Amazon Nova Multimodal Embeddingsで強化する動画意味検索
AWSは、テキスト、画像、動画、音声を単一の意味空間にマッピングするAmazon Nova Multimodal Embeddingsを発表し、従来のテキスト変換に依存しない高精度な動画セマンティック検索ソリューションをAmazon Bedrock上で構築する方法を紹介した。
キーポイント
動画セマンティック検索の産業的価値
スポーツ放送、スタジオ、ニュース組織など様々な業界で、動画内の特定シーンを迅速かつ正確に検索する需要が高まっており、コンテンツ配信と収益化に重要な役割を果たしている。
従来手法の限界
現在主流の手法は動画信号をテキストに変換して検索するが、時間的情報の消失やトランスクリプションエラーなど、重要な情報が失われる問題がある。
Amazon Nova Multimodal Embeddingsの革新性
テキスト、文書、画像、動画、音声をネイティブに処理し、単一の検索可能な表現に直接マッピングする統一埋め込みモデルで、詳細を失わずに高精度な検索を実現する。
実装ソリューションの提供
Amazon Bedrock上で動画セマンティック検索ソリューションを構築する方法を紹介し、ユーザーが独自コンテンツで試せる参照実装を提供している。
メタデータの活用による検索の最適化
技術的メタデータ(解像度、ファイルサイズ)や文脈的メタデータ(場所、ムード、ブランド)を適切にバランスさせ、検索時にメタデータフィルターを重ねることで、検索空間を絞り込み、スケーラビリティと精度を向上させることができる。
意図認識に基づくクエリルーティング
Haikuモデルを使用して各クエリの意図を分析し、視覚、音声、文字起こし、メタデータの各モダリティチャネルに重みを割り当てるインテリジェントなルーターを構築することで、検索の関連性を最適化する。
重要な引用
Video semantic search is unlocking new value across industries.
A user searching for 'a tense car chase with sirens' is asking about a visual event and an audio event at the same time.
What if you had a model that could process all modalities and directly map them into a single searchable representation without losing detail?
Amazon Nova Multimodal Embeddings is a unified embedding model that natively processes text, documents, images, video, and audio into a shared semantic vector space.
The right balance depends on your search use case. Additionally, overlaying metadata filters during retrieval can further enhance search scalability and accuracy by narrowing the search space before semantic matching.
Intent is everything. To solve this, we built an intelligent intent analysis router that uses the Haiku model to analyze each incoming query and assign weight to each modality channel: visual, audio, transcript, and metadata.
影響分析・編集コメントを表示
影響分析
この技術は動画コンテンツの検索・活用方法を根本から変革する可能性があり、メディア・エンターテインメント産業のワークフロー効率化と新たな収益機会を創出する。マルチモーダルAIの実用化が進み、企業の動画資産活用が高度化する契機となる。
編集コメント
AWSがマルチモーダルAIの実用化で先行する姿勢を示す記事。動画検索という具体的なユースケースを通じて、生成AI基盤戦略の一環としての埋め込み技術の重要性を明確に伝えている。
動画のセマンティック検索(Video Semantic Search)は、業界全体で新たな価値を解き放ちつつあります。ビデオファーストの体験への需要は、組織がコンテンツを配信する方法を変革しており、顧客は動画内の特定の瞬間へ迅速かつ正確にアクセスすることを期待しています。例えば、スポーツ放送局は選手が得点した正確な瞬間を抽出し、ファンにハイライトクリップを即座に配信する必要があります。スタジオは、数千時間にわたるアーカイブコンテンツ全体から特定の俳優が出演するすべてのシーンを見つけ出し、パーソナライズされた予告編やプロモーションコンテンツを作成する必要があります。ニュース組織は、雰囲気、場所、またはイベントに基づいて映像を検索し、競合他社よりも速く速報記事を公開する必要があります。目標は同じです。エンドユーザーに動画コンテンツを迅速に提供し、瞬間を捉え、その体験から収益化することです。
動画は、テキストや画像などの他のモーダリティ(Modalities)と比較して本質的に複雑です。それは、画面で展開される視覚シーン、環境音や効果音、会話音声、時間的情報、そしてアセットを記述する構造化メタデータという複数の非構造化シグナル(Signals)を統合しているためです。「サイレンの鳴る緊迫したカーチェイス」を検索するユーザーは、視覚イベントと音声イベントの両方を同時に求めています。特定の選手の名前で検索するユーザーは、画面に大きく映っているが、音声で名前が呼ばれない人物を探している可能性があります。
現在の主流なアプローチは、トランスクリプション(Transcription)、手動タグ付け、または自動キャプション生成のいずれかを通じてすべての動画シグナルをテキストに落とし込み、その後テキスト埋め込み(Text Embeddings)を検索に適用するものです。これは対話中心のコンテンツでは機能しますが、動画をテキストに変換すると本質的に重要な情報が失われます。時間的な理解が消失し、視覚・音声の品質の問題により文字起こしのエラーが発生します。すべてのモーダリティを処理し、詳細を失うことなく単一の検索可能な表現に直接マッピングするモデルがあったらどうでしょうか?Amazon Nova Multimodal Embeddings は、テキスト、ドキュメント、画像、動画、音声をネイティブに処理し、共有のセマンティックベクトル空間(Semantic Vector Space)へ埋め込む統一されたエンベッディングモデルです。これにより、最先級の検索精度とコスト効率を実現します。
この記事では、Nova Multimodal Embeddings を使用して Amazon Bedrock 上で動画セマンティック検索ソリューションを構築する方法をご紹介します。このソリューションはユーザーの意図をインテリジェントに理解し、すべてのシグナルタイプに対して同時に正確な動画結果を返します。また、ご自身のコンテンツでデプロイして探索できるリファレンス実装も共有します。
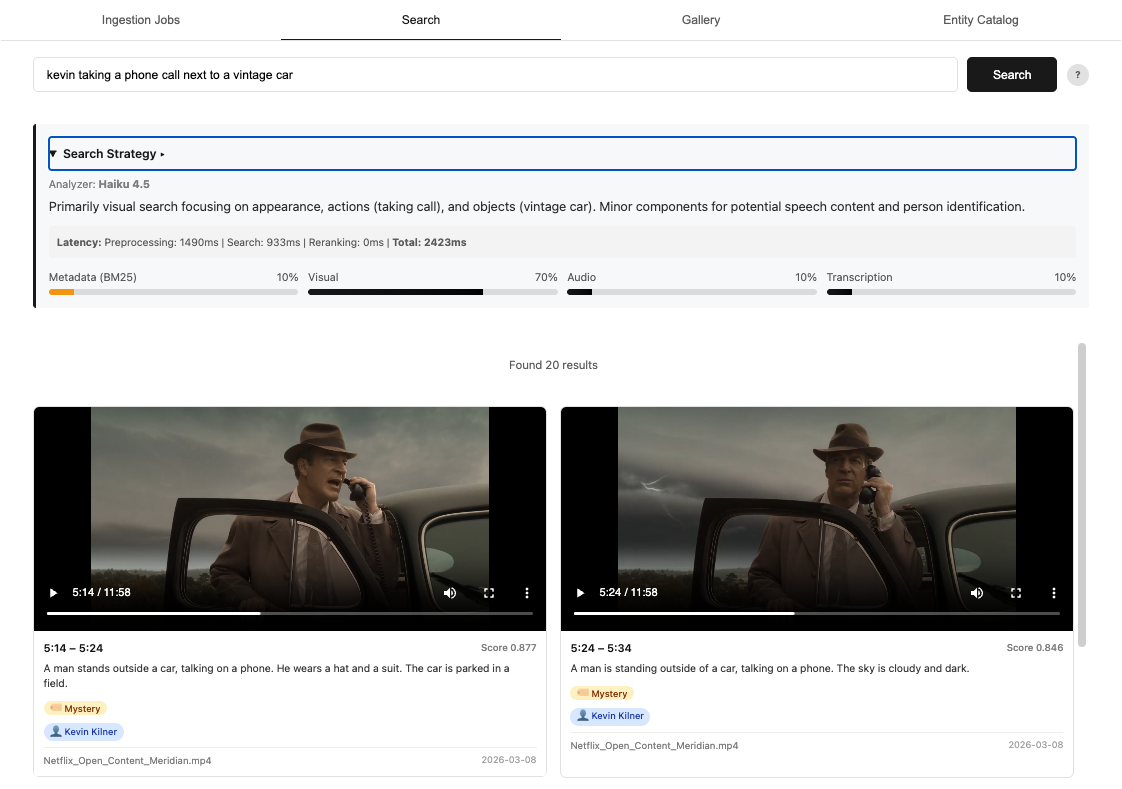
図1:最終検索ソリューションの例スクリーンショット
ソリューションの概要
私たちのソリューションは、Nova Multimodal Embeddings を基盤とし、すべての動画モーダリティ(video modalities)にわたってセマンティック(意味)とレキシカル(語彙)の信号を融合するインテリジェントなハイブリッド検索アーキテクチャ(hybrid search architecture)を組み合わせて構築されています。レキシカル検索(lexical search)は正確なキーワードやフレーズに一致し、セマンティック検索(semantic search)は意味と文脈を理解します。このハイブリッドアプローチの選択理由とそのパフォーマンス上の利点については、後のセクションで説明します。
 image
image
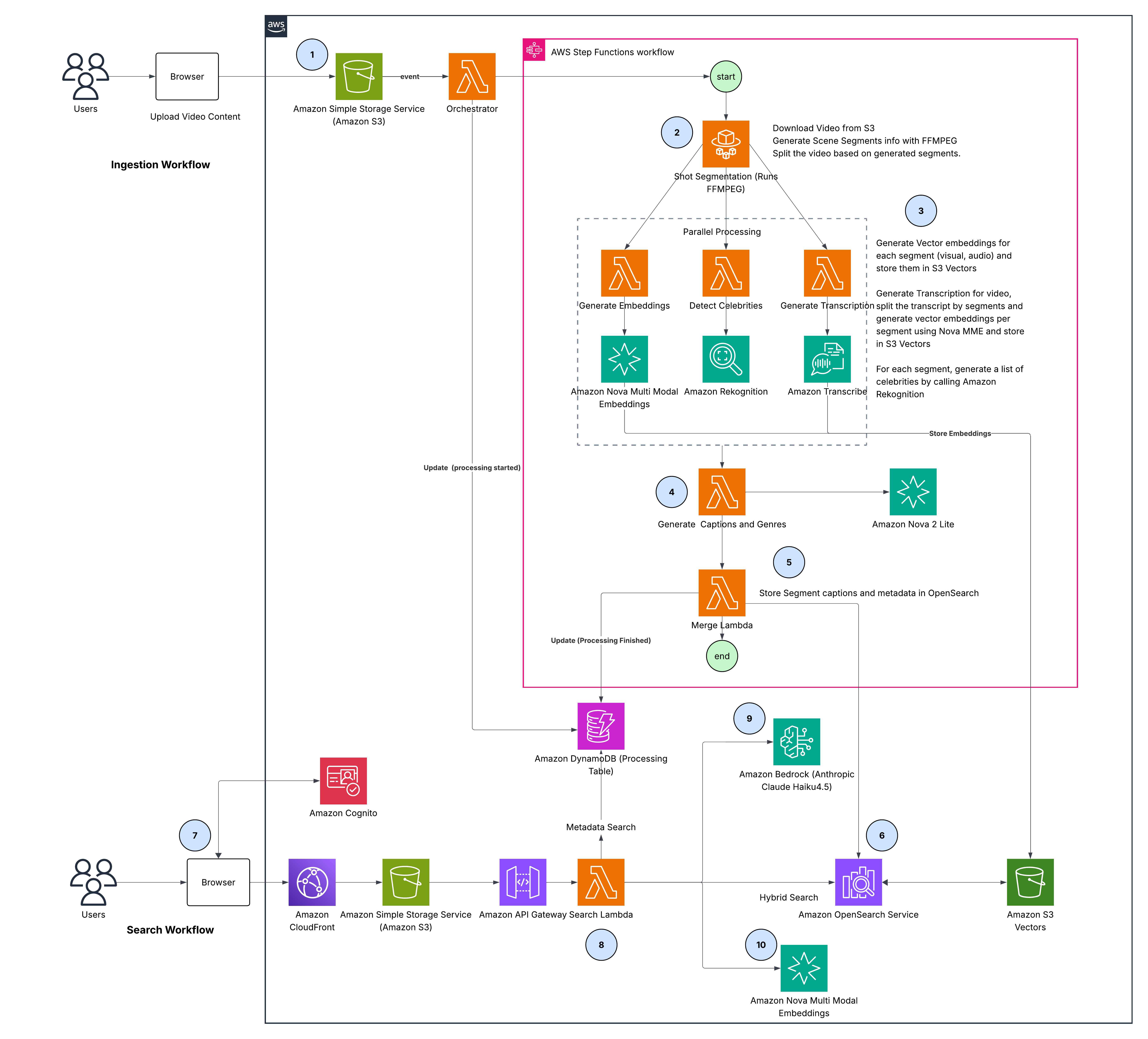
図2:エンドツーエンドのソリューションアーキテクチャ
このアーキテクチャは2つのフェーズで構成されています。動画を検索可能なエンベッディング(embeddings)に変換するインジェストパイプライン(ingestion pipeline、ステップ1-6)、およびユーザークエリ(user queries)をこれらの表現に対してインテリジェントにルーティングし、結果をランク付けされたリスト(ranked list)に統合する検索パイプライン(search pipeline、ステップ7-10)です。各ステップの詳細は以下の通りです:
- アップロード – ブラウザ経由でアップロードされた動画は Amazon Simple Storage Service (Amazon S3) に保存され、オーケストレータの AWS Lambda が Amazon DynamoDB のステータスを更新し、AWS Step Functions パイプラインを開始します
- ショットセグメンテーション – AWS Fargate は FFmpeg のシーン検出機能を使用して、動画を意味的に一貫したセグメントに分割します
- 並列処理 – 3つの並行ブランチが各セグメントを処理します:
Embeddings: Nova Multimodal Embeddings は視覚および音声用の1024次元ベクトルを生成し、Amazon S3 Vectors に保存します
- 文字起こし(Transcription): Amazon Transcribe は音声からテキストへの変換を行い、セグメントにアライメントします。Amazon Nova Multimodal Embeddings はテキスト埋め込みを生成し、Amazon S3 Vectors に保存します
- 有名人検出(Celebrity detection): Amazon Rekognition は著名な人物を識別し、タイムスタンプに基づいてセグメントにマッピングします
- キャプションおよびジャンル生成 – Amazon Nova 2 Lite は、視覚コンテンツと文字起こしデータからセグメントレベルのキャプションおよびジャンルラベルを合成します
- マージ – AWS Lambda はすべてのメタデータ(キャプション、文字起こし、有名人、ジャンル)を結合し、Amazon S3 Vectors から埋め込みを取得します
- インデックス – メタデータとベクトルを備えた完全なセグメントドキュメントが、Amazon OpenSearch Service へ一括インデックス登録されます
- 認証 – ユーザーは Amazon Cognito を介して認証を行い、Amazon CloudFront 経由でフロントエンドにアクセスします
- クエリ処理 – Amazon API Gateway はリクエストを Search Lambda にルーティングし、同Lambdaは意図分析(intent analysis)とクエリ埋め込みの2つの並列操作を実行します
- 意図分析 – Amazon Bedrock(Anthropic Claude Haiku を使用)は、視覚、音声、文字起こし、メタデータ各モダリティに対して関連性重み(0.0〜1.0)を割り当てます
- クエリ埋め込み – Nova Multimodal Embeddings は、視覚、音声、文字起こしの類似度検索のためにクエリを3回埋め込みます
この柔軟なアーキテクチャは、ほとんどの動画検索システムが見落としがちな4つの重要な設計上の意思決定に対応しています。それは、時間的コンテキスト(temporal context)の維持、マルチモーダルクエリ(multimodal queries)の処理、大規模なコンテンツライブラリ全体でのスケーリング、そして検索精度の最適化です。完全な参照実装は GitHub, で公開されており、以下のウォークスルーに沿って進めていただくことで、各意思決定がすべてのシグナルタイプ(signal types)に対して正確かつスケーラブルな検索にどのように貢献するかをご確認いただけます。
コンテキストの連続性を考慮したセグメンテーション(Segmentation for context continuity)
埋め込み(embedding)を生成する前に、動画を検索可能な単位に分割する必要があります。ここで設定する境界線は検索精度に直接影響します。各セグメントが検索の最小単位となります。セグメントが短すぎると、その瞬間に意味を与える周囲のコンテキスト(context)を失います。長すぎると複数のトピックやシーンが融合し、関連性が薄れて検索システムが適切な瞬間を抽出しにくくなります。簡略化のため、固定長のチャンクから始めることもできます。Nova マルチモーダル埋め込みは埋め込みあたり最大30秒をサポートしており、完全なシーンを捉える柔軟性を提供します。ただし、以下の図に示すように、固定の境界線は動作の途中や文の意味の途中でシーンを無理やり切り捨てたり、思考の途中で文を分割したりする可能性があり、検索可能な瞬間の意味するセマンティックな意味(semantic meaning)を損なうことに注意してください。

図3:動画セグメンテーション戦略(Video segmentation strategies)
目標はセマンティックな連続性(semantic continuity)を確保することです。各セグメントは時間の恣意的な切り取りではなく、意味の一貫した単位を表すべきです。固定の10秒ブロックは生成が容易ですが、コンテンツの自然な構造を無視します。セグメント途中でシーンが切り替わると、視覚的なアイデアが2つのチャンクに分割され、検索精度と埋め込み品質の両方が低下します。
これを解決するため、視覚コンテンツが実際にどこで変化するかを特定するためにFFmpegのシーン検出(scene detection)機能を使用します。FFmpegは、動画処理、フォーマット変換、分析に広く使用されているオープンソースのマルチメディアフレームワークです。以下の_detect_scenes関数は、動画に対してffprobe(FFmpegのメディア検査用関連ツール)を実行し、各シーン境界を示すタイムスタンプのリストを返します:
def _detect_scenes(video_path):
result = subprocess.run(
['ffprobe', '-v', 'quiet', '-show_entries', 'frame=pts_time', '-of', 'csv=p=0',
'-f', 'lavfi', f"movie={video_path},select='gt(scene\\,{SCENE_THRESHOLD})'"],
capture_output=True, text=True
) 出力は12.345、28.901、45.678のようなタイムスタンプの単純なリストであり、それぞれがシーンが切り替わる自然な境界を示します。
これらの境界が得られたら、セグメンテーションアルゴリズムは許容範囲内で最も近いシーン変更点に各カットをスナップさせ、現在の開始位置から最小5秒、最大15秒の範囲で約10秒を目標とします。その範囲内にシーン変更がない場合は、目標の長さでハードカット(hard cut)にフォールバックします。その結果、8.3秒、11.1秒、9.8秒、12.4秒、7.6秒といった自然なセグメントのセットが得られ、それぞれが固定タイマーではなく実際のシーン境界に合わせて調整されます。
この単純なショットベースのセグメンテーション(shot-based segmentation)により、セグメント境界が恣意的なカットではなく自然な視覚的トランジション(visual transitions)と一致するよう保証されます。ターゲットセグメントの持続時間は、コンテンツの種類とユースケースに基づいて調整すべきです:カットが頻繁なアクション中心のコンテンツは、このようなビジュアルセグメンテーション(visual segmentation)から恩恵を受ける可能性があります。一方、ロングテイクのドキュメンタリーやインタビューコンテンツは、より長くトピックベースのセグメンテーション(topic-based segmentation)の方が適している場合があります。オーディオベースのトピックセグメンテーションや視覚・音声の組み合わせアプローチなど、より高度なセグメンテーション手法については、Media2Cloud on AWS Guidance: Scene and Ad-Break Detection and Contextual Understanding for Advertising Using Generative AI. をご一読いただくことをお勧めします。
ビジュアル、オーディオ、トランスクリプト信号に対して個別のエンベディングを生成する
セグメントが定義された後、アプローチ間の最大の品質差が生じるのはエンベディングモデル(embedding model)の選択です。現在主流のアプローチは、エンベディングを生成する前にすべてのビデオ信号をテキストへの変換(grounding)を行いますが、前述の通り、ビデオが伝える意味はトランスクリプトやキャプションで表現できるものを大幅に超えています。ビジュアルアクション、環境音、画面テキスト、エンティティコンテキスト(entity context)は、完全に消失するか、不正確な記述によって近似されるかのいずれかです。
Nova Multimodal Embeddings は根本的にこの状況を変えます。これは2つのモードでエンベディングを生成できるビデオネイティブモデル(video-native model)だからです。combined mode(結合モード)は、視覚信号と音声信号を融合させて統一された表現を作成し、最も重要な信号を一緒に捉えます。このアプローチはセグメントごとに1つのエンベディングのみを必要とするため、ストレージコストと検索レイテンシー(retrieval latency)の削減に役立ちます。一方、AUDIO_VIDEO_SEPARATE モードは、個別のビジュアルエンベディングとオーディオエンベディングを生成します。このアプローチは、モダリティ固有のエンベディングにおいて最大限の表現を提供し、ビジュアルコンテンツとオーディオコンテンツのどちらを検索するかをより細かく制御できるメリットがあります。
当社の実装では、Amazon Transcribe から派生した3つ目のスピーチエンベディング(speech embedding)まで追加しました。このエンベディングは、前後のセグメントタイムスタンプに対して完全な文のトランスクリプトをアライニング(整列)して作成されており、音声のセマンティックな完全性(semantic integrity)を保持し、完全な思考が2つのエンベディングにまたがって分割されないようにしています。
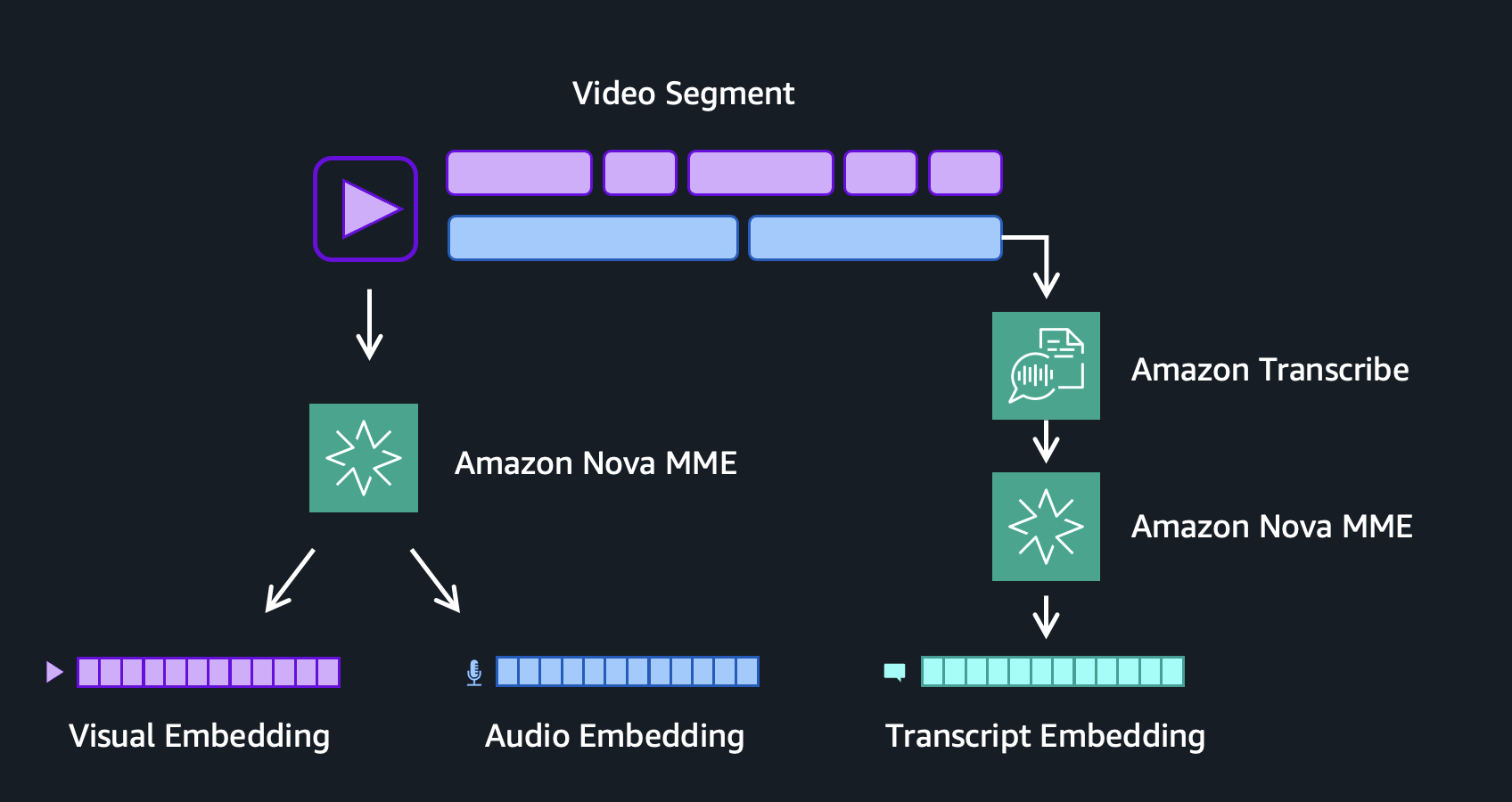
Figure 4: ビデオセグメントごとのビジュアル、オーディオ、スピーチエンベディングの生成
3つの埋め込み(embeddings)を組み合わせることで、ビデオセグメントの全信号空間をカバーできます。ビジュアル埋め込みはカメラが捉えるもの、つまりオブジェクト、シーン、アクション、色彩、空間構成をキャプチャします。オーディオ埋め込みはマイクが拾うもの、つまり音楽、効果音、環境ノイズ、シーンの音響的テクスチャを捉えます。トランスクリプト埋め込みは人々が話す内容を表し、会話やナレーションの意味的意味(semantics)を表現します。これら3つの信号を単一の結合埋め込みに圧縮すると、異なるモダリティ(modality)が1つのベクトルに圧縮されます。これでは、視覚、聴覚、音声の境界が曖昧になり、各信号が単独で有用であるための細粒度の詳細(fine-grained detail)が失われます。これらを分離して保持することで、クエリの意図に基づいて各モダリティの重みを正確に調整する制御が可能になり、検索パイプラインが回答を最も含んでいる可能性の高いモダリティに対してマッチングを行うことができます。
ハイブリッド検索のためにメタデータと埋め込みを組み合わせる
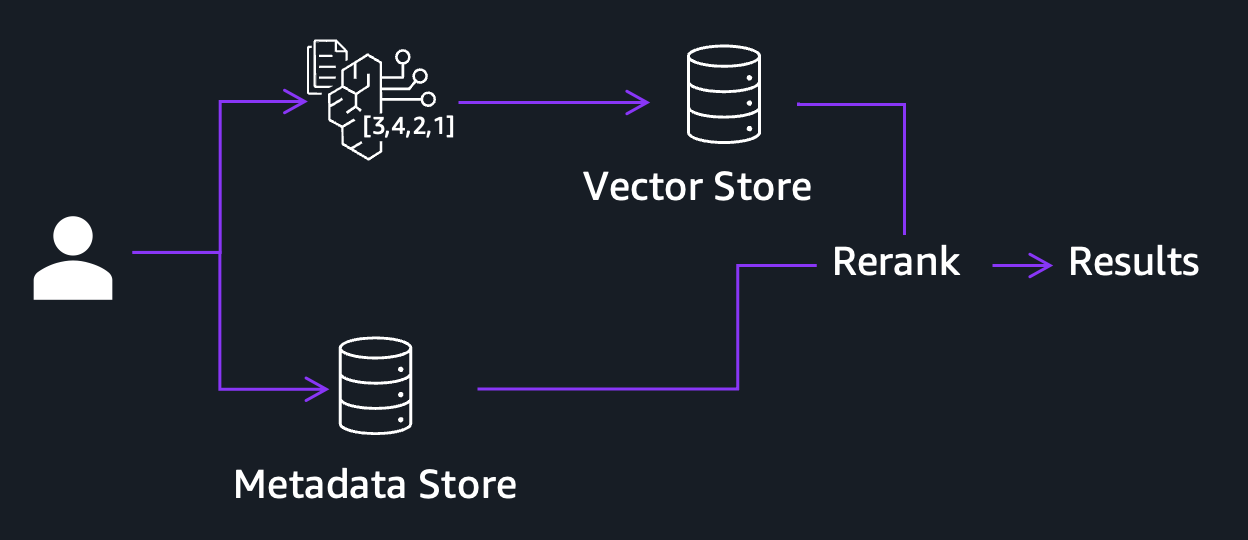
ビジュアル、オーディオ、音声コンテンツをカバーする3つの独立した埋め込み(embeddings)があっても、システムが適切に回答できない種類のクエリはまだ存在します。埋め込みは意味的類似性(semantic similarity)を捉えるように設計されています。「緊迫した群衆の瞬間」や「水面に沈む夕日」のような概念は視覚的・音響的な意味が豊かであるため、埋め込みはそれらの検索に優れています。しかし、ユーザーが特定の人名、製品型番、地理座標(geolocation)、あるいは特定の日付を検索する場合、埋め込みは失敗する可能性が高いです。これらは独自の意味的シグナルがほとんどない離散エンティティ(discrete entities)です。ここでハイブリッド検索(hybrid search)の出番となります。埋め込みのみを頼りにするのではなく、システムは以下の図に示すように2つの並列検索パスを実行します。視覚、オーディオ、トランスクリプト埋め込みに対してマッチングして概念的類似性を捉える「意味的パス(semantic path)」と、構造化メタデータに対して正確なキーワードおよびエンティティマッチングを実行する「語彙的パス(lexical path)」です。
 image
image
図5:意味的検索と語彙的検索を組み合わせたハイブリッド検索パイプライン
必要なメタデータの量はどのくらいでしょうか?その答えはコンテンツの種類、組織の構造、ユースケースによって異なりますが、事前にすべてを収集するのは現実的ではありません。説明のため、メディアおよびエンターテインメントコンテンツにおける一般的なメタデータのタイプを表すために、いくつかのメタデータカテゴリを選択しました。
まず、コンテンツカタログまたはファイルメタデータから直接抽出された技術的メタデータ(technical metadata)を表すために、動画のタイトルと日時を選択しました。次に、Amazon Nova 2 LiteおよびAmazon Rekognitionを使用して生成されたコンテキストメタデータ(contextual metadata)を表すため、セグメントごとのキャプション、ジャンル、有名人の認識を追加しました。キャプションは各セグメントの動画とトランスクリプト(transcript)から生成され、モデルに視覚的および音声的文脈の両方を提供します。ジャンルはすべてのセグメントを通じた完全な動画トランスクリプトから予測され、これはすべての動画クリップを再送信するよりも低コストで信頼性が高いです。有名人の識別はAmazon Rekognitionによって処理され、カスタムトレーニングを必要とせずに画面に登場する著名な公人を認識します。
キャプション生成およびジャンル分類に使用されるプロンプトの例は、以下の通りです。
キャプション生成
この動画クリップを3〜5文で説明してください。以下を含めてください:
- 何が起こっているか、誰が写っているか、動作、設定、環境
- 画面に表示されているすべてのテキスト:タイトル、字幕、看板、ロゴ、透かし、クレジット
- 画面が主に黒または空白の場合は、「Black frame」または「Blank screen」と記載してください
トランスクリプト:{segment_transcript}
記述的なキャプションのみを返してください。それ以外は一切不要です。
ジャンル分類
以下の動画セグメントの説明に基づき、完全な動画を次のリストから正確に1つのジャンルに分類してください:Sports, News, Entertainment,
Documentary, Education, Music, Gaming, Cooking, Travel, Technology,
Business, Lifestyle, Sci-Fi, Mystery, Other
セグメントの説明:
{all_captions}
ジャンル名のみを返してください。それ以外は一切不要です。
この概念は、他のメタデータタイプにも自然に拡張されます。技術的メタデータには解像度やファイルサイズが含まれる場合があり、コンテキストメタデータには場所、雰囲気、ブランドなどが含まれる場合があります。適切なバランスは検索ユースケースによって異なります。さらに、検索時にメタデータフィルターを適用することで、セマンティックマッチング(semantic matching)の前に検索空間を絞り込むことができ、検索のスケーラビリティと精度をさらに向上させることができます。
意図を考慮したクエリルーティングによる検索関連性の最適化(intent-aware query routing)
現在、3つの埋め込み(embeddings)とメタデータがあり、検索可能な次元は4つです。しかし、特定のクエリに対してどの次元を使用すべきかはどうやって判断すればよいでしょうか?重要なのは意図(intent)です。これを解決するため、Haikuモデルを使用して各入力クエリを分析し、視覚、音声、トランスクリプト、メタデータという各モダリティチャネル(modality channel)に重みを割り当てるインテリジェントな意図分析ルーターを構築しました。以下の図に例示された検索クエリをご覧ください。
*「ヴィンテージカーの隣で電話に出るケビン」*
原文を表示
Video semantic search is unlocking new value across industries. The demand for video-first experiences is reshaping how organizations deliver content, and customers expect fast, accurate access to specific moments within video. For example, sports broadcasters need to surface the exact moment a player scored to deliver highlight clips to fans instantly. Studios need to find every scene featuring a specific actor across thousands of hours of archived content to create personalized trailers and promotional content. News organizations need to retrieve footage by mood, location, or event to publish breaking stories faster than competitors. The goal is the same: deliver video content to end users quickly, capture the moment, and monetize the experience.
Video is naturally more complex than other modalities like text or image because it amalgamates multiple unstructured signals: the visual scene unfolding on screen, the ambient audio and sound effects, the spoken dialogue, the temporal information, and the structured metadata describing the asset. A user searching for “a tense car chase with sirens” is asking about a visual event and an audio event at the same time. A user searching for a specific athlete by name may be looking for someone who appears prominently on screen but is never spoken aloud.
The dominant approach today grounds all video signals into text, whether through transcription, manual tagging, or automated captioning, and then applies text embeddings for search. While this works for dialogue-heavy content, converting video to text inevitably loses critical information. Temporal understanding disappears, and transcription errors emerge from visual and audio quality issues. What if you had a model that could process all modalities and directly map them into a single searchable representation without losing detail? Amazon Nova Multimodal Embeddings is a unified embedding model that natively processes text, documents, images, video, and audio into a shared semantic vector space. It delivers leading retrieval accuracy and cost efficiency.
In this post, we show you how to build a video semantic search solution on Amazon Bedrock using Nova Multimodal Embeddings that intelligently understands user intent and retrieves accurate video results across all signal types simultaneously. We also share a reference implementation you can deploy and explore with your own content.
Figure 1: Example screenshot from final search solution
Solution overview
We built our solution on Nova Multimodal Embeddings combined with an intelligent hybrid search architecture that fuses semantic and lexical signals across all video modalities. Lexical search matches exact keywords and phrases, while semantic search understands meaning and context. We will explain our choice of this hybrid approach and its performance benefits in later sections.
Figure 2: End-to-end solution architecture
The architecture consists of two phases: an ingestion pipeline (steps 1-6) that processes video into searchable embeddings, and a search pipeline (steps 7-10) that routes user queries intelligently across those representations and merges results into a ranked list. Here are details for each of the steps:
- Upload – Videos uploaded via browser are stored in Amazon Simple Storage Service (Amazon S3), triggering the Orchestrator AWS Lambda to update Amazon DynamoDB status and start the AWS Step Functions pipeline
- Shot segmentation – AWS Fargate uses FFmpeg scene detection to split video into semantically coherent segments
- Parallel processing – Three concurrent branches process each segment:
Embeddings: Nova Multimodal Embeddings generates 1024-dimensional vectors for visual and audio, stored in Amazon S3 Vectors
- Transcription: Amazon Transcribe converts speech to text, aligned to segments. Amazon Nova Multimodal Embeddings generates text embeddings stored in Amazon S3 Vectors
- Celebrity detection: Amazon Rekognition identifies known individuals, mapped to segments by timestamp
- Caption & genre generation – Amazon Nova 2 Lite synthesizes segment-level captions and genre labels from visual content and transcripts
- Merge – AWS Lambda assembles all metadata (captions, transcripts, celebrities, genre) and retrieves embeddings from Amazon S3 Vectors
- Index – Complete segment documents with metadata and vectors that are bulk-indexed into Amazon OpenSearch Service
- Authentication – Users authenticate via Amazon Cognito and access the front end through Amazon CloudFront
- Query processing – Amazon API Gateway routes requests to Search Lambda, which executes two parallel operations: intent analysis and query embedding
- Intent analysis – Amazon Bedrock (using Anthropic Claude Haiku) assigns relevance weights (0.0-1.0) across visual, audio, transcription, and metadata modalities
- Query embedding – Nova Multimodal Embeddings embeds the query three times for visual, audio, and transcription similarity search
This flexible architecture addresses four key design decisions that most video search systems overlook: maintaining temporal context, handling multimodal queries, scaling across massive content libraries, and optimizing retrieval accuracy. A complete reference implementation is available on GitHub, and we encourage you to follow along with the following walkthrough to see how each decision contributes to accurate, scalable search across all signal types.
Segmentation for context continuity
Before generating any embeddings, you need to divide your video into searchable units, and the boundaries you draw have a direct impact on search accuracy. Each segment becomes the atomic unit of retrieval. If a segment is too short, it loses the surrounding context that gives a moment its meaning. If it is too long, it fuses multiple topics or scenes together, diluting relevance and making it harder for the search system to surface the right moment. For simplicity, you can start with fixed-length chunks. Nova Multimodal Embeddings supports up to 30 seconds per embedding, giving you flexibility to capture complete scenes. However, be aware that fixed boundaries may arbitrarily truncate a scene mid-action or split a sentence mid-thought, disrupting the semantic meaning that makes a moment retrievable, as shown in the following figure.
Figure 3: Video segmentation strategies
The goal is semantic continuity: each segment should represent a coherent unit of meaning rather than an arbitrary slice of time. Fixed 10-second blocks are straightforward to produce, but they ignore the natural structure of the content. A scene change mid-segment splits a visual idea across two chunks, degrading both retrieval precision and embedding quality.
To solve this, we use FFmpeg‘s scene detection to identify where the visual content actually changes. FFmpeg is an open source multimedia framework widely used for video processing, format conversion, and analysis. The _detect_scenes function that follows runs ffprobe (FFmpeg’s associated tool for media inspection) against the video and returns a list of timestamps, each marking a scene boundary:
def _detect_scenes(video_path):
result = subprocess.run(
['ffprobe', '-v', 'quiet', '-show_entries', 'frame=pts_time', '-of', 'csv=p=0',
'-f', 'lavfi', f"movie={video_path},select='gt(scene\\,{SCENE_THRESHOLD})'"],
capture_output=True, text=True
)The output is a simple list of timestamps like 12.345, 28.901, 45.678, each marking a natural boundary where the scene shifts.
With those boundaries in hand, the segmentation algorithm snaps each cut to the nearest scene change within an acceptable window, targeting around 10 seconds with a minimum of 5 seconds and a maximum of 15 seconds from the current start. If no scene changes fall in that range, it falls back to a hard cut at the target duration. The result is a set of segments that feel natural: 8.3s, 11.1s, 9.8s, 12.4s, 7.6s, each aligned to a real scene boundary rather than a fixed ticker.
This simple shot-based segmentation makes sure segment boundaries align with natural visual transitions rather than cutting arbitrarily. The target segment duration should be calibrated based on your content type and use case: action-heavy content with frequent cuts may benefit from visual segmentation like this, while documentary or interview content with longer takes may work better with longer, topic-based segmentation. For more advanced segmentation techniques, including audio-based topic segmentation and combined visual and audio approaches, we recommend reading Media2Cloud on AWS Guidance: Scene and Ad-Break Detection and Contextual Understanding for Advertising Using Generative AI.
Generate separate embeddings for visual, audio, and transcript signals
With segments defined, the choice of embedding model is where the largest quality gap opens between approaches. The dominant approach today grounds all video signals into text before generating embeddings, but as we established earlier, video carries far more meaning than any transcript or caption can express. Visual action, ambient sound, on-screen text, and entity context are either lost entirely or approximated through imprecise descriptions.
Nova Multimodal Embeddings changes this fundamentally because it is a video-native model that can generate embeddings in two modes. The combined mode fuses visual and audio signals into a unified representation, capturing the most important signals together. This approach benefits storage cost and retrieval latency by requiring only a single embedding per segment. Alternatively, the AUDIO_VIDEO_SEPARATE mode generates distinct visual and audio embeddings. This approach provides maximum representation in modality-specific embeddings and gives you better control over when to search visual content versus audio content.
In our implementation, we even added a third speech embedding derived from Amazon Transcribe. This embedding is created from aligning complete sentence transcripts to the embedding segment timestamps, before and after, preserving the semantic integrity of spoken language and ensuring that a complete thought is never split across two embeddings.
Figure 4: Visual, audio, and speech embedding generation per video segment
Together, these three embeddings cover the full signal space of a video segment. The visual embedding captures what the camera sees: objects, scenes, actions, colors, and spatial composition. The audio embedding captures what the microphone hears: music, sound effects, ambient noise, and the acoustic texture of a scene. The transcript embedding captures what people say, representing the semantic meaning of spoken dialogue and narration. Collapsing all three signals into a single combined embedding compresses distinct modalities into one vector. This blurs the boundaries between what is seen, heard, and spoken, and loses the fine-grained detail that makes each signal useful on its own. Keeping them separate gives you precise control to dial each modality up or down based on query intent, allowing the search pipeline to match against the modality most likely to contain the answer.
Combine metadata and embeddings for hybrid search
Even with three independent embeddings covering visual, audio, and spoken content, there is still a class of queries the system cannot answer well. Embeddings are designed to capture semantic similarity. They excel at finding a “tense crowd moment” or a “sun setting over water” because those are concepts with rich visual and audio meaning. But when a user searches for a specific name, product model number, geolocation, or a particular date, embeddings will likely fail. These are discrete entities with little semantic signals on their own. This is where hybrid search comes in. Rather than relying on embeddings alone, the system runs two parallel retrieval paths as shown in the following figure: a semantic path that matches against your visual, audio, and transcript embeddings to capture conceptual similarity, and a lexical path that performs exact keyword and entity matching against structured metadata.
Figure 5: Hybrid search pipeline combining semantic and lexical retrieval
How much metadata do you need? The answer depends on your content type, organization, and use case, and capturing everything upfront is impractical. For illustration purposes, we selected a few categories of metadata to represent common types of metadata in media and entertainment content.
First, we selected video title and datetime to represent technical metadata extracted directly from the content catalog or file metadata. Then we added segment captions, genre, and celebrity recognition to represent contextual metadata, generated using Amazon Nova 2 Lite and Amazon Rekognition. Captions are generated from the video and transcript of each segment, giving the model both visual and spoken context. Genre is predicted from the full video transcript across all segments, which is cheaper and more reliable than re-sending all video clips. Celebrity identification is handled by Amazon Rekognition, which recognizes known public figures appearing on screen without requiring custom training.
Example prompts used for caption generation and genre classification are shown in the following examples:
# Caption generation
Describe this video clip in 3-5 sentences. Include:
- What is happening, who is visible, actions, setting, and environment
- Any text on screen: titles, subtitles, signs, logos, watermarks, or credits
- If the screen is mostly black or blank, state "Black frame" or "Blank screen"
Transcription: {segment_transcript}
Return ONLY the descriptive caption, nothing else.
# Genre classification
Based on all the video segments described below, classify the overall video
into exactly ONE genre from this list: Sports, News, Entertainment,
Documentary, Education, Music, Gaming, Cooking, Travel, Technology,
Business, Lifestyle, Sci-Fi, Mystery, Other
Segment descriptions:
{all_captions}
Return ONLY the genre name, nothing else.The concept extends naturally to other metadata types. Technical metadata may include resolution or file size, while contextual metadata might include location, mood, or brand. The right balance depends on your search use case. Additionally, overlaying metadata filters during retrieval can further enhance search scalability and accuracy by narrowing the search space before semantic matching.
Optimize search relevance with intent-aware query routing
Now you have three embeddings and metadata, four searchable dimensions. But how do you know when to use which for a given query? Intent is everything. To solve this, we built an intelligent intent analysis router that uses the Haiku model to analyze each incoming query and assign weight to each modality channel: visual, audio, transcript, and metadata. See the example search query in the following figure.
*“Kevin taking a phone call next to a vintage car”*
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み