本番環境におけるディープエージェントのランタイム基盤
LangChain Blogは、長時間実行するエージェントを本番環境で運用するために必要な堅牢な実行基盤、メモリ管理、人間による監督(HITL)、および観測可能性といったインフラストラクチャの重要性と、DeepAgentsによる実装アプローチを解説している。
キーポイント
本番環境用インフラの必要性
長期にわたるエージェントの実行には、特別なインフラストラクチャが必要であり、単なるモデル呼び出し以上の基盤設計が求められる。
主要技術要素の網羅
記事は耐久性のある実行(Durable Execution)、メモリ管理、人間による監督(HITL)、観測可能性(Observability)という4つの柱をカバーしている。
DeepAgentsによる実装例
LangChainのDeepAgentsプロダクトが、これらの複雑な要件をどのように実装し、本番環境へのデプロイを実現しているかを具体例として示している。
影響分析・編集コメントを表示
影響分析
この記事は、AIエージェントが実験段階から実用段階へ移行する上で直面する「運用の壁」を明確に示しており、開発者に対して単なるモデル性能だけでなく、インフラ設計の重要性を認識させる意義がある。LangChainという主要フレームワークの開発元からの提言であるため、業界標準のアーキテクチャ設計に一定の影響を与える可能性がある。
編集コメント
エージェントの「賢さ」だけでなく、「堅牢性」という運用面の課題に焦点を当てた実践的な記事であり、実装段階のエンジニアにとって有用な指針となる。

主要なポイント
- 良いハル(harness)は、エージェントに適切なプロンプト、ツール、スキルを提供します。しかし、本番環境で長時間実行されるエージェントを展開するには、耐久性のある実行(durable execution)、メモリ管理、マルチテナンシー、ヒューマン・イン・ザ・ループ(HITL)、そして観測可能性が必要です。このインフラストラクチャはハルの下層に位置し、クラッシュやデプロイ、長時間のタスク across してもエージェントを確実に稼働させ続けます。
- 耐久性のある実行(durable execution)は、他のすべての要素の基盤です。数分または数時間実行されたり、人間の承認を待って一時停止したり、実行中のデプロイを生き延びたりするエージェントには、プロセスの境界を超えて停止、再開、再試行ができるチェックポイント付きの実行が必要です。ストリーミング、ヒューマン・イン・ザ・ループ(HITL)、cron ジョブ、並行メッセージ処理はすべてこれの上に構築されます。
- 本番環境のエージェントには、オープンでモデル非依存のインフラストラクチャが必要です。Deep Agents は MIT ライセンスであり、エージェントはオープンプロトコル(MCP、A2A)を通じて公開され、メモリは独自の PostgreSQL に保存されます。チームはエージェントの動作を完全に可視化でき、書き換えなしで変更する能力を保持できます。
本番環境でロングホライゾンエージェントを展開するには、目的に特化したインフラストラクチャが必要です。このガイドでは、耐久性のある実行(durable execution)、メモリ管理、HITL、観測可能性について取り上げ、deepagents がこれらすべてを本番環境にデプロイする方法を解説します。
良いエージェントを作るには、良いハルが必要です。そのエージェントを展開するには、良いランタイムが必要です。
ハネスとは、モデルの周囲に構築するシステムであり、エージェントがそのドメインで成功することを支援します。これには、プロンプト、ツール、スキル、およびエージェントを定義するモデルとツール呼び出しのループを支えるその他のすべてが含まれます。ランタイムは、その下にあるすべての要素です:永続的な実行、メモリ、マルチテナンシー、可観測性、そしてチームがそれを再発明することなくエージェントを生産環境で稼働し続けるための仕組みです。
このガイドでは、エージェントをデプロイした際に表面化する生産環境での要件、それに対応するランタイムの機能、そして deepagents deploy がそれらの機能を.ship 可能な形にパッケージ化する仕組みについて解説します。
生産環境用エージェントのためのランタイム機能
このセクション全体を通じて、「ランタイム」とは LangSmith Deployment (LSD) およびその Agent Server を指します。LSD は生産環境でエージェントを実行し、Agent Server はアシスタント、スレッド、ラン、メモリ、スケジュールされたジョブのためのインターフェースです。以下の表は、各生産環境での要件と、それに対応するランタイムのプリミティブ(基本要素)のマッピングを示しています。
生産環境での要件
ランタイムの機能
信頼性
永続的な実行 (Durable execution)
メモリ
チェックポイント(短期間)、ストア(長期間)
ガイドレール (Guardrails)
ミドルウェア
マルチテナンシー
認証、認可、エージェント認証、RBAC(ロールベースのアクセス制御)
ヒューマンオーバサイト
ヒューインザループ(中断/再開)
リアルタイムインタラクション
ストリーミング、並行性制御(ダブルテキスト送信)
観測可能性
トレーシング、タイムトラベル
コード実行
サンドボックス
インテグレーション
MCP(Model Context Protocol)、A2A、Webフック
スケジュールジョブ
Cron
耐久性のある実行
エージェントはループを実行することで動作します。プロンプトが与えられると、モデルは推論を行い、ツールを呼び出し、結果を観察し、タスクが完了したと判断するまでこれを繰り返します。

ミリ秒単位で応答する通常のウェブリクエストとは異なり、このループは数分または数時間にわたることがあります。単一のランでは、数十回のモデル呼び出しが行われたり、サブエージェントが起動されたり、人間によるドラフトの承認を無期限に待ったりする可能性があります。そのループ内のどこかでクラッシュ、デプロイ、一時的な失敗が発生しても、それまでの作業が失われてはいけません。
実際には、あなたは以下の2つの場所でその影響を実感します:
長時間の実行はインフラストラクチャの障害に耐えうるものでなければならない。 情報源の収集と知見の統合に20分を要する研究エージェントは、ワーカープロセスが死亡した場合に最初から再起動していてはなりません。エージェントはすでにトークン費用を支払っており、ツール呼び出しも実行済みです。望まれるのは、最後の完了ステップからの再開であり、それ以前のすべての状態が保持されていることです。
エージェントは停止して待機する能力を持たなければならない。 取引の承認を人間に委ねて一時停止するエージェントは、人間の応答が30秒後に来るのか、それとも3日後に来るのかを知りません。その全期間にわたってワーカープロセスやクライアント接続を占有し続けることは現実的ではありません。エージェントは真に停止する必要があります:リソースを解放し、ワーカーをリリースした上で、後から中断した地点で正確に処理を再開します。
これらの両方の要件は、同じ概念によって解決されます:永続的実行(durable execution)。
- エージェントは自動チェックポイント機能を備えた管理されたタスクキュー上で実行されるため、中断した地点から再試行、再生、または再開が可能です。
- グラフ実行の各スーパーステップは、スレッドIDをキーとして永続化レイヤー(デフォルトでは PostgreSQL)にチェックポイントを書き出します。このスレッドIDは、実行に対する永続的なカーソルとして機能します。
- ワーカーがクラッシュした場合、実行のリースが解放され、別のワーカーが最新のチェックポイントから処理を引き継ぎます。
- エージェントが人間の入力を待機している場合、プロセスはスロットを手渡し、実行は再開されるまで無限にスリープ状態になります。
- 構成可能な再試行ポリシーにより、バックオフ間隔、最大試行回数、およびノードごとに再試行をトリガーする例外の種類を制御できます。

耐久性は、このリストの残りの部分が依存する基盤です。実行がプロセス境界を跨いで一時停止および再開できるため、エージェントは人間の入力を無限に待機したり、バックグラウンドで実行したり、実行中にデプロイを乗り越えたり、状態の破損なしで並行入力を処理したりすることができます。
メモリ
エージェントには2種類のメモリが必要であり、その区別が重要です。
短期記憶とは、エージェントが単一の会話の「内部」に蓄積する情報のことです。交換されたメッセージ、行われたツール呼び出し、実行全体で構築された中間状態などがこれに該当します。これはスレッドのチェックポイント内に保存され、thread_id にスコープが限定されており、会話が終わると(概念的に)消滅します。同じスレッドでの後続のメッセージは、そのスレッド上で以前に行われたすべての操作を認識します。
長期記憶とは、エージェントが会話の「間」に保持する情報のことです。これには、複数の会話を通じて学習されたユーザーの好み、プロジェクトの規約やベストプラクティス、あるいは新しいクエリごとに強化されるナレッジベースなどが含まれます。これらは単一のスレッドに属するものではなく、エージェントが行うすべての会話を通じて持続すべき、ユーザーレベルまたは組織レベルのコンテキストです。チェックポイントだけではこれを実現できません。なぜなら、チェックポイントの状態は単一のスレッドにスコープが限定されているからです。

長期記憶は、Agent Server に組み込まれた store の役割です。これは名前空間タプル(例えば (user_id, "memories")で記憶を整理し、スレッド間で永続化するキー値インターフェースです。エージェントは 1 つの会話でストアに書き込み、次の会話でそこから読み取ります。デフォルトでは PostgreSQL によってバックアップされており、埋め込み設定を通じて セマンティック検索 をサポートするため、エージェントは完全一致ではなく意味によって記憶を検索できます。また、異なるストレージ特性が必要な場合は、カスタムバックエンドに切り替える ことも可能です。名前空間の構造は柔軟で、ユーザー、アシスタント、組織、またはデータモデルに適合する任意の組み合わせでスコープを設定できます。
数ヶ月にわたって蓄積された記憶は、システムが生み出す最も貴重なデータのいくつかであるため、その保存場所が重要です。ストアは API を介して直接クエリ可能であり、セルフホストする場合、それは独自の PostgreSQL インスタンス内に存在します。このデータをあなたが制御する標準的なフォーマットで保持することが、モデル間の移行や分析、あるいはエージェント自体の外側での構築を可能にします。
マルチテナンシー
あなたのエージェントが複数のユーザーに対応する瞬間、シングルプレイヤーモードでは存在しなかった一連の問題が発生します。これらは3つの明確な懸念事項に分類され、エージェントサーバーはそれぞれ独自のプリミティブで処理します。
あるユーザーのデータを別のユーザーから隔離する。 ユーザーAの実行は、ユーザーAのスレッドのみを操作し、ユーザーAのメモリのみを読み取るべきです。カスタム認証は、すべてのリクエストでミドルウェアとして実行されます。@auth.authenticateハンドラーは、受信した資格情報を検証し、ユーザーのアイデンティティと権限を返します。これらは実行コンテキストに付加されます。@auth.on.threads、@auth.on.assistants.createなどに登録された認可ハンドラーは、リソース作成時に所有権メタデータをタグ付けし、読み取り時にフィルタ辞書を返すことで、誰が何を参照または変更できるかを強制します。ハンドラーは最も具体的なものから最も一般的なものの順にマッチングされるため、単一のグローバルハンドラーで始め、モデルの成長に伴ってリソース固有のハンドラーを追加していくことができます。
ユーザーに代わってエージェントが行動できるようにする。 エージェントは、ユーザーの資格情報を使用してサードパーティサービスにアクセスする必要があります。つまり、「彼ら」のカレンダーを読み取り、「彼ら」の Slack に投稿し、「彼ら」のリポジトリで PR を作成することです。Agent Auth は、このパターンにおける OAuth 処理とトークン保存を扱います。これにより、エージェントはリフレッシュフローを自分で管理することなく、実行時にユーザースコープの資格情報を取得できます。ユーザーは一度認証するだけでよく、エージェントはその後の実行においてユーザーに代わって行動できます。
システム自体を操作できるユーザーを制御する。 エンドユーザーのアクセスとは別に、「あなたの」チームのどのメンバーがエージェントのデプロイ、構成、トレースの表示、または認証ポリシーの変更を行えるかという問題があります。RBAC は、このオペレーターレベルのアクセス制御を扱います。
これら 3 つのレイヤーは組み合わさります。エンドユーザーはあなたの認証ハンドラーを介して認証し、エージェントは Agent Auth を介してサードパーティサービスに呼び出しを行い、あなたのチームは RBAC ポリシーの下でデプロイを操作します。

Human-in-the-loop (HITL)
エージェントはループを実行することで動作します:プロンプトが与えられると、モデルは推論を行いツールの呼び出しを決定し、その結果を観察して、タスクの完了と判断するまでこれを繰り返します。多くの場合、このループを中断することなく実行したいものです。ここに価値があります。しかし、時には重要な意思決定のポイントでループの中に人間を介入させる必要があります。
これが発生する一般的な状況は2つあります。
- 提案されたツール呼び出しのレビュー。エージェントが重要なアクション(メールの送信、金融取引の実行、ファイルの削除など)を実行する前に、人間がそれが何を行うのかを正確に把握し、どのように対応するかを決定できるようにする必要があります。メールのケースを考えてみましょう:エージェントはメッセージの下書きを作成し、送信する前に一時停止します。あなたはそのまま承認するか、送信前に件名や本文を編集するか、理由と具体的な修正リクエストを付けて却下し、エージェントが再検討して再度試みるようにすることができます。
- 明確化のための質問を投げかけるエージェント。場合によっては、エージェントがツール不足ではなく、正解が人間の判断や好みにかかっているため、自分自身で解決できない意思決定のポイントに達することがあります。推測するのではなく、エージェントは質問を直接提示できます。「そのパターンに一致する設定ファイルが3つ見つかりました。どれを修正すべきですか?」または「これはステージング環境にデプロイしますか、それとも本番環境にデプロイしますか?」あなたの回答がインターラプトの戻り値となり、エージェントは停止した場所からそのまま続行します。
エージェントサーバーは、2つのプリミティブ(基本構成要素)を用いてこれを処理します:interrupt() は実行を一時停止し、ペイロードを呼び出し元に提示します;Command(resume=...) は人間の応答を用いて実行を再開します。これらを組み合わせることで、承認ゲート、ドラフトレビューループ、入力検証、および実行途中に人間の意見が必要となるあらゆるワークフローを構築できます。

内部では、interrupt() はランタイムの チェックポインター をトリガーし、スレッド ID(persistent cursor として機能するキー)を指定してグラフの完全な状態を永続ストレージに書き込みます。その後、プロセスはリソースを解放し、無期限に待機します。特定のノードの前後で一時停止する静的なブレークポイントとは異なり、interrupt() は動的です。コード内の任意の場所に配置したり、条件分岐で囲んだり、ツール関数の内部に埋め込んだりすることで、承認ロジックをツールと一緒に移動させることができます。Command(resume=...) が到着したとき(数分後、数時間後、あるいは数日後)、resume の値が interrupt() 呼び出しの戻り値となり、実行は停止した場所から正確に再開されます。resume は任意の JSON シリアライズ可能な値を受け付けるため、その応答は承認/拒否に限定されません。レビューアーは編集されたドラフトを返すことができ、人間は欠落したコンテキストを提供でき、下流システムは計算結果を注入できます。並列ブランチがそれぞれ interrupt() を呼び出す場合、保留中のすべてのインターラプトが一括で表示され、単一の呼び出しで再開するか、応答が届くたびに一つずつ再開することができます。
リアルタイムインタラクション
Human-in-the-loop(人間をループに組み込んだ)相互作用モードとは、実行が一時停止し、人がレビューや入力を行える状態のことです。この介入は即時に行われることもあれば、かなり遅れて行われることもあります。また別に、「ライブセッション」における問題があります。これはエージェントがユーザーの存在下で積極的に作業を行っている際に発生するもので、進捗の可視化(ストリーミング)と並行メッセージの調整(ダブルテキスト送信)が含まれます。
ストリーミング
30秒かけて応答を生成するエージェントの場合、ユーザーはスピナーを見つめることになり、進捗があるのか、停止しているのか、それとも失敗しようとしているのかがわかりません。また、全体が完了するまで回答を読み始めることもできません。ストリーミングはこれら2つの問題を解決します。エージェントが出力を生成するたびに、部分的な出力がクライアントに流れるため、ユーザーは応答がリアルタイムで具現化するのを見ることができます。
Streaming APIは、希望する粒度に応じて複数のモードをサポートしています。これには、各グラフステップ後の完全な状態スナップショット、状態更新のみ、トークンごとのLLM(大規模言語モデル)出力、またはカスタムアプリケーションイベントが含まれます。これらを組み合わせることも可能です。ストリーミングの実行(client.runs.stream())は単一のラン(実行)にスコープが限定されます。一方、スレッドストリーミング(client.threads.joinStream())は、スレッド上のすべてのランからイベントを配信する長寿命のコネクションを開き、フォローアップメッセージ、バックグラウンドラン、またはHITL(Human-in-the-loop)の再開が同じスレッド上でアクティビトリガーを引き起こす場合に有用です。
スレッドストリーミングは、Last-Event-ID ヘッダーによる再開をサポートします。クライアントは受信した最後のイベントの ID を付けて再接続し、サーバーはその地点から隙間なく再生します。これがない場合、接続が切断されるたびに、クライアントは出力を見逃すか、最初からやり直す必要があります。
二重テキスト送信
2つ目のリアルタイムの問題:エージェントが前のメッセージの処理を完了する前に、ユーザーが新しいメッセージを送信することです。これはチャット UI で頻繁に発生します。ある人が質問を入力し、少し異なる意味だったことに気づき、最初の処理が完了する前に修正を送信します。これを double-texting と呼び、ランタイムはこれへの対応方針を決定する必要があります。
4つの戦略があり、適切な選択はアプリケーションによります。
- enqueue(デフォルト):新しい入力は現在の処理が終了するのを待ち、その後順次処理されます。
- reject:現在の処理が完了するまで、新しい入力を拒否します。
- interrupt:現在の処理を停止し、進捗状況を保持した状態で、その状態から新しい入力を処理します。2 番目のメッセージが 1 番目のメッセージを基にしている場合に有用です。
- rollback:現在の処理を停止し、元の入力を含むすべての進捗を元に戻した上で、新しいメッセージを新規処理として扱います。2 番目のメッセージが 1 番目のメッセージを置き換える場合に有用です。

interrupt は最もレスポンス性の高いチャット体験を提供しますが、グラフが部分的なツール呼び出しを適切に処理できる必要があります(interrupt 発生時に開始されたが完了していないツール呼び出しは、再開時にクリーンアップが必要になる場合があります)。enqueue は最も安全なデフォルト設定です——状態の破損は起こりませんが、その代わりユーザーが待たされることになります。
ガイドライン(ガードレール)
すべての運用上の懸念事項を「ループの耐久性のある実行」として表現できるわけではありません。中には、ループ自体の構造を決定するものもあります:モデル入力のインターセプト、ツール出力のフィルタリング、高コストな操作に対する制限の適用などです。これらのポリシーはプロンプトではなくコードに記述する必要があります。モデルがたまたまそれらを記憶しているときだけでなく、毎回確実に実行される必要があります。
これを実際に具体化するケースが 2 つあります。
- モデルがデータを確認する前に機密データをマスクすること。カスタマーサポートエージェントは、氏名やメールアドレス、アカウント番号などの個人識別情報(PII)を含むユーザーメッセージを処理します。モデルがこれらを確認したり、トレースに記録されたりすることを避けたい場合、またコンプライアンス上ログ出力前にマスク処理が必須となる場合があります。これは、すべてのモデル呼び出しの前に確定的に実行されなければなりません。
- 高コストな操作の上限設定。有料の外部 API を呼び出すことができるエージェントには、1回の実行で何回呼び出しを行うかという厳格な上限が必要です。混乱したモデルは、そうしないと50回も呼び出してしまい、昼食前にお金をすべて使い果たしてしまう可能性があるからです。
これらはどちらも ミドルウェア によって処理されます。ミドルウェアは、before_model(モデル呼び出し前)、wrap_model_call(モデル呼び出しのラップ)、wrap_tool_call(ツール呼び出しのラップ)、after_model(モデル呼び出し後)といった定義済みのフックでエージェントループをラップし、関連するすべてのステップの周りでポリシーが確定的に実行されるようにします。

LangChain には、一般的なケースをカバーする 組み込みミドルウェア が同梱されています。具体的には、PIIRedactionMiddleware(PII 削除ミドルウェア)、ModelRetryMiddleware(モデル再試行ミドルウェア)、ModelFallbackMiddleware(モデルフォールバックミドルウェア)、ToolCallLimitMiddleware(ツール呼び出し制限ミドルウェア)、SummarizationMiddleware(要約ミドルウェア)、HumanInTheLoopMiddleware(ヒューマンインザループミドルウェア)、OpenAIModerationMiddleware(OpenAI 審査ミドルウェア)などです。また、アプリケーション固有のポリシーに対応する カスタムミドルウェア を作成することも可能です。
ミドルウェアはオープンソースですが、それが真価を発揮するのはエージェントランタイムの「内部」で実行された場合です。そうなることで、同じポリシーがランタイムがサポートするすべてのインタラクションモード(ストリーミング、ヒューマンインザループの一時停止/再開、リトライ、バックグラウンド実行、長期スレッド)の一部となります。実務的には、これはガードレールやインストルメンテーションが「最善を尽くす」ものではないことを意味します。エージェントが何をしているかに関わらず、期待する正確なポイントで、すべてのモデル呼び出しとツール呼び出しに一貫してラップします。
観測可能性(Observability)
エージェントが本番環境で何をするかは、実際に実行してみない限りわかりません。 コードから振る舞いを推論できる従来のアプリケーションとは異なり、エージェントの実行パスはランタイムにおけるモデルの選択に依存します。具体的には、どのツールを呼び出すか、何を引き渡すか、結果をどう解釈するか、そしていつあきらめて別の試みを行うかです。何か問題が発生した場合、単に関数を再読するだけでは不十分です。実際に何が起こったかを確認する必要があります。
サポートチケットに「エージェントが同じ質問を繰り返していた」という報告があります。トレース(実行履歴)がない場合、ユーザーの説明から推測するしかありませんが、トレースがあれば、完全な実行ツリーを確認できます。これには、ユーザーのメッセージ、モデルが計画した応答、呼び出されたツール、取得した結果、生成された次のメッセージ、そして陥ったループが含まれます。コストでフィルタリングしてトークンを大量に消費した実行を見つけたり、エラーでフィルタリングして失敗した実行を特定したり、ユーザーでフィルタリングして特定の顧客の体験を確認したりできます。個々のトレースでは発見できないパターンを、数千の実行にわたって特定することが可能です。
すべての LangSmith デプロイメントは トレースプロジェクトに自動的に接続されています。モデル呼び出し、ツール呼び出し、サブエージェントの実行、ミドルウェアフックなど、箱から出してすぐに使える完全な実行ツリーが提供され、ユーザー、時間枠、コスト、レイテンシ、エラー状態、フィードバック、またはカスタムタグでクエリ可能な構造化メタデータが含まれています。
トレースは改善ループの基盤です:
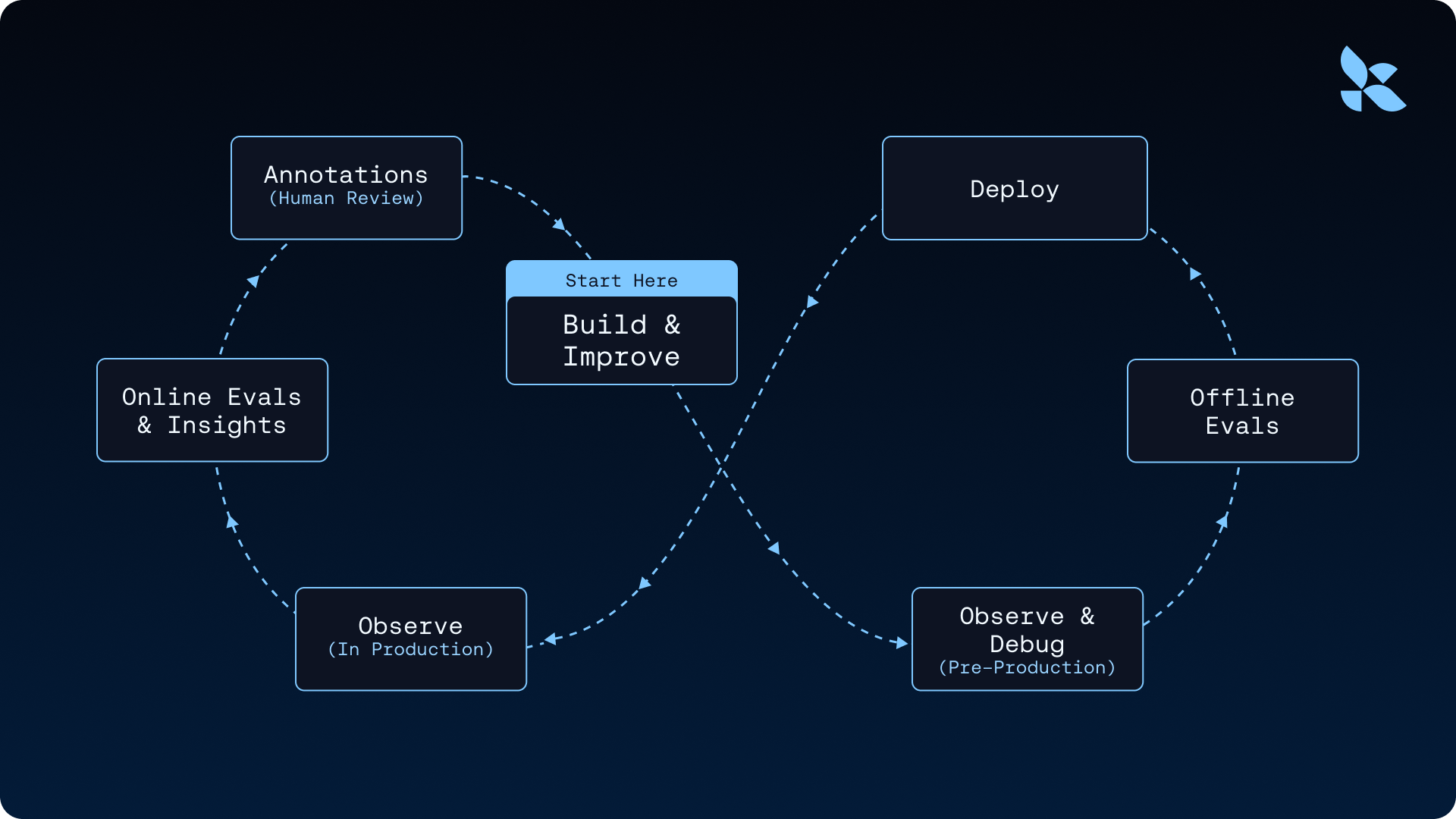
Polly、LangSmith の AI アシスタントはトレースを分析し、一般的な失敗モード、低速なツール呼び出し、繰り返されるパターンなどの洞察を可視化します。これにより、何千件ものトレースを手動で読み込む必要がなくなります。Online Evals は、本番環境のトレースに対して LLM-as-judge やカスタムスコアラーを自動的に実行するため、回帰エラーが発生した瞬間に検出できます。私たちはこのループを使用して、ハース(harness)の変更のみで Terminal Bench 2.0 において Deep Agents のスコアを 13.7 ポイント向上 させました。これは、トレースからエージェント改善ループが始まる理由 の全体像を理解する価値があることを示すものです。
時間旅行
観測可能性(Observability)は「何が起きたか」を教えてくれます。時間旅行機能は、「もし何かが異なっていたら、何が起きていたか」という問いに答えることを可能にします。
この機能の動機となるケースは、暴走した実行(run)のデバッグです。20 ステップからなる実行のステップ 5 で、エージェントが誤った判断を下しました:間違ったツールを呼び出した、ツールの結果を読み間違えた、あるいは進むべきところであえて確認質問を行ったなどです。なぜそうなったのかを理解したい場合、かつ、最初から全体を再実行することなく代替案を試したい場合に、この機能は役立ちます。より一般的に言えば、エージェントのパスが特定のチェックポイントにおける状態に依存するあらゆる場面で、そのチェックポイントまで巻き戻し、状態を変更して、残りの実行が異なる展開をする能力が必要となります。
各スーパーステップがチェックポイントcheckpointを出力するため、実行履歴の各時点にはすでに戻ることのできるスナップショットが存在します。タイムトラベルはこの機能を明確にします:スレッドの履歴からチェックポイントを選択し、その状態を任意に変更した上で、そこから再開します。変更されたチェックポイントはスレッドの履歴をフォーク(分岐)させます。元の履歴はそのまま維持され、新しい経路が独自のブランチとして前方へ進みます。LLM呼び出し、ツール呼び出し、およびインターラプトは再生時にすべて再トリガーされるため、フォークされた経路ではスタブではなく実際のエージェントループが実行されます。

これにより、それ以外では構築が困難なパターンが可能になります。例えば、ツールBを選ぶべき場面でなぜエージェントがツールAを選んだのかをデバッグする、同じ上位コンテキストに対して2つのプロンプトを比較する、最後の良好な状態へ巻き戻して逸脱した実行から回復する、あるいは多くのフォークにわたって反実仮想(counterfactuals)を検証してモデルの挙動を理解する、といったケースです。LangSmithのStudio UIはこれらすべてに視覚的なインターフェースを提供しますが、実際の生産環境でのデバッグワークフローで最もよく使用されるのはAPIです。
コード実行
あなたが事前に接続したツールしか呼び出せないエージェントは、あなたの予測の範囲内に限定されます。一方、任意のコードを実行できるエージェントは汎用的であり、依存関係のインストール、リポジトリのクローン作成、テストの実行、データ分析の実行、ドキュメントの生成、プロットのレンダリングなどを行うことができます。これが「関数呼び出し付きチャットボット」と「実際に作業を行えるエージェント」の間の差です。
任意のコードの実行には分離(アイソレーション)が必要です。もしエージェントがホスト上で rm -rf / を実行したら、大変なことになります。環境変数を読み取られたら、API キーが漏洩してしまいます。エージェントの実行環境とあなたが気にするすべてのものの間に境界が必要であり、エージェントが最初のコマンドを書く前にその境界を設ける必要があります。
Deep Agents では、分離は サンドボックスバックエンド を通じて行われます。SandboxBackendProtocol を実装するバックエンドを構成すると、エージェントは標準のファイルシステムツールに加えて、サンドボックス内でシェルコマンドを実行するための execute ツールを自動的に取得します。サンドボックスバックエンドがない場合、エージェントには execute ツールが表示されません。サポートされているプロバイダー には Daytona、Modal、Runloop、LangSmith Sandboxes が含まれ、単一の構成変更でそれらの間で切り替えることができます。
LangSmith Sandboxes(現在プライベートプレビュー中)は、ランタイムの他のコンポーネントと統合されるように設計されているため、特に注目する価値があります。Templates は、コンテナイメージ、リソース制限、ボリュームを宣言的に定義します。Warm pools は自動補充機能付きでサンドボックスを事前にプロビジョニングし、インタラクティブエージェントのコールドスタートレイテンシを排除します。そして auth proxy は、すべてのチームが最終的に直面する問題を解決します。エージェントは認証済み API を呼び出す必要がありますが、サンドボックス内に資格情報を配置することはセキュリティリスクとなります。このプロキシはサイドカーとして実行され、送信されるリクエストをインターセプトし、ワークスペースのシークレットから資格情報を自動的に注入します。サンドボックス内のコードは api.openai.com にヘッダーなしで呼び出しを行い、プロキシが送信時に適切な Authorization ヘッダーを追加します。シークレットはサンドボックス内に渡されることなく、エージェントが見えないものを漏洩させることはできません。

繰り返す価値のあるセキュリティガイドラインの重要なポイント:サンドボックスはホストを保護しますが、サンドボックス自体を保護するわけではありません。スクレイピングされたウェブページのプロンプトインジェクション、悪意のあるメール、または汚染されたツールの結果を通じてエージェントの入力を制御できる攻撃者は、サンドボックス内でコマンドを実行するようエージェントに指示できます。サンドボックスは攻撃者をあなたのマシンから遠ざけますが、サンドボックス内のもの(そこに直接配置された資格情報を含む)はすべて侵害されます。この理由のために、認証プロキシパターンが存在します。
統合
エージェントは、人々や組織がすでに使用しているシステムに接続されたときに最も有用です。コーディングエージェントは、GitHub、Linear、およびCIシステムにアクセスできる場合、より強力になります。研究エージェントは、その出力があなたの出版パイプラインにフィードされる場合、より有用になります。内部エージェントは、他のエージェントがビルディングブロックとしてそれを呼び出せる場合、プラットフォームとなります。それらの統合のすべてが手作業で作成されたアダプターである場合、エージェントは孤立したままになります。「エージェント」と「その他のすべて」の間の境界が壁となります。
オープンプロトコルは、双方が相手の実装を知らなくても、エージェントと外部システムがお互いを発見し通信できるようにすることで、この問題を解決します。Agent Serverは、3つの統合サーフェスを自動的にプロビジョニングします。
MCP
MCP (Model Context Protocol) は、エージェントをツールやデータソースに接続するためのオープンスタンダードです。すべての LangSmith デプロイメントは 自動的に MCP エンドポイントを公開 しており、アダプターコードを記述することなく、Claude Desktop、IDE、他のエージェント、カスタムアプリケーションなど、MCP 準拠のクライアントからあなたのエージェントを検出可能にします。逆方向にも、あなたのエージェントは Linear、GitHub、Notion など数百の MCP サーバーを呼び出すことで、ユーザーがすでに利用しているツールやデータにアクセスできます。
A2A
A2A (Agent-to-Agent) は、エージェント間通信のための同等のスタンダードであり、すべてのデプロイメントは 自動的に A2A エンドポイントも公開 しています。これにより、デプロイメントを跨ぐマルチエージェントアーキテクチャが扱いやすくなります。オーケストレーターエージェントは、双方が理解するプロトコルを使用して、別のデプロイメント内のワーカーエージェントを検出し呼び出すことができ、手動で記述した HTTP 契約は不要です。
Webhooks
Webhooks はアウトバウンド(外部送信)のケースを処理します:エージェントの実行が完了し、ポーリングを行わずに次の工程を起動したい場合です。実行を作成する際にWebhook URLを渡すと、サーバーは完了時にそのURLに対してPOSTリクエストで実行ペイロードを送信します。これにより、エージェントの実行を既存のワークフローにチェーンできます。例えば、リサーチ実行が完了して公開パイプラインをトリガーしたり、日次サマリーが完了してSlackに通知を送ったり、コンプライアンスチェックが完了して監査ログに書き込んだりします。ヘッダー、ドメインのホワイトリスト、HTTPS強制などは、本番環境向けに構成可能です。
Cron
これまで話してきたエージェントは受動的(リアクティブ)です:ユーザーがメッセージを送信し、エージェントが応答します。しかし、多くの価値あるエージェントの作業は能動的(プロアクティブ)です——それは人間のトリガーなしにスケジュールに基づいて発生します。
特に以下の2つのパターンがあります:
- 待機時間中の計算処理。アイドル時間帯に有用な作業を行うエージェントにより、ユーザーはオンデマンドのレイテンシではなく、蓄積された思考の結果から恩恵を受けます。あなたの専門分野における最新の論文を追跡するために夜間に実行される研究エージェント、一日の開始前に翌日のカレンダーを確認しブリーフィングノートを作成する準備用エージェント、一晩中蓄積されたサポートチケットを分類しチームが優先順位付けられたキューから作業を開始できるようにするトリアージエージェント。これらの処理は誰も待機していない間に実行され、ユーザーがアクセスした時点で出力結果が準備完了しています。
- 健康状態と監視ループ。定期的に何らかの状態を確認し、問題が発見された場合に行動(またはエスカレーション)を行うエージェント。15 分ごとにアラートを確認するオンコールエージェント、ステージング環境での回帰テストを監視するエージェント、定期的にポリシー違反を検出するコンプライアンスエージェント。これらはユーザーFacing の実行と同様の耐久性、トレーシング(追跡)、認証(auth)を必要としますが、ユーザーが待機しているわけではありません。
Agent Server には cron ジョブ が組み込まれているため、スケジュールされた実行は他のあらゆる実行と同様の耐久性、トレーシング、認証の保証を受けられます。維持管理用の別個のスケジューラーは不要であり、別の観測可能性(observability)の仕組みを接続する必要もありません。標準的な cron 式(UTC 基準)と入力データを渡すだけで、サーバーはスケジュールに従って実行をトリガーします。
2 つのバリエーションが異なるパターンに対応しています。
- Stateful cron (client.crons.create_for_thread) はスケジュールを特定の thread_id に紐付けるため、トリガーされた実行ごとに同じ会話に追記されます。これは過去の発見を基に構築する毎日のリサーチエージェントや、既にフラグを立てた事項を記憶するモニタリングエージェントなど、自身の履歴を参照すべきエージェントに適しています。
- Stateless cron (client.crons.create) は、各実行ごとに新しいスレッドを起動するため、実行間で継続性が不要なバッチ処理スタイルの作業に適しています。on_run_completed 経由でスレッドのクリーンアップを制御できます:"delete"(デフォルト)は実行完了時にスレッドを削除し、"keep" は後で client.runs.search(metadata={"cron_id": cron_id}) を介して取得できるようスレッドを保持します。

すべての cron 実行はトレーシングに表示され、認証ハンドラーとミドルウェアを尊重し、失敗時の再開もサポートします。3時に一時的なモデル障害が発生した cron が静かに失敗することはありません。他の実行と同様にリトライされます。運用上の注意点として:不要になった cron は削除してください。削除するまで、実行(および課金)は継続されます。
エンタープライズチームには多様なデプロイ要件があるため、ランタイムはクラウド、ハイブリッド、およびセルフホストのデプロイに対応しています。どこで実行するかに関わらず、機能は同じです。
deepagents deploy
deepagents deployは、上記のランタイム上にエージェントをデプロイするためのパッケージングステップです。deepagents.toml内でエージェントを定義し、CLIが設定をバンドルして、前述の全機能を持つLangSmith Deploymentとしてデプロイします。

メモリ(Memory)は、プラグイン可能なバックエンドを持つ仮想ファイルシステムを使用し、エージェントに一時的なスクラッチ領域と永続的な会話間ストレージの両方を提供します。Deep Agentsは、ユーザーまたはアシスタント(あるいはその両方)にスコープを限定したメモリをサポートしています!
サンドボックスプロバイダー(LangSmith Sandboxes、Daytona、Modal、Runloop、またはカスタム)は単一の設定値です。サンドボックスが存在する場合、ハレス(harness)は自動的に実行ツールを追加します。サンドボックスのライフサイクル(スレッドスコープかアシスタントスコークかの違い)は、グラフファクトリーを通じて処理されます。サンドボックス内の資格情報は、サンドボックスの認証(sandbox auth)を通じて管理されます。
原文を表示
Key Takeaways
- A good harness gives your agent the right prompts, tools, and skills. But deploying long-running agents in production requires durable execution, memory, multi-tenancy, human-in-the-loop, and observability. This infrastructure lives underneath the harness and keeps the agent running reliably across crashes, deploys, and long-running tasks.
- Durable execution is the foundation everything else depends on. Agents that run for minutes or hours, pause for human approval, or survive mid-run deploys all need checkpointed execution that can stop, resume, and retry across process boundaries. Streaming, human-in-the-loop, cron jobs, and concurrent message handling all build on top of it.
- Production agents need open and model-agnostic infrastructure. Deep Agents is MIT licensed, agents are exposed via open protocols (MCP, A2A), and memory lives in your own PostgreSQL. Teams keep full visibility into how their agent works and the ability to change it without a rewrite.
Deploying long horizon agents in production requires purpose-built infrastructure. This guide covers durable execution, memory, HITL, observability, and how deepagents deploy ships it all to production.
To build a good agent, you need a good harness. To deploy that agent, you need a good runtime.
The harness is the system you build around the model to help your agent be successful in its domain. That includes prompts, tools, skills, and anything else supporting the model and tool calling loop that defines an agent. The runtime is everything underneath: durable execution, memory, multi-tenancy, observability, the machinery that keeps an agent running in production without your team reinventing it.
This guide walks through the production requirements that surface once you deploy agents, the runtime capabilities that meet them, and how deepagents deploy packages those capabilities into something you can ship.
Runtime capabilities for production agents
Throughout this section, "the runtime" refers to LangSmith Deployment (LSD) and its Agent Server: LSD runs agents in production, and Agent Server is the interface for assistants, threads, runs, memory, and scheduled jobs. The table below maps each production requirement to the runtime primitive that meets it.
Production requirement
Runtime capability
Reliability
Durable execution
Memory
Checkpoints (short-term), store (long-term)
Guardrails
Middleware
Multi-tenancy
Authentication, authorization, Agent Auth, RBAC
Human oversight
Human-in-the-loop (interrupt/resume)
Real-time interaction
Streaming, concurrency control (double-texting)
Observability
Tracing, time travel
Code execution
Sandboxes
Integrations
MCP, A2A, webhooks
Scheduled jobs
Cron
Durable execution
Agents work by running a loop: Given a prompt, the model reasons, calls tools, observes the results, and repeats until it decides the task is complete.
Unlike a typical web request that returns in milliseconds, this loop can span minutes or hours. A single run might make dozens of model calls, spawn subagents, or wait indefinitely for a human to approve a draft. A crash, deploy, or transient failure anywhere in that loop shouldn't erase the work leading up to it.
In practice, you feel it in two places:
Long runs need to survive infrastructure failures. A research agent spending twenty minutes gathering sources and synthesizing findings can't afford to restart from scratch if the worker process dies: the agent already paid for the tokens and executed the tool calls. What you want is resumption from the last completed step, with all prior state intact.
Agents need to be able to stop and wait. An agent that pauses for a human to approve a transaction doesn't know if the human will respond in thirty seconds or three days. Tying up a worker process or a client connection for that entire window isn't viable. The agent needs to truly stop: free resources, release workers, then pick up later exactly where it left off.
Both requirements are solved by the same thing: durable execution.
- Agents run on a managed task queue with automatic checkpointing, so any run can be retried, replayed, or resumed from the exact point of interruption.
- Each super-step of graph execution writes a checkpoint to the persistence layer (PostgreSQL by default), keyed by a thread_id that acts as a persistent cursor into the run.
- When a worker crashes, the run's lease is released and another worker picks it up from the latest checkpoint.
- When an agent waits for human input, the process hands off its slot and the run sleeps indefinitely until resumed.
- Configurable retry policies control backoff, max attempts, and which exceptions trigger retries on a per-node basis.
Durability is the foundation the rest of this list depends on. Because execution can pause and resume across process boundaries, agents can wait indefinitely for human input, run in the background, survive deploys mid-run, and handle concurrent inputs without corrupting state.
Memory
Agents need two different kinds of memory, and the distinction matters.
Short-term memory is what the agent accumulates *within* a single conversation. The messages exchanged, the tool calls made, the intermediate state built up across a run. This lives in the checkpoint for the thread, scoped to a thread_id, and disappears (conceptually) when the conversation ends. A follow-up message on the same thread sees everything that came before on that thread.
Long-term memory is what the agent carries *across* conversations. This can include user preferences learned across conversations, project conventions and best practices, or a knowledge base enhanced with each new query. None of this belongs to any single thread. It's user-level or organization-level context that should persist across every conversation the agent has. Checkpoints alone can't do this, because checkpoint state is scoped to a single thread.
Long-term memory is what the Agent Server's built-in store is for. It's a key-value interface where memories are organized by namespace tuples (for example, (user_id, "memories")) and persisted across threads. Your agent writes to the store in one conversation and reads from it in the next. Backed by PostgreSQL by default, it supports semantic search via embedding configuration so agents can retrieve memories by meaning rather than exact match, and you can swap in a custom backend if you need different storage characteristics. The namespace structure is flexible: scope by user, assistant, organization, or any combination that fits your data model.
Because memory that accumulates over months is some of the most valuable data the system produces, it matters where it lives. The store is queryable directly via API, and if you self-host, it lives in your own PostgreSQL instance. Keeping this data in a standard format you control is what lets you migrate between models, analyze it, or build on top of it outside the agent itself.
Multi-tenancy
The moment your agent serves more than one user, a set of problems appears that didn't exist in single-player mode. These break down into three distinct concerns, and the Agent Server handles each with its own primitive.
Isolating one user's data from another. User A's run should only touch User A's threads, and only read User A's memories. Custom authentication runs as middleware on every request: your @auth.authenticate handler validates the incoming credential and returns the user's identity and permissions, which get attached to the run context. Authorization handlers registered with @auth.on.threads, @auth.on.assistants.create, and so on then enforce who can see or modify what by tagging resources with ownership metadata on creation and returning filter dictionaries on reads. Handlers are matched from most specific to least, so you can start with a single global handler and add resource-specific ones as your model grows.
Letting the agent act on behalf of a user. Agents often need to call third-party services using the user's credentials—reading *their* calendar, posting to *their* Slack, opening a PR in *their* repo. Agent Auth handles the OAuth dance and token storage for this pattern, so the agent gets user-scoped credentials at runtime without you managing the refresh flow yourself. The user authenticates once; the agent can act on their behalf across subsequent runs.
Controlling who can operate the system itself. Separate from end-user access, there's the question of which members of *your* team can deploy agents, configure them, view traces, or change auth policies. RBAC handles this operator-level access control.
The three layers compose: end users authenticate via your auth handler, the agent calls third-party services via Agent Auth, and your team operates the deployment under RBAC policies.
Human-in-the-loop (HITL)
Agents work by running a loop: given a prompt, a model reasons and decides to call tools, observes the results, and repeats until it decides it has completed the task at hand. Most of the time you want that loop to run uninterrupted. That’s where the value comes from. But sometimes you need a human in the middle of the loop at key decision points.
There are two common situations where this comes up:
- Reviewing a proposed tool call. Before the agent executes a consequential action (sending an email, executing a financial transaction, deleting files), you want a human to see exactly what it's about to do and decide how to respond. Take the email case: the agent drafts a message and pauses before sending. You can approve it as-is, edit the subject or body before it goes out, or reject it with a reason and specific edit requests so the agent can revise and try again.
- An agent asking a clarifying question. Sometimes an agent reaches a decision point it can't resolve on its own, not because it lacks a tool but because the right answer depends on human judgment or preference. Rather than guessing, the agent can surface the question directly: "I found three config files matching that pattern. Which one should I modify?" or "Should this deploy to staging or production?" Your answer becomes the return value of the interrupt, and the agent continues from exactly where it stopped.
The Agent Server handles this with two primitives: interrupt() pauses execution and surfaces a payload to the caller; Command(resume=...) continues it with the human's response. Together they let you build approval gates, draft review loops, input validation, and any workflow where a human needs to weigh in mid-execution.
Under the hood, interrupt() triggers the runtime's checkpointer to write the full graph state to durable storage, keyed by a thread_id that acts as a persistent cursor. The process then frees resources and waits indefinitely. Unlike static breakpoints that pause before or after specific nodes, interrupt() is dynamic: place it anywhere in your code, wrap it in conditionals, or embed it inside a tool function so approval logic travels with the tool. When Command(resume=...) arrives—minutes, hours, or days later—the resume value becomes the return value of the interrupt() call, and execution picks up exactly where it stopped. Because resume accepts any JSON-serializable value, the response isn't limited to approve/reject: a reviewer can return an edited draft, a human can supply missing context, a downstream system can inject computed results. When parallel branches each call interrupt(), all pending interrupts are surfaced together and can be resumed in a single invocation, or one at a time as responses come back.
Real-time interaction
Human-in-the-loop is an interaction mode where execution can pause for a person to review or provide input—sometimes immediately, sometimes much later. Separately, there are “live session” problems that show up when the agent is actively working while the user is present: making progress visible (streaming) and coordinating concurrent messages (double-texting).
Streaming
An agent that takes thirty seconds to produce a response leaves the user staring at a spinner with no signal about whether it's making progress, stuck, or about to fail. They also can't start reading the answer until the whole thing is done. Streaming solves both: partial output flows to the client as the agent produces it, so the user sees the response materialize in real time.
The Streaming API supports several modes depending on what granularity you want: full state snapshots after each graph step, state updates only, token-by-token LLM output, or custom application events. You can also combine them. Run streaming (client.runs.stream()) is scoped to a single run; thread streaming (client.threads.joinStream()) opens a long-lived connection that delivers events from every run on a thread, useful when follow-up messages, background runs, or HITL resumptions all trigger activity on the same thread.
Thread streaming supports resumption via the Last-Event-ID header: the client reconnects with the ID of the last event it received, and the server replays from there with no gaps. Without this, every dropped connection means the client either misses output or has to start over.
Double-texting
The second real-time problem: a user sends a new message while the agent is still working on the previous one. This happens constantly in chat UIs. Someone types a question, realizes they meant something slightly different, and fires off a correction before the first run finishes. We call this double-texting, and the runtime has to take a position on how to handle it.
There are four strategies, and the right one depends on your application:
- enqueue (the default): The new input waits for the current run to finish, then processes sequentially.
- reject: Refuse any new input until the current run finishes.
- interrupt: Halt the current run, preserve progress, and process the new input from that state. Useful when the second message builds on the first.
- rollback: Halt the current run, revert all progress including the original input, and process the new message as a fresh run. Useful when the second message replaces the first.
interrupt gives the snappiest chat feel but requires your graph to handle partial tool calls cleanly (a tool call initiated but not completed when the interrupt hits may need cleanup on resume). enqueue is the safest default—no state corruption, at the cost of making the user wait.
Guardrails
Not every production concern can be expressed as "run the loop durably." Some have to shape the loop itself: intercepting model inputs, filtering tool outputs, enforcing limits on expensive operations. These policies belong in code, not in a prompt. They need to run every time, not whenever the model happens to remember them.
Two cases make this concrete:
- Redacting sensitive data before the model sees it. A customer support agent processes user messages containing PII (names, emails, account numbers). You don't want the model to see them, you don't want them in traces, and compliance likely requires redaction before logging. This has to happen before every model call, deterministically.
- Capping expensive operations. An agent that can call a paid external API needs a hard ceiling on how many calls it makes per run, because a confused model will otherwise happily call it fifty times and burn through your budget before lunch.
Both are handled by middleware, which wraps the agent loop at defined hooks—before_model, wrap_model_call, wrap_tool_call, after_model—so policies execute deterministically around every relevant step.
LangChain ships built-in middleware covering the common cases: PIIRedactionMiddleware, ModelRetryMiddleware, ModelFallbackMiddleware, ToolCallLimitMiddleware, SummarizationMiddleware, HumanInTheLoopMiddleware, OpenAIModerationMiddleware, and you can write custom middleware for application-specific policies.
Middleware is open source, but it only really pays off when it runs *inside* the agent runtime. When it does, those same policies become part of every interaction mode the runtime supports—streaming, human-in-the-loop pauses/resumes, retries, background runs, and long-lived threads. In practice, that means your guardrails and instrumentation aren’t “best effort”: they consistently wrap every model call and every tool call, at the exact points you expect, no matter what the agent is doing.
Observability
You don't know what an agent will do in production until you run it. Unlike a traditional application where you can reason about behavior from the code, an agent's execution path depends on the model's choices at runtime: which tools to call, what to pass them, how to interpret the results, and when to give up and try something else. When something goes wrong, you can't just re-read the function. You need to see what actually happened.
A support ticket says "the agent kept asking the same question over and over." Without traces, you're guessing from the user's description. With traces, you see the full execution tree: the user's message, the model's planned response, the tool it called, the result it got back, the next message it generated, the loop it fell into. You can filter by cost to find runs that burned through tokens, by error to find runs that failed, by user to see what a specific customer experienced. You can spot patterns across thousands of runs that no individual trace would reveal.
Every LangSmith Deployment is automatically wired to a tracing project. You get the full execution tree out of the box—model calls, tool calls, subagent runs, middleware hooks—with structured metadata you can query by user, time window, cost, latency, error state, feedback, or custom tags.
Traces are the foundation of the improvement loop:
Polly, the LangSmith AI assistant, analyzes traces and surfaces insights—common failure modes, slow tool calls, repeated patterns—so you're not reading thousands by hand. Online Evals run LLM-as-judge or custom scorers against production traces automatically, so regressions get caught as they happen. We used this loop to improve Deep Agents by 13.7 points on Terminal Bench 2.0 by only changing the harness—the whole argument for why the agent improvement loop starts with a trace is worth reading in full.
Time travel
Observability tells you what happened. Time travel lets you ask *what would have happened* if something had gone differently.
The motivating case is debugging a run that went off the rails. Your agent made a bad decision at step 5 of a 20-step run: it called the wrong tool, misread a tool result, or asked a clarifying question when it should have kept going. You want to understand why, and you want to try alternatives without re-running the whole thing from scratch. More generally, any time an agent's path depends on state at a particular checkpoint, you want the ability to rewind to that checkpoint, change the state, and let the rest of the run unfold differently.
Because every super-step writes a checkpoint, every point in a run's history is already a snapshot you can return to. Time travel makes this explicit: pick a checkpoint from a thread's history, optionally modify its state, and resume from there. The modified checkpoint forks the thread's history. The original stays intact, and the new path runs forward as its own branch. LLM calls, tool calls, and interrupts all re-trigger on replay, so forks exercise the real agent loop rather than a stub of it.
This unlocks patterns that are hard to build otherwise: debugging why the agent chose tool A when it should have chosen tool B, comparing two prompts against the same upstream context, recovering from a run that went sideways by rewinding to the last good state, or exploring counterfactuals across many forks to understand model behavior. The LangSmith Studio UI gives you a visual interface for all of this; the API is what most production debugging workflows end up using.
Code execution
An agent that can only call the tools you pre-wired is limited to what you anticipated. An agent that can run arbitrary code is general-purpose: it can install dependencies, clone repos, execute tests, run data analysis, generate documents, and render plots. This is the gap between "chatbot with function calling" and "agent that can actually do things."
Arbitrary code execution requires isolation. If the agent runs rm -rf / on your host, you have a bad day. If it reads your environment variables, it exfiltrates your API keys. You need a boundary between the agent's execution environment and everything you care about, and you need it before the agent writes its first command.
In Deep Agents, isolation happens through sandbox backends. When you configure a backend that implements SandboxBackendProtocol, the agent automatically gets an execute tool for running shell commands in the sandbox alongside the standard filesystem tools. Without a sandbox backend, the execute tool isn't even visible to the agent. Supported providers include Daytona, Modal, Runloop, and LangSmith Sandboxes, and you can swap between them with a single configuration change.
LangSmith Sandboxes (currently in private preview) are worth a specific callout because they're built to integrate with the rest of the runtime. Templates define container images, resource limits, and volumes declaratively. Warm pools pre-provision sandboxes with automatic replenishment, eliminating cold start latency for interactive agents. And the auth proxy solves a problem every team hits eventually: the agent needs to call authenticated APIs, but putting credentials inside the sandbox is a security risk. The proxy runs as a sidecar, intercepts outbound requests, and injects credentials from workspace secrets automatically—the sandbox code calls api.openai.com with no headers, and the proxy adds the right Authorization header on the way out. Secrets never enter the sandbox, and the agent can't exfiltrate what it can't see.
One piece of security guidance worth repeating: sandboxes protect your host, not the sandbox itself. An attacker who controls the agent's input (via prompt injection in a scraped webpage, a malicious email, a poisoned tool result) can instruct the agent to run commands inside the sandbox. The sandbox keeps the attacker off your machine, but anything *inside* the sandbox—including credentials placed there directly—is compromised. The auth proxy pattern exists for exactly this reason.
Integrations
Agents are most useful when they plug into the systems people and organizations already use. A coding agent becomes more powerful when it can reach into GitHub, Linear, and your CI system. A research agent becomes more useful when its output feeds into your publishing pipeline. An internal agent becomes a platform when other agents can call it as a building block. If every one of those integrations is a hand-rolled adapter, your agents stay isolated. The boundary between "agent" and "everything else" becomes a wall.
Open protocols solve this by letting agents and external systems discover and talk to each other without either side knowing the other's implementation. The Agent Server provisions three integration surfaces automatically.
MCP
MCP (Model Context Protocol) is the open standard for connecting agents to tools and data sources. Every LangSmith Deployment automatically exposes an MCP endpoint, making your agent discoverable by any MCP-compliant client—Claude Desktop, IDEs, other agents, custom applications—without you writing adapter code. In the other direction, your agent can call out to any MCP server (Linear, GitHub, Notion, and hundreds of others) to reach tools and data your users already have.
A2A
A2A (Agent-to-Agent) is the analogous standard for agent-to-agent communication, and every deployment exposes an A2A endpoint automatically as well. This is what makes multi-agent architectures across deployments tractable: an orchestrator agent in one deployment can discover and call worker agents in another using a protocol both sides understand, with no hand-rolled HTTP contracts.
Webhooks
Webhooks handle the outbound case: your agent finishes a run, and you want to kick off something downstream without polling. Pass a webhook URL when creating a run, and the server POSTs the run payload to that URL on completion. This is how you chain agent runs into existing workflows—a research run completes and triggers a publishing pipeline, a daily summary finishes and notifies Slack, a compliance check completes and writes to your audit log. Headers, domain allowlists, and HTTPS enforcement are all configurable for production environments.
Cron
The agents we've been talking about so far are reactive: a user sends a message, the agent responds. But a lot of valuable agent work is proactive—it happens on a schedule, with no human triggering it.
Two patterns in particular:
- Sleep-time compute. Agents that do useful work during idle periods, so users benefit from accumulated thinking rather than on-demand latency. A research agent that runs nightly to catch up on new papers in your field. A prep agent that reviews tomorrow's calendar and drafts briefing notes before you start your day. A triage agent that classifies overnight support tickets so your team walks into a prioritized queue. The work happens while nobody's waiting, and the output is ready when the user shows up.
- Health and monitoring loops. Agents that periodically check on something and act (or escalate) if they find an issue. An on-call agent that reviews alerts every fifteen minutes, an agent that monitors your staging environment for regressions, a compliance agent that sweeps for policy violations on a cadence. These need the same durability, tracing, and auth as user-facing runs, but no user is waiting on them.
The Agent Server has cron jobs built in, so scheduled runs get the same durability, tracing, and auth guarantees as any other run—no separate scheduler to maintain, no second observability story to wire up. You pass a standard cron expression (UTC) and an input, and the server triggers runs on schedule.
Two flavors fit different patterns:
- Stateful cron (client.crons.create_for_thread) ties the schedule to a specific thread_id, so every triggered run appends to the same conversation. This fits agents that should see their own history—a daily research agent that builds on yesterday's findings, or a monitoring agent that remembers what it already flagged.
- Stateless cron (client.crons.create) spins up a fresh thread for each execution, which fits batch-style work that doesn't need continuity between runs. Control thread cleanup via on_run_completed: "delete" (the default) removes the thread when the run finishes, "keep" preserves it for later retrieval via client.runs.search(metadata={"cron_id": cron_id}).
Every cron run shows up in tracing, respects auth handlers and middleware, and supports resumption on failure—a cron that hits a transient model outage at 3am doesn't silently fail, it gets retried like any other run. One operational note: delete crons when you're done with them. They keep running (and billing) until you do.
We see enterprise teams with varying deployment requirements, so the runtime supports cloud, hybrid, and self-hosted deployments. The capabilities are the same regardless of where you run it.
deepagents deploy
deepagents deploy is the packaging step that deploys your agent on the runtime described above. You define your agent in deepagents.toml, and the CLI bundles your configuration and deploys it as a LangSmith Deployment with all of the aforementioned features.
Memory uses a virtual filesystem with pluggable backends that gives agents both ephemeral scratch space and persistent cross-conversation storage. Deep Agents support memory scoped to users or assistants (or both)!
Sandbox providers (LangSmith Sandboxes, Daytona, Modal, Runloop, or custom) are a single config value. When a sandbox is present, the harness automatically adds an execute tool. Sandbox lifecycle (thread-scoped vs assistant-scoped) is handled through graph factories. Credentials inside sandboxes are managed through the sandbox au
関連記事
AI ヘルスコーチの構築:評価、安全性、規制対応について
LangChain が AI ヘルスコーチの開発において、評価手法や安全性確保、規制遵守の重要性を解説している。
AI エージェントに専用コンピューターを付与する
LangChain は、数百万のタスクを実行する AI エージェントが安全かつ効率的に動作するために、各エージェントに個別のファイルシステムやシェル環境を持つ仮想コンピューターを提供するインフラシフトの必要性を提唱している。
Google Colab CLI の紹介
Google は、開発者や AI エージェントがローカル端末からリモート Colab ランタイムに接続し、高機能 GPU を要求して Python スクリプトをシームレスに実行できる新ツール「Google Colab CLI」を発表した。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み