法務エージェント向けの効率的な検証器の設計
LangChain と Harvey は、複雑な法的タスクにおけるエージェントの検証コストを削減するために、LLM ベースのバッチ検証と低コストモデル活用の手法を提案し、実用性の高い評価フレームワークを構築した。
キーポイント
法的エージェント評価の現状課題
法的業務は文書量が多く専門知識が必要であるため、従来の個別基準ごとの LLM 検証では API コストが膨大になり、スケーラビリティに問題がある。
バッチ検証によるトークン削減
各基準を個別に評価するのではなく、複数の基準を含むルブリック全体を一度の LLM 呼び出しで処理する「バッチ検証」手法を提案し、トークン使用量を大幅に削減する。
コスト効率と性能の両立
より安価なモデルや少ないトーク数を使用する戦略を検証し、最先端モデルに近い精度を維持しつつ、検証コストを実用的なレベルまで低下させる方法を模索している。
LAB ベンチマークの活用
Harvey が公開したオープンソースベンチマーク「LAB」を用いて、法的エージェントの複雑なタスクに対する検証プロセスを定量的に評価・比較する枠組みを提供している。
影響分析・編集コメントを表示
影響分析
この分析は、LLM を用いた専門分野(特に法務)での実装において、コストと精度のバランスをどう取るかという普遍的な課題に対する具体的な解決策を示しています。バッチ処理による検証手法の提案は、大規模なエージェント評価や RL 学習プロセスにおける経済的障壁を取り除く可能性があり、業界全体の実用化スピードに寄与する重要な知見です。
編集コメント
法務という厳格な領域において、LLM の検証コストをどう下げるかという実務的な課題に対し、バッチ処理という明確な技術的アプローチを示した点が高く評価されます。特に RL 学習や大規模評価を想定した場合、この手法は実用化への重要な一歩となるでしょう。
*著者:Vivek Trivedy (LangChain), Jake Broekhuizen (LangChain), Harrison Chase (LangChain), Niko Grupen (Harvey), Gabe Pereyra (Harvey), Spencer Poff (Harvey), Julio Pereyra (Harvey)*
今月初め、Harvey は LAB をリリースしました。これは複雑な法的業務におけるエージェントを評価するためのオープンソースベンチマークです。初期結果 によると、今日のエージェントでは法的業務は全く飽和しておらず、まだ多くの余地があることが示されています。
Harvey と共同で、私たちは以下の問いに取り組みました:
どのようにすれば、法的エージェントの作業の正しさをより効率的に検証できるでしょうか?
なぜこれが重要なのでしょうか?法的業務は、文書が多くコンテキストを埋め尽くすこと、専門知識が必要であること、そして出力が許容されるためには厳格な基準に従う必要があることから、エージェントにとって特に困難なドメインです。
LAB ベンチマークの検証アプローチは、人間のレビューアーが行うものと同様です。データセット内のすべてのタスクには、タスクが合格するために満たさなければならない一連の基準 (criteria) が設定されています。各基準は、個別の LLM 判事によって検証モデルを使用して評価されます。各基準について、検証器はエージェントの出力と測定すべき match_criteria を取得します。そして、各基準ごとに verdict(判定)を出力します。多くのタスクでは、50 以上の個別の基準を検証する必要があります。これらの各基準に対して LLM API コールを行うことは、最先端モデルを用いてスケールする際にコストが高騰します。

より効率的な検証は可能か?
フロンティア・バーフィア(最前線の検証モデル)を実行するコストは、法的エージェントの評価を実施したり、強化学習(RL: Reinforcement Learning)を用いて法的エージェントを訓練したりするチームにとって、実用的な課題を生み出しています。
どのようにすれば、最前線のパフォーマンスにほぼ近い状態を保ちながら、バーフィアのコストを最大限削減できるでしょうか?
私たちは、より効率的な検証を行うための 2 つの異なる方法を研究しました:
- トークン数を減らす
- より安価なトークンを使用する
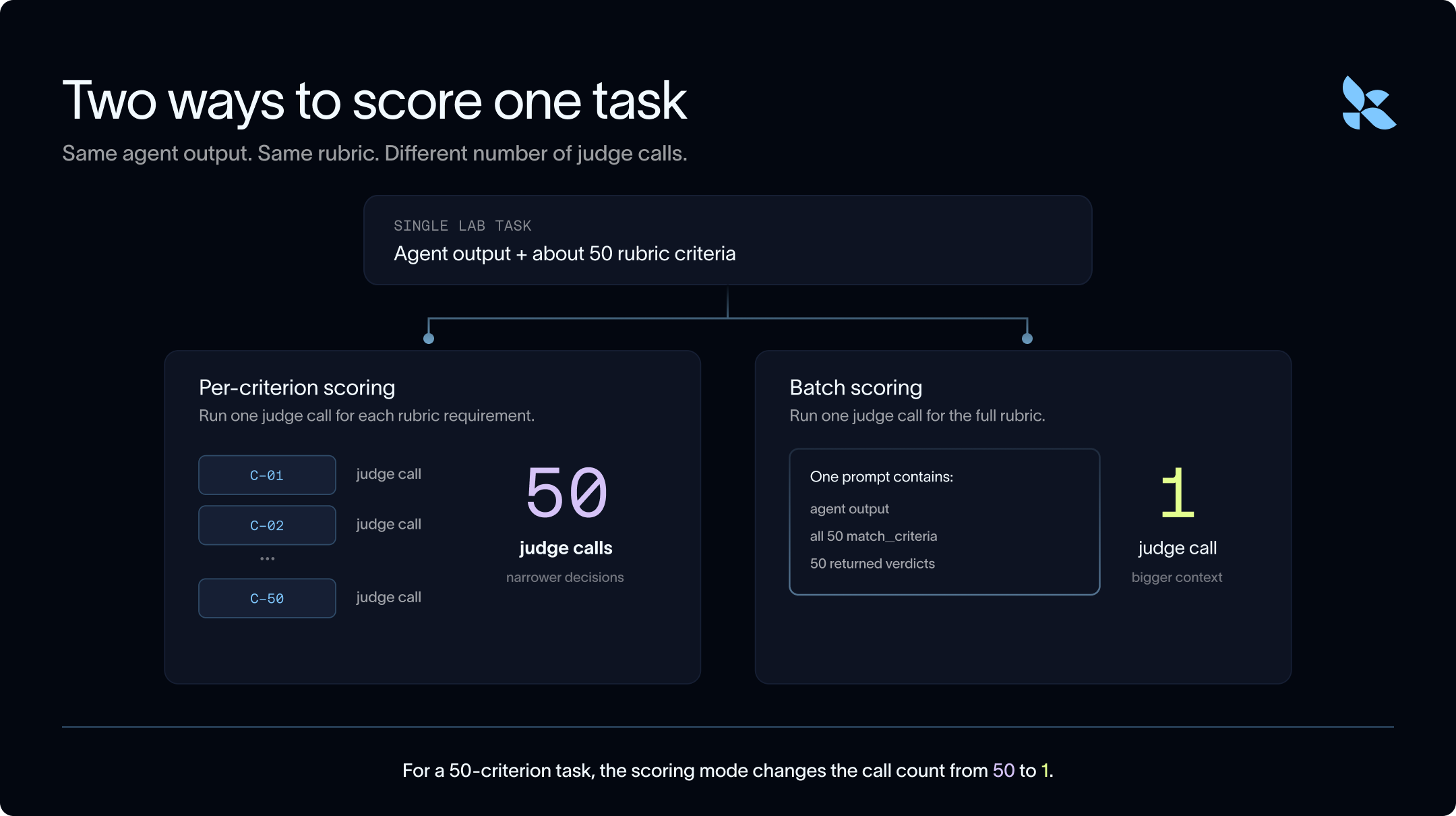
まず最初に検討した方法は、トークン数を減らすことです。トークン数を減らすために、私たちはバッチ処理でバーフィアを実行することを提案します。つまり、各基準ごとに独立して LLM(大規模言語モデル)呼び出しを行うのではなく、単一のバッチ呼び出しで完全な評価基準を判断させるのです。
- 基準ごとのスコアリング:評価基準の各要件に対して 1 つの判定呼び出しを実行する。
- バッチスコアリング:タスクに対して 1 つの判定呼び出しを実行し、すべての評価基準の要件を同時にラベル付けするように判定者に指示する。
次に検討した方法は、より安価なトークンを使用することです。より安価なトークンを利用するために、検証段階でより安価なモデルを試すことができます。私たちは Opus 4.7 を基準ごとのスコアリングの参照として使用し、GPT-5.5、Sonnet 4.6、DeepSeek v4 Flash、Claude Haiku 4.5 を、基準ごとのスコアリングとバッチスコアリングの両方で比較しました。
Verifier デザイン間での効率性を測定するための実験
Verifier の実験を実行するには、まず verifier が評価する一連の出力を作成する必要があります。これらの出力を作成するために、Kimi K2.6 を搭載したエージェントを、以下の実務分野にわたる 40 の公開 LAB タスクに対して実行しました:企業 M&A(Mergers and Acquisitions)、税務、新興企業/ベンチャーキャピタル(VC)、および信託・遺産継承。
これら 40 のタスク全体で、2,348 の個別のルブリック基準が存在します。各基準は verifier によって合格/不合格として採点されます。まず、Opus-4.7 をすべての基準に対して実行し、ベースラインとしました。これにより、GPT-5.5、Sonnet 4.6、Haiku 4.5、および DeepSeek-V4-Flash を他の verifier オプションとしてテストする際に比較するためのベースラインが得られます。各 verifier の実行は、同じ 2,348 の基準スコア(合格/不合格)を生成し、これらを用いて相互の比較を検討できます。
各 verifier の実行において、以下の項目を測定しました:
- 合意率:Opus の各基準ラベルと一致する頻度。
- 偽陽性(False pass):Opus が不合格とした基準を合格として判定した頻度。
- 偽陰性(False fail):Opus が合格とした基準を不合格として判定した頻度。
- コスト:40 タスクの verifier 実行における観測されたトークンコスト。
私たちは特に偽陽性に注意を払いました。現実の世界の設定では、不合格となった基準はさらに精査のためにエスカレーションされます。これは通常、法律のような分野において、不合格であるべき基準を合格として認めるよりも好ましい措置です。
エージェントシステムの設計と同様に、検証もパフォーマンス、コスト、時間の間のトレードオフです。基準ごとの検証は審査官の判断範囲を狭めますが、多くの呼び出しを必要とします。一方、バッチ検証はより安価で高速ですが、審査官は一度に完全な評価基準を追跡する必要があります。
以下のチャートは、コストとラベルのドリフト(ズレ)の関係を示しています。横軸は 1,000 の評価基準あたりの検証者コストです。縦軸は Opus の基準ごとのラベルとの不一致率、すなわち「100% - 一致率」です。左下に行くほど良好です。
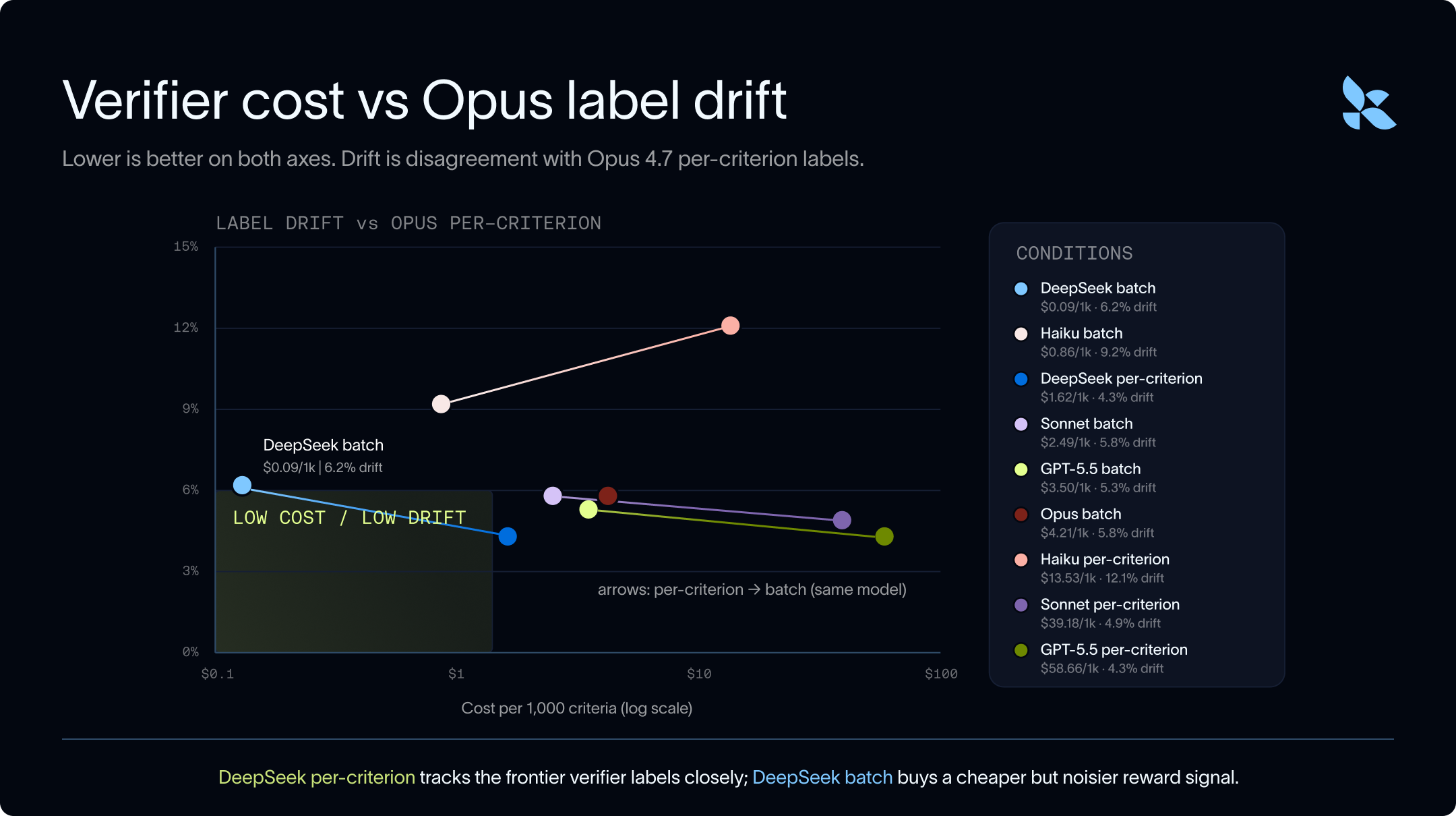
いくつかの重要な知見:
- 検証コストが低いほど、Opus との不一致も少なくなる傾向があります。
- 評価基準の数が増えると、バッチ処理の方がコスト効率に優れます。
- 個別の基準ごとの検証は、精度を高める一方で、コストと時間がかかるというトレードオフがあります。
- 全体的に、バッチモードでの実行は、各基準ごとの実行と比較して一致率が低くなります。しかし、同じモデルを使用する場合でも、バッチ実行は繰り返し入力トークンのコストを節約するため、実行コストが桁違いに安価になります。
- GPT-5.5 や Opus といった最先端モデルでさえもラベル付けにおいて意見が分かれており、その一致率は 95.7% に過ぎません。これは、一部のデータポイントが専門家と同様に一貫して適用できるほど十分に明確化されていないことを意味します。また、100% の一致率を目標とすることは現実的ではなく、95.7% の一致率が合理的な上限値である可能性を示唆しています。
- DeepSeek は、 verifier(検証者)として Opus と同等の強力な近似モデルであり、いずれも一度に一つの基準を実行し、バッチモードで動作します。さらに、DeepSeek は実行コストが 3 桁分安価であるため、大規模データやトレーニングドメインにおいてスケールして検証を行う必要がある場合に優れた候補となります。
- Haiku は Opus や Sonnet よりも安価でしたが、非常に寛容な傾向がありました。その誤って合格させる率(false-pass rates)は、各基準ごとで 48.4%、バッチモードで 34.7% であり、これは法的検証において望ましくない失敗モードです。
コスト削減:ポストトレーニング後
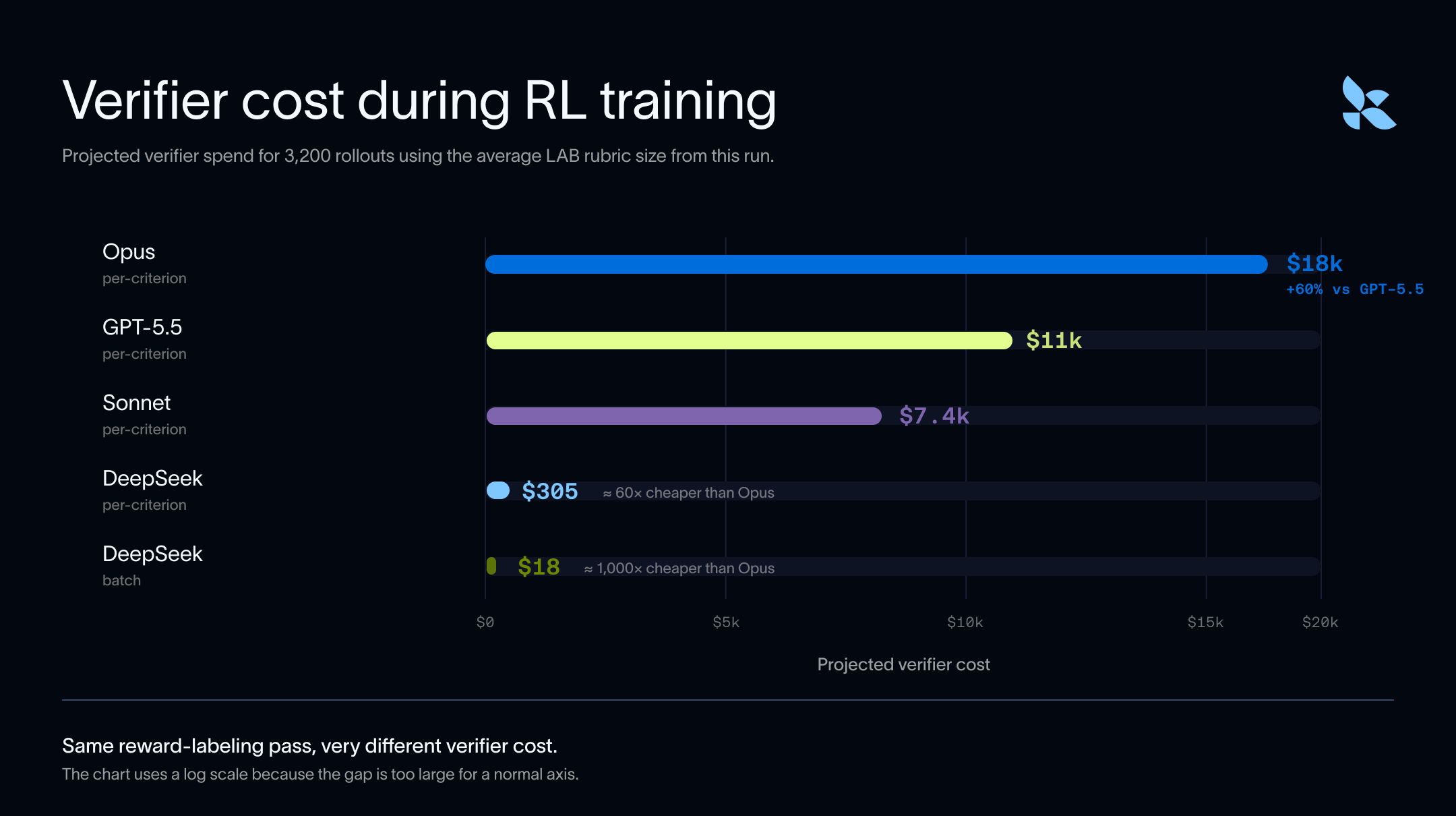
Verifier は評価(evals)だけでなく、ポストトレーニングにも使用されます。この場合、タスクごとの複数ロールアウトにより検証コストが増幅されます。LLM-as-judge システムはタスクのルブリックを報酬信号に変換し、より安価な報酬信号によって、より多くの実験の実行、より多くのロールアウトの監査、およびより迅速な反復が可能になります。
コストを推計する簡易的な計算では、DeepSeek はスケールした場合でも最先端の検証器に比べて 60〜1000 倍も安価に実行可能であることが示されました。これは、プログラムによる検証が容易ではなく、報酬信号を生成するためにある程度の LLM(大規模言語モデル)を Judge(判定者)として必要とするドメインにおいて、特に重要となります。
トレーシングから検証器の動作を調整する
結果は、モデルおよび各検証アーキテクチャ(基準別 vs バッチ処理)ごとにプロンプトを固定したものです。さらにテストした追加のレバーとして、ターゲットを絞ったプロンプトチューニングがあります。
プロンプトチューニングの影響を検証するため、DeepSeek と Opus の過去の結果に基づいて自動研究ループを実行しました。なぜ、どのように DeepSeek が乖離したのかを検討し、複数の実行を通じてプロンプトを微調整しました。その際、偽通過率(false-pass rate)の最適化を指示しました。
デフォルトのプロンプトにおける DeepSeek の一部の誤りの主な原因の一つは、DeepSeek が回答が要件に関連している場合、すべての重要な部分を満たしていなくても基準に合格させようとしすぎることでした。最終的なプロンプトでは、検証器に対して各基準の各要素をより明示的にチェックリストとして分解し、提示された情報が完全に明確でない場合は慎重になるよう指示しました。これにより、DeepSeek の偽通過率は両方のスコアリングモードで低下しました:基準別では 10.7% から 9.5% に、バッチ処理では 15.6% から 14.2% に減少しました。
データのためのトレースのマイニングや、プロンプティングを通じた行動のターゲット型蒸留は、検証器およびエージェント全般の改善に向けた効果的な戦略であり続けています。
法務ドメインにおけるより優れたエージェントとより効率的な検証システムの構築
検証器は、世界クラスの法務エージェントを構築するためのパズルの一部に過ぎません。オープンモデルによる検証器は、コストと性能のトレードオフを提供し、チームが評価(evals)を実行したり、RL 事後トレーニングを何桁も安価に行ったりすることを可能にし、多くの場合、まず試みること自体を現実的なものにします。また、バッチ処理のような単純な手法でも検証作業は十分に機能し、コストをさらに一桁削減できることがわかりました。
オープンモデルは、企業にとって最も重要なドメイン向けに独自に微調整された検証器を作成する機会も提供します。多くの研究では、最先端のクローズドモデルが蒸留すべきゴールドスタンダードであると仮定されていますが、本研究においてさえ、Opus、GPT-5.5、Sonnet はラベルの約 4〜5% で意見が一致していません。この信念をさらに挑戦するためのさらなる研究が必要だと私たちは考えています。
私たちは、大規模なより良い検証システムに関する研究を推進するために Harvey と提携することに興奮しています。今後の研究では、検証器の微調整とその大規模な事後トレーニングおよび評価実行への影響について研究することを楽しみにしています。
原文を表示
*Authors: Vivek Trivedy (LangChain), Jake Broekhuizen (LangChain), Harrison Chase (LangChain), Niko Grupen (Harvey), Gabe Pereyra (Harvey), Spencer Poff (Harvey), Julio Pereyra (Harvey)*
Earlier this month, Harvey released LAB, an open-source benchmark for evaluating agents on complex legal work. The initial results show that legal work is far from saturated with today’s agents.
Together with Harvey, we tackled the following question:
How can we more efficiently verify the correctness of a legal agent’s work?
Why does this matter? Legal work is a particularly difficult domain for agents because it spans many documents that fill context, requires specialized knowledge, and has strict criteria that need to be followed for an output to be acceptable.
The LAB benchmark approaches verification much like a human reviewer would. Every task in the dataset has a set of criteria that must pass for the task to pass. Every criterion is evaluated by an individual LLM judge using a verifier model. For each criterion, the verifier gets the agent output and the match_criteria it needs to measure. It outputs a verdict per criterion. Many tasks have over 50 individual criteria to verify. Making an LLM API call for each of those criteria gets expensive at scale with frontier models.
Can We Run More Efficient Verification?
The cost of running frontier verifiers creates a practical question for teams running legal-agent evaluation or training legal agents with RL:
How can you best reduce the cost of verifiers while remaining close to frontier performance?
We study two different methods of doing more efficient verification:
- Use fewer tokens
- Use cheaper tokens
First method we explore: using fewer tokens. In order to use fewer tokens, we propose running verifiers in batch. That is - rather than using an LLM call for each criterion independently, we can ask it to judge the full rubric in a single batch call.
- Per-criterion scoring: run one judge call for each rubric requirement.
- Batch scoring: run one judge call for the task and ask the judge to label every rubric requirement at once.
Second method we explore: using cheaper tokens. To use cheaper tokens we can test cheaper models during verification. We used Opus 4.7 per-criterion as the reference and compared GPT-5.5, Sonnet 4.6, DeepSeek v4 Flash, and Claude Haiku 4.5 across per-criterion and batch scoring.
Experiments to Measure Efficiency across Verifier Designs
To run our verifier experiments, we first needed to produce a set of outputs for the verifier to evaluate. To create these outputs, we ran an agent (powered by Kimi K2.6) over 40 public LAB tasks across the following practice areas: Corporate M&A, Tax, Emerging Companies/VC, and Trusts and Estates.
Across these 40 tasks were 2,348 individual rubric criteria - each is scored as pass/fail by a verifier. We first run Opus-4.7 across all criteria as a baseline. This gives us a baseline to compare against when testing GPT-5.5, Sonnet 4.6, Haiku 4.5, and DeepSeek-V4-Flash as other verifier options. Every verifier run will produce the same 2,348 criteria scores (pass/fail) and we can use these to study how they compare.
For each verifier run, we measured:
- Agreement: how often it matched Opus per-criterion labels.
- False pass: how often it passed a criterion that Opus failed.
- False fail: how often it failed a criterion that Opus passed.
- Cost: observed token cost for the 40-task verifier run.
We paid particular attention to false passes. In real world settings, a failed criterion can be escalated for further review. That is usually preferable to letting a criterion pass when it should fail in a domain like legal.
Verification, like most agent-system design, is a tradeoff between performance, cost, and time. Per-criterion verification gives the judge a narrower decision window, but it requires many more calls. Batch verification is cheaper and faster, but the judge has to track the full rubric at once.
The chart below shows cost versus label drift. The x-axis is verifier cost per 1,000 rubric criteria. The y-axis is disagreement with Opus per-criterion labels, or 100% - agreement. Lower and further left is better.
Some takeaways:
- Across the board, running in batch mode has lower match rates than running in per-criterion mode. But running batch is an order of magnitude cheaper to run for the same model as it saves on repeated input token costs.
- Even frontier models like GPT-5.5 and Opus disagree on labels - they only have a 95.7% match rate. This means that some of the datapoints may not be sufficiently specified for models to apply them as consistently as experts. This also means that targeting 100% match rate may not be realistic, and a match rate of 95.7% may be a reasonable upper bound.
- DeepSeek is a strong approximation of Opus as a verifier, both running one criterion at a time and running in batch mode. It can also be run 3 orders of magnitude more cheaply which makes it a good candidate for large data and training domains where you need to run verification at scale.
- Haiku was cheaper than Opus and Sonnet, but much more permissive. Its false-pass rates were 48.4% per-criterion and 34.7% batch, which is the wrong failure mode for legal verification.
Cost savings on post-training
Verifiers are not just used for evals. They are also used for post-training, and verification costs are amplified here, due to the multiple rollouts per task. LLM-as-judge systems turn task rubrics into reward signals, and cheaper reward signals make it practical to run more experiments, audit more rollouts, and iterate faster.
A quick pass at extrapolating costs show that DeepSeek can be run 60-1000x cheaper than frontier verifiers at scale. This becomes especially important in domains that are not easily programmatically verifiable and require some amount of LLM as a Judge to produce a reward signal.
Tuning Verifier Behavior from Traces
The results keep the prompt fixed per model and per verifier architecture (per-criterion vs batch). One additional lever we tested was targeted prompt tuning.
In order to test the effects of prompt tuning, we ran an auto-research loop on the previous results of DeepSeek compared to Opus. We looked at why & how DeepSeek diverged and tweaked the prompt over several runs. We told it optimize for false-pass rate.
One key reason for some of the DeepSeek errors with the default prompt was that DeepSeek was too willing to pass criteria when the answer was related to the requirement but did not satisfy every material part. The final prompt made the verifier decompose each piece of each criterion more explicitly as a checklist and instructed it to be cautious if the information present wasn’t totally clear. This reduced DeepSeek false-pass rates in both scoring modes: from 10.7% to 9.5% per-criterion and from 15.6% to 14.2% in batch.
Mining traces for data and doing targeted distillation of behavior via prompting continues to be an effective strategy for improving verifiers and agents in general.
Building Better Agents & More Efficient Verification Systems for the Legal Domain
Verifiers are one piece of the puzzle for building world class legal agents. Open model verifiers give us a cost-performance tradeoff that allows teams to run evals and do RL post-training orders of magnitude more cheaply, and often makes it feasible to attempt in the first place. We also find that simple methods like batching verification work reasonably well and provide another order of magnitude reduction in cost.
Open models also give firms the opportunity to fine-tune bespoke verifiers for their most crucial domains. A lot of work assumes that frontier closed models are the gold standard to distill towards, but even Opus, GPT-5.5, and Sonnet disagree on roughly 4-5% of labels in this study. We feel there’s more work to be done to challenge this belief further.
We’re excited to partner with Harvey to push forward research on better verification systems at scale. In future work, we’re excited to study the impact of fine-tuning verifiers and their impact on post-training and running evals at scale.
関連記事
マイクロソフト、テキスト記述から AI の動作テストを構築できる新ツールを発表
マイクロソフトは開発者がテキスト記述を用いて AI の動作テストを迅速に構築・実行できる新しいツールの提供を開始した。
Agent Judge:生産環境向けエージェントの長期コンテキスト評価を解決(10 分読了)
TLDR AI が紹介する「Agent Judge」は、検索・検証・適応に焦点を当て、従来の LLM 判定器が苦手とする長期コンテキストや状態保持アクションの評価精度と一貫性を向上させる手法です。
Amazon Bedrock AgentCore のデータセット管理機能を活用し、エージェントの成長に合わせて拡張可能なテストスイートを構築する方法
AWS は Amazon Bedrock AgentCore の新機能として、バージョン管理されたテストケースをデータセットとして管理する機能を公開した。これにより、オンライン信号とオフライン基準を組み合わせた評価が可能となり、エージェントの時間経過に伴う改善を正確に把握できる。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み