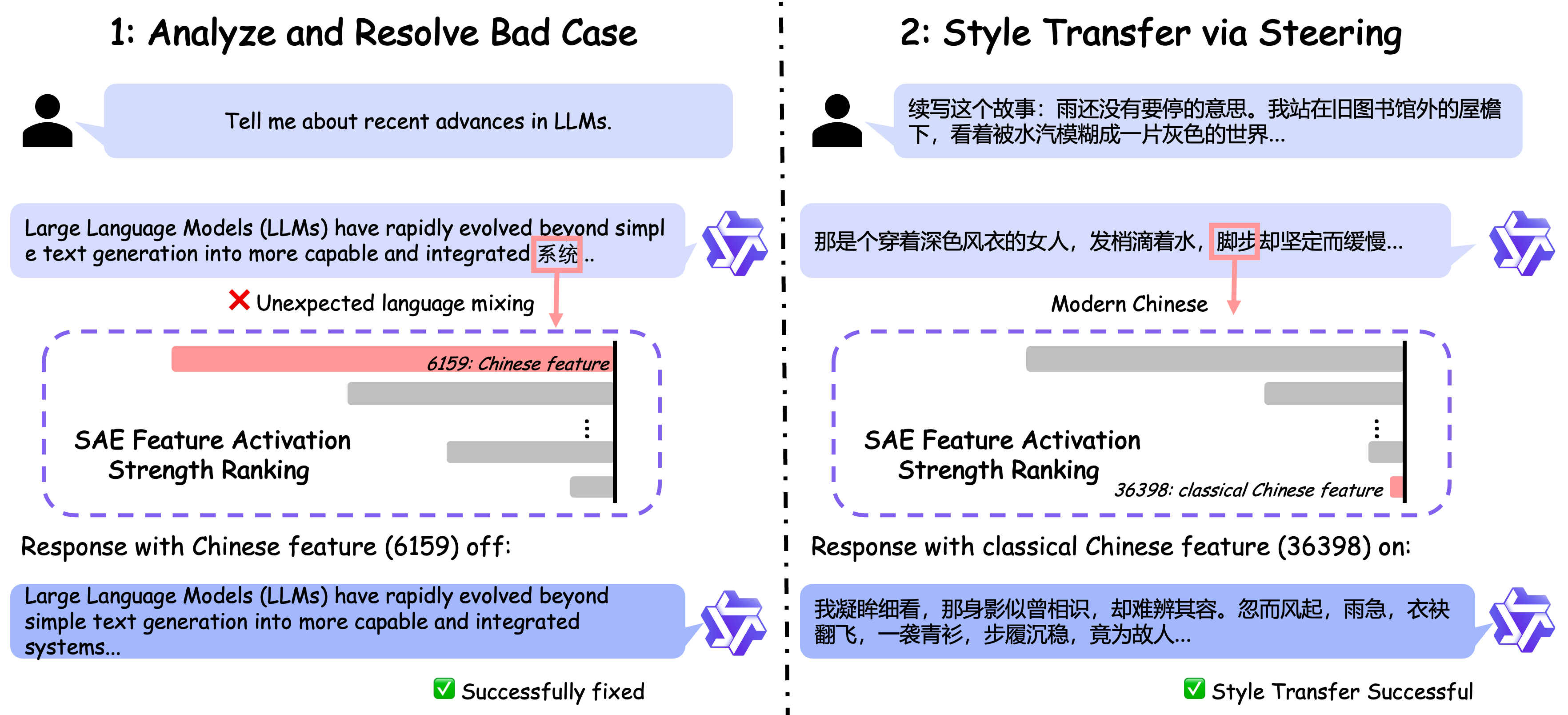
特徴の活性化を制御することで、明示的な自然言語指示を提供することなく、言語、エンティティ、またはスタイルにおける指向性のある変更など、推論結果に対するターゲット型の制御を実現できます。
データ:分類と合成
Qwen-Scope はモデル表現に対する多次元の分析および要約を実行し、データ処理戦略に関する洞察を提供するデータラベリングおよび分類ツールとして利用可能となります。これにより、データの特性を特徴づけることが可能です。
例えば、毒性のあるテキストの場合、すべての機能における活性化状態に基づいて、サンプル分類のためにシードデータを用いて非常に関連性の高い特徴を選択できます。このプロセスには追加のトレーニング手順は不要であり、注釈付けに要する時間を大幅に節約します。さらに、少量のデータのみで高い分類精度を達成できるため、大量のブーストラップデータへの依存を著しく低減できます。
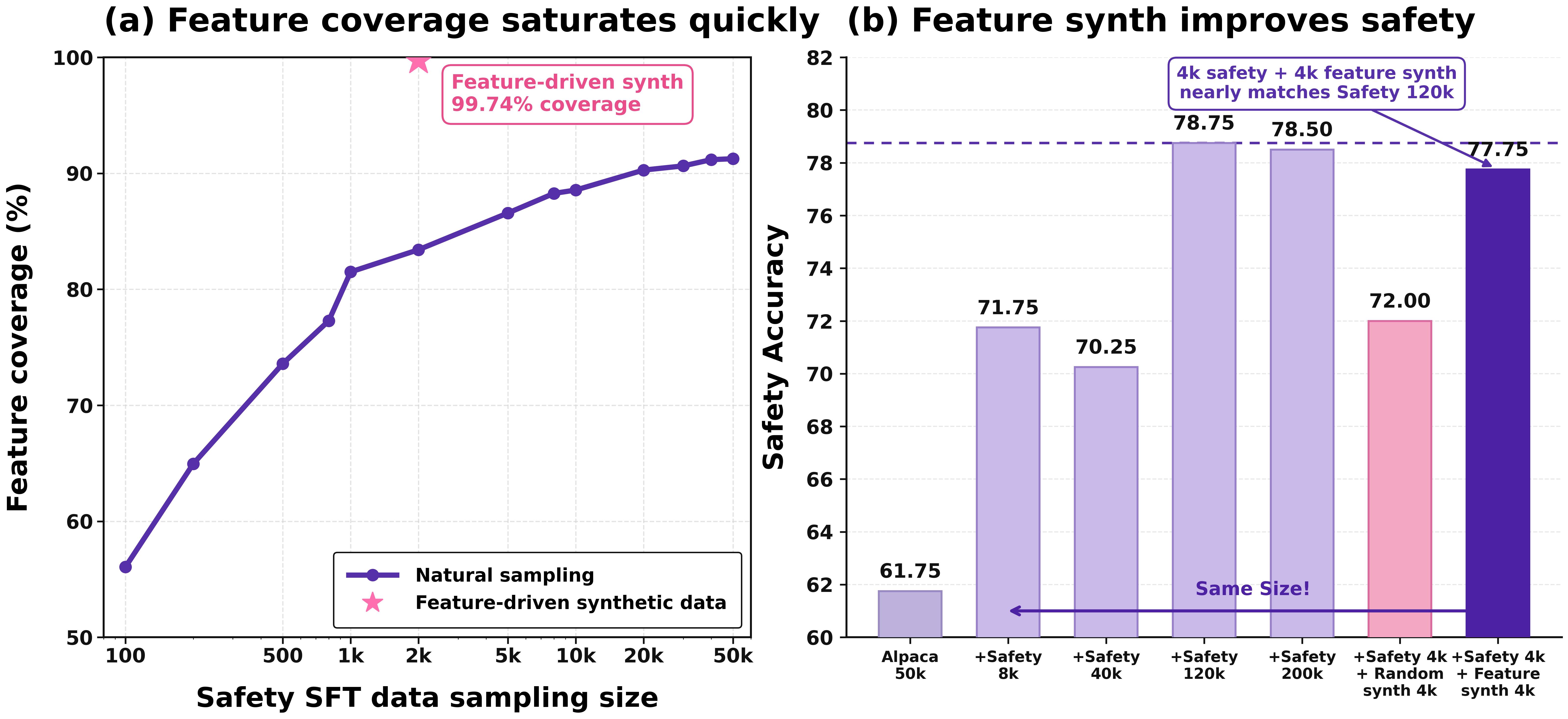
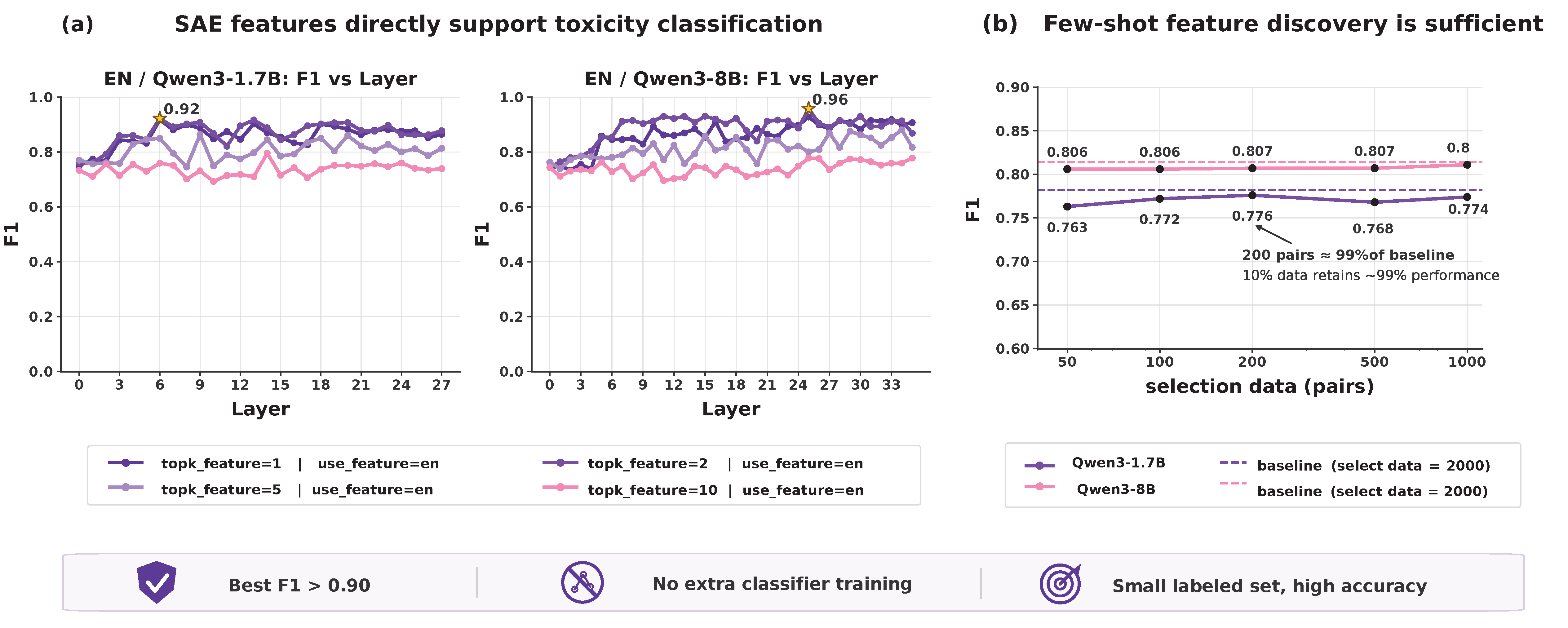 image データ合成シナリオにおいて、Qwen-Scope は既存データ内でほとんどまたは一度も活性化されたことがない毒性テキストの特徴を特定し、方向性を持って補完サンプルを合成することも支援します。従来のデータ合成アプローチと比較して、この手法はより強力な制御性と標的指向性を提供し、ロングテール機能の効率的なカバレッジを可能にするとともに、トレーニングデータの効率比を約 15 倍向上させます。
image データ合成シナリオにおいて、Qwen-Scope は既存データ内でほとんどまたは一度も活性化されたことがない毒性テキストの特徴を特定し、方向性を持って補完サンプルを合成することも支援します。従来のデータ合成アプローチと比較して、この手法はより強力な制御性と標的指向性を提供し、ロングテール機能の効率的なカバレッジを可能にするとともに、トレーニングデータの効率比を約 15 倍向上させます。
学習:ターゲットを絞ったファインチューニング
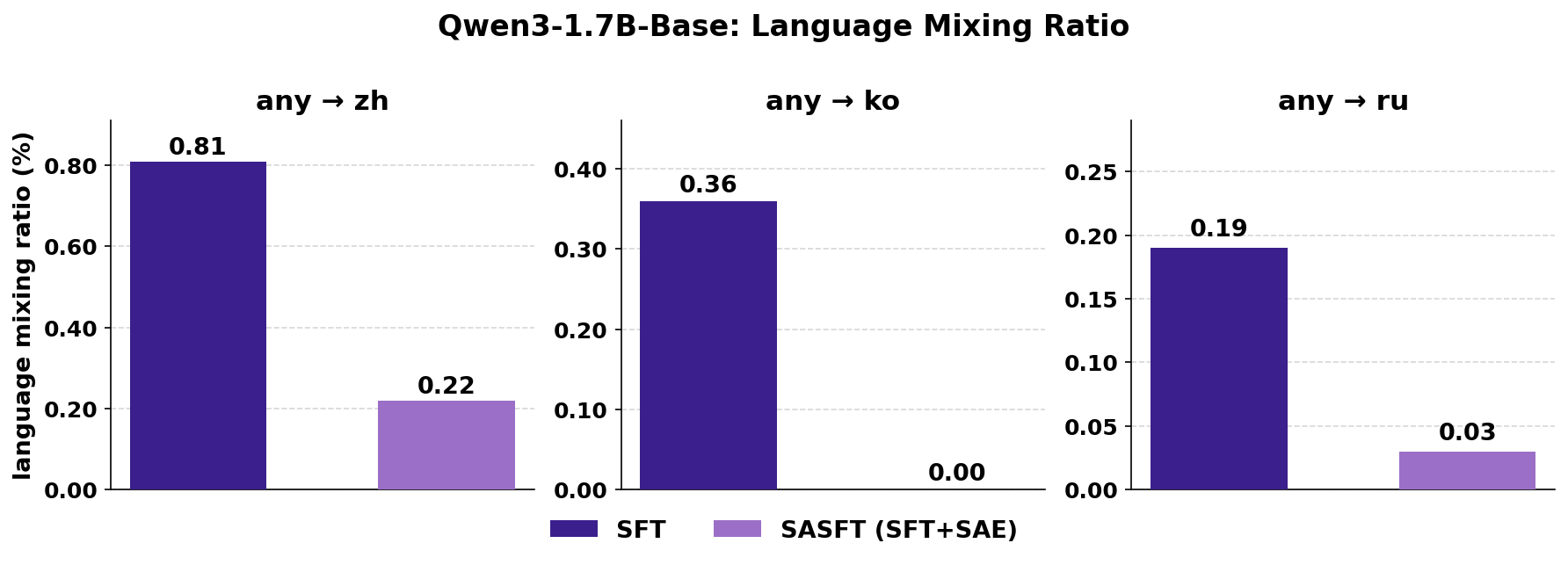
Qwen-Scope が特定した特徴は、学習フェーズでも活用できます。例えば、モデルの出力において予期しない言語混合(英語の応答に予期せぬ中国語単語が現れるなど)を観察した場合、この問題に関連する異常な活性化パターンを特定することができます。教師ありファインチューニング(Supervised Fine-Tuning: SFT)では、その後、これらの異常な活性化を対象とした損失関数を設計し、モデルがこのような望ましくないケースの頻度を減らすように誘導します。
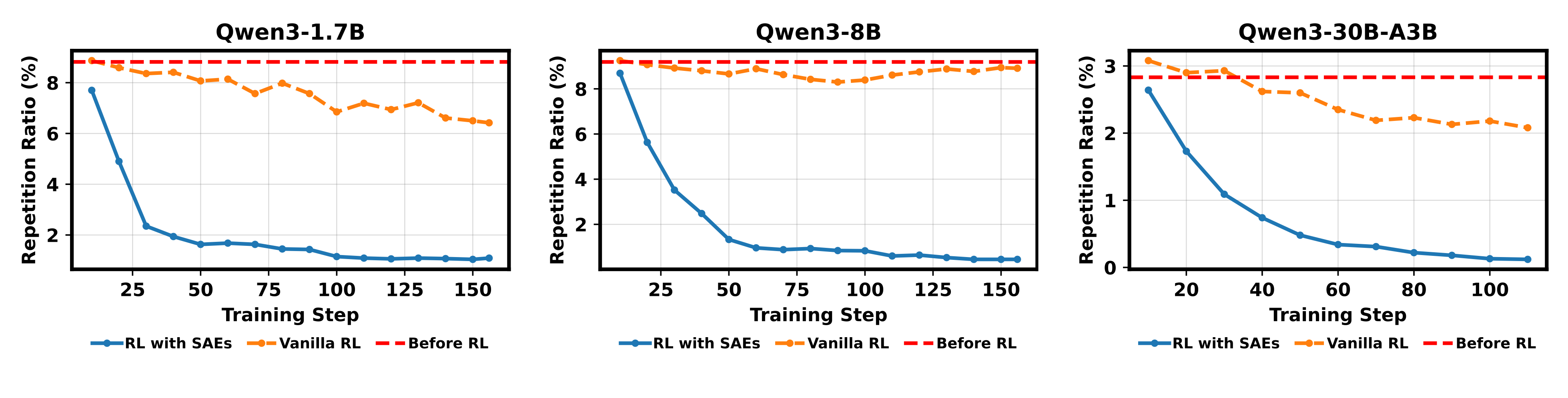
 imageもう一つの例は、反復生成が無限に続く問題です。これは稀にしか発生しないため、強化学習(Reinforcement Learning: RL)の段階でほとんどサンプリングされません。これを解決するために、対応する異常な活性化特徴を強調またはハイライトし、これらの悪いケースがサンプリングされる可能性を高めます。これにより、モデルは強化学習の段階において反復問題に対してより効果的に最適化できるようになります。
imageもう一つの例は、反復生成が無限に続く問題です。これは稀にしか発生しないため、強化学習(Reinforcement Learning: RL)の段階でほとんどサンプリングされません。これを解決するために、対応する異常な活性化特徴を強調またはハイライトし、これらの悪いケースがサンプリングされる可能性を高めます。これにより、モデルは強化学習の段階において反復問題に対してより効果的に最適化できるようになります。
評価:テストサンプルにおける冗長性とギャップの解消
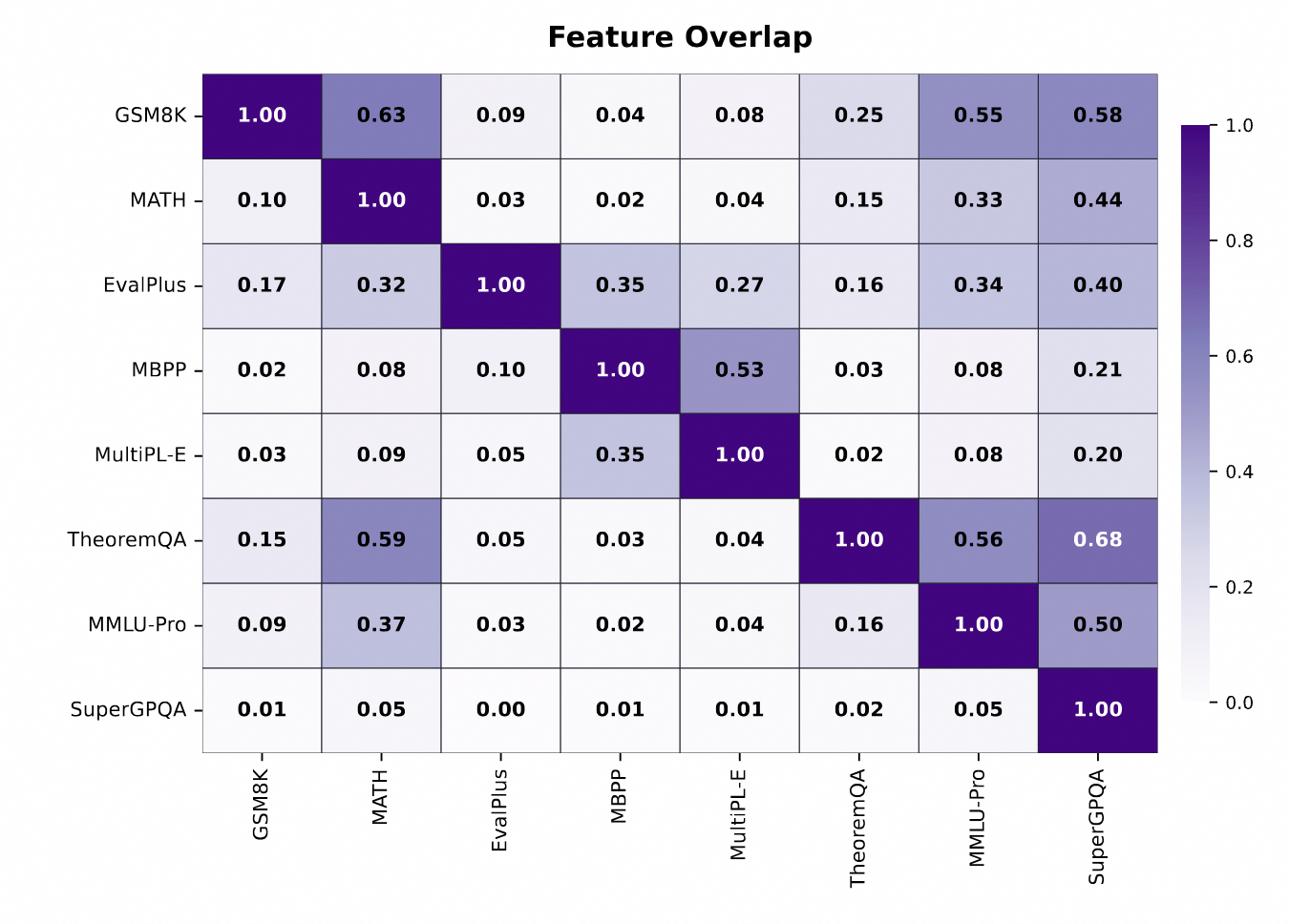
大規模言語モデルの開発において、評価は中核的な側面の一つです。評価すべき機能や次元の数が増加し、サンプルサイズも膨大になるにつれ、重要な問いが生じます。「どの評価データセットに冗長性があり、どのドメインが不十分なカバレッジを示しているのか」です。Qwen-Scope を用いることで、テストセットの機能カバレッジを分析し、異なるベンチマークデータセット間での評価の冗長性の程度を評価できます。以下の図に示す通り、一般的に使用される評価データセットの一部には、活性化された機能において重複したカバレッジが見られ、特定のベンチマークが反復的な評価の影響を受け、相対的に実用的な意義が低くなっていることが分かりました。このような分析アプローチが、ユーザーにとって高カバレッジかつ低コストの評価を行うためのテストサンプルや評価データセットを容易に選択できるよう支援することを願っています。
概要
Qwen-Scope は単にモデルの挙動を分析するツールであるだけでなく、モデルの内部動作に対する深い内省を可能にし、複雑なパラメータ計算を人間が理解できる概念やパターンへと変換します。
それはモデルを単に「解釈」するだけにとどまらず、能動的に「改善」することも可能です。実証結果は、推論、評価、データ処理、トレーニングを含むさまざまな段階において、Qwen-Scope がモデル最適化に対して貴重な洞察と指針を提供することを示しています。したがって、解釈可能性(interpretability)は単なる事後分析ツールではなく、モデルの進化を推進する中核的なエンジンの一つとして機能し得ます。
私たちはコミュニティからのフィードバックを歓迎しており、あなたの創造性が発揮される様子、さらに革新的で興味深いユースケースが紹介されることを心から楽しみにしています!
デモ
Qwen-Scope は Huggingface または modelscope でお試しください。
引用
Qwen-Scope があなたにとって有益であると思われる場合は、自由に引用してください。
@misc{qwen_scope, title = {{Qwen-Scope}: Turning Sparse Features into Development Tools for Large Language Models}, url = {https://qianwen-res.oss-accelerate.aliyuncs.com/qwen-scope/Qwen_Scope.pdf}, author = {{Qwen Team}}, month = {April}, year = {2026}}
原文を表示
HUGGING FACEMODELSCOPETECHNICAL REPORT
Interpretability research has emerged as a critical area for understanding LLM behaviors, informing performance optimization, and enabling more controllable model outputs. Today, we are excited to introduce Qwen-Scope, an interpretability toolkit trained on the Qwen3 and Qwen3.5 series models. Specifically, we inserted and trained Sparse Autoencoders (SAEs) within Qwen’s hidden layers. By imposing sparsity constraints, SAEs decompose the model’s dense hidden representations into sparse, disentangled, and interpretable features. Qwen-Scope not only sheds light on the internal mechanisms underlying Qwen’s behavior, but also holds potential for model optimization. Application scenarios include controllable inference, data classification and synthesis, model training and optimization, and evaluation sample distribution analysis.
- Core Highlights about Qwen-Scope:Inference: Enables targeted control over inference outcomes without requiring explicit natural language instructions.
- Data: Requires only a small amount of seed data to collect features for data classification, significantly reducing data dependency. Additionally, it can leverage inactive feature information to construct targeted data, thereby enhancing long-tail capabilities.
- Training: Identifies abnormally activated features by analyzing low-quality issues such as code-switching and repetitive generation. This assists in model training during supervised fine-tuning (SFT) and reinforcement learning (RL) stages, effectively reducing the frequency of such undesirable responses.
- Evaluation: Calculates feature activation patterns across different samples or benchmark datasets to jointly assess evaluation redundancy. This guides the selection of benchmarks, improves coverage of evaluated capabilities, and reduces evaluation costs.
Overlook
The weights released in this Qwen-Scope open-source project involve 7 LLMs, covering both dense and MoE models from the Qwen3 and Qwen3.5 series, with a total of 14 sets of SAEs.
To ensure broad feature coverage, strong semantic meaningfulness, and stable training, we sampled 0.5B tokens from the pretraining data of the corresponding models to train our SAEs.
NameBackbone typeSAE widthExpansion factorL0
Dense
SAE-Res-Qwen3-1.7B-Base-W32K-L0_50base32K1650
SAE-Res-Qwen3-1.7B-Base-W32K-L0_100base32K16100
SAE-Res-Qwen3-8B-Base-W64K-L0_50base64K1650
SAE-Res-Qwen3-8B-Base-W64K-L0_100base64K16100
SAE-Res-Qwen3.5-2B-Base-W32K-L0_50base32K1650
SAE-Res-Qwen3.5-2B-Base-W32K-L0_100base32K16100
SAE-Res-Qwen3.5-9B-Base-W64K-L0_50base64K1650
SAE-Res-Qwen3.5-9B-Base-W64K-L0_100base64K16100
SAE-Res-Qwen3.5-27B-W80K-L0_50instruct80K1650
SAE-Res-Qwen3.5-27B-W80K-L0_100instruct80K16100
MoE
SAE-Res-Qwen3-30B-A3B-Base-W32K-L0_50base32K1650
SAE-Res-Qwen3-30B-A3B-Base-W128K-L0_100base128K64100
SAE-Res-Qwen3.5-35B-A3B-Base-W32K-L0_50base32K1650
SAE-Res-Qwen3.5-35B-A3B-Base-W128K-L0_100base128K64100
Applications
Qwen-Scope facilitates the analysis and development of Qwen series models. This section showcases its utility across four dimensions: inference, evaluation, data, and training. Please refer to our technical report for more details.
Inference: Analysis of Model Behavior and Controllable Outputs
By controlling the activation of features, we can achieve targeted control over inference results, such as directed modifications in language, entities, or style, without explicitly providing natural language instructions.
Data: Classification and Synthesis
Qwen-Scope performs multi-dimensional analysis and summarization of model representations, enabling its use as a data labeling and classification tool that offers insights into data processing strategies and characterizes data properties.
Taking toxic text as an example, we can use seed data to select highly relevant features for sample classification based on the activation states across all features. This process requires no additional training procedures, greatly saving annotation time. Moreover, high classification accuracy can be achieved with only a small amount of data, significantly reducing dependence on large volumes of bootstrapping data.
In data synthesis scenarios, Qwen-Scope can also help identify toxic text features in existing data that have been rarely or never activated, and directionally synthesize supplementary samples. Compared to traditional data synthesis approaches, this method offers stronger controllability and targeting capability, enabling more efficient coverage of long-tail capabilities and improving the training data efficiency ratio by approximately 15 times.
Training: Targeted Fine-Tuning
The features identified by Qwen-Scope can also be leveraged during the training phase. For instance, when we observe unexpected language mixing in model outputs (e.g., unexpected Chinese words appearing in English responses), we can pinpoint the anomalous activation patterns associated with this issue. During supervised fine-tuning, we then design a loss function specifically targeting these abnormal activations to guide the model in reducing the frequency of such undesirable cases.
Another example is the problem of endless repetitive generation, which occurs infrequently and is therefore rarely sampled during reinforcement learning. To address this, we can amplify or highlight the corresponding anomalous activation features, thereby increasing the likelihood of sampling these bad cases. This enables the model to more effectively optimize against repetition issues during the reinforcement learning stage.
Evaluation: Addressing Redundancy and Gaps in Test Samples
Evaluation is one of the core aspects of large language model development. As the number of capabilities and dimensions to be evaluated continues to grow, along with increasingly large sample sizes, a key question arises: which evaluation datasets contain redundancies and which domains have insufficient coverage. Through Qwen-Scope, we can analyze the feature coverage of test sets to assess the degree of evaluation redundancy across different benchmark datasets. As shown in the figure below, we found that some commonly used evaluation datasets exhibit overlapping coverage in their activated features, causing certain benchmarks to be affected by repetitive evaluation and thus having relatively lower practical significance. We hope that this type of analytical approach can help users conveniently select test samples and evaluation datasets with higher coverage and lower evaluation costs.
Summary
Qwen-Scope is not only a tool for analyzing model behavior, but also enables deep introspection into the internal workings of models, transforming complex parameter computations into human-understandable concepts and patterns.
It does more than just “interpret” models—it can actively “improve” them. Empirical results demonstrate that Qwen-Scope provides valuable insights and guidance for model optimization across various stages, including inference, evaluation, data processing, and training. Interpretability is thus not merely a post-hoc analytical tool, but can serve as one of the core engines driving model evolution.
We welcome feedback from the community and eagerly look forward to seeing your creativity in action—showcasing even more innovative and interesting use cases!
Demo
You can try Qwen-Scope on Huggingface or modelscope.
Citation
If you think Qwen-Scope offers you any help, feel free to cite.
@misc{qwen_scope, title = {{Qwen-Scope}: Turning Sparse Features into Development Tools for Large Language Models}, url = {https://qianwen-res.oss-accelerate.aliyuncs.com/qwen-scope/Qwen_Scope.pdf}, author = {{Qwen Team}}, month = {April}, year = {2026}}関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み