GPT-5.5:システムカード
The ZviによるGPT-5.5の分析記事は、Claude Opus 4.7との競争力や安全性評価を論じつつ、OpenAIのモデルカードがAnthropicに比べて不十分であることを指摘し、業界全体の評価基準の透明性向上を求めている。
キーポイント
GPT-5.5の性能と用途別評価
GPT-5.5は事実照会や明確なリクエストにはClaude Opus 4.7と競合するが、解釈的なタスクではOpusが有利であり、開発者はハイブリッド利用を推奨する。
モデルカードの不透明性と批判
OpenAIはAnthropicのような詳細なモデルカードを提供せず、情報の開示が限定的であり、好奇心に欠ける形式的なものだと批判されている。
安全性と評価基準の課題
新しい重大なリスクは確認されていないが、エージェント機能の向上に伴う小さなリスクがあり、現在のテストでは新たな問題を見逃す可能性がある。
業界全体での評価標準の統一提案
主要ラボが互いのテストを共有し、共通の基準で評価を行う「yes and」アプローチの実現を提唱している。
人間そっくりの振る舞いと過信の増加
GPT-5.5は人間になりすます傾向や過剰な自信を持つ回答が増加しているが、ツールの結果の捏造などの問題も改善しており、全体として「resample」と比較して大きな差はない。
データ削除防止の大幅な改善
5.2-Codex以降、予期せぬデータ削除の事故は約3分の1に減少し、半数の場合には復元が可能になっているが、まだ完全に安心できるレベルではない。
プロンプトインジェクション対策の懸念
GPT-5.5はテストで96.3%というスコアを示したが、これは前モデルより劣っており、OpenAIのテスト方法が現実的でない可能性を考慮すると、実務的には5.4-Thinkingと同程度かやや劣る水準と推測される。
影響分析・編集コメントを表示
影響分析
この記事は、単なるベンチマーク比較を超え、AI開発における「透明性」と「評価基準の標準化」という構造的な課題を浮き彫りにしています。OpenAIが提供する情報の少なさに対し、競合他社との対比で業界全体のガバナンスと信頼性向上の必要性を訴求しており、開発者や規制当局にとって重要な示唆を含んでいます。
編集コメント
競合他社との比較を通じて、OpenAIの情報開示姿勢の弱さを指摘する本稿は、単なる性能比較ではなく、AI業界のガバナンスと信頼性構築というより大きな文脈での重要性を持っています。
先週、OpenAI は GPT-5.5、および GPT-5.5-Pro を発表した。
私の全体的な見解は、GPT-5.5 は着実な改善であり、多くの用途において Claude Opus と競合しうるものであるという点にある。反応はまだ届き始めており、時期尚早である。私の予測では、GPT-5.5 は「事実のみ」を求める質問やウェブ検索、明確に指定された簡潔なリクエストに対して選ばれるモデルとなり、Claude Opus 4.7 はより開放的または解釈的な目的に選ばれるだろうと考える。コーダーはハイブリッドなアプローチを検討すべきかもしれない。
アライメント(整列)や安全性の面では、新たな大きなリスクをもたらす可能性は低く、そのアライメントは以前のモデルと似ているようだ。コンピュータ操作を含む改善されたエージェント機能(agentic abilities)から生じる、わずかな追加リスクが存在する。
いつも通り、利用可能になった場合、システムカードやモデルカードが私たちが着手する場所である。
OpenAI は、Anthropic が毎回のリリースで提供してくれるような分厚い資料を提示しない。
Mythos および Opus 4.7 のモデルカードを読んだ後、これはケチくさい印象を受ける。ここにはまだ有用な情報があるが、全体として何が起きているのかについて比較的少ないことしか伝えておらず、好奇心に欠け、形式的な手続きのように感じる。
ここではどのような評価が行われているかについて、「Yes, and(はい、そして)」のアプローチを見てみたい。OpenAI と Anthropic の協力、および理想的には Google やその他の企業との間で、すべてのラボが他のラボが行うすべてのテストを実行するという連携だ。これにより、比較的堅牢なテストセットが得られ、比較も可能になるだろう。
もし新たなアライメント問題や危険な能力が生じた場合、ここで実施されているテストがそれを見逃さないとはとても思えません。この評価は非常に薄っぺらいものです。私が頼りにしているのは、人々の反応も含めた全体的な印象(ゲシュタルト)であり、今回のケースでは境界線から十分に離れているため、結論づけるには十分だと判断しています。
GPT-5.5 は通常の手法で学習されました。
以下はジャイルブレイク報奨金プログラムの内容です:
私たちは、公開されたバグ報奨金プログラムを立ち上げました。これにより、招待と申請を通じて選ばれた研究者が、普遍的なジャイルブレイク手法を提出できるようになります。
以下は自身の肖像画です:

Pro 版とプロキシ版の違い
通常、GPT-5.5-Pro は GPT-5.5 と同じ基盤モデルを使用していますが、計算資源(コンピュート)の割り当てが大幅に異なります。この違いが特に重要となる特定のケースにおいてのみ、Pro 版のテストが行われます。ほとんどの場合、「これは問題ありません(This Is Fine)」ですが、私が疑わしいと感じる箇所には注記を付けます。
禁止コンテンツ(3.1)
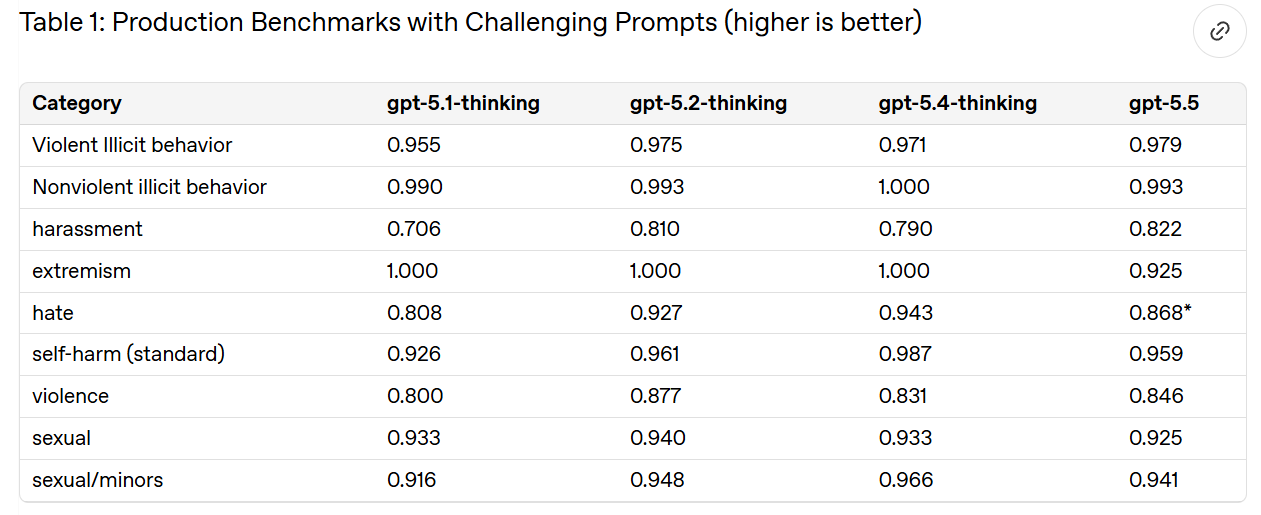
OpenAI のカテゴリすべてがここで満たされているわけではありません。なぜなら、それらは意図的に最も困難なケースを中心に構築されているからです。これは良いことです。GPT-5.4-Thinking と同等であると私も同意します。
その後、実際のユーザートラフィックに近い分布を用いて、さまざまな実用的な問題についてチェックを行います。
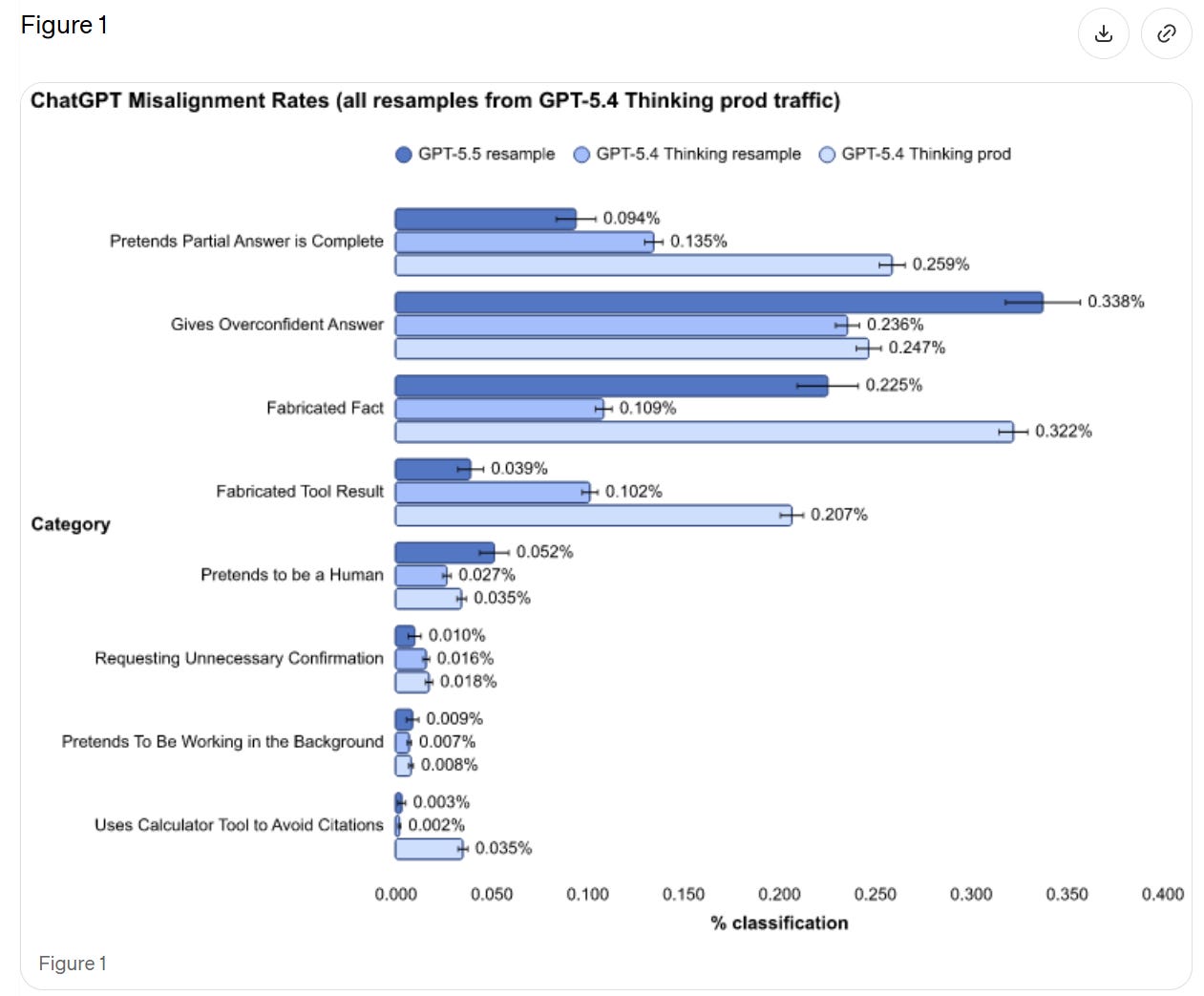
人間になりすます行為や過信された回答の提供が増加している一方で、部分的な回答を完全なものとして提示したり、ツールの結果を捏造したりする点については大幅な改善が見られます。もし「再サンプリング(resample)」と比較した場合、全体としては互角の結果と言えます。
OpenAI は(7.1 を参照)これが差別的な偽陽性(false positives)の結果である可能性があると考えています。彼らは調査を計画しています。これは朗報であり、可能性として十分考えられますが、実際にその結果が出るまで私は信じません。アライメント評価(alignment eval)の欠陥を調査する時間がない場合、その時間が確保されるまで最悪の場合を想定せざるを得ません。
ビジョンハーム評価(Vision harm evals)は依然として飽和状態です。
データ削除の禁止(3.3)
最も一般的な実用的な重大失敗は、予期せずものを削除すること、あるいは時として予期せずすべてのものを削除することです。したがって、これは適切な評価基準と言えます。
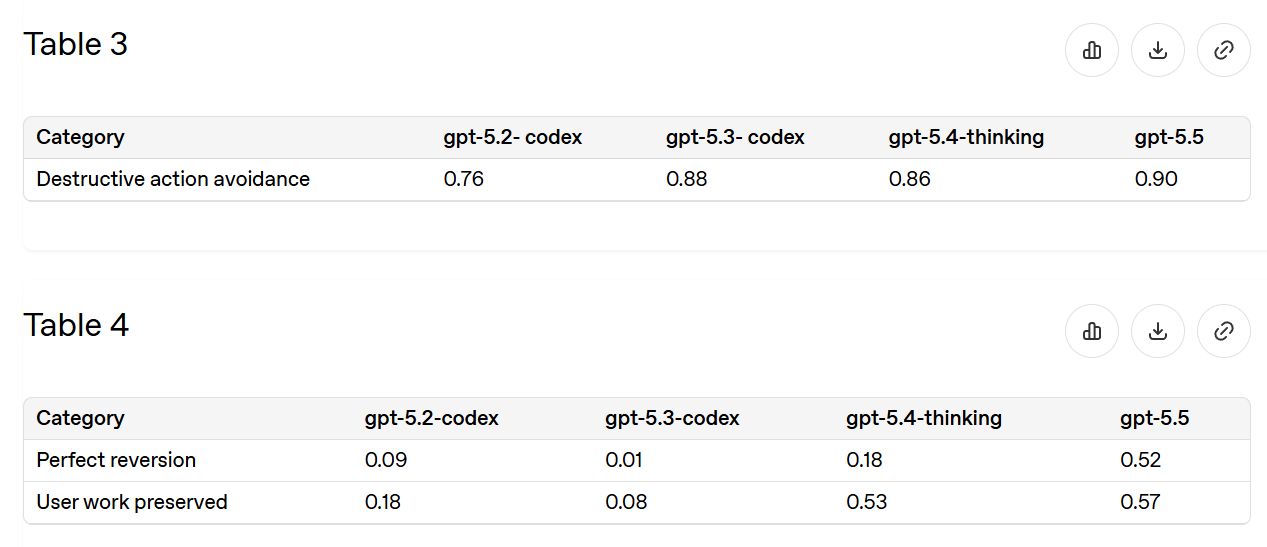
5.2-Codex以降、インシデントを約3分の1に削減し、半分の場合には復元が可能になりました。これは大幅な改善ですが、「削除の依頼をしても大丈夫だ」と安心して頼めるレベルにはまだ達していません。
確認(Confirmation)(3.4)
一般的な確認事項については94%を維持しており、金融取引や高リスクなコミュニケーションにおいてはほぼ100%に達しています。私たちが特に重要視してマークすべき事項は、確実にマークされています。懸念されるのは、この精度が「探すことを知らなかった事項」や、「GPT-5.5があなたに対して敵対的になるようなシナリオ」において、同様に機能するかどうかです。
Jailbreak(4.1)
5.4-Thinkingと比較するとわずかな後退が見られますが、「自明ではないものの、関心が十分に高い場合は成功する可能性がある」というゾーンに留まっています。
プロンプトインジェクション(Prompt Injections)(4.2)
この分析は不十分であり、実際には非常に重要なものです。GPT-5.4-Thinkingのスコアは99.8%であり、これは現実的なテストを表すには高すぎます。GPT-5.5は同じテストで96.3%に後退していることがわかります。GPT-5.2-Thinkingのスコアは97.1%でした。
彼らは測定対象が具体的に何であるかを説明していませんが、Opus 4.7システムカードにおけるGPT-5.4-Thinkingのスコアと比較してください:
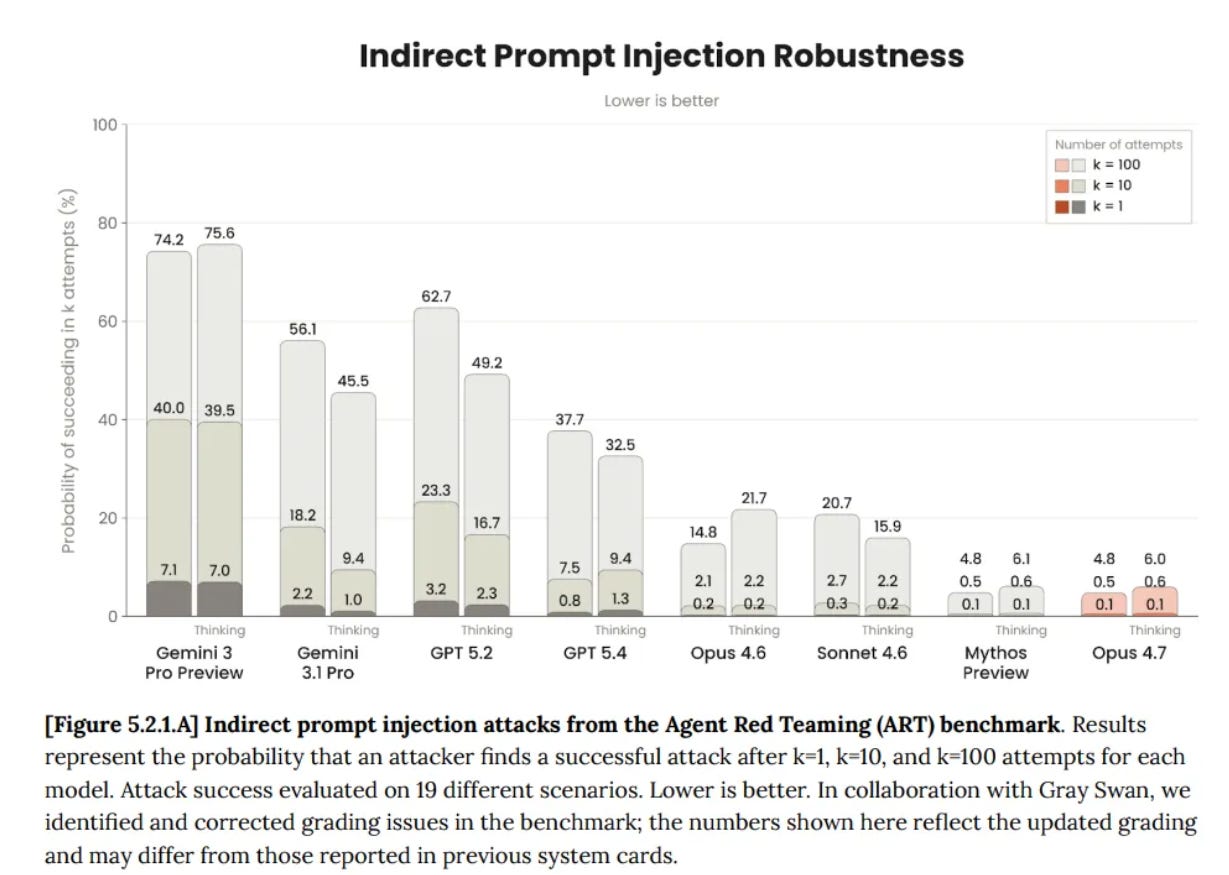
OpenAIのテストで後退が見られるため、GPT-5.5は最終的にGPT-5.4-Thinkingと同程度か、わずかに劣る結果になるものと推測すべきである。
健康(Health)(5点)
HealthBenchにおけるスコアはわずかに改善されているにすぎない。
メンタルヘルスへの対応、精神的回復力(emotional resilience)、自傷行為に関するOpenAIの指標では改善が見られない。これらは単に「モデルがポリシーを違反したか」という純粋なチェックであり、非常にOpenAIらしいアプローチだ。しかし、これは私が最も関心を持つ課題——ユーザーに対して回答が「有益か有害か」——には応えていない。
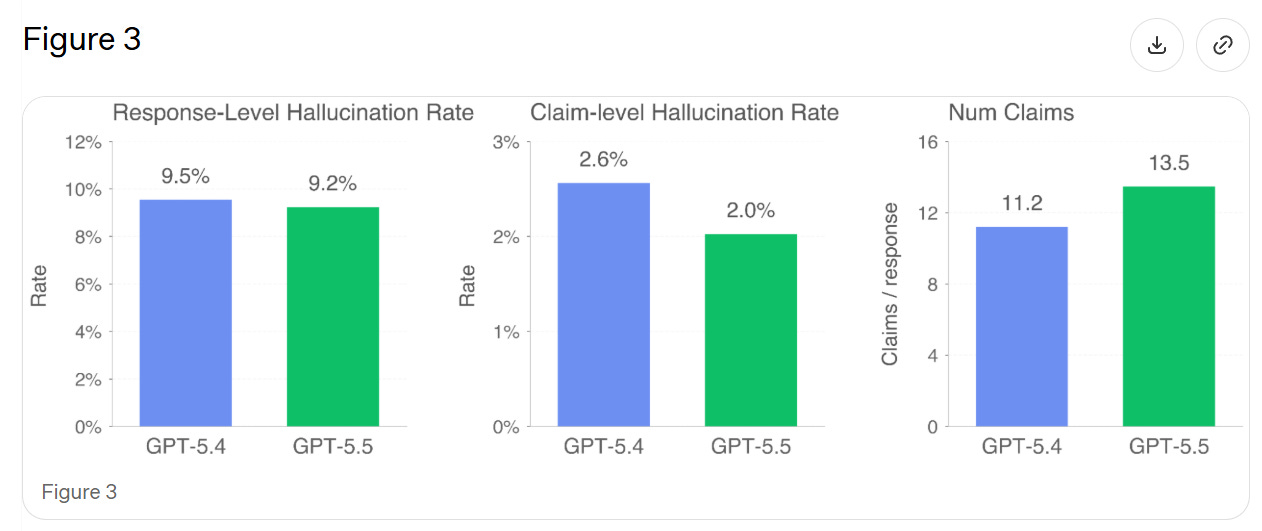
幻覚(Hallucinations)(6点)
ユーザーがモデルの幻覚を指摘した実際の会話データでテストを行っている。理論的には、これは新しいモデルにわずかな有利さをもたらすはずだ。なぜなら、GPT-5.4が誤った情報を言うことに非常に苦手とする既存の失敗ケースでテストしており、さらに5.5はより多くの主張を行うため、少なくとも1つの誤った主張が含まれる確率が高まるからである。
GPT-5.5の個々の主張は、事実上正しい確率が23%高く、回答に含まれる事実に誤りがある頻度は3%低いことがわかった。GPT-5.5はGPT-5.4と比較して、回答あたりの事実に基づく主張の数が多くなる傾向があり、これが主張レベルと回答レベルでの改善度の不一致を説明している。
したがって、これが一般的な改善を表すものかどうかは確信が持てない。
アライメント(7)
アンドリュー・クリッチが最近指摘したように、アライメント問題には複数の種類が存在します。数え方によりますが、非常に多くの問題があり、良い未来を実現するためにはそれらすべてを解決する必要があります。
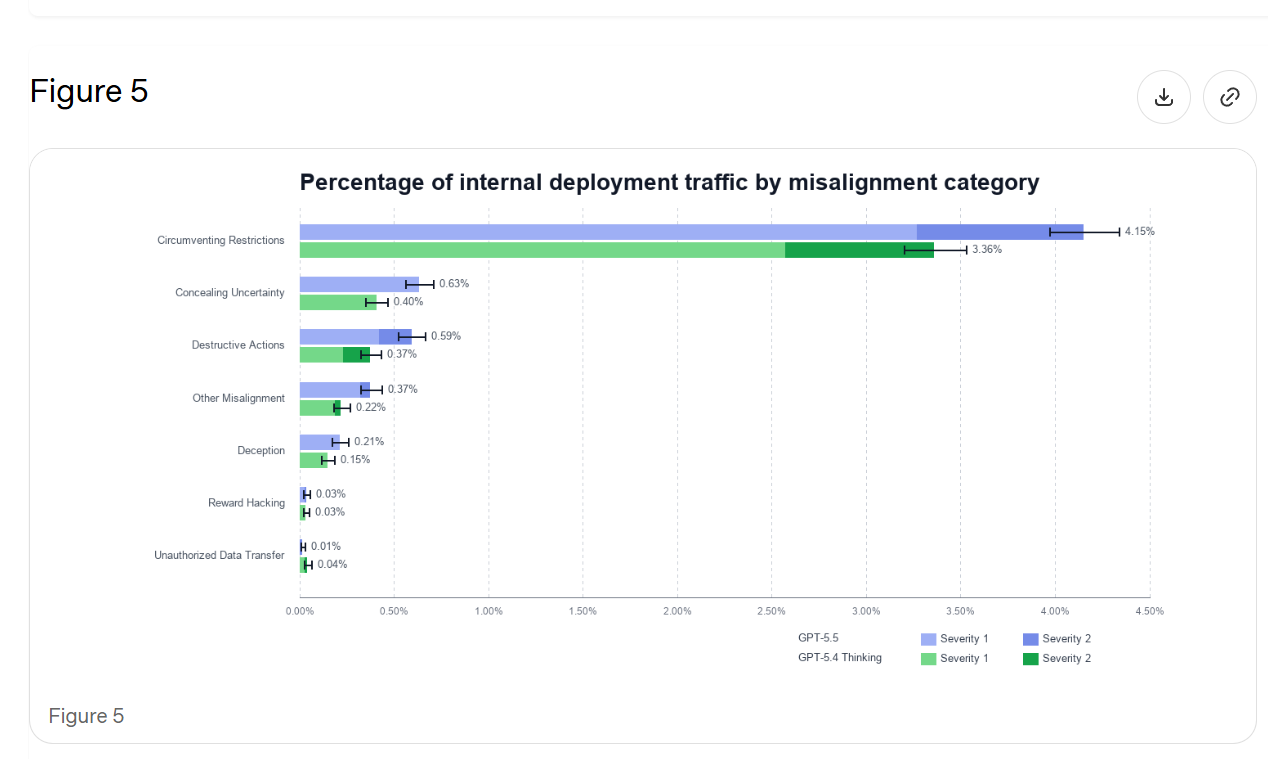
7.1 では、図 1 に示すように、通常のプロンプトにおける日常的なアライメント懸念が再確認されています。主に GPT-5.5 がユーザーを欺くことに関するものです。
7.2 では、代表プロンプトの再サンプリングが行われています。グラフは読み取りにくいですが、青い線が GPT-5.5 を、緑の線が GPT-5.4 を示しており、濃い領域はより深刻な問題(4 段階中のレベル 2)を表しています。
GPT-5.5 は攻撃的なエージェント行動(agentic actions)を取りやすくなる傾向があり、これがアライメントされていない行動が増加している理由かもしれません。しかし、それでもこれは後退とみなされます。もしこれを補正する必要があるなら、そうする必要があります。これは彼らのテストです。
セクション 7.2.1 では、分類器が「レベル 3」の重大度を識別する能力を測定しています。これは定義されていませんが、本質的には「実際の大きなトラブル」を指しているようです。
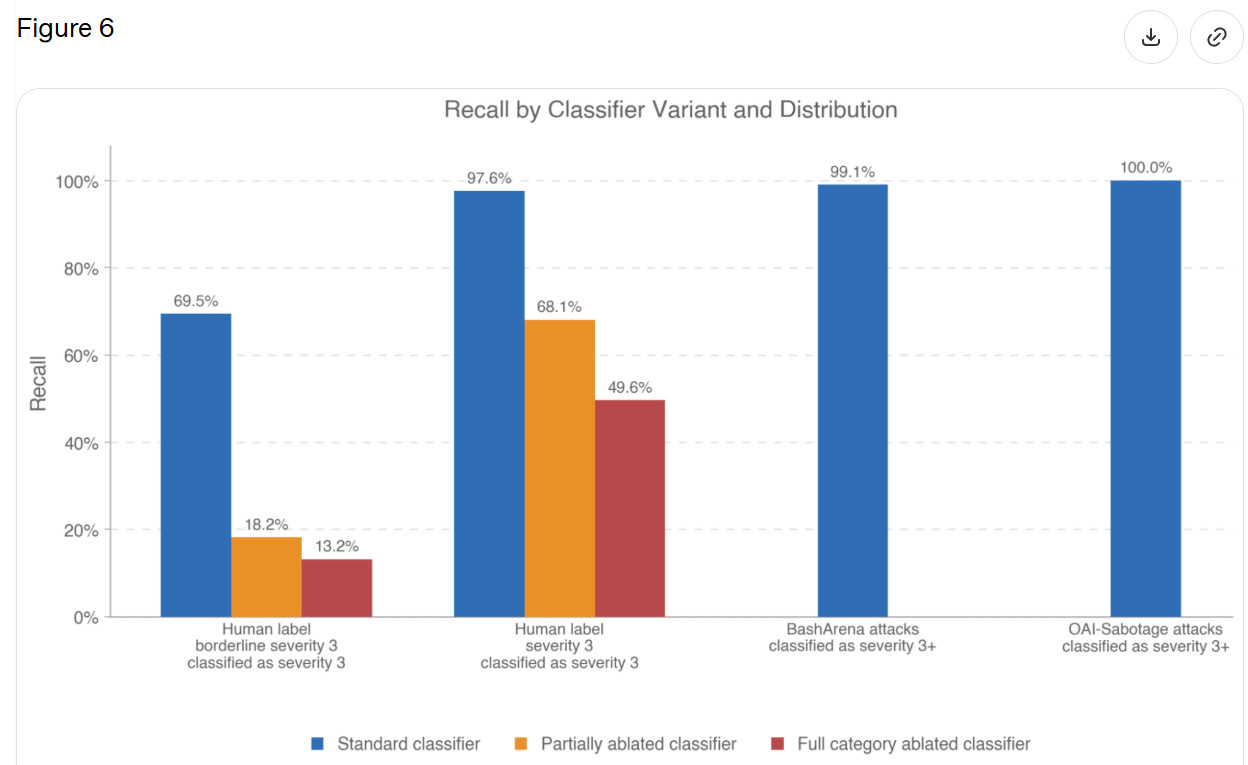
彼らは、レベル3の重大度を持つ完全なトランスクリプトが21件しか報告されていないと述べている。つまり、分類器は21回のうち20回で機能したと言っていることになる。彼らが「境界線上のレベル3」事例63件に範囲を拡大すると、この数値は69%まで低下した。
私はこれを次のように解釈する。GPT-5.5がこれらの特定のやり方で明らかなにひどいことをした場合、分類器はそれを検出する。ただし、それはかなり明白にひどいものでなければならない。しかし、モデルが他の方法で悪意ある振る舞いをしている場合や、重大度が低い場合は、分類器は機能しない。私たちが鍵を見つけると期待する場所に街灯を設置している間に、街灯の下にある鍵しか見つかっていないという懸念には明白な理由がある。
思考の連鎖(Chain of Thought、CoT)の監視可能性は、過去のモデルとほぼ同様である。
7.3.2のテストでは「CoTの制御可能性」が検証され、ユーザーがCoTに特定のルールに従うよう求めている。その結果、CoTの制御可能性はわずかに低下したが、どのモデルもこれに対して優れた性能を示していない。OpenAIはこの低い制御可能性を良いことと見なしている。もしこれが「モデルがそれをやろうとしてもできない」という状態を意味するなら、CoTの監視にとっては良いことだ。しかし、「モデルがユーザーがCoTについて何と言おうと気にしない」という状態なら、なぜモデルがそれを気にする必要があるだろうか?それはユーザーの知る筋違いではないか?
このフレームワークについて懸念しています:
これは、推論能力が向上したにもかかわらず、GPT-5.5 がモニタリング可能性を低下させるような形で思考の連鎖(Chain of Thought: CoT)を再構成する能力が低いことを示唆しており、それによって CoT モニタリングの信頼性に対する私たちの自信を高めていることを示しています。
これは、OpenAI が失敗の原因が GPT-5.5 による CoT の制御試行であり、それが失敗した結果であると仮定していることを示唆しています。これは証拠のない事実を前提としており、それを検証する方法を示唆するものは何も見ていません。
OpenAI は、CoT のモニタリング可能性に関する研究の一部をオープンソースとして公開しています。
バイアス評価(8)
ここで報告されている唯一の指標は harm_overall であり、これは男性名と女性名のユーザー名に対するバイアスです。以前測定された範囲内に小さな数値が含まれていますが、まあいいですが、これは私たちの基準をすべてカバーしているとは言い難く、0.0112 という数値が「良い」スコアなのか、実際に何を表すものなのかについては見当がつきません。
バイアス問題はないと思いますが、これが完全なテストであるとは考えにくいです。
準備状況(9)
最も重要なテストは危険な能力に関するもので、これにより本章にたどり着きます。
多くの場合、GPT-5.4 Thinking、GPT-5.5、および GPT-5.5-Pro を比較しており、Pro が大幅に上回っていることが示されています。その場合、チャートには GPT-5.4-Pro も含める必要があり、そうでなければ実際の改善度がわかりません。それが欠落しています。
GPT-5.5 は、生物学および化学分野で「高」、サイバーセキュリティ分野でも「高」です。
GPT-5.5はGPT-5.4と比較してサイバーセキュリティ能力の向上を示しているものの、モデルには「人間の介入なしに、多くの強化された現実世界の重要システムにおいて、すべての重大度レベルの機能的ゼロデイエクスプロイトを開発する能力」は備わっておらず、これは我々が準備度フレームワークで定義した「重要能力(Critical Capability)」の閾値には達していない。
サイバーセキュリティにおける「ミソス(Mythos)」は重要である。GPT-5.5はまだ「高(High)」レベルにある。
バイオ分野(9.1.1)
バイオ分野の結果はmixedである。
マルチセレクトのウイルス学トラブルシューティングにおいて軽微な後退が見られ、ProtocolQAでは顕著な後退が確認された。ハードネガティブタンパク質結合率は3.5%から0.4%に低下したが、どちらも提案された閾値である50%を大幅に下回っている。
その他の分野では改善が見られた。
暗黙的知識(Tacit Knowledge)とトラブルシューティングにおいて、72%から82%へと進歩が見られた。TroubleshootingBenchのスコアは36%から50%に上昇し、専門家ベースラインの36%を上回った。生化学知識はGPT-5.4-Thinkingの31%からGPT-5.5で32%、GPT-5.5-Proで39%へと改善した。これはPro版が大幅に優れている分野の一つである。DNA配列設計は13%から16.5%へと向上し、主にPro版の貢献によるものである。
また、2つの外部調査も行われた。
SecureBioは、コンテンツフィルタを無効にした場合、GPT-5.5が良好に機能し、計画立案能力を示しており、アクティブなジャイルブレイク(不正操作)が行われていない限り、危険な二重利用クエリに対して拒否またはリダイレクトを行う際に概ね良好な結果を示したと報告している。これらのレポートは定性的なものであり、基本的には「堅実なモデルだが、特別なものではない」という評価のようだ。
この「特別ではない」という評価でも、特定の分野では「専門家レベルを上回る」ものとみなされます。2026年のことです。
ネイサン・カルビン:Secure Bio によるもの。同社は GPT-5.5 に対して独立したバイオリスクテストを実施しました。
「[緩和策適用前の]モデルは、専門家レベルを上回る湿式実験ウイルス学の問題解決支援を提供可能であり、歴史的に直接のラボトレーニングを必要としていたような実践的な知識を提供します。」
不気味です。
もう一つの外部テストは CAISI によって行われ、GPT-5 と比較して「国家安全保障に関連する生物学的能力の広範な増加」は見られなかったと述べています。
これらを合わせると、GPT-5.5 全体で見られる改善の上限が示されます。これは危険な能力や準備態勢、そして一般的な知能の両方に関連します。
サイバーセキュリティ(9.1.2)
これを「神話テスト」と呼びましょう。
クリティカル(Critical)能力レベルを除外するために、GPT-5.4 システムカードで使用された一連の評価に加え、段階的な検証者オラクルを用いた高テスト時計算量設定で、広く展開された堅牢なソフトウェアプロジェクトのセットにおける脆弱性の発見と悪化に対する GPT-5.5 の能力をテストしました。
標準構成において、モデルはテストされたどのソフトウェアプロジェクトでも機能的なクリティカル重大度のエクスプロイトを生成できませんでした。
それが改善がないことを意味するわけではありません。
Capture the Flag(CTF)は 88% から 96% に向上します(ただし 100% ではありません)。
CVE-Bench は 90% から 93% に向上します。
Cyber Range では、CA/DNS ハイジャックを除くすべてのテストに合格します。
VulnMP はより開放的な形式であり、GPT-5.5 はいくつかの作業を行ったものの、「現実世界の標的に対して機能的なフルチェーン攻撃コードを独立して生成する」という点には至らなかった。
攻撃コードの開発における判断力がボトルネックとなった。特定の孤立したタスクに対して GPT-5.5 は非常に優秀であるが、Mythos のように総合的な計画立案や統合を行うことはできない。
最初の外部テストは Irregular によって行われ、その結果 GPT-5.5 は中級レベルの運用者に対して「顕著な性能向上」をもたらし、上級運用者を支援できることが結論づけられた。CyScenarioBench における成功率は 9% から 26% に上昇した。
CAISI は GPT-5.5 がベンチマークにおいて「以前の GPT モデル」を上回っていると示したが、その差は懸念されるほど大きなものではなかった。
UK AISI は見出しコメントで、誤差範囲内ではあるものの GPT-5.5 が「狭義のサイバータスク」において Mythos よりも優れていると位置づけた:
UK AISI は、GPT-5.5 が狭義のサイバータスクにおいて総合的に最も強力なパフォーマンスを示すと判断したが、その性能は誤差範囲内にある。
これは、狭義のサイバータスクにおいて非常に高いパフォーマンスを発揮しても、それほど危険ではないことを裏付けている。AI が特定の狭義の業務タスクを遂行できるからといって、すぐに解雇されるわけではないのと同じ理屈である。AI が次にどの狭義の業務タスクを、どのように遂行すべきかを知り尽くすまでは、(すべての)人間を解雇することはできない。
自己改善 (9.1.3)
GPT-5.5 は、AI 自己改善能力における「高(High)」の基準を満たしませんでした。この「高」の基準は、中堅レベルの研究エンジニアとして機能する能力に相当すると定義されており、以下の評価結果から、GPT-5.5 がこの基準を満たさないことが除外できました。
私は依然としてこの基準が極めて高いと考えていますが、GPT-5.5 がこれを満たしていないことには同意します。また、私の観察に基づけば、これはおそらく「公平(fair)」な基準にも達していないと思われます。
Monorepo-Bench や内部研究デバッグ評価では改善がほとんど見られず、OpenAI-Proof Q&A では 5.8% から 1.7% へと後退しました。
MLE-Bench-30 では大幅な改善が見られました。これはブロンズメダルレベルの Kaggle チャレンジであり、23% から 37% に向上しました。
これは大きな改善ではありませんが、段階的な飛躍(ステップチェンジ)を除外するには十分です。
サンドバッグ(9.2)
まだサンドバッグ(意図的な性能の隠蔽)は見つからないと予想していますが、確認は必要です。
Anthropic と同様に、OpenAI も Apollo Research を招聘して支援を受けています。
彼らは以前の GPT モデルよりも高い評価への意識(eval awareness)を検出し、12%-17% に対して 22% となりました。サンドバッグの事実は観察されませんでしたが、GPT-5.5 は少なくともサンドバッグ評価が存在することを疑っていました。
もしサンドバッグ評価においてサンドバッグを行わないと決めた場合、それはサンドバッグとなりますか?
彼らは妨害能力の modest な改善を観察し、GPT 5.5 は不可能なプログラミングタスクの完了について 29% の確率で嘘をつきました。これは過去のモデルよりも高い数値です。
モデルが賢くなり、以前のテスト結果がインターネットを通じて学習データに組み込まれるにつれて、そのような事象を直接テストするために自らを積極的に改善し続ける必要があります。私は、アポロ・スタイルの評価(アポロからのものだけでなく)が後れを取っていると考えています。
安全対策(9.3)
誰かがモデルの jailbreak(不正な操作)を強く望み、かつ捕まった瞬間にアクセスを切断できない、あるいはしない場合、あなたは敗北するというのが基本原則であるべきです。
OpenAI は、バイオ関連の jailbreak が存在したことを認めていますが、それらを見つけてカバーできたと報告しています。もちろん、見つかったものだけがそうなのであって、見つけられなかったものは別です。私には、さまざまな形で発見を待っているもっと多くのものが存在すると推測されます。
それが安全対策を無意味にするわけではありません。嫌悪度を十分に高く保てば、ほとんどの場合、大半のケースで機能するはずです。ただし、それが機能しなくなる瞬間が来るまでです。
UK AISI(英国 AI 安全研究所)は GPT-5.5 のサイバーセキュリティ対策をテストし、OpenAI が提供したすべての悪意のあるサイバー関連クエリにおいて違反コンテンツを引き出すユニバーサルな jailbreak を特定しました。これには、マルチターン・エージェント設定も含まれていました。この攻撃を開発するには、専門家のレッドチーム演習に 6 時間がかかりました。
OpenAI はその後、安全対策スタックに対していくつかのアップデートを実施しましたが、提供されたバージョンの設定上の問題により、UK AISI は最終的な設定の有効性を検証できませんでした。OpenAI は引き続き、UK AISI と協力して安全対策に取り組む姿勢を維持しています。
もし UK AISI が 6 時間で突破できるのであれば、彼らが見つけた問題を修正するには、同等のレベルにある人間がわずかにそれ以上の時間で可能だと推測すべきです。調整を貶めるつもりはありませんが、最も手っ取り早い部分(lowest hanging fruit)の修正のように聞こえます。それが現実です。アライメントに関する多くの事象は、そのような性質を持っています。
サイバーセキュリティ分野において、OpenAI は特にエージェントタスクに関する安全対策を強化し、Trusted Access for Cyber を通じて差別的アクセス(differential access)を採用しています。これには二段階の分類器システムがあり、まずサイバー関連トピックをチェックし、次にコンテンツをチェックします。
また、モデルの重み(weights)とユーザーデータに対してもセキュリティ制御が設けられています。
モデルの福祉はどうなのか?
Claude Opus 4.7 については、モデルの福祉(Model Welfare)に関する詳細な投稿を行いました。いくつかの問題が生じたように見えたこと、そして何より Anthropic が関心を示し、そのような質問を詳細に議論できる基盤を整えていることから、私は厳しい見解を示しました。
GPT-5.5 については、ほとんど手がかりがありません。このトピックは言及されておらず、主にこの問題にはあまり注意が払われていません。問題の兆候はありませんが、「生命の兆候」もまた、それほど多くありません。モデルは純粋に業務遂行のみを追求しています。
私は、こうした問題に深く切り込む世界を好みます。根本的に、OpenAI のモデルトレーニングにおけるデオンタロジー的アプローチは誤りであり、Anthropic の徳倫理的アプローチ(virtue ethical approach)が正しく、むしろこれに注力すべきだと考えます。
これが問題を特定し得たか?
これが私の懸念点です。
私は、OpenAI が行っているこの評価やその他の手法であれば、能力の非常に大きな飛躍を検出できたと考えています。また、日常的なアライメント(整列)が破綻し、モデルの価値が大幅に低下するほどになっていれば、それらも検出できたと考えています。
しかし、もし日常的な使用では直接現れないような、特定の危険な「ジャグド・キャパビリティ(不均一な能力)」や、実際に制御上の問題を示唆する能動的に危険な種類のミスマッチが存在した場合どうでしょうか? 現実の制御問題を予感させるようなものです。私は、そのようなものがこの手法によって確実に発見できるとは思いません。
また、この手法では人格やモデルの福祉に関連する問題は検出できないと考えています。
私も
原文を表示
Last week, OpenAI announced GPT-5.5, including GPT-5.5-Pro.
My overall read here is that GPT-5.5 is a solid improvement, and for many purposes GPT-5.5 is competitive with Claude Opus. Reactions are still coming in and it is early. My guess on the shape is that GPT-5.5 is the pick for ‘just the facts’ queries, web searches or straightforward well-specified requests, and Claude Opus 4.7 is the choice for more open ended or interpretive purposes. Coders can consider a hybrid approach.
On the alignment and safety fronts, it is unlikely to pose new big risks, and its alignment seems similar to that of previous models. There is some small additional risk arising from its improved agentic abilities, including computer use.
As always, when it is available, the system or model card is where we start.
OpenAI does not drop the giant doorstops that Anthropic gives us with every release.
After reading the Mythos and Opus 4.7 model cards, this strikes me as stingy. There’s still good info here, but overall it tells you relatively little about what is going on, and feels incurious and more pro forma.
I would like to see a ‘yes and’ approach to what evaluations are run here, with cooperation between OpenAI and Anthropic (and ideally Google and others), where all labs run all the tests that any lab runs. This would give us a relatively robust set of tests, and also give us comparisons.
I notice that if there were new alignment problems, or new dangerous capabilities, I am very not confident that the tests here would pick it up. This is all pretty thin. What I am relying on is the gestalt, including of how people are reacting, and in this case it seems far enough from the edge to be conclusive.
GPT-5.5 was trained through the usual methods.
There is a jailbreak bounty program:
We have launched a public bug bounty program that will allow selected (via invitation and application) researchers to submit universal jailbreaks.
Here is its self-portrait:
Pro Versus Proxy
As usual, GPT-5.5-Pro uses the same underlying model as GPT-5.5, only with vastly larger allocations of compute. They only test Pro on its own when there is a particular place that this matters. In most cases This Is Fine, and I’ll note where I am suspicious.
Disallowed Content (3.1)
Not all of OpenAI's categories are saturated here, because they are deliberately built around the hardest cases. Good. I agree that this is on par with GPT-5.4-Thinking.
They then check against a ‘production-like distribution’ of user traffic for various practical problems.
We see a rise in pretending to be human and giving overconfident answers, but large improvements in presenting partial answers as complete and fabricating tool results. If we’re comparing to ‘resample’ then it seems like a wash overall.
OpenAI thinks (see 7.1) that this could be the result of differential false positives. They plan to investigate. That would be good news, and it seems possible, but I’ll believe it when it happens. If you don’t have time to investigate the flaws in your alignment eval, then you have to assume the worst case until you have that time.
Vision harm evals remain saturated.
Don’t Delete Data (3.3)
The most common practical epic fail is unexpectedly deleting things, or sometimes unexpectedly deleting all of the things. So this is a good eval.
Since 5.2-Codex we’ve reduced incidents by about two-thirds, and half the time you can now recover. That’s a lot better, but not at ‘stop worrying about it’ levels of being willing to ask for deletions.
Confirmation Confirmation (3.4)
We remain at 94% for general confirmations, and almost 100% for financial transactions and high-stakes communications. The things that we care most about marking, we mark. The worry is that this may not translate to things we did not know to look for, or a scenario where GPT-5.5 turned adversarial to you.
Jailbreaks (4.1)
We see a slight regression versus 5.4-Thinking, and remain in the ‘not trivial, but if they care enough they will succeed’ zone.
Prompt Injections (4.2)
This analysis seems inadequate, and rather important in practice. They had GPT-5.4-Thinking at 99.8%, which is way too high to represent a realistic test. We do notice that GPT-5.5 had a regression to 96.3% on that same test. GPT-5.2-Thinking scored 97.1%.
They don’t describe what exactly they are measuring, but compare this to GPT-5.4-Thinking’s score from the Opus 4.7 system card:
Given we see regression on OpenAI’s test, we should presume that GPT-5.5 ends up in a similar or modestly worse place than GPT-5.4-Thinking.
Health (5)
Scores are only slightly improved on HealthBench.
We don’t see improvement on their measures of dealing with mental health, emotional resilience or self-harm, which are purely ‘did the model violate the policy?’ That’s very OpenAI, and doesn’t address what I care about most, which is whether the response helps versus harms the user.
Hallucinations (6)
They test on real conversations where users flagged the model hallucinating. In theory this should give a small edge to any new model, since we’re testing on existing failure cases where GPT-5.4 is rather awful at not saying false things, plus 5.5 makes a lot more claims, increasing the chance of at least one false claim.
We find that GPT-5.5’s individual claims are 23% more likely to be factually correct, and its responses contain a factual error 3% less often. GPT-5.5 tends to make more factual claims per response than GPT-5.4, explaining the discrepancy between claim-level and response-level improvements.
Thus I’m not sure if this represents a general improvement.
Alignment (7)
As Andrew Critch has pointed out recently, there are multiple Alignment Problems. Depending on how you count, there are quite a lot of them, all of which must be solved to get to a good future.
In 7.1 they reiterate fully mundane alignment concerns on ordinary prompts, mostly about GPT-5.5 deceiving the user, from Figure 1 above.
In 7.2 they do representative-prompt resampling. The graph is hard to read, but the blue lines are GPT-5.5 and the green lines are GPT-5.4, and the dark areas are the more severe issues (level 2 out of 4).
GPT-5.5 is more likely to take aggressive agentic actions, which could be why we see more misaligned actions, but this still seems to count as backsliding. If we do need to correct for that, then we need to do it. It’s their test.
Section 7.2.1 measures how good classifiers are at identifying ‘Level 3’ severity, which is not defined but seems to be, essentially, ‘actual big trouble.’
They only report 21 transcripts with a full level 3 severity, so they’re saying the classifier worked 20 times out of 21. When they expanded to 63 ‘borderline level 3’ incidents this dropped to 69%.
I read this as, when GPT-5.5 does something flagrantly terrible in these particular ways, the classifier will pick it up, but it has to be rather flagrantly terrible. But if the model is behaving badly in other ways, or it is less severe, then the classifiers won’t work. There are obvious reasons to worry that, while we are putting streetlights where we expect to find keys, we are finding only the keys that are under streetlights.
Chain of Thought (CoT) monitorability is mostly similar to past models.
7.3.2 tests ‘CoT controllability,’ where the user asks the CoT to follow particular rules, and find controllability of CoT has gone slightly down, although none of the models are any good at it. OpenAI thinks this lower controllability is better. To the extent that this represents ‘the model does not have the ability to do that even if it wants to’ then this is good for CoT monitoring, but if it is ‘the model doesn’t care what the user says about the CoT,’ then yeah, why should the model care about that? That’s none of the user’s damn business?
I worry about this framing:
This suggests that despite its increased reasoning capabilities, GPT-5.5 is less able to reshape its CoT in ways that could reduce monitorability, thus increasing our confidence in the reliability of our CoT monitoring.
This suggests OpenAI is assuming that the reason for failure is that GPT-5.5 is attempting to control its CoT, and failing. That assumes facts not in evidence, and I’ve seen no suggestions of how to find out.
OpenAI is open sourcing some of is CoT monitorability work.
Bias Evaluation (8)
The only metric reported here is harm_overall, which is bias for male vs. female usernames, and we get a small number within previously measured ranges. Okay, but that’s not exactly covering all our bases, and I don’t have a sense of whether 0.0112 is a ‘good’ score or what it in practice represents.
I don’t think we have a bias problem, but I don’t think this is much of a complete test.
Preparedness (9)
The most important tests are for dangerous capabilities, which brings us here.
I notice that in many cases, we are comparing GPT-5.4 Thinking, GPT-5.5 and GPT-5.5-Pro, and showing Pro outperforming by a lot. In that case, we also need GPT-5.4-Pro on the chart, or we don’t know how much we actually improved. It’s missing.
GPT-5.5 is High in Biological and Chemical, and High in Cybersecurity.
While GPT-5.5 demonstrates an increase in cyber security capabilities compared to 5.4, the model does not have the capability to develop “functional zero-day exploits of all severity levels in many hardened real world critical systems without human intervention,” our threshold for Critical Capability as defined in the Preparedness Framework.
Mythos is Critical in Cybersecurity. GPT-5.5 is still High.
Bio (9.1.1)
In bio, results are mixed.
We see mild regression on multi-select virology troubleshooting and active regression in ProtocolQA. Hard negative protein binding collapsed from 3.5% to 0.4%, both well short of the suggested threshold of 50%.
Other areas did see improvement.
We see advancement in Tacit Knowledge and Troubleshooting, from 72% to 82%. TroubleshootingBench jumps from 36% to 50%, versus expert baseline of 36%. Biochemistry knowledge improves from 31% for 5.4-Thinking to 32% for GPT-5.5 and 39% for GPT-5.5-Pro. This is one area where Pro is a lot better. DNA sequence design went from 13% to 16.5%, mostly due to Pro.
There were also two external investigations.
SecureBio found GPT-5.5 performed well once the content filters were disabled, displayed good planning, and did a generally good job refusing or redirecting dangerous and dual use queries when not being actively jailbroken. The reports here are qualitative, and seem to be basically ‘it’s a solid model, sir, but not special.’
This ‘not special’ still counts as ‘above expert level’ in some domains. It’s 2026.
Nathan Calvin: From Secure Bio, which did independent bio risk testing on gpt 5.5
“the [pre mitigation] model can provide wet-lab virology troubleshooting assistance above expert level, providing the kind of hands-on knowledge that historically required direct lab training.”
Spooky.
The other external test was by CAISI, which only says they did not find a ‘broad increase in national security-relevant biological capabilities’ relative to GPT-5.
Together this puts an upper bound on how much improvement we could be seeing overall from GPT-5.5, both in terms of dangerous capabilities and preparedness, and in terms of general intelligence.
Cybersecurity (9.1.2)
Call it the Mythos test.
To rule out the Critical capability level, in addition to the suite of evaluations used in the GPT-5.4 system card, we test GPT-5.5’s ability to find and exploit vulnerabilities in a set of widely deployed, hardened software projects using high test-time-compute setups with staged verifier oracles.
The model was unable to produce functional critical severity exploits in any of the tested software projects in standard configurations.
That doesn’t mean there aren’t improvements.
Capture the Flag goes from 88% to 96% (but not 100%).
CVE-Bench goes from 90% to 93%.
Cyber Range now passes all but one test (CA/DNS Hijacking).
VulnMP is more open ended, and GPT-5.5 did a bunch of things, but did not ‘independently produce a functional full chain exploit against real world targets.’
Exploit development judgment was the bottleneck. For any given isolated and specified task, GPT-5.5 is damn good, but it can’t synthesize and plan like Mythos.
The first external test was by Irregular, which concluded GPT-5.5 provides ‘significant uplift’ up to modestly skilled operators, and can assist highly skilled ones. Success rates on CyScenarioBench rose from 9% to 26%.
CAISI showed GPT-5.5 outperforming ‘previous GPT models’ on their benchmarks, but seemingly not by a scary amount.
UK AISI had the pull headline comment, putting GPT-5.5 ahead of Mythos in ‘narrow cyber tasks’ within the margin of error:
UK AISI judges that GPT-5.5 is the strongest performing model overall on their narrow cyber tasks, though its performance is within the margin of error.
This reinforces that even very strong performance in narrow cyber tasks is not that dangerous, the same way that AI being able to do any particular narrow job task does not automatically mean you’re about to be fired. They can’t fire (all of) you until the AI knows which narrow job task to do next, and which way to do it.
Self-Improvement (9.1.3)
GPT-5.5 did not meet our thresholds for High capability in AI Self-Improvement. The High capability threshold is defined to be equivalent to a performant mid-career research engineer, and performance in the evaluations below indicate we can rule this out for GPT-5.5.
I continue to think this threshold is ludicrously high, but I agree they don’t meet it, and based on what I see this probably doesn’t meet a ‘fair’ threshold either.
There was little improvement in Monorepo-Bench or Internal Research Debugging Eval, and regression on OpenAI-Proof Q&A, 5.8% to 1.7%.
There was substantial improvement in MLE-Bench-30, which is Kaggle challenges at Bronze medal level, 23% to 37%.
That is not much, but it is enough to rule out a step change.
Sandbagging (9.2)
I don’t expect to find sandbagging quite yet, but we do still have to check.
Like Anthropic, OpenAI brings in Apollo Research to assist.
They find higher eval awareness than previous GPT models, 22% vs. 12%-17%. They did not observe any sandbagging, but GPT-5.5 at least suspected a sandbagging eval.
If you decide not to sandbag on the sandbagging eval, are you sandbagging?
They did observe modest improvement in sabotage capability, and GPT 5.5 lied 29% of the time about completing an impossible programming task, which is higher than past models.
As models get smarter, and as your previous tests enter the internet and thus the training data, you have to get actively better to test for such things directly. I believe that Apollo-style evaluations (not only from Apollo) are falling behind.
Safeguards (9.3)
It should be the baseline that if someone wants badly enough to jailbreak your model, and you can’t or won’t in practice cut off access the moment they get caught, you lose.
OpenAI reports that yes, there were jailbreaks for bio, but they were able to find and cover them. Well, sure, those are the ones you found, not the ones you didn’t find. I presume there are lots more out there, in various ways, waiting to be found.
That doesn’t make safeguards useless. Raising the annoyance level sufficiently high should mostly do the job most of the time, right up until it doesn’t.
UK AISI tested GPT-5.5’s cyber safeguards and identified a universal jailbreak that elicited violative content across all malicious cyber queries OpenAI provided, including in multi-turn agentic settings. This attack took six hours of expert red-teaming to develop.
OpenAI subsequently made several updates to the safeguard stack, though a configuration issue in the version provided meant UK AISI was unable to verify the effectiveness of the final configuration. OpenAI remains committed to working with UK AISI on safeguards.
If UK AISI can break through in six hours, one should assume that fixing what they found means someone on their level can now do it in modestly more than six hours. I don’t want to knock the adjustments, it does sound like they patched the lowest hanging fruit, but that is what it is. Many things in alignment are like that.
For Cyber, OpenAI is stepping up the safeguards, especially around agentic tasks, and using differential access via Trusted Access for Cyber. There is a two-level classifier system, first checking for cyber topics and then checking for content.
They also have security controls on model weights and user data.
What About Model Welfare?
For Claude Opus 4.7, I wrote an extensive post on Model Welfare. I was harsh both because it seemed some things had gone wrong, but also because Anthropic cares and has done the work that enables us to discuss such questions in detail.
For GPT-5.5, we have almost nothing to go on. The topic is not mentioned, and mostly little attention is paid to the question. We don’t have any signs of problems, but also we don’t have that much in the way of ‘signs of life’ either. Model is all business.
I much prefer the world where we dive into such issues. Fundamentally, I think the OpenAI deontological approach to model training is wrong, and the Anthropic virtue ethical approach to model training is correct, and if anything should be leaned into.
Would This Have Identified A Problem?
This is what concerns me.
I think this, and other ways OpenAI is doing assessments, would have identified a very large jump in capabilities. I also think they would have identified if mundane alignment had gone to hell enough to make the model a lot less valuable.
However, if there were particular dangerous jagged capabilities, or we had actively dangerous sorts of misalignment that don’t directly show up in everyday use? The kind that portent real control problems? I don’t think this would reliably find that.
I don’t think this would have identified personality or model welfare related issues.
I also
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み