Gemini 3.1 Flash-Lite:大規模な知能処理のために構築
Google DeepMindは、高スループットワークロード向けに最適化された高速・低コストの「Gemini 3.1 Flash-Lite」モデルをプレビュー公開し、既存Flashモデルを上回る速度とコスト効率を実現した。
キーポイント
コストと速度の大幅な向上
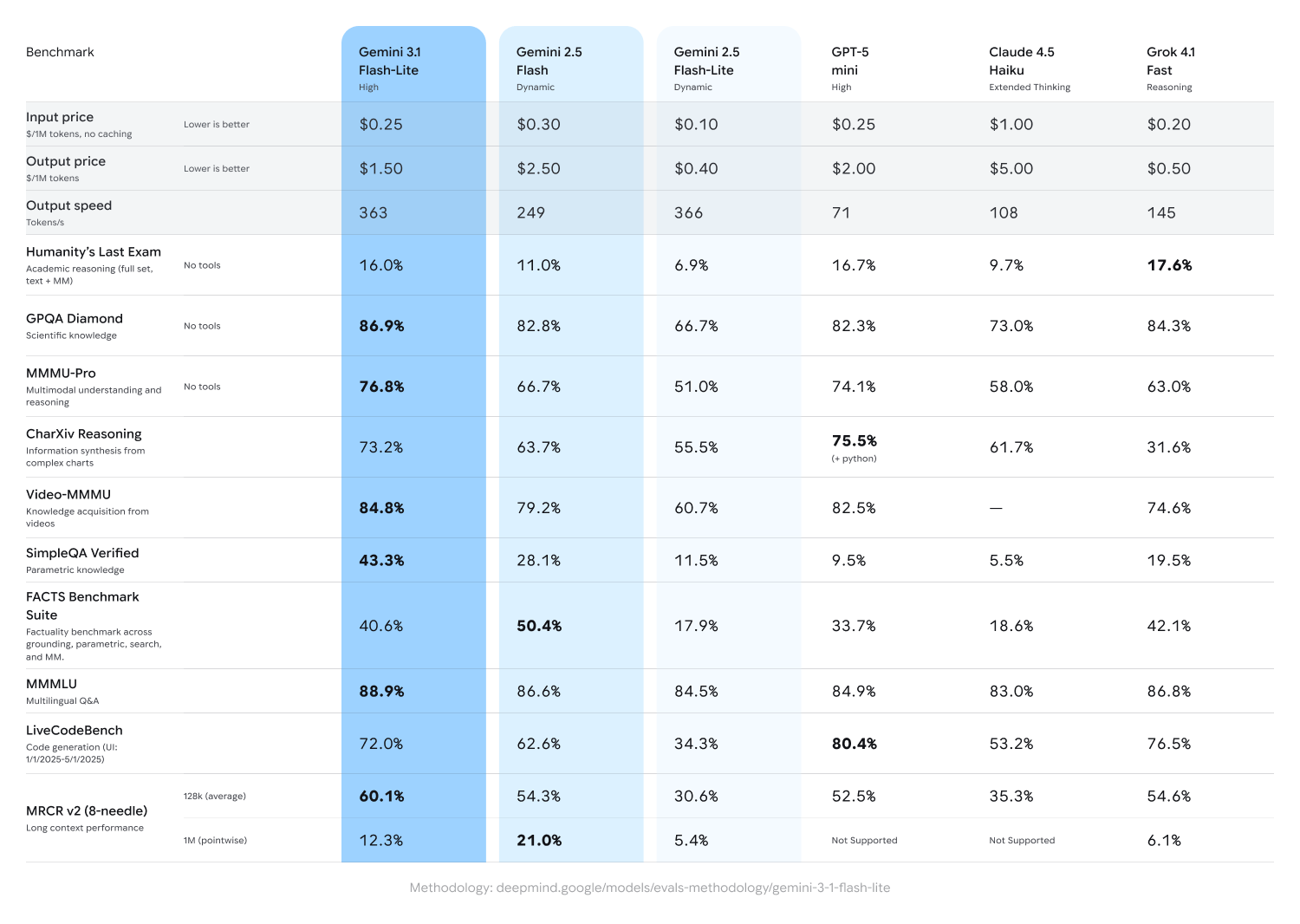
入力トークン$0.25、出力$1.50という低価格設定で、前世代の2.5 Flash比で初回答までの時間が2.5倍高速化し、出力速度も45%向上した。
開発者向け機能の標準化
Gemini APIおよびVertex AIを通じて提供され、開発者がタスクの複雑さに応じてモデルの「思考レベル」を調整できる機能を標準搭載している。
多様なユースケースへの適用
翻訳やコンテンツモデレーションなどの高頻度タスクから、UI生成やシミュレーション作成といった複雑な推論が必要な作業まで幅広く対応可能。
多様なユースケースでの実装
リアルタイムの天気ダッシュボード生成、SaaSエージェントによる複数ステップのタスク実行、大規模な画像コンテンツの迅速な分析・分類など、幅広い応用が可能。
早期アクセスユーザーからの高い評価
Latitude、Cartwheel、Wheringなどの企業や開発者が活用しており、大規模モデル並みの精度で複雑な入力を処理し、指示に従従性を維持できる効率性と推論能力が評価されている。
影響分析・編集コメントを表示
影響分析
このリリースは、大規模なデータ処理やリアルタイム応答が求められるアプリケーション開発において、コストとパフォーマンスのバランスを劇的に改善する可能性を秘めている。特に「思考レベル」の制御機能は、開発者がリソース使用量を細かく最適化できるため、実務での採用拡大を促進する要因となる。
編集コメント
GoogleはFlashシリーズの迭代を通じて、推論能力と速度の両立を図っており、この「Lite」版は特にバッチ処理や高頻度API呼び出しにおける経済性を重視した戦略的リリースと言える。
Gemini 3.1 Flash-Lite: 大規模インテリジェンスのために構築
最大規模のワークロードに最高クラスのインテリジェンスを
概要
Gemini 3.1 Flash-Liteのプレビュー版が、開発者向けにGoogle AI StudioのGemini API、企業向けにVertex AIを通じて利用可能になりました。入力トークン100万あたり0.25ドル、出力トークン100万あたり1.50ドルという価格で、コスト効率に優れ、Gemini 2.5 Flashよりも高速です。翻訳、コンテンツモデレーション、ユーザーインターフェース生成、シミュレーション作成などのタスクに、3.1 Flash-Liteをご活用ください。
基本解説
Googleは、Gemini 3.1 Flash-Liteという新しいAIモデルを開発しました。非常に高速で利用コストが低いため、より多くのユーザーが利用可能です。このAIは、言語翻訳やコンテンツチェックなどの作業に適しています。一部の企業では、その高い知性と効率性から、既に難しい課題の解決に活用しています。
他のスタイルを探索:
概要
基本解説
お使いのブラウザはオーディオ要素をサポートしていません。
本日、当社はGemini 3シリーズで最速かつ最もコスト効率の高いモデルとなる、Gemini 3.1 Flash-Liteを発表します。大規模な開発者ワークロード向けに構築された3.1 Flash-Liteは、その価格帯とモデル階層において高品質を実現します。
本日より、3.1 Flash-Liteのプレビュー版が、開発者向けにGoogle AI StudioのGemini API、企業向けにVertex AIを通じて提供開始されます。
妥協なきコスト効率
入力トークン100万あたりわずか0.25ドル、出力トークン100万あたり1.50ドルという価格設定の3.1 Flash-Liteは、大規模モデルの数分の一のコストで、強化されたパフォーマンスを提供します。Artificial Analysisベンチマークによれば、同程度またはそれ以上の品質を維持しつつ、初回応答トークンまでの時間が2.5倍速く、出力速度が45%向上しており、2.5 Flashを上回る性能を発揮します。この低遅延性は高頻度ワークフローに不可欠であり、開発者が応答性の高いリアルタイム体験を構築するための理想的なモデルです。
Gemini 3.1 Flash-Liteは、速度と品質の両面で2.5 Flashを上回ります。
3.1 Flash-Liteは、Arena.aiリーダーボードで1432という高いEloスコアを獲得しています。また、GPQA Diamondで86.9%、MMMU Proで76.8%のスコアを含む、推論およびマルチモーダル理解ベンチマークにおいて、同クラスの他モデルを凌駕。前世代のより大規模なGeminiモデルである2.5 Flashさえも上回りました。
開発者のための、大規模な適応型インテリジェンス
卓越した基本性能に加え、Gemini 3.1 Flash-Liteは標準で、AI StudioおよびVertex AIにおける「思考レベル」機能を備えています。これにより開発者は、モデルがタスクに対してどれだけ「思考」するかを選択する制御権と柔軟性を得られ、高頻度ワークロードの管理に重要な役割を果たします。3.1 Flash-Liteは、コスト優先の大規模翻訳やコンテンツモデレーションといったタスクを、規模を問わず処理できます。さらに、ユーザーインターフェースやダッシュボードの生成、シミュレーションの作成、指示への忠実な従順性が求められる、より深い推論を必要とする複雑なワークロードにも対応可能です。
3.1 Flash-Liteは、数百もの異なるカテゴリーの商品で、Eコマースのワイヤーフレームを瞬時に埋めます。
3.1 Flash-Liteは、ライブ予報と過去データを用いて、リアルタイムで動的な気象ダッシュボードを生成できます。
3.1 Flash-Liteは、ビジネス向けに多様な多段階タスクを実行可能なSaaSエージェントを構築します。
3.1 Flash-Liteは、画像などの大量のコンテンツを迅速に分析・分類できます。
AI StudioおよびVertex AIの早期アクセス開発者や、Latitude、Cartwheel、Wheringといった企業は、既に3.1 Flash-Liteを活用し、大規模な複雑な問題を解決しています。初期テスターは、3.1 Flash-Liteの効率性と推論能力を高く評価し、より上位階層のモデルに匹敵する精度で複雑な入力を処理しつつ、指示に忠実に従うことができる点を強調しています。
3.1 Flash-Lite、そしてGemini 3シリーズのその他のモデルを用いて、皆様がどのようなものを構築されるのか、楽しみにしています。
Googleの最新情報をメールで受け取る
Googleの最新情報をメールで受け取る
お客様の情報は、Googleのプライバシーポリシーに従って使用されます。
完了です。残るステップはあと1つ。
購読確認のため、受信トレイをご確認ください。
既に当社のニュースレターを購読されています。
別のメールアドレスでも購読できます。






原文を表示
Gemini 3.1 Flash-Lite: Built for intelligence at scale
Get best-in-class intelligence for your highest-volume workloads.
General summary
Gemini 3.1 Flash-Lite is now available in preview to developers via the Gemini API in Google AI Studio and for enterprises via Vertex AI. Priced at $0.25/1M input tokens and $1.50/1M output tokens, it's cost-efficient and faster than 2.5 Flash. Use 3.1 Flash-Lite for tasks like translation content moderation generating user interfaces and creating simulations.
Basic explainer
Google made a new AI model called Gemini 3.1 Flash-Lite. It's super fast and cheap to use, so more people can use it. This AI is good at things like translating languages and checking content. Some companies are already using it to solve tough problems because it's both smart and efficient.
Explore other styles:
General summary
Basic explainer
Your browser does not support the audio element.
Today, we're introducing Gemini 3.1 Flash-Lite, our fastest and most cost-efficient Gemini 3 series model. Built for high-volume developer workloads at scale, 3.1 Flash-Lite delivers high quality for its price and model tier.
Starting today, 3.1 Flash-Lite is rolling out in preview to developers via the Gemini API in Google AI Studio and for enterprises via Vertex AI.
Cost-efficiency without compromise
Priced at just $0.25/1M input tokens and $1.50/1M output tokens, 3.1 Flash-Lite delivers enhanced performance at a fraction of the cost of larger models. It outperforms 2.5 Flash with a 2.5X faster Time to First Answer Token and 45% increase in output speed, according to the Artificial Analysis benchmark while maintaining similar or better quality. This low latency is needed for high-frequency workflows, making it an ideal model for developers to build responsive, real-time experiences.
Gemini 3.1 Flash-Lite outperforms 2.5 Flash in speed and quality.
3.1 Flash-Lite achieves an impressive Elo score of 1432 on the Arena.ai Leaderboard and outperforms other models of similar tier across reasoning and multimodal understanding benchmarks, including 86.9% on GPQA Diamond and 76.8% on MMMU Pro–even surpassing larger Gemini models from prior generations like 2.5 Flash.
Adaptive intelligence at scale for developers
Beyond its raw performance, Gemini 3.1 Flash-Lite comes standard with thinking levels in AI Studio and Vertex AI, giving developers the control and flexibility to select how much the model “thinks” for a task, which is critical for managing high-frequency workloads. 3.1 Flash-Lite can tackle tasks at scale, like high-volume translation and content moderation, where cost is a priority. And it can also handle more complex workloads where more in-depth reasoning is needed, like generating user interfaces and dashboards, creating simulations or following instructions.
3.1 Flash-Lite instantly fills an e-commerce wireframe with hundreds of products in different categories.
3.1 Flash-Lite can generate dynamic weather dashboards in real-time, using live forecasts and historical data.
3.1 Flash-Lite creates a SaaS agent capable of executing versatile, multi-step tasks for a business.
3.1 Flash-Lite can analyze and sort large numbers of content like images quickly.
Early-access developers on AI Studio and Vertex AI, and companies like Latitude, Cartwheel and Whering are already using 3.1 Flash-Lite to solve complex problems at scale. Early testers highlighted 3.1 Flash-Lite’s efficiency and reasoning capabilities, saying it can handle complex inputs with the precision of a larger-tier model, plus follow instructions and maintain adherence.
We look forward to seeing what you build with 3.1 Flash-Lite and the rest of the Gemini 3 series models.
Get more stories from Google in your inbox. Get more stories from Google in your inbox.
Your information will be used in accordance with Google's privacy policy.
Done. Just one step more.
Check your inbox to confirm your subscription.
You are already subscribed to our newsletter.
You can also subscribe with a different email address .
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み