SonraiがAmazon SageMaker AIを活用して精密医療試験を加速する方法
生命科学AI企業Sonraiは、AWSと提携し、Amazon SageMaker AIを用いたMLOpsフレームワークを構築。規制環境で必要な追跡可能性と再現性を維持しながら、精密医療試験の効率化を実現。
キーポイント
高次元バイオマーカー解析におけるMLOpsの重要性を示す実践例
Amazon SageMakerを活用した医療AIの規制対応フレームワーク構築
少数サンプル・多数特徴量問題へのAIソリューション適用の成功事例
影響分析・編集コメントを表示
影響分析
本記事は、医療AI分野におけるMLOpsの実践的な適用事例として、規制対応環境での再現性・トレーサビリティ確保の重要性を明確に示している。特に、数千のバイオマーカーと数百の患者サンプルという高次元データへの対応は、精密医療の実用化における共通課題への解決策として業界全体に影響を与える可能性がある。
編集コメント
医療AIの実用化においてMLOpsが不可欠であることを、具体的なユースケースを通じて説得力を持って示した良質な事例記事。規制対応環境でのAI開発のベストプラクティスとして参考になる。
Sonrai が Amazon SageMaker AI を活用して精密医療試験を加速させる方法
精密医療において、早期疾患検出のための診断テストを開発する研究者たちは、重要な課題に直面しています。それは、数千もの潜在的なバイオマーカーを含むデータセットに対して、患者サンプルが数百しかないという状況です。この次元の呪いは、画期的な発見の成功か失敗かを決定づける可能性があります。
現代のバイオインフォマティクスでは、早期疾患検出テストの開発のために、ゲノミクス、リポミクス、プロテオミクス、メタボロミクスなど、複数のオミックスモダリティが用いられています。この業界の研究者たちはまた、特徴量がサンプル数を桁違いに上回るデータセットにも直面することが多くあります。新しいモダリティが検討されるにつれて、組み合わせは指数関数的に増加し、実験の追跡が大きな課題となります。さらに、ソース管理とコード品質は、全体的な機械学習アーキテクチャにおいて極めて重要な側面です。効率的な機械学習運用(MLOps)プロセスが整備されていない場合、特にサイクルの初期発見段階ではこれが見過ごされがちです。
本稿では、ライフサイエンス AI 企業である Sonrai が AWS と提携し、規制環境で求められるトレーサビリティと再現性を維持しつつ、これらの課題に対処する堅牢な MLOps フレームワークを Amazon SageMaker AI を用いて構築した方法について探ります。
MLOps の概要
MLOps は、機械学習(ML)、DevOps、データエンジニアリングのプラクティスを組み合わせることで、生産環境における ML システムを信頼性高く効率的にデプロイおよび維持するためのものです。
初期から MLOps のベストプラクティスを導入することで、実験の反復を迅速化し、信頼性が高く追跡可能なモデル展開が可能になります。これらはすべて、ガバナンスと検証が最も重要な医療技術企業において不可欠な要素です。
Sonrai のデータ課題
Sonrai は、未治療のがん種に対するバイオマーカーテストを開発する大手バイオテクノロジー企業と提携しました。このプロジェクトでは、プロテオミクス、メタボロミクス、リポミクスなど複数のオミックスモダリティにわたる豊富なデータセットを扱い、高い感度と特異度を備えた早期検出用バイオマーカーのための最適な特徴量の組み合わせを特定することが目的でした。顧客はいくつかの重要な課題に直面していました。彼らのデータセットには 3 つのモダリティにまたがる 8,000 件以上の潜在的なバイオマーカーが含まれていましたが、患者サンプルは数百例のみでした。この極端な特徴量対サンプル比は、過学習を防ぐために洗練された特徴量選択を必要としました。チームは、モダリティの組み合わせやモデリングアプローチの数百通りを評価する必要があり、手動での実験追跡は現実的ではありませんでした。臨床使用を目的とした診断テストであるため、規制当局への提出には、生データからすべてのモデル化決定を経て最終的に展開されたモデルに至るまでの完全な追跡可能性が不可欠でした。
ソリューション概要
これらの MLOps の課題に対処するため、Sonrai は SageMaker AI を活用した包括的なソリューションを設計しました。SageMaker AI は、データサイエンティストや開発者が大規模な機械学習モデルの構築、トレーニング、デプロイを行うための完全管理型サービスです。このソリューションは、より安全なデータ管理、柔軟な開発環境、堅牢な実験追跡機能、そして完全なトレーサビリティを備えたスムーズなモデルデプロイを実現します。
以下の図は、アーキテクチャとプロセスフローを示しています。
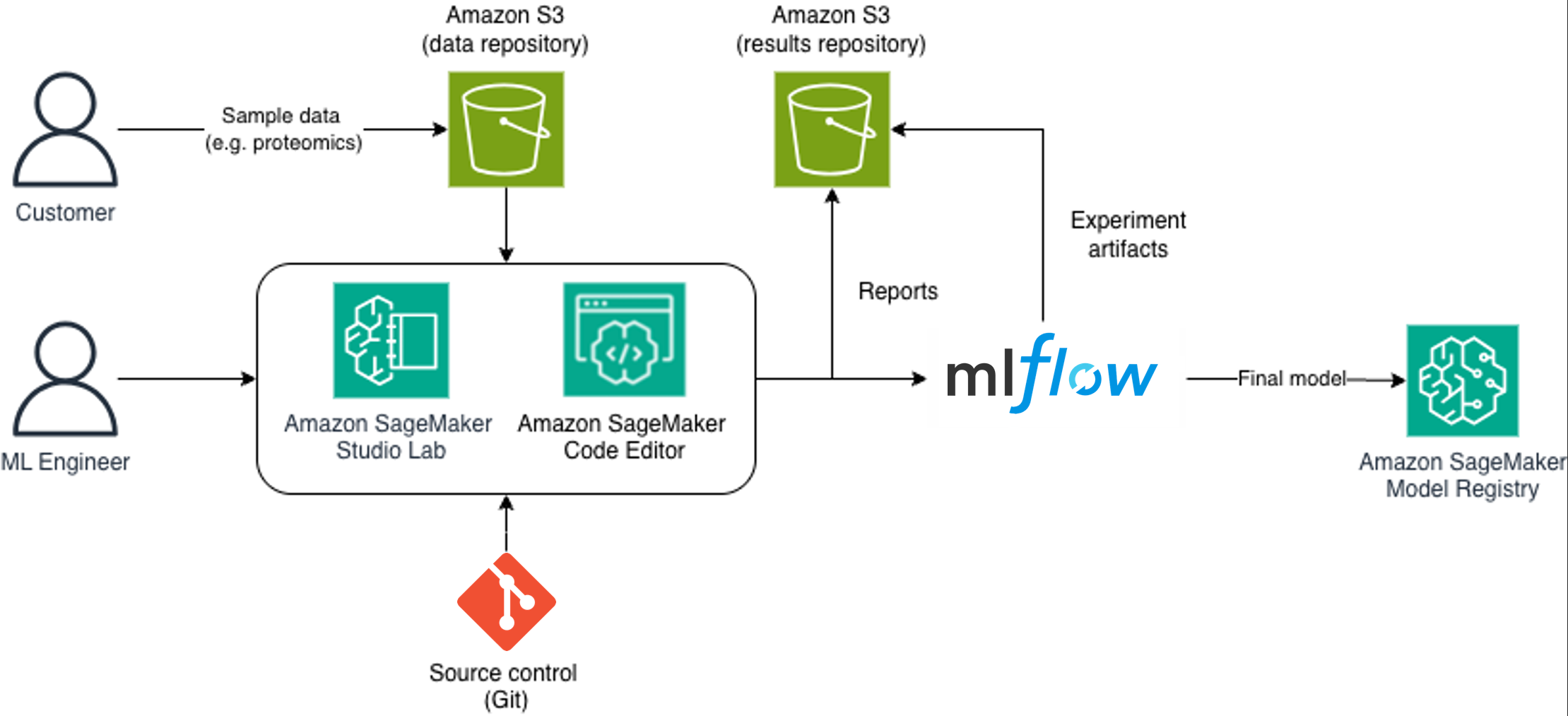
エンドツーエンドの MLOps ワークフローは、明確な経路に従います。
顧客がサンプルデータを Amazon Simple Storage Service (Amazon S3) の安全なデータリポジトリに提供します。
機械学習エンジニアは、ソース管理と連携した Amazon SageMaker Studio Lab と Code Editor を使用します。
パイプラインがデータリポジトリから読み取り、データを処理し、結果を Amazon S3 に書き込みます。
実験は Amazon SageMaker Studio 内の MLflow にログ記録されます。
生成されたレポートは Amazon S3 に保存され、ステークホルダーと共有されます。
検証済みのモデルは Amazon SageMaker Model Registry へプロモートされます。
最終的なモデルは推論またはさらなる検証のためにデプロイされます。
このアーキテクチャにより完全なトレーサビリティが可能になります。登録された各モデルは、ハイパーパラメータの選択やデータセットの分割を通じて、それを生成したソースデータとコードバージョンまで遡って追跡できます。
Amazon S3 を活用した安全なデータ管理
Sonrai のソリューションの基盤は、Amazon S3 を活用したセキュアなデータ管理です。Sonrai は、機密性の高い患者データを扱うために、S3 バケットに階層化されたアクセス制御を設定しました。サンプルおよび臨床データは、アクセス制限が設けられた専用データリポジトリバケットに保存され、データ保護要件に沿ったガバナンスを容易にしています。一方、処理済みのデータ、モデルの出力結果、生成されたレポートは、別の結果用リポジトリバケットに格納されます。この分離により、生体患者データのセキュリティを維持しつつ、分析結果の柔軟な共有が可能になります。Git リポジトリとのシームレスな統合により、協働作業、ソース管理、品質保証プロセスが実現されながら、AWS 環境内で機密性の高い患者データが保護されます。これは規制産業におけるガバナンスを維持する上で極めて重要です。
SageMaker AI MLOps
プロジェクト開始当初から、Sonrai は SageMaker AI 環境内で JupyterLab と Code Editor の両方のインターフェースを活用しました。この環境は顧客の Git リポジトリと統合され、初日からバージョン管理およびコードレビューのワークフローが確立されました。SageMaker AI は、数分でプロビジョニングでき、使用しない場合は停止できる幅広い ML 最適化コンピューティングインスタンスを提供しており、コスト効率を最大化します。本プロジェクトでは、Sonrai は大規模なオミクスデータセットを処理するのに十分なメモリを持つコンピューティングインスタンスを使用し、集中的なモデリング実行時には起動し、分析フェーズ中はシャットダウンしました。
Code Editor は、生産品質のパイプライン構築のための主要な開発環境として機能し、統合されたデバッグ機能と Git ワークフロー機能を備えています。JupyterLab はデータ探索および顧客との共同会議に使用され、そのインタラクティブなノートブック形式が結果のリアルタイム議論を容易にしました。
Quarto というオープンソースの技術出版システムなどのサードパーティ製ツールは、モデリングパイプライン内でレポート生成を可能にするため、SageMaker のコンピューティング環境内にインストールされました。単一の quarto レンダーコマンドを実行するだけで、完全なパイプラインが実行され、ステークホルダーが即座に使用可能なインタラクティブなビジュアライゼーション、統計テーブル、詳細なマークダウン注釈を備えたレポートが作成されます。レポートは自動的に結果用の S3 バケットに書き込まれ、顧客はパイプライン完了から数分以内にダウンロードできます。
SageMaker AI 内の管理された MLflow の機能により、実験の追跡がシームレスに行えるようになりました。SageMaker AI 環境内で実行される実験は自動的に MLflow に追跡・記録され、実験プロセスの包括的なビューが取得されます。本プロジェクトでは、MLflow がモデリング実験における唯一の信頼できる情報源となり、パフォーマンス指標、ハイパーパラメータ、特徴量の重要度ランキング、ROC カルブや混同行列などのカスタムアーティファクトをログとして記録しました。MLflow の UI は、実験を並べて比較するための直感的なインターフェースを提供し、チームが有望なアプローチを迅速に特定し、顧客レビューセッションで結果を共有することを可能にしました。
MLOps パイプライン
Sonrai のモデリングパイプラインは、生データを複数のステージを通じて処理して最終モデルを生成する、再現性がありバージョン管理されたワークフローとして構成されています:
Amazon S3 からの生オミクスデータが読み込まれ、正規化および品質管理が行われます。
ドメイン固有の変換が適用され、モデリング準備完了の特徴量が作成されます。
再帰的特徴選択 (Recursive Feature Elimination: RFE) により、疾患検出において最も重要な特徴量のみを残すために数千の特徴量が削減されます。
個別および複合モダリティにわたって複数のモデルがトレーニングされます。
モデルのパフォーマンスが評価され、包括的なレポートが生成されます。
各パイプラインの実行は MLflow で追跡され、入力データのバージョン、コードのコミット履歴、ハイパーパラメータ、パフォーマンス指標が記録されます。これにより、生データから最終モデルに至るまでの監査可能なトレイルが作成され、規制当局への提出に不可欠となります。これらのパイプラインは SageMaker 学習ジョブ上で実行され、スケーラブルな計算リソースを提供するとともに、学習メタデータの自動キャプチャを実現します。
最も重要なパイプラインの段階は RFE(再帰的特徴消去)であり、これはモデルのパフォーマンスを監視しながら、重要性の低い特徴を反復的に削除するプロセスです。MLflow は各イテレーションを追跡し、どの特徴が削除されたか、各ステップにおけるモデルのパフォーマンス、そして最終的に選択された特徴セットをログに記録しました。この詳細な追跡により、特徴選択の決定を検証可能にし、規制審査のための文書化を提供しました。
モデルデプロイメント
Sonrai は、開発ライフサイクル全体を通じてモデルのアーティファクトとメタデータを管理するために、MLflow と SageMaker Model Registry を補完し合う形で利用しています。活発な実験期間中、MLflow が主要な追跡システムとして機能し、軽量な実験追跡による迅速な反復を可能にします。モデルが事前に設定されたパフォーマンス閾値を満たし、より広範な検証や展開の準備が整った段階では、SageMaker Model Registry へプロモートされます。このプロモーションは、研究から開発への正式な移行を表しています。
候補となるモデルは成功基準に対して評価され、推論コードとコンテナと共にパッケージ化された上で、一意のバージョン識別子とともに SageMaker Model Registry に登録されます。SageMaker Model Registry は、Sonrai の品質管理システムに整合した正式な展開承認ワークフローをサポートしており、以下のステータスを含みます:
Pending – 新規に登録されレビュー待ちのモデル
Approved – 検証基準を通過し展開準備が整ったモデル
Rejected – 受入基準を満たさず、その理由が文書化されたモデル
がんバイオマーカープロジェクトにおいては、モデルは厳格な臨床基準に対して評価されました。具体的には、感度が少なくとも 90%、特異度が少なくとも 85%、AUC-ROC が少なくとも 0.90 であることが求められました。
承認されたモデルについては、展開オプションとして、リアルタイム推論用の SageMaker エンドポイント、大規模データセットの処理のためのバッチ変換ジョブ、または顧客固有環境での展開のためにアーティファクトを取得する選択肢があります。
結果とモデルの性能
SageMaker AI の ML 最適化コンピューティングインスタンスを使用することで、生データから最終モデルおよびレポートに至るまでのパイプライン全体が 10 分未満で実行されました。この迅速な反復サイクルにより、モデルの毎日更新や顧客会議中のリアルタイムコラボレーション、仮説の即時検証が可能になりました。従来は数日かかった作業が、今では単一の顧客通話内で完了できるようになっています。
モデリングパイプラインは、単一モダリティおよびマルチモダリティの組み合わせにおいて 15 の個別モデルを生成しました。最も性能が高かったモデルは、プロテオーム(タンパク質)とメタボローム(代謝物)の特徴を組み合わせたものであり、感度 94%、特異度 89%、AUC-ROC(曲線下面積:Area Under the Curve - Receiver Operating Characteristic)0.93 を達成しました。このマルチモダリティアプローチは単一モダリティのみを使用した場合よりも優れており、異なるオミクスデータタイプを統合することの価値を示しています。
優勝したモデルは、完全なメタデータとともに SageMaker Model Registry へ登録されました。これにはモデルアーティファクトの場所、トレーニングデータセット、MLflow(機械学習ライフサイクル管理ツール)実験 ID、評価指標、およびカスタムメタデータが含まれています。この登録済みモデルは、臨床検証研究への承認前に、顧客の臨床チームによる追加検証を受けました。「SageMaker AI をフルモデル開発プロセスに使用したことで、チームは完全な追跡可能性と最終結果に対する信頼を持ってコラボレーションし、迅速に反復することができました。Amazon SageMaker AI で利用可能な豊富なサービス群は、堅牢なモデルの開発、デプロイメント(展開)、およびモニタリングのための包括的なソリューションとなっています」と、Sonrai の AI 及び医療画像担当ディレクターである Matthew Lee は述べています。
Sonrai は AWS と提携し、SageMaker AI を活用して精密医療試験を加速する MLOps ソリューションを開発しました。このソリューションは、バイオマーカー発見における主要な課題に対処します。具体的には、限られた患者サンプルを扱いながら数千もの特徴量を持つ複数のオミクスモダリティからのデータセットの管理、数百に及ぶ複雑な実験の組み合わせの追跡、そして規制対応のためのバージョン管理とトレーサビリティの維持です。
その結果、開発の反復時間を日単位から分単位に短縮するスケーラブルな MLOps フレームワークが実現されました。
原文を表示
How Sonrai uses Amazon SageMaker AI to accelerate precision medicine trials
In precision medicine, researchers developing diagnostic tests for early disease detection face a critical challenge: datasets containing thousands of potential biomarkers but only hundreds of patient samples. This curse of dimensionality can determine the success or failure of breakthrough discoveries.
Modern bioinformatics use multiple omic modalities—genomics, lipidomics, proteomics, and metabolomics—to develop early disease detection tests. Researchers in this industry are also often challenged with datasets where features outnumber samples by orders of magnitude. As new modalities are considered, the permutations increase exponentially, making experiment tracking a significant challenge. Additionally, source control and code quality are a mission-critical aspect of the overall machine learning architecture. Without efficient machine learning operations (MLOps) processes in place, this can be overlooked, especially in the early discovery stage of the cycle.
In this post, we explore how Sonrai, a life sciences AI company, partnered with AWS to build a robust MLOps framework using Amazon SageMaker AI that addresses these challenges while maintaining the traceability and reproducibility required in regulated environments.
Overview of MLOps
MLOps combines ML, DevOps, and data engineering practices to deploy and maintain ML systems in production reliably and efficiently.
Implementing MLOps best practices from the start enables faster experiment iterations for and confident, traceable model deployment, all of which are essential in healthcare technology companies where governance and validation are paramount.
Sonrai’s data challenge
Sonrai partnered with a large biotechnology company developing biomarker tests for an underserved cancer type. The project involved a rich dataset spanning multiple omic modalities: proteomics, metabolomics, and lipidomics, with the objective to identify the optimal combination of features for an early detection biomarker with high sensitivity and specificity.The customer faced several critical challenges. Their dataset contained over 8,000 potential biomarkers across three modalities, but only a few hundred patient samples. This extreme feature-to-sample ratio required sophisticated feature selection to avoid overfitting. The team needed to evaluate hundreds of combinations of modalities and modeling approaches, making manual experiment tracking infeasible. As a diagnostic test destined for clinical use, complete traceability from raw data through every modeling decision to the final deployed model was essential for regulatory submissions.
Solution overview
To address these MLOps challenges, Sonrai architected a comprehensive solution using SageMaker AI, a fully managed service for data scientists and developers to build, train, and deploy ML models at scale. This solution helps provide more secure data management, flexible development environments, robust experiment tracking, and streamlined model deployment with full traceability.The following diagram illustrates the architecture and process flow.
The end-to-end MLOps workflow follows a clear path:
Customers provide sample data to the secure data repository in Amazon Simple Storage Service (Amazon S3).
ML engineers use Amazon SageMaker Studio Lab and Code Editor, connected to source control.
Pipelines read from the data repository, process data, and write results to Amazon S3.
The experiments are logged in MLflow within Amazon SageMaker Studio.
Generated reports are stored in Amazon S3 and shared with stakeholders.
Validated models are promoted to the Amazon SageMaker Model Registry.
Final models are deployed for inference or further validation.
This architecture facilitates complete traceability: each registered model can be traced back through hyperparameter selection and dataset splits to the source data and code version that produced it.
Secure data management with Amazon S3
The foundation of Sonrai’s solution is secure data management with the help of Amazon S3. Sonrai configured S3 buckets with tiered access controls for sensitive patient data. Sample and clinical data were stored in a dedicated data repository bucket with restricted access, facilitating governance with data protection requirements. A separate results repository bucket stores processed data, model outputs, and generated reports. This separation makes sure raw patient data can remain secure while enabling flexible sharing of analysis results. Seamless integration with Git repositories enables collaboration, source control, and quality assurance processes while keeping sensitive patient data secure within the AWS environment—critical for maintaining governance in regulated industries.
SageMaker AI MLOps
From project inception, Sonrai used both JupyterLab and Code Editor interfaces within their SageMaker AI environment. This environment was integrated with the customer’s Git repository for source control, establishing version control and code review workflows from day one.SageMaker AI offers a wide range of ML-optimized compute instances that can be provisioned in minutes and stopped when not in use, optimizing cost-efficiency. For this project, Sonrai used compute instances with sufficient memory to handle large omic datasets, spinning them up for intensive modeling runs and shutting them down during analysis phases.Code Editor served as the primary development environment for building production-quality pipelines, with its integrated debugging and Git workflow features. JupyterLab was used for data exploration and customer collaboration meetings, where its interactive notebook format facilitated real-time discussion of results.
Third-party tools such as Quarto, an open source technical publishing system, were installed within the SageMaker compute environments to enable report generation within the modeling pipeline itself. A single quarto render command executes the complete pipeline and creates stakeholder-ready reports with interactive visualizations, statistical tables, and detailed markdown annotations. Reports are automatically written to the results S3 bucket, where customers can download them within minutes of pipeline completion.
The managed MLflow capability within SageMaker AI enabled seamless experiment tracking. Experiments executed within the SageMaker AI environment are automatically tracked and recorded in MLflow, capturing a comprehensive view of the experimentation process. For this project, MLflow became the single source of truth for the modeling experiments, logging performance metrics, hyperparameters, feature importance rankings, and custom artifacts such as ROC curves and confusion matrices. The MLflow UI provided an intuitive interface for comparing experiments side-by-side, enabling the team to quickly identify promising approaches and share results during customer review sessions.
MLOps pipelines
Sonrai’s modeling pipelines are structured as reproducible, version-controlled workflows that process raw data through multiple stages to produce final models:
Raw omic data from Amazon S3 is loaded, normalized, and quality-controlled.
Domain-specific transformations are applied to create modeling-ready features.
Recursive Feature Elimination (RFE) reduces thousands of features to the most significant for disease detection.
Multiple models are trained across individual and combined modalities.
Model performance is assessed and comprehensive reports are generated.
Each pipeline execution is tracked in MLflow, capturing input data versions, code commits, hyperparameters, and performance metrics. This creates an auditable trail from raw data to final model, essential for regulatory submissions. The pipelines are executed on SageMaker training jobs, which provide scalable compute resources and automatic capture of training metadata.The most critical pipeline stage was RFE, which iteratively removes less important features while monitoring model performance. MLflow tracked each iteration, logging which features were removed, the model’s performance at each step, and the final selected feature set. This detailed tracking enabled validation of feature selection decisions and provided documentation for regulatory review.
Model deployment
Sonrai uses both MLflow and the SageMaker Model Registry in a complementary fashion to manage model artifacts and metadata throughout the development lifecycle. During active experimentation, MLflow serves as the primary tracking system, enabling rapid iteration with lightweight experiment tracking. When a model meets predetermined performance thresholds and is ready for broader validation or deployment, it is promoted to the SageMaker Model Registry.This promotion represents a formal transition from research to development. Candidate models are evaluated against success criteria, packaged with their inference code and containers, and registered in the SageMaker Model Registry with a unique version identifier. The SageMaker Model Registry supports a formal deployment approval workflow aligned with Sonrai’s quality management system:
Pending – Newly registered models awaiting review
Approved – Models that have passed validation criteria and are ready for deployment
Rejected – Models that did not meet acceptance criteria, with documented reasons
For the cancer biomarker project, models were evaluated against stringent clinical criteria: sensitivity of at least 90%, specificity of at least 85%, and AUC-ROC of at least 0.90. For approved models, deployment options include SageMaker endpoints for real-time inference, batch transform jobs for processing large datasets, or retrieval of model artifacts for deployment in customer-specific environments.
Results and model performance
Using ML-optimized compute instances on SageMaker AI, the entire pipeline—from raw data to final models and reports—executed in under 10 minutes. This rapid iteration cycle enabled daily model updates, real-time collaboration during customer meetings, and immediate validation of hypotheses. What previously would have taken days could now be accomplished in a single customer call.The modeling pipeline generated 15 individual models across single-modality and multi-modality combinations. The top-performing model combined proteomic and metabolomic features, achieving 94% sensitivity and 89% specificity with an AUC-ROC of 0.93. This multi-modal approach outperformed single modalities alone, demonstrating the value of integrating different omic data types.The winning model was promoted to the SageMaker Model Registry with complete metadata, including model artifact location, training dataset, MLflow experiment IDs, evaluation metrics, and custom metadata. This registered model underwent additional validation by the customer’s clinical team before approval for clinical validation studies. “Using SageMaker AI for the full model development process enabled the team to collaborate and rapidly iterate with full traceability and confidence in the final result. The rich set of services available in Amazon SageMaker AI make it a complete solution for robust model development, deployment, and monitoring,” says Matthew Lee, Director of AI & Medical Imaging at Sonrai.
Sonrai partnered with AWS to develop an MLOps solution that accelerates precision medicine trials using SageMaker AI. The solution addresses key challenges in biomarker discovery: managing datasets with thousands of features from multiple omic modalities while working with limited patient samples, tracking hundreds of complex experimental permutations, and maintaining version control and traceability for regulatory readiness.The result is a scalable MLOps framework that reduces development iteration time from days to minutes wh
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み