AWS Inferentia2 上でペット行動検出を行うビジョン言語モデルの低コスト展開
台湾のペットテック企業 Tomofun は、AWS Inferentia2 を活用した EC2 Inf2 インスタンスへの移行により、リアルタイムのビジョン言語モデル推論コストを大幅に削減し、大規模なペット行動検出サービスの持続可能性を確立しました。
キーポイント
GPU から Inferentia2 への移行によるコスト最適化
常時稼働するリアルタイム推論ワークロードにおいて、従来の GPU ベースの EC2 インスタンスから AWS 専用 AI チップである Inferentia2 を搭載した Inf2 インスタンスへ移行し、コスト効率を劇的に改善しました。
既存コードベースの活用とスケーラビリティ
PyTorch で最適化された BLIP モデルの大幅な書き換えを行わずに Inferentia2 上で動作可能にし、Auto Scaling グループと ELB を組み合わせて数十万台規模のデバイス対応を可能にしました。
ビジョン言語モデルの実用化アーキテクチャ
Furbo カメラからの映像ストリームを CloudFront と ELB を経由して処理し、ペットの行動(吠え、走行など)をリアルタイムで検知・アラートするエンドツーエンドのシステム構成を実現しました。
非改変コンパイル戦略
元のBLIPモデルのロジックを変更せず、`torch_neuronx.trace()` を直接使用してNeuron最適化されたTorchScriptアーティファクトを生成します。
軽量ラッパーによる統合
`torch_neuronx.trace()` の入出力形式要件を満たすために、既存のアーキテクチャを変更しない軽量なラッパー(`TextEncoderWrapper`)をアダプター層として導入します。
開発とデプロイの分離
コンパイル時には元のモデルを使用し、本番環境での実行時にのみラッパー経由でコンパイル済みモデルをロード・実行することで、コード変更を最小限に抑えつつ生産パイプラインへのシームレスな統合を実現します。
コスト削減とパフォーマンスの両立
AWS Inferentia2 (Inf2) への移行により、GPU オンデマンド環境と比較して83%のコスト削減を実現しつつ、大規模な同時リクエスト処理でも低レイテンシを維持しました。
影響分析・編集コメントを表示
影響分析
この事例は、大規模なビジョン言語モデル(VLM)をクラウド上で実運用する際のコスト課題に対する具体的な解決策を示しており、特に IoT デバイスと組み合わせたリアルタイム AI アプリケーションの普及に寄与します。AWS Inferentia2 の採用成功は、GPU 依存からの脱却と、AI インフラの経済的持続可能性を追求する業界全体のトレンドを象徴しています。
編集コメント
ペットカメラという身近な IoT デバイスにおいて、高コストな GPU を避け、専用チップで VLM を動かす実例は非常に示唆に深いです。大規模展開を前提とした AI サービスの設計において、インフラ選定が収益性に直結する重要な要素であることを再認識させられます。
Tomofun は、Furbo ペットカメラの開発元である台湾に本社を置くペットテックスタートアップであり、ペットオーナーが遠隔でペットとどのように関わるかを再定義しています。Furbo はスマートカメラと AI を組み合わせ、吠えや走行、あるいは不審な活動などの行動を検知し、オーナーにリアルタイムでアラートを通知します。この機能の核心には、動画ストリームからペットの動作を解釈するコンピュータビジョンおよびビジョン・ランゲージモデル(vision-language models)があります。
当初、Furbo の推論ワークロードは、GPU ベースの Amazon Elastic Compute Cloud (Amazon EC2) インスタンス上でホストされていました。GPU は高いスループットを提供しましたが、スケールしてリアルタイムのペット活動アラートをサポートするために常時稼働する必要がある推論にはコストがかかるという課題がありました。コスト削減と精度維持のため、Tomofun は Amazon 専用 AI チップである AWS Inferentia2 を搭載した EC2 Inf2 インスタンス に移行しました。本稿では、以下のセクションについて詳しく解説します。
チャレンジ:大規模なリアルタイムビジョン言語モデルの GPU 推論コスト削減
Bootstrapping Language-image Pre-Training (BLIP) のような高度なビジョン言語モデルは、元の 論文 に詳述されている通り、GPU インスタンス上でホストされていましたが、大規模かつ常時稼働するリアルタイム推論ワークロードにおいてはコスト効率が低いことが判明しました。課題は二重のものでした。Tomofun は、数十万台のデバイスにわたるほぼ継続的なペット行動監視においてコスト効率を維持する必要がありながら、モデルの忠実度とスループットも維持しなければなりませんでした。また、PyTorch 向けに最適化済みの既存の BLIP コードベースの大部分を書き換えることなく、これを実現する必要がありました。
ソリューション概要
アーキテクチャの詳細に入る前に、以下の図は、AWS サービスを横断して大規模なペット行動検出システムがどのように処理を行うかを示す高レベルの概要です。
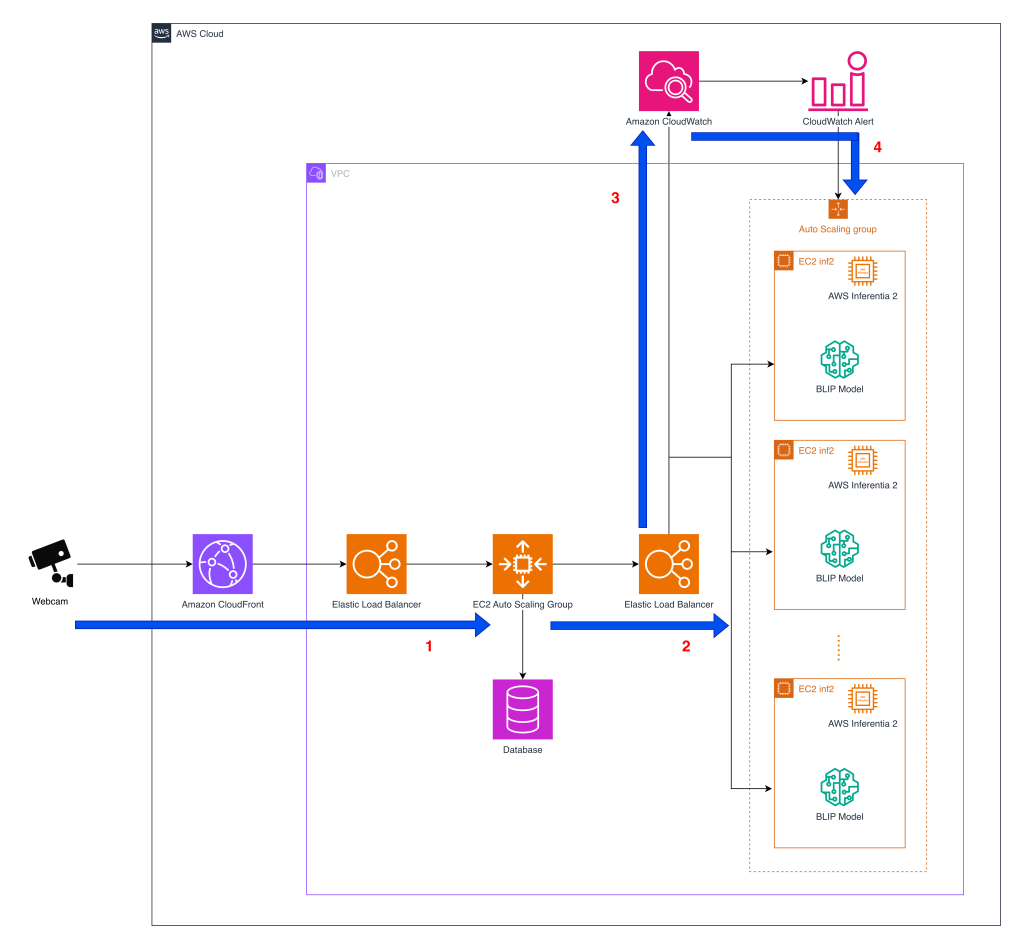
- ウェブカメラとのインタラクション – Furbo の API は、Tomofun のペット行動検出サービスの中心に位置し、顧客のペット用カメラからの画像ストリームを AWS 内の推論エンドポイントへ調整しています。図は、EC2 Inf2 インスタンスを使用して実装された Elastic Load Balancing (ELB) と Amazon EC2 Auto Scaling グループのアーキテクチャを示しており、推論ボリュームがリアルタイムで増加する際にスケーリングを提供します。カメラがフレームをキャプチャすると、データは Amazon CloudFront を経由して ELB にルーティングされ、ペット行動検出 API サーバーをホストする EC2 Auto Scaling グループの第 1 レイヤーへ送られます。API レイヤーが各リクエストを処理した後、画像はモデル推論を実行するために専用に割り当てられた第 2 レイヤーの Auto Scaling グループへ転送されます。
- モデル推論 – 処理後、画像は推論インスタンスを含む第 2 レイヤーの EC2 Auto Scaling グループへ転送されます。このグループ内では、コンテナが BLIP モデルをホストしており、これは Inferentia2 ベースの EC2 Inf2 インスタンス上で実行可能です。Neuron SDK を使用してコンパイルされた BLIP モデルコンポーネントは、Inf2 インスタンス上のコンテナにロードされます。初期の実装では、Furbo の API は推論呼び出しを GPU コンテナへ専らルーティングしていましたが、現在はアップストリームの API やダウンストリームのアラートロジックを変更することなく、Inf2 ベースのコンテナへのリクエストも指示できるようになりました。このアーキテクチャにより、Tomofun はリアルタイムで推論リクエストを GPU と Inferentia2 のバックエンド間で転送・切り替えることが可能になります。これにより高可用性が維持され、Furbo ユーザーに対して同じ API サーフェスを保ちながら、コスト効率の高いスケーリングを実現する柔軟性が提供されます。
- メトリクス収集 – Amazon CloudWatch は、推論ファーム全体にわたる遅延、スループット、エラーレートといった重要な運用メトリクスを監視します。これらのシグナルは、パフォーマンスの低下を早期に検出し、1 日のうちでトラフィックパターンが変化する際にもサービスレベル目標が満たされるようにするために必要な観測性を提供します。
- デマンドに応じたスケーリング – ELB はリクエストを Auto Scaling グループ内の利用可能なインスタンスへ配信し、このグループは CloudWatch メトリクスである着信リクエスト数に基づいてインスタンスプールサイズを管理します。各インスタンスタイプのスループットベンチマークがストレステストを通じて既に確立されているため、このメトリクス駆動型のアプローチが採用されており、スケーリングの決定は画像リクエストのボリュームによって直接行われます。その結果、需要が増大する際にも高可用性を維持しながら、リアルタイムでコスト効率の高い推論容量をスケーリングできるアーキテクチャが実現されています。
Inferentia2 上での BLIP の改善
モデルの詳細に踏み込む前に、以下の図は BLIP アーキテクチャのハイレベルな概要と、その主要コンポーネントがどのように相互作用するかを示しています。
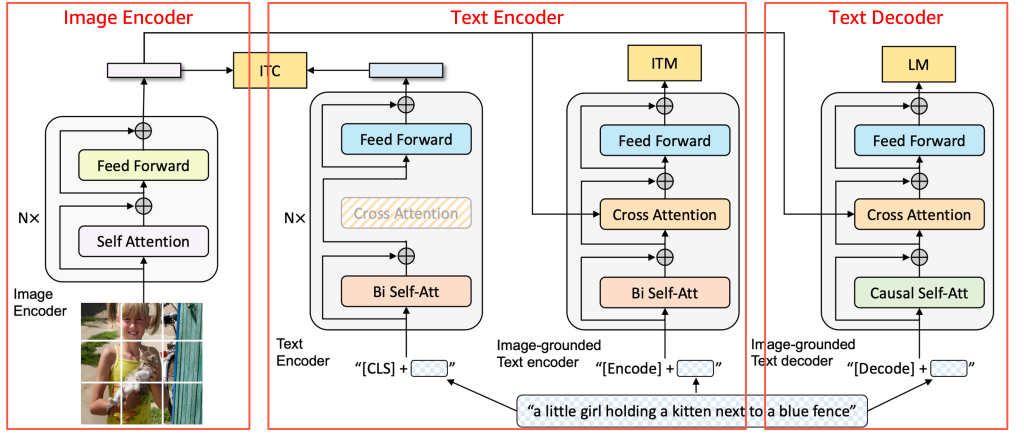
出典:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, 2022 https://arxiv.org/pdf/2201.12086
BLIP は、画像に示されている通り、3 つのコンポーネントで構成されています。すなわち、Image Encoder(画像エンコーダー)、Text Encoder(テキストエンコーダー)、そして Text Decoder(テキストデコーダー)です。Inferentia2 でのサポートにおいては、モデルをこれらのコンポーネントに分割し、入力および出力の形状に合わせてラップ処理を行うことが可能です。Tomofun はこの手法を BLIP に適用し、BLIP モデルの各 3 つのコンポーネントに対して軽量なラッパーを作成しました。これにより、元のアーキテクチャは変更されずに維持されています。各コンポーネントは torch_neuronx を用いて個別にコンパイルされ、その後推論パイプラインへと結合されました。これにより、入力は順次流れるようになります。このモジュラーアプローチは、BLIP の事前学習済みロジックを変更することなく、Inferentia2 との互換性を維持しています。
オリジナルモデルコード
最初のステップは、内部ロジックを変更せずにコンパイルできるように、元の BLIP テキストエンコーダを分離することです。TextEncoder クラスは、元のサブモジュール (model.text_encoder.model) を薄いラッパーとして囲み、主要なテンソルのみを返すことで前方出力を標準化しています。これにより、元のアーキテクチャを維持しつつ、Neuron でトレースおよびコンパイルが容易になります。
class TextEncoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask):
output = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)
return output[0]
コンパイルフェーズでは、事前学習済み BLIP のロジックを変更することなく、元のモデル (model.text_encoder.model) を直接 torch_neuronx.trace() に渡して Neuron 最適化された TorchScript アーティファクトとしてコンパイルします。
Wrapper code
torch_neuronx.trace() API は入力と出力にテンソルのタプルを期待するため、ラッパーコードが必要です。モデルの書き換えを避けるため、軽量なラッパーはアダプター層として機能し、入出力の形式を変換しながら元のアーキテクチャを変更しません。このアプローチにより、コード変更を最小限に抑えつつ、コンパイル済みコンポーネントを既存の推論パイプラインにシームレスに統合できます。
class TextEncoderWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = TextEncoder(model)
@classmethod
def from_model(cls, model):
wrapper = cls(model)
wrapper.model = model
return wrapper
def forward(self, input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask, return_dict):
output = self.model(input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask)
return (output,)
このラッパーは、コンパイル済みモデルの読み込みと入出力の形式変換をデプロイ時に行うため、既存の BLIP パイプラインに適合します。
- コンパイル:元のモデル(model.text_encoder.model)を使用
- デプロイ:TextEncoderWrapper を使用してコンパイル済みモデルを実行
これにより、元のコードを変更せずに、コンパイル済みモデルを本番環境に容易に組み込むことができます。
Inferentia2 向けのモデルコンパイル
以下のコードスニペットでは、model.text_encoder.model は未変更の Text Encoder サブモジュールを表しており、これが Neuron 最適化された TorchScript フォーマットにコンパイルされます。
def trace_model(model, directory, compiler_args=f"--auto-cast-type fp16 --logfile {LOG_DIR}/log-neuron-cc.txt"):
if os.path.isfile(directory):
print(f"指定されたパス ({directory}) はディレクトリであるべきで、ファイルではありません")
return
os.makedirs(directory, exist_ok=True)
os.makedirs(LOG_DIR, exist_ok=True)
# モデルが既にトレース済みならスキップ
if not os.path.isfile(os.path.join(directory, 'text_encoder.pt')):
print("text_encoder のトレースを実行中")
# ステップ 1: 期待される形状とデータ型を持つ疑似入力データを指定
inputs = (
torch.ones((1, 8), dtype=torch.int64),
torch.ones((1, 8), dtype=torch.int64),
torch.ones((1, 577, 768), dtype=torch.float32),
torch.ones((1, 577), dtype=torch.int64),
)
# ステップ 2: torch_neuronx.trace() を使用して Inferentia 向けにモデルをコンパイル
encoder = torch_neuronx.trace(model.text_encoder.model,
inputs,
compiler_args=compiler_args)
# ステップ 3: コンパイル済みモデルを TorchScript アーティファクトとして保存
torch.jit.save(encoder, os.path.join(directory, 'text_encoder.pt'))
else:
print('text_encoder.pt のスキップ')
Inferentia2 向けに BLIP コンポーネントをコンパイルするために、Tomofun は GPU で訓練された PyTorch モデルを Inferentia 最適化アーティファクトへ変換するトレーシング関数を定義しました。このプロセスはまず、モデルの入力に対する期待される形状とデータ型を表す疑似入力テンソルを用意することから始まります。これによりトレーシングプロセスがガイドされます。入力が定義された後、関数は torch_neuronx.trace() を呼び出して Inferentia 実行用の BLIP サブモデルをコンパイルし、元のコードの Neuron 最適化バージョンを生成します。最後に、torch.jit.save でコンパイル済みアーティファクトを保存し、Inf2 インスタンス上でのデプロイ準備を整えます。この「ラッパーの読み込み」「疑似入力データの提供」「Neuron によるコンパイル」という 3 ステップの流れにより、Tomofun は元のモデルコードを変更せずに BLIP の TextDecoder および他のコンポーネントを移行することが可能になります。
Inferentia2 上のモデルデプロイメント
デプロイメントフェーズでは、コンパイル済みサブモジュールがラッパークラスを通じて読み込まれ、最終的な BLIP 推論パイプラインが構築されます。この分離により明確なワークフローが確立され、コンパイル中には元のモデルコンポーネントが Neuron の改善に直接利用される一方、推論時にはラッパークラスが入出力のフォーマット処理を担当し、Inferentia2 との互換性を確保します。デプロイメントフェーズのコードは以下の通りです:
models.text_encoder = TextEncoderWrapper.from_model(** torch.jit.load(os.path.join(directory, 'text_encoder.pt')))
この設計は、Neuron SDK の I/O インターフェース要件を軽量なラッパークラスを通じて満たしつつ、元の BLIP アーキテクチャを変更せずに維持しました。また、コンパイルとデプロイメントの両方においてモジュール化されたコンポーネントレベルのワークフローを実現し、各 BLIP サブモジュールを独立してコンパイル・管理可能にしています。その結果、直接 Neuron 最適化を行うためのコンパイルフェーズでは model.text_encoder.model の使用が不可欠であり、一方、ラッパークラスは Inferentia2 上でスムーズな実行を確保するために推論時の入力と出力のフォーマット処理を担当します。
ストレステスト
スケーラビリティにおけるパフォーマンスを検証するため、Tomofun は実際の Furbo カメラのワークロードをシミュレートしたストレステストを実施しました。各ビデオストリームは、「犬が吠えているか?」「犬は遊んでいるか?」「犬は家具を噛んでいるか?」といったアクション検出クエリをトリガーします。これらのテストにより、Inf2 インスタンス(Inferentia2 チップ 1 基、メモリ 32 GB)が、必要なスループットを維持しつつ低レイテンシで動作できることが確認されました。精度に加えて、このテストでは Inf2 のデプロイメントが数十万台のデバイスからの同時リクエストを処理可能であることも浮き彫りになり、常時稼働するグローバルな顧客基盤を持つ Furbo にとって非常に適していることが示されました。重要なのは、比較のベンチマークとして使用されたベースラインが、オンデマンド課金モデルを採用した GPU ベースのインスタンスであった点です。これは、Inf2 への移行前に Tomofun が支払っていたコストを反映したものです。GPU のオンデマンドデプロイメントから Inferentia2 を搭載した Inf2.xlarge インスタンスへ移行することで、Tomofun はパフォーマンスを損なうことなく、83% のコスト削減を実現しました。
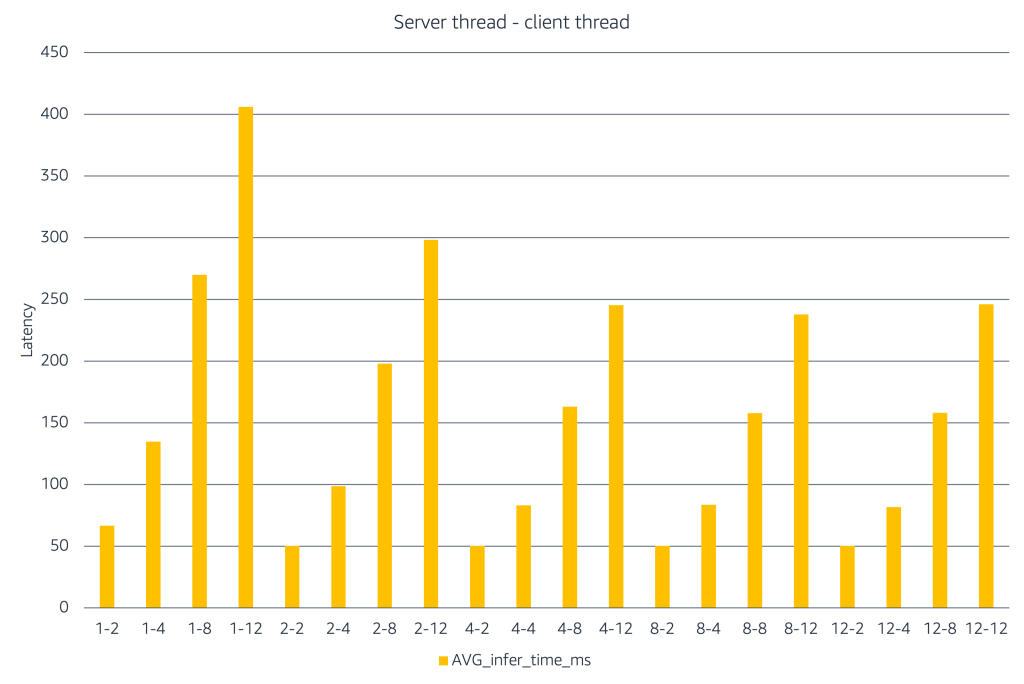
このグラフは、サーバーとクライアントの並行処理数が増加するにつれて推論レイテンシがどのように変化するかを示しています。X 軸は「#server スレッド – #client スレッド」というラベルの組み合わせを表しており、異なる負荷シナリオ下でのパフォーマンスをシミュレーションします。利用可能なサーバースレッドが少ない場合、クライアントスレッドを追加するとレイテンシが急激に上昇します。一方、サーバースレッド数を増やすことでこの負荷を吸収し、レイテンシを低く保つことができます。高い並行処理レベルでは、レイテンシは増加し、その後頭打ちになる傾向を示し、飽和状態にあることを示唆しています。この実験から、チームは負荷テストを使用して、クライアントの並行処理とサーバー容量の間の適切なバランスを見極め、その範囲内で並行処理を制限することで、本番環境において最適なレイテンシとコストのトレードオフを実現できることがわかります。
結論
BLIP の推論を AWS Inferentia ベースの EC2 Inf2 インスタンス に移行したことで、Tomofun は Furbo アプリケーションの展開コストを 83% 削減しました。GPU から Inferentia2 への移行はスムーズで、軽量なラッパークラスの追加のみが必要であり、BLIP のコアロジックには一切変更を加える必要はありませんでした。テストにより、Inferentia2 を使用することで展開コストが削減されるだけでなく、大規模なリアルタイム推論においても高いスループットを維持できることが確認されました。Tomofun は、音声イベント検出(吠えの認識など)や、ペットと飼い主の相互作用を強化するための将来の大規模言語モデルとの統合など、ビジョン・ランゲージモデル以外のワークロードもサポートしているため、さらに多くのワークロードを Inferentia2 へ移行する計画です。また、AWS Deep Learning Containers (DLCs) の採用は次のステップとしてロードマップに組み込まれており、事前構築された改善済みのコンテナイメージを使用して依存関係の管理を簡素化し、推論ワークフローを効率化する予定です。
同様の改善を実装する方法については、参照可能な AWS Neuron ドキュメントと例をご覧ください。AWS Neuron Document です。また、Furbo website を訪れて、AI 搭載機能を探ったり、Furbo エコシステムがどのようにペットの安全を守っているかを確認したりすることもできます。
著者について
 image
image
Chen-Hsin Ding は Tomofun のスタッフ機械学習エンジニアであり、10 年以上のソフトウェア開発経験を持っています。彼は生成 AI プロジェクトを主導し、バックエンドチームと緊密に連携して実用的な AI システムアーキテクチャを設計しています。MLOps のベストプラクティスを AI チームに取り入れ、本番環境で運用可能な LLM(大規模言語モデル)および RAG(検索拡張生成)アプリケーションを提供することに注力しています。仕事以外では、Chen-Hsin はコーヒーの淹れ方や、ハイレゾオーディオシステムで映画サウンドトラックやジャズを聴くことを楽しんでいます。

Ray Wang は AWS のシニアソリューションアーキテクトです。IT 業界で 15 年の経験を持つ Ray は、クラウド上で現代的なソリューションを構築することに専念しており、特に NoSQL(非リレーショナルデータベース)、ビッグデータ、機械学習、そして生成 AI に注力しています。貪欲な達成者として、彼は AWS の認定資格 12 種すべてに合格し、技術分野の深さと幅の両方を確立しました。趣味では読書や SF 映画鑑賞を楽しんでいます。

Howard Su 氏は AWS のソリューションアーキテクトです。ソフトウェア開発とシステム運用における豊富な経験を持ち、RD(研究開発)、QA(品質保証)、SRE(サイト信頼性エンジニア)など多様な役割を歴任してきました。Howard は多数の大規模システムのアーキテクチャ設計を担当し、複数のクラウド移行プロジェクトを主導しました。長年にわたる深い技術的蓄積を経て、現在は生成 AI を活用して自己修復機能を持つ「AI ネイティブ」なインフラストラクチャを構築することで DevOps を推進することに注力しており、ソフトウェア開発ライフサイクル(SDLC)を従来のオーケストレーションから、真に知的で予測的なエコシステムへと移行させることを目指しています。
原文を表示
Tomofun, the Taiwan-headquartered pet-tech startup behind the Furbo Pet Camera, is redefining how pet owners interact with their pets remotely. Furbo combines smart cameras with AI to detect behaviors such as barking, running, or unusual activity, and alerts owners in real time. At the core of this capability are computer vision and vision-language models that interpret pet actions from the video streams.
Originally, Furbo’s inference workloads were hosted on GPU-based Amazon Elastic Compute Cloud (Amazon EC2) instances. While GPUs provided high throughput, they were also costly because the always-on inference needed to support real-time pet activity alerts at scale. To reduce costs and maintain accuracy, Tomofun turned to EC2 Inf2 instances powered by AWS Inferentia2, the Amazon purpose-built AI chips. In this post, we walk through the following sections in detail.
Challenge: Reducing GPU inference cost for real-time vision-language models at scale
Running advanced vision-language models like Bootstrapping Language-image Pre-Training (BLIP), detailed in the original paper, were hosted on GPU instances and proved less cost-effective for always-on, real-time inference workloads at scale. The challenge was twofold: Tomofun needed to sustain cost efficiency for nearly continuous pet behavior monitoring across hundreds of thousands of devices, while also maintaining model fidelity and throughput. Tomofun needed to do this without rewriting large portions of the BLIP code base already optimized for PyTorch.
Solution overview
Before diving into the architecture, the following diagram provides a high-level view of how the system processes pet behavior detection at scale across AWS services.
- Webcam interaction – Furbo’s API sits at the center of Tomofun’s pet-behavior detection service, orchestrating image streams from customer’s pet cameras to inference endpoints in AWS. The diagram shows the architecture of Elastic Load Balancing (ELB) and Amazon EC2 Auto Scaling group implemented using EC2 Inf2 instances providing scaling as the inference volume grows in real-time. When a camera captures a frame, the data is routed through Amazon CloudFront and an ELB to the first layer of the EC2 Auto Scaling group that hosts the pet-behavior detection API servers. After the API layer processes each request, it forwards the image to a second-layer Auto Scaling group dedicated to running model inference.
- Model inference – After processing, the images are forwarded to a second layer EC2 Auto Scaling group containing inference instances. Inside this group, containers host the BLIP model, which can run on Inferentia2-based EC2 Inf2 instances. The BLIP model components compiled using the Neuron SDK are loaded into containers on Inf2 instances. In the early implementation, Furbo’s API routed inference calls exclusively to GPU containers, but now it can also direct requests to Inf2-based containers without changing the upstream API or downstream alert logic. This architecture allows Tomofun to direct inference requests to and switch between GPU and Inferentia2 backends in real-time. This maintains high availability and gives them the flexibility to scale cost-efficient inference while preserving the same API surface for Furbo users.
- Metrics collection – Amazon CloudWatch monitors key operational metrics across the inference fleet, including latency, throughput, and error rates. These signals provide the observability needed to detect performance degradation early and ensure that service-level objectives are met as traffic patterns shift throughout the day.
- Scaling with Demand – The ELB dispatches requests to the available instances within the Auto Scaling group, which manages the size of the instance pool size based on the incoming request count as the CloudWatch metric. This metric-driven approach is adopted because the throughput benchmarks for each instance type have already been established through stress testing, so scaling decisions can be driven directly by the volume of image requests. The result is an architecture that scales cost-efficient inference capacity in real time, maintaining high availability as demand grows.
Improving BLIP on Inferentia2
Before diving into the model details, the following diagram provides a high-level overview of the BLIP architecture and how its core components interact.
Source: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, 2022 https://arxiv.org/pdf/2201.12086
BLIP is composed of three components—the Image Encoder, Text Encoder, and Text Decoder, as shown in the image. For support on Inferentia2, models can be broken into components and wrapped to fit input and output shapes. Tomofun applied this method to BLIP, creating lightweight wrappers for each of the three components of the BLIP model so the original architecture remained unchanged. Each component was compiled independently with torch_neuronx and then combined into the inference pipeline, allowing inputs to flow sequentially. This modular approach maintained compatibility with Inferentia2 without altering BLIP’s pretrained logic.
Original model code
The first step is to isolate the original BLIP Text Encoder so it can be compiled without modifying its internal logic. The TextEncoder class is a thin wrapper around the original submodule (model.text_encoder.model) that standardizes the forward output by returning only the primary tensor. This makes the component straightforward to trace and compile with Neuron while preserving the original architecture.
class TextEncoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask):
output = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)
return output[0]During the compilation phase, the original model (model.text_encoder.model) is passed directly into torch_neuronx.trace() and compiled into a Neuron-optimized TorchScript artifact, without modifying the pretrained BLIP logic.
Wrapper code
A wrapper is needed because the torch_neuronx.trace() API expects a tensor tuple of tensors as input and output. To avoid rewriting the model, lightweight wrappers act as an adapter layer that reformats inputs and outputs while keeping the original architecture unchanged. This approach minimizes code changes and allows the compiled components to integrate seamlessly into the existing inference pipeline.
class TextEncoderWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = TextEncoder(model)
@classmethod
def from_model(cls, model):
wrapper = cls(model)
wrapper.model = model
return wrapper
def forward(self, input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask, return_dict):
output = self.model(input_ids, attention_mask, encoder_hidden_states, encoder_attention_mask)
return (output,)The wrapper is used only at deployment to load the compiled model and format I/O, so it fits the existing BLIP pipeline.
- Compile: use the original model (model.text_encoder.model)
- Deploy: use TextEncoderWrapper to run the compiled model
This keeps the original code unchanged while making the compiled model easy to plug into production.
Model compilation for Inferentia2
In the following code snippet, model.text_encoder.model represents the unmodified Text Encoder submodule, which is compiled into a Neuron-optimized TorchScript format.
def trace_model(model, directory, compiler_args=f"--auto-cast-type fp16 --logfile {LOG_DIR}/log-neuron-cc.txt"):
if os.path.isfile(directory):
print(f"Provided path ({directory}) should be a directory, not a file")
return
os.makedirs(directory, exist_ok=True)
os.makedirs(LOG_DIR, exist_ok=True)
# Skip trace if the model is already traced
if not os.path.isfile(os.path.join(directory, 'text_encoder.pt')):
print("Tracing text_encoder")
# Step 1: Provide pseudo input data with expected shapes and dtypes
inputs = (
torch.ones((1, 8), dtype=torch.int64),
torch.ones((1, 8), dtype=torch.int64),
torch.ones((1, 577, 768), dtype=torch.float32),
torch.ones((1, 577), dtype=torch.int64),
)
# Step 2: Use torch_neuronx.trace() to compile the model for Inferentia
encoder = torch_neuronx.trace(model.text_encoder.model,
inputs,
compiler_args=compiler_args)
# Step 3: Save the compiled model as TorchScript artifact
torch.jit.save(encoder, os.path.join(directory, 'text_encoder.pt'))
else:
print('Skipping text_encoder.pt')To compile BLIP components for Inferentia2, Tomofun defined a trace function that automates the conversion of GPU-trained PyTorch models into Inferentia-optimized artifacts. The process begins by preparing pseudo input tensors that represent the expected shapes and data types of the model’s inputs, which guides the tracing process. After the inputs are defined, the function calls torch_neuronx.trace() to compile the BLIP sub-model for Inferentia execution, producing a Neuron-optimized version of the original code. Finally, the compiled artifact is saved with torch.jit.save, making it ready for deployment on Inf2 instances. This three-step flow—loading the wrapper, providing pseudo input data, and compiling with Neuron—makes sure that Tomofun can migrate BLIP’s TextDecoder and other components without changing the original model code.
Model deployment on Inferentia2
In the deployment phase, the compiled submodules are loaded through wrapper classes to assemble the final BLIP inference pipeline. This separation creates a clear workflow where the original model components are used directly for Neuron improvement during compilation, while the wrapper classes handle input and output formatting during inference to ensure compatibility with Inferentia2. The deployment phase code is as following:
models.text_encoder = TextEncoderWrapper.from_model(** torch.jit.load(os.path.join(directory, 'text_encoder.pt')))
This design preserved the original BLIP architecture without modification while meeting the Neuron SDK’s I/O interface requirements through lightweight wrapper classes. It also enabled a modular, component-level workflow for both compilation and deployment, allowing each BLIP submodule to be compiled and managed independently. As a result, the use of model.text_encoder.model is essential during the compilation phase for direct Neuron optimization, whereas the wrapper classes handle input and output formatting during inference to ensure smooth execution on Inferentia2.
Stress testing
To validate performance at scale, Tomofun conducted stress tests simulating real-world Furbo camera workloads. Each video stream triggered action detection queries such as “Is the dog barking?”, “Is the dog playing?”, or “Is the dog chewing furniture?”. These tests confirmed that Inf2 instances (one Inferentia2 chip, 32 GB memory) could sustain the required throughput while maintaining low latency. In addition to accuracy, the tests highlighted that the Inf2 deployment could handle simultaneous requests across hundreds of thousands of devices, making it well-suited for Furbo’s always-on global customer base. Importantly, the comparison baseline was running GPU-based instances with an on-demand pricing model, which reflected the cost Tomofun was paying before migration to Inf2. By migrating from those GPU on-demand deployments to Inf2.xlarge instances with Inferentia2, Tomofun achieved 83% cost reduction without compromising performance.
The chart illustrates how inference latency changes as server and client concurrency increase. The X-axis represents combinations of the labels represent #server threads – #client threads to simulate performance under different load scenarios. When only a few server threads are available, adding more client threads causes latency to rise quickly. Increasing the number of server threads helps absorb this load and keeps latency lower. At higher concurrency levels, latency increases and gains level off, indicating saturation. This experiment shows that teams should use load testing to identify the right balance between client concurrency and server capacity, and then limit concurrency to that range to achieve the right latency–cost tradeoff in production.
Conclusion
By migrating BLIP inference on AWS Inferentia-based EC2 Inf2 instances, Tomofun reduced their Furbo application deployment costs by 83%. The transition from GPU to Inferentia2 was seamless, as the migration required only lightweight wrapper classes and left BLIP’s core logic untouched. Testing confirmed that using Inferentia2 not only reduced the deployment costs, but also maintained high throughput for real-time inference at scale. Tomofun plans to migrate more workloads to Inferentia2 as it supports workloads beyond vision-language models, such as audio event detection for barking recognition and potential future integration with large language models to enhance pet-owner interactions. Additionally, the adoption of AWS Deep Learning Containers (DLCs) has been scheduled into the roadmap as a next step, using pre-built, improved container images to simplify dependency management and streamline inference workflows.
To learn how to implement similar improvements, explore the AWS Neuron documentation and examples you can reference AWS Neuron Document. You can also visit Furbo website to explore Furbo’s AI-powered features and see how the Furbo ecosystem keeps your pets safe.
About the authors
Chen-Hsin Ding** is a Staff Machine Learning Engineer at Tomofun, with over 10 years of software development experience. He leads Generative AI projects and works closely with backend teams to design practical AI system architectures, focusing on bringing MLOps best practices into the AI team and delivering production-ready LLM and RAG applications. Outside of work, Chen-Hsin enjoys brewing coffee and listening to movie soundtracks and jazz on his hi-fi audio system.
Ray Wang is a Senior Solutions Architect at AWS. With 15 years of experience in the IT industry, Ray is dedicated to building modern solutions on the cloud, especially in NoSQL, big data, machine learning, and Generative AI. As a hungry go-getter, he passed all 12 AWS certificates to make his technical field not only deep but wide. He loves to read and watch sci-fi movies in his spare time.
Howard Su is a Solutions Architect at AWS. With extensive experience in software development and system operations, he has served in various roles including RD, QA, and SRE. Howard has been responsible for the architectural design of numerous large-scale systems and has led several cloud migrations. Following years of deep technical accumulation, he is now dedicated to advocating for DevOps by leveraging Generative AI to build self-healing, “AI-Native” infrastructures, transitioning the SDLC from traditional orchestration to a truly intelligent, predictive ecosystem.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み