プロンプト最適化の探求
LangChain Blog は、大規模言語モデルを用いたプロンプト最適化手法の体系的なベンチマークを実施し、Claude Sonnet が最も効果的であり、ドメイン知識が不足するタスクでは精度を約 200% 向上させる可能性を示した。
キーポイント
プロンプト最適化手法の比較検証
Few-shot prompting を含む 5 つの異なるシステム的手法を実装・ベンチマークし、従来の手動試行錯誤との違いを定量的に評価した。
モデル性能の相違と推奨
gpt-4o, o1, Claude Sonnet の 3 モデルを比較し、プロンプト最適化タスクにおいては o1 よりも Claude Sonnet がより高い成果を示した。
効果的な適用領域とインパクト
モデル自体がドメイン知識を持たないタスクにおいて最適化が最も有効であり、ナイーブなベースラインに対して約 200% の精度向上を達成した。
長期記憶としての最適化
データから直接適応して学習するプロンプト最適化は、モデルの「長期記憶」を形成する一種のメカニズムとして位置づけられる。
影響分析・編集コメントを表示
影響分析
この記事は、プロンプトエンジニアリングを単なる調整作業から、データ駆動型のシステム最適化へと昇華させる重要な知見を提供しています。特に、特定のモデル(Claude Sonnet)の優位性と、適用条件(ドメイン知識不足時)を明確に示すことで、実務におけるリソース配分やツール選定の指針となるでしょう。
編集コメント
プロンプトエンジニアリングの分野において、どのモデルが最適化タスクに最も適しているかを定量的に示した点は非常に貴重です。実務では「万能な手法」ではなく「ドメイン知識の有無に応じた使い分け」が重要であるという結論は、現場の運用戦略を見直すきっかけとなるでしょう。
クリッシュ・マニア(https://www.linkedin.com/in/krishmaniar4?ref=blog.langchain.com)とウィリアム・フー=ヒンソーン
*より多くのプロンプト最適化手法のベータテストにご興味がある場合は、*こちら*の関心表明フォームにご記入ください。*
プロンプトを作成する際、私たちは大規模言語モデル(LLM)に適用する意図を、雑多なデータに対して伝えようとしています。しかし、すべてのニュアンスを一度に効果的に伝えるのは困難です。プロンプティングは通常、手動の試行錯誤によって行われ、より良い結果が得られるまでテストと調整を繰り返します。一方、DSPyやpromptimのようなツールは、実データ上での計測とテストを通じて意図と指示のギャップを埋めることで、プロンプト「プログラミング」および体系的なプロンプト最適化の有効性を示しています。本記事では、以下の取り組みを行います:
- プロンプト最適化のベンチマーク用に、検証可能な結果を持つ5つの異なるデータセットを選定
- プロンプトを体系的に改善する5つの異なる手法を実装し、ベンチマークを実施
- 3つの異なるモデル(gpt-4o、claude-sonnet、o1)がプロンプト最適化においてどれほど優秀に機能するかをベンチマーク
結論:
- プロンプト最適化に推奨されるモデルは、o1 ではなく claude-sonnet です
- プロンプト最適化は、基盤モデルのドメイン知識が不足しているタスクにおいて最も効果的です
- 上記のような状況では、プロンプト最適化により、単純なベースライン・プロンプトと比較して精度が約 200% 向上することがあります
- このような状況におけるプロンプト最適化は、データから直接適応する方法を学習する一種の長期記憶(long-term memory)と見なすこともできます
検証内容
私たちは、5 つの一般的なプロンプト最適化手法(詳細な説明は後述)をベンチマークしました:
- フューショット・プロンプティング(Few-shot prompting):トレーニング例を用いて期待される動作のデモンストレーションを行う手法
- メタ・プロンプティング(Meta-prompting):大規模言語モデル(LLM)を用いてプロンプトの分析と改善を行う手法
- 反射付きメタ・プロンプティング(Meta-prompting with reflection):更新されたプロンプトを確定する前に、LLM に分析の検討と批判的思考を行わせる手法
- プロンプト勾配(Prompt gradients):各例に対して「テキスト勾配」として対象的な改善提案を生成し、それらを別の LLM 呼び出しで適用する手法
- 進化的最適化(Evolutionary optimization):制御された変異を通じてプロンプト空間を探索する手法
私たちは、一般的なタスクを表す 5 つのデータセット上で、O1、GPT-4、Claude-3.5-Sonnet の 3 つのモデルに対してこれらを実行し、以下の主要な問いに答えることを意図しました:
- プロンプト最適化はいつ最も効果的か?
- 最先端モデルの中で、プロンプト最適化にどのものが適しているか?
- どのアルゴリズムが最も信頼性が高いか?
アルゴリズム
私たちは、プロンプトの改善方法に関する独自の理論を持つ 5 つの異なるプロンプト最適化アプローチをテストしました:
Few-shot プロンプティング
最も単純にテストされた手法として、トレーニングセットから最大50例を選び(数エポックにわたってサンプリング)、それらを期待される動作のデモンストレーションとしてプロンプトに含めました。これは学習効率が良好です(変更を提案するためにLLM呼び出しが必要ないため)、ただしテスト時のトークンコストが高くなるという課題があります(典型的なデモンストレーションには、単一の直接指示よりも多くの内容が含まれるため)。
メタプロンプティング
これは最も単純なインストラクションチューニング手法でした。まず、対象となるLLMに対して例を処理させました。その後、出力に対するスコアを計算しました。なお、これには評価者のセットアップが必要です。次に、メタプロンプティング用のLLMに対して、入力例、出力、参照出力(利用可能な場合)、およびそれらの出力に対する現在のプロンプットのスコアを示しました。これらの変数に基づき、LLMにより良いプロンプトの作成を依頼します。このプロセスをミニバッチで繰り返し、定期的に保持された開発(dev)セットで評価を行います。devセットのスコアが最も高いプロンプトを保持します。
反射付きメタプロンプティング
最初のステップで用いたメタプロンプティングの手法を再利用しつつ、LLM に「思考(think)」および「批判(critique)」ツールの使用オプションを提供します。これらのツールは、特定のプロンプト更新を確定する前に、LLM がスクラッチパッドに思考を書き出す機会を与える以上のことは行いません。これにより、LLM は次のプロンプト更新を確定する前に、より多くのテスト時計算(test-time compute)を用いて過去のプロンプトを分析し、基礎となるデータ分布の中に隠れたパターンを探すことが可能になります。
プロンプト勾配(Prompt Gradients)
Pryzant らの論文「Automatic Prompt Optimization」などで普及したこのアプローチは、最適化をより小さなステップに分割します。

- 現在のプロンプトの出力をスコアリングする
- LLM を用いて、プロンプトが失敗した各例に対して具体的なフィードバックを生成する(これらが「勾配」です)
- 収集したこれらの「勾配」に基づいてプロンプトの更新案を提案する
この考え方は、変更を行う前に細粒度(fine-grained)のフィードバックを収集することで、メタプロンプティングアプローチよりもより焦点を絞った改善につながるとするものです。
進化的最適化
これらのアルゴリズムは「世代」において動作し、複数の世代のグループがより大きなカリキュラムのフェーズによって整理されます。各世代において、アルゴリズムは半ランダムな「突然変異」(本稿のケースでは、LLM の支援を受けて作成された異なる種類のプロンプト更新)を適用して候補となるプロンプトを作成します。各世代の終了後、最もパフォーマンスの高いプロンプトが保持されます。
これらの実験では、Cui らによる最近の手法である PhaseEvo を適応させました。この手法は、前述のような直接的な「テキスト勾配」アプローチと、既存の個体群における共通パターンに基づいて新しいプロンプトを作成するよう LLM に指示する、より「大域的」または横断的な更新を組み合わせています。理論的には、これによりプロンプト個体群全体における多様性の探索を深めることで、アルゴリズムが局所最適解から脱出するのに役立ちます。PhaseEvo はフェーズ単位で動作します:
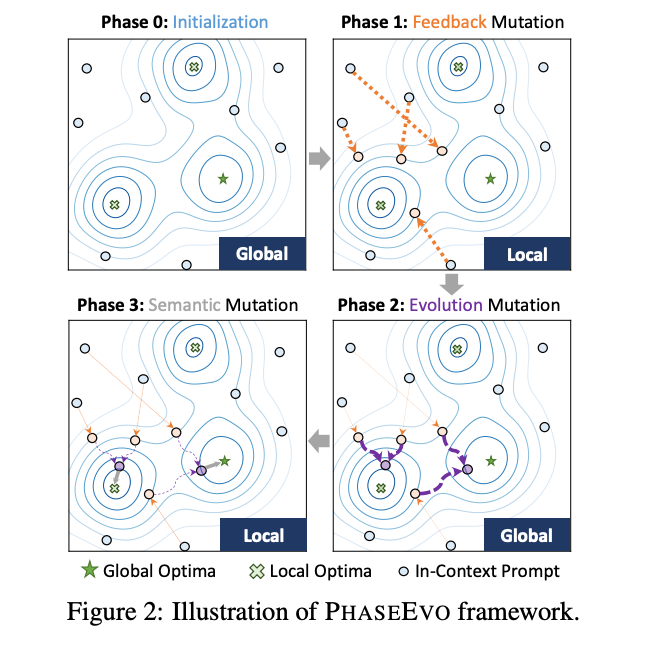
- 多様な初期プロンプトを生成する(一連のトレーニング例に対して期待される出力を作成すると推測された指示を予想し、それらのプロンプトをより多様になるよう言い換える)
- 最良のパフォーマンスを示したプロンプトにプロンプト勾配を適用する(詳細は前述のプロンプト勾配セクションを参照)
- 上位5位のパフォーマンスを示したプロンプトの新しいバリエーションを、言い換えを通じて作成する
- 成功したプロンプトを組み合わせて、それぞれの最良の要素を抽出する。これにより、最も異なる2つ以上の既存プロンプトから新しいプロンプトが生成される。この手法は既存のプロンプトを凝縮または拡張することに焦点を当てるため、局所的なエラーに陥るのを避け、さらなる探索を促進する。
- 勝者に対して勾配最適化を繰り返し適用して完了させる。
これらのアプローチに対する仮説は、大規模言語モデル(LLM: Large Language Model)は、データを全体として十分に分析したり、他のプロンプティング技法を十分に探索したりすることなく、観察されたエラーに基づいた表面的な修正を行うことに陥りがちであるというものである。構造化されたプロンプト進化は、より単純なヒルクライミング(山登り法)アプローチと比較して、より大域的に最適な解を見つけるプロセスを助ける可能性がある。
データセット
- これらのベンチマークを行うために、5つのデータセットを作成した。
- サポートメールのルーティング 3:着信メールごとに、3 人の担当者の中から適切な担当者に振り分ける。
- サポートメールのルーティング 10:(1) と同様だが、担当者が 10 人に増える。各担当者の「ドメイン専門知識」の区別がつかれにくくなるため、より困難なタスクとなる。
- 多言語数学:LLM に数学の文章題が与えられ、その答えを 5 か国の言語のいずれかで記述するよう求める。どの言語を使用するかは、文章題のトピックやテーマによって決定される(スポーツ→韓国語、宇宙→アラビア語、料理→ドイツ語、音楽→英語、野生生物→ロシア語)。プロンプトも最適化アルゴリズムも、なぜ特定の目標言語が選択されるのかを理解していないため、最適化アルゴリズムはデータセットに隠された潜在パターンを発見できなければならない。
- シンプルなメールアシスタント:これは合成データセットであり、LLM のドメイン知識で十分にカバーできるタスクにおいてプロンプト最適化が有用かどうかをテストすることを目的としている。LLM は、特定のメールに対して無視するか、返信するか、ユーザーに通知するかの分類を行うよう求められる。
- 奇抜なメールアシスタント:上記のデータセットと似ているが、より隠れた優先順位ルールに基づいている。注記:これらの優先順位ルールは奇抜であり、回答ラベル自体は LLM のドメイン知識に含まれるものの、優先順位ルールそのものは含まれていないことを意味する。私たちは、回答の正解ラベルを提供するために、忙しく奇抜なテック企業の最高経営責任者(CEO)のペルソナを構築した。
結果
最適化アルゴリズムを駆動するメタプロンプティングLLMとして、OpenAIのGPT-4oおよびO1モデル、AnthropicのClaude-3.5-sonnetを用い、5つのデータセット全体で実験を実行しました。対象となるLLMはGPT-4o-miniです(つまり、他のモデルを使用してGPT-4o-mini用のプロンプトを最適化しています)。
各アルゴリズムについて、開発セット(dev set)で最高のスコアを示したプロンプトを最適化実行の最終出力として選択しました。そのプロンプトについて、テスト分割(test split)における3回のランの平均スコアを棒グラフでプロットしました**。バイナリのパス/フェイル指標に対してウィルソン信頼区間を用いて計算された95%信頼限界も示されています。付録では、各実験の学習ダイナミクスをより明確に示すため、各エポック(進化アルゴリズムの場合はフェーズ)の開発セットスコアもプロットしています。
ベースラインとして、各タスクのスタータープロンプトに対するGPT-4o-miniのスコアと比較しました。また、ベースラインプロンプトにおいて他のベースモデル(Claude-3.5-sonnet、O1、O1-mini、GPT-4o)がどのように振る舞ったかという結果も含まれています。以下が私たちの発見です。
*注記:進化プロンプティングアルゴリズムの実行中にO1エンドポイントでコンテンツ違反によるフラグが散発的に発生したため、完了できなかったいくつかのO1実験は省略しました。
サポートメールルーティング(3)
最適化アルゴリズムはすべてベースラインのプロンプトに対して一貫して改善を示し、勾配法と進化論的手法の両方で同様の向上が見られました。Claude はすべてのアプローチにおいて GPT-4o を大きく上回る結果となりました。一方、メタプロンプティング手法を用いた場合、Claude も 4o も開発用データセットにおいて大幅な改善には至りませんでした。
以下はテスト分割における結果です。フューショットプロンプティングは一貫して性能を向上させましたが、最適解には届かず、4o-mini の設定はメタプロンプティング手法の中で最も低い性能のものよりもわずかに上回る程度でした。また、より複雑な進化論的手法も他のアルゴリズムをわずかに上回りました。Claude は O1 よりも基盤モデルの最適化においてやや優れた結果を示し、GPT-4o は遅れを取っています。

サポートメールルーティング (3) データセットに対する実験のテストセットにおける性能。プロンプトとモデルの組み合わせがメールを正しい担当者へ割り当てた場合、回答は正解 (1) とみなされます。各実験設定では、開発用分割で最も高いパス率を示したプロンプトが選択され、テスト分割で評価されました。モデルおよびアルゴリズムごとの集計は算術平均を用いて行われました。サポートメールルーティング (10)
これは、以前のデータセットと同様のスタイルを持つ、やや難易度の高い10クラス分類問題です。以下の曲線からわかるように、単純なメタプロンプティングやメタプロンプティング+リフレクションアルゴリズムを使用した場合、GPT-4oが開発セットで収束に失敗することは、テスト分割におけるパフォーマンスの悪さを予測するものです。
最終的なテスト結果は以下の通りです。最初のデータセットと同様、few-shotプロンプティングは一貫した改善をもたらしますが、他の多くのプロンプト最適化手法には依然として劣っています。

サポートメールルーティング(10)データセットの実験におけるテストセットのパフォーマンス。プロンプトとモデルの組み合わせがメールを正しい個人に割り当てた場合、回答は正解(スコア1)とみなされます。各実験設定では、開発分割で最高パス率を示すプロンプトが選択され、テスト分割で評価されました。モデルおよびアルゴリズムごとの集計は算術平均を用いて行われました。
O1はこのデータセットで真価を発揮し、同様の構成においてClaudeを上回るパフォーマンスを示しました。Gpt-4oは、進化的アルゴリズムと勾配アルゴリズムを除くすべてのケースで再び苦戦しました。驚くべきことに、GPT-4oはメタプロンプト+リフレクション構成を使用した場合、プロンプトの*劣化(regression)*を引き起こしています。これはおそらくトレーニング分割の特定の事象に対する過学習によるものです。
多言語数学
このデータセットは、開発セットの性能が epoch 3 または 4 付近の単一エポックで大半の改善を示したことから、おそらく最も不連続的なものでした(Appendix参照)。これは、データに単純な隠れたパターンが含まれているためです。つまり、目標言語は単語問題のトピックによって決定されます。以下はテスト分割の結果です。

多言語数学データセットに対する実験のテストセット性能。値が正しく、かつ正しい目標言語で表現されている場合、回答は正解(1)とみなされます。各実験設定では、開発分割で最も高いパス率を示したプロンプトが選択され、テスト分割で評価されました。モデルおよびアルゴリズムごとの集計は算術平均を用いて行われました。前述した不连续性のため、大半のモデル<>アルゴリズムの組み合わせはベースラインに対して大幅な改善を提供できませんでした。
推論モデル(O1 および O1-mini)は、ファーストショット例を効果的に活用する点で最も優れており、正しい解に収束できなかったすべての手法を上回りました。しかし驚くべきことに、O1 はファーストショットを活用できたものの、プロンプト指示の最適化は不十分でした。O1 はいかなるアルゴリズムにおいても、そのトリックを発見できませんでした。
Claude および(やや驚くべきことに)GPT-4o は、進化型アルゴリズムを用いて解を発見することができました。このアルゴリズムは、特定の誤りに繰り返し焦点を当てるのではなく、局所情報と大域情報を捉えるためにカリキュラムを通じて最適化を実行します。同様に、Claude はメタプロンプトとリフレクションの組み合わせにおいても正しい解を発見することができました。
メールアシスタント(シンプル版)
このデータセットは、モデルに対してメールアシスタントがユーザーに通知するか、メールを無視するか、それともメールに直接返信するかどうかを判断させるものです。このタスクは比較的明白なルールに従っているため、基本となるプロンプト構成が良好に機能することを期待しています。以下は学習曲線です。
そして、以下のものがテスト結果です。一目でわかるように、モデルとアルゴリズムの組み合わせ間で結果は非常に一貫しています。

メールアシスタント(シンプル)データセットのテスト分割における性能(パス率)。各実験設定では、開発分割で最も高いパス率を示したプロンプトを選択し、テスト分割で評価しました。モデルおよびアルゴリズムごとの集計は算術平均を用いて行いました。
このケースでは、few-shot examplesが最も信頼性の高い改善をもたらします。このタスクは、ターゲットモデルの既存の動作から遠く離れた隠れたパターンをオプティマイザーが発見する必要はありません。パターンはほとんど隠れていません。そのため、few-shotが期待される動作を伝えるのに最も優れた役割を果たします。
直接プロンプト最適化のアプローチ(勾配、メタプロンプト)は、モデルがすでに知っていることを超えて、合理的な指示を抽出してモデルを導くことが難しい状況にあります。私たちは、オプティマイザーが失敗に明示的に対応する指示の追加みに焦点を当てるよう指示されていた場合でも、メタプロンプティングは不要な指示を含みやすいことに注意しました。O1 と GPT-4o は、このタスクの支援でどちらも苦戦しました。
メールアシスタント・エキセントリック
このタスクは、アルゴリズム間の興味深い違いを明らかにしました。進化的アプローチはトレーニングを通じて着実な改善を示しましたが、完璧なスコアには到達しませんでした。さらに重要なのは、その改善が 3 つの組み合わせのうち 2 つにおいてテストセットのパフォーマンスへより信頼性高く転移したことです。
ここで、Claude は GPT-4o および O1 を上回ります。進化的アルゴリズムは一般的に他の 2 つの手法を上回りますが、O1 はその設定においてパフォーマンスが低いようです。

総合結果
以下に、テストされたすべてのデータセット全体で各実験設定の平均パーセント変化をプロットします。各指標について95%信頼区間を描画するためにブートストラップサンプリングを使用します。また、結果をオプティマイザーモデルおよびアルゴリズム別にグループ化しています。パーセント変化は、GPT-4o-miniベースラインに対するターゲットモデルへのオプティマイザーの影響を表します。100%とは、相対的な影響が2倍になったことを意味し、例えば元のプロンプトがあるタスクで20%のスコアを得た場合、最適化されたプロンプトは40%になります。
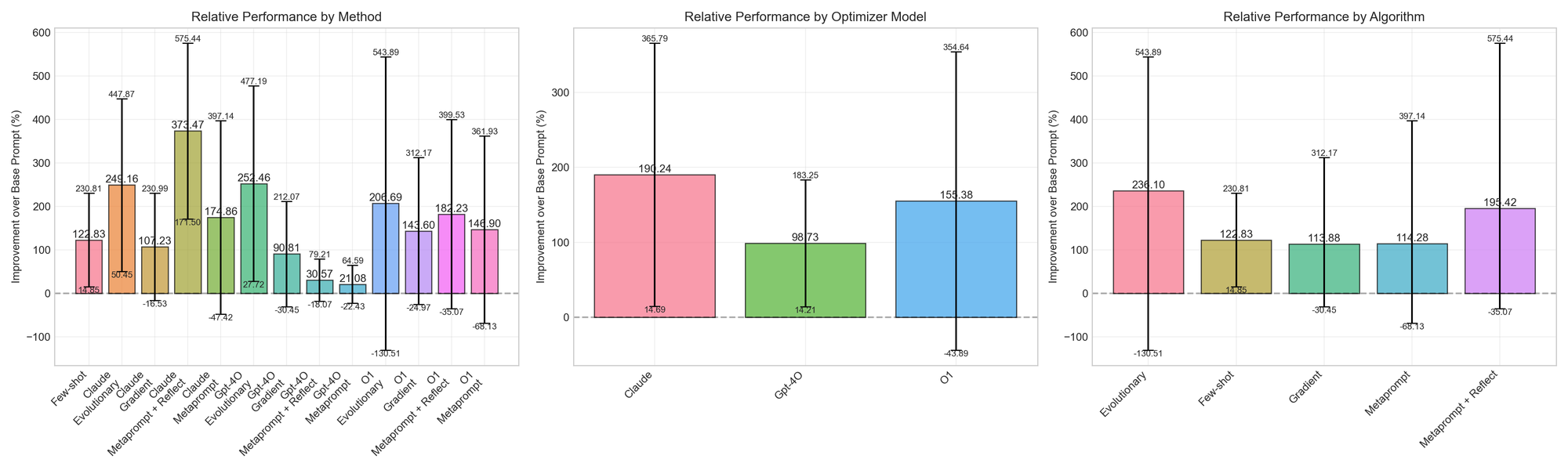
ベースラインに対する平均相対改善率(100%はパス率の2倍、200%は3倍など)。ご覧いただけるように、結果には誤差範囲が広く存在します!これらのデータセットに対して多くのアルゴリズム<>モデル設定で一貫した改善が見られるものの、実験の下限は負 - 現在の設定では、堅牢なシステムを導くのではなく、プロンプトがトレーニング例に過学習してしまうことがあります。これらの手法を適用する際は、訓練用および開発用分割で確認した改善が、実際により整合性の取れた行動につながっていることを確認するために、独立したテスト分割を維持し続けることが重要です。
上記の結果から、Claude と O1 は平均的なパフォーマンスで同等の性能を示していますが、O1 の結果には非常に大きなばらつきが見られます。もし勝率のみを重視するのであれば、その一貫性はより明確です。テストされた設定において、Claude はより信頼性の高い最適化モデルでした。
O1 の処理速度が遅いこと、コストが高いこと、さらに API が不安定であること(OpenAI は半頻繁に当社の生成結果を利用規約違反として誤ってフラグを立てていました)といった要素を加味すると、現時点では Sonnet 3.5 を優先的な最適化モデルとして推奨することに問題はありません。O3 やその他のモデルの発売に伴い、今後の推奨事項を更新することも楽しみにしています。
得られた知見
上記の結果は、大規模言語モデル(LLM: Large Language Model)が効果的なプロンプトエンジニアリングを行えるという既存の文献を概ね支持するものです。これらの実験は、LLM がいつ効果的であり、いつ効果的でないかについてもいくつかの示唆を与えています。
- メタプロンプティングは、大規模言語モデル(LLM)のドメイン知識に含まれていなかった可能性のある、データ内のルールや好み、その他の明確なパターンを発見する際に特に有用です。つまり、望ましい動作を例を通じて定義し、それらが合理的な指示の従順者である限り、その動作を他の LLM に翻訳するようオプティマイザーに依存することができます。これにより、宣言的プロンプトプログラミングモデルが可能になります。
- メタプロンプティング(指示微調整経由)は、単純なメール分類データセットで示されたように、好みのニュアンスを伝達する際には有用ではありません。単純なメールデータセットでは、区別が明確なルールや条件分岐よりも微妙な点に関わるものであったため、すべてのプロンプト微調整アプローチが、ファーストショット・プロンプティング(few-shot prompting)アプローチよりも低いパフォーマンスを示しました。
- 私たちは (1) と (2) から、ファーストショット・プロンプティングと指示微調整を組み合わせることで補完的な改善が得られると推測しています。これは Opsahl Ong 氏らの研究や Wan 氏らの研究などの既存の結論を支えるものです。ファーストショットの例は単純な指示よりも多くの情報を伝達しますが、おそらく自社企業のエージェントの一部となる複雑な条件分岐やルールは捉えきれません。一方、反射(reflection)、「テキスト勾配」、または進化的アルゴリズムを通じたプロンプト最適化は、既存のパフォーマンスやデータセットの特徴に基づいてより標的を絞った改善を行い、よりトークン効率的な方法でそれを実現します。
- メタプロンプティングはモデルに新しい能力を付与するものではありません。多言語数学データセットの場合、GPT-4o-mini は最適化された構成のいずれにおいても 65% のパス率を上回ることはなく、これは主に推論エラーによるものです。オプティマイザーはモデルにどのように振る舞うべきかを指示することに成功しました(これは場合によっては、例示された推論軌跡を通じてより優れた思考方法を誘発することがあります)、しかし、それらはより強力な推論能力や複雑なドメイン固有の知識を解き放つものではありません。
評価を超えて
私たちは、チームがLLMアプリケーションを体系的に評価できるよう支援するためにLangSmithを開発してきました。優れた評価により、問題が発生した際に検知し、システムの挙動を理解することができます。しかし、評価のために構築するデータセットと指標は、さらに価値のあるものを解き放ちます。それは、最適化を通じてシステムを体系的に改善する能力です。
私たちの実験で使用されたデータセットは、明確な検証可能な結果を持っていたため、最適化に対して良好に機能しました。
- 正解ラベル付きのルーティング判断
- 検証可能な数学的答案
- プログラム的にチェック可能な言語制約
これは重要です。曖昧または信頼性の低い指標に対して最適化を行うと、プロンプトが改善されるのではなく悪化する可能性があるからです。曖昧な基準に基づいて出力を判断するLLMは、実際の要件ではなく自身のバイアスに向かって最適化してしまいます。
LangSmithでアプリケーションのパフォーマンスを追跡している場合、効果的なプロンプト最適化に必要な基盤をすでに構築しています。失敗の原因を理解するのに役立つデータセットは、体系的な改善を推進することができます。データ、指標、学習がループを閉じます。
プロンプト最適化を長期記憶として捉える
最適化とは学習であり、その意味で「常時オン」の行動パターンを捉える長期記憶の特殊なケースとしてプロンプト最適化を考えることが有用です。
従来のメモリシステムが情報データベース(ベクトル、グラフ、その他)に情報を保存するのに対し、プロンプト最適化はそれらをエージェントのプロンプト内に直接保存し、常にコンテキスト内で利用可能にします。これにより、すべての意思決定に影響を及ぼすことが保証されます。これは、行動ルール、スタイルの好み、主要な人格特性などのコアパターンを保存する際に有用です。
メモリの「学習と改善」のプロセスは、従来のプロンプト最適化と非常に似ていますが、更新のスケジュール方法と保存場所がわずかに異なります。プロンプト最適化や一般的な学習アルゴリズムで機能する同じ手法が、メモリにも適用できる可能性があります。これは私たちが積極的に調査している視点です。
なぜこれが重要なのか
これらの結果は、私たち(およびDSPyのような他の組織)が観察してきたことを支持しています:LLM駆動のプロンプト最適化は、プロンプトを体系的に改善し、今日のプロンプトエンジニアリングを支配する手動の試行錯誤プロセスの多くを自動化できます。この方法論をすべての関係者にアクセス可能にすることで、より良く、より高度なシステムを構築するのを助けることができます。
しかし、それは万能薬ではありません。最適化されたプロンプトのいずれもテストセットを飽和させず、改善度はタスクによって異なりました。これは、プロンプト最適化はLLMアプリケーションを改善するためのより広範なツールキットにおける一つの道具として見なすのが最善であることを示唆しています。
これらの知見を LangSmith に直接統合する計画です。これにより、チームは手動のプロンプトエンジニアリングから脱却し、より高度な作業に移行できるようになります。目標は人間の判断を排除することではなく、それをより体系的でデータ駆動型のものにする点にあります。
付録
トレーニングダイナミクス
これまでのセクションでは、主にホールドアウトされたテスト分割における*最終的な*プロンプトのパフォーマンスについて議論しました。以下では、各データセットの開発分割におけるアルゴリズムのトレーニングダイナミクスのチャートを示します。これらのチャートは、異なるアルゴリズムが提供されたデータセットにどのように適合するかを示しています。これらのチャートと最終スコアを比較することで、アルゴリズムが一貫した改善につながらない方法でデータに*過学習(overfit)*している程度が明らかになります。
サポートメールルーティング (3)
ほとんどの最適化アルゴリズムは、ベースラインプロンプトに対して一貫して改善を示しました。勾配法と進化的アプローチの両方で同様の向上が見られました。Claude は、すべてのアプローチにおいて GPT-4o を上回る結果を示しました。一方、Claude と 4o は、メタプロンプティングアプローチを使用した場合、開発セットにおいても大幅な改善を示しませんでした。
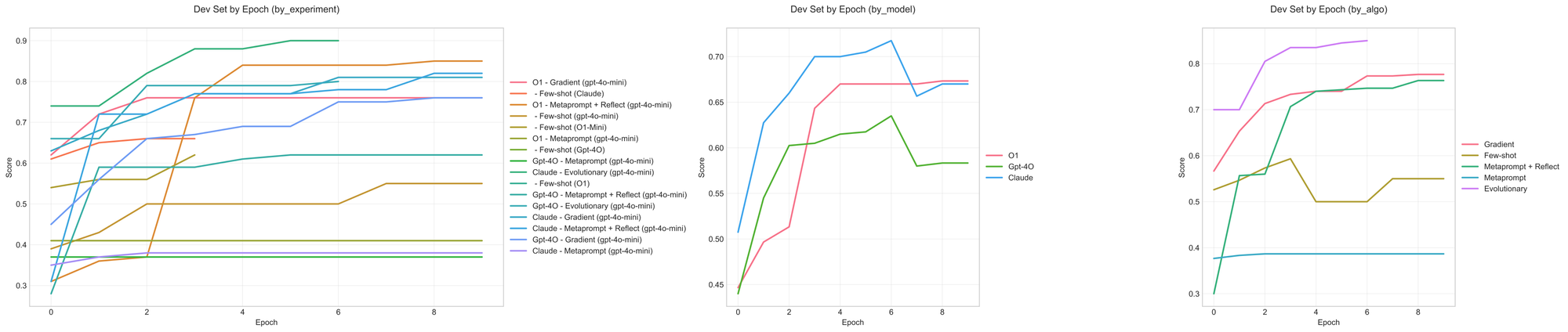
時間経過に伴う開発セットでのスコアサポートメールルーティング (10)
単純なGPT-4o搭載のメタプロンプティングや、メタプロンプティングにリフレクション(振り返り)機能を追加した設定では、このデータセットの分類ルールを学習できませんでした。私たちはすぐに共通のパターンを目撃し始めています:曲線が平坦なままの場合、それは明らかに学習できていません。一方、曲線がすぐに完璧なスコアに近づくと、それは過学習(オーバフィッティング)の可能性が高いです。中間的なアルゴリズムで、一貫した改善が見られるものが、最も良いテストセットのパフォーマンスにつながりやすいことがわかります。
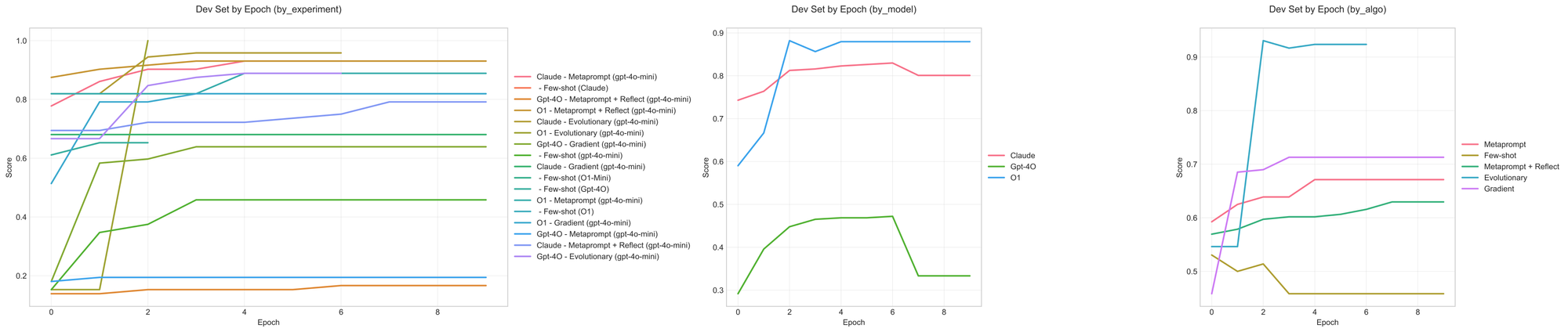
多言語数学
このデータセットは、おそらく最も不連続的(discontinuous)なものでした。これは、いくつかの設定において開発セットの性能が、第2エポックや第3エポック(あるいはそれ以降)で改善の大部分を得ていることからも示されています。また、これは最後の試行数回だけでなく、編集履歴(edit history)を追跡することの有効性も浮き彫りにしています。LLMは、編集の履歴をより効果的な更新に変換できるという点で、非常に有用なメタオプティマイザー(最適化エージェント)です。
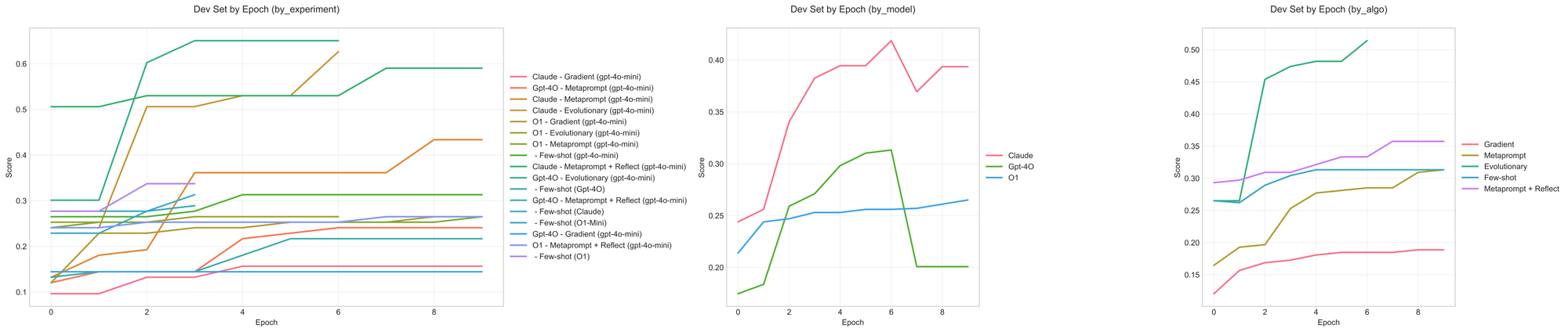
メールアシスタント シンプル
ここでは、開発セットで最高パフォーマンスを達成するプロンプト最適化設定(gpt-4o + メタプロンプティング + リフレクション)が、実際にはテストセットで良いパフォーマンスにつながらないという事象を再び確認できます。
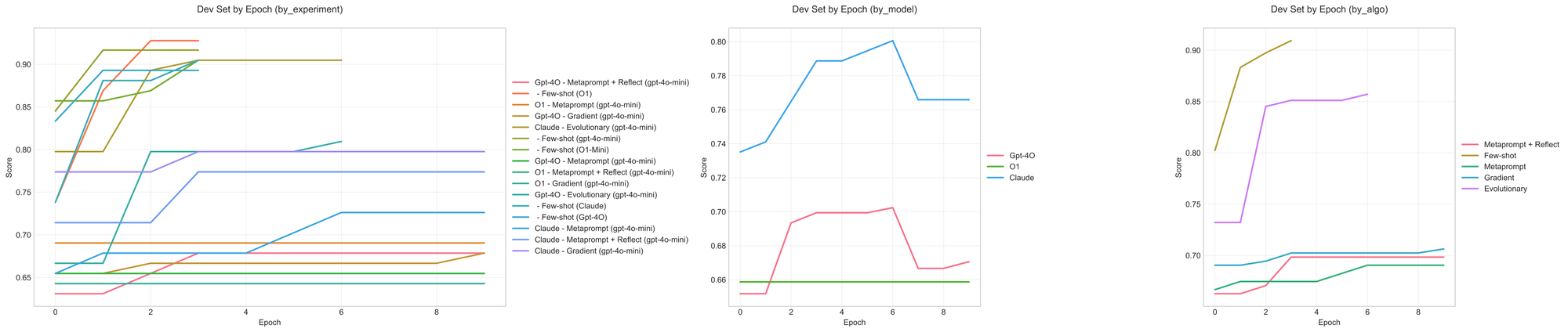
メールアシスタント エクリュック(奇抜なスタイル)
Claude+進化的アルゴリズムの設定はテスト分割において最高性能を達成しましたが、開発セットに対して最も速く(かつ最も多く)適合したのはO1搭載のアルゴリズムであることがわかります。o1進化的設定は、最終的にテストセットにおけるシステムの品質を大幅に改善できなかったものの、データセットに対して最も速く適合しました。一方、開発セットに適合しない設定は、テストセットにおけるプロンプトの大幅な改善にも失敗しています(上記参照)。
プロンプトの比較
最終的に私たちが重視するのは正確なプロンプトの内容よりも下流指標ですが、最適化アルゴリズムが実際に何を修正することを学習し、どのような変更が改善につながったのかを見るために最終的なプロンプトを確認するのは示唆に富みます。ここでは、Support 10-way分類データセットを例として取り上げます。まず、Sonnetによって駆動された4つのアルゴリズムを比較します。




4つのアルゴリズムすべてが、主要な割り当てルールを学習することに成功しました。勾配ベースのアプローチは、境界を明確にするために曖昧な領域を見つけ出す点において、他の手法に比べて頑健性に欠けるように見えました。一方、他のアルゴリズムは「優先順位ルール」を特定するか、あるいはこれらの境界を明確にするための意思決定木(decision trees)を独自に構築する傾向がありました。
同じアルゴリズムを用いて最適化モデル(optimizer models)を比較すると、動作のわずかな違いも確認できます。このケースでは、O1は異なる技法(合成few-shotsおよび段階的指示)を組み込む際に創造性を見せやすく、ルールセットの間には特徴的な区切り記号(「—」)を使用する傾向があります。一方、Claudeはこの場合において最も簡潔かつ直接的な表現を採用していますが、両者とも優先順位ルールとドメインマッピング(domain mapping)の学習には成功しています。GPT-4oは、情報密度が低い指示文を生成する傾向があるようです。


原文を表示
By Krish Maniar and William Fu-Hinthorn
*If you are interested in beta-testing more prompt optimization techniques, fill out interest form *here*.*
When we write prompts, we attempt to communicate our intent for LLMs to apply on messy data, but it's hard to effectively communicate every nuance in one go. Prompting is typically done through manual trial and error, testing and tweaking until things work better; on the other hand, tools like DSPy and promptim have shown the usefulness of prompt "programming" and systematic prompt optimization by closing the intent-instruction gap through measurement and testing on real data. In this post, we:
- Curate five different datasets with verifiable outcomes for benchmarking prompt optimization
- Implement and benchmark five different methods of systematically improving prompts
- Benchmark how well three different models (gpt-4o, claude-sonnet, o1) do on prompt optimization
Our conclusions:
- Our recommended model for prompt optimization is claude-sonnet (over o1)
- Prompt optimization is most effective on tasks where the underlying model lacks domain knowledge
- In the above situations, prompt optimization can show a ~200% increase in accuracy over naive baseline prompts
- Prompt optimization in these situations can also be thought of as a form of long-term memory: learning to adapt directly from your data
What we tested
We benchmarked five popular prompt optimization approaches (more detailed explanations later on):
- Few-shot prompting: use training examples as demonstrations of expected behavior
- Meta-prompting: use an LLM to analyze and improve prompts
- Meta-prompting with reflection: let the LLM think and critique its analysis before committing to an updated prompt
- Prompt gradients: generate targeted improvement recommendations for each example as "text gradients" and then apply those in a separate LLM call
- Evolutionary optimization: explore prompt space through controlled mutations
We ran these across three models (O1, GPT-4, and Claude-3.5-Sonnet) on five datasets representative of common tasks, intending to answer the following primary questions:
- When does prompt optimization work best?
- Which frontier models work well for prompt optimization?
- Which algorithms are the most reliable?
Algorithms
We tested five different approaches to prompt optimization, each with its own theory of how to improve prompts:
Few-shot prompting
For the simplest tested technique, we chose up to 50 examples from the training set (sampled over a few epochs) and included them in the prompt as demonstrations of expected behavior. This is efficient to learn (since no LLM calls are required to propose changes), though it leads to higher token costs at test time (since typical demonstrations contain more content than direct single instructions).
Meta-prompting**The was the simplest instruction-tuning approach. We first ran the target LLM over the examples. We then calculated scores on the outputs. Note: this requires evaluator(s) to be set up. We then showed the meta-prompting LLM examples of inputs, outputs, reference outputs (if available), and the current prompt's scores on those outputs. Based on those variables, we then asked the LLM to write a better prompt. We repeat this process in mini-batches, periodically evaluating on a held-out development (dev) set. The prompt with the highest dev set score is retained.
Meta-prompting with reflection**
We re-use the meta-prompting technique from the first step but give the LLM the option to use "think" and "critique" tools. These tools do nothing more than give the LLM an opportunity to write down thoughts in a scratchpad before committing to a particular prompt update. This helps the LLM use more test-time compute to analyze previous prompts and look for more hidden patterns in the underlying data distribution before committing to the next prompt update.
Prompt Gradients**Popularized by papers such as "Automatic Prompt Optimization" by Pryzant et al., this approach breaks optimization into smaller steps:
- Score the current prompt's outputs
- Using an LLM, generate specific feedback for each example where the prompt failed (these are the "gradients")
- Propose prompt updates based on these collected "gradients"
The idea is that collecting fine-grained feedback before making changes leads to more targeted improvements than the meta-prompting approach.
Evolutionary Optimization****These algorithms operate in "generations", with groups of generations organized by a phase of a larger curriculum. For each generation, the algorithm applies semi-random "mutations" (in our cases, different types of prompt updates created with the help of an LLM) to create candidate prompts. The best performing prompts are retained after each generation.
In these experiments, we adapted PhaseEvo, a recent technique by Cui et al. that combines direct "text gradient" approaches like the one described above with more "global" or lateral updates that instruct the LLM to create new prompts based on shared patterns in the existing population. In theory, this helps the algorithm overcome local optima through greater exploration of variations across the prompt population. PhaseEvo works in phases:
- Generate diverse initial prompts (by guessing instructions that would create the expected outputs for a set of training examples and then paraphrasing these prompts for more diversity)
- Apply prompt gradients to the best performers (See the prompt gradients section above for more information)
- Create new variants of the top 5 performing prompts through paraphrasing
- Combine successful prompts to capture their best elements. This generates a new prompt from two or more existing prompts that are most dissimilar. Since this focuses on distilling or expanding existing prompts, it avoids getting stuck on local errors and encourages further exploration.
- Repeat gradient optimization on the winners to finish.
The hypothesis for these types of approaches is that LLMs tend to get stuck making shallow corrections based on observed errors without sufficiently analyzing the data as a whole and without adequately exploring other prompting techniques. The structured prompt evolution in theory could help the process find a more globally optimal solution compared to the more straightforward hill-climbing approaches.
Datasets
We created five datasets to benchmark these on.
- Support email routing 3: for each inbound email, route them to the correct assignee (of 3 assignees).
- Support email routing 10: same as (1) but with 10 possible assignees. This is more challenging, since the "domain expertise" of each assignee is less distinct.
- Multilingual math: the LLM is given a mathematical word problem and must respond with the correct answer spelled out in one of 5 languages. Language is determined by the topic or theme of the word problem (sports->Korean, outer space-> Arabic, cooking -> German, music->English, wildlife->Russian). Neither the prompt nor the optimizer know why a target language is chosen, so the optimizer must be able to discover the latent pattern hidden in the dataset.
- Email assistant simple: this is a synthetic dataset meant to test whether prompt optimization is useful for tasks that are well-covered by the LLM's domain knowledge. The LLM is tasked with classifying whether to ignore, respond, or notify the user for a given email.
- Email assistant eccentric: this is similar to the dataset above, but based on more hidden preference rules. Note: these preference rules are eccentric, meaning even though the response labels are within the LLM's domain knowledge, the preference rules are not. We crafted a persona of a busy, eccentric tech mogul to provide the ground truth labels for the responses.
Results
We ran experiments across the five datasets using OpenAI's GPT-4o and O1 models, and Anthropic's Claude-3.5-sonnet as meta-prompting LLMs to drive the optimization algorithms. The target LLM is GPT-4o-mini (meaning we are using other models to optimize a prompt for GPT-4o-mini).
For each algorithm, we select the prompt with the best score on the dev set as the final output of the optimization run. For that prompt, we plot the average scores over three runs on the test split (in the bar charts)**. 95% confidence bounds are also shown, computed using Wilson score interval for the binary pass/fail metrics. In the appendix, we also plot the dev set scores for each epoch (or phase in the case of the evolutionary algorithm) to better show the training dynamics for each experiment.
As baselines, we compare the results against GPT-4o-mini scores on a starter prompt for each task. We also include results for how other based models (Claude-3.5-sonnet, O1, O1-mini, and GPT-4o) would have fared on the baseline prompt. Here is what we found.
*Note: Due to sporadic flagging for content violations in the O1 endpoint during the evolutionary prompting algorithm, we have omitted a couple o1 experiments that were unable to complete.*
Support email routing (3)
The optimizers consistently improved over the baseline prompt, with both gradient and evolutionary approaches showing similar gains. Claude notably outperformed GPT-4o across all approaches. Claude and 4o fail to improve much even on the dev set using the meta-prompting approach.
Below are the results on the test split. Few-shot prompting consistently led to improved, but sub-optimal performance, with the 4o-mini setup only slightly outperforming the worst of the meta-prompting techniques. The more involved evolutionary algorithm slightly outcompeted the other algorithms as well. Claude does a slightly better job at optimizing the underlying model than O1, with GPT-4o lagging behind.
Support email routing (10)
This is a slightly harder 10-way classification problem of a similar style to the previous dataset. As you can see from the curves below, GPT-4o's failure to converge on the development set when using the simple meta-prompting & the meta-prompting + reflection algorithms is predictive of poor performance on the test split.
The final test results are below. Similar to the first dataset, few-shot prompting gives consistent improvement, though it still lags behind most of the other prompt optimizer techniques.
O1 really shines on this dataset, outperforming Claude under similar configurations. Gpt-4o suffers once more in all but the evolutionary and gradient algorithms. Surprisingly, GPT-4o causes a prompt *regression* when using meta-prompt + reflect configuration, likely due to overfitting to specifics on the training split.
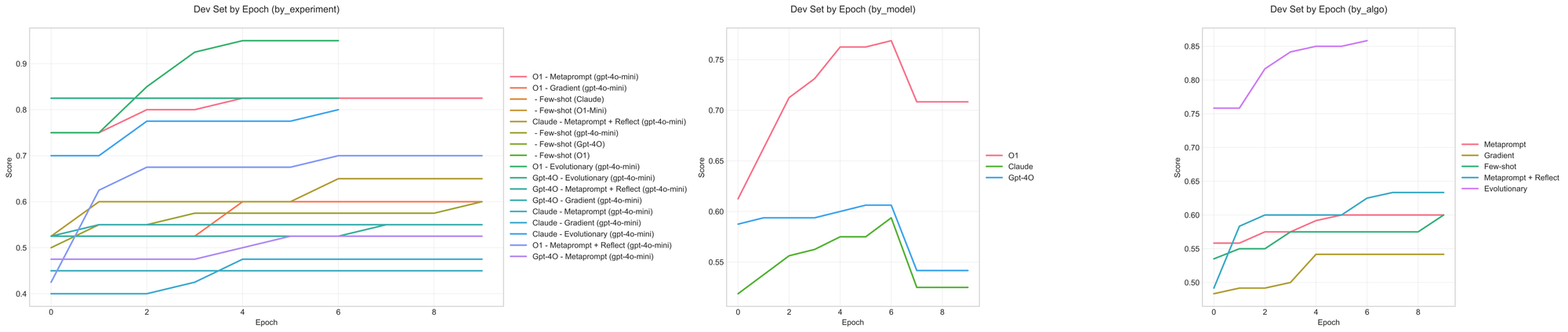
Multilingual math
This dataset was perhaps the most discontinuous, as shown by the dev set performance getting most of its improvements in a single epoch around epoch 3 or 4 (see Appendix). This is because the data contains a simple hidden pattern: the target language is determined by the topic of the word problem. Below are the test split results.
Due to the stated discontinuity, most of the model<>algorithm combinations failed to provide much improvement over the baseline.
The reasoning models (O1 and O1-mini) were the best at effecively leveraging the few-shot examples, beating out all the techniques that weren't able to converge to the correct solution. Surprisingly, though O1 was able to leverage the few-shots, it did a poor job of optimizing the prompt instructions. O1 was unable to discover the trick in any of the algorithms.
Claude and (somewhat surprisingly) GPT-4o were both able to discover the solution using the evolutionary algorithm (which runs the optimizer through a curriculum to capture local and global information rather than repeatedly focusing on specific errors). Similarly, Claude was able to discover the correct solution under the metaprompt + reflection setup.
Email assistant simple
This dataset prompts the model to decide whether an email assistant should notify the user, ignore the email, or respond to the email directly. It follows rules that are fairly obvious, meaning that we expect the base prompt configurations to work well. Below are the training curves.
And the following are the test results. As you can see at a glance, the results are fairly consistent across model<>algorithm combinations.
In this case few-shot examples produce the most reliable improvements. The task doesn't require the optimizer to uncover any hidden patterns far from the target model's existing behavior. The patterns are barely hidden. Because of this, few-shots do the best job of communicating the expected behavior.
The direct prompt optimization approaches (gradient, metaprompt) have a hard time capturing reasonable instructions to guide the model in this case beyond what it already knows. We noted that meta-prompting tends to include some unnecessary instructions, even if the optimizer is instructed to focus only on adding instructions that explicitly address failures. O1 and GPT-4o both struggled to assist on this task.
Email assistant eccentric
This task revealed interesting differences between algorithms. The evolutionary approach showed steady improvement throughout training, though never reached perfect scores. More importantly, its improvements translated more reliably to test set performance for 2 of the 3 combinations.
Here, Claude still outperforms GPT-4o and O1. The evolutionary algorithm generally outshines the other two techniques, though O1 seems to underperform in that setting.
Overall Results
Below we plot the average percentage change of each experimental setup across all tested datasets. We use bootstrap sampling to plot 95% confidence intervals for each metric. We also group results by optimizer model and by algorithm. Percentage change represents the optimizer's impact on the target model, relative to the GPT-4o-mini baseline. 100% means that the score has doubled in relative impact, so if the original prompt gets a 20% on a task, the optimized prompt is 40%, etc.
As you can see, the results have wide error margins! While we do see consistent improvements for many of the algorithm<>model settings for these datasets, the lower bound for most of the experiments is negative - the current settings sometimes cause the prompt to overfit to training examples rather than leading to robust systems. When applying these techniques, it continues to be important that you maintain a separate test split to confirm that the improvements you see on the train & development splits actually translates to more aligned behavior in reality.
As shown, Claude and O1 perform comparably on-average, but O1 has a very high variance. If you were to care just about the head-to-head win rate, the consistency is more clear: under the tested settings, Claude was a more reliable optimizer model.
Adding in O1's slower processing time, higher costs, and less reliable API (OpenAI semi-frequently incorrectly flagged our completions as violating the ToS), we feel comfortable recommending Sonnet 3.5 as the preferred optimizer model for now. We're excited to update our recommendations with the launch of O3 and other models.
What We Learned
The results above generally support the existing literature that LLMs are effective prompt engineers. These experiments also shed some light on when they would be (in)-effective.
- Meta-prompting is especially useful for discovering rules or preferences and other clear patterns in the data that may not have been in the LLM's domain knowledge. This means you can define the behavior you want through examples and rely on the optimizer to translate those behaviors to other LLMs so long as they are reasonable instruction followers. This makes declarative prompt programming models possible.
- Meta-prompting (via instruction tuning) is less useful for communicating nuance in preferences, as shown in the simple email classification dataset. All the prompt tuning approaches underperformed the few-shot prompting approach for the simple email dataset, where the distinction was less about bright-line rules and conditionals.
- We suspect from (1) and (2) that combining few-shot prompting & instruction tuning provides complementary improvements. This supports existing conclusions such by Opsahl Ong, et. al. and Wan, et. al. Few-shot examples communicate more information than simple instructions but don't capture complex conditionals and rules that will likely be a part of your own enterprise's agents. On the other hand, prompt optimization through reflection, "text gradients", or evolutionary algorithms can make more targeted improvements based on existing performance and dataset characteristics, and do so in a more token-efficient way.
- Meta-prompting doesn't endow the model with new capabilities. For the multilingual math dataset, GPT-4o-mini still didn't surpass 65% pass rate on any of the optimized configurations, largely due to reasoning errors. While the optimizers were able to instruct it on how to behave (which sometimes can induce better ways to think via example reasoning trajectories), they don't unlock more powerful reasoning abilities or complex domain-specific knowledge.
Beyond evals
We have been building LangSmith to help teams evaluate their LLM applications systematically. Good evaluation lets you detect when things go wrong and understand your system's behavior. But the datasets and metrics you build for evaluation unlock something even more valuable: the ability to improve your system systematically through optimization.
The datasets in our experiments worked well for optimization because they had clear, verifiable outcomes:
- Routing decisions with ground truth labels
- Math answers that can be validated
- Language constraints that can be programmatically checked
This matters because optimizing against fuzzy or unreliable metrics often makes prompts worse, not better. An LLM judging outputs based on vague criteria will optimize toward its own biases rather than your actual requirements.
If you're tracking your application's performance in LangSmith, you're already building the foundation needed for effective prompt optimization. The same datasets that help you understand failures can drive systematic improvements. Data, metrics, and learning close the loop.
Prompt optimization as long-term memory
Optimization is learning, and as such, it can be useful to think of prompt optimization as a special case of long-term memory that captures "always-on" behavioral patterns.
While traditional memory systems store information in databases (vector, graph, or otherwise), prompt optimization stores them directly in your agent's prompt so they are always available in context. Doing so ensures they influence every decision. This is useful for storing core patterns like behavioral rules, stylistic preferences, and key personality traits.
Memory's process of "learning and improving" is very similar to traditional prompt optimization, just with slight differences in how updates are scheduled, and where the updates are stored. The same techniques that work for prompt optimization and learning algorithms in general may also apply to memory. This is an angle we are actively investigating.
Why this matters
These results support what we (and others like DSPy) have observed: LLM-driven prompt optimization can systematically improve prompts and automate much of the manual guess-and-check process that dominates prompt engineering today. Making this methodology accessible to all stakeholders can help us all build better, more capable systems.
But it's not a silver bullet. None of our optimized prompts saturated the test sets, and the improvements varied across tasks. This suggests prompt optimization is best viewed as one tool in a broader toolkit for improving LLM applications.
We plan to integrate these insights directly into LangSmith to help teams move beyond manual prompt engineering. The goal isn't to eliminate human judgment, but to make it more systematic and data-driven.
Appendix
Training Dynamics
In the previous sections, we primarily discussed how the *final* prompts performed on the held-out test split. Below, we share charts of the algorithms' training dynamics on the development split for each dataset. These charts show how different algorithms fit to the provided dataset. Comparing these charts with the final scores also reveals the extent to which the algorithms *overfit* the data in ways that don't translate to consistent gains.
Support email routing (3)
Most of the optimizers consistently improved over the baseline prompt, with both gradient and evolutionary approaches showing similar gains. Claude notably outperformed GPT-4o across all approaches. Claude and 4o fail to improve much even on the dev set using the meta-prompting approach.
Support email routing (10)
Naive GPT-4o-powered meta-prompting & meta-prompting + reflection settings fail to learn the classification rules in this dataset. We quickly are seeing a common pattern forming: if the curves stay flat, they obviously don't learn. If the curves quickly approach a perfect score, they likely overfit. It's the algorithms in the middle and with consistent improvements that tend to translate to the best test-set performance.
Multilingual math
This dataset was perhaps the most discontinuous, as shown by the dev set performance getting most of its improvements in epochs 2, 3 (or even later) for a few of the settings. This also highlights the usefulness of tracking the edit history beyond the last attempt or two. LLMs are fairly useful meta-optimizers by being able to translate the history of edits into more effective updates.
Email assistant simple
Here again we see that the prompt optimization setting (gpt-4o + metaprompting + reflect) that achieves the highest performance on the dev split doesn't actually translate to good performance on the test split.
Email assistant eccentric
Though the Claude+evolutionary algorithm setting earned the highest test-split performance, we see that the algorithms that fit the dev set the fastest (and most) were those powered by O1. The o1-evolutionary setting fit the dataset the fastest, despite ultimately failing to significantly improve the quality of the system on the test set. On the other side, settings that don't fit the dev set also fail to improve the prompt significantly on the test set (above).
Comparing Prompts
While we ultimately care more about the downstream metrics than the exact content of the prompt, it can be illustrative to review the final prompts to see *what* the optimizers actually learn to modify, and what changes lead to improvements. We will take the Support 10-way classification dataset as an example. First, comparing the four algorithms when driven by Sonnet
All four of the algorithms were able to learn the primary assignment rules. The gradient-based approach seemed to be less robust about finding the areas of ambiguity to clarify the boundaries. The other algorithms identify either "priority rules" or invent decision trees to help clarify these bounds.
Comparing optimizer models on the same algorithm, you can also see slight differences in behavior. In this case, O1 seems more likely to be creative with incorporating different techniques (synthetic few-shots & stepwise instructions) and tends to use its characteristic section demarcators ("—") between rulesets, while Claude seems to be the most terse and direct in this case, but both these two learn priority rules as well as domain mapping. GPT-4o seems to create the least information-dense instructions.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み