エージェント・ハネスの解剖学
LangChain Blog は、モデルそのものではなく、状態管理やツール実行などを担う「Harness(ハルネス)」の概念を定義し、AI エージェントを構築する際の設計指針を示した。
キーポイント
Agent の構成要素としての Harness の定義
エージェントは「モデル+ハルネス」で構成され、ハルネスとはモデル自体以外のすべてのコード、設定、実行ロジック(プロンプト、ツール、インフラ、オーケストレーションなど)を指す。
モデル単体では不可能な機能の実現
LLM は本来状態維持やコード実行ができないため、ハルネスがこれらを補完することで実用的なエージェントとして機能するようになる。
システム設計の明確化と境界線引き
モデルとハルネスの境界を明確に定義することで、モデルの知能を最大限に活用しつつ、必要な機能を外部から付与する設計思考が促進される。
具体的な Harness の構成要素
システムプロンプト、ツール・スキル定義、ファイルシステムやブラウザなどのインフラ、サブエージェントの生成ロジックなどがハルネスに含まれる。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェント開発における設計思想を明確化し、単なるプロンプトエンジニアリングからシステム全体のアーキテクチャ設計へと視座を高める重要な指針となる。特に LangChain のようなフレームワークを利用する開発者にとって、エージェントの構成要素を体系的に理解し、堅牢なシステムを構築するための基礎理論として広く参照されるだろう。
編集コメント
「モデル以外すべてがハルネス」という定義は、複雑化するエージェントシステムの責任分界点を明確にする優れた視点です。開発者はこの概念を基に、よりモジュール化された堅牢なシステム設計を進めるべきでしょう。
著者:ヴィヴェク・トリヴェーディ
要約:エージェント=モデル+ハルネス。ハルネスエンジニアリングとは、モデルの周りにシステムを構築してそれらを作業エンジンに変える方法です。モデルは知能を含み、ハルネスはその知能を実用的なものにします。
今日および明日のエージェントに必要なコアコンポーネントを定義し、導出します。
「ハルネス」とは何か、誰かが定義してください
エージェント=モデル+ハルネス
あなたがモデルでなければ、あなたはハルネスです。
ハルネスとは、モデル自体以外のすべてのコード、設定、実行ロジックの断片です。生粋のモデルはエージェントではありません。しかし、ハルネスが状態、ツール実行、フィードバックループ、強制可能な制約などを提供すると、それはエージェントになります。
具体的には、ハルネスには以下のようなものが含まれます:
- システムプロンプト
- ツール、スキル、MCP(Model Context Protocol)およびその説明
- 統合インフラストラクチャ(ファイルシステム、サンドボックス、ブラウザ)
- オーケストレーションロジック(サブエージェントの生成、ハンドオフ、モデルルーティング)
- 決定論的実行のためのフック/ミドルウェア(圧縮、継続、リンティングチェック)
エージェントシステムの境界をモデルとハルネスの間で分割する方法は、ごちゃごちゃとしたものがたくさんあります。しかし、私の意見では、これは最もクリーンな定義です。なぜなら、それは私たちにモデルの知能を中心にシステムを設計することを強いるからです。
この投稿の残りの部分では、コアハルネスコンポーネントを walkthrough し、モデルのコアプリミティブから逆算して、各ピースがなぜ存在するのかを導出します。
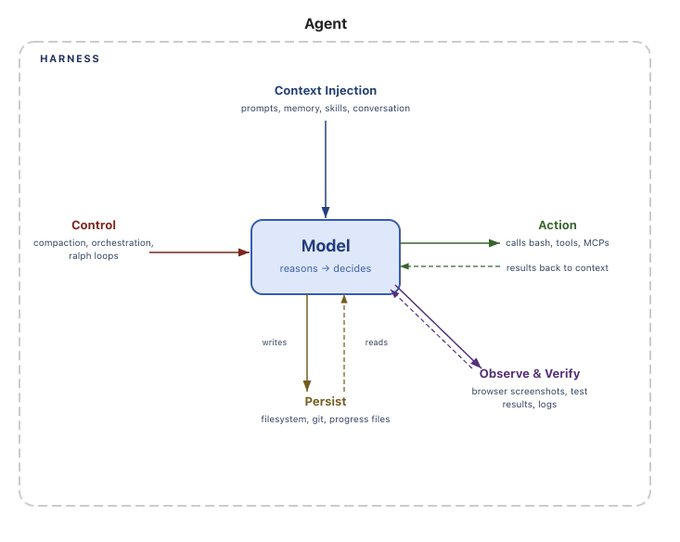
なぜハルネス(Harness)が必要なのか。モデルの視点から
エージェントに実行してほしいタスクの中には、モデル単体では実現できないものがあります。ここでハルネスの出番です。 モデルは主にテキスト、画像、音声、動画などのデータを入力として受け取り、テキストを出力します。それだけです。標準状態(Out of the box)では、以下のことができません:
- 対話間をまたいで永続的な状態(State)を維持する
- コードを実行する
- リアルタイムの知識にアクセスする
- 作業を完了するために環境を設定し、パッケージをインストールする
これらはすべてハルネスレベルの機能です。大規模言語モデル(LLM)の構造上、有用な作業を行うためにそれらを包み込む何らかの機械装置が必要です。例えば、「チャット」のような製品ユーザー体験(UX)を実現するには、以前のメッセージを追跡し新しいユーザーのメッセージを追加するwhileループでモデルをラップします。これを読んでいる方はみな、すでにこのようなハルネスを使用したことがあるでしょう。主要なアイデアは、望ましいエージェントの振る舞いをハルネス内の実際の機能に変換することです。
望ましいエージェントの振る舞いから逆算してハルネスエンジニアリングを行う
ハルネスエンジニアリングは、エージェントの振る舞いをガイドするために人間が有用な事前知識(Priors)を注入することを支援します。そして、モデルの能力が高まるにつれて、ハルネスは以前不可能だったタスクを完了するために、モデルを手術のように拡張・修正するために使用されてきました。
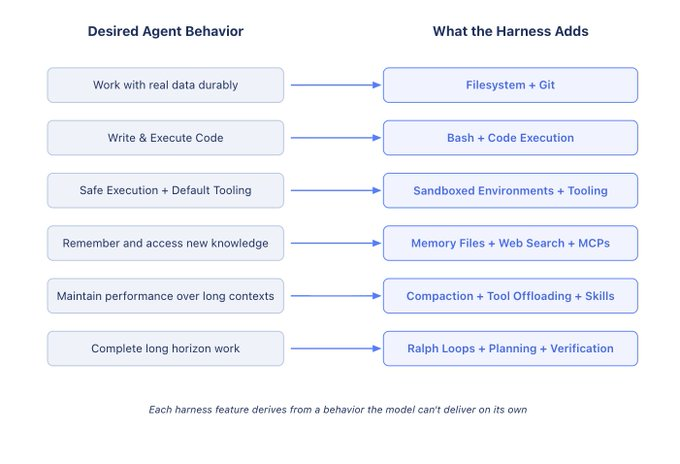
ハルネスの機能の網羅的なリストをすべて取り上げるわけではありません。目標は、モデルが有用な作業を行うのを支援するという出発点から一連の機能を導き出すことです。私たちは以下のようなパターンに従います:
私たちが望む行動(または修正したい行動)→ その目標をモデルが達成できるよう支援するハースの設計。
耐久性のあるストレージとコンテキスト管理のためのファイルシステム
エージェントには、実データとのインターフェース、コンテキストに収まらない情報のオフロード、セッションを跨ぐ作業の永続化を実現するための耐久性のあるストレージを持たせたい。
モデルは、コンテキストウィンドウ内の知識に対してのみ直接操作を行うことができます。ファイルシステムが存在する以前は、ユーザーがモデルにコンテンツを直接コピー&ペーストする必要がありましたが、これは使い勝手の悪いUXであり、自律型エージェントには適していませんでした。世界はすでにファイルシステムを使用して作業を行っていたため、モデルはそれらの使用方法に関する数十億のトークンで自然に学習していました。したがって、自然な解決策は以下のようになりました。
ハースにはファイルシステムの抽象化とfs-ops(ファイルシステム操作)のツールが含まれて出荷されます。
ファイルシステムは、それが解き放つ可能性ゆえに、おそらく最も基礎的なハースのプリミティブ(基本要素)と言えます。
- エージェントは、データ、コード、ドキュメントを読み取るためのワークスペースを与えられます。
- 作業はコンテキスト内にすべてを保持するのではなく、段階的に追加したりオフロードしたりできます。エージェントは中間出力を保存し、単一のセッションを超えて状態を維持することができます。
- ファイルシステムは自然な協調の場です。複数のエージェントや人間が共有ファイルを通じて調整できます。「Agent Teams」のようなアーキテクチャはこれに依存しています。
Git はファイルシステムにバージョン管理を追加し、エージェントが作業を追跡し、エラーをロールバックし、実験を分岐できるようにします。後ほどファイルシステムについて再検討しますが、それは私たちが必要とする他の機能のための主要なハーンネスのプリミティブであることが判明しました。
汎用ツールとしての Bash + コード
私たちは、人間がすべてのツールを事前に設計する必要なく、エージェントが自律的に問題を解決できるようにしたいと考えています。
現在の主要なエージェント実行パターンは ReAct ループ です。これは、モデルが推論し、ツール呼び出しを通じてアクションを実行し、結果を観察し、while ループ内で繰り返すものです。しかし、ハーンネスは論理を持つツールしか実行できません。ユーザーがすべての可能なアクションに対してツールを構築することを強いるのではなく、bash のような汎用ツールをエージェントに与える方がより良い解決策です。
ハーンネスには bash ツールが含まれており、モデルはコードの記述と実行により自律的に問題を解決できます。
Bash とコード実行は、モデルにコンピュータを与え、残りの作業を自律的に解決させるという大きな一歩です。モデルは事前に設定された固定のツールセットに制約されるのではなく、コードを通じてその場で独自のツールを設計できます。
ハネスには他のツールも付属していますが、コード実行は自律的な問題解決のためのデフォルトの汎用戦略となっています。
作業の実行と検証のためのサンドボックスとツール
エージェントは、安全に行動し、結果を観察し、進捗を遂げられるよう、適切なデフォルト設定が施された環境を必要とします。
モデルにストレージとコード実行能力を与えましたが、それらはどこかで行われる必要があります。エージェントが生成したコードをローカルで実行するのはリスクが高く、単一のローカル環境では大規模なエージェントのワークロードを処理できません。
サンドボックスは、エージェントに安全な動作環境を提供します。 ローカルで実行するのではなく、ハネスはサンドボックスに接続してコードを実行し、ファイルを検査し、依存関係をインストールし、タスクを完了させることができます。これにより、コードの安全で隔離された実行が可能になります。さらにセキュリティを高めるため、ハネスはコマンドのホワイトリスト化やネットワークの分離を実施できます。また、サンドボックスはスケーラビリティも実現します。環境は必要に応じて作成でき、多数のタスクに分散展開され、作業が完了すれば削除されます。
優れた環境には、適切なデフォルトのツールチェーンが付随しています。 ハーネスはエージェントが有用な作業を行えるよう、ツールチェーンの構成を担当します。これには、言語ランタイムやパッケージの事前インストール、git やテスト用のコマンドラインインターフェース(CLI)、ブラウザ(Web 上の対話と検証用)が含まれます。
ブラウザ、ログ、スクリーンショット、テストランナーなどのツールは、エージェントが自身の作業を観察・分析するための手段を提供します。これにより、アプリケーションコードの記述、テストの実行、ログの確認、エラーの修正 を行う 自己検証ループ を構築することが可能になります。
モデルは、初期状態では自身の実行環境を構成しません。エージェントの実行場所、利用可能なツール、アクセス権限、作業の検証方法といった決定は、すべてハーネスレベルでの設計判断です。
継続的学習のためのメモリと検索機能
エージェントは、自身の学習時に存在しなかった情報にアクセスし、過去に見た情報を記憶できる必要があります。
モデルが持つ知識は、重み(weights)と現在のコンテキストに含まれる情報の範囲を超えません。モデルの重みを編集するアクセス権限がない場合、「知識を追加」できる唯一の方法は コンテキストの注入 です。
メモリに関して言えば、ファイルシステムは再び中核的なプリミティブです。ハルセスはエージェント開始時にコンテキストに注入される AGENTS.md などのメモリファイル標準をサポートしています。エージェントがこのファイルを追加・編集すると、ハルセスは更新されたファイルをコンテキストに読み込みます。これは一種の 継続的学習 の形態であり、エージェントがセッション間で知識を永続的に保存し、その知識を将来のセッションに注入します。
知識のカットオフ(知識限界)により、モデルは更新されたライブラリバージョンなどの新しいデータにユーザーが直接提供しない限りアクセスできません。最新の知識を得るために、Web Search や Context7 などの MCP ツールは、エージェントがトレーニング終了時に存在しなかった新しいライブラリバージョンや現在のデータなど、知識カットオフを超えた情報にアクセスするのを支援します。
最新のコンテキストを照会するための Web Search やツールは、ハルセスに組み込むべき有用なプリミティブです。
コンテキスト劣化との戦い
エージェントのパフォーマンスは作業の進行に伴って低下すべきではありません。
コンテキスト劣化 は、コンテキストウィンドウが埋まるにつれてモデルの推論能力やタスク完了能力が低下する現象を指します。コンテキストは貴重で限られたリソースであるため、ハルセスにはそれを管理する戦略が必要です。
現在のハルセスは、主に優れたコンテキストエンジニアリングの配信手段です。
コンパクションは、コンテキストウィンドウがほぼ一杯になった場合にどう対処するかという問題に対応します。コンパクションを行わない場合、会話がコンテキストウィンドウの容量を超えたときどうなるでしょうか?一つの選択肢はAPIがエラーを返すことで、これは望ましくありません。そのため、ハースはこのケースに対応する何らかの戦略を使用する必要があります。したがって、コンパクションは既存のコンテキストウィンドウを賢明にオフロードして要約し、エージェントが作業を継続できるようにします。
ツール呼び出しのオフロードは、有用な情報を提供せずにノイズとしてコンテキストウィンドウを混乱させるような大きなツール出力の影響を軽減するのに役立ちます。ハースは、トークン数が閾値を超えるツール出力の先頭と末尾のトークンを保持し、完全な出力をファイルシステムにオフロードします。これにより、モデルが必要に応じてそれらにアクセスできるようになります。
スキルは、エージェント開始時にコンテキストに読み込まれるツールやMCPサーバーが多すぎるとパフォーマンスが低下するという問題に対応します。スキルは、プログレッシブ・ディスクロージャー(段階的開示)を通じてこれを解決するハースレベルのプリミティブです。モデルは開始時にスキル用のフロントマターがコンテキストに読み込まれるよう選択していませんでしたが、ハースはこれに対応することで、モデルがコンテキストの劣化(コンテキスト・ロット)から保護されるようにします。
長期自律実行
私たちは、エージェントが複雑な作業を、自律的に、正確に、長期間にわたって完了することを望みます。
自律的なソフトウェアの生成は、コーディングエージェントにとって聖杯のような存在です。しかし、現在のモデルは早期終了や複雑な問題の分解に関する課題、そして作業が複数のコンテキストウィンドウにまたがる際の整合性の欠如という問題を抱えています。優れたハネスは、これらすべてを設計の中心に据える必要があります。
ここで、前述のハネスの基礎要素が複合的に作用し始めます。長期にわたる作業には、複数のコンテキストウィンドウにまたがって作業を継続するために、永続的な状態管理、計画策定、観察、検証が必要です。
セッションをまたいで作業を追跡するためのファイルシステムとgit。 エージェントは長時間のタスクにおいて数百万トークンを生成するため、ファイルシステムは時間経過に伴う進捗を追跡するために作業を永続的に保存します。gitを追加することで、新しいエージェントがプロジェクトの最新作業と履歴を素早く把握し、状況に追いつくことができます。複数のエージェントが共同で作業する場合、ファイルシステムはさらに、エージェントがお互いに協力できる作業の共有台帳としても機能します。
作業を継続するためのRalphループ。 The Ralph Loop は、フックを通じてモデルの終了試行をインターセプトし、クリーンなコンテキストウィンドウ内で元のプロンプトを再注入することで、完了目標に対してエージェントの作業を強制し続けるハネスパターンです。ファイルシステムによりこれが可能になります。各イテレーションは新鮮なコンテキストから開始されますが、前のイテレーションからの状態を読み取ります。
計画策定と自己検証による軌道維持。 計画策定とは、モデルが目標を一連のステップに分解するプロセスです。ハッシュは適切なプロンプトと、ファイルシステム内の計画ファイルの使用方法に関するリマインダーを注入することでこれをサポートします。各ステップを完了した後、エージェントは自己検証を通じて作業の正しさをチェックすることから恩恵を受けます。ハッシュ内のフックは事前に定義されたテストスイートを実行し、失敗した場合はエラーメッセージとともにモデルにループバックするか、またはモデルに対してコードを独立して自己評価するようプロンプトを与えることができます。検証はソリューションを検証に基づき grounding し、自己改善のためのフィードバックシグナルを生成します。
ハッシュの未来
モデルトレーニングとハッシュ設計の結合
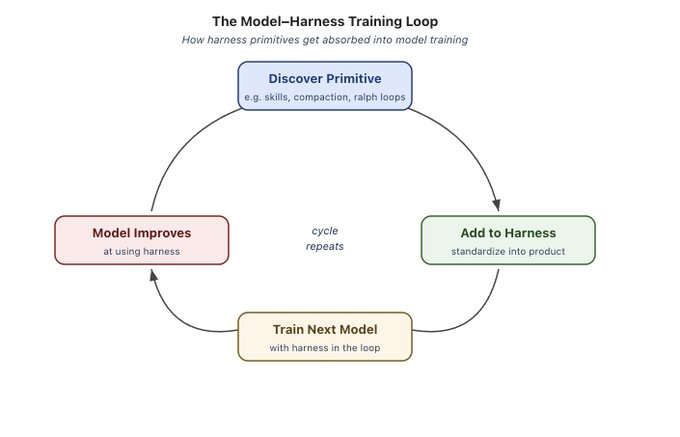
Claude Code や Codex などの今日のエージェント製品は、モデルとハッシュをループに乗せた後トレーニング(post-training)が行われます。これにより、モデルはファイルシステム操作、bash 実行、計画策定、またはサブエージェントとの並列作業など、ハッシュ設計者がモデルが元々得意とするべきと考えるアクションにおいて改善されます。
これはフィードバックループを生み出します。有用なプリミティブが発見され、ハッシュに追加され、その後次世代のモデルをトレーニングする際に使用されます。このサイクルが繰り返されるにつれて、モデルは自身がトレーニングされたハッシュ内でより高度な能力を発揮するようになります。
しかし、この共進化は汎化において興味深い副作用をもたらします。ツールのロジックを変更するとモデルのパフォーマンスが低下するという現象として現れます。ファイル編集のための apply_patch ツールのロジックに関する例が、Codex-5.3 プロンプティングガイドで詳しく説明されています。真に知能の高いモデルであれば、パッチ方法の切り替えはそれほど難しくないはずですが、ループ内にハーンネス(検証環境)を組み込んでトレーニングを行うことで、この過学習が生じます。
しかし、これはあなたのタスクにとって最適なハーンネスが、モデルのポストトレーニング(微調整)時に使用されたものとは限らないことを意味しません。 The Terminal Bench 2.0 リーダーボード はその良い例です。Claude Code における Opus 4.6 のスコアは、他のハーンネスでの Opus 4.6 よりも大幅に低いものです。以前のブログ で、ハーンネスを変更しただけで、Terminal Bench 2.0 における当社のコーディングエージェントのトップ30位がトップ5位に改善されたことを示しました。タスクに合わせてハーンネスを最適化することには、まだ大きな余地があります。
ハーネスエンジニアリングの行先
モデルの能力が向上するにつれて、現在のハーネスに含まれる機能の一部はモデル内部に吸収されていくでしょう。モデルは計画立案、自己検証、長期の一貫性といった能力をネイティブに向上させ、その結果、コンテキストの注入などへの依存は減少します。
これは時間とともにハーネスの重要性が低下することを示唆しています。しかし、プロンプトエンジニアリングが今日でも価値を持ち続けるのと同様に、ハーネスエンジニアリングは優れたエージェントを構築し続けるために有用であり続けると思われます。
確かに、現在のハーネスはモデルの欠点を補完する役割を果たしていますが、それと同時にモデルの知能を取り囲むシステムを設計し、より効果的なものへと作り上げています。適切に構成された環境、適切なツール、堅牢な状態管理、そして検証ループは、モデルの基礎的な知能のレベルに関わらず、あらゆるモデルをより効率的にします。
ハーネスエンジニアリングは非常に活発な研究領域であり、LangChainでは私たちのハーネス構築ライブラリ deepagents を改善するためにこれを活用しています。以下は、現在探求しているいくつかのオープンで興味深い問題です:
- 共有コードベース上で並列動作する数百のエージェントをオーケストレーションすること
- 自身のトレースを分析し、ハーネスレベルの失敗モードを特定して修正するエージェント
- 事前に設定されるのではなく、特定のタスクに対して必要なツールとコンテキストをその場(ジャストインタイム)で動的に組み立てるハーネス
このブログ記事は、ハーネスとは何か、そしてモデルに求める作業によってそれがどのように形作られるかを定義する試みでした。
モデルには知性が含まれており、ハネスはその知性を有用にするシステムです。
より良いハネスの構築、より優れたシステム、そしてより高性能なエージェントへ向けて。
原文を表示
*By Vivek Trivedy*
TLDR: Agent = Model + Harness. Harness engineering is how we build systems around models to turn them into work engines. The model contains the intelligence and the harness makes that intelligence useful. We define what a harness is and derive the core components today's and tomorrow's agents need.
Can Someone Please Define a "Harness"?
Agent = Model + Harness
If you're not the model, you're the harness.
A harness is every piece of code, configuration, and execution logic that isn't the model itself. A raw model is not an agent. But it becomes one when a harness gives it things like state, tool execution, feedback loops, and enforceable constraints.
Concretely, a harness includes things like:
- System Prompts
- Tools, Skills, MCPs + and their descriptions
- Bundled Infrastructure (filesystem, sandbox, browser)
- Orchestration Logic (subagent spawning, handoffs, model routing)
- Hooks/Middleware for deterministic execution (compaction, continuation, lint checks)
There are many messy ways to split the boundaries of an agent system between the model and the harness. But in my opinion, this is the cleanest definition because it forces us to think about designing systems around model intelligence.
The rest of this post walks through core harness components and derives *why* each piece exists working backwards from the core primitive of a model.
Why Do We Need Harnesses. From a Model's Perspective
There are things we want an agent to do that a model cannot do out of the box. This is where a harness comes in.Models (mostly) take in data like text, images, audio, video and they output text. That's it. Out of the box they cannot:
- Maintain durable state across interactions
- Execute code
- Access realtime knowledge
- Setup environments and install packages to complete work
These are all harness level features. The structure of LLMs requires some sort of machinery that wraps them to do useful work.For example, to get a product UX like "chatting", we wrap the model in a while loop to track previous messages and append new user messages. Everyone reading this has already used this kind of harness. The main idea is that we want to convert a desired agent behavior into an actual feature in the harness.
Working Backwards from Desired Agent Behavior to Harness Engineering
Harness Engineering helps humans inject useful priors to guide agent behavior. And as models have gotten more capable, harnesses have been used to surgically extend and correct models to complete previously impossible tasks.
We won’t go over an exhaustive list of every harness feature. The goal is to derive a set of features from the starting point of helping models do useful work. We’ll follow a pattern like this:
Behavior we want (or want to fix) → Harness Design to help the model achieve this.
Filesystems for Durable Storage and Context Management
We want agents to have durable storage to interface with real data, offload information that doesn't fit in context, and persist work across sessions.
Models can only directly operate on knowledge within their context window. Before filesystems, users had to copy/paste content directly to the model, that’s clunky UX and doesn't work for autonomous agents. The world was already using filesystems to do work so models were naturally trained on billions of tokens of how to use them. The natural solution became:
Harnesses ship with filesystem abstractions and tools for fs-ops.
The filesystem is arguably the most foundational harness primitive because of what it unlocks:
- Agents get a workspace to read data, code, and documentation.
- Work can be incrementally added and offloaded instead of holding everything in context. Agents can store intermediate outputs and maintain state that outlasts a single session.
- The filesystem is a natural collaboration surface. Multiple agents and humans can coordinate through shared files. Architectures like Agent Teams rely on this.
Git adds versioning to the filesystem so agents can track work, rollback errors, and branch experiments. We revisit the filesystem more below, because it turns out to be a key harness primitive for other features we need.
Bash + Code as a General Purpose Tool
We want agents to autonomously solve problems without humans needing to pre-design every tool.
The main agent execution pattern today is a ReAct loop, where a model reasons, takes an action via a tool call, observes the result, and repeats in a while loop. But harnesses can only execute the tools they have logic for. Instead of forcing users to build tools for every possible action, a better solution is to give agents a general purpose tool like bash.
Harnesses ship with a bash tool so models can solve problems autonomously by writing & executing code.
Bash + code exec is a big step towards giving models a computer and letting them figure out the rest autonomously. The model can design its own tools on the fly via code instead of being constrained to a fixed set of pre-configured tools.
Harnesses still ship with other tools, but code execution has become the default general-purpose strategy for autonomous problem solving.
Sandboxes and Tools to Execute & Verify Work
Agents need an environment with the right defaults so they can safely act, observe results, and make progress.
We've given models storage and the ability to execute code, but all of that needs to happen somewhere. Running agent-generated code locally is risky and a single local environment doesn’t scale to large agent workloads.
Sandboxes give agents safe operating environments. Instead of executing locally, the harness can connect to a sandbox to run code, inspect files, install dependencies, and complete tasks. This creates secure, isolated execution of code. For more security, harnesses can allow-list commands and enforce network isolation. Sandboxes also unlock scale because environments can be created on demand, fanned out across many tasks, and torn down when the work is done.
Good environments come with good default tooling. Harnesses are responsible for configuring tooling so agents can do useful work. This includes pre-installing language runtimes and packages, CLIs for git and testing, browsers for web interaction and verification.
Tools like browsers, logs, screenshots, and test runners give agents a way to observe and analyze their work. This helps them create self-verification loops where they can write application code, run tests, inspect logs, and fix errors.
The model doesn’t configure its own execution environment out of the box. Deciding where the agent runs, what tools are available, what it can access, and how it verifies its work are all harness-level design decisions.
Memory & Search for Continual Learning
Agents should remember what they've seen and access information that didn't exist when they were trained.
Models have no additional knowledge beyond their weights and what's in their current context. Without access to edit model weights, the only way to "add knowledge" is via context injection.
For memory, the filesystem is again a core primitive. Harnesses support memory file standards like AGENTS.md which get injected into context on agent start. As agents add and edit this file, harnesses load the updated file into context. This is a form of continual learning where agents durably store knowledge from one session and inject that knowledge into future sessions.
Knowledge cutoffs mean that models can't directly access new data like updated library versions without the user providing them directly. For up-to-date knowledge, Web Search and MCP tools like Context7 help agents access information beyond the knowledge cutoff like new library versions or current data that didn't exist when training stopped.
Web Search and tools for querying up-to-date context are useful primitives to bake into a harness.
Battling Context Rot
Agent performance shouldn’t degrade over the course of work.
Context Rot describes how models become worse at reasoning and completing tasks as their context window fills up. Context is a precious and scarce resource, so harnesses need strategies to manage it.
Harnesses today are largely delivery mechanisms for good context engineering.
Compaction addresses what to do when the context window is close to filling up. Without compaction, what happens when a conversation exceeds the context window? One option is that the API errors, that’s not good. The harness has to use some strategy for this case. So compaction intelligently offloads and summarizes the existing context window so the agent can continue working.
Tool call offloading helps reduce the impact of large tool outputs that can noisily clutter the context window without providing useful information. The harness keeps the head and tail tokens of tool outputs above a threshold number of tokens and offloads the full output to the filesystem so the model can access it if needed.
Skills address the issue of too many tools or MCP servers loaded into context on agent start which degrades performance before the agent can start working. Skills are a harness level primitive that solve this via progressive disclosure. The model didn't choose to have Skill front-matter loaded into context on start but the harness can support this to protect the model against context rot.
Long Horizon Autonomous Execution
We want agents to complete complex work, autonomously, correctly, over long time horizons.
Autonomous software creation is the holy grail for coding agents. But today's models suffer from early stopping, issues decomposing complex problems, and incoherence as work stretches across multiple context windows. A good harness has to design around all of this.
This is where the earlier harness primitives start to compound. Long-horizon work requires durable state, planning, observation, and verification to keep working across multiple context windows.
Filesystems and git for tracking work across sessions. Agents produce millions of tokens over a long task so the filesystem durably captures work to track progress over time. Adding git allows new agents to quickly get up to speed on the latest work and history of the project. For multiple agents working together, the filesystem also acts as a shared ledger of work where agents can collaborate.
Ralph Loops for continuing work. The Ralph Loop is a harness pattern that intercepts the model's exit attempt via a hook and reinjects the original prompt in a clean context window, forcing the agent to continue its work against a completion goal. The filesystem makes this possible because each iteration starts with fresh context but reads state from the previous iteration.
Planning and self-verification to stay on track. Planning is when a model decomposes a goal into a series of steps. Harnesses support this via good prompting and injecting reminders how to use a plan file in the filesystem. After completing each step, agents benefit from the checking correctness of their work via self-verification. Hooks in harnesses can run a pre-defined test suite and loop back to the model on failure with the error message or models can be prompted to self-evaluate their code independently. Verification grounds solution in tests and creates a feedback signal for self-improvement.
The Future of Harnesses
The Coupling of Model Training and Harness Design
Today's agent products like Claude Code and Codex are post-trained with models and harnesses in the loop. This helps models improve at actions that the harness designers think they should be natively good at like filesystem operations, bash execution, planning, or parallelizing work with subagents.
This creates a feedback loop. Useful primitives are discovered, added to the harness, and then used when training the next generation of models. As this cycle repeats, models become more capable within the harness they were trained in.
But this co-evolution has interesting side effects for generalization. It shows up in ways like how changing tool logic leads to worse model performance. A good example is described here in the Codex-5.3 prompting guide with the apply_patch tool logic for editing files. A truly intelligent model should have little trouble switching between patch methods, but training with a harness in the loop creates this overfitting.
But this doesn't mean that the best harness for your task is the one a model was post-trained with. The Terminal Bench 2.0 Leaderboard is a good example. Opus 4.6 in Claude Code scores far below Opus 4.6 in other harnesses. In a previous blog, we showed how we improved our coding agent Top 30 to Top 5 on Terminal Bench 2.0 by only changing the harness. There's a lot of juice to be squeezed out of optimizing the harness for your task.
Where Harness Engineering is Going
As models get more capable, some of what lives in the harness today will get absorbed into the model. Models will get better at planning, self-verification, and long horizon coherence natively, thus requiring less context injection for example.
That suggests harnesses should matter less over time. But just as prompt engineering continues to be valuable today, it’s likely that harness engineering will continue to be useful for building good agents.
It’s true that harnesses today patch over model deficiencies, but they also engineer systems around model intelligence to make them more effective. A well-configured environment, the right tools, durable state, and verification loops make any model more efficient regardless of its base intelligence.
Harness engineering is a very active area of research that we use to improve our harness building library deepagents at LangChain. Here are a few open and interesting problems we’re exploring today:
- orchestrating hundreds of agents working in parallel on a shared codebase
- agents that analyze their own traces to identify and fix harness-level failure modes
- harnesses that dynamically assemble the right tools and context just-in-time for a given task instead of being pre-configured
This blog was an exercise in defining what a harness is and how it’s shaped by the work we want models to do.
The model contains the intelligence and the harness is the system that makes that intelligence useful.
To more harness building, better systems, and better agents.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み