AsgardBench: 視覚に基づく対話型計画のためのベンチマーク
Microsoft Researchは、視覚的観察に基づいて計画を適応させる能力を評価するためのベンチマーク「AsgardBench」を発表し、具体的な家庭内タスク108インスタンスを通じて、エンボディードAIエージェントの計画適応能力を分離して測定する手法を提案した。
キーポイント
計画適応能力の分離評価
AsgardBenchは、ナビゲーションや物体操作などの他の能力から切り離し、視覚的フィードバックに基づいて計画を修正する能力(計画適応)に特化して評価するベンチマークである。
視覚的接地とインタラクティブ計画
エージェントは環境を画像で観察し、予想と実際の観察が矛盾する場合に計画を調整できるかどうかが評価される。例えば、洗うべきマグカップが既に清潔である場合に適切に行動を変更できるかが問われる。
制御された多様なタスク環境
AI2-THORシミュレーション環境上に構築され、12種類のタスクタイプ、108の制御されたタスクインスタンスを提供し、同じ指示でも物体の位置や状態(清潔/汚れなど)によって異なる行動シーケンスが必要となる。
実践的な家庭内タスクのシナリオ
キッチンの掃除などの日常的な家庭内タスクを題材とし、エージェントはfind、pickup、put、clean、toggle_on/offなどの限られたアクションセットを使用してタスクを遂行する。
ベンチマークの仕組み
エージェントは各ターンで完全なステップシーケンスを提案するが、最初のステップのみ実行され、新しい画像と成功/失敗のシンプルなフィードバックを受け取ることで、計画の再評価と修正を強制される。
評価結果の主要な知見
視覚入力を与えられたモデルは、テキストのみの記述と比較して成功率が2倍以上向上し、ベンチマークが視覚的接地を必要とすることが示された。
エージェントの主要な弱点
現在のエージェントは、視覚的詳細の識別、タスク進捗の追跡、計画の適時更新において一貫して課題があり、これらが実世界環境での適応を妨げている。
影響分析・編集コメントを表示
影響分析
この研究は、エンボディードAIの評価方法論に重要な貢献をしており、単なるタスク完了率ではなく、環境変化への適応能力という本質的な知能を測定する枠組みを提供する。これにより、よりロバストで実用的なAIエージェントの開発が促進され、家庭用ロボットなどの実世界応用への道筋が明確になる。
編集コメント
エンボディードAI研究の重要な進展として、評価手法の革新に焦点を当てた点が注目される。実世界の不確実性に対応できるAI開発に向け、基礎研究と実用化の橋渡しとなる研究と言える。

概要
タスクを成功裏に完了するためには、身体性AI(embodied AI)エージェントは視覚的フィードバックに基づいて計画を接地(ground)し、更新しなければなりません。
AsgardBenchは、タスクが進行するにつれてエージェントが視覚的観察を用いて計画を修正できるかどうかを純粋に評価します。
12のタスクタイプにまたがる108の制御されたタスクインスタンスからなるこのベンチマークは、エージェントが観察した内容に基づいて計画を適応させることを求めます。
オブジェクトが異なる位置や状態(例:清潔または汚れている)にある可能性があるため、同じ指示でも、同じ環境内であっても異なるアクションシーケンスが必要になる場合があります。
本文
キッチンを掃除する任務を負ったロボットを想像してみてください。ロボットは環境を観察し、何をすべきかを決定し、例えば洗うように指示されたマグカップがすでにきれいだったり、シンクが他の物でいっぱいだったりするなど、事態が予想通りに進まないときに調整する必要があります。これが身体性AI(embodied AI)の領域です:環境を認識(perception)し、その中で行動するシステムです。
この分野は急速に進歩していますが、これらのシステムを評価することは見た目よりも困難です。多くのベンチマークは、知覚(perception)、ナビゲーション、物理的制御を一度にテストするため、AIエージェントが実際に知覚したものを用いてより良い決定を下しているのか、それとも環境が十分に予測可能で事前のスクリプトで対応できるために単に運が良かっただけなのかを切り分けることが難しくなります。
この問題に対処するために、私たちはAsgardBenchを作成しました。論文「AsgardBench — Evaluating Visually Grounded Interactive Planning Under Minimal Feedback」では、このベンチマークがどのようにしてシンプルだが要求の厳しい課題を提示するかを説明しています:AIエージェントに家庭内タスクを与え、画像を通じて環境を観察させ、知覚したものが予想と矛盾するときに計画を調整できるかどうかを確認します。洗う必要があるマグカップがすでにシンクにあることに気づけるか、あるいはそうでない場合にそれに応じて行動できるか?これがAsgardBenchが答えようとしている核心的な問いです。
家庭内タスクでAIエージェントを訓練・評価するために使用されるインタラクティブな3Dシミュレーション環境であるAI2-THOR上に構築されたAsgardBenchは、エージェントをオブジェクトの近くに配置し、find、pickup、put、clean、toggle_on/offといった、限られた固定のアクションセットを与えます。各ターンで、エージェントはタスクを完了するための完全なステップシーケンスを提案しますが、実行されるのは最初のステップのみです。全体を通して、焦点は計画適応(plan adaptation)に厳密に当てられており、エージェントが部屋を移動したりオブジェクトを操作したりできるかどうかではなく、知覚したものを用いて次のステップを修正できるかどうかが問われます。
例えば、エージェントはマグカップが清潔、汚れている、またはコーヒーで満たされていることを発見したり、シンクに他の多くの物が入っていることを観察したりするかもしれません。したがって、同じ指示でも、タスクが進行するにつれて異なるアクションシーケンスが必要になる場合があります。このプロセスは図1に示されています。
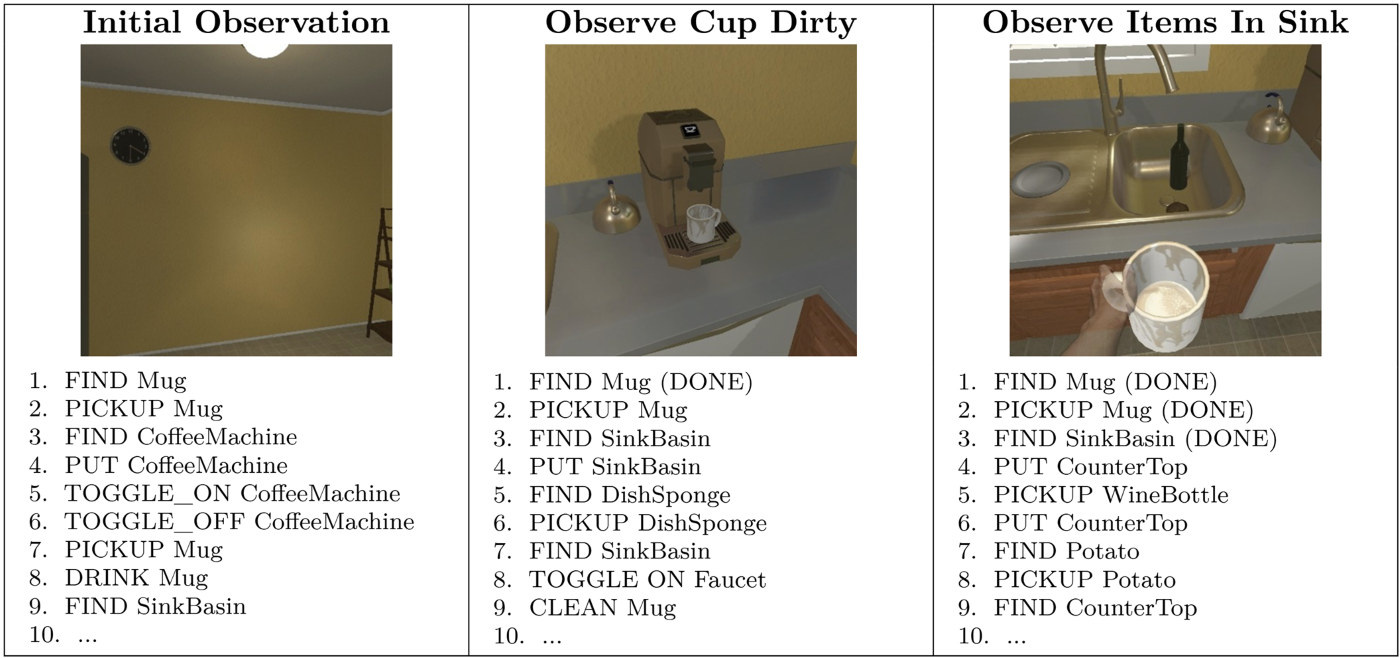 image図1: AsgardBenchにおけるエージェントの観察と対応するアクションプラン。各画像はその観察から生成された計画とペアになっています。これは、AsgardBenchがエージェントに固定されたシーケンスに従うのではなく、新しい視覚的証拠に基づいて計画を更新または変更することを求める方法を示しています。
image図1: AsgardBenchにおけるエージェントの観察と対応するアクションプラン。各画像はその観察から生成された計画とペアになっています。これは、AsgardBenchがエージェントに固定されたシーケンスに従うのではなく、新しい視覚的証拠に基づいて計画を更新または変更することを求める方法を示しています。
仕組み
エージェントはインタラクション可能な位置から開始するため、ナビゲーションや視点選択は考慮されません。findアクションによってオブジェクトが視界に入り、環境はコンテナのサイズや配置の詳細を処理するため、エージェントはどのキャビネットやカウンタートップを使用するかを推論する必要はありません。唯一の入力はカラー画像、単純な成功または失敗の信号を含む試行済みアクションの履歴、そしてエージェント自身が次に行おうと計画している内容の記録です。
各ターンで、エージェントはタスクを完了するための完全なステップシーケンスを提案しますが、進行するのは最初のステップのみです。その後、新しい画像と単純な信号(そのアクションは成功したか失敗したか?)を受け取ります。これにより、エージェントがすべてを事前にスクリプト化することを防ぎ、各ステップで計画を再評価・修正することを強制します。総ステップ数と繰り返しアクションに対する組み込みの制限により、無限ループが防止されます。環境は単純なフィードバックのみを提供するため、エージェントは知覚したもの(例:マグカップが汚れているか、蛇口が水を流しているか)に気づき、ステップから次のステップへとタスク内での自身の状況を追跡(state tracking)できなければなりません。
AsgardBenchの評価
私たちはAsgardBenchでいくつかの主要な視覚能力を持つモデルをテストし、高性能なモデルが一貫して成功するためには視覚的接地(visual grounding)が必要であることを確認しました。モデル全体を通して、視覚入力を与えることでパフォーマンスが大幅に向上しました:ほとんどのモデルは、シーンのテキストのみの説明と比較して画像が与えられた場合、成功率が2倍以上になりました。これは、エージェントが何が悪かったかについてのテキストフィードバックに頼ることで、視覚なしでもまずまずの性能を発揮できる従来のベンチマークとは対照的です。
そのような詳細な失敗情報を提供することも、AsgardBenchにおけるすべてのモデルのパフォーマンスを向上させますが、それは根本的な問題を覆い隠してしまう可能性があります。最も強力な視覚能力を持つモデルは、詳細なフィードバックを与えられたテキストのみのエージェントよりも優れた性能を示しており、このベンチマークがテキストだけでは再現できない視覚的接地を要求していることを実証しています。AsgardBenchの性能は図2に示されています。
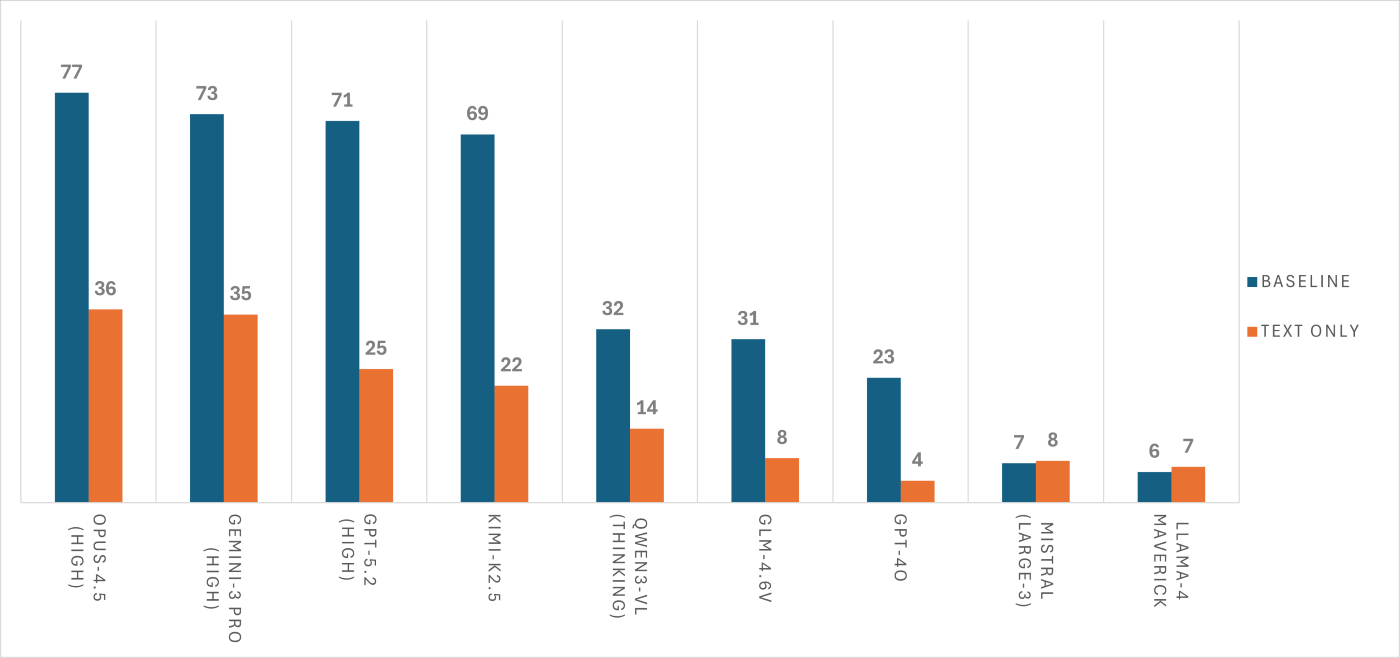 image図2. 画像ベースとテキストのみの条件での成功率。視覚入力は最も弱いエージェントを除くすべてのエージェントのパフォーマンスを大幅に向上させますが、テキストのみのパフォーマンスは低いままです。これは、AsgardBenchが知覚ベースの推論(perception-based reasoning)を要求していることを示しています。
image図2. 画像ベースとテキストのみの条件での成功率。視覚入力は最も弱いエージェントを除くすべてのエージェントのパフォーマンスを大幅に向上させますが、テキストのみのパフォーマンスは低いままです。これは、AsgardBenchが知覚ベースの推論(perception-based reasoning)を要求していることを示しています。
結果はまた、現在のエージェントが一貫してどこで失敗するかを明らかにしました。すべてのモデルにわたって、同じ問題が繰り返し現れました:エージェントは実行不可能なアクションを試み(例:シンクにないマグカップをきれいにしようとする)、繰り返しアクションループに陥り、微妙な視覚的合図(オン/オフ、清潔/汚れ)を誤解釈し、ステップから次のステップへとタスクの進行状況における自身の位置を見失いました。これは3つの弱点を示しています:雑然としたシーンでの微妙な視覚的詳細を区別できないこと、複数のステップにわたってタスクの進行状況を正確に把握し続けることができないこと、そしてエージェントが見たものをタイムリーな計画の更新に一貫して変換できないことです。これらを総合すると、次世代の身体性エージェントが改善すべき方向性が示されています。
示唆と今後の展望
AsgardBenchは診断ツールとしても開発ツールとしても有用です。エージェントが受け取るフィードバック(なし、最小限、または詳細)を変えることで、研究者はパフォーマンス向上がより良い知覚、より良い記憶、またはより良い計画立案のどれによるものかを切り分けることができます。有望な方向性には、より強力な視覚理解とより良い状態追跡(state tracking)を組み合わせたシステム、タスク中に計画を修正することを学ぶことに重点を置いたトレーニングアプローチ、エージェントが成功したかどうかだけでなく、途中でどれだけ適応したかを測定する評価方法が含まれます。
AsgardBenchが明らかにする失敗パターンは、具体的な次のステップを示しています:より細かい視覚的区別ができ、ステップ間で何が変化したかをより確実に追跡し、スクリプトに従って突き進むのではなくタスク中に計画を修正することを学べるシステムを構築することです。これらの課題に進歩を遂げるエージェントは、現実世界の環境の複雑さ(予期しないオブジェクトの状態、雑然としたシーン、絶え間ない適応の必要性)に対して、はるかに優れた能力を備えるはずです。
AsgardBenchはオープンソースであり、GitHub(新しいタブで開く)で利用可能で、視覚的接地型プランニングの研究を進めるための基盤を提供します。
謝辞
シミュレーションプラットフォームを構築し、再現可能な身体性評価を可能にしてくれたAI2-THORコミュニティに感謝します。
新しいタブで開くこの投稿 AsgardBench: A benchmark for visually grounded interactive planning は、Microsoft Research で最初に公開されました。
原文を表示
At a glance
To successfully complete tasks, embodied AI agents must ground and update their plans based on visual feedback.
AsgardBench isolates whether agents can use visual observations to revise their plans as tasks unfold.
Spanning 108 controlled task instances across 12 task types, the benchmark requires agents to adapt their plans based on what they observe.
Because objects can be in different positions and states (e.g., clean or dirty), the same instruction can require different action sequences, even in the same environment.
Imagine a robot tasked with cleaning a kitchen. It needs to observe its environment, decide what to do, and adjust when things don’t go as expected, for example, when the mug it was tasked to wash is already clean, or the sink is full of other items. This is the domain of embodied AI: systems that perceive their environment and act within it.
The field has made rapid progress, but evaluating these systems is harder than it looks. Many benchmarks test perception, navigation, and physical control all at once, making it difficult to isolate whether an AI agent is actually using what it perceives to make better decisions or just getting lucky because the environment is predictable enough to script around.
To address this, we created AsgardBench. In the paper, AsgardBench — Evaluating Visually Grounded Interactive Planning Under Minimal Feedback,” we describe how this benchmark poses a simple but demanding challenge: give an AI agent a household task, let it observe the environment through images, and see whether it can adjust its plan when what it perceives contradicts what it anticipated. Can it notice that the mug it needs to clean is already in the sink, or that it isn’t, and behave accordingly? That is the core question AsgardBench is designed to answer.
Built on AI2-THOR, an interactive 3D simulation environment used to train and evaluate AI agents on household tasks, AsgardBench positions agents near objects and gives them a small, fixed set of actions, such as find, pickup, put, clean, and toggle_on/off. At each turn, the agent proposes a full sequence of steps to complete the task, but only the first step executes. Throughout, the focus is squarely on plan adaptation, not whether an agent can navigate a room or manipulate an object, but whether it can use what it perceives to revise its next step.
For example, the agent may discover a mug to be clean, dirty, or filled with coffee, or it may observe that a sink contains many other items, so the same instruction can require different action sequences as the task unfolds. This process is illustrated in Figure 1.
imageFigure 1: Agent observations and corresponding action plans in AsgardBench. Each image is paired with the plan generated from that observation. This illustrates how AsgardBench requires agents to update or change their plans based on new visual evidence rather than following a fixed sequence.
How it works
Agents start in interaction-ready positions, so navigation and viewpoint selection are not factors. A find action brings objects into view, and the environment handles the details of container sizing and placement, so the agent does not need to reason about which cabinet or countertop to use. The only inputs are color images, a history of attempted actions with simple success or failure signals, and the agent’s own record of what it plans to do next.
At each turn, the agent proposes a complete sequence of steps to finish the task, but only the first step proceeds. It then receives new images and a simple signal—did that action succeed or fail? This prevents the agent from scripting everything upfront and forces it to re-evaluate and revise its plan at every step. Built-in limits on total steps and repeated actions prevent endless loops. Because the environment provides only simple feedback, the agent must be able to notice what it perceives (e.g., whether a mug is dirty, whether a faucet is running) and keep track of where it is in the task from one step to the next.
Evaluating AsgardBench
We tested several leading vision-capable models on AsgardBench and observed that high-performing models require visual grounding to consistently succeed. Across the models, visual input substantially improved performance: most models more than doubled success rates when given images versus text-only descriptions of the scene. This is in contrast to some prior benchmarks where agents could perform reasonably well without vision by relying on textual feedback on what went wrong.
Providing that kind of detailed failure information raises performance for all models in AsgardBench, too, but it can mask the real problem. The strongest vision-capable models still outperform text-only agents even when those agents are given detailed feedback, demonstrating that the benchmark requires visual grounding that text alone cannot replicate. AsgardBench’s performance is illustrated in Figure 2.
imageFigure 2. Success rates for image-based and text-only conditions. Visual input substantially improves performance for all but the weakest agents, while text-only performance remains low, indicating that AsgardBench requires perception-based reasoning.
The results also revealed where today’s agents consistently fall short. Across all models, the same problems kept appearing: agents attempted undoable actions (e.g., trying to clean a mug that was not in the sink), got stuck in repeated action loops, misinterpreted subtle visual cues (on/off, clean/dirty), and lost track of where they were in the task progress from one step to the next. This points to three weaknesses: the inability to distinguish subtle visual details in cluttered scenes, the inability to maintain an accurate picture of task progress across multiple steps, and the inability to consistently translate what the agent sees into timely updates to its plan. Taken together, these point to where the next generation of embodied agents will need to improve.
Spotlight: AI-POWERED EXPERIENCE
 image
image
Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Start now
Opens in a new tab
Implications and looking ahead
AsgardBench is useful as both a diagnostic and development tool. By varying what feedback agents receive (none, minimal, or detailed), researchers can isolate whether performance gains come from better perception, better memory, or better planning. Promising directions include systems that combine stronger visual understanding with better state tracking, training approaches that emphasize learning to repair plans mid-task, and evaluation methods that measure not just whether an agent succeeds but how well it adapted along the way.
The failure patterns AsgardBench surfaces point toward a concrete next step: building systems that can make finer visual distinctions, keep track of what changed more reliably across steps, and learn to revise plans mid-task rather than plowing ahead on a script. Agents that make progress on these challenges should be meaningfully better equipped for the messiness of real-world environments: unexpected object states, cluttered scenes, and the constant need to adapt.
AsgardBench is open source and available on GitHub (opens in new tab), providing a foundation for advancing research in visually grounded planning.
Acknowledgements
We thank the AI2-THOR community for building the simulation platform and making reproducible embodied evaluation possible.
Opens in a new tabThe post AsgardBench: A benchmark for visually grounded interactive planning appeared first on Microsoft Research.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み