GitHubの利用状況に関する最新情報
GitHubは、エージェント型開発ワークフローの急激な拡大による負荷増大を受け、インフラ容量を30倍に拡張し、アーキテクチャの分離とクラウド移行を進めて可用性の向上を図っている。
キーポイント
スケーリング計画の大幅な見直し
当初10倍とする予定だった容量拡張計画を、急増するリポジトリ作成やAPI利用などの需要に対応するため30倍規模に引き上げている。
エージェント型開発による負荷の急増
2025年12月以降、AIエージェントを活用した開発ワークフローが加速し、プルリクエストや自動化処理のトラフィックが指数関数的に増加している。
アーキテクチャの刷新と単一障害点の排除
GitやGitHub Actionsなどの重要サービスを他のワークロードから分離し、Rubyモノリシックコードの一部をGoへ移行させるなど、システムの耐障害性を高めている。
優先順位の見直しと短期的な対策
新機能開発を一時停止し、可用性確保と容量拡張を最優先とする方針を示しつつ、データベース負荷軽減やキャッシュ設計の見直しなどの短期的対策を実施している。
マルチクラウドへの移行と大規模モノレポへの対応
将来のレジリエンス、低レイテンシ、柔軟性を実現するためマルチクラウドへの移行を進めており、大規模モノレポの増加に対応するためGitシステムとプルリクエスト体験の強化に投資している。
4月23日のマージキュー障害とプロセス改善
スクイッシュマージ方式を使用するマージキューで、複数のプルリクエストを含む場合に誤ったマージコミットが生成される問題が発生したが、データ損失はなかった。このプロセス上の失敗を是正し、再発防止策を講じている。
4月27日の検索障害と根本原因調査
ボットネット攻撃によりElasticsearchクラスターが過負荷となり検索結果が返されなくなる障害が発生したが、Git操作やAPIへの影響はなくデータ損失もなかった。現在も根本原因分析を進めている。
影響分析・編集コメントを表示
影響分析
この発表は、生成AI時代におけるソフトウェア開発プロセスの変革が、基盤インフラにどのような物理的制約をもたらすかを浮き彫りにしている。GitHubの対応は、単なるスケーリングの問題ではなく、AIエージェントが生成する高頻度・複雑なAPI呼び出しに対するシステム設計の転換点を示唆しており、他のコードホスティングプラットフォームやSaaS企業にも同様のインフラ刷新を迫る波及効果がある。
編集コメント
AIエージェントによる開発自動化が単なる効率化ツールを超え、インフラ設計の根本的な見直しを必要とするレベルに達していることを示す重要な事例である。開発者は、AI利用に伴うシステム負荷への理解を深める必要がある。
最近発生した2つのインシデントを踏まえ、GitHubの稼働状況に関する最新情報をお伝えします。これら2つのインシデントはいずれも許容できるものではなく、お客様にご迷惑をおかけしたことを深くお詫び申し上げます。これらの詳細について共有するとともに、信頼性を向上させるために私たちが実施した施策および現在進行中の取り組みについて説明させていただきます。
2025年10月、GitHubのキャパシティを10倍に拡大する計画の実行を開始し、信頼性とフェイルオーバー(障害時切り替え)の大幅な向上を目指しました。2026年2月までに、現在のスケールの30倍に対応する設計が必要であることが明確になりました。
この主な要因は、ソフトウェアの構築方法が急速に変化していることです。2025年12月下旬以降、エージェント型開発ワークフロー(agentic development workflows)が急激に加速しました。ほぼすべての指標において、その方向性はすでに明確です:リポジトリの作成、プルリクエストのアクティビティ、API使用量、自動化、大規模リポジトリのワークロードがすべて急速に成長しています。
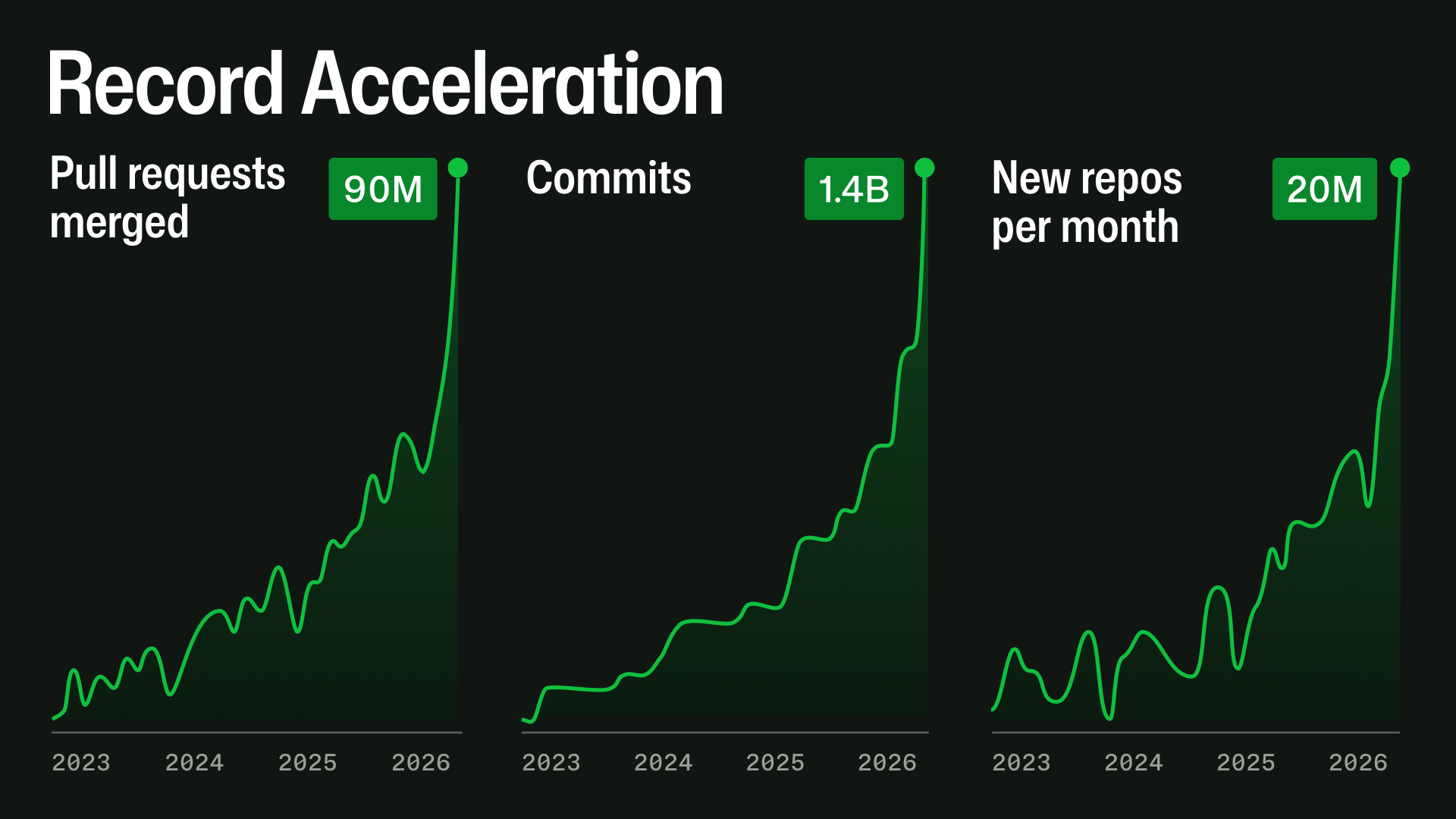
この指数関数的な成長は、一度に一つのシステムに負荷をかけるわけではありません。1つのプルリクエストが、Gitストレージ、マージ可能性チェック、ブランチ保護、GitHub Actions、検索、通知、権限管理、Webhooks、API、バックグラウンドジョブ、キャッシュ、データベースなど複数のシステムに波及影響を与えます。高スケール環境では、小さな非効率性が累積します:キューが深まり、キャッシュミスがデータベース負荷となり、インデックスが遅れ、リトライがトラフィックを増幅し、1つの低速な依存関係が複数の製品体験に影響を及ぼす可能性があります。
私たちの優先順位は明確です。まず可用性、次に容量、そして新機能です。不要な作業を削減し、キャッシングを改善し、重要サービスを分離し、単一障害点を排除し、パフォーマンスが敏感な処理経路をこれらのワークロード用に設計されたシステムに移行しています。これは分散システムの作業であり、隠れた結合を減らし、被害の範囲を限定し、あるサブシステムに圧力がかかった場合でもGitHubが適切に機能低下する(graceful degradation)ようにすることを目指しています。私たちは急速に進歩していますが、これらのインシデントは、まだ作業が必要な箇所を示す例です。
私たちが行っていること
短期的には、Webフックを別のバックエンド(MySQL以外)に移行したことで予想より早く現れたさまざまなボトルネックを解決する必要がありました。また、データベースの負荷を大幅に削減するために、認証および認可フローを見直すためにユーザーセッションキャッシュを再設計しました。さらに、Azureへの移行を活用して、より多くのコンピューティングリソースを確保しました。
次に、GitやGitHub Actionsといった重要サービスを他のワークロードから分離し、単一障害点を最小限に抑えることで被害の範囲を限定することに注力しました。この作業は、切り離す必要があるものや、さまざまな攻撃から正当なトラフィックへの影響を最小限に抑える方法を理解するために、依存関係や異なる階層のトラフィックを慎重に分析することから始まりました。その後、リスクの順序に従ってそれらに対処しました。同様に、パフォーマンスやスケーラビリティが敏感なコードをRubyモノリシックアプリケーションからGoへ移行する一部の作業を加速しました。
私たちはすでに小規模なカスタムデータセンターからパブリッククラウドへの移行を進めていましたが、マルチクラウドへの移行経路の構築に取り掛かりました。この中長期的な対策は、将来必要となるレジリエンス(耐障害性)、低レイテンシ、および柔軟性を達成するために不可欠です。
GitHub 上のリポジトリ数は過去最高ペースで増加していますが、より困難なスケーリングの課題として、大規模モノレポ(monorepo)の増加が挙げられます。過去3ヶ月間、私たちはこの傾向に対応するため、git システム内部およびプルリクエストの体験において大幅な投資を行ってきました。
私たちは近日中、効率性とスケーラビリティを高めるための広範な作業内容と新しい API デザインについて、別の記事で詳しく説明する予定です。この取り組みの一環として、毎日数千件のプルリクエストを扱うリポジトリにとって重要となるマージキュー(merge queue)の操作の最適化にも投資を行いました。
最近のインシデント
直近2つのインシデントは原因と影響が異なりましたが、どちらも私たちが可用性、分離(isolation)、および爆発半径の縮小に注力する理由を反映しています。
4月23日のマージキューインシデント
4月23日、プルリクエストでマージキューの操作に影響する回帰(regression)が発生しました。
スクイッシュマージ(squash merge)方式を使用してマージキュー経由でマージされたプルリクエストは、マージグループに複数のプルリクエストが含まれている場合、不正なマージコミットを生成しました。影響を受けたケースでは、以前にマージされたプルリクエストおよび以前のコミットからの変更が、後続のマージによって意図せず取り消されました。
影響期間中、230件のリポジトリと2,092件のプルリクエストが影響を受けました。当初はより高い数値を共有しましたが、これは最初の評価があえて慎重に行われたためです。この問題は、マージキュー外でマージされたプルリクエストには影響せず、マージまたはリベース方式を使用するマージキューグループにも影響しませんでした。
データ損失はありませんでした:すべてのコミットはGit内に保持されていました。しかし、影響を受けたデフォルトブランチの状態が正しくなく、すべてのリポジトリを安全に自動修復できませんでした。詳細はインシデントの根本原因分析をご覧ください。
このインシデントにより複数のプロセス上の問題が浮き彫りになり、私たちはこれらのプロセスを変更して、同種の事象の再発を防ぐ取り組みを行っています。
4月27日の検索関連インシデント
4月27日、Elasticsearchサブシステムに影響のあるインシデントが発生し、GitHub全体の検索機能を支える複数の体験領域(プルリクエストの一部、イシュー、プロジェクトなど)が影響を受けました。
根本原因分析はまだ完了しておらず、近日中に公開する予定です。現時点で分かっているのは、クラスターが過負荷状態(おそらくボットネット攻撃によるもの)に陥り、検索結果を返さなくなったことです。データ損失はなく、Git操作やAPIへの影響はありませんでした。しかし、検索に依存するUIの一部で結果が表示されず、大きな混乱を招きました。
これは、単一障害点として完全に分離できていなかったシステムの1つです。他の領域がリスク優先度の高い信頼性向上作業でより優先されていたためです。この影響は許容できるものではなく、今後同種の障害が発生する可能性と影響を軽減するために、前述の依存関係および爆発半径分析を適用しています。
透明性の向上
私たちはまた、インシデント発生時に顧客がより高い透明性を求めているという明確なフィードバックを受け取っています。
私たちはGitHubのステータスページを更新し、可用性の数値を含めるようにしました。また、大規模なインシデントから小規模なものまで、すべてのインシデントの状況を報告することを約束しました。これにより、問題が顧客側にあるのか当社側にあるのかを推測する必要がなくなります。
私たちはインシデントの分類方法を継続的に改善しており、その規模と範囲をより理解しやすくしています。また、障害発生時に顧客がインシデントを報告し、当社とシグナル(信号)を共有するためのより良い方法の開発にも取り組んでいます。
私たちのコミットメント
GitHubの役割は、常にオープンで拡張性の高いプラットフォーム上で開発者を支援することにあります。
GitHubのチームは、私たちの仕事に対して非常に情熱を持っています。あなたが経験している痛みを私たちは理解しています。すべてのメール、ソーシャルメディアの投稿、サポートチケットを読み、それを心から受け止めています。申し訳ありません。
私たちは、可用性の向上、レジリエンス(回復力)の強化、ソフトウェア開発の未来に向けたスケーリング、そしてその過程でのより透明なコミュニケーションにコミットしています。
「GitHubの可用性に関する更新」記事は、最初にThe GitHub Blogに掲載されました。
原文を表示
I wanted to give an update on GitHub’s availability in light of two recent incidents. Both of those incidents are not acceptable, and we are sorry for the impact they had on you. I wanted to share some details on them, as well as explain what we’ve done and what we’re doing to improve our reliability.
We started executing our plan to increase GitHub’s capacity by 10X in October 2025 with a goal of substantially improving reliability and failover. By February 2026, it was clear that we needed to design for a future that requires 30X today’s scale.
The main driver is a rapid change in how software is being built. Since the second half of December 2025, agentic development workflows have accelerated sharply. By nearly every measure, the direction is already clear: repository creation, pull request activity, API usage, automation, and large-repository workloads are all growing quickly.
This exponential growth does not stress one system at a time. A pull request can touch Git storage, mergeability checks, branch protection, GitHub Actions, search, notifications, permissions, webhooks, APIs, background jobs, caches, and databases. At high scale, small inefficiencies compound: queues deepen, cache misses become database load, indexes fall behind, retries amplify traffic, and one slow dependency can affect several product experiences.
Our priorities are clear: availability first, then capacity, then new features. We are reducing unnecessary work, improving caching, isolating critical services, removing single points of failure, and moving performance-sensitive paths into systems designed for these workloads. This is distributed systems work: reducing hidden coupling, limiting blast radius, and making GitHub degrade gracefully when one subsystem is under pressure. We’re making progress quickly, but these incidents are examples of where there’s still work to do.
What we’re doing
Short term, we had to resolve a variety of bottlenecks that appeared faster than expected from moving webhooks to a different backend (out of MySQL), redesigning user session cache to redoing authentication and authorization flows to substantially reduce database load. We also leveraged our migration to Azure to stand up a lot more compute.
Next we focused on isolating critical services like git and GitHub Actions from other workloads and minimizing the blast radius by minimizing single points of failure. This work started with careful analysis of dependencies and different tiers of traffic to understand what needs to be pulled apart and how we can minimize impact on legitimate traffic from various attacks. Then we addressed those in order of risk. Similarly, we accelerated parts of migrating performance or scale sensitive code out of Ruby monolith into Go.
While we were already in progress of migrating out of our smaller custom data centers into public cloud, we started working on path to multi cloud. This longer-term measure is necessary to achieve the level of resilience, low latency, and flexibility that will be needed in the future.
The number of repositories on GitHub is growing faster than ever, but a much harder scaling challenge is the rise of large monorepos. For the last three months, we’ve been investing heavily in response to this trend both within git system and in the pull request experience.
We will have a separate blog post soon describing extensive work we’ve done and the new upcoming API design for greater efficiency and scale. As part of this work, we have invested in optimizing merge queue operations, since that is key for repos that have many thousands of pull requests a day.
Recent incidents
The two recent incidents were different in cause and impact, but both reflect why we are increasing our focus on availability, isolation, and blast-radius reduction.
April 23 merge queue incident
On April 23, pull requests experienced a regression affecting merge queue operations.
Pull requests merged through merge queue using the squash merge method produced incorrect merge commits when a merge group contained more than one pull request. In affected cases, changes from previously merged pull requests and prior commits were inadvertently reverted by subsequent merges.
During the impact window, 230 repositories and 2,092 pull requests were affected. We initially shared slightly higher numbers because our first assessment was intentionally conservative. The issue did not affect pull requests merged outside merge queue, nor did it affect merge queue groups using merge or rebase methods.
There was no data loss: all commits remained stored in Git. However, the state of affected default branches was incorrect, and we could not safely repair every repository automatically. More details are available in the incident root cause analysis.
This incident exposed multiple process failures, and we are changing those processes to prevent this class of issue from recurring.
April 27 search-related incident
On April 27, an incident affected our Elasticsearch subsystem, which powers several search-backed experiences across GitHub, including parts of pull requests, issues, and projects.
We are still completing the root cause analysis and will publish it shortly. What we know now is that the cluster became overloaded (likely due to a botnet attack) and stopped returning search results. There was no data loss, and Git operations and APIs were not impacted. However, parts of the UI that depended on search showed no results, which caused a significant disruption.
This is one of the systems we had not yet fully isolated to eliminate as a single point of failure, because other areas had been higher in our risk-prioritized reliability work. That impact is unacceptable, and we are using the same dependency and blast-radius analysis described above to reduce the likelihood and impact of this type of failure in the future.
Increasing transparency
We have also heard clear feedback that customers need greater transparency during incidents.
We recently updated the GitHub status page to include availability numbers. We have also committed to statusing incidents both large and small, so you do not have to guess whether an issue is on your side or ours.
We are continuing to improve how we categorize incidents so that the scale and scope are easier to understand. We are also working on better ways for customers to report incidents and share signals with us during disruptions.
Our commitment
GitHub’s role has always been to support developers on an open and extensible platform.
The team at GitHub is incredibly passionate about our work. We hear the pain you’re experiencing. We read every email, social post, support ticket, and we take it all to heart. We’re sorry.
We are committed to improving availability, increasing resilience, scaling for the future of software development, and communicating more transparently along the way.
The post An update on GitHub availability appeared first on The GitHub Blog.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み