エージェントがサンドボックスを接続する2つのパターン
LangChain Blogは、エージェントとサンドボックスの統合における「エージェント内実行」と「ツールとしてのサンドボックス」の2つの主要なアーキテクチャパターンを比較分析し、セキュリティと運用効率のトレードオフを示唆している。
キーポイント
2つの統合パターン
エージェントをサンドボックス内部で実行するパターン(密結合・ローカル開発に近い)と、外部からサンドボックスをツールとして呼び出すパターン(疎結合・セキュリティ管理が容易)の2つの主要な設計方針を提示。
セキュリティと運用のトレードオフ
パターン1はAPIキーをサンドボックス内に置く必要がありセキュリティリスクがある一方、パターン2はロジックの更新が容易でシークレット管理が外部で完結するため、用途に応じた選択が必要。
インフラストラクチャの重要性
サンドボックスとの通信にはWebSocketやHTTPレイヤー、セッション管理などのインフラ整備が必要であり、プロバイダー(E2B, Runloopなど)のSDK支援の有無が実装負荷に直結する。
Sandbox as Toolの利点
コンテナイメージの再構築不要で反復開発が高速化され、APIキーなどの機密情報はサンドボックス外に保持できる。
Sandbox as Toolの追加メリット
複数のリモートサンドボックスでの並列実行や、コード実行時のみ課金される従量課金モデルが可能になる。
Sandbox as Toolの課題
実行呼び出しごとにネットワーク境界を跨ぐため、小さな実行タスクが多い場合、ネットワークレイテンシが累積する。
Stateful sessions reduce latency
Many sandbox providers offer stateful sessions where variables, files, and installed packages persist across invocations within the same session. This can mitigate some of the latency concerns by reducing the number of round trips needed.
影響分析・編集コメントを表示
影響分析
この記事は、AIエージェントの実装において「環境分離」が標準化しつつある現状を捉えており、開発者がセキュリティリスクと運用コストのバランスをどう取るかが重要な判断基準になることを示している。特に、エージェントが自律的にコードを実行する際の情報隔離とシークレット管理のアーキテクチャ設計は、次世代エージェントプラットフォームの競争において重要な差別化要素となる。
編集コメント
エージェント開発のベストプラクティスが整理されつつあり、セキュリティ要件が高い場合はパターン2を、開発速度を優先する場合はパターン1を選ぶといった明確な指針が得られる。
Witan LabsのNuno Campos氏、E2BのTomas Beran氏とMikayel Harutyunyan氏、RunloopのJonathan Wall氏、Zo ComputerのBen Guo氏に、レビューとコメントをいただき感謝します。
ますます多くのエージェントがワークスペースを必要としています。ワークスペースとは、コードを実行し、パッケージをインストールし、ファイルにアクセスできるコンピュータのことです。サンドボックスはこれを提供します。
エージェントとサンドボックスを統合するためのアーキテクチャパターンには2つあります:
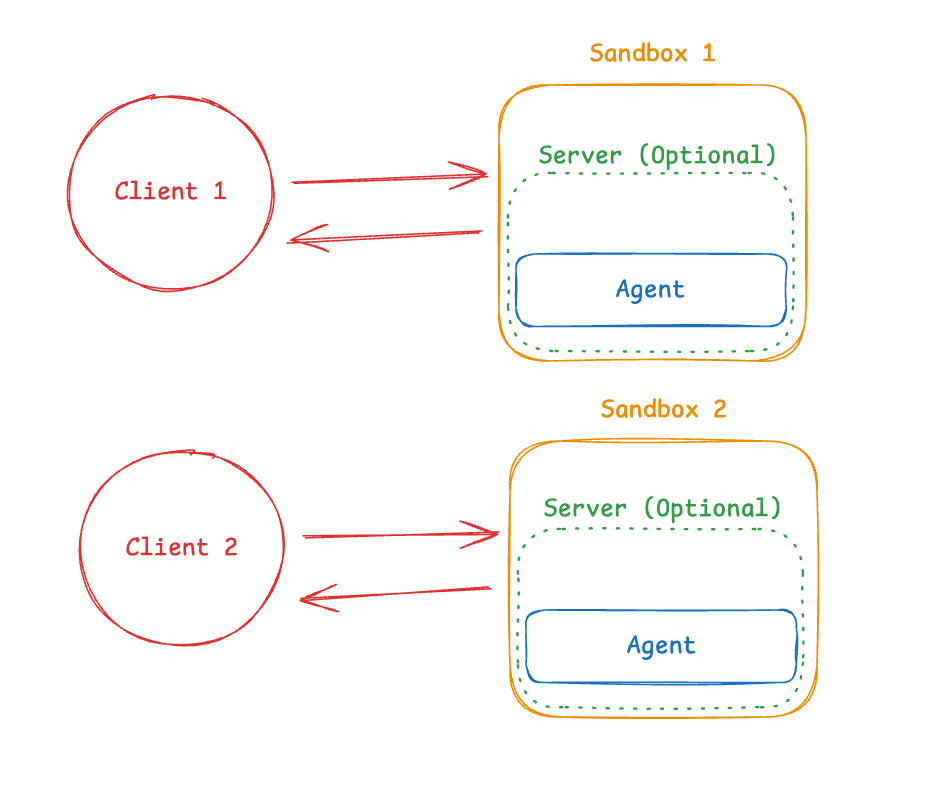
パターン1(エージェントINサンドボックス): エージェントはサンドボックス内で実行され、ネットワークを介して通信します。利点: ローカル開発を模倣し、エージェントと環境の緊密な結合が可能です。
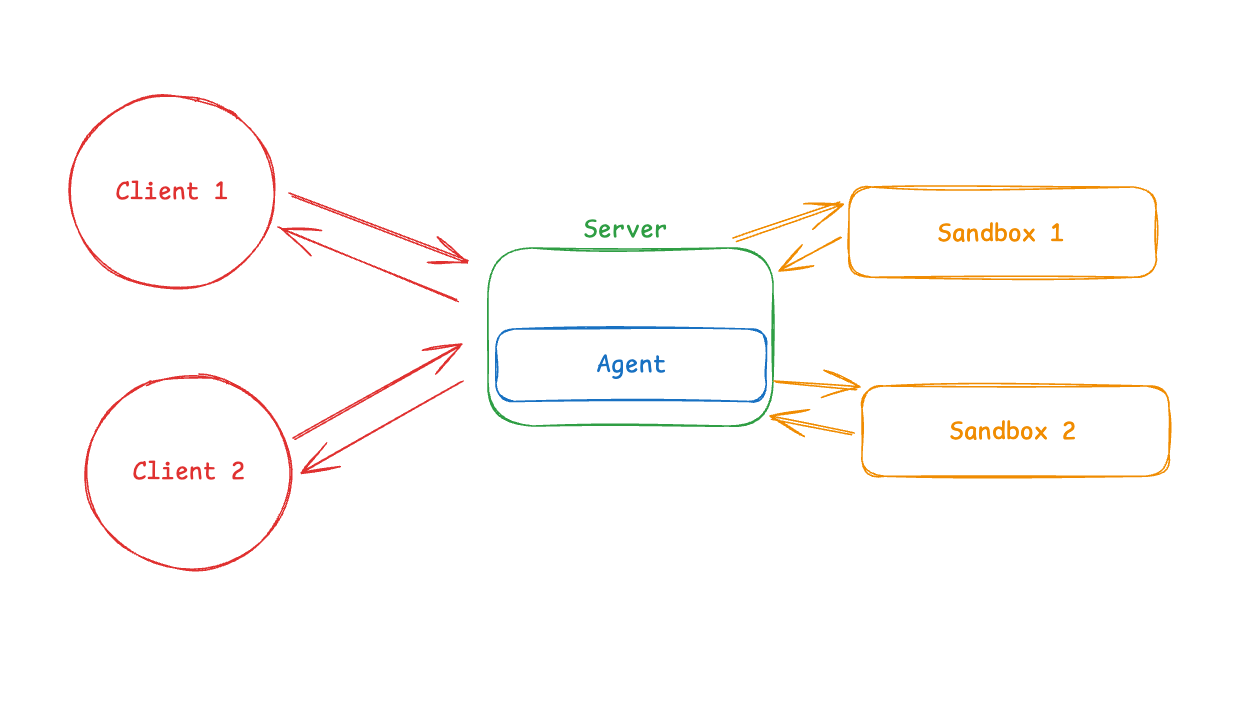
パターン2(ツールとしてのサンドボックス): エージェントはローカルまたは自社サーバーで実行され、実行のためにサンドボックスをリモートで呼び出します。利点: エージェントロジックの更新が容易、APIキーはサンドボックスの外に保持、関心の分離が明確です。
deepagentsはシンプルな設定で両方のパターンをサポートします
ますます多くのエージェントがワークスペースを必要としています。ワークスペースとは、コードを実行し、パッケージをインストールし、ファイルにアクセスできるコンピュータのことです。そのワークスペースは、エージェントがあなたの認証情報、ファイル、ネットワークにアクセスできないように分離されている必要があります。サンドボックスは、エージェントの環境とホストシステムの間に境界を作ることで、この分離を提供します。これらのエージェントを構築するチームが直面する問題は、サンドボックスを使うかどうかではなく、エージェントアーキテクチャとどう統合するかです。
エージェントが実行される場所に基づいて、2つの一般的なパターンがあります: サンドボックス内か、その外かです。各パターンには異なる利点とトレードオフがあります。
注: この記事では、エージェントに完全な「コンピュータ」を提供するサンドボックス、つまりDockerコンテナやVMのような完全な実行環境に焦点を当てます。プロセスレベルのサンドボックス(bubblewrapなど)や言語レベルのサンドボックス(Pyodideなど)は扱いません。
パターン1: エージェントはサンドボックス内で実行
このパターンでは、エージェントはサンドボックス内で実行されます。あなたはネットワークを介してそれと通信します。
実際の様子:
エージェントフレームワークがプリインストールされたDockerまたはVMイメージを構築し、サンドボックス内で実行し、外から接続してメッセージを送信します。エージェントはAPIエンドポイント(通常はHTTPまたはWebSocket)を公開し、あなたのアプリケーションはサンドボックスの境界を越えてそれと通信します。
このパターンはローカル開発に非常に近い形を模倣します。例えば、deepagentsを実行する場合、
サンドボックスの境界を越えた通信にはインフラストラクチャが必要です。一部のプロバイダーはこれをSDKで処理します。例えば、OpenCodeのようなエージェントはサンドボックス内でサーバーを実行し、E2BのようなプロバイダーはこれをクリーンなAPIを通じて公開できます。もしプロバイダーがこれを提供していない場合、セッション管理やエラーハンドリングを含むWebSocketまたはHTTPレイヤーを自分で構築する必要があります。
APIキーは、エージェントが推論呼び出しを行うために、サンドボックス内に存在しなければなりません。これは、分離技術の脆弱性を通じてであれ、認証情報を流出させるプロンプトインジェクション攻撃を通じてであれ、サンドボックスが侵害された場合に潜在的なセキュリティリスクを生み出します。注: E2BやRunloopのようなプロバイダーがシークレットボールト機能に取り組んでいるのを見ています。これはこの問題に対処するものです。
更新にはコンテナイメージの再構築と再デプロイが必要であり、開発中のイテレーションサイクルを遅くする可能性があります。
もう一つの欠点は、エージェントがアクティブになる前にサンドボックスを再開する必要があることで、これはしばしば追加のロジックを必要とします。
エージェントのIPを保護することに関心がある人にとっては、エージェントがサンドボックス内で実行されている場合、エージェントのコードとプロンプト全体を流出させることがはるかに簡単になります。
Witan LabsのNuno Campos氏は、別のセキュリティリスクも指摘しています:「エージェントインサンドボックスのもう一つの欠点は、事実上、あなたのエージェントのどの部分も、bashツールよりも多くの権限を持つことができないということだと思います。例えば、bashツールとWeb検索やWebフェッチができるツールを持つエージェントを想像してみてください。すると、LLMが生成するコードはすべて無制限のWebフェッチを行うことができます(これは大きなセキュリティリスクです)。もしツールとしてのサンドボックスであれば、セキュリティ境界がエージェント全体ではなくbashツールの周りにあるので、LLM生成コードに与える権限よりも多くの権限を持つツールを簡単に持つことができます(これは多くのエージェントにとって非常に有用に聞こえます)。」
パターン2: ツールとしてのサンドボックス
このパターンでは、エージェントはあなたのマシンまたはサーバー上で実行されます。コードを実行する必要があるとき、APIを介してリモートのサンドボックスを呼び出します。
実際の様子:
あなたのエージェントはローカル(または自社サーバー)で実行され、実行が必要なコードを生成すると、サンドボックスプロバイダーのAPI(E2B、Modal、Daytona、Runloopなど)を呼び出します。プロバイダーのSDKがすべての通信の詳細を処理します。あなたのエージェントの視点からは、サンドボックスは単なるもう一つのツールです。
コンテナイメージを再構築することなくエージェントコードを即座に更新できるため、開発中のイテレーションが高速化されます。APIキーはサンドボックスの外に留まります。分離されるのは実行だけです。これにより、関心の分離がより明確になります: エージェントの状態(会話履歴、推論チェーン、メモリ)はエージェントが実行される場所に存在し、サンドボックスとは分離されています。これは、サンドボックスの障害がエージェントの状態を失わないことを意味し、エージェントのコアロジックに影響を与えずにサンドボックスのバックエンドを切り替えることができます。
E2BのTomas Beran氏が指摘する、このオプションの他の2つの利点:
複数のリモートサンドボックスで並行してタスクを実行するオプションがあること
プロセス全体の実行時間ではなく、コードを実行している間だけサンドボックスの料金を支払うこと
Ben Guo氏は、エージェントのランタイムとサンドボックスのランタイムを分離することの利点について最後のポイントを追加しています:「私たちがパターン2を選んだ理由は、あなたが言及した理由のためですが、また、エージェントハーネスをGPUマシンで実行することが理にかなう未来に備えてでもあります。一般的に、永続的なサンドボックスと推論ハーネスの間では環境要件が分岐するように感じられます」
ネットワーク遅延が主な欠点です。各実行呼び出しはネットワーク境界を越えます。多くの小さな実行があるワークロードでは、これが累積する可能性があります。
多くのサンドボックスプロバイダーは、同じセッション内の呼び出し間で変数、ファイル、インストールされたパッケージが永続するステートフルなセッションを提供しています。これは、必要なラウンドトリップの回数を減らすことで、遅延に関する懸念の一部を緩和することができます。
パターンの選択
以下の場合にパターン1を選択してください:
エージェントと実行環境が緊密に結合している場合(例えば、エージェントが特定のライブラリや複雑な環境状態への永続的なアクセスを必要とする場合)
本番環境をローカル開発に可能な限り近づけたい場合
プロバイダーのSDKが通信レイヤーを処理してくれる場合
以下の場合にパターン2を選択してください:
開発中にエージェントロジックを迅速にイテレーションする必要がある場合
APIキーをサンドボックスの外に保持したい場合
エージェントの状態と実行環境の間のより明確な分離を好む場合
実装例
これらのパターンを具体的にするために、組み込みのサンドボックスサポートを持つオープンソースのエージェントフレームワークであるdeepagentsを使用した例を示します。同様のパターンは他のエージェントフレームワークにも適用できます。
パターン1: エージェントINサンドボックス
パターン1では、まずエージェントがプリインストールされたイメージを構築します:
FROM python:3.11 RUN pip install deepagents-cli
次に、それをサンドボックス内で実行します。完全な実装には、アプリケーションとサンドボックス内のエージェント間の通信を処理するための追加のインフラストラクチャ(WebSocketまたはHTTPサーバー、セッション管理、エラーハンドリング)が必要です。これはこの記事の範囲を超えていますが、これについてより詳細に掘り下げるフォローアップ記事をいくつか用意する予定です。
パターン2: ツールとしてのサンドボックス
from daytona import Daytona from langchain_anthropic import ChatAnthropic from deepagents import create_deep_agent from langchain_daytona import DaytonaSandbox # E2B、Runloop、Modalでも同様に実行可能 sandbox = Daytona().create() backend = DaytonaSandbox(sandbox=sandbox) agent = create_deep_agent( model=ChatAnthropic(model="claude-sonnet-4-20250514"), system_prompt="サンドボックスアクセス権を持つPythonコーディングアシスタントです。", backend=backend, ) result = agent.invoke( { "messages": [ { "role": "user", "content": "小さなPythonスクリプトを実行してください", } ] } ) sandbox.stop()
このコードが実行されるときに起こること:
エージェントはあなたのマシン上でローカルに計画を立てます
問題を解決するためのPythonコードを生成します
Runloop APIを呼び出し、それは
原文を表示
Thank you to Nuno Campos from Witan Labs, Tomas Beran and Mikayel Harutyunyan from E2B, Jonathan Wall from Runloop, and Ben Guo from Zo Computer for their review and comments.
More and more agents need a workspace: a computer where they can run code, install packages, and access files. Sandboxes provide this.
There are two architecture patterns for integrating agents with sandboxes:Pattern 1 (Agent IN Sandbox): Agent runs inside the sandbox, you communicate with it over the network. Benefits: mirrors local development, tight coupling between agent and environment.
Pattern 2 (Sandbox as Tool): Agent runs locally/on your server, calls sandbox remotely for execution. Benefits: easy to update agent logic, API keys stay outside sandbox, cleaner separation of concerns.
deepagents supports both patterns with simple configuration
An increasing number of agents need a workspace - a computer where they can run code, install packages, and access files. That workspace needs to be isolated so the agent can't access your credentials, files, or network. Sandboxes provide this isolation by creating a boundary between the agent's environment and your host system. The question teams building these agents face isn't whether to use sandboxes - it's how to integrate them with their agent architecture.
There are two common patterns based on where the agent runs: inside the sandbox or outside of it. Each pattern has different benefits and trade-offs.
Note: this post focuses on sandboxes that give agents a full 'computer’ - complete execution environments like Docker containers or VMs. We won't cover process-level sandboxes (like bubblewrap) or language-level sandboxes (like Pyodide).
Pattern 1: Agent Runs IN Sandbox
In this pattern, the agent runs inside the sandbox. You communicate with it over the network.
What this looks like in practice:
You build a Docker or VM image with your agent framework pre-installed, run it inside the sandbox, and connect from outside to send messages. The agent exposes an API endpoint (typically HTTP or WebSocket), and your application communicates with it across the sandbox boundary.
This pattern mirrors local development closely—if you run deepagents
Communication across the sandbox boundary requires infrastructure. Some providers handle this in their SDK—for example, agents like OpenCode run a server inside the sandbox, and providers like E2B can expose this through a clean API. If your provider doesn't offer this, you'll need to build the WebSocket or HTTP layer yourself, including session management and error handling.
API keys must live inside the sandbox to allow the agent to make inference calls. This creates a potential security risk if the sandbox is compromised, whether through a vulnerability in the isolation technology or through prompt injection attacks that exfiltrate credentials. Note: we see providers like E2B and Runloop working on secret vault capabilities, which addresses this.
Updates require rebuilding the container image and redeploying, which can slow iteration cycles during development.
Another downside is that the sandbox must be resumed before the agent becomes active, which often requires extra logic.
For those worried about protecting the IP of their agents, if your agent is running in the sandbox it becomes much easier to exfiltrate the entire code and prompts of the agent.
Nuno Campos from Witan Labs also points out another security risk: “I’d say another downside of agent in sandbox is that effectively no part of your agent can have more privileges than the bash tool does. E.g. imagine you want an agent that has a bash tool and a tool that can do web search or web fetch, then all the LLM generated code can do unlimited web fetches (which is a big security risk). If it’s sandbox as tool then you can have tools with more permissions than you give to llm generated code (which sounds very useful for many agents) trivially, as the security boundary is around the bash tool, not the whole agent.”
Pattern 2: Sandbox as Tool
In this pattern, the agent runs on your machine or server. When it needs to execute code, it calls a remote sandbox via API.
What this looks like in practice:
Your agent runs locally (or on your server), and when it generates code that needs to execute, it calls out to a sandbox provider's API (like E2B, Modal, Daytona, or Runloop). The provider's SDK handles all the communication details. From your agent's perspective, the sandbox is just another tool.
You can update agent code instantly without rebuilding container images, which speeds up iteration during development. API keys stay outside the sandbox—only execution happens in isolation. This provides cleaner separation of concerns: agent state (conversation history, reasoning chains, memory) lives where your agent runs, separate from the sandbox. This means sandbox failures don't lose your agent's state, and you can switch sandbox backends without affecting your agent's core logic.
Two other benefits of this option, as pointed out by Tomas Beran of E2B:
Having the option to run tasks in multiple remote sandboxes in parallel
Paying for sandboxes only when executing code, rather than for the whole process runtime.
Ben Guo adds a final point about the benefits of separating agent runtime from sandbox runtime: “We chose Pattern 2 for the reasons you mention, but also in preparation for a future where it makes sense to run the agent harness in a GPU machine – generally feels like the environment requirements will diverge between the persistent sandbox and the inference harness”
Network latency is the main downside. Each execution call crosses the network boundary. For workloads with many small executions, this can add up.
Many sandbox providers offer stateful sessions where variables, files, and installed packages persist across invocations within the same session. This can mitigate some of the latency concerns by reducing the number of round trips needed.
Choosing Between Patterns
Choose Pattern 1 when:
The agent and execution environment are tightly coupled (for example, the agent needs persistent access to specific libraries or complex environment state)
You want production to mirror local development closely
Your provider's SDK handles the communication layer for you
Choose Pattern 2 when:
You need to iterate quickly on agent logic during development
You want to keep API keys outside the sandbox
You prefer cleaner separation between agent state and execution environment
Implementation Example
To make these patterns concrete, we'll show examples using deepagents, an open-source agent framework with built-in sandbox support. Similar patterns apply to other agent frameworks.
Pattern 1: Agent IN Sandbox
For Pattern 1, first you build an image with your agent pre-installed:
FROM python:3.11 RUN pip install deepagents-cli
Then run it inside the sandbox. A complete implementation requires additional infrastructure to handle communication between your application and the agent inside the sandbox (WebSocket or HTTP server, session management, error handling). This is beyond the scope of this post, but we will have some follow up posts diving into this in more detail.
Pattern 2: Sandbox as Tool
from daytona import Daytona from langchain_anthropic import ChatAnthropic from deepagents import create_deep_agent from langchain_daytona import DaytonaSandbox # Can also do this with E2B, Runloop, Modal sandbox = Daytona().create() backend = DaytonaSandbox(sandbox=sandbox) agent = create_deep_agent( model=ChatAnthropic(model="claude-sonnet-4-20250514"), system_prompt="You are a Python coding assistant with sandbox access.", backend=backend, ) result = agent.invoke( { "messages": [ { "role": "user", "content": "Run a small python script", } ] } ) sandbox.stop()
Here's what happens when this code runs:
The agent plans locally on your machine
It generates Python code to solve the problem
It calls the Runloop API, which executes the code in a remote sandbox
The sandbox returns the result
The agent sees the output and continues reasoning locally
Agents need to execute code in isolated environments for security. There are two architecture patterns: running the agent inside the sandbox (mirrors local development, tight coupling) or running it outside with the sandbox as a tool (easy updates, API keys stay secure). Each has different benefits and trade-offs depending on your needs.
deepagents supports both patterns with simple configuration. Try it out to see which pattern works best for your use case.
Join our newsletter
Updates from the LangChain team and community
Processing your application...
Success! Please check your inbox and click the link to confirm your subscription.
Sorry, something went wrong. Please try again.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み