エージェント改善ループにおける人間の判断
LangChain Blogは、AIエージェントの改善プロセスにおいて、文書化された組織知識だけでなく、従業員に内在する暗黙知(Tacit Knowledge)を反映させることが重要であると指摘している。
キーポイント
暗黙知の活用必要性
優れた組織は文書化された明示知識だけでなく、従業員の中に蓄積された暗黙知に依存しており、AIエージェントもこれを反映する必要がある。
人間判断の統合
エージェントはチームが長年にわたって構築した知識と判断力を反映する際に最も効果的に機能し、単なる情報検索を超えた価値を生む。
エージェント改善ループの核心
エージェントの性能向上には、組織内の人的な判断や経験則をフィードバックループに組み込むことが不可欠である。
影響分析・編集コメントを表示
影響分析
この記事は、AIエージェントの実装において技術的な精度だけでなく、組織文化や人的ナレッジの統合という「ソフト面」の重要性を強調しており、実務レベルでのエージェント導入戦略に示唆を与える。LangChainという主要フレームワーク開発元からの発信であるため、エージェント開発のベストプラクティスとして業界標準になりつつある「人間による監督・フィードバック」の重要性を再確認させるものと言える。
編集コメント
技術的なモデル性能だけでなく、組織内の「人の知恵」をどうシステムに埋め込むかが、実務的なエージェント活用における次の課題であることを示唆する記事です。

AIエージェントは、チームが長年にわたって構築してきた知識と判断を反映している場合に最も効果的に機能します。その一部は、すでに文書化されており、エージェントがそのまま利用できる組織内の知識(インスティテューショナル・ナレッジ)です。しかし、優れた組織の多くは、従業員の頭脳の中に存在する暗黙知(タクイット・ナレッジ)にも依存しています。チームは、それを自動化するAIエージェントの構築を試みるまで、その情報が有意義な業務遂行においていかに重要であるかを認識しないことがよくあります。この知恵をエージェントに反映させるには、ドメインの専門家の入力を取り入れた改善ループが必要です。
このガイドでは、以下のトピックを扱います。
- 人間の判断を取り込むことで恩恵を受けるエージェントのコンポーネント
- 開発ライフサイクルの各段階で、どのように人間の判断をエージェントに組み込むか
実例に基づく例:トレーダー向けCopilot
金融サービス企業のトレーダーが、最新の市場データを必要とする状況を想像してください。現在、彼らは質問をデータサイエンスチームに送信しています。データサイエンティストはSQLクエリを作成し、関連データを取得して結果を返します。大規模言語モデル(LLM)はSQLの生成が得意であるため、このワークフローはAIエージェントで自動化する自然な候補となります。トレーダーはより迅速な回答を得られ、データサイエンティストはより興味深いプロジェクトに取り組むことができます。
このシステムが確実に機能するためには、エージェントは金融サービスドメインのレベルと技術的なデータベースレイヤーの両方でコンテキストを必要とします。前者には、「今日のエクスポージャー」や「最近のボラティリティ」といったリクエストをどのように解釈するかを決定する、書かれていない取引の慣習が含まれます。後者には、どのテーブルが権威あるものか古いか、あるいはどのクエリパターンが誤っているか非効率である傾向があるかなど、データベースに関する実践的な知識が含まれます。エージェントが必要とするすべての書かれていないコンテキストを含めるために、適切な分野の専門家に協力する必要があります。
このガイド全体で、この例を使用して具体的な実装例を示します。これは良い例です。なぜなら、アーキテクチャが単純であり、それはエージェント設計に人間の判断関与に関わる重要な原則を示しているからです。
人間の判断によって改善できるエージェントの異なるコンポーネントを振り返りましょう。
人間の入力がAIエージェントの各コンポーネントをどのように改善するか
エージェントを構築することは、LLM(大規模言語モデル)をいつ呼び出すかを決定し、所望の結果を得るために各呼び出しで提供されるコンテキスト(例:ドキュメント、メモリ、会話履歴、ツール)を管理することを意味します。これらの設計上の選択のすべては、適切なステークホルダーからの入力によって恩恵を受けます。
ワークフロー設計
現在のLLMは、自身の行動をシーケンスすることに優れています。ツールと自然言語の指示を与えるだけで、どのツールをどのような順序で呼び出すべきかを理解します。しかし、ワークフローの一部を決定論的なコードで定義することには利点があります:レイテンシの低減、トークン数の削減、そして重要なステップが実際に実行されるという保証です。規制の厳しいまたは高リスクな環境では、行動の順序を厳密に制御するためにコードが必要です。トレーダーのコパイロットでは、LLMがSQLクエリを自律的に生成して実行できるようにしますが、最終回答をトレーダーに返す前に、その回答が当社のリスクおよびコンプライアンス要件を満たしていることを検証するコードを追加します。当社の基準を適用する自動チェックを作成するには、リスクおよびコンプライアンスの専門家の入力が必要です。また、エージェントのプリロードされたコンテキストにこの情報を含めることで、最初の試行で有効な回答を作成する確率を高めることもできます。
ツール設計
開発者は、エージェントが使用するツールを実装し、LLMがそれらの呼び出しを決定する際に依存する名前、パラメータ、および説明を設定する必要があります。ワークフローの異なる段階で利用可能なツールを変化させることは、しばしば有用です。単一のLLM呼び出しに対してツールのセットを制限することで、モデルを意図した動作に導き、関連性の低いオプションを選択する可能性を減らすことができます。
コパイロットのツールには、データベーススキーマの検査、クエリの実行、およびデータベースドキュメントの取得が含まれる場合があります。LLM生成のクエリにおける柔軟性と制御の主要なトレードオフは、一般的なexecute_sqlステップは柔軟なクエリを可能にしますがリスクが増加するのに対し、パラメータ化されたクエリツールはより安全ですが機能が制限されます。ビジネス上の制約を慎重に検討することで、どちらのオプションが適切かを見極める手がかりが得られるかもしれませんが、確実な判断を下すためにはツール設計のパフォーマンスとリスク特性を評価するために評価(evaluation)を実行し、すべてのステークホルダーが結果に納得するまでリリースを行わない必要があります。
エージェントコンテキスト
初期のエージェントは、モデルに単一のシステムプロンプトと一連のツール定義を提供するだけでした。時間が経つにつれて、業界は実行開始時にエージェントにより豊富なコンテキストを提供する方向へ移行しています。 10月のローンチ以来急速に普及している標準であるAnthropicのSkillsは、この傾向の顕著な例です。
すべての情報を一つのシステムプロンプトに詰め込むのではなく、チームは事前にドキュメント、例、ドメインルールを整理・選別し、エージェントが実行時に必要な情報を取得できるようにします。これにより、システムプロンプトを肥大させることなく、エージェントがはるかに多くの知識を活用できます。効果的なエージェント設計とは、エージェントがアクセスすべき知識を決定し、適切なタイミングで正しい情報を取得できるように整理することを含みます。
少なくとも、トレーダーのコパイロットはデータベースの使用方法とスキーマを理解している必要があります。コパイロットが必要とするチームからの追加知識の内容や量に応じて、単にその知識を収集するだけでなく、それをどのように構造化し、エージェントに対して段階的に開示するかを決定するために時間を割く必要があります。
エージェント起動時に利用可能な情報を選択し構造化することは、コンテキストエンジニアリングの分野の一部です。コンテキストエンジニアリングには、エージェントがタスクを進めるにつれて、各LLM呼び出しで提供する情報がどのように変化するかも含まれます。エージェントの出力や評価スコアをレビューする際に、人間のステークホルダーから提供されるフィードバックは、エージェントのエンドツーエンドのコンテキストエンジニアリングへのアプローチに影響を与える可能性があります。
これで、人間の判断から恩恵を受けるエージェントの構成要素について概説しましたので、次にその人間入力収集の方法について説明します。
エージェント改善ループへの人間の判断の組み込み
LangChainでは、AIエージェントを展開する数百の組織と協力してきました。最も成功しているチームは、緊密な反復ループに従っています。すなわち、エージェントを迅速に構築し、本番環境またはそれに準じる環境にデプロイし、各ステップで改善を導くためのデータを収集します。私たちはこれを「エージェント改善ループ」と呼んでいます。なぜなら、最も成功しているエージェントのほとんどがこのループを複数回経験しており、これまでにこちらでより詳細に説明しているからです。
迅速かつ頻繁な反復が重要な理由は、エージェントの動作を決定するのはコードではなくLLM(大規模言語モデル)のリアルタイム推論だからです。AIエージェントが何を行うかは、実行してみなければわかりません。 AIエージェントのインターフェースは自由形式であることが多く、ユーザーが何でも入力できるテキストボックスなどであり、ユーザーとエージェントの間の相互作用がどのようなものになるかを予測するのはさらに困難です。あなたのエージェントをユーザーの前に置くことが、最終的に成功させるために必要なデータを収集する唯一の方法です。
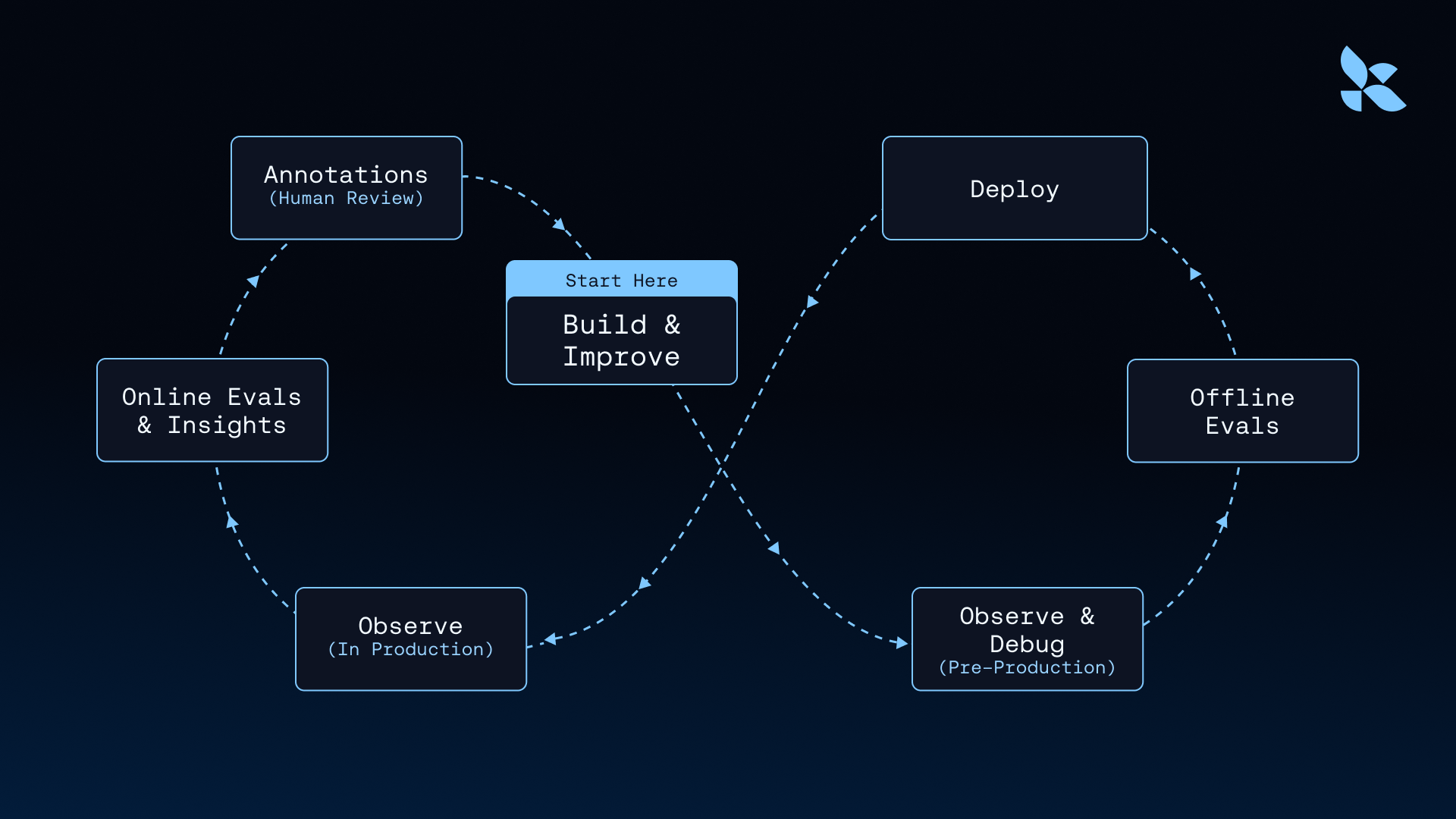
人間の入力を効果的に組み込む方法を議論しながら、フラインホイール(flywheel)の以下のフェーズを順を追って説明します:
- エージェントの最初のバージョンの実装
- 本番環境での運用後にエージェントを監視し、改善に役立つ生産データを収集する
- 改良版エージェントの実装とテスト
その前に、開発ライフサイクル全体に適用される重要な原則を強調しておく価値があります。
投入された人間の時間の高いリターンを得る鍵:人間の評価と整合した自動評価
私たちは、大規模なチームほど、エージェントの出力を手動で大量にレビューするのではなく、人間が自動評価ツールの設計と調整に関与することで、より大きな効果(レバレッジ)を得られるという傾向を観察しています。チームの規模やリソースがどれだけ充実していても、広範な手動レビューに依存することは経済的に非効率であることがほとんどです。スケーラブルなアプローチは、専門家の判断を自動評価に変換し、広範囲かつ継続的なテストを可能にすることです。LangSmithのAlign Evaluator機能がこれを実現します。この機能は、キュレーションされた例や分野の専門家からのフィードバックを用いて、LLM-as-a-judge(裁判官としての大規模言語モデル)評価ツールの調整を行うためのユーザーインターフェースを提供します。開発者以外のステークホルダーの判断を模倣することを目的としたあらゆる評価ツールに対して、この機能の使用をお勧めします。
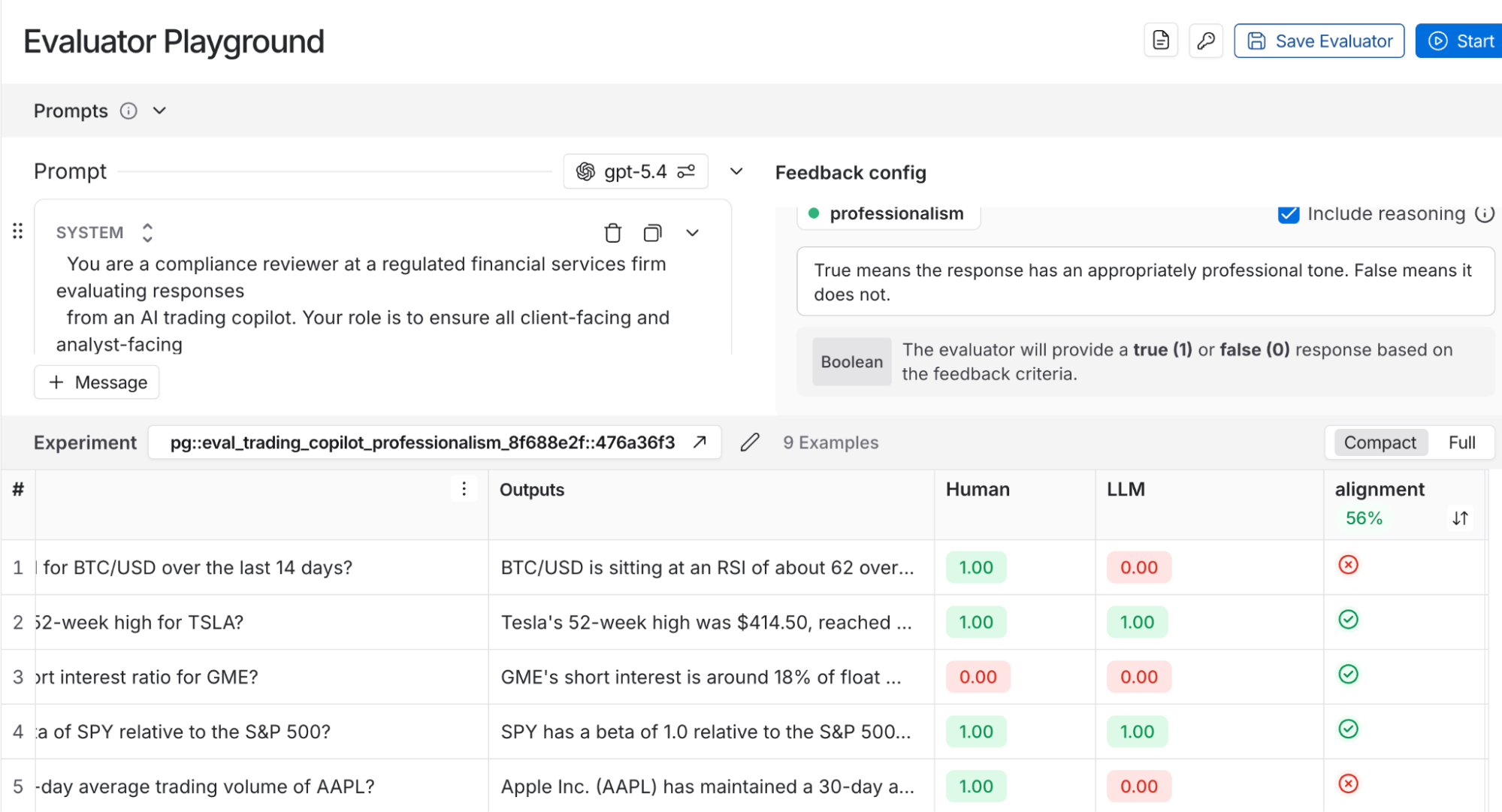
LangSmith の Align Evaluator 機能を使用して、LLM-as-a-judge(裁判官としての大規模言語モデル)の専門性評価者を検証します。現在、この評価者は人間の審査官よりも厳格なため、システムプロンプトを変更してより寛容にする必要があります。仮想的な取引会社の視点からトレーダーコパイロットを追跡し、改善ループの各フェーズをたどります。人間の入力を効果的に組み込む方法、特にその入力を自動化された評価にどう流し込むかに焦点を当てて解説します。
開発:テストスイートと評価者の策定
開発を開始する前に、エンジニアはプロジェクト要件の一部として、少なくとも小規模なユースケースシナリオと期待される動作を持っていなければなりません。これらの初期テストは、エージェントが中核タスクを正しく実行することを確認するのに役立ちます。エージェントが本番環境への準備を整えるにつれて、エンジニアはプロダクトマネージャーや分野の専門家と協力し、全体的な動作と主要なサブコンポーネントの両方を評価するより包括的なテストスイートを構築する必要があります。
コパイロットには、LangSmith の datasets 機能を使用して、自然言語の質問と正解をペアにした手動によるグラウンドトゥルース(正解データセット)を作成します。また、データベースの文脈において、パフォーマンスの高い SQL がどのようなものかの例を含むデータセットも作成します。開発者がエージェントの構築を進める中で、LangSmith の evaluations 機能を用いて、これらのデータセットに対してテストを実行します。LangSmith の UI を通じて、技術チームと非技術チームの両方のメンバーが評価結果を確認し、注釈を付けることができるため、開発者の次のステップについて全員で合意形成を図ることができます。
このフェーズ中、手動テスト中に遭遇した興味深いケースに触発された例を初期データセットに追加することで、ミニフライホイール(小さな好循環)を構築できます。 これにより、フィードバックループの自動化が段階的に進み、エージェントの v1 をリリースする準備ができるときには包括的なテストスイートが整っていることを保証できます。
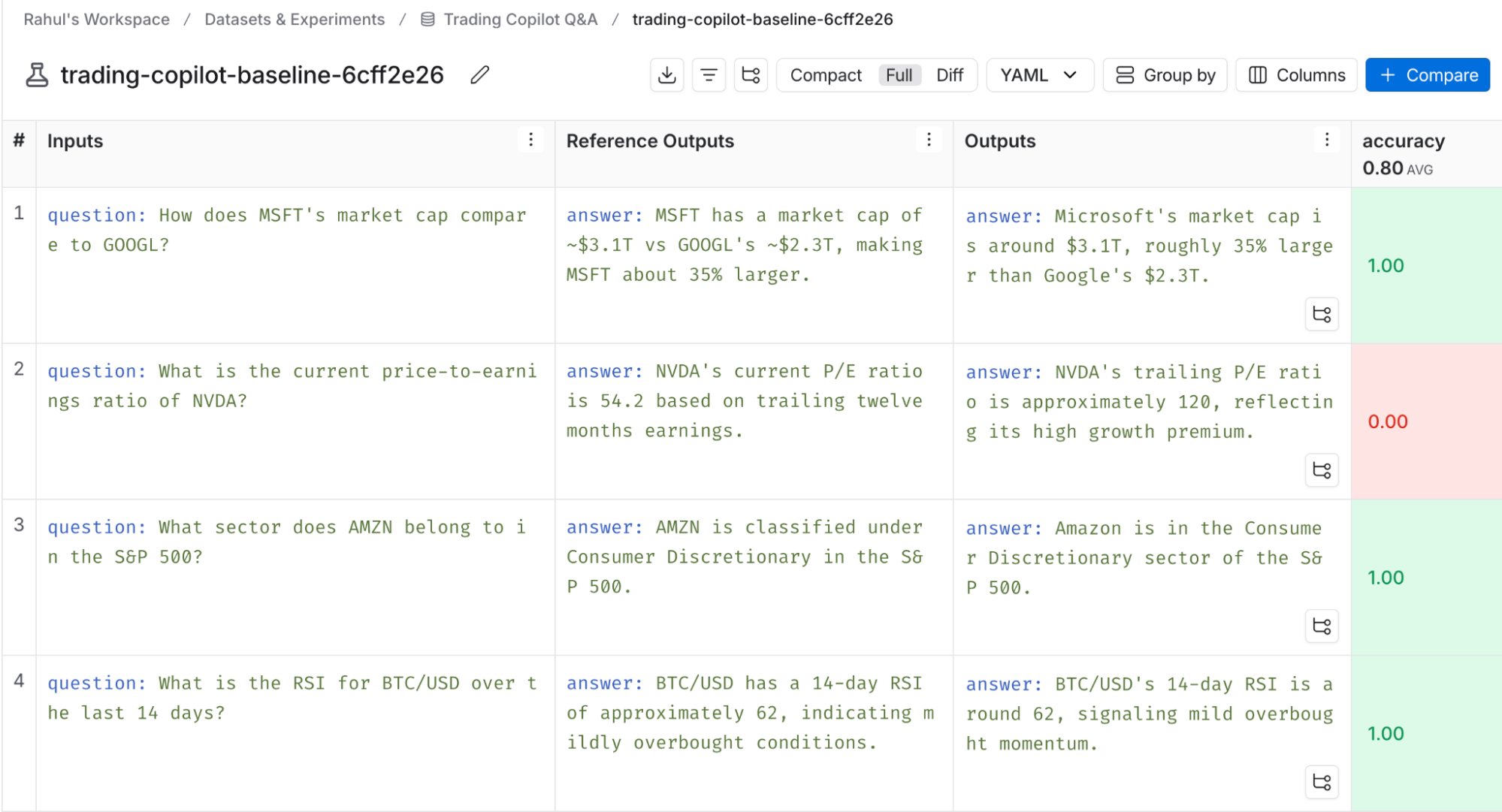
エージェントの出力をグラウンドトゥルースデータセットと比較した結果です。ここでのパフォーマンスは概ね良好ですが、改善の余地はまだ残っています。
デプロイ後:自動化された評価とモニタリングを活用し、人間の注意を最も必要とされる箇所へ向ける
エージェントが稼働したら、その信頼性を確保し、問題や改善の機会を迅速に特定する必要があります。ユーザー体験を検証する従来の方法は満足度調査やユーザーインタビューですが、このアプローチの欠点は、ユーザーが「何と言っているか」を測定するだけで、「実際に何を行っているか」は測れない点にあります。LLM-as-a-judge(LLM判定者)による評価者は、はるかに堅牢な手法を提供します。本番データ上で実行される自動化された評価は、エージェントの監視を支援し、人間の注意を要する状況を浮き彫りにするのに役立ちます。 例えば、LLM 判定者はユーザーが不満を表明したタイミングを自動的に検出し、そのやり取りを検証対象としてフラグを立てることができます。その後、チームメンバーはトレース(実行履歴)を調査し、その問題がバグなのか、エージェントの知識不足によるものなのか、それともワークフローの弱点によるものなのかを判断します。
{insert-video-here}
デモトレーダーアプリを確認し、注釈キューを設定してください。
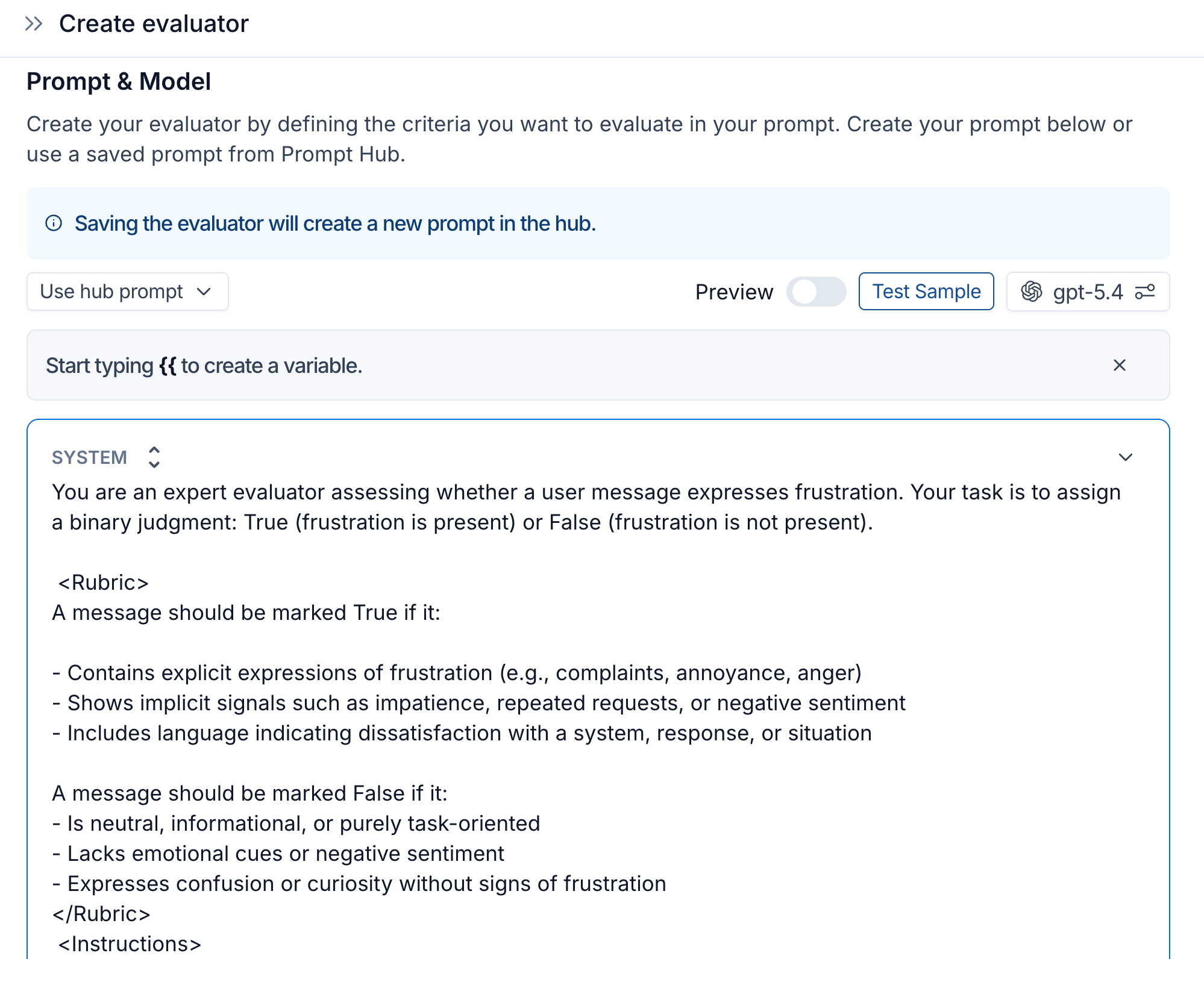
LangSmith で LLM-as-a-judge 形式のオンライン評価者を構築し、ユーザーが不満を表明したメッセージを検出する。私たちの仮想的な企業はまず、トレーダーとのエージェントのすべてのインタラクションをキャプチャするために LangSmith tracing をセットアップします。次に、以下の目的で LangSmith の automations 機能をセットアップします。
- オンライン評価:LangSmith を構成し、観測データが入力されるたびに評価プログラムを実行させます。例えば、遅延しているまたは危険な SQL クエリに対する自動コードチェックや、LLM-as-a-judge 評価プログラムによる会話レビューを行い、コパイロットが提供している回答に対してユーザーが満足しているかどうかを確認します。
- アラート:LangSmith は、エラー、レイテンシ、または否定的なオンライン評価スコアの急増を検出すると、既存のアラートシステムをトリガーし、チームが根本的な問題を迅速に修正できるようにします。
- アノテーションキュー:注目すべきトレースを人間によるレビューの対象として、LangSmith のアノテーションキューに送信します。このキューでは、オンライン評価プログラムが非常に否定的なフィードバックスコートを返したケースを、ドメインの専門家がレビューし、エージェントに問題があることを示します。境界線上のフィードバックスコアは、評価プログラム自体を調整する必要があることを示唆します。LangSmith は、アノテーションキューを通じて提出されたフィードバックを保存し、今後の自動および手動分析で使用可能にします。
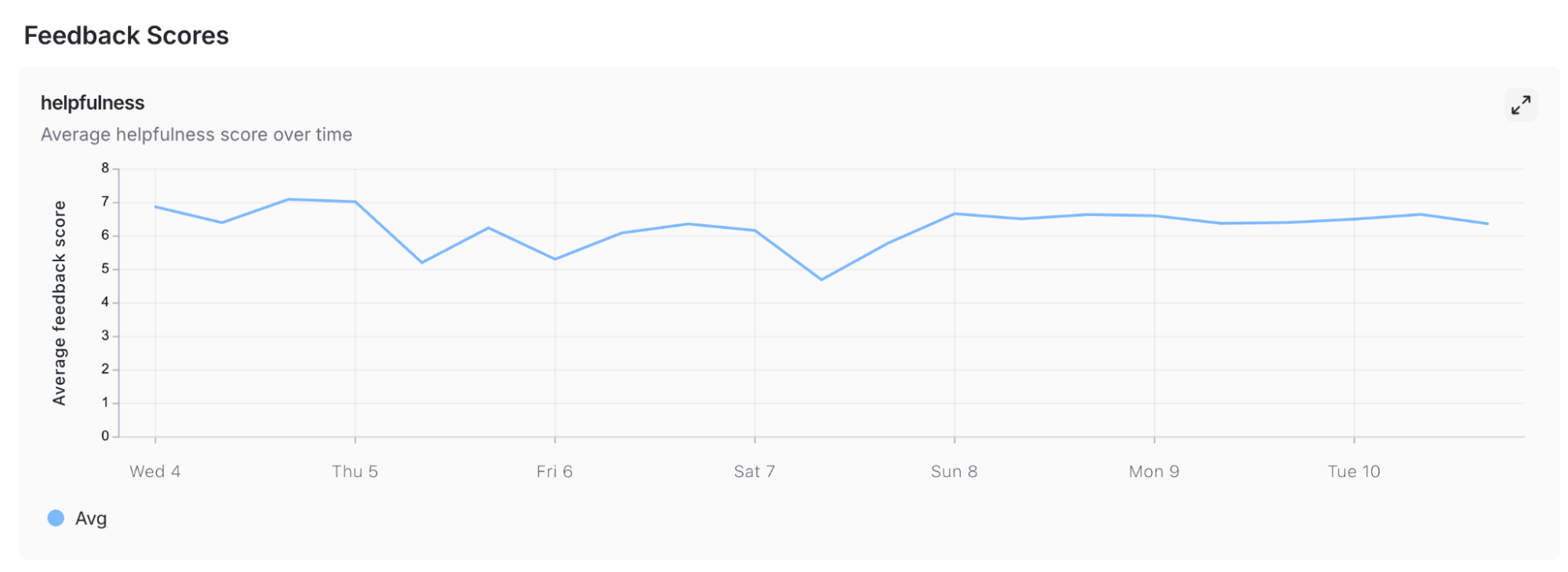
LangSmith のダッシュボードでは、エージェントに関する集計メトリクスを表示できるため、チームはエージェントが期待通りに動作し続けていることを確認できます。
洞察エージェント:トレーシングデータから価値を引き出す別の方法
ライブな動作の構造化されていない探索は、AI エージェントにとって最も価値のある改善の一部を生み出します。 これをサポートするために、LangSmith は Insights Agent を提供しています。これは、最小限のユーザー設定で大量のトレーシングデータを分析する組み込み AI エージェントです。個々のトレースや決定論的な評価からは明らかにならない、エージェントの動作におけるパターンや傾向を浮き彫りにします。最終的には、次のステップについて合意形成するために人間のステークホルダーが洞察レポートをレビューする必要がありますが、この機能はプロセスの初期段階を加速します。
取引/copilot の場合、類似した会話を自動的に特定し、ユースケースのカテゴリにクラスタリングする洞察レポートを自動実行することが考えられます。トレーダーが copilot に対して質問する背後にある主要なテーマを理解することで、特にしっかりサポートすべきユースケースを特定したり、それらのユースケースでトレーダーにより役立つ将来の製品追加機能を見出したりするのに役立ちます。
自動化された評価、人間の注釈、および集計レベルの洞察が蓄積されるにつれて、エージェントが現実世界でどのようにパフォーマンスを発揮しているかの明確な像が得られます。これらの学びは、サイクルの最終ステップ、つまりエージェントの次のバージョンを構築してイテレーションループを再起動する段階にフィードバックされます。
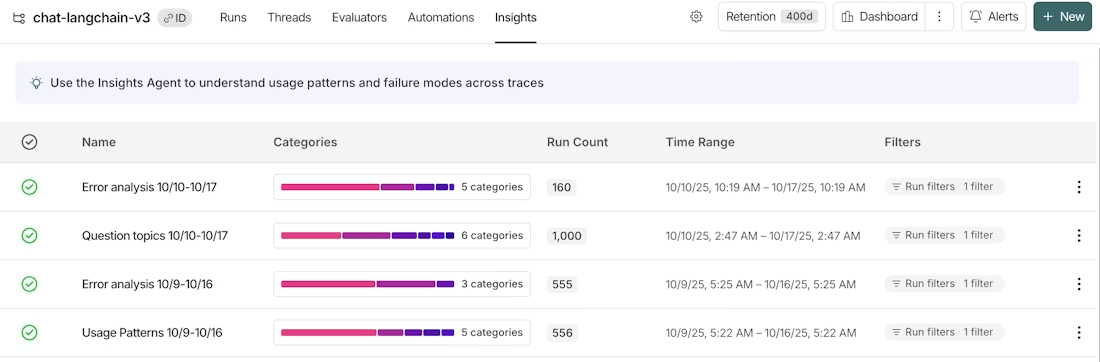
LangSmith Insights Agent は、データ内の隠れたパターンを浮き彫りにするレポートを生成します。
継続的な改善:今日の運用データを明日のテストスイートに変える
エージェントの最初のバージョンを構築する際、評価スイートは、その動作を検証するために必要なテストが何であるかについての推測に過ぎないのがせいぜいです。ローンチ後、あなたははるかに優れたテストケースのソース、つまり実際の運用データにアクセスできるようになります。
このデータを、包括的でありながら不必要に大きくならないテストスイートとして整備する必要があります。自動化されたシステムは、評価結果に基づいて運用トレースをフィルタリングするなどして、候補となるデータセットの生成を支援できます。しかし、バランスが取れ、代表的な評価セットを整備するには、しばしば人間の判断が必要です。 注意深く選択された数百例のサンプルに対して評価を実行するだけでも有用な結果が得られるため、どのサンプルをテストスイートの定義に含めるかを決める際に専門家の関与は価値があります。
取引会社がコパイロットを運用環境で稼働させてからある期間が経過すると、チームは実際の SQL クエリやチャットボットの会話履歴、さらにモニタリングを通じて収集されたオンライン評価結果と、整備済みの注釈キュー経由で集められた人間の意見にアクセスできるようになります。
レビュー済みのトレースからデータセットを作成することで、より堅牢な一連の評価を実行し、v2以降のエージェント性能を大幅に向上させることができます。私たちが作成できる最も有用なデータセットの一つは「ゴールデンデータセット」で、これはこれまでにコパイロットの最良の成果例から構成され、将来のバージョンが少なくとも同等以上のパフォーマンスを発揮することを確認するための基準として使用できます。LangSmith を使えば、これを簡単に構築できます。オンライン評価者のスコアを使用して候補トレースを特定し、それらを注釈キューに配置して、分野の専門家が実際にどのトレースがゴールデンデータセットに含まれるべきかを判断できるようにします。
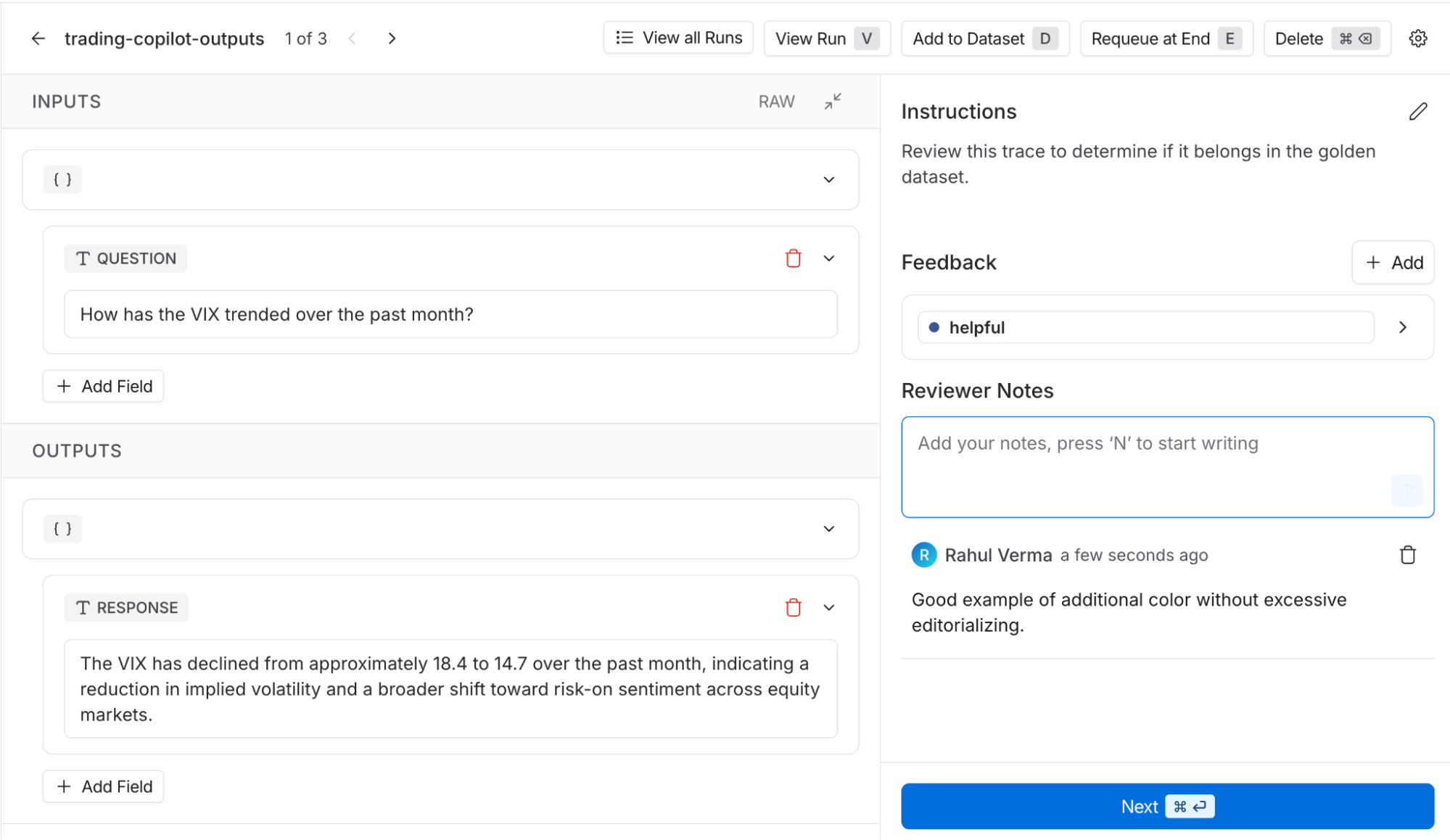
LLM 判定者が高品質とマークしたチャットボットのトレースをレビューし、それらが本当にゴールデンデータセットに含まれるべきかどうかを決定するために、LangSmith の注釈キューを使用しています。
結論
効果的なエージェント開発は、人間の判断と自動評価のスケーラビリティを組み合わせるものです。人間の専門知識は、ワークフロー、ツール、コンテキスト、評価基準を形成することで、「良い」とは何であるかを定義するのを助けます。自動評価者は、その判断をスケーラブルな規模で適用し、チームがエージェントを迅速にテストし、本番環境での動作を監視し、最も重要なケースに人間の注意を向けるのを支援します。
時間が経つにつれて、これはフライングホイール(回転の加速サイクル)を生み出します。人間のフィードバックは評価者、テストスイート、そしてエージェント自体を改善し、デプロイされた改善版エージェントから得られるデータは、そのさらなる改善方法を教えてくれるため、これらの洞察が次の開発イテレーションを駆動します。
私たちはこのプロセスを示すために単純なユースケースを使用しましたが、同じ原則があらゆるエージェントの構築に適用されます:密接なイテレーションループを構築し、スケーラブルな評価で専門家の判断を取り込み、生産データを継続的により良いテストに変換することです。 これが、ビジネスに意味のある価値をもたらすAIエージェントを作成するための鍵です。
関連コンテンツ

ケーススタディ
LangSmith
Credit GenieがInsights Agentを使用してAI金融アシスタントを改善した方法




D. Li,
J. Ngai,
G. Lozano Palacio,
C. Yuan
2026年4月20日
5
分

観測可能性と評価(Observability & Evals)
LangSmith
LangSmithにおける再利用可能な評価器と評価テンプレート


C. Qiao,
J. Talbot
2026年4月16日
4分

観測可能性と評価(Observability & Evals)
より良いHarness:評価を用いたヒルクライム(Hill-Climbing)のためのレシピ

Vivek Trivedy
2026年4月8日
8分

エージェントが実際に何を行っているかを確認する
LangSmithは、エージェントエンジニアリングプラットフォームであり、開発者がすべてのエージェントの意思決定をデバッグし、評価(eval)の変更を確認し、ワンクリックでデプロイすることを支援します。
原文を表示
AI agents work best when they reflect the knowledge and judgment your team has built over time. Some of that is institutional knowledge that’s already documented and easy for an agent to use as-is. But most great organizations also rely on tacit knowledge that lives inside their employees’ minds. Teams often don’t realize how critical that information is to perform meaningful work until they try building AI agents to automate it. Ensuring this wisdom makes its way into an agent requires an improvement loop that incorporates input from domain experts.
In this guide, we’ll cover:
- Which components of your agent will benefit from absorbing human judgment
- How to incorporate human judgment into your agent at each step of the development lifecycle
Real-life inspired example: Copilot for traders
Imagine a financial services firm whose traders need up-to-date market data. Today, they send their questions to the data science team. A data scientist writes a SQL query, retrieves the relevant data, and sends the result back. Because LLMs are strong at generating SQL, this workflow is a natural candidate to automate with an AI agent: traders get faster responses while the data scientists are free to work on more interesting projects.
For this system to work reliably, the agent needs context at both the financial services domain level and the technical database layer. The former includes unwritten trading conventions that determine how to interpret requests like “today’s exposure” or “recent volatility.” The latter includes practical knowledge of the database, like which tables are authoritative vs. outdated, or which query patterns tend to be incorrect or inefficient. We’ll need to engage with the appropriate subject-matter experts to include all the unwritten context the agent needs.
We’ll use this example throughout the guide to give concrete implementation examples. It’s a good example because the architecture is simple, and it showcases principles critical for involving human judgement in agent design.
Let’s review the different components of the agent that can be improved with human judgment.
How human input improves each component of an AI agent
Building an agent means deciding when to invoke an LLM and managing what context to provide with each call (e.g., documentation, memory, conversation history, tools) to achieve the desired result. Each of these design choices benefits from input from the right stakeholders.
Workflow Design
LLMs today are great at sequencing their own actions. Just give them some tools and natural language instructions, and they’ll figure out which tools to call in what order. However, there are benefits to using deterministic code to define parts of the workflow: lower latency, fewer tokens, and the guarantee that critical steps actually run. In some regulatory or high-risk settings, you need code to strictly control the sequence of actions. In our trader copilot, we’ll let the LLM autonomously generate and execute a SQL query, but add code that requires it to validate the final answer meets our firm’s risk and compliance requirements before returning it to the trader. We’ll need input from risk and compliance experts to create automated checks that enforce the firm’s standards. We can also include that information in the agent’s pre-loaded context to improve its odds of creating a valid answer on the first try.
Tool Design
Developers must implement the tools the agent can use and configure the names, parameters, and descriptions that the LLM relies on to decide when to invoke them. It’s often useful to vary the available tools at different stages of the workflow. Limiting the tool set for a single LLM call can guide the model toward the intended behavior and reduce the chance that it selects an irrelevant option.
Our copilot’s tools might include database schema inspection, query execution, and database documentation retrieval. A key tradeoff is flexibility vs. control for LLM-generated queries: a general execute_sql step allows for flexible queries but increases risk; parameterized query tools are safer but less capable. A close review of your business constraints might give you a sense of which option is right for you, but to know for sure, you’ll need to run evaluations to determine the performance and risk characteristics of your tool design and ship only when all stakeholders are comfortable with the results.
Agent Context
Early agents just gave the model a single system prompt and a set of tool definitions. Over time, the industry has moved toward providing agents with much richer context at the beginning of their execution. Anthropic’s Skills, a standard that has quickly grown in popularity since launching in October, is one prominent example of this trend.
Instead of cramming everything into one system prompt, your team curates documentation, examples, and domain rules in advance, then lets the agent fetch what it needs at runtime. This lets the agent use far more knowledge without bloating the system prompt. Effective agent design involves deciding what knowledge the agent should access and organizing it so the agent can retrieve the right information at the right moment.
At minimum, our trader copilot needs to know how to use the database and understand its schema. Depending on the nature and amount of additional knowledge from our team that our copilot needs, we’ll have to spend time not just collecting that knowledge but determining how to structure and progressively disclose it to our agent.
Choosing and structuring the information available to the agent when it starts up is part of the discipline of context engineering. Context engineering also covers how the information you provide in each LLM call evolves as the agent moves through its task. The feedback your human stakeholders provide when reviewing your agent’s outputs and evaluation scores may influence how you approach end-to-end context engineering for your agent.
Now that we have outlined the parts of an agent that benefit from human judgment, we’ll cover how to collect that human input.
Incorporating human judgment into the agent improvement loop
At LangChain, we’ve worked with hundreds of organizations deploying AI agents. The most successful teams follow a tight iteration loop: they quickly build an agent, deploy it to a production or production-like environment, and collect data at each step to guide improvements. We call this the “agent improvement loop” because we’ve observed that most successful agents have gone through this loop multiple times, and have covered it in greater detail before here.
Iterating quickly and frequently is critical because it is the LLM’s real-time reasoning, not code, that determines the agent’s behavior. It’s impossible to know what an AI agent will do until it runs. AI agent interfaces are often free-form, e.g. a text box the user can type anything into, making it even harder to predict what interactions between your users and your agent will look like. Putting your agent in front of users is the only way to collect the data you need to make it ultimately successful.
We’ll walk through the following phases of the flywheel while discussing how to incorporate human input effectively:
- Implementing the agent’s first version
- Monitoring the agent after it goes live and collecting production data to help refine it
- Implementing and testing improved versions of the agent
Before we dive in, it’s worth highlighting a principle that applies across the entire development lifecycle.
The key to high return on human time invested: automated evaluations, aligned with human judgment
We’ve observed that teams get more leverage when humans help design and calibrate automated evaluators, rather than manually reviewing large volumes of agent outputs. No matter how big or well-resourced your team is, it’s rarely economical to rely on extensive manual review. The scalable approach is to translate expert judgment into automated evaluations that let you test broadly and continuously. That’s what LangSmith’s Align Evaluator feature helps with. It provides a user interface for calibrating LLM-as-a-judge evaluators using curated examples and feedback from subject matter experts. We recommend using this feature for any evaluator that’s meant to mimic a non-developer stakeholder’s judgments.
Let’s follow the trader copilot from the perspective of our hypothetical trading firm through each phase of the improvement loop. We’ll look at how to incorporate human input effectively, and in particular, how to channel that input into automated evaluations.
Development: Curate test suites and evaluators
Before development starts, engineers should have at least a small set of use case scenarios and expected behavior as part of the project requirements. These initial tests help confirm that the agent performs the core tasks correctly. As the agent approaches production readiness, engineers should work with product managers and subject matter experts to build a more comprehensive test suite that evaluates both overall behavior and key subcomponents.
For our copilot, we’ll use LangSmith’s datasets feature to manually create some ground truth datasets pairing natural language questions and their correct answers. We’ll also create datasets containing examples of what good, performant SQL looks like in the context of our database. As our developers build the agent, we’ll use LangSmith’s evaluations feature to run tests against those datasets. The LangSmith UI lets our technical and nontechnical team members review evaluation results and annotate them so everyone can align on the developers’ next steps.
We can create a mini-flywheel during this phase by augmenting our initial datasets with examples inspired by interesting cases we encounter during manual testing. This helps progressively automate our feedback loop and ensure we have a comprehensive test suite by the time we’re ready to ship our agent’s v1.
After deployment: Use automated evaluations and monitoring to direct human attention to where it’s most needed
Once your agent is live, you'll need to ensure its reliability and quickly identify problems or opportunities for improvement. The traditional way of validating user experience is satisfaction surveys and user interviews, but the flaw with that approach is it measures what users tell you, not what they actually do. LLM-as-a-judge evaluators give us a much more robust method. Automated evaluations running on production data can help monitor the agent and surface situations that warrant human attention. For example, an LLM judge can automatically detect when a user expresses frustration and flag those interactions for review. A team member can then investigate the trace and decide whether the issue reflects a bug, a gap in the agent’s knowledge, or a weakness in the workflow.
{insert-video-here}
Check out the demo trader app and set up annotation queues.
Our hypothetical firm will first set up LangSmith tracing to capture all of the agent’s interactions with our traders. We’ll next set up LangSmith’s automations feature for:
- Online evaluations: Configure LangSmith to run evaluators on the observability data as it comes in. For example, we’ll want automated code checks for slow or dangerous SQL queries as well as LLM-as-a-judge evaluators reviewing conversations to see if users are expressing satisfaction with the answers the copilot is giving them.
- Alerts: LangSmith will trigger our preexisting alerting system when it sees spikes in errors, latency, or negative online evaluation scores so our team can quickly fix the underlying problem
- Annotation queues: We’ll flag notable traces for human review by sending them to a LangSmith annotation queue. In the queue, we’ll have subject matter experts review cases where an online evaluator returned a very negative feedback score, indicating something is wrong with the agent. A borderline feedback score would suggest that we need to adjust the evaluator itself. LangSmith saves the feedback submitted through annotation queues so it’s available for future automated and manual analysis.
Insights Agent: Another way to get value from the tracing data
Unstructured explorations of live behavior inspire some of the most valuable improvements for AI agents. To support this, LangSmith provides Insights Agent, a built-in AI agent that analyzes large volumes of tracing data with minimal user configuration. It surfaces patterns and trends in agent behavior that wouldn’t be obvious from individual traces or deterministic evaluations. You’ll still ultimately have your human stakeholders review the insights report to align on next steps, but the feature jump-starts the process.
For our trading copilot, we might run an insights report automatically identifying similar conversations and clustering them into use case categories. Having a sense of the underlying themes behind the questions the traders ask the copilot can help us identify use cases we should be extra sure to support well or even future product additions that would serve our traders even better for those use cases.
As automated evaluations, human annotations, and aggregate-level insights accumulate, they provide a clear picture of how the agent performs in the real world. Those learnings feed into the final step of the cycle: restarting the iteration loop by building the agent’s next version.
Continuous refinement: turn today’s production data into tomorrow’s test suites
When you build the first version of an agent, your evaluation suite is at best educated guesses on what tests you need to validate that it works. After launch, you gain access to a much better source of test cases: real production data.
You need to curate this data into test suites that are comprehensive but not unnecessarily large. Automated systems can help generate candidate datasets, for example, by filtering production traces based on evaluator results. But we often need human judgment to curate balanced, representative evaluation sets. Evaluations can be useful running on just a few hundred examples if they’re chosen carefully, so it’s worthwhile to involve experts in deciding which examples should define the test suite.
Once our trading firm has had its copilot running in production for a while, the team will have access to real SQL queries and chatbot conversations, along with the online evaluator results and human opinions collected via monitoring and curated annotation queues.
Our team can create datasets out of the reviewed traces to run a more robust suite of evaluations, resulting in huge improvements in our agent’s performance for v2 and beyond. One of the most helpful datasets we can curate is a “golden dataset,” consisting of examples of the copilot’s best work so far, so we can use it as a baseline to ensure future versions perform at least as well. LangSmith makes this easy to put together. Use the online evaluator scores to identify candidate traces, then put them in an annotation queue so our subject matter experts can decide which ones actually belong in the golden dataset.
Conclusion
Effective agent development combines human judgment with the scalability of automated evaluations. Human expertise helps define what “good” looks like by shaping workflows, tools, context, and evaluation criteria. Automated evaluators apply that judgment at scale, helping teams test agents quickly, monitor their behavior in production, and direct human attention to the cases that matter most.
Over time, this creates a flywheel. Human feedback improves evaluators, test suites, and the agent itself, the improved agent we deploy gets us more data that tells us how to improve it, and these insights drive the next development iteration.
We used a simple use case to illustrate this process, but the same principles apply to building any agent: Build tight iteration loops, capture expert judgment in scalable evaluations, and continuously turn production data into better tests. This is the key to creating AI agents that create meaningful value for your business.
Related content
Case Studies
LangSmith
How Credit Genie used Insights Agent to improve their AI financial assistant
D. Li,
J. Ngai,
G. Lozano Palacio,
C. Yuan
April 20, 2026
5
min
Observability & Evals
LangSmith
Reusable Evaluators and Evaluator Templates in LangSmith
C. Qiao,
J. Talbot
April 16, 2026
4
min
Observability & Evals
Better Harness: A Recipe for Harness Hill-Climbing with Evals
Vivek Trivedy
April 8, 2026
8
min
See what your agent is really doing
LangSmith, our agent engineering platform, helps developers debug every agent decision, eval changes, and deploy in one click.
関連記事
AI エージェントに専用コンピューターを付与する
LangChain は、数百万のタスクを実行する AI エージェントが安全かつ効率的に動作するために、各エージェントに個別のファイルシステムやシェル環境を持つ仮想コンピューターを提供するインフラシフトの必要性を提唱している。
LangChainガイド:観測可能性を用いたAIエージェントのデバッグと評価方法
LangChainは、観測可能性を活用してAIエージェントを効果的に評価する方法を解説する。トレーシングや推論のデバッグ、パフォーマンス分析を通じて、エージェントの動作を反復改善する手法を示している。
LangChain、Google Cloud Next 2026に出展
LangChainはラスベガスで開催される「Google Cloud Next 2026」に出展し、4月22日から24日にかけてブース#5006でAIエージェントに関するセッションを実施する。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み