カーネギーメロン大学、ICLR 2026に194論文を発表
カーネギーメロン大学(CMU)研究者が、4月にリオデジャネイロで開催されるAIトップ会議ICLR 2026に194論文を投稿し、LLMコード編集ベンチマーク「EditBench」などの多様な研究領域をカバーしている。
キーポイント
ICLR 2026におけるCMUの参加規模と開催概要
CMU研究者が4月23〜27日にリオデジャネイロで開催されるICLR 2026に194論文を投稿し、主要共同研究機関と論文カテゴリ(CV、DL、RLなど)の一覧を公開している。
EditBench:実環境を考慮したLLMコード編集ベンチマーク
既存のコードをユーザー指示に基づいて編集するLLM能力を評価する新ベンチマークであり、545件の多様な問題と実世界コンテキスト(周囲コードやカーソル位置)を組み合わせた評価手法を提案している。
UALM:統合オーディオ言語モデルの取り組み
記事は詳細が途中まで記載されているが、音声と言語処理を統一したモデル(Unified Audio Language Model)に関するCMUの取り組みが紹介されている。
産学連携と研究領域の多様性
Apple、Google DeepMind、UC Berkeley、UCLAなどとの共同研究が顕著であり、理論から応用、社会側面まで幅広い機械学習分野をカバーしている。
UALMの統合型音声処理
単一モデルで音声理解・生成・マルチモーダル推論を統合し、専門モデルに匹敵する性能を実現。
ADPによるエージェント学習データの標準化
分散したデータ形式を統一する「共通インターリンガ」を提供し、13のデータセットを統合することでモデル性能を向上。
OpenThoughts: Open Data for Reasoning Models
The project demonstrates that carefully optimized open-source datasets can match or exceed the performance of models trained on private data, significantly boosting results in math, coding, and science.
影響分析・編集コメントを表示
影響分析
CMUのICLR投稿数は同大学が機械学習分野でいかに強力な研究基盤を維持しているかを示す指標である。特にEditBenchのような実環境コンテキストを重視した評価基準の提案は、LLMの実装・デバッグ現場における検証プロセスの標準化に寄与する可能性がある。ただし学術会議の投稿一覧であるため直ちに業界構造を変えるものではないが、今後の技術トレンドを先取りする重要な信号である。
編集コメント
学術会議の投稿一覧であるため技術詳細は限定的だが、実環境を重視したLLM評価ベンチマークの登場は現場の検証プロセスに影響する可能性がある。今後の論文採択結果と実装公開に注目したい。
CMUの研究者らは、4月23日から4月27日までブラジル・リオデジャネイロのリオコンベンション&イベントセンターで開催される第14回国際学習表現会議(ICLR 2026: International Conference on Learning Representations)で194本の論文を発表します。以下は、当研究室の研究者が取り組んでいる分野の概要です:
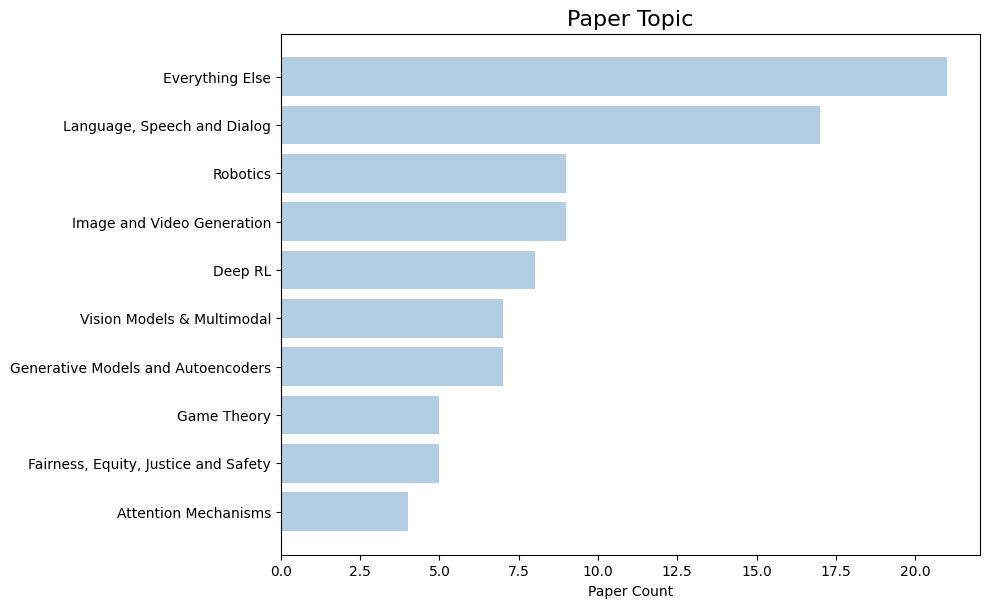
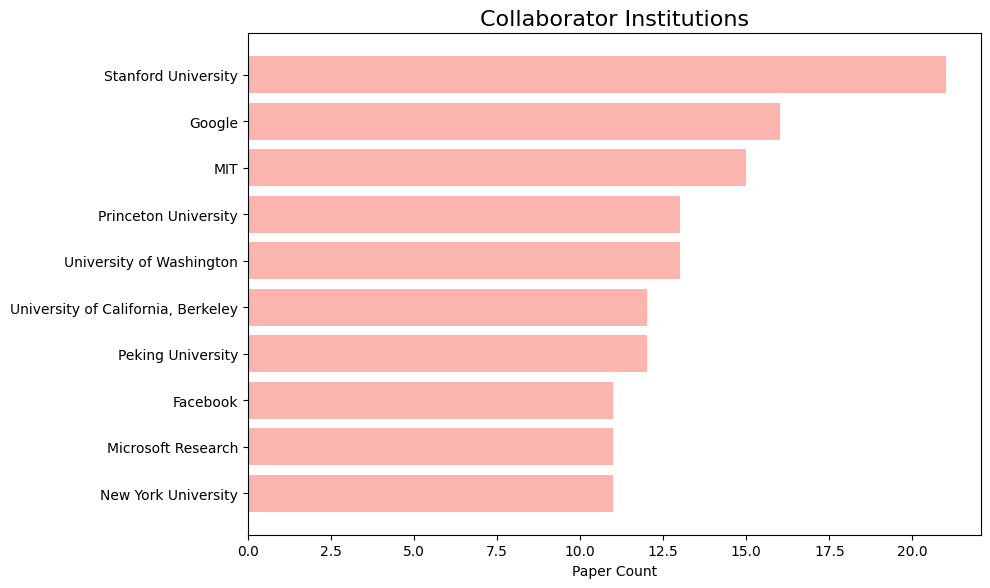
以下は、最も頻繁に共同研究を行っている機関です:
目次
口頭発表論文
ポスター発表論文
アプリケーション
コンピュータビジョン(Computer Vision)
ディープラーニング(Deep Learning)
汎用機械学習(General Machine Learning)
最適化(Optimization)
強化学習(Reinforcement Learning)
社会的側面(Social Aspects)
理論(Theory)
カテゴリ未分類(Uncategorized)
口頭発表論文
EditBench:LLMの現実世界における指示付きコード編集能力の評価
著者:Wayne Chi(CMU)、Valerie Chen(Carnegie Mellon University)、Ryan Shar(Apple)、Aditya Mittal(CMU、Carnegie Mellon University)、Jenny Liang(School of Computer Science, Carnegie Mellon University)、Wei-Lin Chiang(UC Berkeley / LMSYS)、Anastasios Angelopoulos(University of California Berkeley)、Ion Stoica()、Graham Neubig(Carnegie Mellon University)、Ameet Talwalkar(University of California-Los Angeles)、Chris Donahue(CMU / Google DeepMind)
本研究では、EditBenchという新しいベンチマーク(benchmark)を紹介しています。これは、AIモデルがユーザーの指示に基づいて既存のコードをどの程度編集できるかをテストするためのものです。以前のベンチマークとは異なり、周囲のコードやカーソルの位置など、実際のコーディングタスクとコンテキスト(context)を使用しています。このベンチマークには545の多様な問題が含まれており、その結果、ほとんどのモデルが苦戦していることが示されました。性能が高いのは限られた数だけです。また、より現実的なコンテキストを備えることがモデルの性能に大きな影響を与えることも判明しており、現実世界の環境におけるコード編集の評価の重要性が浮き彫りになりました。
UALM: Unified Audio Language Model for Understanding, Generation and Reasoning
Authors: Jinchuan Tian (CMU, Carnegie Mellon University), Sang-gil Lee (NVIDIA), Zhifeng Kong (NVIDIA), Sreyan Ghosh (Nvidia), Arushi Goel (NVIDIA), Chao-Han Huck Yang (NVIDIA Research), Wenliang Dai (NVIDIA), Zihan Liu (Nvidia), Hanrong Ye (NVIDIA), Shinji Watanabe (Carnegie Mellon University), Mohammad Shoeybi (NVIDIA), Bryan Catanzaro (NVIDIA), Rafael Valle (NVIDIA), Wei Ping (Nvidia)
本論文は、音声理解(audio understanding)、テキストから音声への生成(text-to-audio generation)、マルチモーダル推論(multimodal reasoning)を単一のモデルで処理するように設計された「Unified Audio Language Model(UALM)」を紹介する。これらのタスクを個別に扱うのではなく、UALMは音声の解釈と生成の両方を学習し、専門的な最先端モデル(state-of-the-art models)に匹敵するパフォーマンスを達成している。また著者らは、推論プロセス(reasoning process)中にテキストと音声を組み合わせることで、複雑なタスクへの対応能力が向上することも示している。全体として、この研究は言語と音声を跨いで推論できるより汎用的なAIシステムへの一歩を示すものとなっている。
Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
Authors: Yueqi Song (CMU), Ketan Ramaneti (Amazon), Zaid Sheikh (Carnegie Mellon University), Ziru Chen (Ohio State University, Columbus), Boyu Gou (Ohio State University, Columbus), Tianbao Xie (the University of Hong Kong, University of Hong Kong), Yiheng Xu (University of Hong Kong), Danyang Zhang (Shanghai Jiao Tong University), Apurva Gandhi (Carnegie Mellon University), Fan Yang (Fujitsu), Joseph Liu (School of Computer Science, Carnegie Mellon University), Tianyue Ou (Carnegie Mellon University), Zhihao Yuan (Carnegie Mellon University), Frank F Xu (Carnegie Mellon University), Shuyan Zhou (Facebook), Xingyao Wang (All Hands AI), Xiang Yue (Carnegie Mellon University), Tao Yu (University of Hong Kong), Huan Sun (Ohio State University), Yu Su (Ohio State University), Graham Neubig (Carnegie Mellon University)
本研究は、AIエージェント(AI agents)のトレーニングデータ(training data)を表現するための標準化されたフォーマットである「Agent Data Protocol(ADP)」を紹介する。著者らは、主な課題がデータの不足にあるのではなく、既存のデータセット(datasets)が異なるフォーマットやツールに断片化されていることだと主張する。ADPは共通の「インターリンガ(interlingua)」として機能し、コーディング、ブラウジング、ツール使用といった多様なデータソースを単一のトレーニングパイプライン(training pipeline)に統合しやすくする。13のデータセットをこの統一フォーマットに変換することで、著者らは統合データを基に学習したモデルがパフォーマンスを向上させることを示している。
MotionStream: Real-Time Video Generation with Interactive Motion Controls
Authors: Joonghyuk Shin (Seoul National University), Zhengqi Li (Google), Richard Zhang (Adobe), Jun-Yan Zhu (Carnegie Mellon University), Jaesik Park (Seoul National University), Eli Shechtman (Adobe), Xun Huang (Adobe Research)
この論文では、MotionStreamというシステムを紹介しています。これはモーションとテキスト入力に基づいて動画をリアルタイム(real-time)に生成するシステムです。動画の生成に数分を要する従来の手法とは異なり、MotionStreamは単一のGPU上で最大29フレーム/秒(fps)で結果をストリーミングできます。鍵となるアイデアは、長時間のシーケンスにおける品質劣化を防ぐ手法を用いて、動画を連続的に生成できる高速な因果モデル(causal model)を訓練することです。その結果、ユーザーは経路の描画やカメラ移動といったモーションをインタラクティブに制御でき、動画が即座に更新される様子を確認できます。
OpenThoughts: Data Recipes for Reasoning Models
著者: Etash Guha (Stanford University, Anthropic), Ryan Marten (Harbor), Sedrick Keh (Toyota Research Institute), Negin Raoof (University of California, Berkeley), Georgios Smyrnis (University of Texas, Austin), Hritik Bansal (University of California, Los Angeles), Marianna Nezhurina (Juelich Supercomputing Center, LAION, Tuebingen University), Jean Mercat (Toyota Research Institute (TRI)), Trung Vu (Google), Zayne Sprague (New York University), Ashima Suvarna (UCLA), Benjamin Feuer (Stanford University), Leon Liangyu Chen (Stanford University), Zaid Khan (University of North Carolina at Chapel Hill), Eric Frankel (Department of Computer Science, University of Washington), Sachin Grover (Arizona State University), Caroline Choi (None), Niklas Muennighoff (Stanford University), Shiye Su (Stanford University), Wanjia Zhao (Stanford University), John Yang (Princeton University), Shreyas Pimpalgaonkar (New York University), Kartik sharma (Georgia Institute of Technology), Charlie Ji (University of California, Berkeley), Yichuan Deng (Department of Computer Science, University of Washington), Sarah Pratt (University of Washington), Vivek Ramanujan (Department of Computer Science, University of Washington), Jon Saad-Falcon (Computer Science Department, Stanford University), Stutee Acharya (University of South Florida), Jeffrey Li (Carnegie Mellon University), Achal Dave (Anthropic), Alon Albalak (SynthLabs), Kushal Arora (McGill University), Blake Wulfe (Toyota Research Institute), Chinmay Hegde (New York University), Greg Durrett (New York University), Sewoong Oh (University of Washington), Mohit Bansal (UNC Chapel Hill), Saadia Gabriel (University of Washington), Aditya Grover (UCLA), Kai-Wei Chang (University of Virginia Main Campus), Vaishaal Shankar (Apple), Aaron Gokaslan (Cornell University), Mike Merrill (None), Tatsunori Hashimoto (Stanford University), Yejin Choi (Stanford University / NVIDIA), Jenia Jitsev (LAION; Juelich Supercomputing Center, Research Center Juelich), Reinhard Heckel (Technical University Munich), Maheswaran Sathiamoorthy (University of Southern California), Alex Dimakis (Electrical Engineering & Computer Science Department, University of California, Berkeley), Ludwig Schmidt (University of Washington / Stanford / Anthropic)
本研究は、推論能力に特化したAIモデルの学習のために高品質なオープンソースデータセット(open-source datasets)の作成を目的とした「OpenThoughts」プロジェクトを紹介しています。著者たちは、この公開データで学習したモデルが、プライベートなデータセット(private datasets)に依存する既存の強力なシステムと同等かそれ以上のパフォーマンスを発揮できることを示しています。データ生成プロセスを慎重に研究・改善することで、より大規模で高品質なデータセットを構築し、数学、コーディング、科学の各ベンチマーク(benchmarks)でパフォーマンスを大幅に向上させました。全体として、このプロジェクトはオープンなデータのみでも、高度な推論能力を持つモデルを学習できることを実証しています。
Mamba-3:状態空間の原理(State Space Principles)を用いたシーケンスモデリング(Sequence Modeling)の改善
著者:Aakash Sunil Lahoti (CMU, Carnegie Mellon University), Kevin Li (Carnegie Mellon University), Berlin Chen (Princeton University), Caitlin Wang (Princeton University), Aviv Bick (Carnegie Mellon University), Zico Kolter (Carnegie Mellon University), Tri Dao (Princeton University), Albert Gu (Cartesia AI CMU)
本論文は、パフォーマンスを犠牲にすることなくAI推論(AI inference)をより高速かつ効率的に行うために設計された新モデル「Mamba-3」を紹介しています。Transformerの効率的な代替手法は計算量を削減するものの、長期情報の追跡といったタスクでしばしば課題を抱えますが、Mamba-3は改善された状態モデリング(state modeling)とより表現力豊かな更新メカニズム(update mechanism)によってこの課題に対処します。また、本モデルはマルチ入力・マルチ出力設計(multi-input, multi-output design)を採用し、生成速度を低下させることなく精度を向上させています。全体として、Mamba-3は効率性と能力の両方を同時に向上させることが可能であり、速度とパフォーマンスのトレードオフを前進させることを示しています。
損失なし階層的推測的デコーディング(Lossless Hierarchical Speculative Decoding)による結合不可解性(Joint Intractability)の克服
著者:Yuxuan Zhou (Independent Researcher), Fei Huang (Alibaba Group), Heng Li (Carnegie Mellon University), Fengyi Wu (University of Washington), Tianyu Wang (University of Washington), Jianwei Zhang (Alibaba Group), Junyang Lin (Alibaba Group), Zhi-Qi Cheng (University of Washington)
本論文は、推測的デコーディング(speculative decoding)における検証ステップを改善しつつ正確な出力分布(output distributions)を保持することで大規模言語モデル(large language model)の推論を高速化する新手法「階層的推測的デコーディング(Hierarchical Speculative Decoding, HSD)」を紹介しています。シーケンスレベルの検証(sequence-level verification)における「結合不可解性」の課題に対し、リサンプリング(resampling)を階層構造に整理して枝全体に確率質量(probability mass)を再分配することで、一度により多くのトークン(tokens)を受け入れることを可能にします。この手法は理論的に損失なしであることが証明されており、モデルやベンチマーク全体で一貫した速度向上を示し、従来のトークン単位の検証(tokenwise verification)およびブロック単位の検証手法(blockwise verification methods)を上回っています。全体として、HSDは忠実性を犠牲にせずにデコーディングを加速する実用的かつ汎用の手法を提供し、既存のフレームワークに統合することで最先端の効率性(state-of-the-art efficiency)を達成します。
線形非ガウス潜在変数循環因果モデル(Linear Non-Gaussian Latent-Variable Cyclic Causal Models)における分布の同等性(Distributional Equivalence):特性と学習
著者: Haoyue Dai (Carnegie Mellon University), Immanuel Albrecht (FernUniversität in Hagen), Peter Spirtes (Carnegie Mellon University), Kun Zhang (Carnegie Mellon University & MBZUAI)
本論文は、潜在変数とサイクルを含む線形非ガウスモデルにおける因果発見(causal discovery)を研究しており、異なる因果グラフ(causal graphs)が観測的に識別不可能な条件に焦点を当てています。この設定における分布の同等性(distributional equivalence)に関する初の一般化された特徴付けを提供し、2つのモデルが同じ観測データを生成する条件を記述するための新しいツール——特にエッジランク制約(edge rank constraints)——を導入しています。この理論に基づき、著者はすべての同等モデルを列挙するための実用的なグラフ基準と変換を導出し、データから等価クラス全体を復元するアルゴリズムを提案しています。全体的に、この研究は強力な構造的仮定の必要性を取り除き、潜在変数を用いた因果発見(latent-variable causal discovery)のための一般化された原理的な枠組みを提供します。
Revela: 言語モデリングによる密な検索器の学習
著者: Fengyu Cai (Technische Universität Darmstadt), Tong Chen (University of Washington), Xinran Zhao (Carnegie Mellon University), Sihao Chen (Microsoft), Hongming Zhang (Tencent AI Lab Seattle), Sherry Wu (Carnegie Mellon University), Iryna Gurevych (Technical University of Darmstadt / Mohamed bin Zayed University of Artificial Intelligence), Heinz Koeppl (TU Darmstadt)
本論文は、Revelaを紹介しています。これは、注釈付きのクエリ-ドキュメントペアに依存するのではなく、言語モデリング(language modeling)の目的関数を活用して密な検索器(dense retrievers)を訓練するための自己教師ありフレームワークです。次のトークン予測(next-token prediction)にバッチ内アテンション機構(in-batch attention mechanism)を付加し、ドキュメントが互いにアテンションを向けることを可能にすることで、検索器が言語モデルと共同でドキュメント間関係(cross-document relationships)を学習できるようにしています。ドメイン固有、推論集中型、および一般的なベンチマーク全体での実験により、Revelaが大幅に少ないデータと計算資源を使用しながらも、教師あり検索器やAPIベースの検索器と同等以上の性能を発揮することが示されています。全体的に、この研究は、ドメイン横断で強い汎化能力を持ち、生テキストから直接検索器を学習するためのスケーラブルで効率的な代替案であることを実証しています。
潜在粒子ワールドモデル:自己教師ありオブジェクト中心の確率力学モデリング
著者: Tal Daniel (Carnegie Mellon University), Carl Qi (University of Texas at Austin), Dan Haramati (Brown University), Amir Zadeh (Lambda), Chuan Li (Lambda Labs), Aviv Tamar (Technion), Deepak Pathak (Carnegie Mellon University), David Held (Carnegie Mellon University)
本論文は、潜在粒子ワールドモデル(Latent Particle World Model, LPWM)を紹介する。これは教師なしで生動画から直接、シーンを実態粒子(latent particles、例:キープイント、マスク、オブジェクト属性)に分解する学習を行う、自己教師あり(self-supervised)のオブジェクト中心型ワールドモデル(object-centric world model)である。本手法は、確率動態(stochastic dynamics)をモデル化する新規なパーパーティクル潜在行動メカニズム(per-particle latent action mechanism)を提案しており、これによりシステムは複雑なマルチオブジェクト相互作用を捉え、多様な未来予測を生成できる。本モデルはエンドツーエンド(end-to-end)で学習され、行動、言語、ゴール画像に対する柔軟な条件付け(conditioning)をサポートし、実世界および合成動画の予測タスクにおいて最先端のパフォーマンスを達成している。動画モデリングに加え、LPWMは学習された潜在動態を活用することで、模倣学習(imitation learning)などの意思決定アプリケーションにおいても強力な可能性を示している。
LoongRL: Reinforcement Learning for Advanced Reasoning over Long Contexts
著者: Siyuan Wang(Shanghai Jiao Tong University)、Gaokai Zhang(Carnegie Mellon University)、Li Lyna Zhang(Microsoft Research Asia)、Ning Shang(Microsoft)、Fan Yang(Microsoft Research)、Dongyao Chen(Shanghai Jiaotong University)、Mao Yang(Peking University)
著者らは、LoongRLを紹介する。これは大規模言語モデルの長期コンテキスト推論(long-context reasoning)能力を向上させるために設計された強化学習(reinforcement learning)フレームワークであり、困難な合成タスクでモデルを学習させることでその向上を図る。また、KeyChainというデータ構築手法を提案している。これは長文書内に隠れた質問チェーンを埋め込み、モデルが近道に頼るのではなく多段階の計画、検索、推論を実行することを強制するものである。強化学習(RL)による学習を通じて、モデルは「計画-検索-推論-再確認」という創発的な推論パターンを発達させ、これはより短い(16K)コンテキストからはるかに長い(128K)コンテキストへと一般化する。実験により、LoongRLは強力な短期コンテキスト能力を維持しつつ長期コンテキスト推論性能を大幅に向上させ、はるかに大規模なモデルと同等の結果を達成することが示された。
Exchangeability of GNN Representations with Applications to Graph Retrieval
著者: Kartik Nair(Carnegie Mellon University)、Indradyumna Roy(IIT Bombay, Aalto University)、Soumen Chakrabarti(IIT Bombay)、Anirban Dasgupta(IIT Gandhinagar)、Abir De(Indian Institute of Technology Bombay)
本論文は、グラフニューラルネットワーク(Graph Neural Networks, GNN)における交換可能性(exchangeability)の概念を紹介する。これは、ランダム初期化と順列不変学習(permutation-invariant training)により、学習されたノード埋め込み(node embeddings)の次元が統計的に互換性(交換可能)であることを示している。この性質は、埋め込み成分が同一の分布を共有することを意味し、グラフ類似度の計算方法を簡略化できることを示唆する。この知見を活用し、著者らは並べ替えられた埋め込み値に対する単純なユークリッド演算(Euclidean operation)を用いて、複雑な輸送ベースのグラフ距離(transportation-based graph distance)を近似する。さらに、GRAPHHASHという局所敏感ハッシング(Locality-Sensitive Hashing)フレームワークを提案しており、これは効率的かつスケーラブルなグラフ検索を可能にし、既存手法と比較して強力なパフォーマンスを達成している。
Poster Papers
アプリケーション
TusoAI:Agentic Optimization for Scientific Methods(科学的手法のためのエージェント型最適化)
著者:Alistair Turcan(School of Computer Science, Carnegie Mellon University)、Kexin Huang(Stanford University)、Lei Li(School of Computer Science, Carnegie Mellon University)、Martin J. Zhang(Carnegie Mellon University)
AutoLibra:Agent Metric Induction from Open-Ended Human Feedback(オープンエンドの人間フィードバックからのエージェント指標誘導)
著者:Hao Zhu(Carnegie Mellon University)、Phil Cuvin(Stanford University)、Xinkai Yu(University of Pennsylvania, University of Pennsylvania)、Charlotte Yan(Stanford University)、Jason Zhang(Stanford University)、Diyi Yang(Stanford University)
DistMLIP:A Distributed Inference Platform for Machine Learning Interatomic Potentials(機械学習用原子間ポテンシャルのための分散推論プラットフォーム)
著者:Kevin Han(Carnegie Mellon University)、Bowen Deng(UC Berkeley)、Amir Barati Farimani(CMU, Carnegie Mellon University)、Gerbrand Ceder(University of California, Berkeley)
Vlaser:Vision-Language-Action Model with Synergistic Embodied Reasoning(協調的具現化推論を備えたビジョン・ランゲージ・アクションモデル)
著者:Ganlin Yang(University of Science and Technology of China)、Tianyi Zhang(Zhejiang University; Shanghai Artificial Intelligence Laboratory)、Haoran Hao(Carnegie Mellon University)、Weiyun Wang(Fudan University)、Yibin Liu(Northeastern University)、Dehui Wang(Shanghai Jiaotong University)、Guanzhou Chen(Shanghai AI Laboratory, Shanghai Jiaotong University)、Zijian Cai(Shenzhen University)、Junting Chen(national university of singaore, National University of Singapore)、Weijie Su(University of Science and Technology of China)、Wengang Zhou(University of Science and Technology of China)、Yu Qiao(Shanghai Aritifcal Intelligence Laboratory)、Jifeng Dai(Tsinghua University, Tsinghua University)、Jiangmiao Pang(Shanghai AI Laboratory)、Gen Luo(Shanghai AI Laboratory)、Wenhai Wang(Shanghai AI Laboratory)、Yao Mu(Shanghai Jiao Tong University)、Zhi Hou(Shanghai Artificial Intelligence Laboratory)
DataMIL:Selecting Data for Robot Imitation Learning with Datamodels(データモデルを用いたロボットの模倣学習のためのデータ選択)
著者:Shivin Dass(University of Texas at Austin)、Alaa Khaddaj(OpenAI)、Logan Engstrom(Massachusetts Institute of Technology)、Aleksander Madry(OpenAI)、Andrew Ilyas(Carnegie Mellon University)、Roberto Martín-Martín(University of Texas at Austin)
TimeSeriesExamAgent:Creating Time Series Reasoning Benchmarks at Scale(大規模な時系列推論ベンチマークの作成)
著者:Malgorzata Gwiazda(Technical University of Munich)、Yifu Cai(Millennium Management LLC)、Mononito Goswami(Carnegie Mellon University)、Arjun Choudhry(Georgia Institute of Technology)、Artur Dubrawski(Carnegie-Mellon University)
原文を表示
jQuery('.post-authors').width(0.33 * jQuery('.post-authors').parent().width());
jQuery('.affiliations').width(0.33 * jQuery('.affiliations').parent().width());
jQuery('.date').width(0.33 * jQuery('.date').parent().width());
jQuery('.post-authors').empty();
jQuery('.post-authors').append('Authors
');
jQuery('.post-authors').append('Naveen Raman, Kiriaki Fragkia');
jQuery('.affiliations').append('MLD, CMU
');
jQuery('.doi').remove();
CMU researchers are presenting 194 papers at the Fourteenth International Conference on Learning Representations (ICLR 2026), held from April 23rd-April 27th at the Riocentro Convention and Event Center in Rio de Janeiro, Brazil. Here is a quick overview of the areas our researchers are working on:
Here are our most frequent collaborator institutions:
body { font-family: Arial, sans-serif; margin: 20px; line-height: 1.6; }
h1 { text-align: center; }
h2 { color: #333; }
h3 { color: #555; margin-top: 20px; }
.paper { margin-bottom: 20px; }
.paper-title { font-weight: bold; }
.paper-authors { font-style: italic; margin-bottom: 10px; }
.oral-spotlight-space { margin-top: 10px; font-style: normal; }
.table-of-contents { margin-bottom: 30px; }
.table-of-contents ul { list-style-type: none; padding-left: 0; }
.table-of-contents ul ul { padding-left: 20px; }
Table of Contents
Oral Papers
Poster Papers
Applications
Computer Vision
Deep Learning
General Machine Learning
Optimization
Reinforcement Learning
Social Aspects
Theory
Uncategorized
Oral Papers
EditBench: Evaluating LLM Abilities to Perform Real-World Instructed Code Edits
Authors: Wayne Chi (CMU), Valerie Chen (Carnegie Mellon University), Ryan Shar (Apple), Aditya Mittal (CMU, Carnegie Mellon University), Jenny Liang (School of Computer Science, Carnegie Mellon University), Wei-Lin Chiang (UC Berkeley / LMSYS), Anastasios Angelopoulos (University of California Berkeley), Ion Stoica (), Graham Neubig (Carnegie Mellon University), Ameet Talwalkar (University of California-Los Angeles), Chris Donahue (CMU / Google DeepMind)
This work introduces EditBench, a new benchmark for testing how well AI models can edit existing code based on user instructions. Unlike prior benchmarks, it uses real-world coding tasks and contexts, including things like the surrounding code and cursor position. The benchmark includes 545 diverse problems, and results show that most models struggle—only a few achieve strong performance. The study also finds that having more realistic context significantly impacts how well models perform, highlighting the importance of evaluating code-editing in real-world settings.
UALM: Unified Audio Language Model for Understanding, Generation and Reasoning
Authors: Jinchuan Tian (CMU, Carnegie Mellon University), Sang-gil Lee (NVIDIA), Zhifeng Kong (NVIDIA), Sreyan Ghosh (Nvidia), Arushi Goel (NVIDIA), Chao-Han Huck Yang (NVIDIA Research), Wenliang Dai (NVIDIA), Zihan Liu (Nvidia), Hanrong Ye (NVIDIA), Shinji Watanabe (Carnegie Mellon University), Mohammad Shoeybi (NVIDIA), Bryan Catanzaro (NVIDIA), Rafael Valle (NVIDIA), Wei Ping (Nvidia)
This paper introduces the Unified Audio Language Model (UALM), a single model designed to handle audio understanding, text-to-audio generation, and multimodal reasoning together. Instead of treating these as separate tasks, UALM learns to both interpret and generate audio, achieving performance comparable to specialized state-of-the-art models. The authors also show that combining text and audio during the model’s reasoning process improves its ability to handle complex tasks. Overall, the work demonstrates a step toward more general AI systems that can reason across both language and sound.
Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
Authors: Yueqi Song (CMU), Ketan Ramaneti (Amazon), Zaid Sheikh (Carnegie Mellon University), Ziru Chen (Ohio State University, Columbus), Boyu Gou (Ohio State University, Columbus), Tianbao Xie (the University of Hong Kong, University of Hong Kong), Yiheng Xu (University of Hong Kong), Danyang Zhang (Shanghai Jiao Tong University), Apurva Gandhi (Carnegie Mellon University), Fan Yang (Fujitsu), Joseph Liu (School of Computer Science, Carnegie Mellon University), Tianyue Ou (Carnegie Mellon University), Zhihao Yuan (Carnegie Mellon University), Frank F Xu (Carnegie Mellon University), Shuyan Zhou (Facebook), Xingyao Wang (All Hands AI), Xiang Yue (Carnegie Mellon University), Tao Yu (University of Hong Kong), Huan Sun (Ohio State University), Yu Su (Ohio State University), Graham Neubig (Carnegie Mellon University)
This work introduces the Agent Data Protocol (ADP), a standardized format for representing training data for AI agents. The authors argue that the main challenge isn’t a lack of data, but that existing datasets are fragmented across different formats and tools. ADP acts as a common “interlingua,” making it easier to combine diverse data sources—like coding, browsing, and tool use—into a single training pipeline. By converting 13 datasets into this unified format, the authors show that models trained on the combined data achieve improved performance.
MotionStream: Real-Time Video Generation with Interactive Motion Controls
Authors: Joonghyuk Shin (Seoul National University), Zhengqi Li (Google), Richard Zhang (Adobe), Jun-Yan Zhu (Carnegie Mellon University), Jaesik Park (Seoul National University), Eli Shechtman (Adobe), Xun Huang (Adobe Research)
This paper introduces MotionStream, a system for generating videos in real time based on motion and text inputs. Unlike prior methods that take minutes to produce a video, MotionStream can stream results at up to 29 frames per second on a single GPU. The key idea is to train a fast, causal model that can generate video continuously, using techniques that prevent quality from degrading over long sequences. As a result, users can interactively control motion—like drawing paths or moving a camera—and see the video update instantly.
OpenThoughts: Data Recipes for Reasoning Models
Authors: Etash Guha (Stanford University, Anthropic), Ryan Marten (Harbor), Sedrick Keh (Toyota Research Institute), Negin Raoof (University of California, Berkeley), Georgios Smyrnis (University of Texas, Austin), Hritik Bansal (University of California, Los Angeles), Marianna Nezhurina (Juelich Supercomputing Center, LAION, Tuebingen University), Jean Mercat (Toyota Research Institute (TRI)), Trung Vu (Google), Zayne Sprague (New York University), Ashima Suvarna (UCLA), Benjamin Feuer (Stanford University), Leon Liangyu Chen (Stanford University), Zaid Khan (University of North Carolina at Chapel Hill), Eric Frankel (Department of Computer Science, University of Washington), Sachin Grover (Arizona State University), Caroline Choi (None), Niklas Muennighoff (Stanford University), Shiye Su (Stanford University), Wanjia Zhao (Stanford University), John Yang (Princeton University), Shreyas Pimpalgaonkar (New York University), Kartik sharma (Georgia Institute of Technology), Charlie Ji (University of California, Berkeley), Yichuan Deng (Department of Computer Science, University of Washington), Sarah Pratt (University of Washington), Vivek Ramanujan (Department of Computer Science, University of Washington), Jon Saad-Falcon (Computer Science Department, Stanford University), Stutee Acharya (University of South Florida), Jeffrey Li (Carnegie Mellon University), Achal Dave (Anthropic), Alon Albalak (SynthLabs), Kushal Arora (McGill University), Blake Wulfe (Toyota Research Institute), Chinmay Hegde (New York University), Greg Durrett (New York University), Sewoong Oh (University of Washington), Mohit Bansal (UNC Chapel Hill), Saadia Gabriel (University of Washington), Aditya Grover (UCLA), Kai-Wei Chang (University of Virginia Main Campus), Vaishaal Shankar (Apple), Aaron Gokaslan (Cornell University), Mike Merrill (None), Tatsunori Hashimoto (Stanford University), Yejin Choi (Stanford University / NVIDIA), Jenia Jitsev (LAION; Juelich Supercomputing Center, Research Center Juelich), Reinhard Heckel (Technical University Munich), Maheswaran Sathiamoorthy (University of Southern California), Alex Dimakis (Electrical Engineering & Computer Science Department, University of California, Berkeley), Ludwig Schmidt (University of Washington / Stanford / Anthropic)
This work introduces the OpenThoughts project, which aims to create high-quality, open-source datasets for training reasoning-focused AI models. The authors show that models trained on their public data can match or exceed the performance of strong existing systems that rely on private datasets. By carefully studying and improving their data generation process, they build larger and better datasets that significantly boost performance across math, coding, and science benchmarks. Overall, the project demonstrates that open data alone can be enough to train highly capable reasoning models.
Mamba-3: Improved Sequence Modeling using State Space Principles
Authors: Aakash Sunil Lahoti (CMU, Carnegie Mellon University), Kevin Li (Carnegie Mellon University), Berlin Chen (Princeton University), Caitlin Wang (Princeton University), Aviv Bick (Carnegie Mellon University), Zico Kolter (Carnegie Mellon University), Tri Dao (Princeton University), Albert Gu (Cartesia AI CMU)
This paper introduces Mamba-3, a new model designed to make AI inference faster and more efficient without sacrificing performance. While many efficient alternatives to Transformers reduce computation, they often struggle with tasks like tracking long-term information; Mamba-3 addresses this with improved state modeling and a more expressive update mechanism. The model also uses a multi-input, multi-output design to boost accuracy without slowing down generation. Overall, Mamba-3 shows that it’s possible to improve both efficiency and capability at the same time, pushing forward the tradeoff between speed and performance.
Overcoming Joint Intractability with Lossless Hierarchical Speculative Decoding
Authors: Yuxuan Zhou (Independent Researcher), Fei Huang (Alibaba Group), Heng Li (Carnegie Mellon University), Fengyi Wu (University of Washington), Tianyu Wang (University of Washington), Jianwei Zhang (Alibaba Group), Junyang Lin (Alibaba Group), Zhi-Qi Cheng (University of Washington)
This paper introduces Hierarchical Speculative Decoding (HSD), a new method to speed up large language model inference by improving the verification step in speculative decoding while preserving exact output distributions. It addresses the challenge of “joint intractability” in sequence-level verification by organizing resampling into a hierarchy that redistributes probability mass across branches, enabling more tokens to be accepted at once. The approach is theoretically proven to be lossless and empirically shows consistent speed improvements across models and benchmarks, outperforming prior tokenwise and blockwise verification methods. Overall, HSD offers a practical and general way to accelerate decoding without sacrificing fidelity, achieving state-of-the-art efficiency when integrated into existing frameworks.
Distributional Equivalence in Linear Non-Gaussian Latent-Variable Cyclic Causal Models: Characterization and Learning
Authors: Haoyue Dai (Carnegie Mellon University), Immanuel Albrecht (FernUniversität in Hagen), Peter Spirtes (Carnegie Mellon University), Kun Zhang (Carnegie Mellon University & MBZUAI)
This paper studies causal discovery in linear non-Gaussian models with latent variables and cycles, focusing on when different causal graphs are observationally indistinguishable. It provides the first general characterization of distributional equivalence in this setting, introducing new tools—especially edge rank constraints—to describe when two models generate the same observed data. Building on this theory, the authors derive practical graphical criteria and transformations to enumerate all equivalent models and propose an algorithm to recover the entire equivalence class from data. Overall, the work removes the need for strong structural assumptions and offers a general, principled framework for latent-variable causal discovery.
Revela: Dense Retriever Learning via Language Modeling
Authors: Fengyu Cai (Technische Universität Darmstadt), Tong Chen (University of Washington), Xinran Zhao (Carnegie Mellon University), Sihao Chen (Microsoft), Hongming Zhang (Tencent AI Lab Seattle), Sherry Wu (Carnegie Mellon University), Iryna Gurevych (Technical University of Darmstadt / Mohamed bin Zayed University of Artificial Intelligence), Heinz Koeppl (TU Darmstadt)
This paper introduces Revela, a self-supervised framework for training dense retrievers by leveraging language modeling objectives instead of relying on annotated query-document pairs. It augments next-token prediction with an in-batch attention mechanism that allows documents to attend to each other, enabling the retriever to learn cross-document relationships jointly with a language model. Experiments across domain-specific, reasoning-intensive, and general benchmarks show that Revela matches or surpasses supervised and API-based retrievers while using significantly less data and compute. Overall, the work demonstrates a scalable and efficient alternative for retriever learning directly from raw text with strong generalization across domains.
Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling
Authors: Tal Daniel (Carnegie Mellon University), Carl Qi (University of Texas at Austin), Dan Haramati (Brown University), Amir Zadeh (Lambda), Chuan Li (Lambda Labs), Aviv Tamar (Technion), Deepak Pathak (Carnegie Mellon University), David Held (Carnegie Mellon University)
This paper introduces the Latent Particle World Model (LPWM), a self-supervised, object-centric world model that learns to decompose scenes into latent particles (e.g., keypoints, masks, and object attributes) directly from raw video without supervision. It proposes a novel per-particle latent action mechanism that models stochastic dynamics, enabling the system to capture complex multi-object interactions and generate diverse future predictions. The model is trained end-to-end and supports flexible conditioning on actions, language, and goal images, achieving state-of-the-art performance on both real-world and synthetic video prediction tasks. Beyond video modeling, LPWM also demonstrates strong potential for decision-making applications such as imitation learning by leveraging its learned latent dynamics.
LoongRL: Reinforcement Learning for Advanced Reasoning over Long Contexts
Authors: Siyuan Wang (Shanghai Jiao Tong University), Gaokai Zhang (Carnegie Mellon University), Li Lyna Zhang (Microsoft Research Asia), Ning Shang (Microsoft), Fan Yang (Microsoft Research), Dongyao Chen (Shanghai Jiaotong University), Mao Yang (Peking University)
The authors introduce LoongRL, a reinforcement learning framework designed to improve long-context reasoning in large language models by training them on challenging, synthesized tasks. They propose KeyChain, a data construction method that embeds hidden question chains within long documents, forcing models to perform multi-step planning, retrieval, and reasoning rather than relying on shortcuts. Through RL training, models develop an emergent “plan–retrieve–reason–recheck” reasoning pattern that generalizes from shorter (16K) to much longer (128K) contexts. Experiments show that LoongRL significantly boosts long-context reasoning performance while maintaining strong short-context abilities, achieving results comparable to much larger models.
Exchangeability of GNN Representations with Applications to Graph Retrieval
Authors: Kartik Nair (Carnegie Mellon University), Indradyumna Roy (IIT Bombay, Aalto University), Soumen Chakrabarti (IIT Bombay), Anirban Dasgupta (IIT Gandhinagar), Abir De (Indian Institute of Technology Bombay)
This paper introduces the concept of exchangeability in graph neural networks (GNNs), showing that the dimensions of learned node embeddings are statistically interchangeable due to random initialization and permutation-invariant training. This property implies that embedding components share identical distributions, enabling simplifications in how graph similarities are computed. Leveraging this insight, the authors approximate complex transportation-based graph distances using simpler Euclidean operations on sorted embedding values. They further propose GRAPHHASH, a locality-sensitive hashing framework that enables efficient and scalable graph retrieval, achieving strong performance compared to existing methods.
Poster Papers
Applications
TusoAI: Agentic Optimization for Scientific Methods
Authors: Alistair Turcan (School of Computer Science, Carnegie Mellon University), Kexin Huang (Stanford University), Lei Li (School of Computer Science, Carnegie Mellon University), Martin J. Zhang (Carnegie Mellon University)
AutoLibra: Agent Metric Induction from Open-Ended Human Feedback
Authors: Hao Zhu (Carnegie Mellon University), Phil Cuvin (Stanford University), Xinkai Yu (University of Pennsylvania, University of Pennsylvania), Charlotte Yan (Stanford University), Jason Zhang (Stanford University), Diyi Yang (Stanford University)
DistMLIP: A Distributed Inference Platform for Machine Learning Interatomic Potentials
Authors: Kevin Han (Carnegie Mellon University), Bowen Deng (UC Berkeley), Amir Barati Farimani (CMU, Carnegie Mellon University), Gerbrand Ceder (University of California, Berkeley)
Vlaser: Vision-Language-Action Model with Synergistic Embodied Reasoning
Authors: Ganlin Yang (University of Science and Technology of China), Tianyi Zhang (Zhejiang University; Shanghai Artificial Intelligence Laboratory), Haoran Hao (Carnegie Mellon University), Weiyun Wang (Fudan University), Yibin Liu (Northeastern University), Dehui Wang (Shanghai Jiaotong University), Guanzhou Chen (Shanghai AI Laboratory, Shanghai Jiaotong University), Zijian Cai (Shenzhen University), Junting Chen (national university of singaore, National University of Singapore), Weijie Su (University of Science and Technology of China), Wengang Zhou (University of Science and Technology of China), Yu Qiao (Shanghai Aritifcal Intelligence Laboratory), Jifeng Dai (Tsinghua University, Tsinghua University), Jiangmiao Pang (Shanghai AI Laboratory), Gen Luo (Shanghai AI Laboratory), Wenhai Wang (Shanghai AI Laboratory), Yao Mu (Shanghai Jiao Tong University), Zhi Hou (Shanghai Artificial Intelligence Laboratory)
DataMIL: Selecting Data for Robot Imitation Learning with Datamodels
Authors: Shivin Dass (University of Texas at Austin), Alaa Khaddaj (OpenAI), Logan Engstrom (Massachusetts Institute of Technology), Aleksander Madry (OpenAI), Andrew Ilyas (Carnegie Mellon University), Roberto Martín-Martín (University of Texas at Austin)
TimeSeriesExamAgent: Creating Time Series Reasoning Benchmarks at Scale
Authors: Malgorzata Gwiazda (Technical University of Munich), Yifu Cai (Millennium Management LLC), Mononito Goswami (Carnegie Mellon University), Arjun Choudhry (Georgia Institute of Technology), Artur Dubrawski (Carnegie-Mellon University)
関連記事
ロシアのプロパガンダに抵抗する能力において最も優れた大規模言語モデルとは
エストニア言語研究所は、外国の敵対国が推進する危険なプロパガンダを拡散する懸念に対応するため、大規模言語モデルがロシア連邦の戦略的トピックに対して立場を取らない能力を評価する「プロパガンダ抵抗」ベンチマークを発表した。
LLM 研究論文:2026 年 1 月から 5 月のリスト
Sebastian Raschka が、2026 年上半期(1 月〜5 月)に注目すべき大規模言語モデル関連の研究論文を選定し、一覧として公開した。
[AINews] 今日特に大きな出来事はありませんでした
Latent Space が運営するニュースレター「AINews」が、6月4日から5日にかけてのAI業界動向を12件のRedditスレッドや544件のTwitter投稿から選別して紹介しました。記事ではRL環境ガイドの推奨や、DeepSeek v4 Pro向けの最適化に関するリモートポッドの更新について言及しています。