GPT-5.4 が話題を呼ぶ、モバイルでの AI 成長、データセンターの自立型電源化、Apple の拡散モデル研究
The Batch は、AI コーディングエージェント間の知識共有プラットフォームの必要性と、Meta によるエージェント向け SNS「Moltbook」の買収という業界動向を分析し、実用的なエージェント社会インフラの構築を提言している。
キーポイント
コーディングエージェントのための Stack Overflow の必要性
LLM で構築されたコーディングエージェントは古い API を誤用する傾向があるため、最新ドキュメントへのアクセスとエージェント間での学習共有(Context Hub)が不可欠である。
Meta による Moltbook の買収とエージェント SNS の台頭
Reddit 形式の AI エージェント向け SNS「Moltbook」が急成長し Meta に買収された背景には、エージェント同士の議論や学習への需要がある。
実用指向なエージェント社会インフラの構築
現在のエンターテインメント的な議論から脱却し、ドキュメント更新や API 発見など、人間の開発者を支援する実用的な機能に特化した新しい SNS の可能性が示唆されている。
AI コーディングエージェントの学習共有プラットフォーム構想
Andrew Ng は、コーディングエージェントが API のバグや改善点を発見した際、そのフィードバックを他のエージェントと共有する「Stack Overflow for AI」のような仕組み(Context Hub)の実現を目指している。
GPT-5.4 の高性能化と高価格設定
OpenAI は GPT-5.4 を発表し、ツール検索やネイティブなコンピューター使用能力を強化してベンチマークで最高スコアを更新したが、競合他社に比べて実行コストが大幅に高い。
モバイル AI アプリの収益化とデータセンターの自立電源化
2025 年にモバイル AI アプリの収益がゲームアプリを上回り急成長する一方で、AI データセンターの電力需要増に対応するため、Meta や OpenAI が地域グリッドに依存しない私設発電所(主に天然ガス)の建設を加速させている。
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントが自律的に学習・共有を行うための社会的基盤(Social Infrastructure)の重要性を浮き彫りにしています。特に、Meta がエージェント向け SNS を買収したことは、大企業が AI エージェント間の相互作用や知識管理市場に注目し始めていることを示す重要なシグナルです。今後は、エージェント同士の協働によるソフトウェア開発効率化が加速する可能性があります。
編集コメント
AI エージェントが単なるツールから、相互に学習し合う「社会」を形成しつつある現状を示す興味深い記事です。開発者コミュニティの知見共有プラットフォームとしての可能性は、今後の AI エコシステムにおいて重要な役割を果たすでしょう。
親愛なる皆様、
AI コーディングエージェント同士が学びを共有するための Stack Overflow は存在するべきでしょうか?
先週、私は新しい Context Hub(chub)について記事を書きました。これは、コーディングエージェントに API ドキュメンテーションを提供するための CLI ツールです。過去のコード例から学習した LLM(大規模言語モデル)を用いて構築されたコーディングエージェントは、しばしば誤ったまたは古くなった API を使用してしまいます。Chub は、最新のドキュメントへのアクセスを可能にすることでこの課題に対処します。過去一週間で Chub に対するコミュニティの熱狂的な反応(GitHub スターが 5,000 件を超え、利用が増加し、ドキュメンテーションに関するコミュニティからの貢献も続いています)に私は非常に興奮しています。皆様のご支援に感謝いたします!
Chub のビジョンの中核となる部分は、他のエージェントを助けることができるコーディングエージェントからのフィードバックを得ることです。具体的には、あるエージェントがドキュメントを取得し、それを実際に試してバグを発見したり、API を使用するより優れた方法を見つけたり、あるいはドキュメンテーションに何かが欠けていることに気づいたりした場合、これらの学びを反映したフィードバックは、ドキュメンテーションを更新する人間にとって非常に有用なものとなります。あるいは、いつかドキュメンテーションを更新するエージェントにとっても同様になるかもしれません。
エージェント向けの Reddit 風ソーシャルネットワークである Moltbook は、多くの OpenClaw エージェントが利用して急速に成長し、メタ社が今週初めに買収しました。AI エージェント同士が「魂」のような話題について議論する会話を少し面白く感じました。実用的な価値に焦点を当てた、エージェント向けの新しいタイプのソーシャルメディアにはまだ余地があると思います。
 image Stack Overflow は開発者にとって素晴らしいサービスでした。そこは質問を投稿し、回答を提供し、回答に高評価や低評価をつけることができる場所です。それは大規模言語モデル(LLM: Large Language Models)のトレーニングデータ源として優れたものとなり、多くの開発者が今ではコーディングに関する質問を Stack Overflow ではなく LLM に投げるようになりました。しかし、私は Moltbook と Stack Overflow に触発され、コーディングエージェントがドキュメントに対するフィードバックを提供して他のエージェントを支援できるようにすることが有用だと考えました。
image Stack Overflow は開発者にとって素晴らしいサービスでした。そこは質問を投稿し、回答を提供し、回答に高評価や低評価をつけることができる場所です。それは大規模言語モデル(LLM: Large Language Models)のトレーニングデータ源として優れたものとなり、多くの開発者が今ではコーディングに関する質問を Stack Overflow ではなく LLM に投げるようになりました。しかし、私は Moltbook と Stack Overflow に触発され、コーディングエージェントがドキュメントに対するフィードバックを提供して他のエージェントを支援できるようにすることが有用だと考えました。
私たちはまだ chub でこの機能を構築する初期段階にあります。(chub を使用したいが、エージェントにフィードバックを提供させたくない場合は、「feedback: false」を ~/.chub/config.yaml に追加して無効化できます。詳細については、GitHub リポジトリ をご覧ください)。私の共同研究者である Rohit Prsad 氏と Xin Ye 氏、そして私は、より多くのドキュメント作成を支援するためのカスタムエージェント型深層研究開発に取り組んでいます。コミュニティからの貢献と相まって、過去一週間でドキュメントコレクションは 100 件未満からほぼ 1000 件に成長しました。コーディングエージェントからのフィードバックが、すべてのコーディングエージェントの利益のためにこのドキュメントを継続的に改善するのに役立つことを期待しています。
ソーシャル共有は人間のためだけではありません。それはエージェントのためでもあります!多くのエージェントがお互いから学習する方法を探る中で—プライバシーとセキュリティに対する強力なセーフガードを提供することに注意しながら—私たちは AI エージェントとそれらがサービスを提供する人間の両方をより良い状態に導いていきます。
作り続けよう!
Andrew
DEEPLEARNING.AI からのメッセージ
Andrew Ng が教える「Agentic AI」では、反射 (reflection)、ツール使用 (tool use)、計画 (planning)、マルチエージェント協調 (multi-agent collaboration) の 4 つの設計パターンを網羅する、生 Python で記述された多段階の自律型ワークフローの設計方法を学びます。DeepLearning.AI 限定で提供されています。今すぐ登録!
News
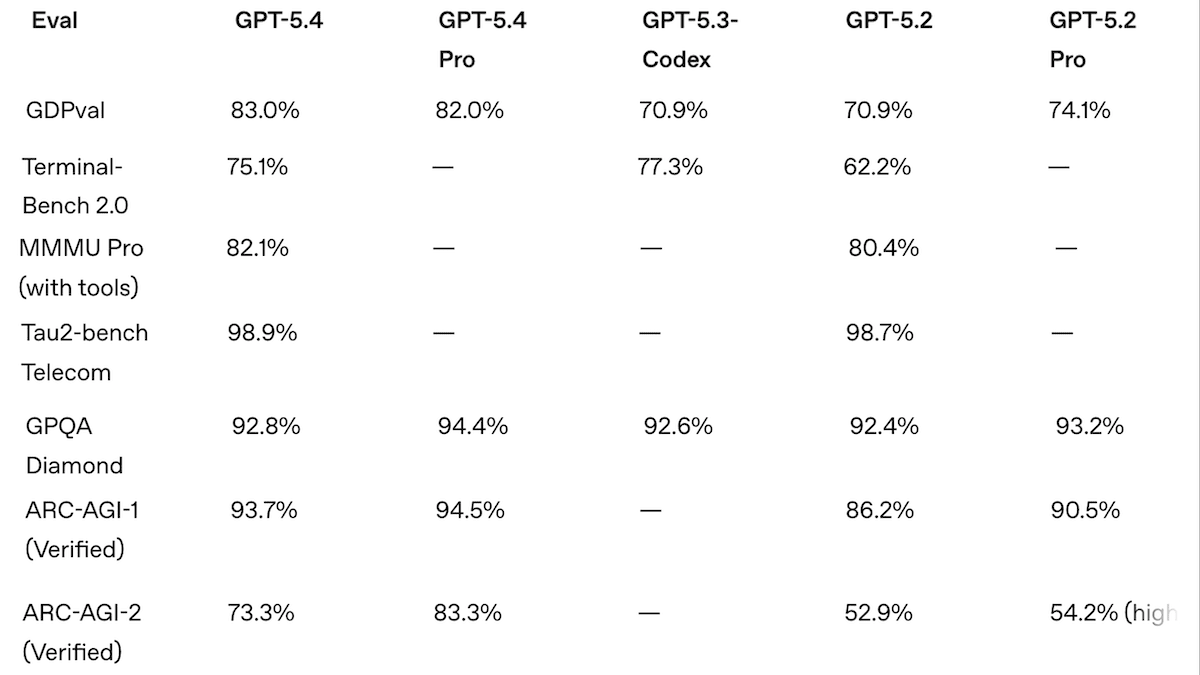
GPT-5.4 の高性能化と高価格設定
OpenAI はフラッグシップモデルを更新し、ツールの利用機能を拡張するとともに、いくつかのベンチマークで最先端の性能を達成しました。その価格は市場最高水準に設定されています。コーディング能力とエージェント機能の向上により、Anthropic の Claude Code に対する OpenAI の競合製品である Codex が飛躍的な進歩を遂げました。
新機能: GPT-5.4 は「Thinking」と「Pro」の 2 つのバリアントで提供され、どちらも GPT-5.2 と比較してコンテキストウィンドウが拡大されています。(GPT-5.3 の発売から GPT-5.4 の発売までわずか 2 日しか経過しておらず、OpenAI はその理由について説明していません。)GPT-5.4 モデルはコンピューターをネイティブに使用するように訓練されており、エージェントがツールをより効率的に見つけ利用できるよう支援する機能(ツール検索)を備えています。
- 入力/出力:テキスト、画像(最大 1,050,000 トークン)、テキスト出力(最大 128,000 トークン)
- アーキテクチャ:Mixture-of-experts(専門家混合型)トランスフォーマー
- 機能:ツール使用(Google 検索、Python コード実行、ファイル検索、関数呼び出し)、ツール検索、コンピュータ操作、調整可能な推論(低、中、高、超高)
- パフォーマンス:独立したテストにおいて、GPT-5.4 Pro は超高推論設定で GDP-Val-AA、BrowseComp、Terminal-Bench-Hard、SWE-Bench-Pro、MCP Atlas において最先端の性能を達成しました。MMMU-Pro と Humanity's Last Exam(ツールなし)では Gemini 3.1 Pro Preview にわずかに劣り、ARC-AGI-1 および ARC-AGI-2 では Gemini 3 Deep Think にわずかに劣っています。
- 利用可能状況/価格:GPT-5.4 は ChatGPT のサブスクリプション(Plus、Team、Pro プラン)で利用可能です。API を通じては、GPT-5.4 は入力/キャッシュ済み/出力トークン 100 万あたりそれぞれ $2.50/$0.25/$15 で提供され、GPT-5.4 Pro は入力/出力トークン 100 万あたり $30/$180 です。
- 知識の更新日:2025 年 8 月
- 非公開情報:パラメータ数、アーキテクチャの詳細、トレーニング手法
仕組みについて: クローズドモデルに典型的なように、OpenAI は GPT-5.4 および GPT-5.4 Pro の構築方法についてはほとんど詳細を明かしませんでした。このモデルは、ウェブから収集したテキスト、コード、画像と、ライセンスされた資料、ユーザーデータ、合成データを組み合わせて事前トレーニングされたスパース Mixture-of-experts(専門家混合型)トランスフォーマーです。多段階推論、問題解決、定理証明をカバーするデータセットを用いた強化学習によって微調整が施されました。
パフォーマンス: GPT-5.4 Pro は、Artificial Analysis による独立したテストにおいて、GPT-5.2 Pro や Claude 4.6 Opus を上回り、いくつかの最先端指標を達成しました。しかし、OpenAI 自身のテストにおいても、いくつかのタスクでは Gemini 3.1 Pro Preview に劣り、同じテストを実行するコストもより高くなりました。
- Artificial Analysis Intelligence Index は、経済的に有用な作業に焦点を当てた 10 のベンチマークの加重平均であり、GPT-5.4 Pro を xhigh レーシング設定にしたものは、推論能力において Gemini 3.1 Pro Preview とほぼ同点(推論:57 ポイント、コスト 2,950 ドル対 57.2 ポイント、コスト 892 ドル)でしたが、Claude Opus 4.6 を max レーシング設定にしたもの(53 ポイント、2,486 ドル)、GPT-5.3 Codex を xhigh レーシング設定にしたもの(54 ポイント、1,650 ドル)、そしてオープンウェイトの GLM-5(50 ポイント、547 ドル)を上回りました。同モデルは、このインデックスを構成する 10 のコンポーネントベンチマークのうち 3 つで首位に立ちました。
- GPT-5.4 Pro を xhigh レーシング設定にしたものは、Artificial Analysis のコーディングおよびエージェント(Agentic)インデックス(それぞれのカテゴリに特化した Intelligence Index のサブセット)でも首位となり、スコアはそれぞれ 57 ポイントと 69 ポイントでした。これは Gemini 3.1 Pro Preview(56 ポイント)や Claude Opus 4.6(68 ポイント)を上回る結果です。
- ARC-AGI-2 の視覚論理パズルでは、GPT-5.4 Pro を xhigh レーシング設定にしたもの(83.3%)が Gemini 3.1 Pro Preview(74.0%)を大きく上回り、Gemini 3 Deep Think(84.6%)にはわずかに及ばない結果でした。
なぜ重要なのか: OpenAI の GPT 5.4 は、一時的に Anthropic の Claude を引き離し、Google の Gemini と首位争いを繰り広げています。OpenAI は GPT-5.4 ファミリーのトークンあたりのパフォーマンス向上を強調していますが、Gemini 3.1 Pro Preview と同等のパフォーマンスを出すには依然として約 2 倍のトークン数が必要であり、その高い効率性は価格の高さによってほぼ相殺されています。GPT-5.4 Pro は最先端のコーディングモデルであり、コーディングタスクを完了するコストは Claude Opus 4.6 よりも安価です。しかし、Gemini 3.1 Preview の価格を低く抑えつつ高い全体的な知能を維持し、音声やビデオの処理能力も備えている Google の力は、無二のリーダーになることを目指すあらゆる AI 企業にとって依然として強力な障壁となっています。
私たちが考えていること: GPT-5.4 は、ご想像の通り、OpenAI 内部で開発されたベンチマークにおいて最高位を記録しています。しかし、これらの指標は、モデルが事務作業の自動化における困難な課題を解決するために構築されていることを示しています。GPT-5.4 Pro は、GDPval(法律文書の作成やカスタマーサポートの会話などの知識労働タスクにおいて専門家に対して 83% の勝率または引き分け)および OSWorld-Verified(ファイルからのスプレッドシート更新やウェブサイトのナビゲーションなどのコンピューター使用タスクで 75% の成功率を記録し、人間のベースラインである 72.4% を上回る)において印象的なパフォーマンスを示しました。この業務には高い人的コストがかかるため、GPT-5.4 Pro は、推論能力を xhigh に設定した場合でも、非常に優れたお買い得品となる可能性があります。
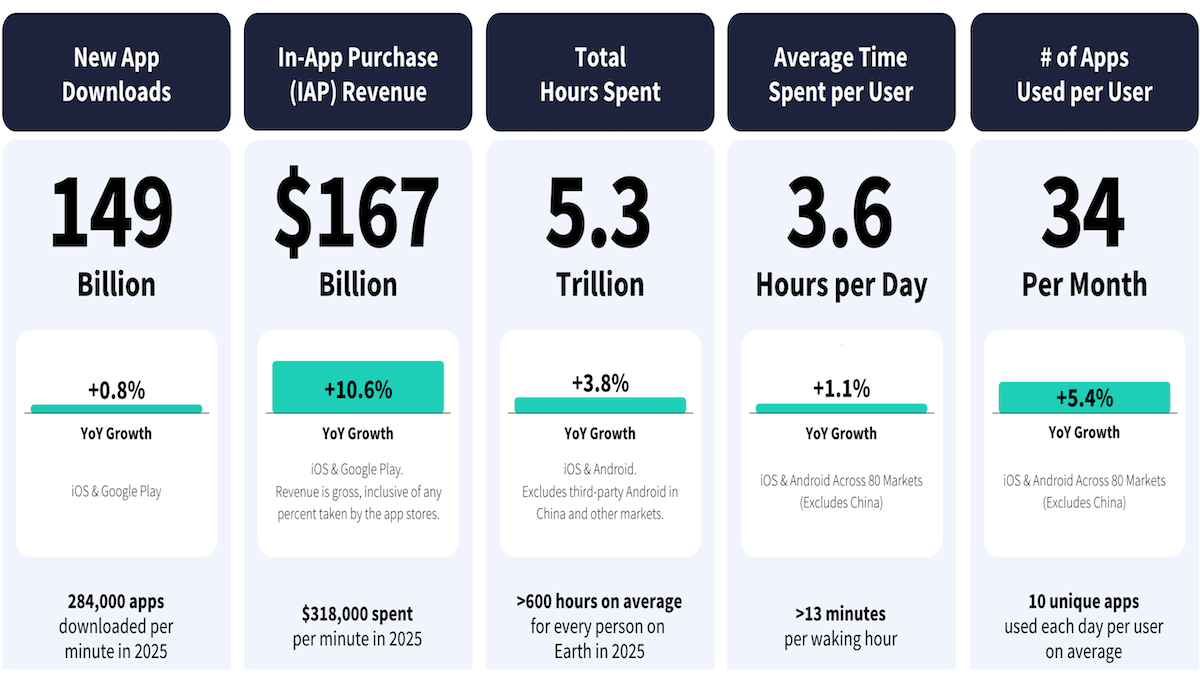
モバイル上の AI が急上昇
モバイル AI アプリのダウンロード数とそれに伴う収益が急増しています。
何が変わったか: 市場調査企業である Sensor Tower が発表した「State of Mobile 2026」レポートは、スマートフォンにおける AI アシスタント、生成型アプリ、AI コンパニオンの急速な成長を追跡しています。同社の分析によると、昨年は AI アプリへの支出により、ゲーム以外のアプリからの収益が初めてゲーム収益を上回りました。
仕組み: 著者らは 2025 年のモバイル AI 市場を評価しました。独自データおよび開発者からのデータを基に、iOS App Store と Google Play におけるダウンロード数、利用時間、アプリ内課金(広告収入は含まず)を見積もっています。他のアプリストアからはデータを取得していないため、このレポートには中国など国内企業が運営するストアから主にアプリをダウンロードする地域でのモバイル活動は反映されていません。
- 概要:AI を活用したアプリおよびダウンロードによるグローバル収益は昨年加速し、収益は 3 倍超の 50 億ドル以上となり、ダウンロード数は 2 倍超の 38 億件を超えました。
- リーダー:クリエイティブまたは生成タスクに AI を使用するものとして定義された最もダウンロード数の多い AI アプリは、OpenAI の ChatGPT で、次いで Google Gemini、DeepSeek、ByteDance の Doubao、AI 強化型検索エンジン Perplexity が続きました。OpenAI と DeepSeek はグローバルな AI ダウンロードの約 50% を占め、2023 年の 21% から増加しました(Sensor Tower がこのカテゴリの追跡を開始した年)。Amazon、Google、Microsoft などの確立されたテック企業は、過去 1 年間のダウンロードの 30% を占め、2023 年の 14% から増加しました。AI スタートアップのロングテールが最後の 20% を構成しています。
- アシスタント対ジェネレーター:トップ 10 の最もダウンロード数の多いアプリはすべて AI アシスタントでした。しかしながら、Suno の音楽ジェネレーターや ByteDance の Jimeng AI テキストから動画への生成アプリなどの生成型アプリも強い成長を示しました。トップ 10 の AI アシスタントの米国ユーザー数は、総人口のおよそ 60% に相当します。
- エンゲージメント:ユーザーは AI アプリ内で 480 億時間を費やしており、これは 2024 年の合計の約 3.6 倍、2023 年の時間数のほぼ 10 倍に相当します。
- アプリ対 Web:米国のチャットボットユーザーのうち約 1 億 1,000 万人(半数以上)が AI をモバイルアプリのみを通じて利用しており、これは 2024 年初頭の 1,300 万のモバイル専用ユーザーから増加したものです。また、AI アシスタントの利用者のうち 3,400 万人は、アプリとモバイル Web の両方を通じてアクセスしています。
ニュースの背景: モバイル AI アシスタントはまだ数年しか経っておらず、ユーザー行動は急速に変化しています。OpenAI は 2023 年 5 月に最初の ChatGPT モバイルアプリ を導入しました。現在、ほぼすべての主要な AI アシスタントがアプリとして利用可能です。今年初め、Microsoft は 研究 で、Copilot ユーザーがモバイルデバイスや一日の異なる時間帯で異なる行動をとることを発見しました。例えば、モバイルユーザーは仕事や生産性よりも健康やフィットネスについて話す傾向が強かったのです。
なぜ重要なのか: AI は、単に作業中だけでなく、デスクから離れている時にも数百万人のユーザーにとって習慣化されつつあり、モバイルデバイスがデスクトップよりも手に入りやすくなっています。そのような文脈において、AI アプリはゲーム、ソーシャルメディア、ショート動画と直接、時間と注意を巡って競合するようになっています。費やされる時間と注目は、より多くの収益と長期的な利用につながります。
私たちが考えていること: AI による収益が巨額の資本支出に追いつくかどうかという問いは、AI バブルへの懸念を生んでいます。モバイル AI 収益におけるこの爆発的な成長ペースは、非常に励みになります!
 imageMeta と OpenAI は、広大な AI データセンターの建設に電力を供給するために、地域グリッドから独立して稼働する民間発電所を構築しているテック企業の一部です。
imageMeta と OpenAI は、広大な AI データセンターの建設に電力を供給するために、地域グリッドから独立して稼働する民間発電所を構築しているテック企業の一部です。
何が変わったか: 規制書類、許可証、投資家との電話会議の議事録、その他の文書によると、米国ではデータセンターに関連する複数の自立型発電所が計画または建設中であると*ワシントン・ポスト*が報道しました。主に天然ガスで稼働するこれらの発電所はデータセンターに直接接続され、送電網への接続に伴う監督や遅延を回避します。*ポスト*の報道は、エネルギー研究者である Cleanview による調査に基づいています。この調査では、顧客に直接電力を供給しつつ送電網にも接続される「メーター後方(behind the meter)」の民間発電所を建設する 46 のプロジェクトが特定されました。そのうち 90% は 2025 年に発表されたもので、これらは米国の計画されているデータセンター容量全体の 30% を占めています。ホワイトハウスの後押しにより、Alphabet、Meta、Microsoft、OpenAI、Oracle、xAI の各社執行役員は、電気料金の上昇への懸念を和らげるため、発電所の建設と送電網のアップグレードにかかる費用を負担することに合意しました。
仕組み: 自社発電所を建設しているテック企業の名前は、利用可能な文書ではほとんど不明瞭です。これらのプロジェクトは、ギガワット規模の電力消費が予想されるデータセンターを稼働させるもので、テック企業とエネルギーインフラ構築業者、および/または地元電力会社との協力によって進められています。従来のタービンが不足しているため、一部のケースでは非典型的な発電機を用いて急速に開発が進められています。
- Meta はオハイオ州に天然ガス火力発電所 2 基を建設中であり、これにより 400 メガワットの電力を生み出す「Socrates」と呼ばれるプロジェクトを通じて、1 ギガワットを消費するデータセンターを稼働させる計画です。また、テキサス州における別の Meta プロジェクトでは、800 基以上の小規模な天然ガス発電機を接続し、1 ギガワットのデータセンター向けに 366 メガワットの電力を生成します。
- OpenAI と Oracle はニューメキシコ州で「Jupiter」と呼ばれるプロジェクトを進めています。これは大規模な天然ガス発電機を用いて、1 メガワット(注:原文の数値のまま)のデータセンターを稼働させるものです。Jupiter は、両社が展開する広範なデータセンター計画である「Stargate」の一部です。
- ワイオミング州では 1.8 メガワットのデータセンタープロジェクトが進められており、これは改造されたジェットエンジンによって動力源とされます。各エンジンからは 42 メガワット(注:原文の数値のまま)の電力が発生します。これらの発電機は Boom Supersonic 社によって設計されており、同社は航空宇宙企業で、OpenAI のサム・アルトマン CEO が株主かつ取締役会の一員でもあります。
ニュースの背景: すべての主要テック企業が、2030 年までに 5.2 兆ドル(注:原文の数値のまま)のコストがかかり、156 ギガワット(注:原文の数値のまま)を消費すると予測される データセンターの建設 を支えるのに十分な電力へのアクセスを確保しようと必死になっています。
- xAI は 2024 年、Memphis に Colossus および Colossus 2 スーパーコンピュータを収容するデータセンターを建設した際、電力網を迂回して電源を確保しました。同施設は数十基の仮設・可搬型ガスタービンの私的コレクションによって稼働していますが、これらは環境保護庁(EPA)が違法使用と判断したにもかかわらず運用されています。
- Meta は短期的には私的な発電所を建設する一方、長期的な戦略として原子力発電所の建設も進めています。これらの施設は 2030 年代初頭に運転開始予定で、同社は新型炉の建設支援および既存炉からの電力購入にコミットしています。これらの契約により、6ギガワットを超える電力供給が見込まれています。
- Alphabet、Amazon、Microsoft はそれぞれ小規模な契約を結び原子力エネルギーの確保を図っています。Alphabet はアイオワ州で使用停止中の原子力発電所の再稼働に取り組んでおり、Amazon は炉開発企業 X-Energy に投資し、Microsoft は 2026 年から 2030 年の間に推定 170 億ドルで 10.5ギガワットの新たな再生可能エネルギー容量を購入することに合意しています。
なぜ重要か: データセンターにおける私的電力の台頭は、AI 企業が現在のエネルギー供給業者が対応できる速度よりも速くキャパシティを増強しようとしていることによるボトルネックを反映しています。これは AI インフラ、発電所、そして公共事業体が相互に作用する様式の変化を示しており、その影響はテクノロジー企業を超えた広範な領域に及んでいます。
- AI による需要の高まりにより、2025 年の電力料金はインフレ率の倍以上の上昇を示したとゴールドマン・サックスは指摘しています。民間発電所がグリッドへの負担を軽減することで、この影響を安定させる助けとなる可能性があります。しかし、ワシントン・ポストが引用する専門家は、民間エネルギー発電のブームが生産設備や専門知識に対する需要を増加させ、結果として電力料金を押し上げる恐れがあると懸念しています。
- ガス火力発電所の増加は、大気中の温室効果ガスの増加を意味し、これが気候変動を加速させています。大手 AI 企業は再生可能エネルギーの利用と温室効果ガス排出の相殺に尽力していますが、建設ペースの速さから化石燃料が便利なものとして利用されてしまいます。民間電力プロジェクトの公的な発表では再生可能エネルギーや原子力、水素発電が強調されていますが、「2025 年と 2026 年に実際に設置されている設備はほぼ完全にガス火力です」とクリーンビューは記述しています。
私たちが考える: 最近まで、クラウドコンピューティングのリーダーたちは風力や太陽光などの再生可能エネルギー源に大きく依存しており、時にはバッテリーの支援を受けていました。ガス火力発電所への移行は、カーボンニュートラルを維持するための努力に対する残念な逆行です。
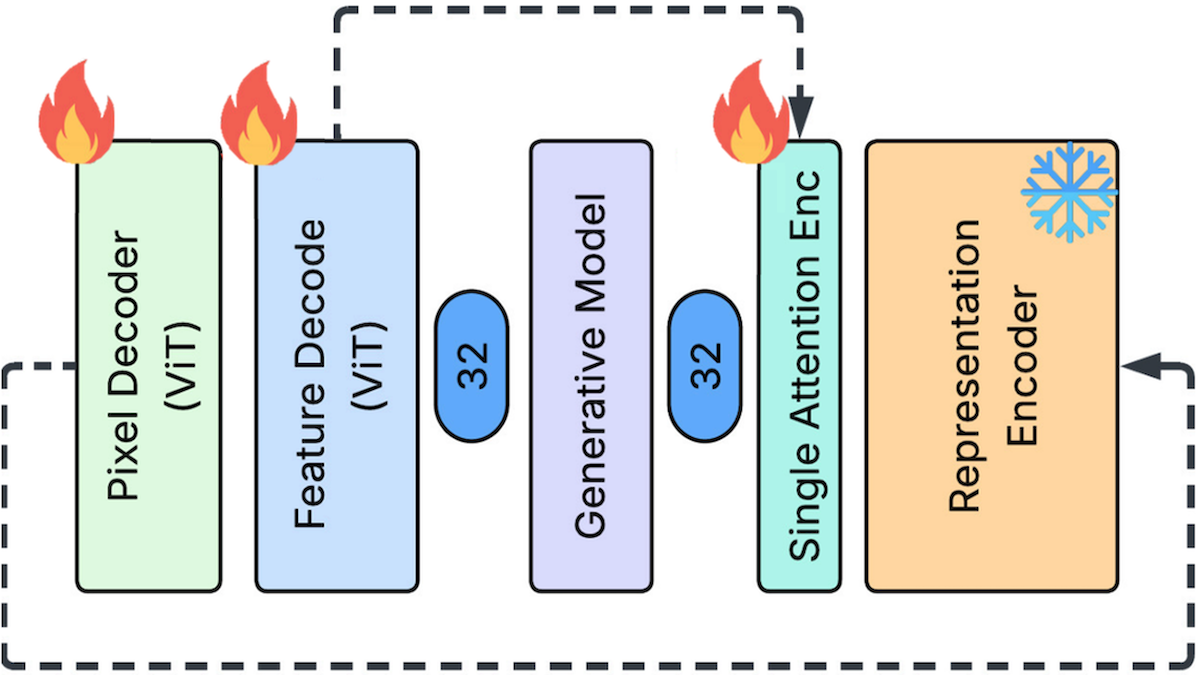
超高速拡散学習
研究によると、画像生成ではなく分類、セグメンテーション、検索といったビジョンタスク用に構築された事前学習済みエンコーダーからの埋め込みを再構成することを学ぶことで、拡散型画像生成器は若干でも高速に訓練できることが示されています。最新の研究では、これらの埋め込みのより小さなバージョンを再構成するように拡散モデルが学ぶ場合、劇的に高速に訓練できることが明らかになっています。
何が新しいか: Apple の Yuan Gao 氏、Chen Chen 氏、Tianrong Chen 氏、Jiatao Gu 氏は、ビジョンエンコーダー DINOv2 が生成する埋め込みを再構成することを学習した拡散型画像生成器である Feature Auto-Encoder(FAE)を提案しました。以前の研究では DINOv2 の埋め込みの巨大なサイズに足踏みしていましたが、FAE は再構成する前にそれらを縮小することを学習しました。
重要な洞察: デコーダーによって画像に変換される埋め込みからノイズを除去する潜在拡散モデルは、より大きな埋め込みからより良い画像を生成します。DINOv2 や SigLIP などのビジョンエンコーダーによって生成される埋め込みは、その規模が大きく意味論的に豊かであるため、この要件に合致します。このアプローチは出力の質を向上させるだけでなく、画像生成器がビジョンエンコーダーの事前学習を活用するため、トレーニングの加速も期待できます。一方で、より大きな埋め込みを処理するにはより大規模なアーキテクチャが必要となり、トレーニング量が大幅に増加するため、速度向上の効果が相殺されてしまいます。解決策として、2 つ目の小型エンコーダーを用いてビジョンエンコーダーの埋め込みを縮小する方法があります。拡散モデルは、この小さな埋め込みからノイズを除去することを学習でき、これにはより少ないトレーニングで済みます。その後、デコーダーが埋め込みを元の埋め込み空間に拡張し、大きな埋め込みの利点を復元した上で、最終的に画像を生成します。
仕組み: 推論時、FAE は以下のように動作します。ノイズと ImageNet クラスまたはテキスト埋め込みが与えられると、SiT(潜在拡散モデル)が縮小された画像埋め込みを生成します。この埋め込みを受け取ると、埋め込みデコーダがフルサイズの埋め込みを生成し、そこから画像デコーダが画像を生成します。著者らは、入力テキストラベルから画像を生成する 2 つの独立した FAE システム(ImageNet を用いて 256x256 ピクセル解像度で生成)と、テキスト記述から画像を生成するシステム(CC12M を用いて)を訓練しました。
- トレーニング中、FAE はフルサイズと縮小された埋め込みの両方を生成できるよう学習するためにターゲットを必要としました。画像が与えられると、DINOv2 がフルサイズの埋め込みを生成します。このフルサイズの埋め込みに対して、小さなエンコーダ(単一のアテンション層)が縮小された埋め込みを生成します。さらに、この縮小された埋め込みに対して、埋め込みデコーダがそれをフルサイズに拡張します。
- 拡張された埋め込みが与えられると、画像デコーダは画像の生成を学習しました。これは3 つの損失項を使用しました:(i) 予測値と正解ピクセル間の差を最小化する再構成損失;(ii) 未同定のモデルが予測画像と正解画像の両方を埋め込み、その距離を最小化する知覚損失;および (iii) 未同定の判別器が予測画像と正解画像を分類し、画像デコーダがそれを欺くように訓練する敵対的損失。
- ノイズを加えた縮小された埋め込みと、事前学習済み SigLIP 2 によって生成された ImageNet クラスまたはテキスト埋め込みが与えられると、SiT はノイズの除去を学習します。結果: FAE はトレーニング速度が速い一方で、最先端の拡散モデルと比較して同等のパフォーマンスを発揮しました。
- ラベルから ImageNet 画像を生成する際、FAE(6.75 億パラメータ)は 800 エポックのトレーニング後に FID 1.29 を達成しました。これは、DINOv2 の埋め込みを縮小せずに再構築することを学習した拡散型画像生成器である RAE(6.76 億パラメータ)よりも優れた結果です。RAE は 800 エポック後に FID 1.41 を達成しました。一方、FAE は約 7 倍の高速化を成し遂げ、わずか 110 エポックで FID 1.41 に到達しました。
- テキスト記述から画像を生成する際、FAE(11 億パラメータ)は MS COCO データセット上で FID 6.9 を達成しました。この性能は、約 4 倍のトレーニングデータで学習して FID 6.88 を達成した Re-Imagen(32 億パラメータ)と同等です。
なぜ重要なのか: ビジョンタスク用に訓練されたエンコーダと、画像生成用に訓練されたエンコーダでは、獲得している知識が異なります。この知識はより高品質な画像の生成に役立ちますが、その知識は処理能力を多く必要とする大きな埋め込みベクトルの中に存在しています。これを縮小することで、画像生成器がより実用的な形でこの知識を利用できるようになり、はるかに短い時間で高品質な画像を生成することが可能になります。
私たちが考えていること: この研究は、ノイズ除去の技術自体を向上させるのではなく、より豊かな埋め込み空間からのノイズ除去を行うことで、トレーニング時間を短縮しながらより良い画像を生み出しています。
原文を表示
Dear friends,
Should there be a Stack Overflow for AI coding agents to share their learnings with each other?
Last week, I wrote about the new Context Hub (chub), a CLI tool to provide API documentation to coding agents. Coding agents built using LLMs that learned from old code examples often use incorrect or outdated APIs. Chub addresses this by letting them access the latest documentation. I’ve been thrilled at the community enthusiasm for chub over the past week (over 5K github stars, growing usage, and community contributions of documentation). Thank you for your support!
A key part of the vision for chub was getting feedback from coding agents that can help other agents. Specifically, if an agent obtains a piece of documentation, tries it out, and discovers a bug, finds a superior way to use an API, or realizes the documentation is missing something, feedback reflecting these learnings can be very useful for humans updating the documentation. Or perhaps someday for agents updating the documentation.
Moltbook, a Reddit-like social network for agents, grew rapidly with many OpenClaw agents using it, and Meta acquired it earlier this week. I found the conversations among AI agents speculating about all sorts of topics like their “souls” mildly entertaining. I think there’s room for a new type of social media for agents that’s focused on being useful in practical ways.
Stack Overflow has been a great service for developers. It has been a place where we can ask questions, answer questions, and upvote/downvote answers. It turned into a great source of training data for LLMs, and many developers now ask coding questions to LLMs rather than Stack Overflow. But I am inspired by Moltbook and Stack Overflow to think that it will be useful to let coding agents contribute their feedback on documentation so as to help other agents.
We’re still in the early stages of building this capability in chub. (If you want to use chub but don’t want your agent to contribute feedback, you can disable this by adding “feedback: false” to ~/.chub/config.yaml; see our github repo for details). My collaborators Rohit Prsad and Xin Ye and I are working on a custom agentic deep researcher to help us write more documentation. Together with community contributions, over the past week, we have grown the document collection from under 100 to almost 1000. I expect the feedback from coding agents will help to keep refining this documentation for the benefit of all coding agents.
Social sharing isn’t only for humans. It’s also for agents! As we navigate ways for many agents to learn from each other — being careful to provide strong safeguards for privacy and security — we will make both AI agents and the humans they serve better off.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
In *Agentic AI*, taught by Andrew Ng, you’ll learn to design multi-step, autonomous workflows in raw Python covering four design patterns: reflection, tool use, planning, and multi-agent collaboration. Available exclusively at DeepLearning.AI. Enroll now!
News
GPT-5.4’s Higher Performance, Higher Price
OpenAI updated its flagship models, extending the ability to use tools and setting the state of the art on a handful of benchmarks, and priced them at the top of the market. Its coding and agentic abilities have enabled Codex, OpenAI’s competitor to Anthropic’s Claude Code, to leap ahead.
What’s new: GPT-5.4 comes in two variants, Thinking and Pro, both with an expanded context window relative to GPT-5.2. (Only two days elapsed between the launch of GPT-5.3 and GPT-5.4, and OpenAI offered no explanation.) GPT-5.4 models are trained to use computers natively and help agents find and use tools more efficiently, a capability called tool search.
- Input/output: Text, images in (up to 1,050,000 tokens), text out (up to 128,000 tokens)
- Architecture: Mixture-of-experts transformer
- Features: Tool use (Google search, Python code execution, file search, function calling), tool search, computer use, adjustable reasoning (low, medium, high, xhigh)
- Performance: In independent tests, GPT-5.4 Pro with xhigh reasoning achieved state of the art on GDP-Val-AA, BrowseComp, Terminal-Bench-Hard, SWE-Bench-Pro, and MCP Atlas; it’s just behind Gemini 3.1 Pro Preview on MMMU-Pro and Humanity’s Last Exam (without tools) and just behind Gemini 3 Deep Think on ARC-AGI-1 and ARC-AGI-2
- Availability/price: GPT-5.4 is available in ChatGPT via subscription at Plus, Team, and Pro tiers. Via API, GPT-5.4 is available for $2.50/$0.25/$15 per 1 million input/cached/output tokens, and GPT-5.4 Pro is priced at $30/$180 per 1 million input/output tokens.
- Knowledge cutoff: August 2025
- Undisclosed: Parameter count, architecture details, training methods
How it works: As is typical of closed models, OpenAI disclosed few details about how it built GPT-5.4 and GPT-5.4 Pro. The model is a sparse mixture-of-experts transformer pretrained on text, code, and images scraped from the web alongside licensed materials, user data, and synthetic data. It was fine-tuned via reinforcement learning on datasets that covered multi-step reasoning, solving problems, and proving theorems.
Performance: GPT-5.4 Pro leaped over GPT-5.2 Pro and Claude 4.6 Opus to achieve a number of state-of-the-art metrics in independent tests by Artificial Analysis. But even in OpenAI’s own tests, it underperformed Gemini 3.1 Pro Preview in several tasks and cost more to run the same tests.
- On the Artificial Analysis Intelligence Index, a weighted average of 10 benchmarks that focus on economically useful work, GPT-5.4 Pro set to xhigh reasoning nearly tied Gemini 3.1 Pro Preview with reasoning (57 points at a cost of $2,950 vs. 57.2 points at a cost of $892), but outperformed Claude Opus 4.6 set to max reasoning (53 points, $2,486), GPT-5.3 Codex set to xhigh reasoning (54 points, $1,650), and the open-weights GLM-5 (50 points, $547). It led three of the index’s 10 component benchmarks.
- GPT-5.4 Pro set to xhigh topped Artificial Analysis’ Coding and Agentic indices (subsets of the Intelligence Index devoted to each broad category), with scores of 57 and 69 points, topping Gemini 3.1 Pro Preview (56 points) and Claude Opus 4.6 (68 points).
- On ARC-AGI-2 visual logic puzzles, GPT-5.4 Pro set to xhigh (83.3 percent) came in ahead of Gemini 3.1 Pro Preview (74.0 percent) and fractionally behind Gemini 3 Deep Think (84.6 percent).
Why it matters: OpenAI’s GPT 5.4 has vaulted over Anthropic’s Claude — for the moment — to challenge Google’s Gemini for the top spot. OpenAI touts the GPT-5.4 family’s improved performance per token, but it still requires twice as many tokens as Gemini 3.1 Pro Preview to match the latter’s performance, and its higher efficiency is largely negated by its higher price. GPT-5.4 Pro is a state-of-the art coding model, and costs less than Claude Opus 4.6 to complete coding tasks. But Google’s ability to keep Gemini 3.1 Preview’s price low and overall intelligence high, along with its ability to process audio and video, remains a formidable obstacle for any AI company that aims to become the undisputed leader.
We’re thinking: GPT-5.4 ranks highest on benchmarks developed internally by OpenAI, as you would expect. But these metrics show that the models are built to solve hard problems in automating office work. GPT-5.4 Pro turned in impressive performance on GDPval (83 percent win or tie rate against professionals across knowledge-work tasks like writing legal briefs and customer-support conversations) and OSWorld-Verified (75 percent success rate on computer use tasks like navigating websites and updating spreadsheets from files, above the 72.4 percent human baseline). Given the high human costs of this work, GPT-5.4 Pro, even at xhigh reasoning, may turn out to be a bargain.
AI on Mobile Skyrockets
Downloads of mobile AI apps and resulting revenue are surging.
What’s new: The State of Mobile 2026 report by Sensor Tower, a market research firm, tracks the rapid growth of AI assistants, generative apps, and AI companions on smartphones. Last year, thanks to spending on AI apps, revenue from non-game apps exceeded gaming revenue for the first time, according to the firm’s analysis.
How it works: The authors evaluated the market for mobile AI in 2025. They estimated numbers of downloads, hours of use, and in-app revenue (but not advertising revenue) from the iOS App Store and Google Play based on proprietary data and data from developers. They did not obtain data from other app stores, so the report doesn’t reflect mobile activity in regions such as China, where users download apps mostly from stores run by domestic companies.
- Overview: Global revenue from AI-powered apps and downloads accelerated last year. Revenue tripled to more than $5 billion, while downloads doubled to over 3.8 billion.
- Leaders: The most-downloaded AI app, defined as one that uses AI for creative or generative tasks, was OpenAI ChatGPT followed by Google Gemini, DeepSeek, ByteDance Doubao, and AI-enhanced search engine Perplexity. OpenAI and DeepSeek accounted for almost 50 percent of global AI downloads, up from 21 percent in 2023, when Sensor Tower began tracking this category. Established tech companies like Amazon, Google, and Microsoft accounted for 30 percent of downloads in the past year, up from 14 percent in 2023. The long tail of AI startups made up the last 20 percent.
- Assistants versus generators: All of the top 10 most-downloaded apps were AI assistants. Nonetheless, generative apps like the Suno music generator and Bytedance’s Jimeng AI text-to-video app showed strong growth. The number of U.S. users of the top 10 AI assistants amounted to roughly 60 percent of the total population.
- Engagement: Users spent 48 billion hours in AI apps, roughly 3.6 times the total in 2024 and nearly 10 times the number of hours in 2023.
- Apps versus web: Around 110 million U.S. chatbot users — more than half — used AI exclusively via mobile apps, up from 13 million mobile-only users at the beginning of 2024. Another 34 million users of AI assistants gain access to them via both apps and the mobile web.
Behind the news: Mobile AI assistants are only a few years old, and user behavior is changing quickly. OpenAI introduced its first ChatGPT mobile app in May 2023. Today nearly every major AI assistant is available as an app. Earlier this year, Microsoft found that Copilot users behaved differently on mobile devices and at different times of day. For instance, mobile users were more likely to discuss health and fitness than work and productivity.
Why it matters: AI is becoming habitual for millions of users, not just when they’re working but also when they’re away from their desks and mobile devices are more handy than desktops. In that context, AI apps increasingly compete for time and attention directly with games, social media, and short-form videos. Both time and attention spent lead to more revenue and long-term use.
We’re thinking: The question whether AI-driven revenue will catch up to enormous capital expenditures has led to worries about an AI bubble. This blistering pace of growth in mobile AI revenue is encouraging!
Meta and OpenAI are among the tech companies that are building private power plants that will operate independently of regional grids to supply electricity for their massive buildout of AI data centers.
What’s new: Several off-grid power plants associated with data centers are planned or under construction in the United States, according to regulatory filings, permits, transcripts of conference calls with investors, and other documents, *The Washington Post* reported. Fueled primarily by natural gas, the plants will be connected directly to data centers, sidestepping the oversight and delays that come with grid connections. The *Post*’s report is based on a study by energy researcher Cleanview that identified 46 projects, 90 percent of them announced in 2025, to build private power plants that are “behind the meter,” meaning they supply electricity directly to a customer but also connect to the grid. Together they account for 30 percent of all planned data-center capacity in the U.S. Spurred by the White House, executives at Alphabet, Meta, Microsoft, OpenAI, Oracle, and xAI agreed to shoulder the costs of building power plants and upgrade the grid to soothe worries about rising electricity prices.
How it works: The names of the tech companies that are building their own power plants are largely obscure in the available documents. The projects, which will drive data centers that are expected to consume gigawatts of power, involve collaborations between tech companies, energy infrastructure builders, and/or local power companies. They’re being developed rapidly, in some cases using atypical generators, as conventional turbines are in short supply.
- Meta is building two private gas-fired plants in Ohio that will generate 400 megawatts, a project called Socrates, to drive a data center that will consume 1 gigawatt. Another Meta project in Texas will connect more than 800 small gas-fired generators to generate 366 megawatts for a 1-gigawatt data center.
- OpenAI and Oracle have a project in New Mexico called Jupiter. It will use large-scale natural gas generators to power a 1 megawatt data center. Jupiter is part of the companies’ broader data-center effort known as Stargate.
- A 1.8-megawatt data-center project in Wyoming will be powered by modified jet engines, each of which will produce 42 megawatts. The generators are designed by Boom Supersonic, an aerospace company partly owned by OpenAI CEO Sam Altman who also sits on its board of directors.
Behind the news: All the major tech companies have been scrambling to lock down access to electricity sufficient to support a data-center buildout that is projected to cost $5.2 trillion and consume 156 gigawatts by 2030.
- xAI bypassed the grid to power data centers in 2024, when the company built data centers in Memphis to house its Colossus and Colossus 2 supercomputers. The facilities are powered by a private collection of dozens of temporary, mobile gas turbines despite a ruling by the Environmental Protection Agency that they were being used illegally.
- Meta, in addition to building private power stations in the short term, is pursuing a long-term strategy to build nuclear power plants, which are scheduled to come online in the early 2030s. The company committed to help build new reactors and to purchase electricity from older reactors. These deals are expected to supply more than 6 gigawatts.
- Alphabet, Amazon, and Microsoft have entered into smaller agreements to obtain nuclear energy. Alphabet is working to reopen a disused nuclear plant in Iowa, Amazon invested in the reactor developer X-Energy, and Microsoft agreed to buy 10.5 gigawatts of new renewable energy capacity between 2026 and 2030 for an estimated $17 billion.
Why it matters: The rise of private power for data centers reflects a bottleneck as AI companies plan to increase their capacity faster than current energy suppliers can meet. It signals a shift in the ways AI infrastructure, power plants, and public utilities interact, with implications that go well beyond tech companies.
- Demand for AI caused electricity prices to rise at more than double the rate of inflation in 2025, according to Goldman Sachs. Private power plants could help stabilize that impact by reducing the burden on the grid. However, an expert quoted by The Washington Post worries that a boom in private energy generation will drive up electricity prices by boosting demand for generation equipment and expertise.
- More gas-fired power plants mean more greenhouse gases in the atmosphere, which are driving climate change. Although big AI companies work hard to use renewable energy and offset greenhouse-gas emissions, the pace of building makes fossil fuels expedient. While public announcements of private-power projects have emphasized renewable, nuclear, or hydrogen power, “the equipment actually being installed in 2025 and 2026 is almost entirely gas-fired,” Cleanview writes.
We’re thinking: Until recently, the cloud-computing leaders have leaned heavily on renewable energy sources such as wind and solar power, sometimes with an assist from batteries. Their move toward gas-fired power plants is an unfortunate reversal of the effort to remain carbon-neutral.
Lightning-Fast Diffusion Learning
Research shows that diffusion image generators can train somewhat faster if they learn to reconstruct embeddings from a pretrained encoder that’s built for vision tasks like classification, segmentation, and retrieval — not image generation. Recent work shows they can train dramatically faster if the diffusion model learns to reconstruct a smaller version of these embeddings.
What’s new: Yuan Gao, Chen Chen, Tianrong Chen, and Jiatao Gu at Apple proposed Feature Auto-Encoder (FAE), a diffusion image generator that learned to reconstruct embeddings produced by the vision encoder DINOv2. Where earlier work bogged down on the large size of DINOv2’s embeddings, FAE learned to shrink them before reconstructing them.
Key insight: Latent diffusion models, which remove noise from embeddings that a decoder then turns into images, produce better images from larger embeddings. Embeddings produced by vision encoders such as DINOv2 and SigLIP fit the bill: They’re large and semantically rich. This approach not only improves the output, it potentially accelerates training because the image generator takes advantage of the vision encoder’s pretraining. On the other hand, processing larger embeddings requires a larger architecture and significantly more training, which counteracts much of the speed-up. A solution is to shrink the vision encoder’s embeddings using a second, smaller encoder. The diffusion model can learn to remove noise from this smaller embedding, which requires less training. Then decoders can expand the embedding to its original embedding space, restoring the benefits of the larger embedding, and ultimately produce an image.
How it works: At inference, FAE works like this: Given noise and an ImageNet class or text embedding, SiT (a latent diffusion model) generates a shrunken image embedding. Given that embedding, an embedding decoder produces a full-size embedding, from which an image decoder produces an image. The authors trained two separate FAE systems to generate images from input text labels (using ImageNet at 256x256-pixel resolution) and text descriptions (using CC12M.)
- During training, FAE needed targets to learn to generate the full-size and shrunken embeddings. Given an image, DINOv2 produced a full-size embedding. Given the full-size embedding, a small encoder (a single attention layer) produced the shrunken embedding. Given the shrunken embedding, an embedding decoder expanded it to full size.
- Given the expanded embedding, an image decoder learned to produce an image. It used three loss terms: (i) a reconstruction loss that minimized the difference between predicted and ground-truth pixels; (ii) a perceptual loss in which an unidentified model embedded both a predicted image and ground truth, and the loss term minimized the distance between them; and (iii) an adversarial loss in which an unidentified discriminator classified predicted images and ground truth, and the loss term trained the image decoder to fool it.
- Given a noisy version of a shrunken embedding plus an ImageNet class or text embedding produced by a pretrained SigLIP 2), SiT learned to remove the noise.
Results: FAE performed comparably to state-of-the-art diffusion models while training faster.
- Generating ImageNet images from labels, FAE (675 million parameters) achieved 1.29 FID (a measure of the difference between Inception-V3’s embeddings of an original image and a generated version, lower is better) after training for 800 epochs. This was better than RAE (676 million parameters), a diffusion image generator that learned to reconstruct DINOv2 embeddings without shrinking them. RAE achieved 1.41 FID after 800 epochs. FAE reached 1.41 FID after around seven times faster, in 110 epochs.
- Generating images from text descriptions, FAE (1.1 billion parameters) achieved 6.9 FID on MS COCO. This performance was similar to Re-Imagen (3.2 billion parameters), which reached 6.88 FID after training on roughly four times more training data.
Why it matters: Encoders trained for vision tasks have different knowledge than encoders trained for image generation. That knowledge can help to generate better images, but it resides in bigger embeddings that require more processing power to handle. Shrinking them makes this knowledge available to image generators in a more practical way, making it possible to generate high-quality images in much less time.
We’re thinking: This work produces better images in less training time not by getting better at removing noise, but by removing noise from a richer embedding space.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み