アドバイザリデータベースの内部と脆弱性情報量が記録を更新した際の対応
GitHub は脆弱性情報の爆発的増加により処理能力が限界に達し、レビュー時間の延長と公開目標の未達成を認めた上で、データ品質維持のための利用者への協力を要請している。
キーポイント
脆弱性レポート数の歴史的増大
2026 年 5 月にはレビュー済みアドバイザリーが 1,560 件と過去最高を記録し、プライベート報告や CVE リクエストも前年同期比で数倍に増加した。
処理遅延と公開目標の未達
入力量の急増により、アドバイザリーのレビュー期間が数週間にも延長し、内部の公開目標を一貫して達成できなくなっている状況にある。
データ品質とインフラの健全性維持
処理速度は低下しているものの、データパイプラインや公開されたアドバイザリーの正確性は保たれており、既存アラートも正常に機能している。
利用者への協力の要請
GitHub は、完全な脆弱性情報の提出、メンテナーとの緊密な連携、CVE 発行の明確な意図の確認を求め、コミュニティ全体の責任分担を強調している。
処理能力の限界と複雑性の増加
システム自体には欠陥がないものの、設計されたボリュームを超えたことでスループットが低下しており、特にパッケージの曖昧さやバージョン範囲の再構築など、調査に時間がかかる複雑な案件が増加している。
検証プロセスの厳格性維持
レビュー済みとされる情報は単なる再公開ではなく、エコシステムの特定、バージョン履歴との照合、重複確認などの厳格な検証を経ており、誤報を防ぐためにこのプロセスを省略しない方針である。
データ品質と割り当て率の安定
処理量の急増中も、CVE 割り当て率は 91–94% の高い水準で推移しており、入力データの質や整合性には明らかな劣化は見られない。
影響分析・編集コメントを表示
影響分析
このニュースは、ソフトウェア開発におけるセキュリティインシデント報告が単なる一時的なスパイクではなく、構造的な増大トレンドにあることを示唆しており、開発者コミュニティ全体での報告プロセスの最適化が喫緊の課題であることを浮き彫りにしています。GitHub が公開目標の未達を率直に認め、利用者への協力を要請した点は、セキュリティエコシステムにおける「共有責任」モデルの実践例として業界全体に影響を与える可能性があります。
編集コメント
セキュリティ担当者が直面する現実的なボトルネックを可視化した重要な報告であり、単なる技術発表ではなく、エコシステム全体の運用体制の見直しを促す内容です。
2026 年 5 月、GitHub Advisory Database は 1,560 のレビュー済みアドバイザリを公開しました。これは通常の月間出力の 5 倍以上であり、同データベース史上最高記録です。
それでもなお、追いつくには足りませんでした。
過去数ヶ月にわたり、脆弱性エコシステムは根本的な変化を遂げました。プライベートな脆弱性情報報告、リポジトリアドバイザリ、CVE リクエストにおける入力が増加し、全体として新たな運用規模へと押し上げられています。
本ブログ記事は、脆弱性報告の進化を追跡する GitHub コミュニティ内の継続的な議論、および PVR(Private Vulnerability Report)と Advisory Database のロードマップに関する開発動向を踏まえたものです。そのスレッドで繰り返し指摘されているテーマは、プラットフォームの変更がアドバイザリの選別やデータ品質に与える下流への影響です。これは、脆弱性報告における「品質」と「共有責任」の重視へと移行する GitHub のより広範な動きと一致しており、これが結果としてアドバイザリデータの選別および維持管理の方法を直接的に形作っています。
TL;DR(要約)
新規アドバイザリのレビューにかかる時間は、脆弱性の量と複雑性が大幅に増加したため長くなっています。ただし、アドバイザリの品質に変化はありません:レビュー済みアドバイザリは依然として人間による検証を経ており、既存のアラートも通常通り機能しています。ご支援いただける場合は、以下の 3 点に焦点を当ててください。完全な脆弱性情報の提出、メンテナーおよび研究者との緊密な連携、そして公開する明確な意図がある場合のみ CVE の発行を依頼することです。
記録的な出力と前例のない入力
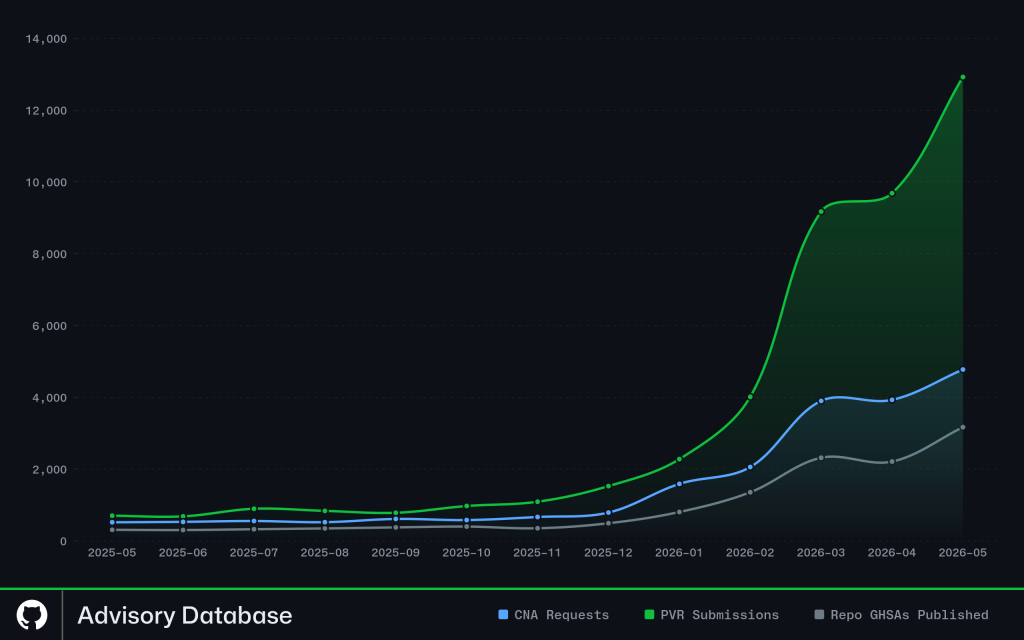
5 月は単発の急増ではありませんでした。3 月から 5 月にかけて、私たちは毎月 6,000 件以上のアドバイザリ決定を維持しました。これには既存のアドバイザリの更新、新しいアドバイザリの公開、および流入するアドバイザリのレビューが含まれ、過去のどの 3 ヶ月のピークも上回りました。
同時に、すべてのソースからの流入が加速しました:
プラットフォーム全体でのプライベート脆弱性レポートは、1 月の週あたり約 550 件から、5 月の大半で週あたり 3,000 件以上に増加しました。
リポジトリアドバイザリは、週あたり約 650 件から 5,000 件以上へと拡大しました。
GitHub CNA CVE リクエストは、5 月だけでほぼ 4,000 件に達し、前年比で約 10 倍となりました。
CVE プログラムはすでに 2026 年に 30,000 件以上の CVE を公開しています。
プライベート脆弱性レポート機能を有効にしたリポジトリの総数は 170 万件を超えています。
これは局所的な急増ではありません。これは脆弱性開示エコシステム全体における構造的変化を反映しています。
影響
4 月中旬以降、この急増により、私たちは公開に関する内部目標を一貫して達成できていませんでした。処理時間はまず約 1 週間となり、その後、意味のある割合で数週間に延びました。公開までの時間が長くなると、曝露期間(エクスポージャーウィンドウ)が増加する可能性があります。私たちはこれを深刻に受け止めており、迅速性は本データベースが提供する価値の核心的な一部です。
まだ機能していること
当社のデータパイプラインと公開インフラは、この期間を通じて稼働を続けています。インポートは実行され、データの整合性は保たれており、公開されたアドバイザリも正確です。本日レビュー済みステータスに達したアドバイザリは、以前と同じ品質基準を満たしています。
CVE 割当の質は依然として高い水準を維持しています。割当率は今回の急増期間中を通じて 91〜94% の範囲で推移しており、これは過去の規範と同等かそれ以上に良好であり、受け取るリクエストに明確な劣化が生じていないことを示しています。
問題はスループットにあります。アドバイザリデータを検証し、拡張し、公開するシステムは機能していますが、現在はその設計上の処理能力を超えた量と複雑さに直面して稼働しています。
作業の均一性はない
すべてのセキュリティアドバイザリが同じレベルの労力を必要とするわけではありません。一部のアドバイザリは良好なフォーマットで到着します。詳細には影響を受けるパッケージとその関連エコシステムが明確に記載され、バージョン範囲も文書化されており、修正箇所もタグ付けされています。キュレーターであれば、これらを数分以内に検証して公開できます。
しかし、増加する割合の incoming advisories(着信アドバイザリ)では、より多くの調査が必要です:
パッケージの曖昧さ解消。アドバイザリの詳細には「foo」と記載されているものの、それが npm 上の foo なのか、PyPI 上の python-foo なのか、それとも Maven 上の無関係な foo なのかを特定する必要があります。上位ソースデータでエコシステムが指定されていない場合、キュレーターがこれを判別します。
バージョン範囲の再構築。多くのセキュリティアドバイザリには影響を受けるバージョン範囲が含まれていないか、実際のリリース履歴と一致しない範囲が記載されています。キュレーターはコミット、変更ログ、タグを追跡して、実際に影響を受けている部分を特定します。
マルチエコシステム向けアドバイザリ。一部のプロジェクトでは、同じ機能を持つライブラリの.NET実装(NuGet)とJavaScript実装(npm)など、複数のレジストリにパッケージを配布しています。共有ロジカルに脆弱性がある場合、両方に影響が及びます。これには複数のデータソースにわたる独立した検証が必要です。
競合する上位元データの存在。CVEレコード、メンテナによるアドバイザリ、コミット履歴の間で、何が影響を受けるかについて不一致が生じる場合があります。その場合、誰かが真実を確定する必要があります。
歴史的にはより単純なアドバイザリが主流であり、困難なものは吸収可能でした。しかし、件数が急増すると、キューに両方が混在し、複雑なものほど不均衡に長い時間を要するようになり、複合的な影響が生じます。現在ではその混合比率が非常に重要になっています。これは単なる作業量の増加ではなく、著しく複雑化していることを意味します。
「レビュー済み」の真の意味
レビュー済みのアドバイザリとは、単なる再公開された記録ではありません。それは検証の結果です。
キュレーターは以下の作業を行います:
- 脆弱性を正しいエコシステムのパッケージにマッピングする
- 影響を受けるバージョンと修正されたバージョンをリリース履歴に対して検証する
- 上位元の情報の正確性を確認する
- 重複や整合性の有無をチェックする
- 分類とスコアリングを検証する
これにより、下流のツールが追加検証なしでこのデータを信頼できるようになります。
検証をスキップして公開速度を上げると、大規模な誤検知が増加し、遅延よりもむしろリスクが高まる可能性があります。
生態系全体の変革
この傾向は GitHub だけに留まりません。
報告され、公開された脆弱性の数は急速に増加し続けており、生態系全体の組織がこの変化に適応しています。
システムは設計通りに機能しています。これまでにない数の脆弱性が報告され、開示され、追跡されています。これが、アドバイザリキュレーションの過程を含む下流のプロセスに圧力をかけています。
現在私たちが行っていること
コミュニティからの貢献の質とスループットの向上です。コミュニティからの貢献は、Advisory Database(アドバイザリデータベース)を改善する上で重要な要素であり、すべての貢献は他のどのアドバイスと同様の検証基準に対してレビューされます。私たちはトリアージと優先順位付けを強化し、高品質な提出物が早期に特定され、一貫してレビューされ、キューをより迅速に通過できるようにしました。これにより、現在のボリュームに対応しつつ、高品質で信頼性の高いデータセットを維持するという主要な目標を強化しています。
キュレーションを支えるシステムの拡張です。バックエンドのキュレーションシステムの容量の一部を増強し、持続的なスループットの高さに対応可能にし、分析やキュー管理をサポートするデータインフラストラクチャの近代化も継続して行っています。
AI を活用した研究ツールの構築。私たちは、アドバイザリレビューの研究フェーズにおいてキュレーターに AI による支援を提供するツールを開発・導入しました。すべての決定は依然としてキュレーターが行いますが、定型の研究作業をより迅速に完了させることで、高品質なアドバイザリの作成が可能になります。
最も効果的な分野での自動化の拡大。私たちは、上位 CVE 情報からより多くのデータを抽出するための自動化や、コミュニティからの貢献が既にレビュー済みのアドバイザリとどのように相互作用するかを処理する仕組みを改善しました。この取り組みにより、意思決定にかかる時間を短縮しつつ、品質基準を低下させることなく実現しています。
ドキュメントとトレーニングへの投資。私たちは運用ドキュメントを大幅に拡充しました。これにより、新しいチームメンバーのオンボーディングを迅速化し、チーム全体での一貫性を向上させています。
今後構築するもの
この新たなスケールに対応するため、私たちは以下の分野に投資を行っています:
最も一般的なケースにおける 1 アドバイザリあたりの所要時間の削減。流入するアドバイザリの多くは、適切なパッケージの特定、バージョン範囲の確認、修正の有無の確認など、予測可能なパターンに従った研究を必要とします。私たちはこれらのパターンを加速させるツールに投資しており、キュレーターが人間の判断を要する真に曖昧なケースに時間を割けるようにしています。
リスクベースのレビュー優先順位付けの高度化。パッケージの使用状況、積極的な悪用の実証、エコシステムへの影響など、追加のリスクシグナルを活用して優先順位付けを行うことを検討しており、最も重要なアドバイザリがまずユーザーに届くようにします。
アップストリームデータソースとのフィードバックループの改善。キュレーション時間の大きな割合は、不完全または不正確なアップストリームデータの修正に費やされています。私たちは、特にリポジトリ GitHub Security Advisory および Private Vulnerability Reporting データの検証を強化することで、取り込むソースとの統合をより緊密にするよう投資を行っており、データ品質の問題がレビューキューではなく発生源に近い段階で解決されるようにしています。
透明性を継続して維持します。進捗があるたびに更新情報を共有していきます。状況が改善すればその旨をお伝えし、新たな課題に直面した際も同様にお知らせいたします。
これがあなたにとって何を意味するか
Dependabot ユーザー:既存の警告は影響を受けません。新しいアドバイザリがトリガーされるまで時間がかかる場合がありますが、重大な問題は優先されます。
API およびフィード利用者:レビュー済みのデータは正確に維持され、未レビューのアドバイザリは表示されますが、まだ検証されていません。
メンテナー:リポジトリアドバイザリは引き続きグローバルデータベースへ流れます。優先順位付けは、プロジェクトへの影響や深刻度など複数の要因に基づいて行われます。
あなたが協力できること
脆弱性情報レポートには完全なデータを含めてください。影響を受けるバージョン範囲、根本原因、明確な再現手順を提供することは、アドバイザリがどの程度迅速かつ正確にレビューされるかに直接的な違いをもたらします。このデータが完全であれば、キュレーションは数分で完了します。しかし不完全な場合、キュレーターはソースコード、リリース履歴、矛盾するアップストリームのシグナルから欠落した詳細を再構築しなければなりません。この規模では、これらのギャップはすぐに蓄積されます。高品質なアップストリームデータは、エコシステム全体の速度と精度の両方を改善するための最も効果的な方法の一つです。
適切なアドバイザリ詳細を含めてください。ベストプラクティスガイドにはエコシステムの分類、パッケージ名、バージョン範囲のフォーマットが記載されていますが、さらにいくつかの詳細を追加することで、GitHub Advisory Database へのレビューおよび公開の迅速さと正確性に直接的な違いが生じます。
レジストリに表示される通りのパッケージ名を使用してください。アドバイザリのパッケージ名は、リポジトリやプロジェクト名ではなく、必ずレジストリと一致させる必要があります。ダウンストリームシステムは、アドバイザリを影響を受ける依存関係にマッチングさせるためにレジストリ識別子に依存しています。名前が誤っているか欠落している場合、アラートを確実に生成できず、影響を受けるユーザーが通知されない可能性があります。レジストリ名を使用することで、アドバイザリを正しくリンクし、インデックス付けし、配布することが可能になります。
影響を受けるすべてのパッケージをリストアップしてください。一部の脆弱性は、プロジェクト内の複数のパッケージに影響を与える可能性があります。各影響を受けるパッケージは、それぞれのエコシステム、パッケージ名、バージョン範囲とともに個別にリストする必要があります。アドバイザリはパッケージレベルで処理されるため、1 つでもパッケージを見落とすと、その依存関係にあるユーザーへの通知も漏れてしまいます。既知の影響を受けるすべてのパッケージを含めることで、カバー率が向上し、影響を受けたすべてのユーザーにアラートが届くことが保証されます。
完全な CVSS ベクトル文字列を提供してください。GitHub Advisory Database は CVSS 3.1 および 4.0 をサポートしています。「High」などの深刻度ラベルは簡潔な要約ですが、完全な CVSS ベクトル文字列には、攻撃の複雑さ、必要な権限、ユーザーの相互作用など、脆弱性をより詳細に記述する属性が豊富に含まれています。この構造化された情報により、深刻度の検証が可能になり、一貫した解釈が行われ、下流のツールによる優先順位付けや自動化に活用できます。これがない場合、スコアリングは精度が低下し、アドバイザリ間での比較が困難になります。スコアを含める場合は、公式の計算機を使用し、完全なベクトルを含めてください。
関連する CWE(Common Weakness Enumeration)分類を含めてください。CWE は、クロスサイトスクリプティング、SQL インジェクション、信頼できないデータのデシリアライズなど、脆弱性の背後にある根本的な欠陥を特定します。物語形式の説明とは異なり、CWE は下流のツールやセキュリティチームに対して、取り扱っている問題の種類を理解するための標準化された方法を提供します。これは重要です。なぜなら、CWE データは、大規模なデータセット全体で脆弱性を分類、フィルタリング、優先順位付け、比較するために使用できるからです。これにより、組織は関連する問題をグループ化し、ポリシーや報告ルールを適用し、自社のソフトウェアに影響を与える脆弱性のパターンを理解することができます。CWE が具体的であればあるほど、下流の消費者にとってそのアドバイザリはより有用になります。
詳細なガイダンスについては、明確で完全なセキュリティアドバイザリの作成に関するベストプラクティスをご覧ください。
CVE(Common Vulnerabilities and Exposures)の要求には意図を持って臨んでください。CVE ID の要求は、脆弱性が公開され追跡されることを示すものです。公開する計画がないまま CVE を要求すると、実際にリリースに向けて進行中のアドバイザリから時間と注意がそらされてしまう可能性があります。明確な公開意図と整合性のある CVE 要求を行うことで、努力が最も即座に影響力を持つ場所に集中し、システムをすべての関係者に対して応答性の高い状態に保つことができます。
メンテナーや他の研究者と密接に連携してください。高品質なアドバイザリデータは、共有された文脈に依存します。影響を受けるパッケージ、バージョン範囲、および修正策を整合させることは、ソース間での曖昧さや矛盾する情報を減らすのに役立ちます。この規模では、連携における小さな隙間が、下流で大きな不整合として現れる可能性があります。
アドバイザリデータベースに対してプルリクエストを投稿することで、アドバイザリの品質向上に貢献してください。バージョン範囲、パッケージマッピング、または修正策に対するあらゆる修正は、開発者が依存する精度を高めるものです。
このエコシステムの変化の規模を認識し、その一員として参加してください。脆弱性報告数の増加は、実際の進歩を反映しています。これまで以上に多くの問題が発見され、修正され、公開されています。この規模で品質を維持するには、研究者、メンテナー、データ消費者およびプロデューサーが同じ目標に向かって協力することが不可欠です。
大きな視点
2 年前、データベースでは月間約 270 のアドバイザリが公開されていました。
2026 年 5 月には、システム全体で数千の追加決定を処理しながら、1,500 を超えるアドバイザリが公開されました。
これはより広範な変化を反映しています:
- 責任ある開示を可能にするリポジトリが増えています。
- 脆弱性を報告する研究者が増えています。
- 修正策とアドバイザリを公開するメンテナーが増えています。
脆弱性エコシステムは、より高い透明性へとスケールしようとしています。
この成長は、私たちのようなシステムに圧力をかけます。しかし同時に、意味のある進歩を表しています。
すべてのアドバイザリが可視性を高め、すべてのアラートがリスクを低減します。
私たちはその現実に対応するために規模を拡大しており、進捗状況についても引き続き共有していきます。
「アドバイザリデータベースの内部と脆弱性数が記録を更新した際に何が起こるか」という投稿は、最初に The GitHub Blog で公開されました。
原文を表示
In May 2026, the GitHub Advisory Database published 1,560 reviewed advisories—more than five times our typical monthly output and the highest in its history.
And it still wasn’t enough to keep up.
Over the past few months, the vulnerability ecosystem has shifted in a fundamental way. Input across private vulnerability reports, repository advisories, and CVE requests has increased simultaneously, pushing the entire system to a new operating scale.
This blog builds on an ongoing GitHub community discussion tracking the evolving nature of vulnerability reporting, as well as PVR and Advisory Database roadmap developments. A recurring theme in that thread is the downstream impact of platform changes on advisory curation and data quality. This aligns with GitHub’s broader shift toward emphasizing quality and shared responsibility in vulnerability reporting, which in turn directly shapes how advisory data must be curated and maintained.
TL;DR
Review times for new advisories are longer because vulnerability volume and complexity have increased significantly. Advisory quality has not changed: reviewed advisories are still human-validated, and existing alerts continue to function normally. If you want to help, focus on three things: submit complete vulnerability data, coordinate closely with maintainers and researchers, and request CVEs only when there is a clear intention to publish.
Record output and unprecedented input
May was not a one-time spike. From March through May, we sustained more than 6,000 advisory decisions per month. This included updating existing advisories, publishing new advisories, and reviewing inbound advisories, and exceeded any prior three-month peak.
At the same time, inflow accelerated across every source:
Private vulnerability reports across the platform increased from ~550/week in January to more than 3,000/week for most of May.
Repository advisories scaled from ~650/week to more than 5,000/week.
GitHub CNA CVE requests reached almost 4,000 in May alone, nearly 10x year –over year.
The CVE program has already published 30,000+ CVEs in 2026.
More than 1.7 million total repositories have enabled private vulnerability reporting.
This is not a localized surge. It reflects structural change across the vulnerability disclosure ecosystem.
The impact
Since mid-April, due to this surge, we have not consistently met our internal goals for publication. Processing times extended first to about a week, then to multiple weeks for a meaningful share. Longer publication times can increase exposure windows. We take that seriously, and timeliness is a core part of the value this database provides.
What’s still working
Our data pipelines and publishing infrastructure have continued to operate through this period. Imports are running, data integrity is intact, and published advisories are accurate. Advisories that reach reviewed status today meet the same quality standard as before.
CVE assignment quality has remained strong. Our assignment rate has held between 91–94% through the entire surge, consistent with or better than historical norms and showing that there hasn’t been a clear degradation in the requests we receive.
The issue is throughput. The system that validates, enriches, and publishes advisory data is functioning; it is now operating beyond the volume and complexity it was designed to handle.
The work isn’t uniform
Not every security advisory requires the same level of effort. Some arrive well formatted: the advisory details clearly name the affected package and its relevant ecosystem, the version range is documented, and the fix is tagged. A curator can validate and publish these in under a few minutes.
But a growing share of incoming advisories require more investigation:
Package disambiguation. The advisory details say “foo”, but is that foo on npm, python-foo on PyPI, or the unrelated foo on Maven? When upstream data doesn’t specify an ecosystem, our curators figure it out.
Version range reconstruction. Many security advisories arrive with no affected version range, or with ranges that don’t match actual release history. Curators trace commits, changelogs, and tags to determine what’s actually affected.
Multi-ecosystem advisories. Some projects ship packages to multiple registries, like a library with both a .NET implementation (NuGet) and a JavaScript implementation (npm) of the same functionality, where a vulnerability in the shared logic affects both. This requires independent verification across multiple data sources.
Conflicting upstream data. When the CVE record, the maintainer’s advisory, and the commit history disagree about what’s affected, someone has to determine the truth.
Historically more straightforward advisories dominated, and the harder ones could be absorbed. When volume surges, the queue fills with both, and the complex ones take disproportionately longer, creating a compounding effect. The mix now matters much more. This isn’t just more work; it’s significantly more complex.
What “reviewed” actually means
A reviewed advisory is not simply a republished record; it’s the result of verification.
Curators:
Map vulnerabilities to the correct ecosystem package
Validate affected and fixed versions against release history
Confirm upstream accuracy
Check for duplication and consistency
Validate classification and scoring
This is what allows downstream tools to rely on the data without additional validation.
Publishing faster by skipping verification would increase false positives at scale, which can create more risk than delay.
A broader ecosystem shift
This trend extends beyond GitHub.
The volume of reported and published vulnerabilities continues to grow rapidly, and organizations across the ecosystem are adapting to that change.
The system is working as designed. More vulnerabilities are being reported, disclosed, and tracked than ever before. That creates pressure downstream, including during advisory curation.
What we’re doing now
Improving community contribution quality and throughput. Community contributions are an important part of how we improve the Advisory Database, and each is reviewed against the same validation standard as any other advisory. We’ve strengthened triage and prioritization, so high-quality submissions are identified earlier, reviewed more consistently, and moved through the queue faster. This helps us respond to current volume while reinforcing our primary goal of maintaining a high-quality, trusted dataset.
Scaling the systems behind curation. We’ve increased aspects of the capacity of our backend curation systems to handle higher sustained throughput and we’re continuing to modernize the data infrastructure that supports analytics and queue management.
Building AI-assisted research tools. We’ve developed and deployed tooling that gives our curators AI-powered assistance during the research phase of advisory review. Curators still make every decision, but routine research can be completed faster for higher quality advisories.
Expanding automation where it helps the most. We’ve improved automation for extracting more data from upstream CVE information and for handling how community contributions interact with already-reviewed advisories. That work reduces time per decision without lowering the quality bar.
Investing in documentation and training. We’ve significantly expanded our operational documentation. This enables us to bring new team members up to speed faster and improves consistency across the team.
What we’re building next
To support this new scale, we are investing in:
Reducing time-per-advisory for the most common cases. A significant portion of incoming advisories require research that follows predictable patterns, such as identifying the correct package, confirming the version range, and checking for a fix. We’re investing in tooling that accelerates these patterns, so curators can spend their time on genuinely ambiguous cases that require human judgment.
Making risk-based review prioritization smarter. We’re exploring additional risk signals for prioritization, such as package usage, evidence of active exploitation, and ecosystem impact to ensure the advisories that matter most reach users first.
Improving the feedback loop with upstream data sources. A significant share of curation time is spent correcting incomplete or inaccurate upstream data. We’re investing in tighter integration with the sources we ingest from, especially through increased repository GitHub Security Advisory and Private Vulnerability Reporting data validation, so that data quality issues get resolved closer to the origin rather than in our review queue.
Continuing to be transparent. We’ll share updates on our progress as we make it. If things improve, we’ll tell you. If we hit new challenges, we’ll share that too.
What this means for you
Dependabot users: Existing alerts are unaffected. New advisories may take longer to trigger, with critical issues prioritized.
API and feed consumers: Reviewed data remains accurate; unreviewed advisories are visible but not yet validated.
Maintainers: Repository advisories continue to flow into the global database; prioritization is based on several factors, including project impact and severity.
How you can help
Include complete data in vulnerability reports. Providing affected version ranges, root cause, and clear reproduction steps makes a direct difference in how quickly and accurately advisories can be reviewed. When this data is complete, curation can take minutes. When it isn’t, curators must reconstruct missing details from source code, release history, and conflicting upstream signals. At this scale, those gaps compound quickly. High-quality upstream data is one of the most effective ways to improve both speed and accuracy across the ecosystem.
Include the right advisory details. Our best practices guide covers ecosystem categorization, package names, and version range formatting, but a few additional details make a direct difference in how quickly and accurately advisories can be reviewed and published to the GitHub Advisory Database.
Use the package name as it appears in the registry. Advisory package names must match the registry, not the repository or project name. Downstream systems rely on registry identifiers to match advisories to affected dependencies. If the name is incorrect or missing, alerts cannot be reliably generated, and affected users may never be notified. Using the registry name ensures the advisory can be correctly linked, indexed, and distributed.
List all affected packages. Some vulnerabilities impact multiple packages within a project. Each affected package should be listed separately with its own ecosystem, package name, and version range. Advisories are consumed at the package level, so missing a package means missing the users who depend on it. Including all known affected packages improves coverage and ensures alerts reach the full set of impacted users.
Provide a complete CVSS vector string. The GitHub Advisory Database supports CVSS 3.1 and 4.0. A severity label such as “High” is a quick summary, but a complete CVSS vector string includes a richer set of attributes, such as attack complexity, required privileges, and user interaction, which describe the vulnerability in greater detail. This structured information allows severity to be validated, interpreted consistently, and used by downstream tools for prioritization and automation. Without it, scoring is less precise and harder to compare across advisories. If you include a score, use the official calculators and include the full vector.
Include relevant CWE classification. A CWE identifies the underlying weakness behind a vulnerability, such as cross-site scripting, SQL injection, or deserialization of untrusted data. Unlike a narrative description, a CWE gives downstream tools and security teams a standardized way to understand what kind of issue they are dealing with. That matters because CWE data can be used to categorize, filter, prioritize, and compare vulnerabilities across large datasets. It helps organizations group related issues, apply policy or reporting rules, and understand patterns in the vulnerabilities affecting their software. The more specific the CWE, the more useful the advisory becomes for downstream consumers.
For more guidance, see the best practices for writing clear, complete security advisories.
Be intentional when requesting CVEs. Requesting a CVE ID signals that a vulnerability will be disclosed and tracked publicly. When requests are made without plans to publish, it can divert time and attention from advisories that are actively moving toward release. Aligning CVE requests with clear publication intent helps ensure that effort is focused on where it has the most immediate impact and keeps the system responsive for everyone.
Coordinate closely with maintainers and other researchers. High-quality advisory data depends on shared context. Aligning affected packages, version ranges, and fixes helps reduce ambiguity and conflicting information across sources. At this scale, small gaps in coordination can become large inconsistencies downstream.
Improve advisory quality by contributing pull requests to the Advisory Database. Every correction to version ranges, package mappings, or fixes improves the accuracy that developers rely on.
Recognize the scale of this ecosystem shift and take part in it. The increase in vulnerability reporting reflects real progress. More issues are being found, fixed, and disclosed than ever before. Maintaining quality at this scale depends on researchers, maintainers, and data consumers and producers working together toward the same goal.
The bigger picture
Two years ago, the database published ~270 advisories per month.
In May 2026, it published over 1,500 while processing thousands of additional decisions across the system.
This reflects a broader shift:
More repositories are enabling responsible disclosure.
More researchers are reporting vulnerabilities.
More maintainers are publishing fixes and advisories.
The vulnerability ecosystem is scaling toward greater transparency.
That growth creates pressure on systems like ours. But it also represents meaningful progress.
Every advisory improves visibility. Every alert reduces risk.
We are scaling to meet that reality, and we will continue to share progress as we do.
The post Inside the Advisory Database and what happens when vulnerability volume breaks records appeared first on The GitHub Blog.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み