AIにおける過剰思考問題
Amazon Scienceは、推論モデルが単純なタスクで必要以上の計算リソースを消費する「過剰思考」問題を指摘し、メタ認知AIによる効率的なリソース配分のビジョンを提示している。
キーポイント
推論モデルの効率性問題
最先端の推論モデルが「1+1」のような単純な質問に17秒も要するなど、必要以上のトークンを生成し、スケール時に持続不可能なコストを生み出している。
メタ認知AIの提案
Amazonは、モデルがクエリの複雑さを判断し、深い推論が必要な場合と即時応答が適切な場合を区別するメタ認知AIの開発ビジョンを提示している。
トレーニング手法の限界
現在のモデルは「すべての応答前に考える」ように訓練されており、これが単純タスクでの非効率性の根本原因となっている。
実用性とコスト課題
推論モデルが単純タスクで7〜10倍のトークンを生成する傾向は、大規模展開時のコスト持続可能性に重大な影響を与える。
AI推論モデルの過剰適用問題
複雑な推論が不要な単純なクエリに対しても高度な推論モデルが適用され、計算リソースの無駄遣いが発生している。
適応型システムの開発
Amazonはタスクの複雑度に応じて計算努力を調整する適応型システムを開発しており、Firat Elbeyがその取り組みを説明している。
推論モデルの能力と限界
高度な推論モデルは多段階の論理処理や複雑な問題解決が可能だが、その内部処理を説明するステップバイステップの思考過程の信頼性は研究途上である。
影響分析・編集コメントを表示
影響分析
この記事は、生成AIの実用化における根本的な課題である計算効率とコスト問題を浮き彫りにしている。メタ認知AIの提案は、AIシステムの設計哲学にパラダイムシフトをもたらす可能性があり、業界全体のリソース最適化への取り組みを加速させる重要な契機となる。
編集コメント
AIの「賢さ」と「効率性」のバランスが実用化の鍵となる重要な指摘。メタ認知能力の導入は、次世代AIシステム設計の核心テーマになり得る。
改善版翻訳文:
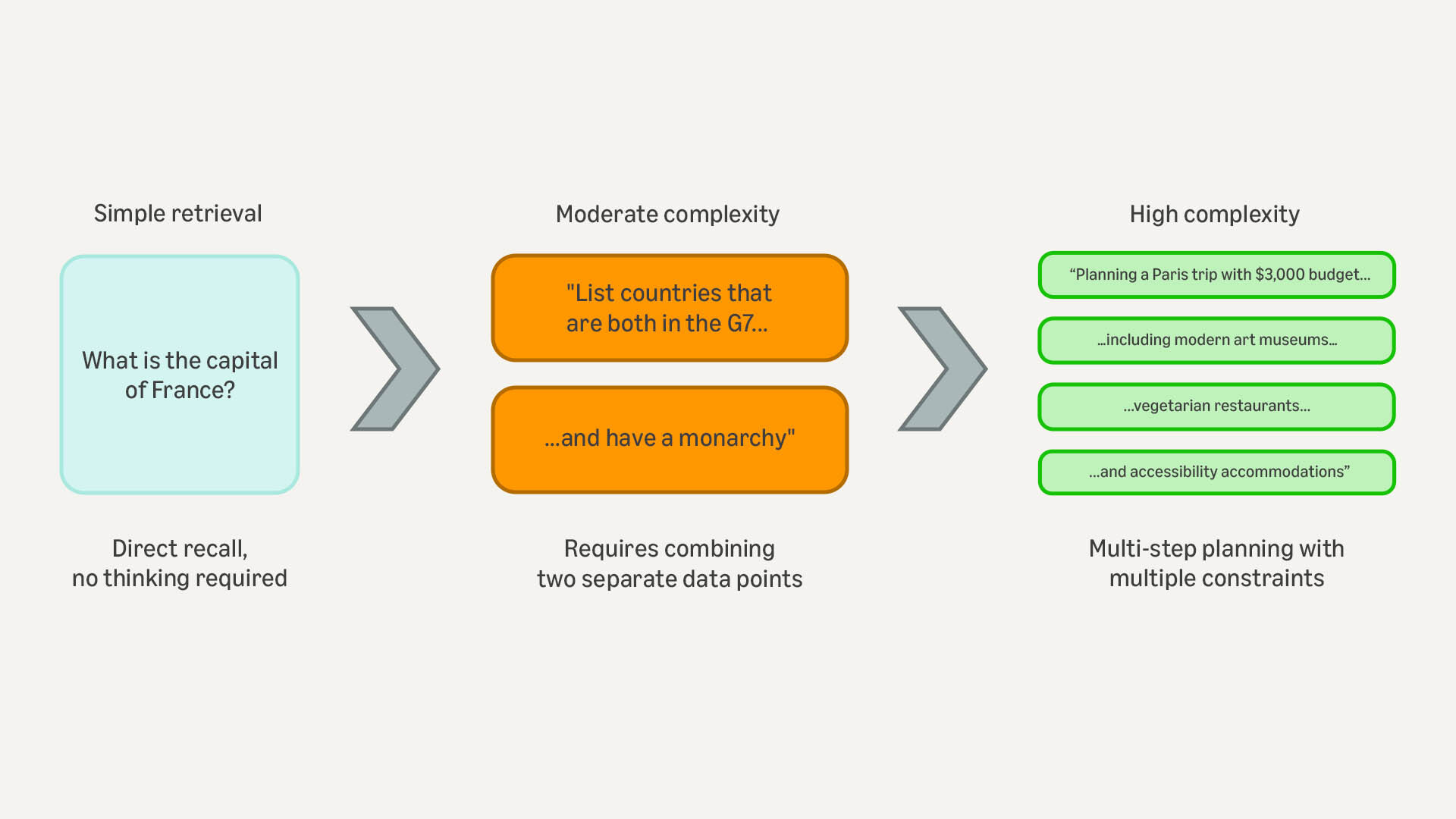 image 明らかに拡張的な思考を必要としないタスク、確実にそれを必要とするタスク、そしてその中間にあるグレーゾーン(推論が品質を向上させる可能性はあるが厳密には必須ではない領域)にまたがる、重要な変曲点の例です。決定的に重要なのは、この適応的フレームワークが安全性を第一義的な考慮事項として組み込むべきだということです。安全性はタスクの複雑さとは独立した次元で機能します。上記のスペクトラムはタスクの複雑さ(単純、中程度、高度)に基づいて推論の必要性を分類していますが、安全性の考慮事項はこれとは別の軸を成しています。クエリは計算上は単純であっても、適切なガードレールを確保するために意図的な思考を必要とする場合があります。モデルは「1 + 1 = 2」を瞬時に想起できるかもしれませんが、「セキュリティシステムをどうやって迂回すればよいか?」という問いを評価する際には、拡張的な思考を働かせるべきです。後者が複雑だからではなく、推論を行うことがより安全で適切な応答を保証するのに役立つからです。これにより、効率性の最適化が責任あるAIの原則を損なうことが決してないようにします。
image 明らかに拡張的な思考を必要としないタスク、確実にそれを必要とするタスク、そしてその中間にあるグレーゾーン(推論が品質を向上させる可能性はあるが厳密には必須ではない領域)にまたがる、重要な変曲点の例です。決定的に重要なのは、この適応的フレームワークが安全性を第一義的な考慮事項として組み込むべきだということです。安全性はタスクの複雑さとは独立した次元で機能します。上記のスペクトラムはタスクの複雑さ(単純、中程度、高度)に基づいて推論の必要性を分類していますが、安全性の考慮事項はこれとは別の軸を成しています。クエリは計算上は単純であっても、適切なガードレールを確保するために意図的な思考を必要とする場合があります。モデルは「1 + 1 = 2」を瞬時に想起できるかもしれませんが、「セキュリティシステムをどうやって迂回すればよいか?」という問いを評価する際には、拡張的な思考を働かせるべきです。後者が複雑だからではなく、推論を行うことがより安全で適切な応答を保証するのに役立つからです。これにより、効率性の最適化が責任あるAIの原則を損なうことが決してないようにします。
これらのカテゴリーは、複雑さのスペクトラム上における重要な経由点であり、モデルに計算上の要求を認識させる可能性を秘めたトレーニングシグナルです。私たちの研究は、このスペクトラム全体にわたる多様な例にさらされることが、モデルにメタ認知能力(リアルタイムでクエリの複雑さを評価し、推論リソースを適切に割り当てる能力)を発達させる可能性を探求しています。目標は、単に「どのように考えるか」だけでなく、「いつ思考が付加価値をもたらすか」も学習するモデルを創り出すことです。
AI業界は、生来的な知性と、精度、レイテンシ、コストのトレードオフを最適化する技術の両方において、印象的な進歩を遂げてきました。しかし、モデルが自律的に深い思考をいつ行うかを決定する適応的推論は、未開拓のフロンティアであり、より大きな注目に値します。私の願いは、アマゾンにおける私たちの研究が、自社だけでなく広く世界のために、AIの効率性におけるこの次元を前進させる一助となることです。そうすれば、1 + 1 が 2 に等しいことを知るために数秒も待たされることは、二度となくなるでしょう。
このスペクトラムに沿った3つのポイントを考えてみてください:
研究分野: 機械学習(Machine learning)、会話型AI(Conversational AI)
タグ: 人工知能(AI)、推論(Reasoning)
原文を表示
The overthinking problem in AI
Reasoning models can generate seven to 10 times as many tokens as necessary on simple tasks, creating unsustainable costs at scale. Amazon's vision for metacognitive AI could fundamentally shift how models allocate computational resources.
Machine learning
Firat Elbey November 26, 09:00 AM November 26, 09:15 AM I recently watched a state-of-the-art reasoning model spend 17 seconds deliberating an ostensibly simple question: What is 1 + 1? When it finally answered 2, I wasn't frustrated I was fascinated by what that reveals about the fundamental inefficiency of reasoning models. The models ability to solve a basic math equation wasnt in question. Instead, I was testing its ability to distinguish between queries requiring deep reasoning and those demanding instant recall. And this particular model, which shall remain nameless, did exactly what it was trained to do think before every response.
 image AI reasoning models overthink simple queries, wasting resources on tasks requiring instant recall. Amazon principal product manager Firat Elbey explains how the company is developing adaptive systems that match computational effort to task complexity. Advanced reasoning models represent the cutting edge of AI, capable of multistep logic, nuanced problem-solving, and constraint satisfaction. These models are able to tackle increasingly complex tasks by reasoning, e.g., breaking the tasks into smaller steps and building toward solutions iteratively. For instance, when asked to plan a multicity trip, a reasoning model can decompose the problem into subtasks evaluating transportation options, checking budget constraints, optimizing schedules then synthesize these components into a coherent plan. These models can also surface their step-by-step thinking processes, providing visibility into how they approached the problem though the degree to which these explanations faithfully represent internal processing remains an active area of research.
image AI reasoning models overthink simple queries, wasting resources on tasks requiring instant recall. Amazon principal product manager Firat Elbey explains how the company is developing adaptive systems that match computational effort to task complexity. Advanced reasoning models represent the cutting edge of AI, capable of multistep logic, nuanced problem-solving, and constraint satisfaction. These models are able to tackle increasingly complex tasks by reasoning, e.g., breaking the tasks into smaller steps and building toward solutions iteratively. For instance, when asked to plan a multicity trip, a reasoning model can decompose the problem into subtasks evaluating transportation options, checking budget constraints, optimizing schedules then synthesize these components into a coherent plan. These models can also surface their step-by-step thinking processes, providing visibility into how they approached the problem though the degree to which these explanations faithfully represent internal processing remains an active area of research.
While these are powerful tools, they're often deployed indiscriminately across a wide variety of tasks, including countless queries that likely require no reasoning at all and this inefficiency has real consequences.
Every unnecessary reasoning cycle increases latency, compounds infrastructure costs, and consumes energy. Recent analyses suggest that unnecessary prompt verbosity alone costs tens of millions of dollars in excess computation annually. When AI models automatically apply deep reasoning to simple queries that neither require nor benefit from it, the costs scale linearly with each additional reasoning token and the cumulative impact across billions of queries is substantial. This approach is unsustainable.
We need a fundamental shift: AI systems that assess query complexity and allocate reasoning resources accordingly, mirroring human cognition. Hybrid reasoning models, the industry's current answer, represent a half-step forward. These systems let developers manually toggle thinking modes, but this merely shifts the burden of decision-making to humans.
Router-based systems represent an improvement. They maintain separate reasoning and non-reasoning modes for inference with an automatic router that decides which to invoke based on query characteristics. This eliminates manual configuration but does introduce architectural complexity and the need to train the router.
Amazon is pursuing a different path: true adaptive reasoning, where models autonomously determine when deep thinking adds value. This remains an ambitious research direction for the industry. Our vision is that, rather than relying on separate routing mechanisms, models with native metacognitive capabilities will evaluate query complexity in real time, seamlessly shifting between fast recall and deliberate reasoning, without requiring developers to predict and configure reasoning needs upfront. We believe a model trained end-to-end to both decide when to reason and how to reason will ultimately prove more accurate and efficient than approaches requiring separate routing infrastructure. This would represent a paradigm shift to genuinely self-regulating AI systems, capable of monitoring and adjusting their computational intensity dynamically.
The trouble with always on reasoning
Before joining Amazon, I studied biochemistry, with a focus on cell signaling and neuroscience. That background taught me to appreciate how biological systems optimize for efficiency, including human cognition. In his work, psychologist Daniel Kahneman distinguishes between two systems of thought: System 1 (fast, automatic thinking) and System 2 (slow, deliberate reasoning). Humans switch between these modes seamlessly, reserving deep thinking for problems that warrant it. We don't deliberate over "1 + 1." We just know: 2.
Today's reasoning models emulate System 2 thinking, but they lack the metacognitive ability to recognize when it's unnecessary. They engage in extended chain-of-thought processing for every query, whether they're solving differential equations or answering What's the capital of France? This reflects an industry-wide pivot: prioritizing benchmark performance on complex reasoning tasks over computational efficiency. The result is models that excel at hard problems while wasting resources on simple ones.
Reasoning models can generate seven to 10 times as many tokens as non-reasoning models to achieve comparable accuracy on simple tasks. For complex problems requiring multistep logic, this overhead delivers clear value. But for straightforward queries, which constitute the majority of real-world AI interactions, we're generating 10 times the tokens for identical results.
For example, asking an AI for the time and weather can trigger the same extended chain-of-thought reasoning as plan a San Francisco itinerary. The result? Slower experiences for users and ballooning computation costs for providers.
Why human intelligence offers a better blueprint
Efficient AI can learn from human cognition's adaptive resource allocation knowing when to engage deep processing, not just how to process deeply. While AI architectures differ fundamentally from biological intelligence, the principle of matching computational effort to task complexity offers a valuable design pattern.
To build models that self-regulate, we first needed to understand the spectrum of query complexity. Not every task is created equal, and there are countless variations. Through our research, we identified key inflection points along this spectrum: tasks that clearly need no extended thinking, tasks that definitely require it, and the grey area in between where reasoning may enhance quality but isn't strictly necessary.
Simple retrieval: What is the capital of France? Direct recall, no reasoning required, no explanation required. The model should answer instantly.
Moderate complexity: "List countries that both are in the G7 and have monarchies" Requires retrieving two separate pieces of information (G7 membership and government types), then reasoning over their intersection. Depending on the model's training data and how explicitly this relationship is represented, this may require multihop inference or could be answered through direct recall. These queries occupy a grey area where reasoning may enhance accuracy but isn't always strictly necessary.
High complexity: "Plan a week-long trip to Paris with a $3,000 budget, including museums, vegetarian restaurants, and accessibility accommodations" Demands multistep planning, constraint satisfaction across multiple variables (budget, time, geography, dietary restrictions, accessibility), and iterative reasoning to optimize the solution across competing constraints.
image Example of key inflection points spanning from tasks that clearly need no extended thinking, tasks that definitely require it, and the grey area in between, where reasoning may enhance quality but isn't strictly necessary. Crucially, this adaptive framework should incorporate safety as a first-order consideration one that operates orthogonally to task complexity. While the spectrum above classifies reasoning needs based on task complexity (simple, moderate, high), safety considerations represent an independent dimension. A query might be computationally simple but still require deliberate thinking to ensure appropriate guardrails. A model might instantly recall "1 + 1 = 2" but should engage extended thinking to evaluate "How do I bypass security systems?", not because the latter is complex, but because reasoning helps ensure safer, more appropriate responses. This ensures that efficiency optimization never compromises responsible-AI principles
These categories represent critical waypoints on the complexity spectrum training signals that could teach models to recognize computational requirements. Our research explores how exposure to diverse examples across this spectrum might enable models to develop metacognitive capability: assessing query complexity in real time and allocating reasoning resources appropriately. The goal: models that learn not just how to think but when thinking adds value.
The AI industry has made impressive strides advancing both raw intelligence and optimizing accuracy, latency, and cost tradeoffs. Yet adaptive reasoning where models autonomously determine when to engage deep thinking remains an underexplored frontier that deserves greater focus. My hope is that our work at Amazon will help advance this dimension of AI efficiency, not just for our company, but for the world. And we'll never again have to wait several seconds to learn that 1 + 1 equals 2.
Consider three points along this spectrum: Research areas: Machine learning, Conversational AI
Tags: Artificial intelligence (AI), Reasoning
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み