百度、長文解析向け KV キャッシュを一定に保つ 3B モデル「Unlimited OCR」を発表
百度は、KV キャッシュのサイズを一定に保つ新しい「Reference Sliding Window Attention」を採用した 3B モデル「Unlimited OCR」を発表し、長文ドキュメントの高速・高精度な解析を実現しました。
キーポイント
定数メモリ設計による高速化
従来のアテンション機構を置き換え、「Reference Sliding Window Attention (R-SWA)」を採用することで、出力トークン数が増加しても KV キャッシュのサイズが一定に保たれ、メモリ使用量とレイテンシが抑制されます。
DeepSeek OCR を基盤とした MoE 構造
30 億パラメータを持つ Mixture-of-Experts モデルでありながら推論時には 5 億パラメータのみを活性化し、DeepSeek OCR のアーキテクチャを継続学習によって拡張したモデルです。
高効率な画像圧縮と多解像度対応
DeepEncoder が SAM-ViT と CLIP-ViT を組み合わせ、1024×1024 の PDF 画像を 256 ビジュアルトークンに圧縮する「16× token compression」を実装し、複数ページ処理(Base モード)と単一ページ処理(Gundam モード)に対応しています。
業界最高水準のベンチマーク性能
OmniDocBench v1.5 で 93.23 のスコアを記録し、DeepSeek OCR ベースラインを 6.22 ポイント上回る性能を示し、数十ページのドキュメントを 1 つのフォワードパスで処理可能です。
DeepSeek OCR を基盤とした効率的な継続学習
ゼロからではなく DeepSeek OCR チェックポイントから 4,000 ステップの継続学習を行い、エンコーダーを凍結してデコーダーのみを訓練することで、2M ドキュメントサンプルで高い性能を達成しました。
KV キャッシュの固定化による長文処理の劇的向上
R-SWA 技術により KV キャッシュが一定に保たれるため、40 ページ以上の書籍全体を単一の連続パスで解析でき、出力トークン数が増加してもメモリとレイテンシが平坦に維持されます。
ベンチマークと推論速度での SOTA 達成
OmniDocBench v1.5/v1.6 で総合スコア 93.23/93.92 を記録し、特に長文出力時(6,000 トークン)ではベースラインモデルより 35% 高速化されるなど、精度と速度の両面で優位性を示しています。
影響分析・編集コメントを表示
影響分析
本技術は、長文ドキュメント解析における最大の課題であった「メモリ爆発と速度低下」を根本的に解決する画期的なアプローチであり、法律文書の自動要約や大量の帳票データ処理など、実務での大規模 OCR アプリケーションの実用化を加速させる可能性があります。特に、既存の高性能モデルをベースに革新を加えた手法は、リソース効率を重視する産業現場への導入障壁を下げる重要な一歩となります。
編集コメント
「Unlimited」という名称通り、従来の OCR モデルが抱えていたメモリ制限という壁を打ち破る技術的ブレークスルーであり、長文処理が必要な業務自動化の未来を変える可能性を秘めています。
エンドツーエンドの OCR モデルは、出力が増加するにつれて処理速度が遅くなります。生成される各トークンは KV キャッシュに追加され、メモリ使用量が増大し、生成が拖曳します。数十ページの文書を解析することは実用的ではなくなります。Baidu の Unlimited OCR はこれを直接的に解決します。これはデコーダーのアテンションを、メモリ使用量を一定に保つ設計に置き換えたものです。
TL;DR
Unlimited OCR は 30 億パラメータの Mixture-of-Experts モデルですが、アクティブなパラメータはわずか 5 億です。
デコーダーのアテンションを Reference Sliding Window Attention (R-SWA) に置き換え、KV キャッシュを一定に保ちます。
このモデルは最大長 32K の条件下で、1 つのフォワードパスで数十ページの文書を解析します。
OmniDocBench v1.5 で 93.23 のスコアを獲得し、DeepSeek OCR ベースラインを 6.22 ポイント上回ります。
これはスクラッチからの実行ではなく、継続学習(continue-training)を通じて DeepSeek OCR を基盤に構築されています。
Unlimited OCR とは何か?
Unlimited OCR は DeepSeek OCR をベースラインとして採用しています。DeepEncoder と Mixture-of-Experts デコーダーを維持します。MoE 設計では合計 30 億パラメータを持ちますが、推論時には 5 億のみがアクティブになります。
DeepEncoder は圧縮エンジンです。ウィンドウアテンション下の SAM-ViT とグローバルアテンション下の CLIP-ViT をカスケードさせます。ブリッジ部分では 16 倍のトークン圧縮を適用します。1024×1024 の PDF 画像は、わずか 256 ビジュアルトークンに圧縮されます。入力トークンが少ないほど、プリフィル(prefill)が小さくなります。
DeepEncoder はネイティブで 5 つの解像度モードをサポートしており、Unlimited OCR はそのうち 2 つを維持しています。「Base」モードは多ページ作業用に 1024×1024 で動作します。「Gundam」モードは単一ページの文書に動的解像度を採用します。
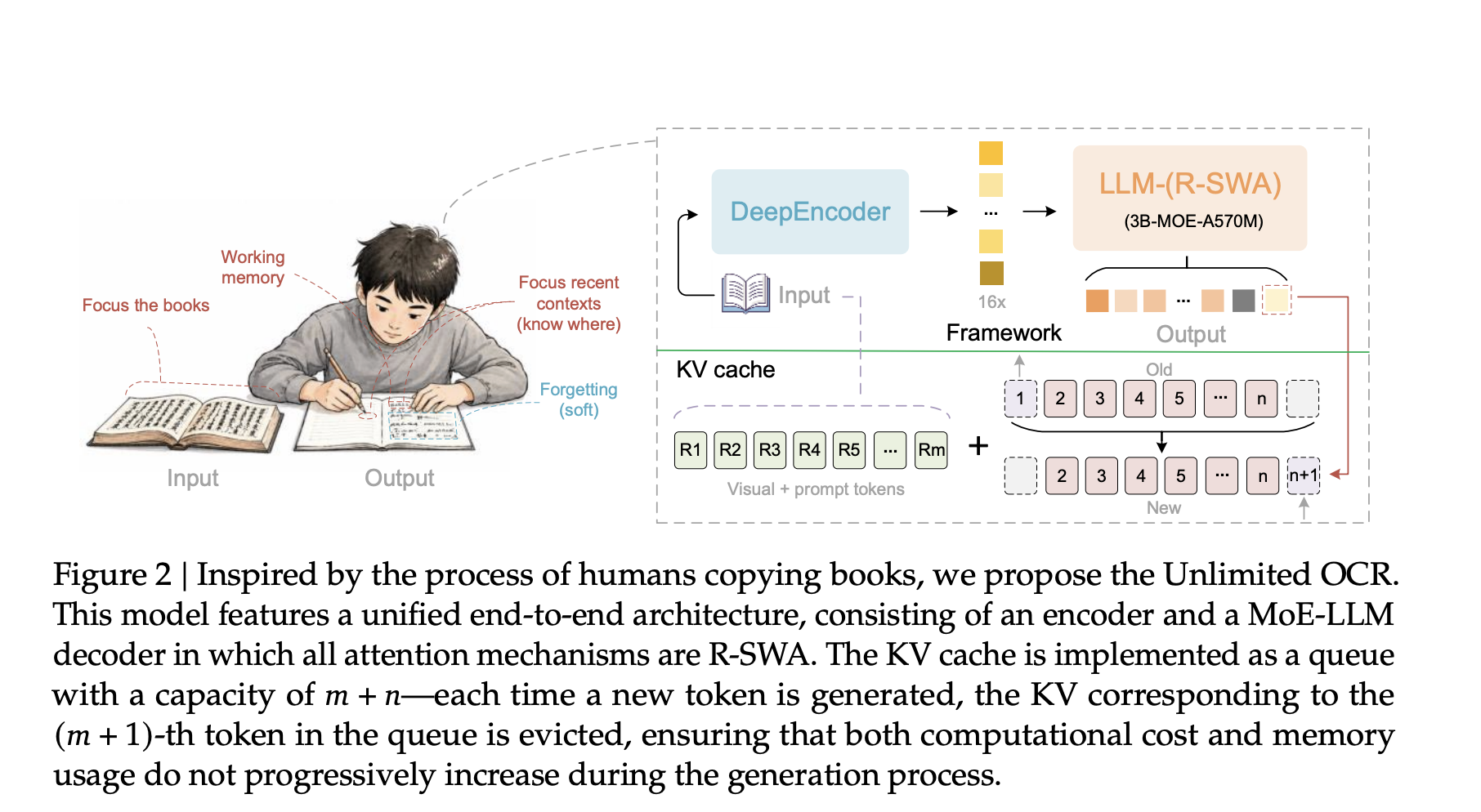 image https://arxiv.org/pdf/2606.23050
image https://arxiv.org/pdf/2606.23050
キャッシュを一定に保つ R-SWA の仕組み
本稿の貢献は、リファレンス・スライディングウィンドウアテンション(Reference Sliding Window Attention)です。標準的なマルチヘッドアテンション(Multi-Head Attention)では、すべてのトークンに対してキーとバリューが保存されます。出力長 T が成長すると、キャッシュもそれに伴って増大します。そのサイズは CMHA(T) = Lm + T です。メモリ使用量とレイテンシは制限なく上昇します。
R-SWA はこのリンクを断ち切ります。生成された各トークンは、すべてのリファレンストークン(つまり視覚トークンとプロンプト)にアテンションを向けます。また、直前の n 個の出力トークンにもアテンションを向けますが、n のデフォルト値は 128 です。それより古いデータはすべて退去します。その結果、キャッシュは m + n という固定サイズのキューとなります。
サイズは CR-SWA(T) = Lm + min(n, T) ≤ Lm + n で表され、一定の値に制限されます。T が n を大きく超えても、キャッシュ比率はゼロに近づきます。つまり、メモリ使用量は平坦なまま保たれ、ステップごとのレイテンシも一定です。
研究チームはこの手法を「ソフトフォアゲティング(soft forgetting)」と比較しています。本を写している人が、原稿と直前の数語を一瞥するだけで、これまでに書き写したすべてを再読しないのと同じです。視覚トークンは状態更新を受けません。これにより、リニアアテンションで見られるような段階的なぼやけを防ぎます。以下のインタラクティブシミュレーターでは、T の値を変化させて両方のキャッシュがどのように反応するかを確認できます。
window.addEventListener("message",function(e){
if(e.data && e.data.type==="uocr-resize"){
var f=document.getElementById("uocr-frame");
if(f){ f.style.height=e.data.height+"px"; }
}
});
トレーニング方法
Unlimited OCR はゼロから訓練されたわけではありません。研究チームは DeepSeek OCR のチェックポイントから 4,000 ステップ継続学習を行いました。DeepEncoder を凍結し、デコーダーのみを訓練しました。訓練には 8×16 A800 GPU で約 200 万のドキュメントサンプルを使用しました。9:1 の分割は単一ページデータを重視しており、多ページサンプルは結合によって構築されました。
ベンチマーク
研究チームは OmniDocBench v1.5 および v1.6 で評価を行いました。主な発見・統計値は v1.5 において全体スコアが 93.23 です。これは DeepSeek OCR のベースラインを 6.22 ポイント上回っています。以下の表で 3 つの関連モデルを比較します。これら 3 つはいずれも同じ 3B-A0.5B サイズを共有しています。
指標 (v1.5)DeepSeek-OCR DeepSeek-OCR 2 Unlimited-OCR
全体 ↑87.01 89.17 93.23
テキスト編集 ↓0.073 0.049 0.038
数式 CDM ↑83.37 86.85 92.61
表 TEDS ↑84.97 85.60 90.93
読み順編集 ↓0.086 0.060 0.045
OmniDocBench v1.6 では、Unlimited OCR は全体スコア 93.92 を達成しました。これは研究論文内の v1.6 比較における最高スコアです。テキスト、数式、表の認識においてすべての分野で向上が確認されました。
速度も改善されています。OmniDocBench の Base モードでは、Unlimited OCR は 5,580 TPS を達成し、DeepSeek OCR の 4,951 TPS を上回りました。これは 12.7% の増加です。出力が長くなるほどこの差は広がります。6,000 トークンの出力上限では、DeepSeek OCR は Unlimited OCR よりも 35% 遅れています。
適用分野:ユースケース
定数キャッシュは、ページごとのシステムが苦手とするワークロードに適しています。
書籍全体の文字起こし:40 ページ以上を一度に読み込み、連続したパスで解析します。報告された編集距離は 40 ページ以上でも 0.11 を下回り、Distinct-35 は 96.90% です。
文書解析パイプライン:テキスト、表、数式、および読み順を単一のフォワードパスで抽出します。
高スループットバッチ解析:同梱の infer.py は SGLang サーバーを起動し、フォルダまたは PDF 全体に対して並行リクエストを送信します。
OCR を超えて:研究チームは R-SWA を ASR(音声認識)や翻訳にも適用可能な汎用的な解析アテンションとして位置付けています。
実行方法:最小限のコード
Transformers パスでは trust_remote_code=True が必要であり、CUDA GPU が必須です。単一画像の解析には Gundam モードを使用します。
コードをコピーしました(別のブラウザでお試しください)
import torch
from transformers import AutoModel, AutoTokenizer
name = "baidu/Unlimited-OCR"
tokenizer = AutoTokenizer.from_pretrained(name, trust_remote_code=True)
model = AutoModel.from_pretrained(
name, trust_remote_code=True, use_safetensors=True,
torch_dtype=torch.bfloat16,
).eval().cuda()
model.infer(
tokenizer,
prompt="document parsing.",
image_file="your_image.jpg",
output_path="your/output/dir",
base_size=1024, image_size=640, crop_mode=True, # gundam mode
max_length=32768,
no_repeat_ngram_size=35, ngram_window=128,
save_results=True,
)
多ページおよび PDF 解析では、Base モードで image_size=1024 を指定して model.infer_multi を呼び出します。本番環境でのスループット向上には、SGLang が fa3 アテンションバックエンドを使用して OpenAI 互換 API を提供します。
強みと弱み
強み:
定数の KV キャッシュ(Key-Value Cache)により、長い出力においてもメモリ使用量とレイテンシが一定に保たれます。
OmniDocBench v1.5 および v1.6 において、エンドツーエンドで最先端(SOTA)スコアを達成しています。
推論コストを抑えるために、アクティブパラメータはわずか 5 億(500M)に抑えられています。
MIT ライセンスの下でオープンウェイトが提供され、デュアルトランスフォーマーアーキテクチャと SGLang のサポートを備えています。
R-SWA の改善点は、単一ページの精度測定においてコストがかかることなく実現されています。
弱点:
解析は真に無制限ではなく、32K のコンテキストがプリフィルの上限として機能します。
強力な圧縮が行われているにもかかわらず、ページ数が増えるにつれてプリフィルの長さは増加します。
複数ページの処理ではベースモードのみが使用されるため、非常に小さな文字が見逃される可能性があります。
音声認識(ASR)や翻訳への転送は今後の課題であり、現時点での実装済み機能ではありません。
論文、リポジトリ、モデルウェイトをチェックしてください。また、Twitter でフォローしたり、15 万人以上の ML サブレッドに参加したり、ニュースレターを購読することもご自由にどうぞ。待ってください!Telegram をご利用ですか?今なら Telegram でも私たちに参加できます。
GitHub リポジトリや Hugging Face ページ、製品リリース、ウェビナーなどのプロモーションでパートナーシップをご希望の方は、ぜひご連絡ください。
本記事「Baidu Releases Unlimited OCR, a 3B Model That Keeps the KV Cache Flat for Long-Document Parsing」は、MarkTechPost で最初に公開されました。
原文を表示
Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and generation drags. Parsing dozens of pages becomes impractical. Baidu’s Unlimited OCR addresses this directly. It swaps the decoder’s attention for a design that keeps memory constant.
TL;DR
Unlimited OCR is a 3B-parameter Mixture-of-Experts model, with only 500M parameters active.
It replaces decoder attention with Reference Sliding Window Attention (R-SWA), keeping the KV cache constant.
The model parses dozens of pages in one forward pass under a 32K maximum length.
It scores 93.23 on OmniDocBench v1.5, beating the DeepSeek OCR baseline by 6.22 points.
It builds on DeepSeek OCR via continue-training, not a from-scratch run.
What is Unlimited OCR?
Unlimited OCR takes DeepSeek OCR as its baseline. It keeps the DeepEncoder and the Mixture-of-Experts decoder. The MoE design holds 3B total parameters but activates only 500M at inference.
The DeepEncoder is the compression engine. It cascades a SAM-ViT under window attention with a CLIP-ViT under global attention. At the bridge, it applies 16× token compression. A 1024×1024 PDF image becomes just 256 visual tokens. Fewer input tokens mean a smaller prefill.
DeepEncoder natively supports five resolution modes, and Unlimited OCR keeps two. ‘Base’ mode runs at 1024×1024 for multi-page work. ‘Gundam’ mode uses dynamic resolution for single pages.
imagehttps://arxiv.org/pdf/2606.23050
How R-SWA Keeps the Cache Constant
The contribution is Reference Sliding Window Attention. Standard Multi-Head Attention stores a key and value for every token. As output length T grows, the cache grows with it. The size is CMHA(T) = Lm + T. Memory and latency climb without bound.
R-SWA breaks that link. Each generated token attends to all reference tokens, meaning the visual tokens and the prompt. It also attends to the preceding n output tokens, where n defaults to 128. Everything older is evicted. The cache becomes a fixed queue of size m + n.
The size is CR-SWA(T) = Lm + min(n, T) ≤ Lm + n. It is bounded by a constant. As T grows far beyond n, the cache ratio trends toward zero. So memory stays flat and per-step latency stays flat.
The research team compare this to soft forgetting. A person copying a book glances at the source and the last few words. They do not re-read everything transcribed so far. Visual tokens never undergo state updates. That avoids the progressive blurring seen in linear attention. The interactive simulator below lets you vary T and watch both caches respond.
window.addEventListener("message",function(e){
if(e.data && e.data.type==="uocr-resize"){
var f=document.getElementById("uocr-frame");
if(f){ f.style.height=e.data.height+"px"; }
}
});
How It Was Trained
Unlimited OCR was not trained from scratch. The research team continue-trained from the DeepSeek OCR checkpoint for 4,000 steps. They froze the DeepEncoder and trained only the decoder. Training used about 2M document samples on 8×16 A800 GPUs. The 9:1 split favored single-page data, with multi-page samples built by concatenation.
Benchmark
The research team evaluates on OmniDocBench v1.5 and v1.6. The main finding/stat is 93.23 overall on v1.5. That beats the DeepSeek OCR baseline by 6.22 points. The table below compares the three related models. All three share the same 3B-A0.5B size.
Metric (v1.5)DeepSeek-OCRDeepSeek-OCR 2Unlimited-OCR
Overall ↑87.0189.1793.23
Text Edit ↓0.0730.0490.038
Formula CDM ↑83.3786.8592.61
Table TEDS ↑84.9785.6090.93
Read-order Edit ↓0.0860.0600.045
On OmniDocBench v1.6, Unlimited OCR reaches 93.92 overall. That is the top score in the research paper’s v1.6 comparison. Gains hold across text, formula, and table recognition.
Speed improves too. On OmniDocBench in Base mode, Unlimited OCR hits 5,580 TPS against DeepSeek OCR’s 4,951 TPS. That is a 12.7% increase. The gap widens with longer output. At a 6,000-token output ceiling, DeepSeek OCR lags Unlimited OCR by 35%.
Where It Fits: Use Cases
The constant cache suits workloads that page-by-page systems handle poorly.
Whole-book transcription: Feed 40+ pages and parse them in one continuous pass. The reported edit distance stays below 0.11 at 40+ pages, with 96.90% Distinct-35.
Document parsing pipelines: Extract text, tables, formulas, and reading order in a single forward pass.
High-throughput batch parsing: The included infer.py launches an SGLang server and sends concurrent requests over a folder or PDF.
Beyond OCR: The research team call R-SWA a general parsing attention, applicable to ASR and translation.
Running It: Minimal Code
The Transformers path needs trust_remote_code=True and a CUDA GPU. Single-image parsing uses Gundam mode.
Copy CodeCopiedUse a different Browser
import torch
from transformers import AutoModel, AutoTokenizer
name = "baidu/Unlimited-OCR"
tokenizer = AutoTokenizer.from_pretrained(name, trust_remote_code=True)
model = AutoModel.from_pretrained(
name, trust_remote_code=True, use_safetensors=True,
torch_dtype=torch.bfloat16,
).eval().cuda()
model.infer(
tokenizer,
prompt="<image>document parsing.",
image_file="your_image.jpg",
output_path="your/output/dir",
base_size=1024, image_size=640, crop_mode=True, # gundam mode
max_length=32768,
no_repeat_ngram_size=35, ngram_window=128,
save_results=True,
)
Multi-page and PDF parsing call model.infer_multi in Base mode at image_size=1024. For production throughput, SGLang serves an OpenAI-compatible API using the fa3 attention backend.
Strengths and Weaknesses
Strengths:
Constant KV cache holds memory and latency flat across long outputs.
End-to-end SOTA scores on OmniDocBench v1.5 and v1.6.
Only 500M active parameters keep inference cheap.
MIT license, open weights, and dual Transformers plus SGLang support.
R-SWA gains arrive without a measured accuracy cost on single pages.
Weaknesses:
Parsing is not truly unlimited; a 32K context still bounds the prefill.
Long prefills grow as page count accumulates, despite heavy compression.
Multi-page runs use Base mode only, so very small text can be missed.
ASR and translation transfer remains future work, not a shipped result.
Check out the Paper, Repo and Model Weights. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post Baidu Releases Unlimited OCR, a 3B Model That Keeps the KV Cache Flat for Long-Document Parsing appeared first on MarkTechPost.
関連記事
Unlimited OCR Works(GitHub リポジトリ)
DeepSeek OCR をベースに定数 KV キャッシュ設計を組み合わせ、人間の作業記憶を模倣する「Unlimited OCR」モデルが開発された。この技術により、32K の最大長制限下で数十ページの文書を単一の順次処理で転写可能となり、音声認識や翻訳タスクにも応用できる。
Mistral OCR 4:文書知能のための最先端 OCR ツール(9 分読了)
Mistral は、170 か国語に対応し、エンタープライズ検索や構造化データパイプラインに統合可能な文書知能ツール「OCR 4」をリリースした。同ツールは単一コンテナで展開可能であり、低リソース言語を含む高精度な抽出と他システムより 4 倍の高速処理を実現している。
Mistral OCR 4 が引用対応の構造化出力を RAG、エージェント型、企業検索パイプラインに提供
Mistral AI は最新ドキュメント理解モデル「OCR 4」を発表し、抽出テキストに境界ボックスやブロック分類、信頼度スコアを追加した。このモデルは 170 か国語に対応し、自己完結型デプロイが可能で、企業検索や RAG パイプラインの ingestion コンポーネントとして機能する。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み