LLM サービングにおける CPU と GPU の分離の必要性:SMG の事例
Shepherd Model Gateway (SMG) は、LLM サービングにおける CPU と GPU の役割を分離・集約するアーキテクチャを採用し、大規模展開時のトラフィック分散とリソース効率を劇的に向上させるゲートウェイです。
キーポイント
CPU/GPU 非集約アーキテクチャの採用
LLM サービングにおいて、リクエスト処理やルーティングなどの制御層(CPU)と推論実行層(GPU)を物理的・論理的に分離する設計を採用し、ボトルネック解消を図っています。
多様なバックエンドとの統合対応
SGLang, vLLM, TRT-LLM などの推論エンジンおよび OpenAI, Anthropic, Gemini 等の API を統一的に管理し、柔軟なトラフィック分散を可能にしています。
エンタープライズ向け機能の強化
履歴保存、MCP ツール連携、プライバシー重視ワークフローなど、大規模導入に必要なガバナンス機能をゲートウェイレベルで提供します。
影響分析・編集コメントを表示
影響分析
このアーキテクチャは、LLM の大規模実装において頻発するリソース競合やスケーラビリティの課題に対し、システム設計の根本的な見直しを促す重要な示唆を与えます。特に、制御層と推論層を分離することで、コスト効率の高いインフラ構築が可能となり、企業における LLM 導入のハードルを下げると期待されます。
編集コメント
LLM の実運用において、単なる推論エンジンの性能向上だけでなく、それを制御するゲートウェイ層の設計思想がコストとパフォーマンスに直結することが再認識される記事です。
How It Started: Hitting the GIL Wall at Scale
始まり:スケールにおける GIL の壁にぶつかる
私たちは長年にわたり、本番環境でのモデル推論サービスを提供してきました。Shepherd Model Gateway の構築を始めた当初の目標は控えめなものでした:キャッシュを意識したロードバランシングが、推論レプリカ間のルーティング改善に寄与するかどうかを検証することです。
それは可能でした。そして、さらに深く掘り下げていくと、はるかに大きな問題が発見されました。
SGLang と vLLM の両方で、トークン化(tokenization)と逆変換(detokenization)がボトルネックとなっていました。理論上の話ではなく、実際のトラフィックがかかる本番環境においてです。その根本原因はアーキテクチャにあります:両方のエンジンとも内部で Rust や C++ のトークナイザーライブラリを使用していますが、呼び出しは Python を経由します。つまり、GIL(Global Interpreter Lock)が存在するということです。つまり、サービスパスの直上に位置する CPU 集約型処理に対して、スレッド単位の天井(制限)が生じるということです。
小規模なスケールでは、これは問題になりません。しかし、大規模な prefill-decode 分離型推論や、GPU クラスター全体にわたる大規模なエキスパート並列化においては、それは極めて重大な問題となります。これらの構成により GPU は非常に高速になりますが、その速度は CPU パイプライン側が制約要因となるほどです。GIL に縛られたトークン化におけるマイクロ秒の遅延は、数十万ドル相当の GPU が入力待ちでアイドル状態になる時間を意味します。
これが、本当の旅の始まりでした。ゲートウェイのビジョンから始まったのではなく、本番環境の問題から始まりました。CPU 負荷全体を GPU パスから分離し、Rust で実行することは可能でしょうか?Python から Rust を呼び出すような形ではなく、純粋な Rust です。GIL はなく、スレッド単位の天井もありません。Python プロセスの境界線も存在しません。
答えはイエスであり、それを証明したプロジェクトが Shepherd Model Gateway です。
*SMG アーキテクチャ:クライアント → ゲートウェイ → ルーター → ワーカー*
SMG のアーキテクチャは一つの原則に基づいています:GPU はテンソル計算のみを行い、それ以外のすべては専用のサービング層に属するというものです。
モデルサービングスタックを精査し、GPU 推論と絡み合った CPU バウンド型のワークロードをすべて特定しました。これには、トークン化、デトークン化、推論出力の解析、関数呼び出しの抽出、MCP ツールのオーケストレーション、マルチモーダル前処理、チャット履歴管理、構造化出力の検証、ストップシーケンス検出が含まれます。それぞれが CPU タスクであり、これらが Python の GIL(グローバルインタプリタロック)に縛られた GPU プロセスと共配置されることで、ラック内で最も高価なハードウェアに対してバックプレッシャーを発生させてしまいます。
SMG はこれらの処理をすべて gRPC を介して推論エンジンと通信する Rust 製のゲートウェイ層へ移管します。このプロトコルは最小限で GPU に特化しており、前処理済みのトークンを入力として送り、生成されたトークンをストリーミング出力するというものです。それ以外のすべての責任はゲートウェイが負います。
これは、分散推論分野のほとんどのプロジェクトが採用しているアプローチではありません。NVIDIA Dynamo や llm-d といったプロジェクトでは、推論エンジン層とその周囲のオーケストレーションを最適化することに注力しており、素晴らしい成果が出ています。私たちはこれらの取り組みを補完的なものとして捉えています。しかし、SMG の賭けは異なります:エンジンを賢くするのではなく、ゲートウェイを賢くすることです。GPU を必要としない処理はすべて、独立してスケールし、独立して進化し、ゼロ GIL 競合で動作する専用ビルトの Rust レイヤーへオフロードします。
gRPC の再アーキテクチャ:実現に向けて
*gRPC パイプライン:エンジンへの引き渡し前のゲートウェイ側処理
SMG の歴史において、最大の技術的投資は、ネイティブな Rust gRPC データプレーンを中心に全体のサービングパイプラインを再構築したことです。これが、 disaggregation(デアグリゲーション)仮説のアーキテクチャ的な証明となりました。
トークン化と逆トークン化がゲートウェイへ移行します。 SMG は、2 段階のキャッシュを持つネイティブな Rust でトークナイザーを実行しています。L0 は重複するプロンプトに対する完全一致キャッシュ、L1 は特殊トークンの境界におけるプレフィックス認識型です。推論エンジンには事前トークン化された入力が渡され、一度もトークナイザーに触れることはありません。Python もありません。GIL(グローバルインタプリタロック)の競合もありません。
推論とツール呼び出しのパース処理は、ゲートウェイのストリーミングパイプラインで実行されます。 gRPC を経由してトークンが到着するにつれ、SMG のパーサー(Cohere Command、DeepSeek、Llama、Nemotron、Kimi-K2、GLM-4、Qwen Coder などを含む)が、リアルタイムで推論ブロック、関数呼び出し、構造化出力を抽出します。エンジン側での後処理ステップは不要です。
マルチモーダル処理は最も野心的な取り組みでした。Hugging Face の transformers イメージプロセッサの主要コンポーネントを Python から Rust へ書き換え、ビジョン前処理パイプライン、テンソル演算、モデル固有の変換を全く異なる言語とランタイムで再実装しました。その結果、SMG は gRPC を介して事前処理されたテンソルをゼロの Python オーバーヘッドでエンジンに直接通信します。Llama 4 Vision、Qwen VL、および主要なビジョン・ランゲージモデルへのサポートに加え、SGLang、vLLM、TensorRT-LLM 向けにバックエンド固有の最適化を提供しています。これは、私どもの知る限り業界初の試みです。
MCP ツールオーケストレーションは、認証対応接続プーリング、並行バッチ実行、承認ワークフロー、自動再接続、HTTP ヘッダー転送をすべてゲートウェイ内で完結して実行されます。推論エンジンは MCP の存在自体を認識しません。また、完全な組み込みツールルーティングインフラストラクチャも構築しました。これにより、任意の MCP サーバーを、あらゆるモデル向けのネイティブ機能(FileSearch、WebSearch、CodeInterpreter)へと変換します。GPT-4 と同じ組み込みツールを備えた Llama や Qwen をデプロイ可能です。
チャット履歴管理では、プラグイン可能なストレージ(PostgreSQL、OracleDB、Redis、およびインメモリ)をサポートし、Flyway によるスキーマバージョン管理、カスタマイズ可能なテーブル/カラム名、前処理・後処理の永続化コールバック用のストレージフックを提供します。これらすべてをゲートウェイ内で完結させ、エンジンはステートレスに保ちます。
WASM ミドルウェアは、コードベースをフォークすることなく、プログラム可能な拡張性を提供します。カスタム認証、コンプライアンスログの記録、PII の赤塗り処理、コスト追跡、圧縮など、すべてがサンドボックス化された分離環境を持つ WebAssembly プラグインを通じて実現されます。これもまた業界初の取り組みです。
gRPC プロトコル自体は PyPI で smg-grpc-proto として公開されており、ゲートウェイとエンジン間の狭い契約を定義しています。この設計により、ゲートウェイ(新しいパーサー、新しいプロトコル、新しいツール)をアップグレードする際に推論エンジンを触る必要がなく、逆に推論エンジン(新しい GPU カーネル、新しい量子化手法)をアップグレードする際にもゲートウェイを触る必要がありません。インターフェースが明確であるため、両者は独立して進化します。
SMG が今日提供するもの
SMG は、LightSeek Foundation のメンバーである Simo Lin と Chang Su によって作成されました。約 6 か月の間に 13 リリースを完了しました。一つひとつのリリースを追跡するのではなく、プロジェクトが現在提供している機能と、それぞれの能力を支える根拠をご紹介します。
マルチモデル推論ゲートウェイ
単一の SMG プロセスが、複数のモデル、複数のエンジンを持つファーム全体をフロントエンドとして支えます。SGLang、vLLM、TensorRT-LLM、MLX バックエンドへのリクエストを同時にルーティングできます。OpenAI、Anthropic、Google Gemini、AWS Bedrock、Azure OpenAI を外部プロバイダーとして追加することも可能です。一つのゲートウェイで、あらゆるエンジンとベンダーに対応します。
5 つのネイティブ・エージェント API
SMG はネイティブで Chat Completions (OpenAI)、Responses API (OpenAI)、Messages API (Anthropic)、Interactions API (Gemini)、および Realtime API (WebSocket/WebRTC) をサポートしています。これらは単なる翻訳レイヤーではなく、それぞれがファーストクラスの実装です。Messages API は ThinkingConfig、thinking_delta ストリーミングイベント、そして推論・テキスト・ツール使用のコンテンツブロックをインターリーブした形で、思考ブロックをエンドツーエンドで維持します。Responses API は OpenAI の会話管理機能を Llama、DeepSeek、Qwen、およびすべてのオープンソースモデルに持ち込みます — SMG はこれをサポートする唯一のオープンソースゲートウェイです。Claude 向けに設計されたエージェントワークフローを、Llama 4、Qwen 3、DeepSeek、または Kimi でフルプロトコルの忠実度をもって実行できます。
ネイティブ Rust gRPC データプレーン
*2 レベルトークナイザーキャッシュ:L0 完全一致、L1 プレフィックス対応*
アーキテクチャの中核は、ゲートウェイとエンジン間のネイティブ Rust gRPC パイプラインです。契約は最小限 — 前処理されたトークンが入力され、生成されたトークンが出力されます。それ以外はすべてゲートウェイの責任です。トークナイゼーションは Rust で実行され、2 レベルキャッシュ(L0 完全一致、L1 プレフィックス対応)を使用します。推論とツール呼び出しのパースは、トークン到着時にストリーミングパイプライン内で実行され — DeepSeek-R1、Qwen3、GLM-4、Kimi、Llama-4、Cohere Command など 15 のモデルファミリーをサポートしています。Python は不要です。GIL(グローバルインタープリタロック)も不要です。gRPC プロトコルは PyPI で smg-grpc-proto として公開されており、vLLM (PR #36169) および NVIDIA TensorRT-LLM(マージされた PR が 5 つ)が既に上流で採用しています。
インテリジェントルーティング
*キャッシュ対応ルーティングフロー*
8 つの負荷分散ポリシー:キャッシュ対応、ラウンドロビン、ランダム、2 乗の法則(power-of-two)、一貫性ハッシュ、プレフィックスハッシュ、手動(スティッキーセッション)、バケットベース。キャッシュ対応ルーティングはゼロから書き直され、10〜12 倍高速化(1 秒あたり 216,000 件の挿入処理)、メモリ使用量が 99% 削減(ノードあたり 180 KB → 1.4 KB、10,000 件のキャッシュ済みプレフィックスで 1.8 GB → 14 MB)。イベント駆動型の KV キャッシュルーティングは、SubscribeKvEvents RPC を経由して全バックエンドからリアルタイムのキャッシュ状態をストリーミングし、自動学習されたブロックサイズを採用。8 つの Llama レプリカでの本番環境結果では、TTFT(Time To First Token)の平均が 23% 低下、p99 が 28% 低下。プレフィル・デコード分離(disaggregation)は、プレフィルフェーズとデコードフェーズを独立したポリシーを持つ別々のワーカープールにルーティングし、PD 構成において TTFT を 20〜30% 改善。
Rust によるマルチモーダル処理
Hugging Face の画像プロセッサの主要コンポーネントを Python から Rust に書き換え — ビジョン前処理パイプライン、テンソル演算、モデル固有の変換を、全く異なる言語とランタイムで実装。8 つのビジョンモデルファミリーをサポート:Kimi K2.5、Llama-4 Vision、LLaVA、Phi-3/Phi-4 Vision、Pixtral、Qwen-VL、Qwen2-VL、Qwen3-VL。前処理されたテンソルは、gRPC を経由して Python オーバーヘッドゼロで直接エンジンへフローします。業界初と確認されています。
MCP ツールオーケストレーション & 組み込みツール
*MCP アーキテクチャ:ゲートウェイにおけるツールオーケストレーション*
MCP は、認証対応の接続プーリング、並行バッチ実行、承認ワークフロー、自動再接続、および 4 つのトランスポート(STDIO, HTTP, SSE, Streamable)をすべてゲートウェイ内で完結して実行します。ユニバーサル MCP ビルトインツールは、任意の MCP サーバーを FileSearch、WebSearch、CodeInterpreter といったネイティブ機能に変換し、あらゆるモデルで利用可能にします。GPT-4 と同じビルトインツールを用いて Llama や Qwen をデプロイできます。テナントごとの分離、ポリシーベースの信頼レベル、実行メトリクスは標準装備です。
WASM ミドルウェア
*WASM プラグパイプライン*
サンドボックス化された隔離を備えた WebAssembly プラグインによるプログラム可能な拡張性 — 業界初の取り組みです。カスタム認証、コンプライアンスログ記録、PII(個人識別情報)の赤塗り処理、コスト追跡、圧縮など、コードベースをフォークすることなくすべて実現できます。Wasmtime を基盤とし、Component Model と非同期サポートを搭載しています。ストレージフックはチャット履歴操作をインターセプトし、カスタムの前処理・後処理を可能にします。
エンタープライズセキュリティと観測性
*TLS/mTLS アーキテクチャ*
JWT/OIDC 認証(JWKS ディスカバリ付き)、ロールベースアクセス制御、API キー認証、マルチテナントレート制限を提供します。クライアント向けおよびノード間通信の両方に TLS と mTLS を採用しています。HTTP、ルーター、ワーカー、推論、ディスカバリー、MCP、データベース、メッシュ層を網羅する 40 以上の Prometheus メトリクスを持つ 6 レイヤーのメトリクスシステムと、フルオープンな OpenTelemetry による分散トレーシング、リクエスト相関付け付き構造化 JSON ログを標準で提供します。
信頼性と高可用性
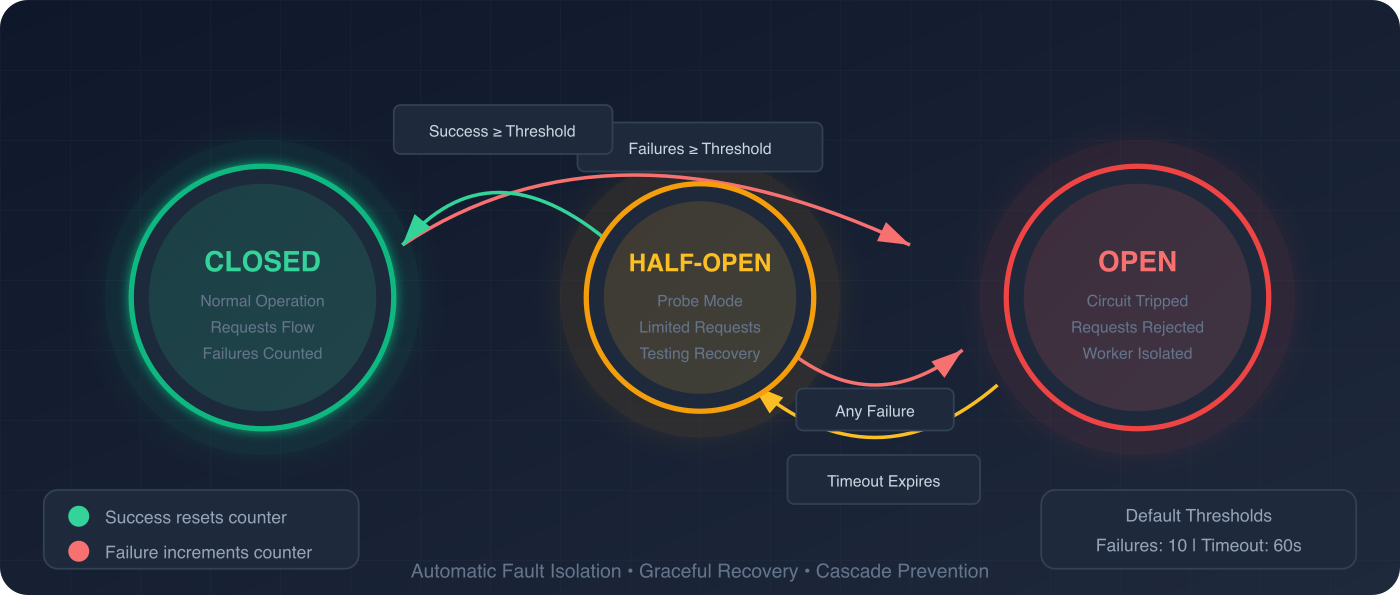
*サーキットブレーカ状態マシン*
ワーカーごとのサーキットブレーカー(クローズド/オープン/ハーフオープン)、指数バックオフとジッターを伴う自動リトライ、定期的なヘルスチェック、並行リクエストレート制限、リクエストタイムアウト、設定可能なグレースフルシャットダウン。SWIM プロトコルによるゴシップメッシュと CRDT ベースの状態同期により、マルチノード展開をサポート。クラスタノード全体にわたる一貫性ハッシングによる分散レート制限。設計上パーティション耐性を備えています。
データ永続化とサービスディスカバリー
*サービスディスカバリー:Kubernetes, DNS, 手動*
プラグイン式ストレージを備えたチャット履歴管理 — PostgreSQL、OracleDB、Redis、またはメモリ内ストレージを選択可能。スキーマバージョン管理とカスタマイズ可能なテーブル/列名に対応。Kubernetes ラベルベースのポッドディスカバリー、DNS ディスカバリー、または手動でのワーカー URL 指定が可能。モデル ID はポッド名前空間、ラベル、または注釈から取得します。PD 設定における自動プリフェッチポート発見のためのブートストラップポート注釈。
ユニバーサルプラットフォームサポート
Linux、Windows、macOS、x86、ARM — 単一の Python ウィール(pip install smg)から対応。Python 3.8〜3.14 対応。Python、Rust、Java、Go 向けの生産環境用クライアント SDK を提供。エンジン固有の Docker イメージも用意。smg-auth、smg-mesh、smg-mcp、smg-wasm、smg-grpc-client、smg-kv-index、llm-tokenizer、llm-multimodal、openai-protocol など、スタンドアローンクレートへの完全なモジュール化を実現。
仮説の実証:gRPC ゲートウェイベンチマーク
分散化の仮説は、CPU ワークロードを GPU パスから外すことで測定可能なメリットが得られることを予測しています — 特に生産環境条件下において。私たちはこれを体系的に検証しました。
方法論
すべてのベンチマークは、GitHub Actions 上の SMG 夜間ベンチマークスイートを通じて NVIDIA GenAI-Perf (genai-perf) を使用し、NVIDIA H100 GPU で実行されました。対象モデルは 8 つ(GPT-OSS-20B, Llama-3.1-8B, Llama-3.3-70B, Llama-3.3-70B-FP8, Llama-4-Maverick, Llama-4-Scout, Qwen2.5-7B, Qwen3-30B-MoE)、ランタイムは 2 つ(SGLang, vLLM)、トラフィックシナリオは 5 つ、並行度は 9 レベル(1〜256)です。合計で gRPC と HTTP の比較ポイントは 1,082 箇所あります。
スケーリングの物語:並行度が高まるほど優位性が増す
並行度が 1 の場合、gRPC と HTTP はノイズの範囲内で同等のパフォーマンスを発揮します。しかし、並行度が 256 に達すると、gRPC は約 8% 高いスループットを提供します。ゲートウェイのバイナリシリアライゼーションと HTTP/2 のマルチプレクシングは負荷がかかるほどその影響を強め、まさに重要な局面で差が生じます。
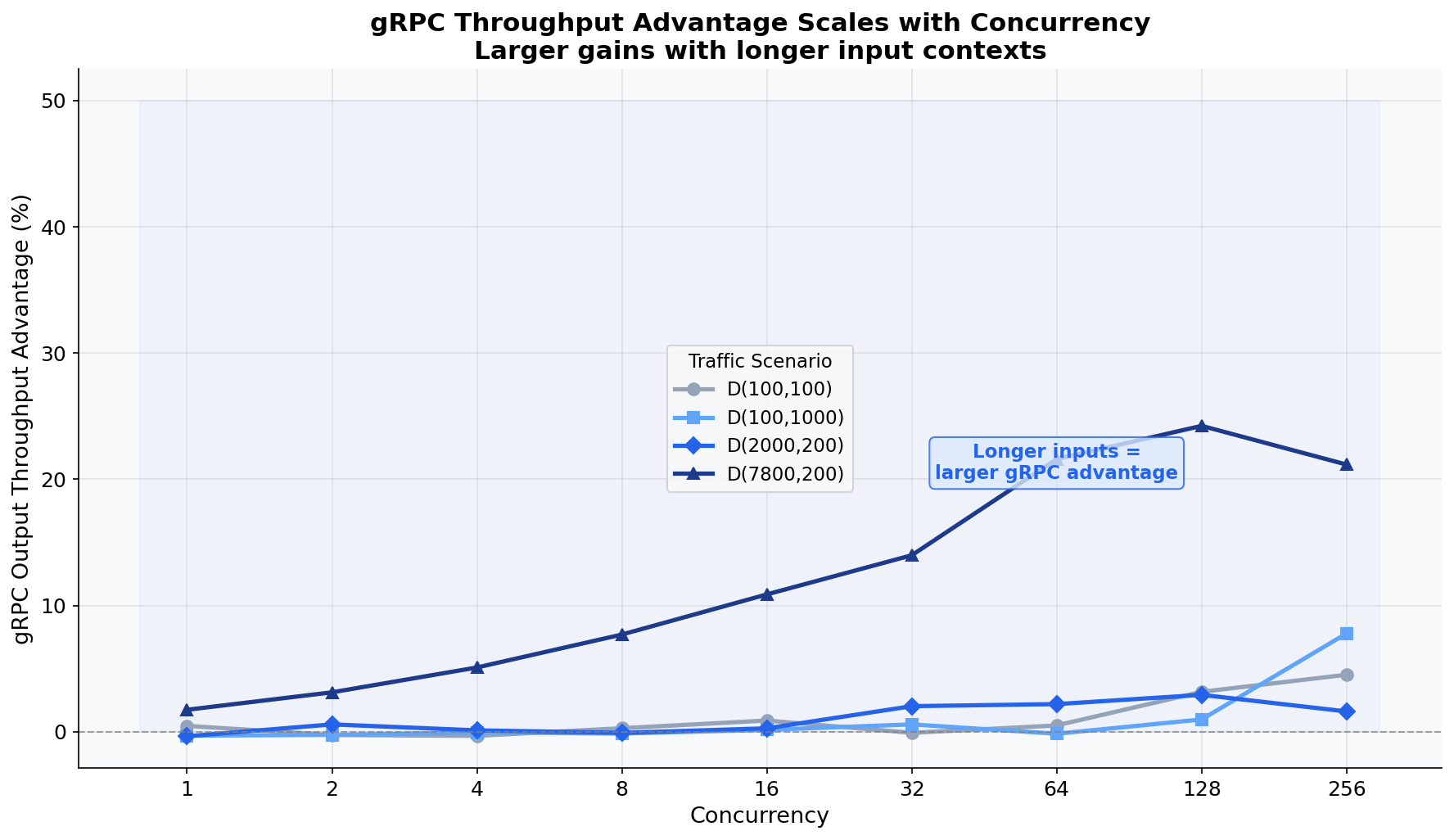
長いコンテキスト:gRPC がパフォーマンスを変革する領域
HTTP/JSON のシリアライゼーションコストはプロンプトの長さに比例して線形に増加します。一方、gRPC/protobuf はコンパクトなバイナリエンコーディングを使用するため、このコストを払う必要がありません。入力トークン数が 7800 に達すると、シリアライゼーションコストは非常に大きくなります。D(7800,200) シナリオでは、すべてのモデルでスループットが +12.2% 向上するという結果が示されました。
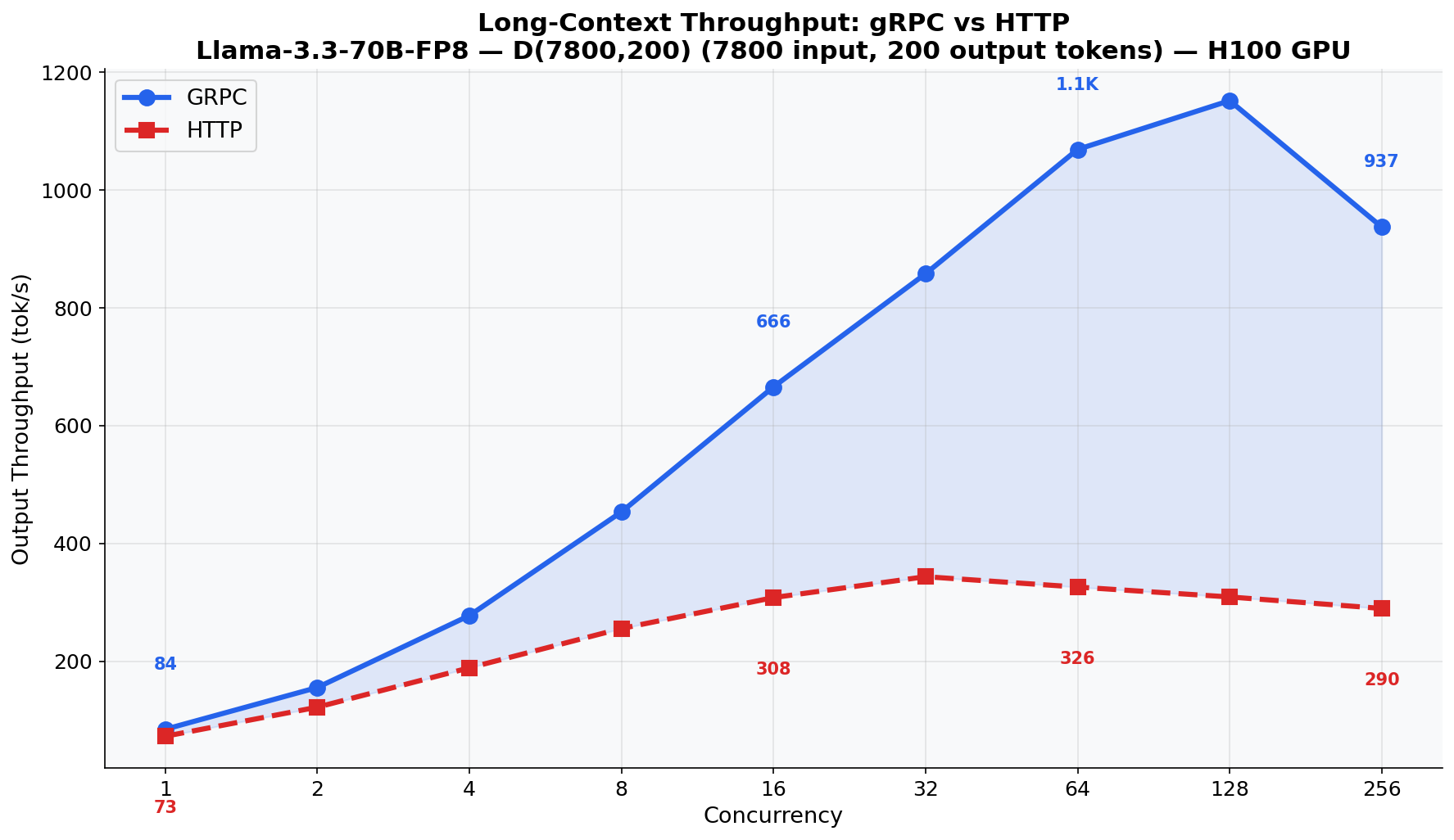
最も劇的な結果は、7800 トークンの入力を持つ Llama-3.3-70B-FP8 です。H100 で FP8 量子化を実行しているこのモデルは非常に高速であるため、HTTP のシリアライゼーションが主要なボトルネックとなっています。gRPC を使用すると、出力スループットは最大で 3.5 倍向上し、1,150 トークン/秒対 327 トークン/秒という差が生じます。
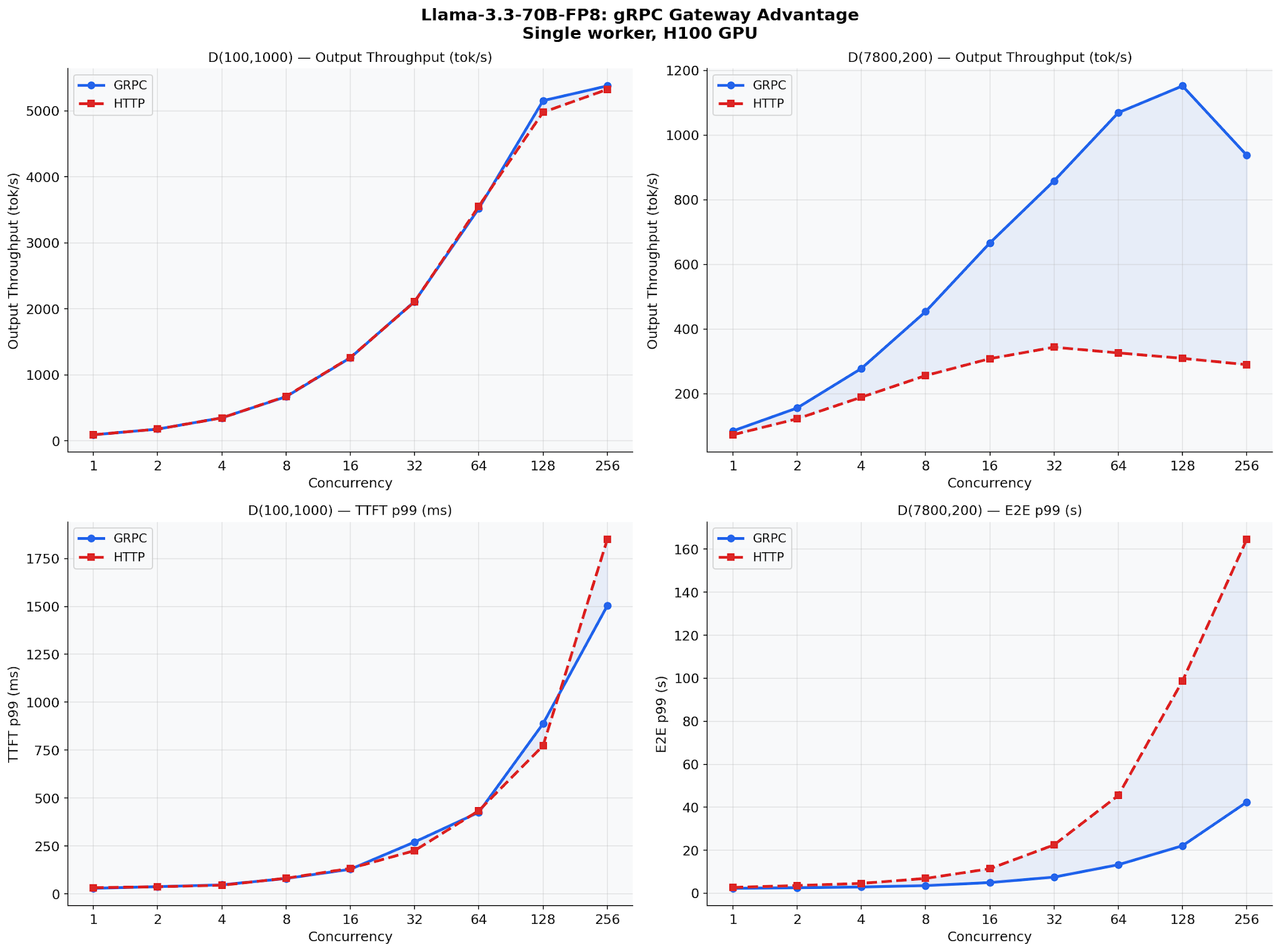
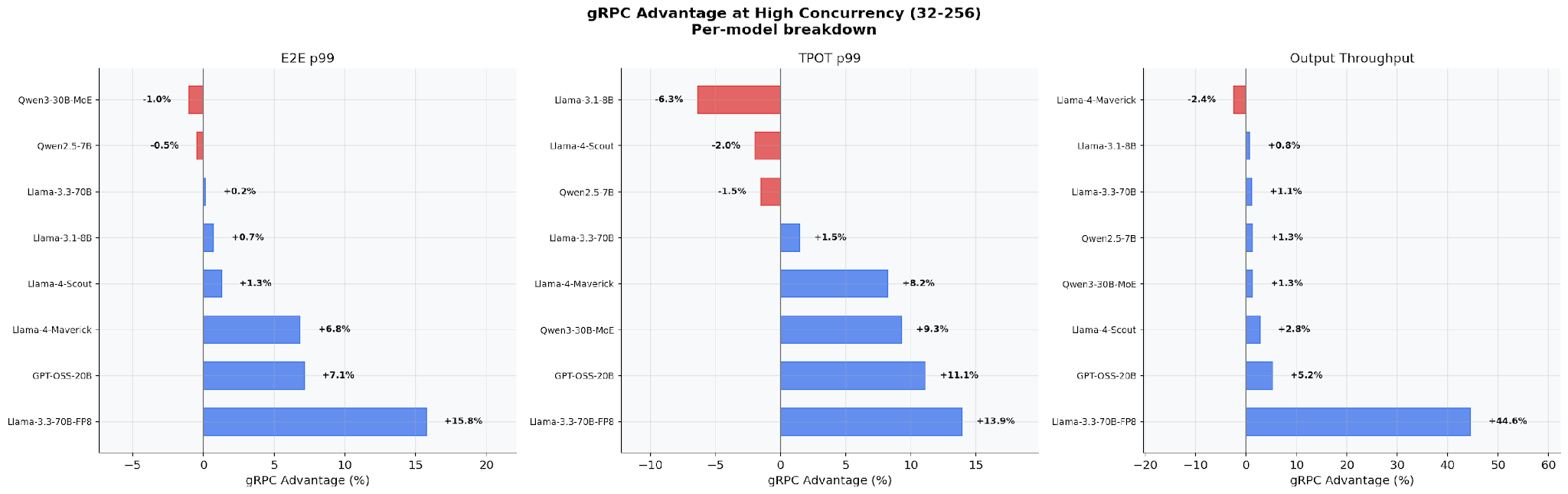
高同時実行時のモデル別内訳
本番環境の同時実行レベル(32〜256)において、gRPC の優位性はモデルアーキテクチャによって異なります。Llama-3.3-70B-FP8 では最大の改善が見られ(エンドツーエンド p99 で +15.8%、出力スループットで +44.6%)、より小さな密結合モデル(Llama-3.1-8B、Qwen2.5-7B)では modest な改善にとどまります。パターンは明確です:GPU が高速になるほど gRPC の優位性は大きくなります。これは、CPU オーバーヘッドが全体のレイテンシに占める割合が大きくなるためです。
現状の状況
LLM インフラストラクチャに取り組んでいるのは私たちだけではありません。
NVIDIA Dynamo は、深いハードウェア統合と最適化された推論オーケストレーションを提供します。llm-d は、Kubernetes ネイティブのアプローチを用いて分散推論スケジューリングに取り組んでいます。両者とも、エンジン層およびクラスター層において重要な役割を果たしています。
SMG は異なる境界で動作します:サービング層とプロトコル層です。私たちはクライアントから GPU までのすべてを担っています——トークン化、エージェント型プロトコル変換、ツールオーケストレーション、キャッシュ認識ルーティング、マルチモーダル前処理、信頼性確保など。1 つのレイヤーに限定され、外部依存関係はゼロ、純粋な Rust で実装されています。
重要な洞察:これらのアプローチは相互に組み合わせ可能です。llm-d が管理する vLLM の前方に SMG を配置したり、Dynamo が GPU オーケストレーションを担当する TensorRT-LLM の前方に SMG を配置したりできます。境界が明確なのは、各担当領域が異なるためです。
本番環境での採用
SMG は以下の場所で本番デプロイメントを支えています:
- Google Cloud Platform — マルチテナント AI インフラストラクチャ
- Oracle Cloud Infrastructure — エンタープライズ向け生成 AI サービス
- Alibaba Cloud — クラウドネイティブな AI ワークロード
- TogetherAI — 分散推論インフラストラクチャ
スタートアップからハイパースケイラーまで。
次のステップ
- バッチ API スケジューリング — オフラインワークロード向けに、ジョブスケジューラとキャパシティガバナーによる 2 層アーキテクチャ。
- セマンティックルーティング — 静的ルールではなく、コンテンツに基づいて軽量な分類ベースのディスパッチを異なるバックエンドへ実行。
- ベンダーミックス (MoV) — 同じモデルを複数のプロバイダにルーティングし、A/B テスト、コスト最適化、品質比較を実現。
- MCP セマンティック検索 — 数百件の登録ツールを持つサーバー間で効率的なツール発見を行う機能。
- カスタムメトリクスロードバランシング — 任意のメトリクスに対する CEL (Common Expression Language) 式を用いた、サブミリ秒単位のルーティングオーバーヘッドでの負荷分散。
GitHub: github.com/lightseekorg/smg
インストール: pip install smg –upgrade
ドキュメント: lightseekorg.github.io/smg
謝辞
SMG の開発は、業界全体にわたるエンジニアリングチームやオープンソースコミュニティとの緊密な協力によって形作られてきました。以下の皆様の貢献、フィードバック、そしてパートナーシップに感謝いたします。
- Oracle Generative AI Service — Jun Qian, Jingqiao Zhang, Wei Gao, Keyang Ru, Xinyue Zhang, Yifeng Liu, Ziwen Zhao, Daisy Zhou, Khoa Tran.
- TogetherAI — Yineng Zhang, Wei Gong, Chandra Mourya, Connor Li.
- Thinking Machines Lab — Eric Zhang, Rajat Goel, Jeff Hanson.
また、SGLang、vLLM、TensorRT-LLM のコミュニティの皆様には、アップストリームでの協力とプロトコルの採用に対し、radixArk および Inferact の各チームにはパートナーシップとフィードバックに対して感謝申し上げます。
彼らの本番環境での展開、コードへの貢献、そして技術的な洞察が、現在の SMG を形作ってきました。
原文を表示
How It Started: Hitting the GIL Wall at Scale
We’ve been running production model serving for many years. When we first started building Shepherd Model Gateway, the goal was modest: figure out if cache-aware load balancing could improve routing across inference replicas.
It could. And as we went deeper, we found a much bigger problem.
In both SGLang and vLLM, tokenization and detokenization had become bottlenecks. Not in theory — in production, under real traffic. The root cause was architectural: although both engines use Rust or C++ tokenizer libraries underneath, the calls go through Python. That means the GIL. That means a single-threaded ceiling on CPU-bound work that sits directly in the serving path.
At a small scale, this doesn’t matter. At large-scale prefill-decode disaggregated serving, and at large-scale expert parallelism across GPU clusters, it matters enormously. These configurations make GPUs extremely fast — fast enough that the CPU side of the pipeline becomes the constraint. Every microsecond of GIL-bound tokenization is a microsecond where GPUs worth hundreds of thousands of dollars sit idle, waiting for input.
That’s where the journey really started. Not with a gateway vision — with a production problem. Could we disaggregate the entire CPU workload from the GPU path and run it in Rust? Not Python-calling-Rust. Pure Rust. No GIL. No single-threaded ceiling. No Python process boundaries.
The answer was yes, and the project that proved it became Shepherd Model Gateway.
*SMG Architecture: Clients → Gateway → Router → Workers*
SMG’s architecture is built on one principle: GPUs should do tensor math. Everything else belongs in a dedicated serving layer.
We looked at the model-serving stack and identified every CPU-bound workload entangled with GPU inference: tokenization, detokenization, reasoning output parsing, function call extraction, MCP tool orchestration, multimodal preprocessing, chat history management, structured output validation, stop sequence detection. Each one is a CPU task that, when co-located with the GPU process behind the Python GIL, creates back-pressure on the most expensive hardware in the rack.
SMG moves all of these into a Rust gateway layer that communicates with inference engines over gRPC. The protocol is minimal and GPU-focused: send preprocessed tokens in, stream generated tokens out. Everything else is the gateway’s responsibility.
This isn’t the approach most projects in the distributed inference space have taken. Excellent work is happening with projects like NVIDIA Dynamo and llm-d, which focus on optimizing the inference engine layer and the orchestration around it. We see that work as complementary. But SMG’s bet is different: rather than making the engine smarter, make the gateway smarter. Offload everything that doesn’t require a GPU onto a purpose-built Rust layer that scales independently, evolves independently, and runs with zero GIL contention.
The gRPC Re-Architecture: Making It Real
***The gRPC Pipeline: Gateway-side processing before engine handoff*
The single largest technical investment in SMG’s history was rebuilding the entire serving pipeline around a native Rust gRPC data plane. This was the architectural proof of the disaggregation thesis.
Tokenization and detokenization move into the gateway. SMG runs tokenizers natively in Rust with a two-level cache — L0 exact-match for repeated prompts, L1 prefix-aware at special-token boundaries. The inference engine receives pre-tokenized input and never touches a tokenizer. No Python. No GIL.
Reasoning and tool call parsing runs in the gateway’s streaming pipeline. As tokens arrive over gRPC, SMG’s parsers — including Cohere Command, DeepSeek, Llama, Nemotron, Kimi-K2, GLM-4, and Qwen Coder — extract reasoning blocks, function calls, and structured output in real-time. No post-processing step on the engine side.
Multimodal processing was the most ambitious piece. We rewrote major components of Hugging Face’s transformers image processor from Python to Rust — reimplementing vision preprocessing pipelines, tensor operations, and model-specific transformations in a completely different language and runtime. The result: SMG communicates preprocessed tensors directly to engines via gRPC with zero Python overhead. Support for Llama 4 Vision, Qwen VL, and all major vision-language models, with backend-specific optimizations for SGLang, vLLM, and TensorRT-LLM. This is, to our knowledge, an industry first.
MCP tool orchestration runs entirely in the gateway with auth-aware connection pooling, concurrent batch execution, approval workflows, automatic reconnection, and HTTP header forwarding. The inference engine has no knowledge of MCP. We also built a complete built-in tool routing infrastructure — turning any MCP server into native capabilities (FileSearch, WebSearch, CodeInterpreter) for any model. Deploy Llama or Qwen with the same built-in tools as GPT-4.
Chat history management with pluggable storage (PostgreSQL, OracleDB, Redis and in-memory), schema versioning via Flyway, customizable table/column names, and storage hooks for pre/post persistence callbacks. All in the gateway, keeping the engine stateless.
WASM middleware provides programmable extensibility without forking the codebase. Custom authentication, compliance logging, PII redaction, cost tracking, compression — all via WebAssembly plugins with sandboxed isolation. Another industry first.
The gRPC protocol itself — published as smg-grpc-proto on PyPI — defines the narrow contract between gateway and engine. This design means you can upgrade your gateway (new parsers, new protocols, new tools) without touching your inference engine, and upgrade your engine (new GPU kernels, new quantization) without touching your gateway. They evolve independently because the interface is clean.
What SMG Delivers Today
SMG was created by Simo Lin and Chang Su, members of the LightSeek Foundation. In roughly six months, we shipped thirteen releases. Rather than walk through each one, here is what the project delivers today — and the evidence behind each capability.
Multi-Model Inference Gateway
A single SMG process fronts your entire fleet — multiple models, multiple engines, one entry point. Route requests across SGLang, vLLM, TensorRT-LLM, and MLX backends simultaneously. Add OpenAI, Anthropic, Google Gemini, AWS Bedrock, and Azure OpenAI as external providers. One gateway, every engine, every vendor.
Five Native Agentic APIs
SMG natively supports Chat Completions (OpenAI), Responses API (OpenAI), Messages API (Anthropic), Interactions API (Gemini), and Realtime API (WebSocket/WebRTC). These are not translation layers — each is a first-class implementation. The Messages API preserves thinking blocks end-to-end with ThinkingConfig, thinking_delta streaming events, and interleaved reasoning + text + tool use content blocks. The Responses API brings OpenAI’s conversation management to Llama, DeepSeek, Qwen, and every open-source model — SMG remains the only open-source gateway supporting it. Run agentic workflows designed for Claude on Llama 4, Qwen 3, DeepSeek, or Kimi with full protocol fidelity.
Native Rust gRPC Data Plane
***Two-Level Tokenizer Cache: L0 exact-match, L1 prefix-aware*
The architectural core: a native Rust gRPC pipeline between gateway and engine. The contract is minimal — preprocessed tokens in, generated tokens out. Everything else is the gateway’s responsibility. Tokenization runs in Rust with a two-level cache (L0 exact-match, L1 prefix-aware). Reasoning and tool call parsing runs in the streaming pipeline as tokens arrive — supporting fifteen model families including DeepSeek-R1, Qwen3, GLM-4, Kimi, Llama-4, Cohere Command, and more. No Python. No GIL. The gRPC protocol is published as smg-grpc-proto on PyPI, and both vLLM (PR #36169) and NVIDIA TensorRT-LLM (five merged PRs) have adopted it upstream.
Intelligent Routing
*Cache-Aware Routing Flow*
Eight load-balancing policies: cache-aware, round robin, random, power-of-two, consistent hashing, prefix hash, manual (sticky sessions), and bucket-based. Cache-aware routing was rewritten from the ground up — 10–12x faster (216,000 insertions/sec), 99% memory reduction (180 KB → 1.4 KB per node, 10,000 cached prefixes: 1.8 GB → 14 MB). Event-driven KV cache routing streams real-time cache state from all backends via SubscribeKvEvents RPC, with auto-learned block sizes. Production results on 8 Llama replicas: TTFT average down 23%, TTFT p99 down 28%. Prefill-decode disaggregation routes prefill and decode phases to separate worker pools with independent policies — 20–30% TTFT improvement in PD setups.
Multimodal Processing in Rust
We rewrote major components of Hugging Face’s image processors from Python to Rust — vision preprocessing pipelines, tensor operations, and model-specific transformations in a completely different language and runtime. Eight vision model families supported: Kimi K2.5, Llama-4 Vision, LLaVA, Phi-3/Phi-4 Vision, Pixtral, Qwen-VL, Qwen2-VL, and Qwen3-VL. Preprocessed tensors flow directly to engines via gRPC with zero Python overhead. To our knowledge, an industry first.
MCP Tool Orchestration & Built-in Tools
*MCP Architecture: Tool orchestration in the gateway*
MCP runs entirely in the gateway with auth-aware connection pooling, concurrent batch execution, approval workflows, automatic reconnection, and four transports (STDIO, HTTP, SSE, Streamable). Universal MCP Built-in Tools turn any MCP server into native capabilities — FileSearch, WebSearch, CodeInterpreter — for any model. Deploy Llama or Qwen with the same built-in tools as GPT-4. Per-tenant isolation, policy-based trust levels, and execution metrics come standard.
WASM Middleware
*WASM Plugin Pipeline*
Programmable extensibility via WebAssembly plugins with sandboxed isolation — another industry first. Custom authentication, compliance logging, PII redaction, cost tracking, compression — all without forking the codebase. Built on Wasmtime with Component Model and async support. Storage hooks intercept chat history operations for custom pre/post processing.
Enterprise Security & Observability
*TLS/mTLS Architecture*
JWT/OIDC authentication with JWKS discovery, role-based access control, API key auth, and multi-tenant rate limiting. TLS and mTLS for both client-facing and inter-node communication. A six-layer metrics system with 40+ Prometheus metrics covering HTTP, router, worker, inference, discovery, MCP, database, and mesh layers. Full OpenTelemetry distributed tracing. Structured JSON logging with request correlation.
Reliability & High Availability
*Circuit Breaker State Machine*
Per-worker circuit breakers (closed/open/half-open), automatic retries with exponential backoff and jitter, periodic health checks, concurrent request rate limiting, request timeouts, and configurable graceful shutdown. SWIM-protocol gossip mesh with CRDT-based state sync for multi-node deployments. Distributed rate limiting via consistent hashing across cluster nodes. Partition-tolerant by design.
Data Persistence & Service Discovery
*Service Discovery: Kubernetes, DNS, Manual*
Chat history management with pluggable storage — PostgreSQL, OracleDB, Redis, or in-memory — with schema versioning and customizable table/column names. Kubernetes label-based pod discovery, DNS discovery, or manual worker URLs. Model ID sourced from pod namespace, labels, or annotations. Bootstrap port annotation for automatic prefill port discovery in PD setups.
Universal Platform Support
Linux, Windows, macOS, x86, ARM — from a single Python wheel (pip install smg). Python 3.8–3.14. Production-ready client SDKs in Python, Rust, Java, and Go. Engine-specific Docker images. Full modularization into standalone crates: smg-auth, smg-mesh, smg-mcp, smg-wasm, smg-grpc-client, smg-kv-index, llm-tokenizer, llm-multimodal, openai-protocol, and more.
Proving the Thesis: gRPC Gateway Benchmarks
The disaggregation thesis predicts that moving CPU workloads off the GPU path should show measurable benefits — especially under production conditions. We tested this systematically.
Methodology
All benchmarks run on NVIDIA H100 GPUs using NVIDIA GenAI-Perf (genai-perf) via the SMG nightly benchmark suite on GitHub Actions. 8 models (GPT-OSS-20B, Llama-3.1-8B, Llama-3.3-70B, Llama-3.3-70B-FP8, Llama-4-Maverick, Llama-4-Scout, Qwen2.5-7B, Qwen3-30B-MoE), 2 runtimes (SGLang, vLLM), 5 traffic scenarios, 9 concurrency levels (1–256). Total: 1,082 matched gRPC vs HTTP comparison points.
The Scaling Story: Advantage Grows with Concurrency
At concurrency 1, gRPC and HTTP perform within noise. At concurrency 256, gRPC delivers ~8% more throughput. The gateway’s binary serialization and HTTP/2 multiplexing compound under load — exactly when it matters.
Long Contexts: Where gRPC Transforms Performance
HTTP/JSON serialization cost grows linearly with prompt length. gRPC/protobuf uses compact binary encoding that doesn’t pay this tax. At 7800 input tokens, the serialization cost is substantial. The D(7800,200) scenario shows +12.2% throughput advantage across all models.
The most dramatic result: Llama-3.3-70B-FP8 with 7800-token inputs. This model, running FP8 quantization on H100, is fast enough that HTTP serialization becomes the dominant bottleneck. gRPC delivers up to 3.5x higher output throughput: 1,150 tok/s vs 327 tok/s.
Per-Model Breakdown at High Concurrency
At production concurrency levels (32–256), the gRPC advantage varies by model architecture. Llama-3.3-70B-FP8 sees the largest gains (+15.8% E2E p99, +44.6% output throughput). Smaller dense models (Llama-3.1-8B, Qwen2.5-7B) show modest improvements. The pattern is clear: faster GPUs → larger gRPC advantage, because CPU overhead becomes a bigger fraction of total latency.
The Landscape
We’re not the only team working on LLM infrastructure.
NVIDIA Dynamo brings deep hardware integration and optimized inference orchestration. llm-d tackles distributed inference scheduling with a Kubernetes-native approach. Both are doing important work at the engine and cluster layer.
SMG operates at a different boundary: the serving and protocol layer. We own everything between the client and the GPU — tokenization, agentic protocol translation, tool orchestration, cache-aware routing, multimodal preprocessing, reliability. One layer, zero external dependencies, pure Rust.
The key insight: these approaches compose. You can run SMG in front of vLLM managed by llm-d, or in front of TensorRT-LLM with Dynamo handling GPU orchestration. The boundaries are clean because the responsibilities are different.
Production Adoption
SMG powers production deployments at:
- Google Cloud Platform — multi-tenant AI infrastructure
- Oracle Cloud Infrastructure — enterprise GenAI services
- Alibaba Cloud — cloud-native AI workloads
- TogetherAI — distributed inference infrastructure
From startups to hyperscalers.
What’s Next
- Batch API scheduling — two-tier architecture with Job Scheduler and Capacity Governor for offline workloads.
- Semantic routing — lightweight classification-based dispatch to different backends based on content, not static rules.
- Mixture of Vendors (MoV) — route the same model across multiple providers for A/B testing, cost optimization, and quality comparison.
- MCP Semantic Search — efficient tool discovery across servers with hundreds of registered tools.
- Custom metrics load balancing — CEL expressions over arbitrary metrics with sub-millisecond routing overhead.
GitHub: github.com/lightseekorg/smg
Install: pip install smg –upgrade
Docs: lightseekorg.github.io/smg
Acknowledgement
SMG’s development has been shaped by close collaboration with engineering teams and open-source communities across the industry. We’re grateful for the contributions, feedback, and partnership of:
- Oracle Generative AI Service — Jun Qian, Jingqiao Zhang, Wei Gao, Keyang Ru, Xinyue Zhang, Yifeng Liu, Ziwen Zhao, Daisy Zhou, Khoa Tran.
- TogetherAI — Yineng Zhang, Wei Gong, Chandra Mourya, Connor Li.
- Thinking Machines Lab — Eric Zhang, Rajat Goel, Jeff Hanson.
We also thank the SGLang, vLLM, and TensorRT-LLM communities for upstream collaboration and protocol adoption, and the teams at radixArk and Inferact for their partnership and feedback.
Their production deployments, code contributions, and technical insights have shaped what SMG is today.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み