開発の退屈な部分を自動化した方法
CyberAgentの開発チームは、タスクチケットから本番環境対応のプルリクエストまでを自動化するワークフローを構築し、AI成熟度モデルにおけるL3「プロジェクトレベル生成」を達成したと発表した。
キーポイント
AI成熟度モデルL3の実現
CyberAgentが定義するAI成熟度モデルにおいて、L3「プロジェクトレベル生成」(チケットからPR、プロンプトからUIへの自動生成)を達成した実践例を紹介している。
開発ワークフローの完全自動化
タスクチケットを起点に、範囲分析、計画、実装、レビュー、PR作成までの開発サイクル全体をAIで自動化するシステムを構築した。
構造化されたAI活用の重要性
単純にLLMにコードベースへのアクセスを許可するだけでは不十分であり、プロンプト設計の微妙な違いによる出力の不安定性や、複雑なタスクにおけるコンテキスト喪失の問題を解決するために構造化されたワークフローが必要であると指摘している。
開発者の認知的負荷軽減
個々の開発タスクは難しくないが、それらが累積することで生じる認知的負荷と開発速度の低下という問題を、AIによる自動化で解決しようとしている。
影響分析・編集コメントを表示
影響分析
この記事は、AIを単なるコーディング支援ツールとしてではなく、開発プロセス全体を再設計するための基盤として位置づけており、AI活用の新たな段階を示している。実務レベルの自動化事例として、業界全体のAI導入の加速と成熟度向上に影響を与える可能性がある。
編集コメント
AI活用の「成熟度」という概念を具体的な開発プロセスに落とし込んだ実践的な事例であり、単なる技術紹介ではなく、組織的なAI導入のロードマップとして参考になる内容。
実装計画
スコープ分類 [小〜中 / 大]
サブタスク(大スコープのみ)
- サブタスク1の説明
- サブタスク2の説明
実装目標 [達成しようとしていること]
実装アプローチ [技術的アプローチと重要な決定事項]
変更するファイル
| ファイルパス | 変更内容 | 新規/修正 |
|---|---|---|
| path/to/file1 | X機能を追加 | 修正 |
| path/to/file2 | Yを実装 | 新規 |
実装手順
- [手順1の詳細]
- [手順2の詳細]
- [手順3の詳細]
リスクと考慮事項
- [潜在的な問題と緩和策]
- [依存関係と影響範囲]
承認を得る:
これは重要です: ユーザーが計画を承認するまでコーディングを開始しません。
このチェックポイントにより、誤った実装に時間を浪費する前に誤解を捕捉できます。
フェーズ3: 実装
実際にコードを書き、品質チェックを組み込みます:
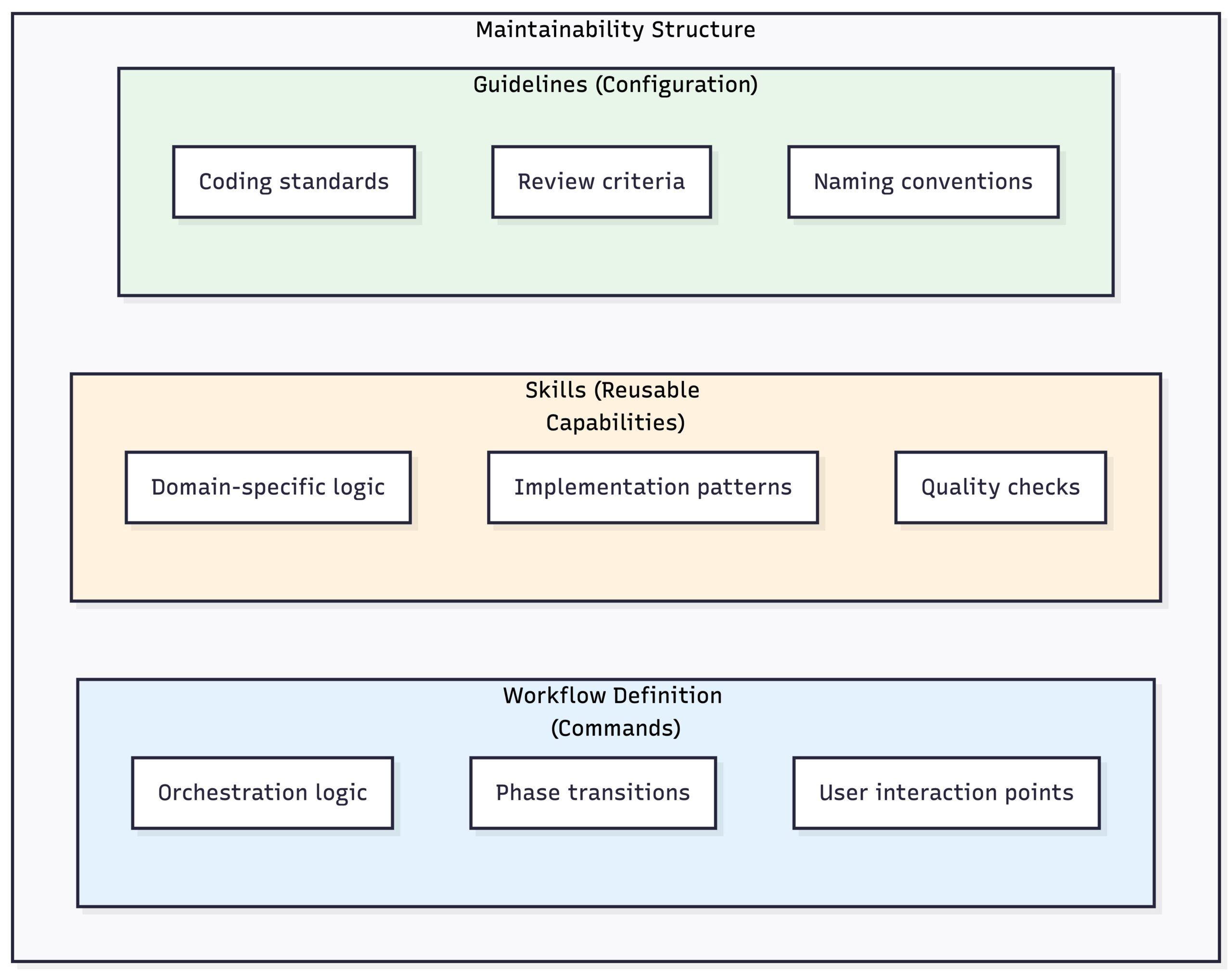
ワークフローはプロジェクト固有のガイドラインを自動的に読み込みます。
フェーズ4: レビューと修正ループ
実装後、レビューサブエージェントがコードをチェックし、見つけた問題を修正します。
フェーズ5: PR(プルリクエスト)の作成
最後に、すべてのドキュメントを含むドラフトPRを作成します。
メトリクス(オプション)
ワークフローは何が起こったかを追跡できます。
ワークフローの洞察
このPRは自動実装ワークフローを使用して作成されました。
セッション概要
| フェーズ | 所要時間 |
|---|---|
| 計画 | X分 |
| 実装 | Y分 |
| レビュー&修正 | Z分 |
| 合計 | N分 |
ユーザー介入
- 計画修正の要求: N回
- レビュー修正の適用: M回
プロセスメモ
- 生成されたサブエージェント: K個
- タスクルーティング: feature-implement / test-implementation
概念実証(Proof of Concept)の結果
異なる複雑さの2つの実際のタスクでこれをテストしました。
ケーススタディ1: E2E(エンドツーエンド)テスト実装
タスク: エンドポイントのE2Eテストを作成。
うまくいった点:
- バリデーションエラーのテストケース
- 認証エラーのテストケース
- 100%ガイドライン準拠
注目すべき瞬間:
- テストタスクとして自動検出
- test-implementationスキルにルーティング
- 自動レビュー中に複数の問題を修正:
- エラーコード修正
- 命名規則修正
- フィクスチャ(fixture)読み込みパターン変更
ケーススタディ2: クロスドメイン(インフラストラクチャ+バックエンド)
タスク: 自動化E2Eテストの環境をセットアップ。
- インフラストラクチャPR
- Terraformインフラストラクチャリソース
- バックエンドのマルチプール検証ロジック
- 後方互換性を維持
注目すべき瞬間:
- 大スコープ(クロスドメイン)として分類
- レビューをクリーンにするため2つのPRに分割
- E2Eテスト実装
- クロスドメイン(インフラストラクチャ+バックエンド)実装
クロスドメインタスクは調査フェーズと2つのPRにわたる複数のレビューサイクルがあったため、よりコストがかかりました。トークン使用量は複雑さに比例して増加します―当然のことです。
参照: Claudeトークン価格設定
このアプローチが機能する理由
新機能の追加:
- スキルモジュールはコアワークフローに触れずに追加可能
- 各スキルは独自のドメインロジックを処理
- 新しいタスクタイプには新しいスキルが必要なだけ
大規模タスクの処理:
- 大規模タスクは自動的にサブタスクに分割
- サブタスクは順次または並列で実行可能
- 保守性が高い
明確な分離:
- コードを変更せずに動作を変更:
- ガイドラインを更新してAIのコード記述方法を変更
- スキルに触れずにレビュー基準を調整
- 新しいパターンを文書化すると即座に適用
より良い開発者体験
以前:
- チケットを手動で読む
- 頭の中で計画し、メモがあちこちに散らばる
- 人間のレビュアーを待つ
- PRテンプレートを手動で記入
- 常にツールを切り替える
現在:
- 構造化された計画、コーディング前の確認
- 即時の自動事前レビュー
- 自動生成された説明
- 一貫した出力
ガイドラインが実際に守られる:
- すべての実装が関連ガイドラインを読み込み
- レビューエージェントが文書化された標準をチェック
- 同じワークフロー=開発者間で同じ標準
予測可能な結果:
- 構造化フェーズ→予測可能な成果物
- Conventional Commits(規約に従ったコミット)→一貫したコミットメッセージ
- テンプレート→大きくばらつかないドキュメント
学んだこと
大きな気づき
- 構造はアドホックなプロンプトより優れています。 ランダムなAI支援はランダムな結果をもたらします。フェーズ、チェックポイント、品質ゲートは信頼性の高い出力をもたらします。
- 人間をループに留めます。 漠然とした監視ではなく、計画優先アプローチは明確な承認チェックポイントを導入します。実行前に計画の人間による検証を要求することで、誤解を早期に特定・修正でき、「あなたは…を意味していると思った」という典型的なシナリオを回避できます。
- スキルは成長の方法です。 再利用可能モジュール内のドメインロジックは、すべてを再構築せずに新しいタスクタイプをサポートできることを意味します。
- 自動レビューは簡単な問題を捕捉します。 人間のレビュアーはリンター(lint)失敗や命名規則違反を指摘する必要がありません。難しい問題に集中できます。
- コスト管理には設計が必要です。 より少ないサブエージェント、ターゲットリンター実行、信頼度ベースのフィルタリング―これらの決定によりトークン使用量を合理的に保ちます。
他にどこで機能するか
このパターンは、以下の開発環境に適合します:
- 読み込んで従える文書化されたガイドラインがある
- タスクが計画、実装、レビューフェーズに分解できる
- 自動化可能な品質ゲート(リンター、テスト、コードレビュー)が存在
- 意思決定ポイントで人間の監視が重要
ポイントは開発者を置き換えることではありません。開発者が面白い問題に集中できるよう、退屈な部分を自動化することです。
私たちのチームの機会
L4/L5に到達するには、「コード生成にAIを使用する」ことから、AIを中心としたシステムをエンジニアリングすることに移行する必要があります:
- ベストプラクティスを構造化スキルにエンコード
- 必須承認チェックポイントを定義
- 客観的な品質ゲートを自動化
- 評価と可観測性をワークフローに組み込み
- コスト、一貫性、正確性を第一級の関心事として扱う
モデル能力だけでなく、オーケストレーション、構造、ガバナンスを解決すれば、L4は現実的になります。規模での調整と自律性を解決すれば、L5が可能になります。
ではこれは何か?
タスクチケットを受け取り、レビュー済みでマージ準備完了のプルリクエストに変換する構造化ワークフローです。AIは機械的な作業―チケットの読み込み、スコープ分析、ガイドラインに従ったコード記述、リンター実行、レビューコメント修正、PR説明生成―を処理します。人間は意思決定ポイントでコントロールを維持します: 実装開始前の計画承認、マージ前の最終レビュー。
開発者にとって、これは退屈な部分に費やす時間が減ることを意味します。チケット詳細の手動解析、リンター実行の忘れ、同じPR説明の定型文記述はもうありません。自動レビューを通過し、チームのパターンに従ったドラフトPRが得られます。
チームにとって、これは一貫性を意味します。ワークフローを使用する全員が同じガイドラインに従ったコード、同じ形式のコミット、同じレベルのドキュメントを含むPRを生成します。新しいチームメンバーは、ワークフローがパターンを自動的に強制するため、より早く生産的になれます。
目標は置き換えではなく増強です。開発者は依然としてアーキテクチャ決定を行い、最終コードをレビューし、人間の判断を必要とする問題を処理します。ワークフローは他のすべてを処理するだけです。






原文を表示
Hey, I’m VuongVu, a backend engineer at CyberAgent Hanoi Dev Center. My main team is AI Business Division – where I mostly work on back-end development for app development for retail companies. I want to share how we built a workflow that takes a task ticket and turns it into a production-ready pull request—hitting AI Maturity level of L3 AI Utilization level in the process.
What’s L3 AI Utilization level?
CyberAgent has this maturity model for AI usage, and L3 is “Project Level Generation”—basically going from a ticket to a PR, or a prompt to a UI. That’s what we were aiming for: automate the full development cycle, but keep humans in the loop where it matters.
The idea is simple: you start with a task ticket (Linear, Jira, whatever), and the AI handles everything—scope analysis, planning, implementation, review, and PR creation.
The Problem We Were Trying to Solve
As projects grow, developers naturally have to juggle many responsibilities. They need to:
Understand existing architectural patterns
Follow coding guidelines
Write and maintain tests
Pass lint and CI checks
Create well-described pull requests
Address review comments
None of these tasks are particularly difficult on their own. However, when combined, they create significant cognitive load and can slow down development:
The challenge is cumulative, not individual. Each step in the development workflow is manageable by itself, but the accumulation of requirements increases friction and reduces development speed.
Best practices are not always obvious. It’s not easy for everyone—especially newcomers—to understand the best practices at each phase of development. Without clear guidance or support, this can lead to uncertainty, inconsistent quality, and additional review cycles.
We’ve tried the usual fixes—docs, code reviews, automation tools. But they don’t talk to each other. You end up with code that passes tests but ignores established patterns, or PRs that reviewers have to guess the context for.
Why Not Just “Use AI”?
LLMs are now capable of understanding and generating code. However, simply granting an AI access to a codebase is not sufficient for reliable results.
Research shows that model behavior can vary significantly based on small changes in prompt wording, leading to inconsistent outputs even when the intent remains the same (Sclar et al., 2023, Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design).
At the same time, real-world software engineering benchmarks demonstrate that resolving multi-file, multi-component issues requires more than raw repository access. Without structured workflows, evaluation, and validation loops, models struggle to maintain context and produce correct solutions (Jimenez et al., 2023, SWE-bench: Can Language Models Resolve Real-World GitHub Issues?).
In practice, using LLMs without structure leads to:
Output variability depending on phrasing
Loss of context across complex tasks
Lack of checkpoints for human validation
Increased token usage and unnecessary costs
These findings suggest that effective AI-assisted development requires structured interaction, evaluation mechanisms, and disciplined workflow design—not just model access.
We built a structured workflow to fix these problems. It takes you from ticket to reviewed draft PR, with human approval at the important decision points.
How the Workflow is Built
Design Principles
Three core principles guided the design of this workflow:
Automation Requires Architecture: Simply “using AI” or pasting code into a chatbot is insufficient for complex engineering tasks. You need a deliberate system: specialized agents (Orchestrator, Planner, Reviewer), modular Skills, and defined phase transitions. Without this architecture, AI output is unpredictable and hard to trust. The workflow itself is the product—not the model.
Human Oversight Is Strategic, Not Mechanical: Not every phase needs a human. The workflow automates the tedious parts—parsing tickets, writing boilerplate, running lint, generating PR descriptions—so developers can focus on the decisions that actually matter: approving the implementation plan and reviewing the final PR. This separation is intentional. Humans intervene at high-leverage checkpoints (plan approval, PR review), while AI handles the repetitive execution in between. The result is a workflow that stays autonomous and stable without sacrificing quality or control.
Consistency Through Structure: A structured workflow ensures that every PR follows the same guidelines, documentation standards, and testing patterns—regardless of which developer initiates it. When phases, templates, and quality gates are built into the system, consistency becomes a property of the process, not a burden on the individual.
The Main Pieces
These principles are realized through the following components:
Main Orchestrator
Runs the show: input handling, phase transitions, user interaction, and coordination
Planning Sub-Agent
Analyzes scope, breaks down into sub-tasks, and writes plans
Spawned for complex analysis
Spawns parallel teammates (backend-dev, frontend-dev, native-dev, test-dev) for multi-domain implementation
Large Scope tasks with 2+ affected domains
Review Sub-Agent
Reviews code, fixes issues
Ticket Integration
Pulls task data, updates status
For external service calls
Domain-specific implementation logic: ticket-lifecycle
feature-implement
Reusable modules
Architecture Overview
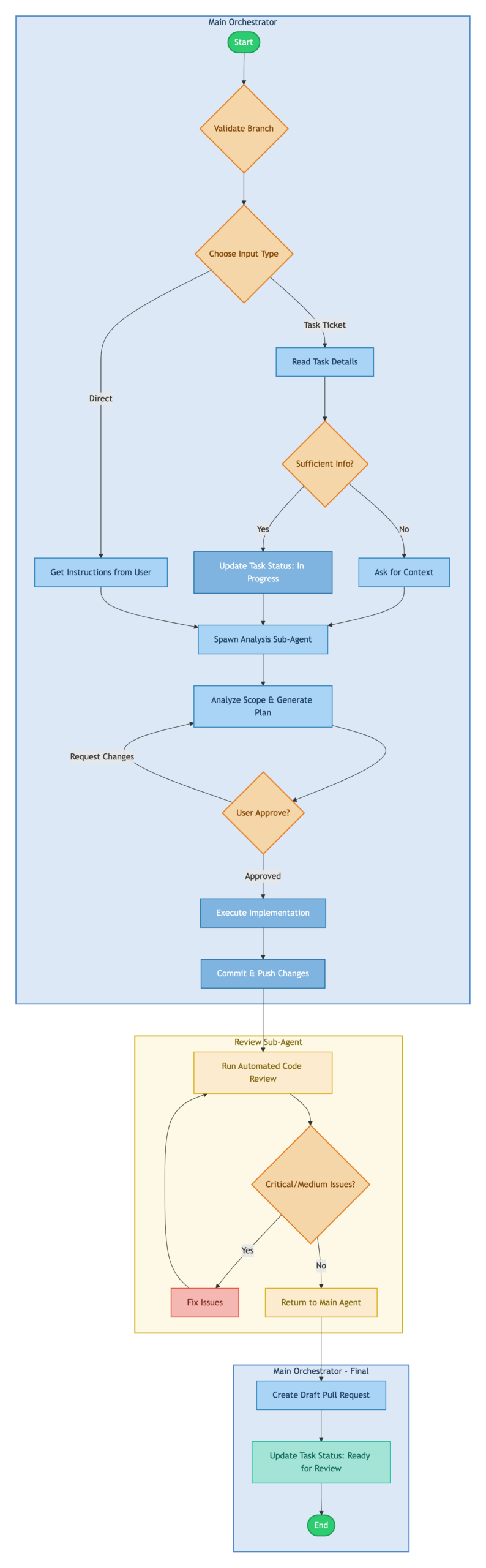
The diagram below illustrates how control flows through the workflow from start to finish. The architecture is divided into three distinct execution contexts, each represented by a colored region:
Main Orchestrator: The primary execution context that handles user interaction, task input processing, and implementation. This is where most of the work happens, maintaining a single coherent context throughout the session.
Review Sub-Agent: A specialized agent spawned after implementation to perform automated code review. It runs independently, iterating through fix cycles until code quality meets the threshold. This separation prevents review logic from polluting the implementation context.
Main Orchestrator – Final: Control returns to the main context for PR creation and status updates, ensuring the user has visibility into the final output.
Skills are modular, self-contained components, each responsible for a specific capability. This design makes every skill an independent and encapsulated unit.
From my experience, I tried using Pull Request review with the implementation agent. However, since the review agent already has context from the implementation phase, it may introduce bias into the review process, leading to reduced objectivity and less critical feedback.
Skill Composition:
A typical feature implementation composes skills sequentially:
scope-analysis → feature-implement → test-implementation → pull-request-review → pull-request-creation
How It Actually Works
Phase 1: Getting the Task
First, we gather info and figure out what kind of task this is.
How ticket should be written:
For the AI agent to work effectively, ticket content needs to be specific and actionable. A well-written ticket should include:
A concise summary of what needs to be done
“Add pagination to user list API endpoint”
Acceptance Criteria
Testable conditions that define “done”
“API returns 20 items per page with next_cursor
Context / Background
Why this task exists and what problem it solves
“Current endpoint returns all users at once, causing timeouts for large datasets”
Scope Boundaries
What is explicitly in-scope and out-of-scope
“In-scope: backend API changes. Out-of-scope: frontend UI updates”
Technical References (optional)
Links to related code, docs, or prior discussions
Avoid vague descriptions like “improve the user page” or “fix the bug”—these force the AI to guess, which leads to wasted cycles and wrong implementations.
Example ticket template:
Title: [Action verb] + [specific target] + [context if needed] ## Background [Why this task exists. Link to related tickets or discussions if applicable.] ## Requirements - [ ] [Specific, testable requirement 1] - [ ] [Specific, testable requirement 2] - [ ] [Specific, testable requirement 3] ## Acceptance Criteria - [Condition that can be verified by test or review] - [Condition that can be verified by test or review] ## Scope - In-scope: [What this ticket covers] - Out-of-scope: [What this ticket explicitly does NOT cover] ## Technical Notes (optional) - Related files: [file paths or module names] - Dependencies: [other tickets or services this depends on] - Constraints: [performance requirements, backward compatibility, etc.]
How we route tasks:
How We Detect It Through Prompt
Test Implementation
“test”, “E2E”, “unit test” in title, or files matching *_test.*
General Implementation
Everything else (features, bugs, refactoring)
feature-implement
Phase 2: Planning
Once we have the task, a sub-agent figures out the scope and builds a plan.
How we classify scope:
We don’t count files or lines of code. We look at functional requirements:
What It Looks Like
How We Handle It
One requirement, one PR, limited blast radius
Single use case change, one admin screen
Implement directly
Multiple requirements, cross-domain, needs staging
API + Backend + Frontend, 3+ domains
Split into subtasks by requirement
The plan template:
Implementation Plan ### Scope Classification [Small-Medium / Large] ### Subtasks (Large Scope only) 1. Subtask 1 description 2. Subtask 2 description ### Implementation Goals [What we're trying to achieve] ### Implementation Approach [Technical approach and key decisions] ### Files to Change | File Path | Change Description | New/Modify | |-----------|-------------------|------------| | path/to/file1 | Add X functionality | Modify | | path/to/file2 | Implement Y | New | ### Implementation Steps 1. [Step 1 details] 2. [Step 2 details] 3. [Step 3 details] ### Risks and Considerations - [Potential issues and mitigations] - [Dependencies and impact areas]
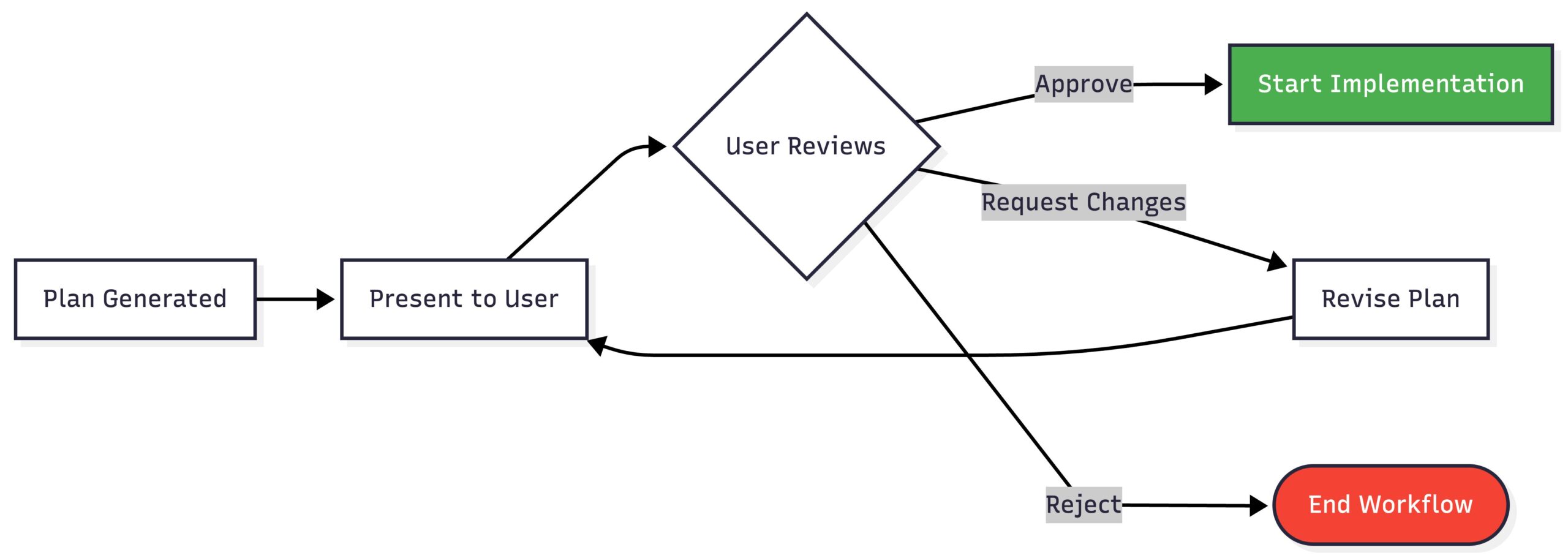
Getting approval:
This is important: we don’t start coding until the user says the plan looks good.
This checkpoint catches misunderstandings before we waste time implementing the wrong thing.
Phase 3: Implementation
Now we actually write code, with quality checks built in:
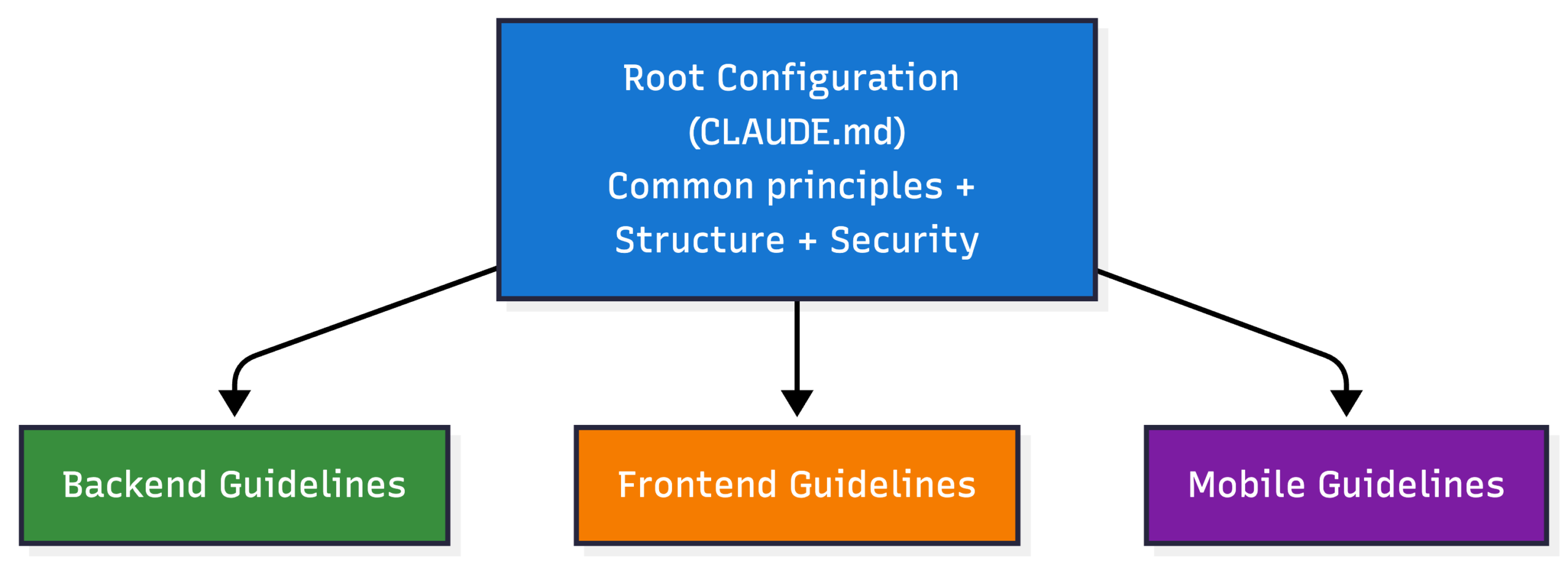
The workflow loads project-specific guidelines automatically:
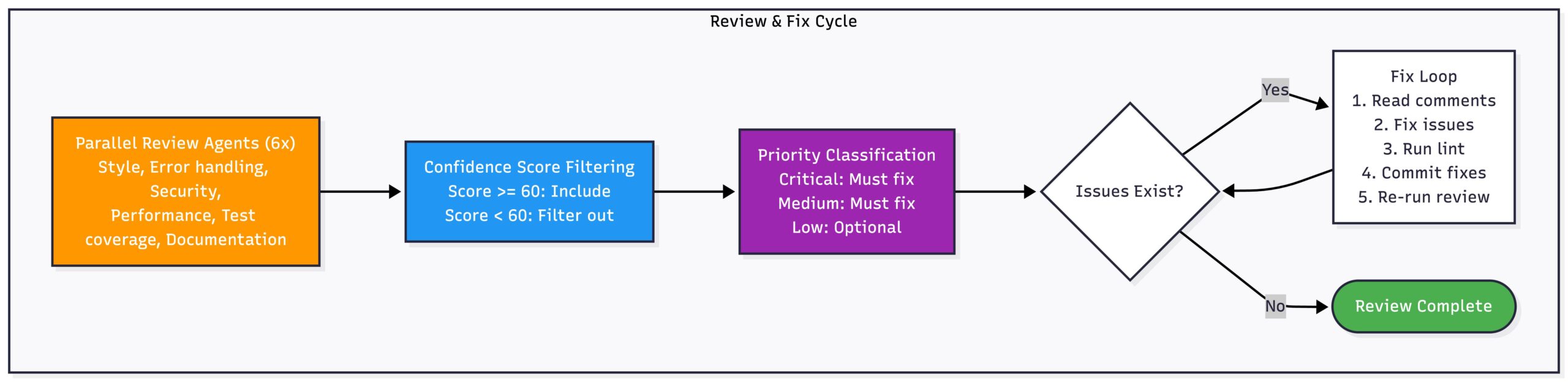
Phase 4: Review and Fix Loop
After implementation, a review sub-agent checks the code and fixes what it finds:
Phase 5: Creating the PR
Finally, we create a draft PR with all the documentation:
Metrics (Optional)
The workflow can track what happened:
Workflow Insights This PR was created using the automated implementation workflow. ### Session Summary | Phase | Duration | |-------|----------| | Planning | X min | | Implementation | Y min | | Review & Fix | Z min | | Total | N min | ### User Interventions - Plan revisions requested: N - Review fixes applied: M ### Process Notes - Sub-agents spawned: K - Task routing: feature-implement / test-implementation
Results from the Proof of Concept
We tested this on two real tasks with different complexity levels.
Case Study 1: E2E Test Implementation
Task: Write E2E tests for an endpoint.
What worked well:
Validation error test cases
Auth error test cases
100% guideline compliance
Notable moments:
Auto-detected as a test task
Routed to the test-implementation skill
Fixed several issues during automated review: Error code corrections
Naming convention fixes
Fixture loading pattern changes
Case Study 2: Cross-Domain Infrastructure + Backend
Task: Set up an environment for automated E2E testing.
Infrastructure PR
Terraform infrastructure resources
Multi-pool verification logic in the backend
Backward compatibility maintained
Notable moments:
Classified as Large Scope (cross-domain)
Split into 2 PRs for cleaner review
E2E Test Implementation
Cross-Domain Infrastructure + Backend
Infrastructure + Backend Implementation:
The cross-domain task cost more because it had an investigation phase and multiple review cycles across two PRs. Token usage scales with complexity—no surprise there.
Ref: Claude Token Pricing
Why This Approach Works
Adding new capabilities:
Skill modules can be added without touching the core workflow
Each skill handles its own domain logic
New task types just need a new skill
Handling big tasks:
Large tasks automatically get split into subtasks
Subtasks can run sequentially or in parallel.
It’s Maintainable
Clear separation:
Change behavior without changing code:
Update guidelines to change how the AI writes code
Adjust review criteria without touching the skill
Document new patterns and they’re immediately applied
Better Developer Experience
Read tickets manually
Plan in your head, notes scattered everywhere
Structured plan, confirmation before coding
Wait for human reviewer
Immediate automated pre-review
Fill out PR templates by hand
Auto-generated descriptions
Switch between tools constantly
Consistent Output
Guidelines actually get followed:
Every implementation loads the relevant guidelines
Review agents check against documented standards
Same workflow = same standards across developers
Predictable results:
Structured phases → predictable artifacts
Conventional Commits → consistent commit messages
Templates → documentation that doesn’t vary wildly
What We Learned
The Big Takeaways
Structure beats ad-hoc prompting. Random AI assistance gives you random results. Phases, checkpoints, and quality gates give you reliable output.
Keep humans in the loop. Rather than vague oversight, the plan-first approach introduces a clear approval checkpoint. By requiring human validation of the plan before execution, misunderstandings can be identified and corrected early — avoiding the classic “I thought you meant…” scenario.
Skills are how you grow. Domain logic in reusable modules means you can support new task types without rebuilding everything.
Automated review catches the easy stuff. Human reviewers don’t have to point out lint failures or naming convention violations. They can focus on the hard problems.
Cost control needs design. Fewer sub-agents, targeted lint runs, confidence-based filtering—these decisions keep token usage reasonable.
Where Else This Could Work
This pattern fits any dev environment where:
You have documented guidelines that can be loaded and followed
Tasks break down into planning, implementation, and review phases
Quality gates exist (lint, tests, code review) that can be automated
Human oversight matters at decision points
The point isn’t to replace developers. It’s to automate the boring parts so developers can focus on the interesting problems.
Our Team’s Opportunity
To reach L4/L5, we must shift from “using AI to generate code” to engineering the system around the AI:
Encode best practices into structured skills
Define mandatory approval checkpoints
Automate objective quality gates
Build evaluation and observability into the workflow
Treat cost, consistency, and correctness as first-class concerns
If we solve orchestration, structure, and governance — not just model capability — L4 becomes realistic. If we solve coordination and autonomy at scale, L5 becomes possible.
So what is this? It’s a structured workflow that takes a task ticket and turns it into a reviewed, ready-to-merge pull request. The AI handles the mechanical work – reading tickets, analyzing scope, writing code that follows your guidelines, running lint, fixing review comments, and generating PR descriptions. Humans stay in control at the decision points: approving the plan before implementation starts, and doing the final review before merge.
For developers, this means less time on the tedious parts. No more manually parsing ticket details, no more forgetting to run lint, no more writing the same PR description boilerplate. You get a draft PR that’s already passed automated review and follows your team’s patterns.
For teams, it means consistency. Everyone using the workflow produces code that follows the same guidelines, commits in the same format, and PRs with the same level of documentation. New team members can be productive faster because the workflow enforces patterns automatically.
The goal is augmentation, not replacement. Developers still make the architectural decisions, review the final code, and handle the problems that need human judgment. The workflow just takes care of everything else.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み