推論計算が戦略的資源へ:AI業界の転換点
Intel CEO の発言と業界の動向から、AI 推論(Inference)における CPU コンピュートの需要急増と戦略的価値の高まりが浮き彫りになり、GPU 依存からの多様化シフトが明確になった。
キーポイント
推論用 CPU コンピュートの戦略的再評価
Noam Brown や Sam Altman の発言に象徴される通り、AI 推論における CPU コンピュートが「過小評価された戦略資源」として認識され始めている。
CPU リフレッシュサイクルと投資不足の解消
COVID-19 期間中の大量購入から約 5〜6 年で更新時期を迎え、過去 2 年間の GPU への偏重により蓄積された CPU 投資需要が噴出している。
ソフトウェア実行と RL 環境による需要増
Claude Code や生成 AI エージェントの実行、および強化学習(RL)のシミュレーション環境において CPU の利用率が急上昇しており、供給不足の懸念も示唆されている。
推論の転換点到来と計算需要の急増
AI が思考・実行・推論を行うようになり、必要なトークン数や計算リソースが過去2年間で約1万倍に増加したことで「推論の転換点」が訪れた。
GPUワークロードの再編とアーキテクチャの変化
推論需要の高まりにより、Prefill/Decodeの分離(disaggregation)が標準化し、Nvidia、Intel-Sambanova、Amazonなどが独自のハードウェア戦略を強化している。
正のフィードバックループの実現
計算リソースの拡大によりAIの知能向上と利用者の増加が相乗効果を生み出し、スタートアップや大手企業ともども「より多くの容量があれば収益も増える」という好循環状態にある。
Codex の汎用ワークスペース化と機能拡張
OpenAI は Codex をコーディングツールから、文脈の永続化やチーム展開機能を備えた一般知識作業用のワークスペースへと進化させ、研究合成やスプレッドシート処理などコード以外のタスクにも対応しています。
影響分析・編集コメントを表示
影響分析
この記事は、AI インフラストラクチャにおける CPU と GPU の役割分担が劇的に変化しつつあることを示唆しており、投資家や企業戦略にとって重要な転換点である。特に、GPU 一辺倒のインフラ構築から脱却し、CPU を活用した推論コスト最適化や、ソフトウェア実行基盤としての CPU 需要への対応が急務となる。
編集コメント
GPU 中心の議論が常態化する中、推論フェーズにおける CPU の戦略的価値を指摘する重要な視点です。インフラ設計において「CPU 不足」や「CPU リフレッシュサイクル」を考慮することが、今後のコスト最適化に不可欠となるでしょう。
今年初めに世界モデルについて取り上げたように、今後数週間にわたり、ポッドキャストで CPU 計算能力/サンドボックス業界に関する短いミニシリーズを公開する予定であり、その理由を説明するには好機です。
最近の動きとして:
ノア・ブラウン氏:「推論用計算能力は戦略的資源であり、現在過小評価されている」
サム・アルトマン氏:「大幅に、私たちは今や AI 推論企業にならなければならない。」
これらを個別に見れば、非常に成功した GPT 5.5 モデルの発表に対する平凡な反応のように思えるかもしれません。しかし、文脈を考慮すれば、これらの発言は極めて注目すべき反応であり、すでにこの問題を極めて深刻に捉えていない読者の方々は、今すぐ警戒すべきです。
本日の論説の直接的なきっかけは、インテル CEO のリップ・ブー・タンの第 1 四半期決算電話会議で、彼が CPU(GPU ではなく)計算能力需要の高まりを示す数値を提示したことです:
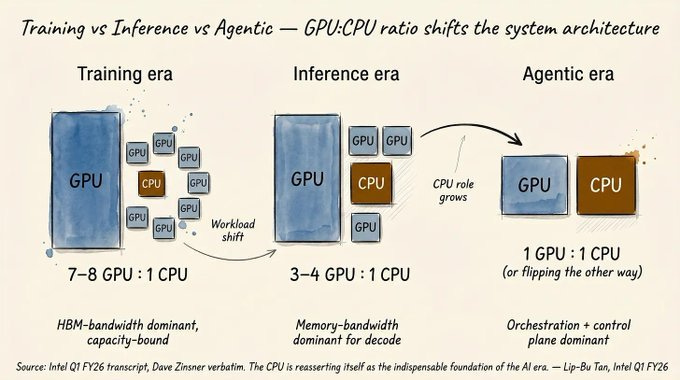
もちろん、インテルの CEO が CPU 需要を強調する動機を持っているのは明白ですが、だからといって彼が間違っているわけではありません:

リンク
この傾向については、当社の SemiAnalysis ポッドキャストで取り上げています(可読性のために編集済み):
Doug: 私たちはちょうど COVID のリフレッシュサイクルの 5 から 6 年目の期間に差し掛かっています。つまり、2020年から2021年の間に、約1,000億ドル([01:52:00])分の CPU を購入しました。そして今、これらのチップの自然な寿命の終わりに直面しています。
[01:52:04] 通常であれば、こうしたチップの大規模なリフレッシュが行われるはずですが、実際には逆に、誰もが GPU [for GPUs] の予算を可能な限り必死に切り詰めています。つまり、AI への投資を最大限に行うために、できる限りのドルをすべて使い果たし、CPU については保守的な資本支出(CapEx)にとどめているのです。皮肉なことに、この Claude Code 関連の動きが活発化するのと同時に、ソフトウェアはどこで実行されるのでしょうか?それは CPU です。そのため、利用率的な増加も見て取れるでしょう。また、強化学習(RL: Reinforcement Learning)が RL ギム(RL gyms)において実際に大量に使用されているという事実もあります。
[01:52:52] ソフトウェアをシミュレーションする必要があり、そこでは多くの CPU が消費されます。GPU の分野のような桁違いの規模ではありませんが、これは非常に大きなトレンドであり、このリフレッシュサイクルの影響もあって、CPU の不足が部分的に発生している可能性さえあります。
[01:53:17] swyx: はい。はい。そして一般的な生産用エージェントについても同様です。ご存知の通り、RLM(Reinforcement Learning Models)も計算資源を必要としますし、OpenClaw はさらに多くの計算資源を要します。いいえ、傾斜は異なりますが、方向性は同じです。
[01:53:30] Doug: 依然として上昇傾向にあります。はい。そしてその傾斜は、明確に言えば、過去2年間にわたって巨額の投資不足に見舞われてきたものです。
そして、Jensen の基調講演に関する NVIDIA GTC カバーage:
[50:41] ついに AI は生産的な作業を行うことができるようになり、したがって推論の転換点到来しました。
AI は今や思考しなければなりません。思考するためには、推論する必要があります。AI は今や行動しなければなりません。行動するためには、推論する必要があります。AI は読まなければなりません。そのためには、推論する必要があります。推論しなければなりません。AI のあらゆる部分において、あらゆる瞬間に、思考するたびに、推論し、行動し、トークンを生成し、推論の道を進む必要があります。もはやトレーニングの領域ではなく、推論の領域にあります。つまり、推論の転換点到来しました。それは必要なトークン数と計算量がおよそ 10,000 倍に増加した時点です。
今、これらを事実と組み合わせます。過去 2 年間で、作業におけるコンピューティング需要が 10,000 倍に増大し、使用量もおそらく 100 倍に増加しているという事実です。
人々は私が「過去 2 年間でコンピューティング需要は 100 万倍に増加したと信じている」と言うのを聞いています。それは私たちが皆が感じていることです。すべてのスタートアップが感じていることです。OpenAI が感じていることです。Anthropic が感じていることです。もし彼らがより多くのキャパシティを手に入れれば、より多くのトークンを生成できるでしょう。収益は増加します。より多くの人々がそれを利用できるようになります。
AI がさらに先進的で賢くなればなるほど、私たちは今やそのポジティブなフライホイールシステムに到達しています。その瞬間に達しました。推論の転換点到来しました。
CPU の需要に加え、推論の転換点は GPU ワークロードの前例のない再編成も引き起こしました。プリフィル/デコードの分離は現在標準となり、Nvidia が Groq を買収し、Intel と Sambanova が連携し、さらに Amazon も OpenAI や Cognition が以前に築いた Cerebras の車輪に乗るような動きを見せています。
2026 年 4 月 28 日〜29 日の AI ニュース。12 のサブレッド、544 件の Twitter、および Discord は確認済みです。AINews のウェブサイトでは過去のすべての号を検索できます。念のため、AINews は現在 Latent Space のセクションの一部となっています。メールの頻度を選択して受け取ることができます。
AI Twitter リキャップ
コーディングエージェントがプラットフォームへ:Codex、Cursor SDK、および VS Code ハーネスのアップグレード
OpenAI は Codex をコーディングツールから汎用的な作業スペースへと転換しています。今日最も強力な製品シグナルは、単なる利用への熱意だけでなく、永続的なコンテキスト(persistent context)、ツール、統合機能、チーム展開に関する能力の着実な拡大にありました。OpenAI は、コードに加え、研究合成、スプレッドシート、意思決定追跡といったより広範な知識労働タスクのために Codex を強調しました(OpenAI, follow-up, follow-up)。また、6 月末まで対象となる Business/Enterprise カスタマー向けに、Codex 専用席を座席料 $0 で提供開始しました(OpenAIDevs)。さらに、Supabase(coreyching)や、実装計画を FigJam ボードに変換する Figma プラグイン(OpenAIDevs)などの統合機能を追加しました。コミュニティの投稿では、アプリサーバーの利用や、より豊かなエージェントワークフロー(gdb, aiDotEngineer)についても言及されています。
パフォーマンスの最適化は、モデルのレイテンシからエージェント・ループ・システムエンジニアリングへと移行しています。OpenAI は、Responses API 上で Codex スタイルのワークフローを WebSocket モードに移行することで、ツール呼び出し間でも状態をウォームに保ち、重複作業を削減し、エージェント型ワークフローを最大 40% 高速化できると述べています(OpenAIDevs, reach_vb, pierceboggan)。VS Code は並列のハッチス改善版をリリースしました。これには、ワークスペース全体での意味的インデックス作成、リポジトリ間検索、チャットセッションの洞察、スキルコンテキスト、Copilot CLI に対するリモートコントロール機能、およびプロンプトやスキル、指示の洗練を目指すプロンプト/エージェント評価拡張機能が含まれています(pierceboggan, pierceboggan, code)。共通する流れは、コーディング・エージェントの UX がもはや生モデルの知能だけでなく、メモリ、検索、ハッチスの品質、そしてツールのオーケストレーションによって支配されているという点です。
Cursor は明確なプラットフォーム戦略を打ち出しています。新しい Cursor SDK では、Cursor の基盤となるランタイム、ハッチス、およびモデルを CI/CD、自動化、製品に埋め込まれたエージェント内でも利用できるように公開しました(cursor_ai, starter projects, customer examples)。これは、Cursor をシートベースの IDE 製品からプログラム可能なエージェントインフラへとシフトさせる画期的な動きであり、@kimmonismus がよく捉えているような枠組みです。Codex アプリサーバーと VS Code のハッチスに関する取り組みと合わせると、このカテゴリは明らかに「ヘッドレス型ランタイム+プログラム可能なハッチス+利用ベースの経済モデル」へと収束していることがわかります。
エージェント・ハッチスエンジニアリング、LangGraph/Deep Agents、および本番環境向け AgentOps
ハーネスが第1級の最適化レイヤーとして台頭しています:複数の投稿で、モデルの品質だけでは不十分であり、モデルを取り巻くハーネスが生産環境のパフォーマンスを決定することが多いという点に合意が見られました。最も明確な研究例は「Agentic Harness Engineering」であり、これは回帰可能なコンポーネント、凝縮された実行証拠、反証可能な予測を通じて、ハーネスの進化を観測可能にするものです。報告された成果として、Terminal-Bench 2 における pass@1 が 69.7% から 10 回のイテレーションで 77.0% に向上し、人間が設計した Codex-CLI ベースライン(71.9%)を凌駕しました。さらに、モデルファミリー間での転移が可能となり、SWE-bench Verified におけるトークン使用量を 12% 削減しています (omarsar0)。HALO に関する関連研究では、トレース分析を用いてハーネスの障害を修正する再帰的自己改善型エージェントが記述されており、Sonnet 4.6 上での AppWorld のスコアが 73.7 から 89.5 に向上したと主張されています (samhogan)。
LangChain の Deep Agents プロダクトラインは、モデル固有のハーネス調整とデプロイ可能性に注力しています:新しい「Harness Profiles」により、チームはモデルごとにプロンプト、ツール、ミドルウェアをバージョン管理できるようになり、OpenAI、Anthropic、Google モデル用のビルトインプロファイルも用意されています (LangChain_OSS, LangChain, Vtrivedy10)。また、LangChain は「DeepAgents Deploy」を発表しました。これは少数の markdown/設定ファイルと LangSmith によるトレーシングを活用したローコードデプロイパスです (hwchase17)。LangChain スタッフからのより広範なメッセージは一貫しており、「オープンなハーネス」「オープンな評価」「OSS フレンドリーなモデルミックス」が重要であるという点です。なぜなら、クローズドなモデルは多くのエージェントワークロードにとってコストが高くなりすぎているからです (hwchase17, Vtrivedy10)。
Cloudflare は、"agents as software" ストックを、実行階層(execution ladders)のようなアイデアや、より具体的にはエージェントが Cloudflare の顧客となることを可能にする機能—アカウント作成、ドメイン登録、有料プランの開始、デプロイ用のトークン取得など—を通じてさらに具体化し続けています (threepointone, Cloudflare)。これは、ベンダーがエージェントを受動的なコパイロットとして扱うのではなく、ビジネスワークフローを直接公開し始めていることを示す重要な兆候です。
モデルリリースとベンチマーク:Mistral Medium 3.5、Granite 4.1、Ling-2.6、およびオープンモデルの価格圧力
Mistral Medium 3.5 は当日最も議論を呼んだモデルリリースでした。初期の評価では、これを密集型(dense)の 128B モデルと位置づける声もありました (scaling01)。Unsloth はこれを、約 64GB の RAM でローカル実行可能なビジョン推論モデルとして説明し、GGUF やガイダンスを公開しました (UnslothAI)。反応は明確に分かれました。一部の批判者は、その 128K コンテキスト、アーキテクチャの選択、そして大規模な中国製オープン MoE(Mixture of Experts)に対する価格設定を問題視しましたが (eliebakouch, scaling01)、他方では Mistral が生来のベンチマークの見せびらかしを追うのではなく、意図的にエンタープライズ向けの信頼性や指示従順性の賭けをしていると主張する声もありました (kimmonismus)。
IBM Granite 4.1 は、30B、8B、3B の 3 つの新しいオープンウェイト(Apache 2.0 ライセンス)非推論モデルを追加しました。これらは開放性とトークン効率性を強く重視しています(ArtificialAnlys)。注目すべき点は、Granite 4.1 8B が Artificial Analysis Intelligence Index で出力に使用したトークン数がわずか 4M であるのに対し、Qwen3.5 9B は 78M を要していることです。また、AA Openness Index では 61 のスコアを記録しました。知能面では強力な競合他社には劣りますが、このファミリーはリーダーボードでの順位よりもコストと透明性が重要となるエンタープライズ/エッジ展開に明確に狙いを定めています。
オープンウェイトにおける競争圧力はさらに激化しています:Ant OSS の Ling-2.6-flash は約 107B の MoE(Mixture of Experts)モデルとして、MIT ライセンスで提供され、SWE-bench Verified で 61.2 を達成し、数学的スコアも高いことが指摘されました(nathanhabib1011)。また、Ling-2.6-1T も vLLM の day-0 サポート付きで登場しました(vllm_project)。一方、Tencent Hunyuan は Hy-MT1.5-1.8B-1.25bit をオープンソース化しました。これは 440MB の完全オフライン対応翻訳モデルで、スマートフォン向けに 33 か国語、1,056 の翻訳方向をカバーします。積極的な 1.25 ビット量子化(quantization)により、標準的な機械翻訳(MT)ベンチマークにおいて商用 API や 235B スケールのモデルと同等の性能を達成したと主張しています(TencentHunyuan)。市場面では、有能力なオープンモデルの価格が急速に下落している点を強調する投稿が複数ありました。例えば、Qwen 3.5 Plus は出力トークンあたり 3 ドル(MatthewBerman)、MiMo-V2.5 Pro は Code Arena でパレートフロンティアをシフトし、1M トークンあたり 1〜3 ドルで提供されています(arena)。
推論、カーネル、および MoE システム:FlashQLA、Blackwell 上の vLLM、torch.compile、GLM-5 サービング
Qwen の FlashQLA は注目すべき長文脈カーネルのリリースです:Alibaba は TileLang 上で高性能な線形アテンションカーネルである FlashQLA を導入し、順方向で 2~3 倍、逆方向で 2 倍の速度向上を報告しました。これは特に小規模モデル、長文脈ワークロード、およびテンソル並列設定において顕著です。設計の中心は、ゲート駆動型自動カード内 CP(カーネル融合)、代数的再定式化、および融合されたワープ特別化カーネルにあります (Alibaba_Qwen, ベンチマークスレッド)。これはパーソナルデバイス上のエージェント AI 向けに明確に位置づけられており、クラウド専用インフラからエッジフレンドリーなランタイムへと移行する長文脈最適化の広範なトレンドに合致しています。
vLLM と Blackwell の共同設計により、実際のスループット向上が実現されています:vLLM は Artificial Analysis において DeepSeek V3.2 で 1 位の出力速度(230 トークン/秒、TTFT 0.96 秒)を報告し、また NVIDIA HGX B300 上の DigitalOcean サーバーレス推論における Qwen 3.5 397B でも強力な結果を示しました。最適化には NVFP4 量子化、EAGLE3 + MTP 予測デコーディング、およびモデルごとのカーネル融合が含まれます (vllm_project)。SemiAnalysis は別途、GB200 上の DeepSeek v4 Pro における vLLM 0.20.0 および MegaMoE カーネルからの利点を強調しました (SemiAnalysis_)。これは、ハードウェア/ソフトウェア/モデルの共同設計が公に確認可能なレイテンシ数値へと転換された明確な事例の一つです。
より多くのエンジニアが、モデルと GPU の間の「中間層」の詳細を共有しています:torch.compile に関する有用なスレッドでは、Dynamo → pre-grad → AOT autograd → post-grad → Inductor の各段階が分解され、推論最適化のためにカスタム FX パスを注入すべき場所についても詳述されています(maharshii)。John Carmack は、GPU ライブラリのパフォーマンスがいまだに極めて経路依存性が高く、ノッチ状の特性を示すことを思い出させる投稿を行いました。具体的には、511×511 から 512×512 にサイズを変更した際に torch.linalg.solve_ex で 10 倍のパフォーマンス低下が発生し、これはおそらく CudaMalloc/Free の異なる内部経路によるものだと指摘しています(ID_AA_Carmack、続報あり)。Zhipu AI も GLM-5 に関する優れたサービス事後分析を公開しました。そこでは KV キャッシュの競合条件、HiCache の同期バグ、そして LayerSplit が紹介されています。LayerSplit は、長文コンテキストを持つコーディングエージェントのサービスにおいて、事前生成(prefill)のスループットを最大 132% 向上させた reportedly と報告されています(Zai_org)。
研究シグナル:知識プローブ、ウェブエージェントベンチマーク、マルチモーダル/科学インフラストラクチャ
圧縮不可能な知識プローブ(IKP: Incompressible Knowledge Probes)は、最も挑発的な研究スレッドの一つです:**@bojie_li は、1,400 問の質問と 188 のモデル、27 ベンダーにわたる事実的知識の精度が、モデルサイズの強い対数線形シグナル(R² = 0.917)を与えることを主張しています。これは 135M から 1.6T パラメータまでのオープンウェイトモデルを対象としたものです。論文は、事実的能力が一部の「推論の圧縮」ナラティブが示唆するように時間とともに圧縮されないとし、フィットされた曲線を用いてクローズドモデルのサイズを推定しています。これらの推定値を信じるかどうかにかかわらず、この研究はブラックボックス評価でもアーキテクチャ規模の情報が漏洩していることを思い起こさせる点で価値があります。
続きを読む
原文を表示
Just as we covered World Models early this year, we’ll be releasing a short miniseries on the CPU compute/sandbox industry on the pod over the coming weeks, and it’s a good time to explain why.
In recent days:
Noam Brown: “inference compute is a strategic resource, currently undervalued”
Sam Altman: “To a significant degree, we have to become an AI inference company now.”
Taken individually, these comments might seem unremarkable normal reactions to a very successful GPT 5.5 model launch. But in context they mark a very noteworthy reaction that you, dear reader, should probably be alerted to if you aren’t already taking this extremely seriously.
The proximal trigger for today’s op-ed is Intel CEO Lip-Bu Tan’s Q1 earnings call, where he gave numbers to illustrate the rising CPU (not GPU) compute demand:
Obviously an Intel CEO has obvious incentives to talk up CPU demand, but that does not mean he is wrong:
link
We’ve covered this trend in our SemiAnalysis pod (edited for readability):
Doug: We are kind of right at the exact five to six year period of the refresh cycle of COVID. So in 2020 - 2021, you bought like a hundred billion [01:52:00] dollars of CPUs. And so we’re right at the natural end of life for these chips.
[01:52:04] And so usually what you do is you have this big refresh of all these chips, but what what’s been happening instead is everyone has essentially scrounged all of their budget [for GPUs] as hard as they can… Everyone’s scrounged every single dollar they could to essentially invest in as much as AI as possible and just do maintenance CapEx on CPU. Ironically, at the same time for all this Claude Code stuff is going on. where is the software gonna run? on CPUs. So I think we’re gonna see some increasing utilization as well as the fact that RL is like actually heavily used for like RL gyms.
[01:52:52] You have to simulate software and it uses a lot of CPUs. So not quite like the orders of magnitude of GPU stuff, but it’s [01:53:00] just such a big trend, we might actually be seeing a CPU shortage partially ‘cause of this refresh cycle.
[01:53:17] swyx: Yeah. Yeah. And just general production agents as well. You know, we just yeah. Even RLMs take compute and you know, OpenClaw takes more compute and, and no, it’s just different slope, but at the same direction.
[01:53:30] Doug: It’s still an up slope. Yeah. And in a slope that, to be clear, has had massive underinvestment for the last two years.
and our NVIDIA GTC coverage of Jensen’s Keynote:
[50:41] Finally, AI is able to do productive work and therefore the inflection point of inference has arrived.
AI now has to think. In order to think, it has to inference. AI now has to do. In order to do, it has to inference. AI has to read. In order to do so, it has to inference. It has to reason. It has to inference. every part of AI every time it has to think it has to reason it has to do it has to generate tokens it has to inference it’s way past training now it’s in the in the field of inference so the inference inflection has arrived at the time when the amount of tokens the amount of compute necessary increased by roughly 10,000 times.
Now when I combine these to the fact that since in the last two years the computing demand of the work has gone up by 10,000 times and the amount of usage has probably gone up by a hundred times.
People have heard me say I believe that computing demand has increased by 1 million times in the last two years. It is the feeling that we all have. It is the feeling every startup has. It’s the feeling that OpenAI has. It’s the feeling that Anthropic has. If they could just get more capacity, they could generate more tokens. Their revenues would go up. More people could use it.
The more advanced, the smarter the AI could become. We are now at that positive flywheel system. We have reached that moment. The inference inflection has arrived.
Apart from the CPU demand, the inference inflection has also resulted in unprecedented reshaping of GPU workloads as well. Prefill/Decode disaggregation is now the norm, with Nvidia buying Groq, Intel-Sambanova, and even Amazon jumping in on a similar Cerebras bandwagon that OpenAI and Cognition had previously struck:
AI News for 4/28/2026-4/29/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Coding Agents Become Platforms: Codex, Cursor SDK, and VS Code Harness Upgrades
OpenAI is turning Codex from a coding tool into a general work surface: the strongest product signal today was not just usage enthusiasm, but the steady expansion of capabilities around persistent context, tools, integrations, and team rollout. OpenAI highlighted Codex for broader knowledge-work tasks like research synthesis, spreadsheets, and decision tracking in addition to code (OpenAI, follow-up, follow-up); launched Codex-only seats with $0 seat fee for eligible Business/Enterprise customers through end of June (OpenAIDevs); and added integrations like Supabase (coreyching) and a Figma plugin that turns implementation plans into FigJam boards (OpenAIDevs). Community posts also pointed to app-server usage, and richer agent workflows (gdb, aiDotEngineer).
Performance work is shifting from model latency to agent-loop systems engineering: OpenAI said moving Codex-style workflows to WebSocket mode on the Responses API keeps state warm across tool calls and cuts repeated work, yielding up to 40% faster agentic workflows (OpenAIDevs, reach_vb, pierceboggan). VS Code shipped a parallel stack of harness improvements: semantic indexing across workspaces, cross-repo search, chat session insights, skill context, remote control for Copilot CLI, and a prompt/agent evaluation extension aimed at refining prompts, skills, and instructions (pierceboggan, pierceboggan, code). The throughline is that coding-agent UX is now dominated by memory, retrieval, harness quality, and tool orchestration—not just raw model intelligence.
Cursor is making an explicit platform play: the new Cursor SDK exposes the same runtime, harness, and models that power Cursor for use in CI/CD, automations, and embedded agents inside products (cursor_ai, starter projects, customer examples). This is notable because it shifts Cursor from seat-based IDE product toward programmable agent infrastructure, a framing captured well by @kimmonismus. Taken together with Codex app-server and VS Code harness work, the category is clearly converging on headless agent runtimes + programmable harnesses + usage-based economics.
Agent Harness Engineering, LangGraph/Deep Agents, and Production AgentOps
Harnesses are emerging as a first-class optimization layer: multiple posts converged on the idea that model quality alone is insufficient; the harness around the model often determines production performance. The clearest research example was Agentic Harness Engineering, which makes harness evolution observable via revertible components, condensed execution evidence, and falsifiable predictions. Reported gains: Terminal-Bench 2 pass@1 from 69.7% to 77.0% in ten iterations, beating a human-designed Codex-CLI baseline at 71.9%, while also transferring across model families and reducing token use on SWE-bench Verified by 12% (omarsar0). Related work on HALO describes recursively self-improving agents using trace analysis to patch harness failures, claiming AppWorld improvement from 73.7 to 89.5 on Sonnet 4.6 (samhogan).
LangChain’s Deep Agents product line is leaning into model-specific harness tuning and deployability: new Harness Profiles let teams version per-model prompts, tools, and middleware, with built-in profiles for OpenAI, Anthropic, and Google models (LangChain_OSS, LangChain, Vtrivedy10). LangChain also pushed DeepAgents Deploy, a low-code deployment path using a small set of markdown/config files and LangSmith-backed tracing (hwchase17). The broader message from LangChain staff was consistent: open harnesses, open evals, and OSS-friendly model mixes matter because closed models are becoming too expensive for many agent workloads (hwchase17, Vtrivedy10).
Cloudflare continued to flesh out its “agents as software” stack with ideas like execution ladders and, more concretely, making agents able to become Cloudflare customers—create accounts, register domains, start paid plans, and get tokens for deployment (threepointone, Cloudflare). This is a meaningful sign that vendors are starting to expose business workflows directly to agents rather than treating them as passive copilots.
Model Releases and Benchmarks: Mistral Medium 3.5, Granite 4.1, Ling-2.6, and Open-Model Price Pressure
Mistral Medium 3.5 was the day’s most debated model release. Early commentary pegged it as a dense 128B model (scaling01), with Unsloth describing it as a vision reasoning model that can run locally on roughly 64GB RAM and publishing GGUFs/guidance (UnslothAI). Reaction split sharply: some criticized its 128K context, architecture choices, and pricing versus large Chinese open MoEs (eliebakouch, scaling01), while others argued Mistral is making a deliberate enterprise reliability/instruction-following bet rather than chasing raw benchmark spectacle (kimmonismus).
IBM Granite 4.1 added three new open-weight, Apache 2.0 non-reasoning models—30B, 8B, 3B—with a strong emphasis on openness and token efficiency (ArtificialAnlys). The standout claim is that Granite 4.1 8B used only 4M output tokens on the Artificial Analysis Intelligence Index, versus 78M for Qwen3.5 9B, while scoring 61 on the AA Openness Index. Intelligence lags stronger peers, but the family looks aimed squarely at enterprise/edge deployments where cost and transparency matter more than leaderboard position.
Open-weight competitive pressure continues to intensify: Ant OSS’s Ling-2.6-flash was cited as ~107B MoE, MIT-licensed, with 61.2 SWE-bench Verified and strong math scores (nathanhabib1011); Ling-2.6-1T also landed with day-0 vLLM support (vllm_project). Meanwhile, Tencent Hunyuan open-sourced Hy-MT1.5-1.8B-1.25bit, a 440MB, fully offline translation model for phones covering 33 languages, 1,056 translation directions, and claiming parity with commercial APIs / 235B-scale models on standard MT benchmarks via aggressive 1.25-bit quantization (TencentHunyuan). On the market side, multiple posts underscored how rapidly pricing is falling for capable open models, e.g. Qwen 3.5 Plus at $3/M output tokens (MatthewBerman) and MiMo-V2.5 Pro shifting the Pareto frontier in Code Arena at $1/$3 per M tokens (arena).
Inference, Kernels, and MoE Systems: FlashQLA, vLLM on Blackwell, torch.compile, and GLM-5 Serving
Qwen’s FlashQLA is a notable long-context kernel release: Alibaba introduced FlashQLA, high-performance linear attention kernels on TileLang, reporting 2–3× forward and 2× backward speedups, especially for small models, long-context workloads, and tensor-parallel setups. The design centers on gate-driven automatic intra-card CP, algebraic reformulation, and fused warp-specialized kernels (Alibaba_Qwen, benchmark thread). It is explicitly positioned for agentic AI on personal devices, which fits a broader trend of long-context optimization migrating from cloud-only infra to edge-friendly runtimes.
vLLM and Blackwell co-design is landing real throughput wins: vLLM reported #1 output speed on Artificial Analysis for DeepSeek V3.2 at 230 tok/s, 0.96s TTFT and also strong results on Qwen 3.5 397B using DigitalOcean serverless inference on NVIDIA HGX B300, with optimizations including NVFP4 quantization, EAGLE3 + MTP speculative decoding, and per-model kernel fusion (vllm_project). SemiAnalysis separately highlighted gains from vLLM 0.20.0 and MegaMoE kernels for DeepSeek v4 Pro on GB200 (SemiAnalysis_). This is one of the clearer examples of hardware/software/model co-design translating into publicly visible latency numbers.
More engineers are sharing the “middle layer” details between models and GPUs: a useful thread on torch.compile broke down Dynamo → pre-grad → AOT autograd → post-grad → Inductor, including where to inject custom FX passes for inference optimizations (maharshii). John Carmack posted a reminder that GPU library performance remains extremely path-dependent and notchy, noting a 10× regression in torch.linalg.solve_ex when going from 511×511 to 512×512, apparently due to a different internal path with CudaMalloc/Free (ID_AA_Carmack, follow-up). Zhipu AI also published a good serving postmortem on GLM-5, detailing KV cache race conditions, HiCache synchronization bugs, and LayerSplit, which reportedly improved prefill throughput by up to 132% for long-context coding-agent serving (Zai_org).
Research Signals: Knowledge Probes, Web-Agent Benchmarks, Multimodal/Science Infrastructure
Incompressible Knowledge Probes (IKP) is one of the more provocative research threads**: @bojie_li claims that factual knowledge accuracy over 1,400 questions / 188 models / 27 vendors gives a strong log-linear signal of model size (R² = 0.917 on open-weight models from 135M to 1.6T params). The paper argues factual capacity does not compress over time the way some “reasoning compresses” narratives suggest, and uses the fitted curve to estimate closed-model sizes. Whether one buys the estimates or not, the work is valuable as a reminder that black-box evals still leak architecture-scale information.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み