Amazon S3 から PDF テキストを抽出するインタラクティブな仕組みの構築
AWS Machine Learning Blog は、Amazon S3 に保存された PDF からリアルタイムでテキストを抽出するインタラクティブな MCP サーバーの構築方法を解説し、従来のバッチ処理や Amazon Textract との比較を通じて、オンデマンドなドキュメントアクセスの実用性を示した。
キーポイント
リアルタイム PDF テキスト抽出の必要性
監査や契約確認など、即時に文書内の特定情報が必要なユースケースにおいて、バッチ処理やスクリプト作成の非効率性を解消するオンデマンドアクセスの重要性を強調している。
MCP サーバーによるインタラクティブアプローチ
Amazon S3 に保存された PDF に対して、プロトコルベースのサーバー(MCP)を構築することで、バッチパイプラインなしでプログラムによる対話型ドキュメントクエリを実現する手法を紹介している。
Amazon Textract との比較検討
本アプローチと AWS の公式サービスである Amazon Textract を比較し、ワークロードの特性(リアルタイム性 vs 構造化抽出など)に応じて最適なツールの選択基準を提供している。
S3 PDF の一時保存と抽出
PDF ファイルをローカルの一時ファイルにダウンロードし、PyPDF2 を使用してページごとにテキストを抽出する処理を実装しています。
ツール定義の構造化
S3 バケット名とオブジェクトキーを入力パラメータとして受け取る「extract_s3_pdf_text」ツールを、入力スキーマ付きで定義しています。
影響分析・編集コメントを表示
影響分析
この記事は、企業内の非構造化データ(PDF)を AI や分析システムに即座に活用したい開発者やアーキテクトにとって、従来のバッチ処理の壁を越える具体的な実装パターンを提供しています。特に MCP プロトコルの採用により、LLM アプリケーションとの連携が容易になるため、RAG システムやドキュメント分析ツールの開発効率向上に寄与する可能性があります。
編集コメント
バッチ処理に依存しないリアルタイムなドキュメント解析ニーズに応える、実用的なアーキテクチャ提案です。MCP プロトコルとの親和性を意識した解説は、現代の AI アプリ開発において非常に参考になります。
想像してみてください:監査中に特定の条項が必要なコンプライアンス担当者、電話で待っているクライアントのために契約条件を確認したい弁護士、10 分後に始まる会議の前に前四半期のレポートから数値が必要となる財務アナリスト。どのケースでも、スケジュールされたジョブの完了を待つのは現実的ではありません。PDF 内のテキストへのオンデマンドアクセスが必要です。
この記事では、Amazon S3 の PDF ファイルからリアルタイムでテキストを抽出するサーバーを構築します。このプロトコルベースのアプローチにより、プログラムによるドキュメントアクセスが可能になります。アーキテクチャの概要を確認し、サーバーを設定し、対話型のドキュメントクエリを実行する方法を順を追って説明します。その過程で、Amazon Textract とこのアプローチを比較し、ご自身のワークロードに最適なツールを選択できるようになります。
私たちは、同じ課題に直面していた複数のチームと協力した経験から、このソリューションを構築しました。彼らの文書は Amazon S3 に保存されていましたが、必要な時にテキストを取り出すには、独自のスクリプトを書くか、バッチパイプラインを待つしかなかったのです。この MCP サーバー(Model Context Protocol Server)アプローチはその中間に位置し、最小限の設定でインタラクティブなアクセスを提供します。Amazon S3 からのインタラクティブな PDF テキスト抽出(PDF Text Extraction)により、バッチパイプラインや大規模なインフラストラクチャを必要とせず、文書からリアルタイムの回答を得ることができます。
この MCP ベースのオプションは、開発環境や概念実証(PoC)におけるテキストベースの PDF にはよく機能します。光学式文字認識 (OCR)、フォーム抽出、レイアウト分析といった複雑なドキュメント処理については、Amazon Textract が引き続き推奨される選択肢です。
このアプローチから恩恵を受ける人々
このソリューションは、いくつかの一般的な役割に適合しています。これらのシナリオがあなたの日常業務と一致するようであれば、続けてお読みください。
コンプライアンスおよび法務チーム:時間制約のあるレビュー期間中、200 ページにわたるポリシー文書や契約書の中に埋もれた特定の条項を見つける必要があります。手動で検索するには時間がかかりすぎます。このソリューションを使えば、自然言語で質問するだけで、関連する記述を数秒で取得できます。
金融サービスチーム:監査セッション中、内部リスクポリシーまたは規制提出書類の正確な文言に即座にアクセスする必要があります。このソリューションを使えば、ターミナルから離れることなく、Amazon S3 ドキュメントリポジトリから直接その情報を取得できます。
経営陣:戦略計画会議では、誰かが前四半期の収益報告書から特定のデータポイントを尋ねた際に、その場で PDF を照会できます。印刷されたコピーをめくったり、会議後に誰かに確認を待ったりする必要はありません。
これらのシナリオにはいくつかの共通点があります。バッチ処理では対応が追いつかないリアルタイムの情報ニーズ、標準的な書式を持つテキストベースの PDF ドキュメント、開発および概念実証環境におけるコストへの敏感さ、そして既存の AWS ワークフローやツールとの統合要件です。
Amazon Textract との併用におけるこのアプローチの位置づけ
Amazon Textract は、大規模なドキュメント処理のために設計された完全管理型の AWS AI サービスです。スキャンされたページ、手書き文字、多段レイアウトを処理します。スキャン文書の OCR が必要である場合、高度なフォームおよびテーブル抽出、複雑なレイアウト分析、サービスレベル合意 (SLA) 要件を満たす生産規模のバッチ処理、またはコンプライアンス機能とエンタープライズサポートが必要な場合に Amazon Textract を選択してください。
MCP ベースのアプローチは、PDF に既にエンコードされたテキストに対して AI アシスタントにインタラクティブなオンデマンドアクセスを提供するという補完的なシナリオに対応します。ドキュメントがテキストベースの PDF(OCR 不要)であり、ワークフローがバッチ処理ではなくインタラクティブであり、開発環境または概念実証環境で作業を行っており、AI アシスタントとソースドキュメント間のインフラを最小限に抑えたい場合は、このパターンを選択してください。それ以外のすべてのケース、すなわち OCR や構造化抽出の恩恵を受けるあらゆるドキュメント処理については、その業務を Amazon Textract へルーティングしてください。
ソリューションの仕組み
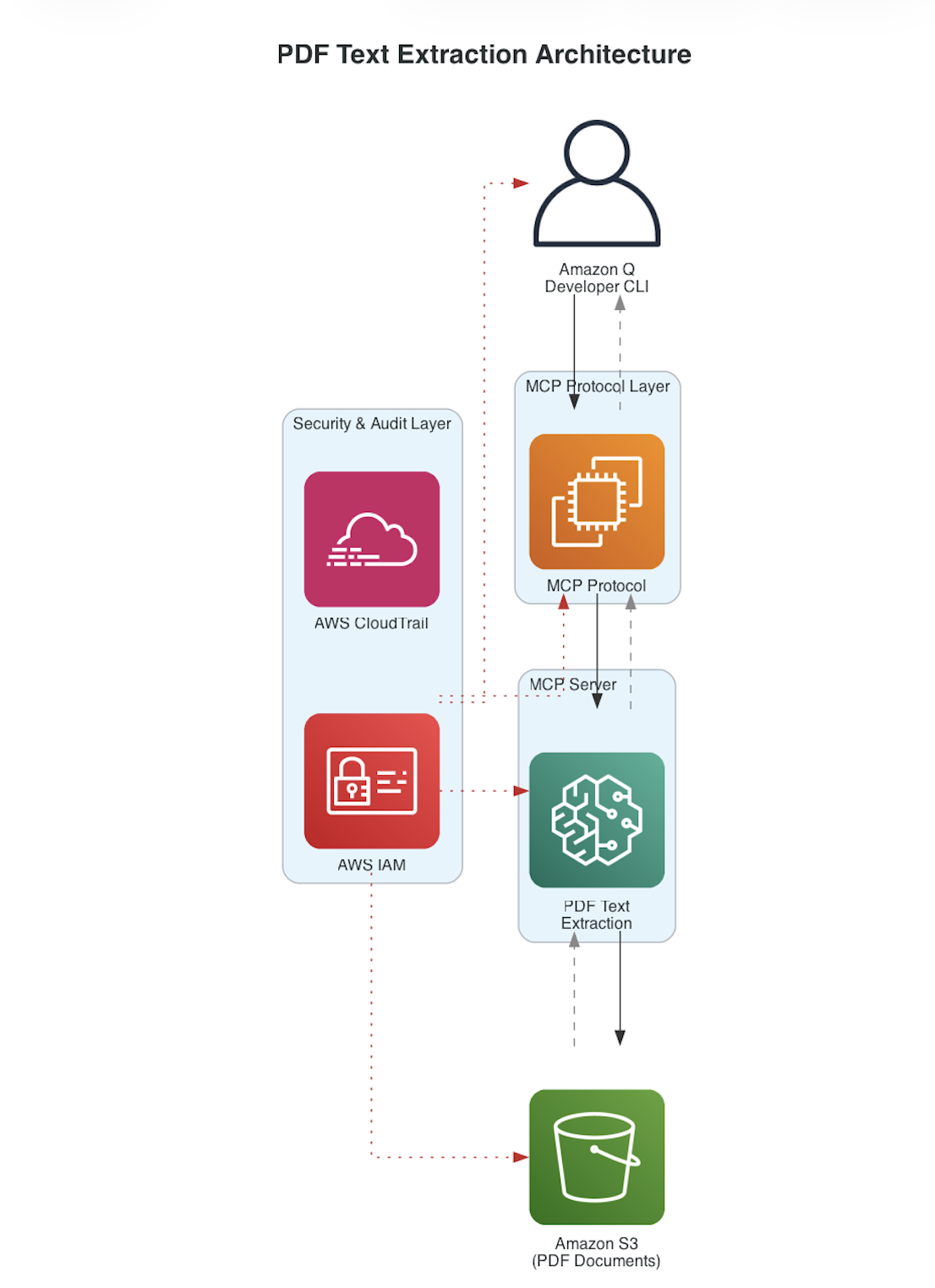
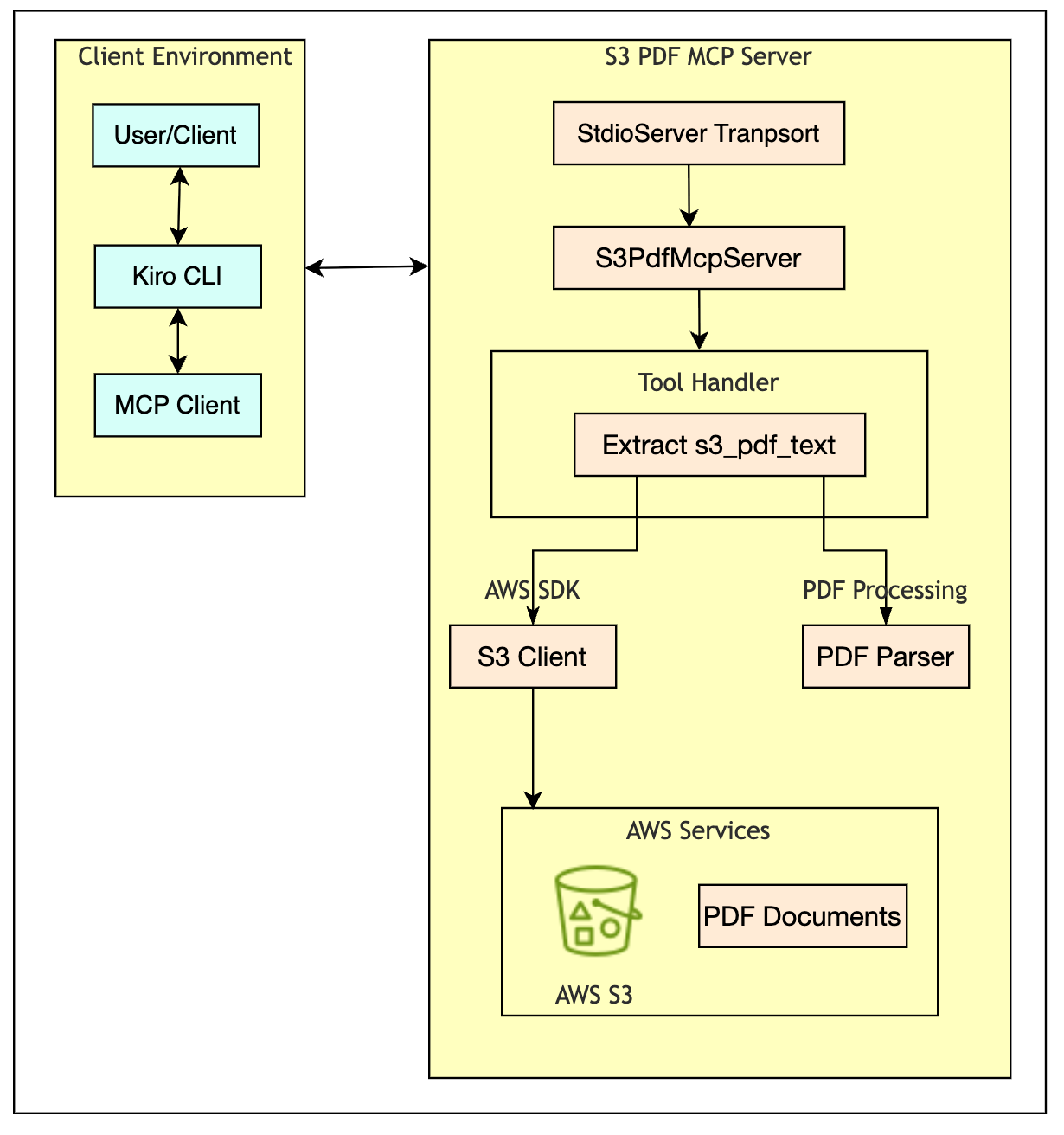
このソリューションでは、AI アシスタントを Amazon S3 に保存された PDF ドキュメントに直接接続し、素早く回答を取得できます。裏側では、外部データソースへの構造化されたアクセス方法を提供するオープン標準である Model Context Protocol (MCP) が使用されています。MCP は、アプリケーションとデータの間の通信層として機能します。このアーキテクチャには 4 つのコンポーネントがあります:ユーザーインターフェースとしてのコマンドラインインターフェース、通信のための MCP レイヤー、PDF 処理用のカスタム MCP サーバー、および AWS Identity and Access Management (AWS IAM) によって保護されたドキュメントストレージ用の Amazon S3 です。
**
 image
image
コスト比較
予算と要件に合ったアプローチを選択してください。概念実証環境で月間約 10,000 ページのテキストベースの PDF を処理する場合、2 つのアプローチは以下のようになります。
これら 2 つの数値は異なる機能セットに対する価格ポイントであり、直接比較してはいけません。これらの数値は、純粋にコストだけで最適化するためではなく、ワークロードに適したツールを選ぶために使用してください。ワークロードにスキャンされた文書、フォーム、表、複雑なレイアウト、または生産環境における SLA(サービスレベルアグリーメント)が含まれる場合、Amazon Textract が適切な選択肢となります。その追加機能は価格にも反映されています。
Amazon Textract の範囲:ページ単位の処理、OCR 対応、フォームおよび表の抽出、レイアウト理解、企業向け SLA**
**
示唆される月額コスト:Amazon Textract による処理は約$15、Amazon S3 のストレージは$2、AWS Lambda によるコンピューティングは$1、そして大規模言語モデル(LLM)のトークン処理は約$5〜$10で、合計は約$23〜$28となります。
MCP サーバーのスコープ:テキストが既にエンコードされている PDF からの直接テキスト抽出であり、管理された処理サービスは関与しません**
**
示唆される月額コスト:Amazon S3 のストレージは$2、データ転送は$0.50で、合計は約$2.50となります。**
*すべてのコスト数値は例示であり、変更される可能性があります。現在の料金は公式の AWS プライシングページを参照してください。
アーキテクチャ概要
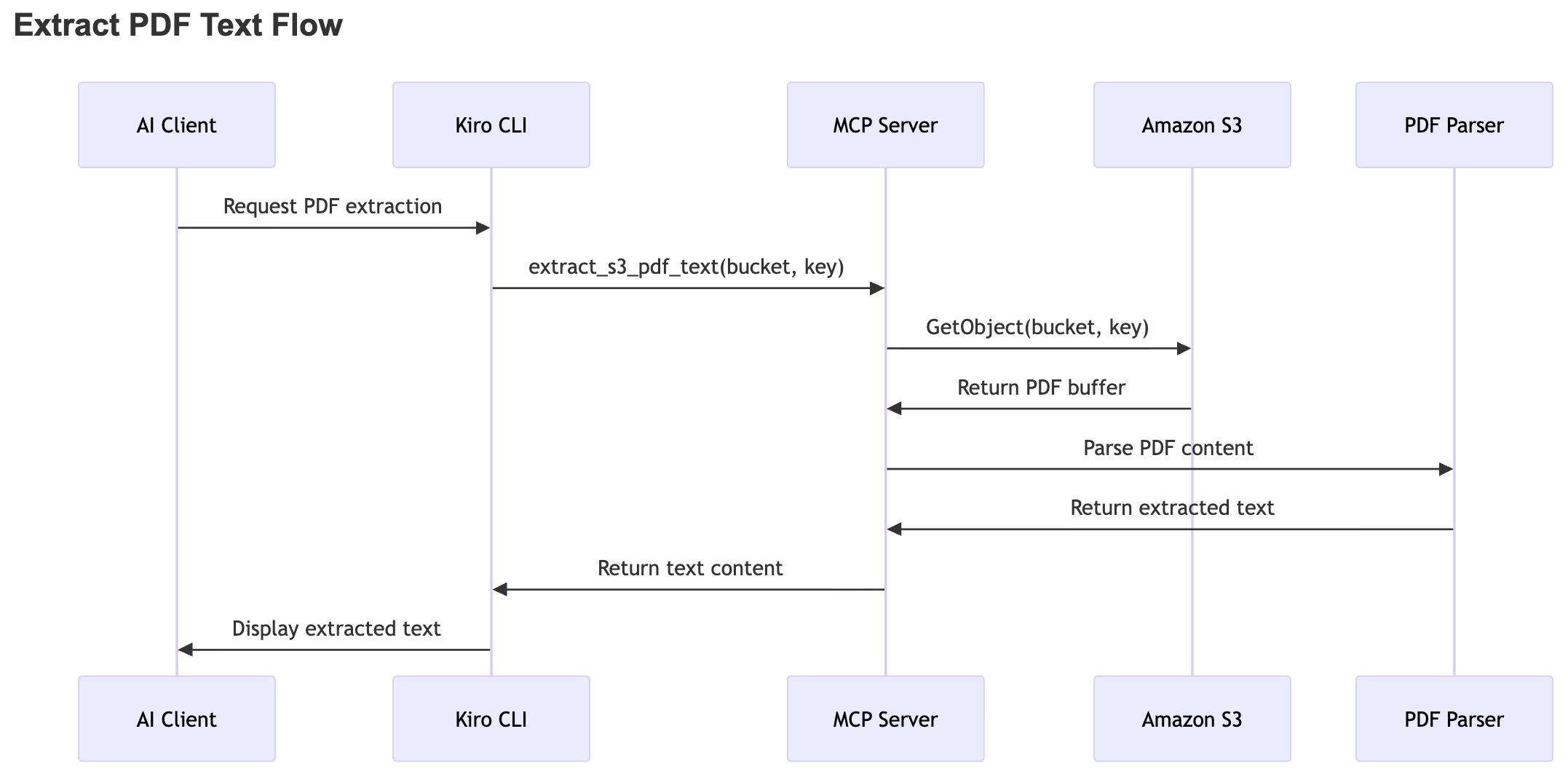
以下のシーケンス図は、Amazon S3 に保存された PDF からテキストを抽出するエンドツーエンドのワークフローを示しています。このプロセスは、AI クライアントが CLI を介して PDF 抽出のリクエストを開始することで始まります。システムはこのリクエストを MCP サーバーに転送し、サーバーは提供されたバケットとオブジェクトキーを使用して Amazon S3 から PDF ファイルを取得します。
MCP サーバーが PDF をフェッチした後、そのファイルを PDF パーシングコンポーネントに渡します。このコンポーネントはドキュメントを処理し、テキストコンテンツを抽出します。その後、MCP サーバーは抽出されたテキストをクライアントに戻し、クライアントがそれをユーザーに表示します。
ステップバイステップの実装
PDF テキスト抽出ソリューションを設定および構成するには、以下の手順に従ってください。まず、必要な前提条件が整っていることを確認することから始めます。
前提条件
開始する前に、以下の項目が準備できているか確認してください。また、Python プログラミングと AWS サービスに関する基本的な知識も必要です。
- Amazon S3 の読み取り権限を持つ AWS アカウント。
- Python 3.10 以降のインストール済み環境。
- 有効な認証情報で設定された AWS Command Line Interface (AWS CLI)。
- Kiro CLI のインストール済み。
- pip install boto3 PyPDF2 mcp
インストール
このセクションでは、MCP サーバーとその依存関係をインストールする手順を案内します。プロセスには、Python 仮想環境の作成、必要なパッケージのインストール、サーバーファイルの作成が含まれます。以下の手順を順番に実行してください。各コマンドはターミナルで実行してください。
開始前に必要なのは:**
- あなたのマシンに Python 3.10 以降がインストールされていること。
- Kiro CLI がインストールされ、ログイン済みであること。
- AWS の認証情報がマシン上に設定されていること(まだの場合は
aws configureを実行してください)。 - PDF ファイルを少なくとも 1 つ含む S3 バケットが存在すること。
ステップ 1 — プロジェクト用のフォルダを作成する
ターミナルで以下の 2 つのコマンドを実行します:
mkdir ~/s3-pdf-extractorステップ 2 — プロジェクトフォルダに移動する
次のコマンドを実行します:
cd ~/s3-pdf-extractorステップ 3 — Python の仮想環境を作成する
次のコマンドを実行します:
python3 -m venv venvステップ 4 — 仮想環境をアクティブ化する
次のコマンドを実行します:
source venv/bin/activateこれにより、ターミナルのプロンプトの先頭に (venv) が表示されます。このターミナルは開いたままにしてください。次のステップでは、この仮想環境内で作業を続ける必要があります。
ステップ 5 — 必要な Python パッケージをインストールする
次のコマンドを実行します:
pip install mcp boto3 PyPDF2完了するまで待ちます。「Successfully installed…」というメッセージで終了することを確認してください。
ステップ 6 — サーバーファイルを作成する
~/s3-pdf-extractor フォルダ内に、正確に以下の名前で新しいファイルを作成します:
s3_pdf_extractor.py以下のコードをそのファイルに貼り付けて保存してください:
ステップ 7 — サーバーが起動することを確認する
ターミナル(venv がアクティブな状態で s3-pdf-extractor フォルダ内にあること)で、次のコマンドを実行します:
python s3_pdf_extractor.pyターミナルは出力なしで「一時停止」したように見えます。これは正しい動作です。サーバーが実行中でリクエストを待機していることを意味します。停止するには Ctrl+C を押してください。
もしエラーが表示された場合は、手順 2 と 3 を再確認してください。
from mcp.server import Server
from mcp.types import Tool, TextContent
import boto3
from PyPDF2 import PdfReader
import tempfile
import os
import logging
Configure logging for production use
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
server = Server("s3-pdf-extractor")
@server.list_tools()
async def list_tools():
return [
Tool(
name="extract_s3_pdf_text",
description="Extract text content from a PDF stored in Amazon S3",
inputSchema={
"type": "object",
"properties": {
"bucket": {"type": "string", "description": "S3 bucket name"},
"key": {"type": "string", "description": "S3 object key"}
},
"required": ["bucket", "key"]
}
)
]
@server.call_tool()
async def call_tool(name: str, arguments: dict):
if name == "extract_s3_pdf_text":
bucket = arguments["bucket"]
key = arguments["key"]
try:
# Use existing AWS credentials and IAM permissions
s3_client = boto3.client('s3')
with tempfile.NamedTemporaryFile(delete=False, suffix='.pdf') as tmp_file:
s3_client.download_file(bucket, key, tmp_file.name)
tmp_path = tmp_file.name
# PyPDF2 を使用してテキストを抽出
reader = PdfReader(tmp_path)
text = ""
for page in reader.pages:
text += page.extract_text()
原文を表示
Picture this: a compliance officer needs a specific clause during an audit, an attorney needs contract terms while a client waits on the phone, or a finance analyst needs numbers from last quarter’s report before a meeting that starts in 10 minutes. In each case, waiting for a scheduled job to finish is not practical. You need on-demand access to the text inside your PDFs.
In this post, you’ll build a server that extracts text from PDF files in Amazon S3 in real time. This protocol-based approach provides programmatic document access. You’ll walk through the architecture, set up the server, and run interactive document queries. Along the way, you’ll compare this approach with Amazon Textract so you can decide which tool fits your workload.
We built this solution after working with several teams who shared the same frustration: their documents lived in Amazon S3, but getting text out of them on demand meant either writing custom scripts or waiting on batch pipelines. This MCP server approach sits in between, giving you interactive access with minimal setup. Interactive PDF text extraction from Amazon S3 gives you real-time answers from your documents without batch pipelines or heavy infrastructure.
This MCP-based option works well for text-based PDFs in development and proof of concept settings. For complex document processing like optical character recognition (OCR), form extraction, and layout analysis, Amazon Textract remains the recommended choice.
Who benefits from this approach
This solution fits several common roles. If these scenarios sound like your day-to-day, read on.
Compliance and legal teams: During a time-sensitive review, you need to locate a specific clause buried in a 200-page policy document or contract. Searching manually takes too long. With this solution, you ask a question in natural language and get the relevant passage back in seconds.
Financial services teams: During an audit session, you need immediate access to the exact wording of an internal risk policy or regulatory filing. This solution lets you pull that information directly from your Amazon S3 document repository without leaving your terminal.
Executive teams: During strategic planning meetings, you can query a PDF on the spot when someone asks about a data point from last quarter’s earnings report. No flipping through printed copies or waiting for someone to look it up after the meeting.
These scenarios share a few common traits: they involve real-time information needs where batch processing is too slow, text-based PDF documents with standard formatting, cost sensitivity in development and proof of concept environments, and integration requirements with existing AWS workflows and tooling.
Where this approach fits alongside Amazon Textract
Amazon Textract is a fully managed AWS AI service purpose-built for document processing at scale. It handles scanned pages, handwriting, and multi-column layouts. Choose Amazon Textract when you need OCR for scanned documents, advanced form and table extraction, complex layout analysis, production-scale batch processing with service level agreement (SLA) requirements, or compliance features and enterprise support.
The MCP-based approach addresses a complementary scenario: giving an AI assistant interactive, on-demand access to text already encoded inside PDFs. Choose this pattern when your documents are text-based PDFs (no OCR required), your workflow is interactive rather than batch, you are working in development or proof of concept environments, and you want minimal infrastructure between the AI assistant and the source document. For everything else, including any document processing that benefits from OCR or structured extraction, route the work to Amazon Textract.
How the solution works
With this solution, you connect your AI assistant directly to your PDF documents in Amazon S3 and can get answers quickly. Under the hood, the solution uses the Model Context Protocol (MCP), an open standard that provides a structured way to access external data sources. MCP acts as a communication layer between your application and your data. The architecture has four components: a command-line interface as the user interface, the MCP layer for communication, a custom MCP server for PDF processing, and Amazon S3 for document storage, secured by AWS Identity and Access Management (AWS IAM).
Cost comparison
Choose the approach that fits your budget and requirements. For approximately 10,000 text-based PDF pages per month in a proof of concept environment, here is how the two approaches compare:
These two figures are price points for different feature sets and should not be read as a head-to-head price comparison. Use them to pick the right tool for the workload, not to optimize purely on dollars. If your workload involves scanned documents, forms, tables, complex layouts, or production SLAs, Amazon Textract is the appropriate choice and the additional capabilities are reflected in its price.
Amazon Textract scope: page-level processing, OCR-ready, form and table extraction, layout understanding, enterprise SLAs
Indicative monthly cost: Amazon Textract processing approximately $15, Amazon S3 storage $2, AWS Lambda compute $1, and large language model (LLM) token processing approximately $5 to $10, for a total of approximately $23 to $28.
MCP server scope: direct text extraction from PDFs whose text is already encoded; no managed processing service involved
Indicative monthly cost: Amazon S3 storage $2 and data transfer $0.50, for a total of approximately $2.50.
*All cost figures are illustrative and may change. Refer to the official AWS pricing pages for current rates.*
Architecture overview
The following sequence diagram illustrates the end-to-end workflow for extracting text from a PDF stored in Amazon S3. The process begins when the AI client initiates a request for PDF extraction through the CLI. The system forwards this request to the MCP server, which retrieves the PDF file from Amazon S3 using the provided bucket and object key.
After the MCP server fetches the PDF, it passes the file to a PDF parsing component. The component processes the document and extracts the textual content. The MCP server then returns the extracted text to the client, and the client displays it to the user.
Step-by-step implementation
Follow these steps to set up and configure the PDF text extraction solution. Begin by confirming you have the required prerequisites in place.
Prerequisites
Before you begin, confirm that you have the following items ready. You’ll also need basic familiarity with Python programming and AWS services.
- An AWS account with Amazon S3 read permissions.
- Python 3.10 or later installed.
- AWS Command Line Interface (AWS CLI) configured with valid credentials.
- Kiro CLI installed.
`
pip install boto3 PyPDF2 mcp
### Installation
This section guides you through installing the MCP server and its dependencies. The process involves creating a Python virtual environment, installing the required packages, and creating the server file. Follow these steps in order. Run each command in your terminal.
**Before you start, you need:**
- Python 3.10 or newer installed on your machine.
- The Kiro CLI installed and logged in.
- AWS credentials set up on your machine (run aws configure if you haven’t).
- An S3 bucket that contains at least one PDF file.
**Step 1 — Create a folder for the project**
Run these two commands in your terminal:
mkdir ~/s3-pdf-extractor
**Step 2 — Navigate to the project folder**
Run this command:
cd ~/s3-pdf-extractor
**Step 3 — Create a Python virtual environment**
Run this command:
python3 -m venv venv
**Step 4 — Activate the virtual environment**
Run this command:
source venv/bin/activate
After this, your terminal prompt will show `(venv)` at the start. Keep this terminal open. You need to stay in this virtual environment for the next steps.
**Step 5 — Install the required Python packages**
Run this one command:
pip install mcp boto3 PyPDF2
Wait for it to finish. It should end with “Successfully installed…”.
**Step 6 — Create the server file**
Inside the `~/s3-pdf-extractor` folder, create a new file named **exactly:**
s3_pdf_extractor.py
Paste the following code into that file and save it:
**Step 7 — Test that the server starts**
In your terminal (still inside the `s3-pdf-extractor` folder with the venv active), run:
python s3_pdf_extractor.py
The terminal will appear to “pause” with no output. That is correct. It means the server is running and waiting for requests. Press `Ctrl+C` to stop it.
If you see an error instead, re-check Steps 2 and 3.
from mcp.server import Server
from mcp.types import Tool, TextContent
import boto3
from PyPDF2 import PdfReader
import tempfile
import os
import logging
# Configure logging for production use
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
server = Server("s3-pdf-extractor")
@server.list_tools()
async def list_tools():
return [
Tool(
name="extract_s3_pdf_text",
description="Extract text content from a PDF stored in Amazon S3",
inputSchema={
"type": "object",
"properties": {
"bucket": {"type": "string", "description": "S3 bucket name"},
"key": {"type": "string", "description": "S3 object key"}
},
"required": ["bucket", "key"]
}
)
]
@server.call_tool()
async def call_tool(name: str, arguments: dict):
if name == "extract_s3_pdf_text":
bucket = arguments["bucket"]
key = arguments["key"]
try:
# Use existing AWS credentials and IAM permissions
s3_client = boto3.client('s3')
with tempfile.NamedTemporaryFile(delete=False, suffix='.pdf') as tmp_file:
s3_client.download_file(bucket, key, tmp_file.name)
tmp_path = tmp_file.name
# Extract text using PyPDF2
reader = PdfReader(tmp_path)
text = ""
for page in reader.pages:
text += page.extract_text()関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み