Claude が自己改善型エージェント機能を追加
Anthropic の Claude が、過去のセッション分析による自己改善(Dreaming)、事前定義された基準に基づく自己修正(Outcomes)、および専門サブエージェントへのタスク委任を可能にするマルチエージェントオーケストレーション機能を追加し、実務での複雑なタスク管理能力を大幅に向上させた。
キーポイント
Dreaming 機能による学習と改善
過去のセッションデータを分析してパターンを特定することで、エージェントの継続的な自己改善を可能にする新機能。
Outcomes による自律的修正
事前に定義された成功基準に基づいてエージェントが自ら結果を検証・修正する仕組みを導入し、精度を高めた。
マルチエージェントオーケストレーション
複雑なタスクを専門的なサブエージェントに委任・管理することで、大規模で多層的な作業フローを実現可能にした。
影響分析・編集コメントを表示
影響分析
このアップデートは、単なるチャットボットの域を超え、自律的に学習・修正し、複雑なタスクを分解実行する「真のエージェント」への転換点を示しています。特に Dreaming や Outcomes の概念は、AI が静的なツールから動的で適応的なパートナーへと進化することを意味し、企業における業務自動化のスケールと信頼性を根本から変える可能性があります。
編集コメント
「Dreaming」という表現が示すように、AI が過去の経験から学習して自身を改良するサイクルが実用化された点は画期的です。これにより、単発のタスク処理だけでなく、長期的な業務改善を目指す企業利用が現実的なものとなりました。
本日、Claude Managed Agents にて「ドリーミング(Dreaming)」機能を研究プレビューとしてリリースいたします。ドリーミングは過去のセッションをレビューしてパターンを見つけ、エージェントが自己改善できるよう支援することで、メモリの機能を拡張します。また、Managed Agents を活用して開発を行う開発者向けに、アウトカム(outcomes)、マルチエージェントオーケストレーション、およびウェブフックの利用も可能にしました。これらの更新により、最小限の操作で複雑なタスクを処理する能力がさらに向上したエージェントとなります。
ドリーミングを活用して自己改善型エージェントを構築する
ドリーミングは、エージェントのセッションやメモリストアを定期的にレビューし、パターンを抽出して記憶を整理することで、時間とともにエージェントが向上するためのスケジュールされたプロセスです。制御の程度はご自身で決定できます:ドリーミングは自動的にメモリを更新することも可能ですし、変更が適用される前に確認を行うことも可能です。
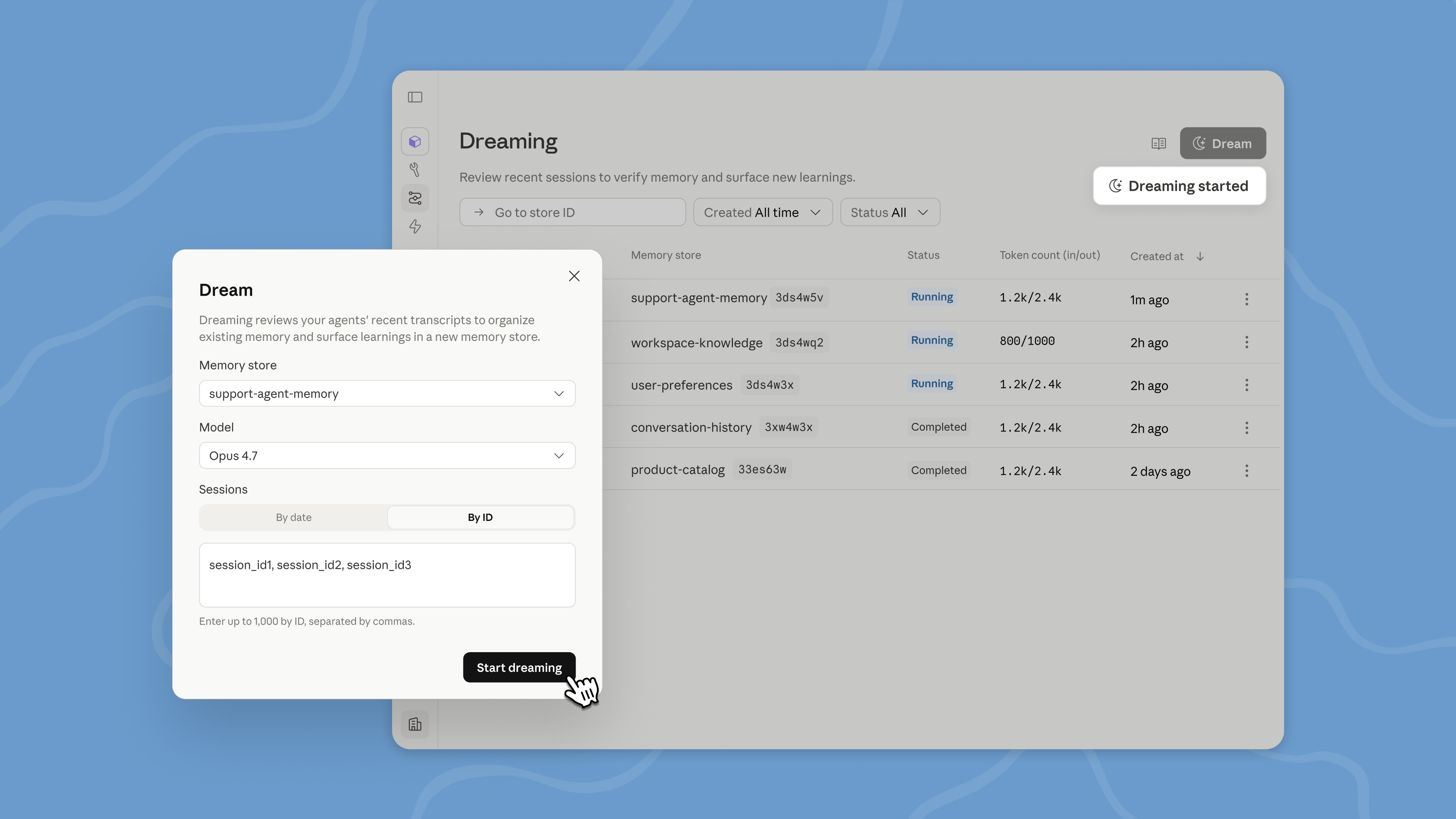
ドリーミングは、単一のエージェントでは見つけることができないパターンを浮き彫りにします。これには、繰り返されるミスの特定、エージェントが収束するワークフロー、チーム全体で共有される嗜好などが含まれます。また、進化しても高品質なシグナル(high-signal)を維持できるようメモリ構造を再構築します。これは、長時間実行されるタスクやマルチエージェントオーケストレーションにおいて特に有用です。
記憶と夢想は、自己改善型エージェントのための堅牢な記憶システムを形成します。記憶により、各エージェントは作業中に学習した内容を捕捉できます。一方、夢想はセッション間にその記憶を洗練させ、共有された学習成果を他エージェント間にも波及させ、常に最新の状態を維持します。
夢想機能は、Claude Platform のマネージドエージェントで利用可能です。開発者は こちら からアクセスをリクエストできます。
より良い成果を実現する
アウトカム(目標) を用いることで、成功の基準となるルブリック(評価基準)を記述し、エージェントはその達成を目指して作業を行います。出力は、エージェントの推論プロセスとは独立した別のコンテキストウィンドウ内で評価者によってチェックされるため、エージェントの思考に影響されません。何かが不適切な場合、評価者は修正すべき点を特定し、エージェントは再度試行します。
エージェントが「良い状態」を明確に理解しているとき、最も優れた成果を出せます。例えば、構造的なフレームワークやプレゼンテーションの基準、あるいは満たす必要がある要件のセットなどが該当します。アウトカムを用いることで、エージェントはこれらの基準に対して自身の作業をチェックし、人間が各試行を手動でレビューする必要なく、出力が十分になるまで自己修正を繰り返すことができます。
Outcomes は、細部への注意と網羅的なカバレッジを要するタスクにおいて特に有用です。また、コピーがブランドボイスに合致しているか、デザインがビジュアルガイドラインに従っているかなど、主観的な品質の評価にも機能します。テストでは、標準的なプロンプトライプと比較してタスクの成功率が最大 10 ポイント向上し、最も困難な問題において最大の改善が見られました。また、ファイル生成の質も向上し、内部ベンチマークでは docx で +8.4%、pptx で +10.1% のタスク成功率アップを記録しました。
また、アウトカム(Outcomes)を定義してエージェントを実行させ、完了時に Webhook を介して通知を受け取ることも可能になりました。
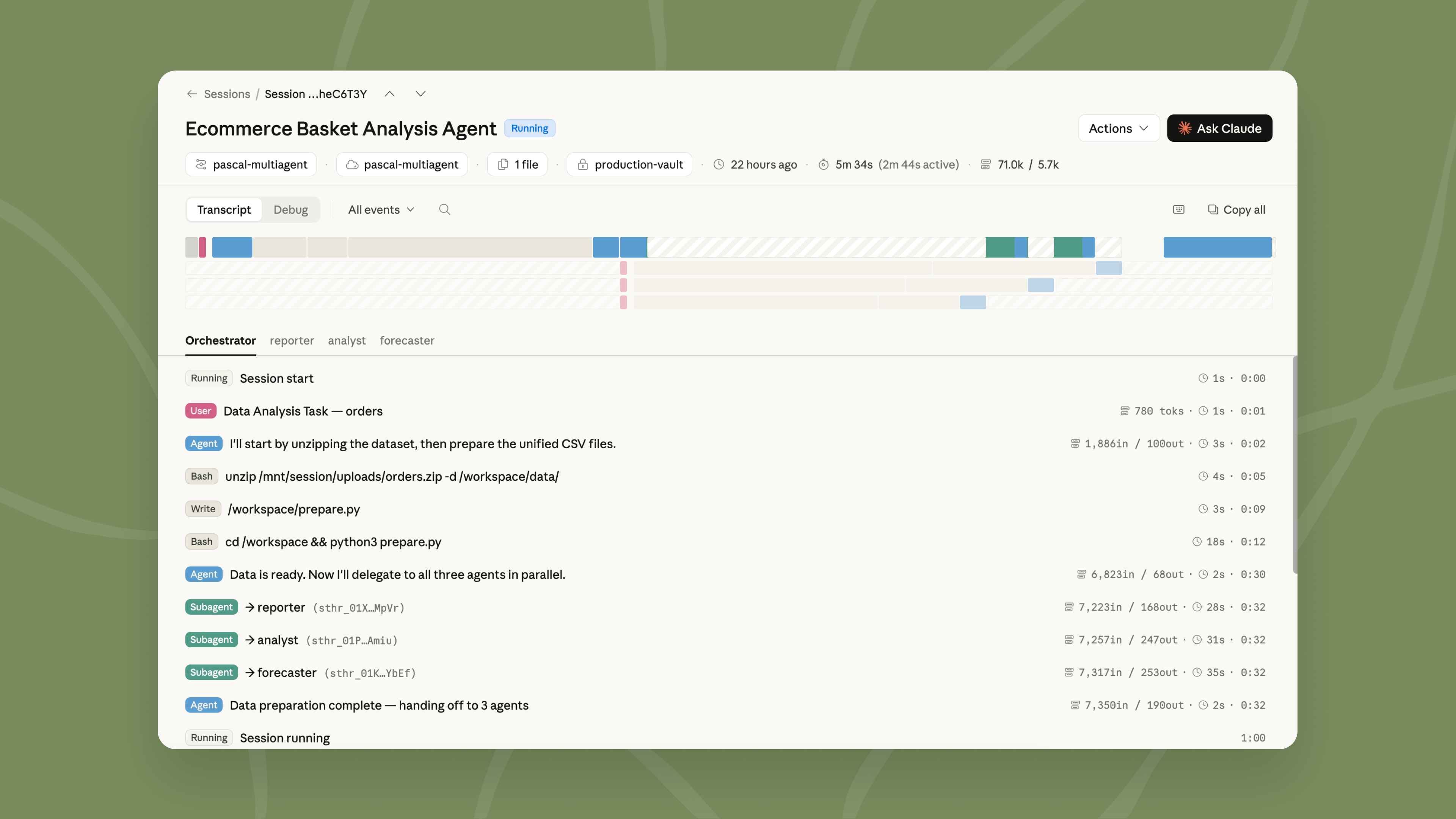
複数のエージェントで複雑なタスクを処理する
単一のエージェントでは対応しきれないほど多くの作業が必要な場合、マルチエージェントオーケストレーション を用いれば、リードエージェントが仕事を細分化し、それぞれに独自のモデル、プロンプト、ツールを持つ専門のエージェントへ委任できます。例えば、リードエージェントは調査を実行する一方で、サブエージェントはデプロイ履歴、エラーログ、メトリクス、サポートチケットなどへと分散して作業を進めます。
これらの専門家は共有ファイルシステム上で並列に動作し、リードエージェントの全体コンテキストに貢献します。イベントは永続的であり、すべてのエージェントが自身の行動を記憶しているため、リードエージェントはワークフローの途中で他のエージェントと再度連携することができます。また、Claude Console では、どのエージェントが何を、どのような順序で、なぜ行ったのかを追跡可能にすることで、タスクがどのように委任され実行されたかについて完全な可視性を提供します。
チームが構築しているもの
チームは、ドリーミング(Dreaming)、アウトカム志向、マルチエージェントオーケストレーションを活用して、自身の作業を検証し、セッション間で学習し、複雑なジョブを並列化できるエージェントをリリースしています:
- Harvey は、Managed Agents を用いて、長文のドラフト作成やドキュメント作成といった複雑な法的業務を調整しています。"dreaming"(夢見機能)により、彼らのエージェントはセッション間で学習した内容を記憶し、ファイル形式の回避策やツール固有のパターンさえも保持します。テストでは完了率が約 6 倍向上しました。
- Netflix のプラットフォームチームは、異なるソースからの数百ビルドのログを処理する分析エージェントを構築しました。数千ものアプリケーションに影響を与える変更において重要なのは、それらの多くで再発する問題を見つけることです。マルチエージェントオーケストレーションにより、エージェントはバッチを並列に分析し、行動を起こす価値のあるパターンのみを浮き彫りにします。
- Every の Spiral は、新しい API および CLI 背後のライティングエージェントを駆動するために、マルチエージェントオーケストレーションとアウトカム(成果指標)を活用しています。リードエージェントは Haiku で動作し、 incoming リクエストを受け付け、必要に応じて迅速なフォローアップ質問を行い、その後ドラフト作成を Opus で動作するサブエージェントに委任します。ユーザーが複数のドラフトを要求した場合、サブエージェントは並列で実行されます。ライティングの質は Spiral の中核的価値であるため、Every の編集原則とユーザーの声(どちらもメモリから取得)に基づく評価基準に対して各ドラフトを採点し、その基準を満たしたもののみを返却します。
- Wisedocs は Managed Agents 上にドキュメント品質チェックエージェントを構築し、アウトカムを用いて各レビューを社内ガイドラインに基づいて採点しています。レビューはチームの基準と整合性を保ちながら、現在 50% 高速化されています。

imageimage
始め方
「Dreaming」機能は研究プレビュー版として利用可能です。また、成果物(outcomes)、マルチエージェントオーケストレーション、メモリ機能は、Managed Agents の一部としてパブリックベータ版で利用できます。
Dreaming を始めるには、こちらからアクセス権をリクエストしてください。詳しくは ドキュメント をご覧ください。または、Claude Console にて最初のエージェントをデプロイすることもできます。
見つかったアイテムはありません。
原文を表示
Today we're launching dreaming in Claude Managed Agents as a research preview. Dreaming extends memory by reviewing past sessions to find patterns and help agents self-improve. We're also making outcomes, multiagent orchestration, and webhooks available to developers building with Managed Agents. Together, these updates make agents more capable at handling complex tasks with minimal steering.
Build self-improving agents with dreaming
Dreaming is a scheduled process that reviews your agent sessions and memory stores, extracts patterns, and curates memories so your agents improve over time. You decide how much control you want: dreaming can update memory automatically, or you can review changes before they land.
Dreaming surfaces patterns that a single agent can’t see on its own, including recurring mistakes, workflows that agents converge on, and preferences shared across a team. It also restructures memory so it stays high-signal as it evolves. This is especially useful for long-running work and multiagent orchestration.
Together, memory and dreaming form a robust memory system for self-improving agents. Memory lets each agent capture what it learns *as it works*. Dreaming refines that memory *between sessions*, pulling shared learnings across agents and keeping it up-to-date.
Dreaming is available in Managed Agents on the Claude Platform; developers can request access here.
Deliver better outcomes
With outcomes, you write a rubric describing what success looks like and the agent works toward it. A separate grader evaluates the output against your criteria in its own context window, so it isn't influenced by the agent's reasoning. When something isn't right, the grader pinpoints what needs to change and the agent takes another pass.
Agents do their best work when they know what "good" looks like. For example, a structural framework, a presentation standard, or a set of requirements that need to be met. With outcomes, agents can check their work against that bar and self-correct until the output is good enough, without a human needing to review each attempt.
Outcomes is particularly useful for tasks that require attention to detail and exhaustive coverage. It also works for subjective quality, like whether copy matches a brand voice or a design follows visual guidelines. In testing, outcomes improved task success by up to 10 points over a standard prompting loop, with the largest gains on the hardest problems. Outcomes also improved file generation quality, with +8.4% task success on docx and +10.1% on pptx in our internal benchmarks.
You can also now define an outcome, let the agent run, and get notified by a webhook when it's done.
Handle complex tasks with multiple agents
When there is too much work for a single agent to do well, multiagent orchestration lets a lead agent break the job into pieces and delegate each one to a specialist with its own model, prompt, and tools. For example, a lead agent can run an investigation while subagents fan out through deploy history, error logs, metrics, and support tickets.
These specialists work in parallel on a shared filesystem and contribute to the lead agent's overall context. The lead agent can check back in with other agents mid-workflow because events are persistent and every agent remembers what it's done. You can also trace every step in the Claude Console: which agent did what, in what order, and why, giving you full visibility into how your task was delegated and executed.
What teams are building
Teams are using dreaming, outcomes, and multiagent orchestration to ship agents that verify their own work, learn across sessions, and parallelize complex jobs:
- Harvey uses Managed Agents to coordinate complex legal work like long-form drafting and document creation. With dreaming, their agents remember what they learned between sessions, including filetype workarounds and tool-specific patterns. Completion rates went up ~6x in their tests.
- Netflix's platform team built an analysis agent that processes logs from hundreds of builds across different sources. With changes that affect thousands of applications, what matters is finding the issues that recur across many of them. Multiagent orchestration lets the agent analyze batches in parallel and surface only the patterns worth acting on.
- Spiral by Every is using multiagent orchestration and outcomes to power the writing agent behind their new API and CLI. The lead agent runs on Haiku: it fields incoming requests, poses quick follow-up questions when needed, then delegates the drafting to subagents running on Opus. When a user asks for multiple drafts, the subagents run in parallel. Writing quality is Spiral's core value, so they use outcomes to enforce it. Each draft is scored against a rubric of Every's editorial principles and the user's voice, both pulled from memory. Only drafts that clear the bar are returned.
- Wisedocs built a document quality check agent on Managed Agents, using outcomes to grade each review against their internal guidelines. Reviews now run 50% faster, while staying aligned with their team's standards.
eBook
Getting started
Dreaming is available in research preview, outcomes, multiagent orchestration, and memory are available in public beta as part of Managed Agents. To get started with dreaming, request access here. Explore our documentation to learn more or visit the Claude Console to deploy your first agent.
No items found.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み