Amazon Athena と Amazon QuickSight を活用した Amazon SageMaker 上のエージェント型 AI アナリティクスの実現
AWS は Amazon QuickSight のエージェント機能と Athena、SageMaker を統合し、自然言語によるデータ分析を可能にする新しいアーキテクチャを発表した。
キーポイント
Agentic AI による自己完結型分析の実現
従来の SQL やモデリングの専門知識が不要となり、ビジネスユーザーが自然言語で複雑な構造化・非構造化データをクエリできるエージェント型 AI アシスタントを提供する。
TPC-H データセットを用いた統合アーキテクチャ
Amazon S3、SageMaker、AWS Glue を基盤とし、Athena でサーバーレス SQL クエリを実行し、QuickSight の機能でダッシュボードと会話型エージェントを構築する具体的な実装例を示している。
セキュリティとガバナンスの維持
データアクセスの民主化を進めつつも、Amazon QuickSight Spaces を活用した統合ナレッジベースにより、エンタープライズレベルのセキュリティとガバナンス枠組みを保持する。
影響分析・編集コメントを表示
影響分析
この発表は、データ分析の専門性を必要とする従来のプロセスから、自然言語による直感的な操作へパラダイムシフトさせる重要な一歩です。特に「Agentic AI」という概念を具体的な AWS サービス構成に落とし込んだことで、大規模組織におけるデータ民主化と意思決定の迅速化が現実的なものとなります。
編集コメント
「Agentic AI」という用語を具体的な分析ツールに適用した事例は、LLM の活用が単なるチャットボットから自律的な業務遂行へと進化していることを示す好例です。
現代の企業は、ペタバイト規模に及ぶ構造化・非構造化データにまたがる膨大なデータレイクやデータハウスから実行可能なインサイトを抽出する上で、ますます深刻な課題に直面しています。従来の分析手法では、SQL、データモデリング、ビジネスインテリジェンスツールに関する専門的な技術的知識が必要とされ、小売、金融サービス、ヘルスケア、旅行・ホスピタリティ、製造業など多くの業界において意思決定を遅らせるボトルネックを生み出していました。本アーキテクチャは、Amazon Quick のエージェント型 AI アシスタントが、データ分析をセルフサービス機能へと変革する方法を示しています。これは、直感的な自然言語インターフェースを通じて、ビジネスユーザーが複雑な構造化データセットを照会し、非構造化データと組み合わせることで、事業成果の向上に役立つ貴重なインサイトを発見できるようにする機能を備えています。
機能のデモンストレーションを行うために、TPC-H データセットを基盤としたレイクハウスを構築しました。この統合アーキテクチャは、ストレージとして Amazon Simple Storage Service (Amazon S3) を活用し、レイクハウスには Amazon SageMaker と AWS Glue を使用します。また、Amazon Athena を用いて、S3 テーブル、Iceberg、Parquet といった複数のストレージ形式にわたるサーバーレス SQL クエリを実行し、Quick の多様な機能を活用してダッシュボードを構築するとともに、データインサイトへの自然言語アクセスを提供する会話型 AI エージェントを実現しています。Amazon Quick spaces を活用した統合ナレッジベースを通じて、本ソリューションは組織全体での現代的なデータ駆動型意思決定に必要なスケーラビリティを維持しつつ、エンタープライズグレードのセキュリティとガバナンスフレームワークを保証しながら、ビジネスユーザーによるレイクハウスデータのアクセスを民主化します。
ソリューション概要
以下の図は、本ブログ記事の一部として実装した全体の設計および対応するデータフローを示しています。
 image
image
図 1: 全体の設計図
詳細なエンドツーエンドのデータフローおよびユーザーインタラクション機能については、以下の手順を参照してください。
- データソース取り込み:構造化データである TPC-H が主要なデータソースとなり、リレーショナルデータベース形式で保存されたベンチマークデータセットを含んでいます。AWS は、この TPC-H データを公開されている S3 バケット (s3://redshift-downloads/TPC-H/2.18/100GB) にホストしています。
- データロード:Amazon Athena が最初のクエリ層として機能し、サーバーレス SQL クエリを実行して TPC-H の構造化データからデータを抽出・準備し、S3 へのデータロードと Glue における対応するカタログの作成を行います。
- マルチフォーマットストレージ層:データレイクおよび Lakehouse の多様性を示すため、データを 3 つの最適化されたストレージ形式に保存しました。
Amazon S3 -CSV: 既存の CSV ファイルに基づいて外部テーブルを作成し、Athena テーブルを構築します。
- Amazon S3 (Apache Iceberg-parquet): 時間旅行機能とスキーマ進化を可能にする ACID 互換のテーブル形式です。
- Amazon S3 Table: Amazon S3 Tables は、組み込みの Apache Iceberg サポートを備えた初のクラウドオブジェクトストレージであり、大規模な表形式データの保存を簡素化します。
- メタデータカタログ:AWS Glue Catalog はこれら 3 つのストレージ形式すべてにインデックスを作成し、異なるデータフォーマット間でのシームレスなクエリを可能にする統合メタデータ層を構築しています。
- Lakehouse クエリ層:Glue Catalog のメタデータを活用して、Amazon Athena SQL クエリをストレージ形式 (S3 Table, Iceberg, Parquet) 全体にわたって実行し、統一されたクエリインターフェースを提供します。
- ビジネスインテリジェンスパイプライン:構造化された TPC-H データは Amazon Quick に流れ込み、Quick Sight と統合して以下を作成します。
データセット – Amazon Quick から Amazon Athena 接続を利用し、構造化データを抽出して Quick SPICE (Super-fast, Parallel, In-memory Calculation Engine) データセットにロードします。
- トピック – ビジネスコンテキストのための整理されたデータドメイン。
- Q を使用したダッシュボード – 自然言語クエリ機能によるインタラクティブな可視化でダッシュボードを構築し、公開します。
- AI 知識強化:構造化データのフローと並行して、TPC-H の仕様に関する Web クローラーが非構造化データ (ドキュメント、仕様書) を取り込み、Knowledge Bases に供給して文脈理解を提供します。
- 対話型エージェント AI レイヤー:Knowledge Bases が Amazon Quick Spaces(協働環境) を駆動し、それによって自然言語での対話を可能にする文脈認識とドメイン知識を備えた Amazon Quick チャットエージェントを実現します。
- エンドユーザーアクセス:ユーザーは主に 2 つのインターフェースを通じてシステムと対話します。
Q を使用したダッシュボード – ビジュアル分析およびセルフサービスビジネスインテリジェンス。
- チャットエージェント – 自然言語によるデータ探索のための対話型 AI。
事前準備
始める前に、以下の前提条件を満たしていることを確認してください:
- AWS アカウントと Amazon QuickSight アカウントの両方を持っていること
- Amazon Simple Storage Service (Amazon S3)、Amazon SageMaker、AWS Lake Formation、および Amazon Athena に関する基本的な理解があること
- S3 内のデータセット作成、Athena クエリの実行、Glue カタログの作成、Lake Formation の管理者権限、および QuickSight の機能へのアクセスを許可するコンソールロールを持っていること。関連するポリシー/ポリシーを決定するには、ポリシードキュメントを参照してください。
レイクハウス / データレイク向けのデータ準備
このセクションでは、外部テーブルを活用して、多くのデータレイク機能を模倣します。これにより、管理されたストレージ層にデータをロードすることなく、Amazon S3 に保存されたデータを照会することが可能になります。Apache Icebergを使用したオープンテーブルフォーマット (OTF) テーブルを探索し、サポートされる ACID トランザクションを持つテーブルの可能性を検討します。また、Amazon がネイティブで Iceberg 互換のテーブル管理を S3 内で直接サポートする方法を示すために、Amazon のマネージドS3 Tablesを活用し、スケールしたレイクハウスアーキテクチャを簡素化する方法を探ります。これらの演習全体を通じて、業界標準のTPC-H データセットを使用します。これは、注文、顧客、ラインアイテムを含む現実的なビジネスデータモデルを表すベンチマークワークロードであり、例が意味があり再現可能であることを保証するためです。
データ準備には Amazon Athena を活用します。Amazon Athenaを初めて使用する場合は、クエリ結果を保存するためのAmazon S3 バケットを作成する必要があります。Athena では、クエリを実行する前に出力先として S3 を使用します。この一度きりのセットアップは、公式の AWS 入門ガイドに従って完了してください:Amazon Athena の入門。あるいは、管理されたクエリ結果機能を使用することもできます。
ヒント: クロスリージョン間のデータ転送コストとレイテンシを回避するため、S3 バケットはデータソースと同じAWS リージョンに選択してください。
S3 の出力先が設定されれば、次の手順に進む準備が整います。
Glue データベースの作成
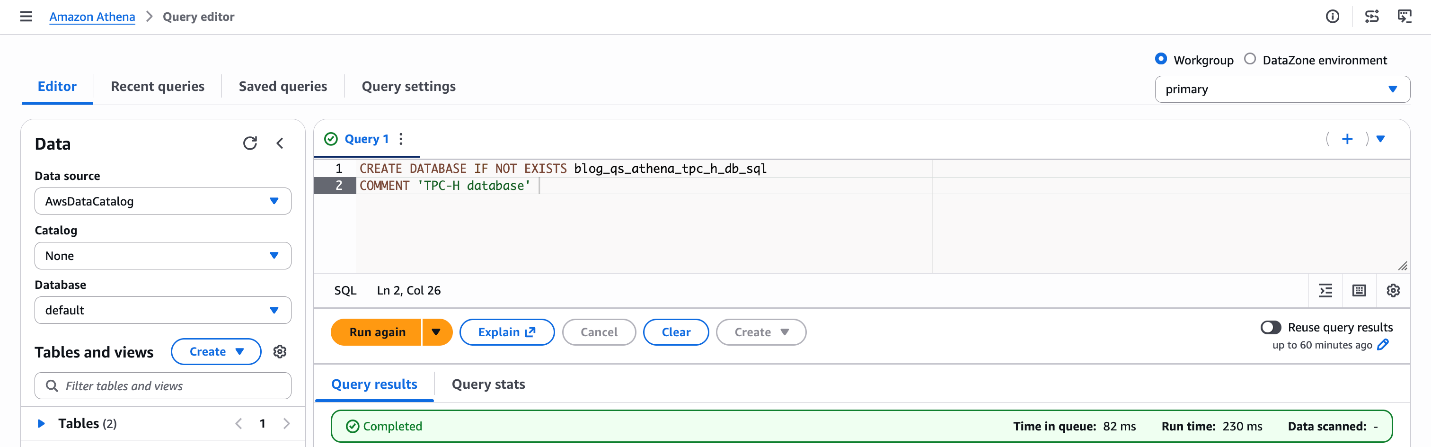
まず、Athena で使用するすべてのテーブルのメタデータカタログとして機能する Glue データベースを作成します。Athena クエリエディターで以下の SQL を実行してください:
CREATE DATABASE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql COMMENT 'TPC-H database';
 image
image
Figure 2: Database creation blog_qs_athena_tpc_h_db_sql
この処理の内容: これは、Athena がテーブルの整理と発見に使用する AWS Glue データカタログ内に論理データベースを登録するものです。後続の手順で作成されるテーブルは、すべてこのデータベースの下に配置されます。
S3 上の外部テーブルの作成
次に、パブリック S3 バケット('s3://redshift-downloads/TPC-H/2.18/100GB/customer/')に保存されている TPC-H の「customer」データセットを指す外部テーブルを作成します。Athena における外部テーブルはデータを移動またはコピーするものではなく、S3 から直接クエリを実行するため、生データを探索するための高速かつコスト効果の高い方法となります。
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.customer_csv
(
C_CUSTKEY INT,
C_NAME STRING,
C_ADDRESS STRING,
C_NATIONKEY INT,
C_PHONE STRING,
C_ACCTBAL DOUBLE,
C_MKTSEGMENT STRING,
C_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/customer/'
TBLPROPERTIES ('classification' = 'csv');
テーブルの検証として、数行をプレビューします:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.customer_csv LIMIT 10;
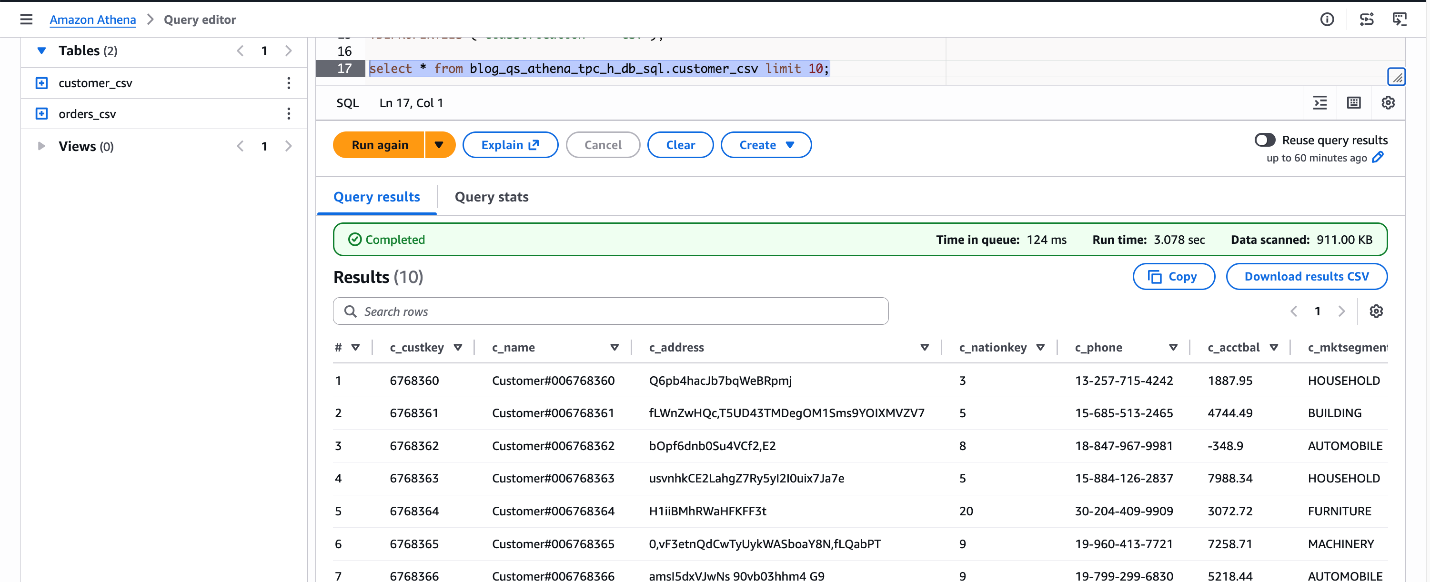
図 3: blog_qs_athena_tpc_h_db_sql.customer_csv の検証
Apache Iceberg テーブルの作成
次に、Apache Iceberg を用いてテーブルを模倣します。Apache Iceberg は ACID トランザクション、タイムトラベル(過去の状態へのアクセス)、パーティション進化といった機能をデータレイクに提供するオープンなテーブルフォーマットであり、本番環境向けのワークロードに理想的です。これは 3 つのステップからなるプロセスです。
ステップ1:S3 バケットの作成 – SQL クエリを書く前に、ストレージ層を設定してください。AWS Management Console または AWS CLI を使用して S3 バケットを作成できます。
このブログでは、以下の S3 バケットを使用しています: amzn-s3-demo-bucket
注意: S3 バケット名はすべての AWS アカウント間でグローバルに一意である必要があるため、バケット名は異なります。
ステップ2:注文用の外部 CSV テーブルの作成 – まず、生の注文データを元の形式(今回は CSV)で外部テーブルとして登録します。
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.orders_csv
(
O_ORDERKEY BIGINT,
O_CUSTKEY BIGINT,
O_ORDERSTATUS STRING,
O_TOTALPRICE DOUBLE,
O_ORDERDATE STRING,
O_ORDERPRIORITY STRING,
O_CLERK STRING,
O_SHIPPRIORITY INT,
O_COMMENT STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = '|')
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/orders/'
TBLPROPERTIES ('classification' = 'csv');
データセットを確認しましょう。
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv LIMIT 10;
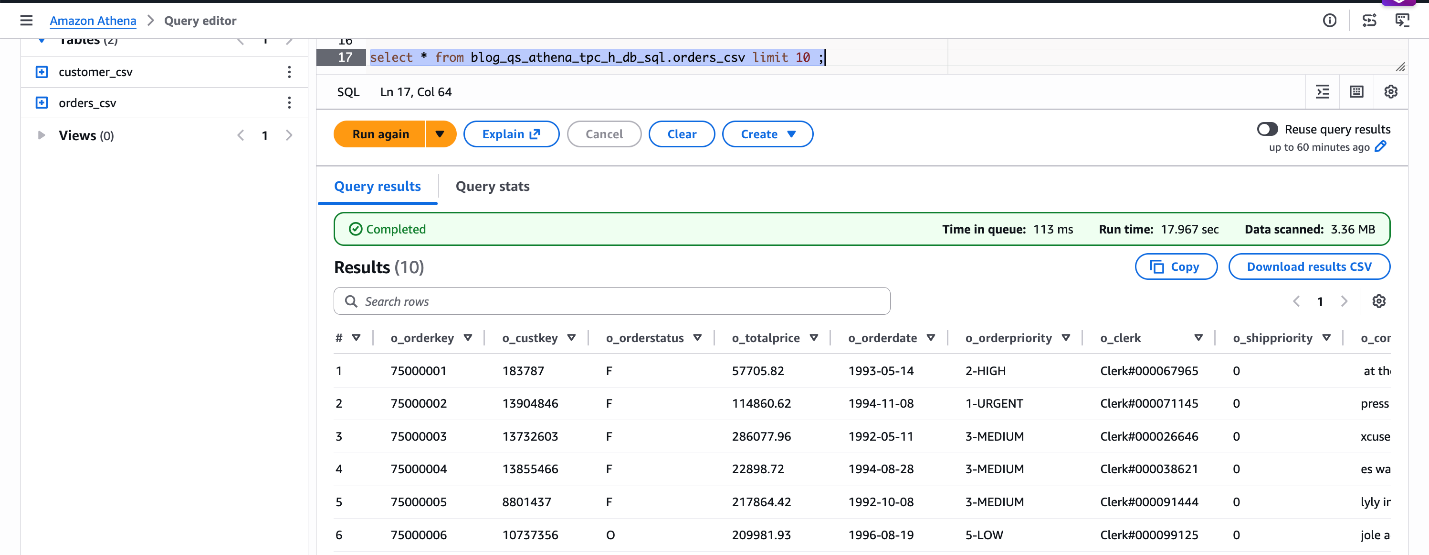
図 4: blog_qs_athena_tpc_h_db_sql.orders_csv の確認
ステップ3: CREATE TABLE AS SELECT (CTAS) を使用して Iceberg テーブルを作成する – CREATE TABLE AS SELECT (CTAS) を使用して、Parquet 形式の自己管理型 Iceberg テーブルを注文日付でパーティション分割して作成します。ここでは、O_ORDERDATE が '1998-06-01' と '1998-12-31' の間のサンプル日付範囲を読み込みます。
CREATE TABLE blog_qs_athena_tpc_h_db_sql.orders_iceberg
WITH (
table_type = 'ICEBERG',
format = 'PARQUET',
is_external = false,
partitioning = ARRAY['o_orderdate'],
location = 's3://amzn-s3-demo-bucket/tpch_iceberg/orders/')
AS
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv
WHERE O_ORDERDATE BETWEEN '1998-06-01' AND '1998-12-31';
Iceberg テーブルのデータを検証します:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_iceberg LIMIT 10;
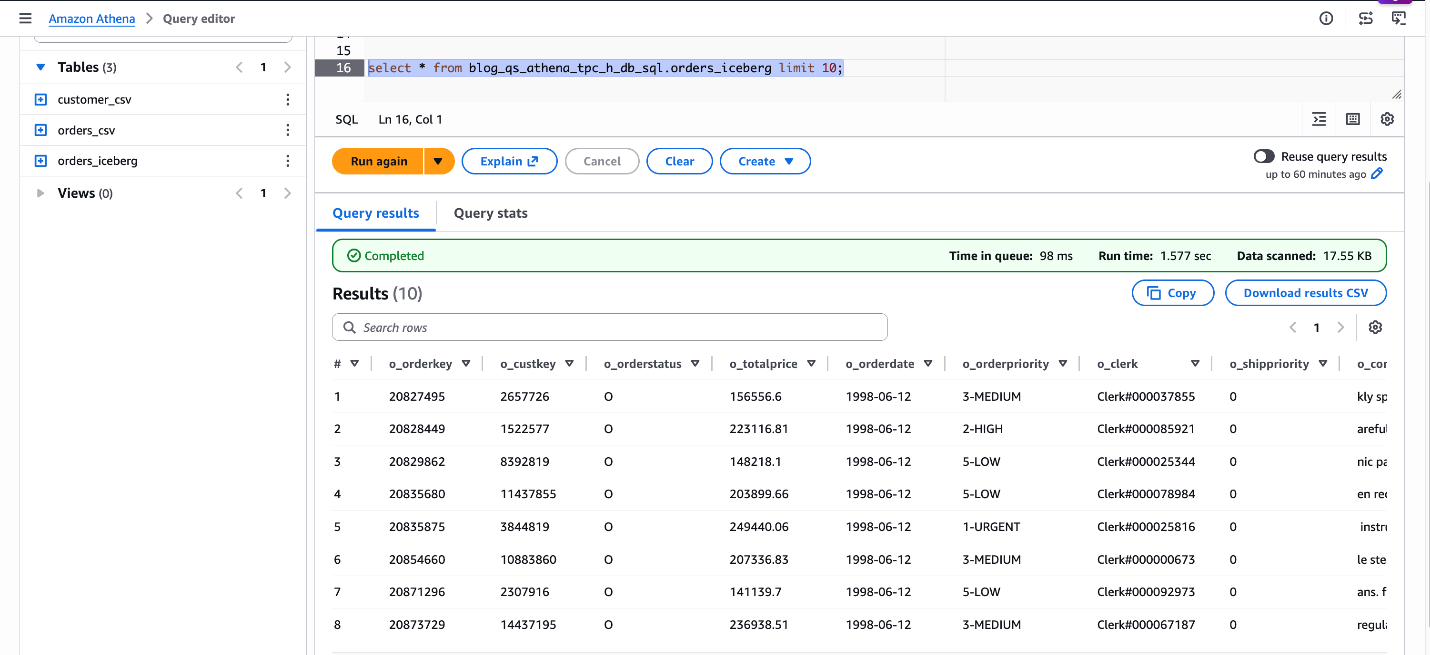
図 5: blog_qs_athena_tpc_h_db_sql.orders_iceberg の検証
Amazon S3 テーブルの作成
Amazon S3 Tables は、組み込みの Apache Iceberg (アイスバーグ) サポートを備えた目的特化型の完全管理型テーブルです。圧縮、スナップショット管理、参照されていないファイルの削除などのメンテナンス操作を管理するオーバーヘッドなしに、高パフォーマンスなクエリ処理スループットを提供します。これは 3 つの手順で構成されます。
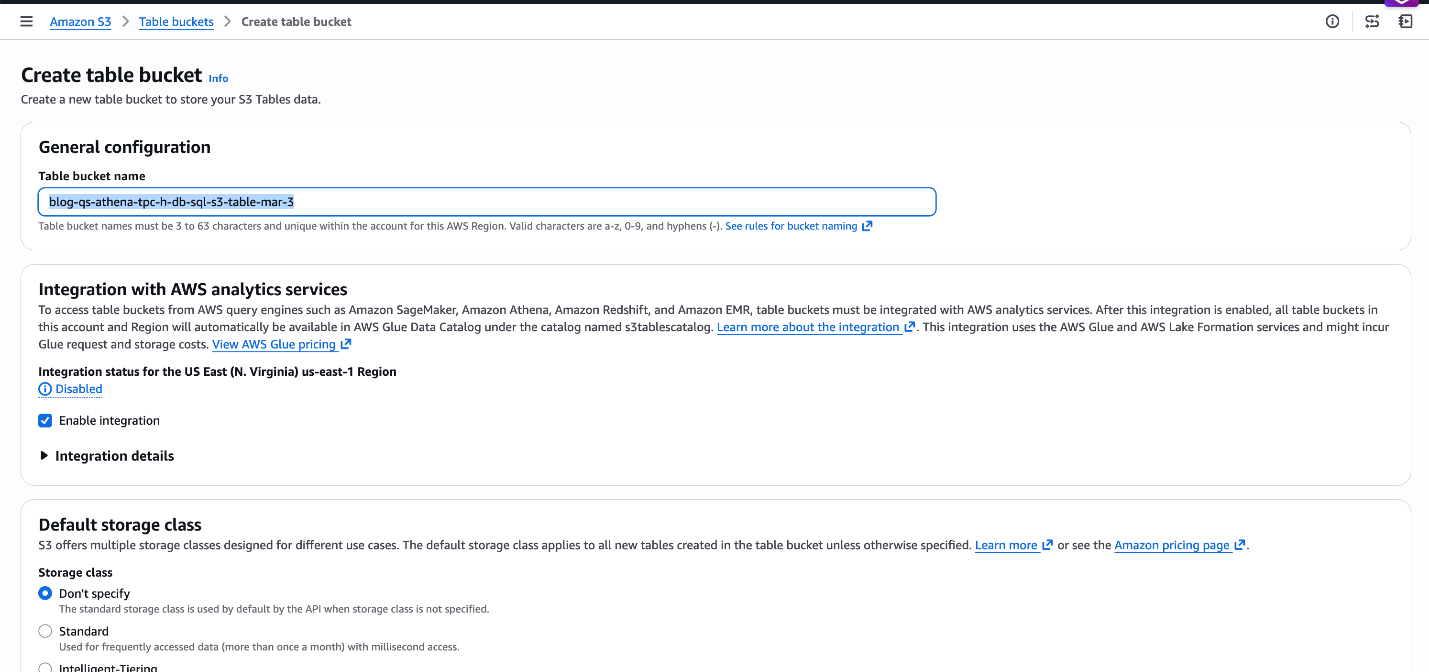
ステップ1:S3 テーブルバケットとネームスペースの作成 – AWS コンソールで S3 → Table Buckets に移動し、バケット blog-qs-athena-tpc-h-db-sql-s3-table-mar-3 とネームスペースを作成します。または、AWS CLI を使用したスクリプトによるセットアップ も利用可能です。
注:すでに S3 テーブルバケットとネームスペースが利用可能な場合は、これらの手順を無視してください。
 image
image
図 6:S3 テーブルバケット blog-qs-athena-tpc-h-db-sql-s3-table-mar-3 の作成
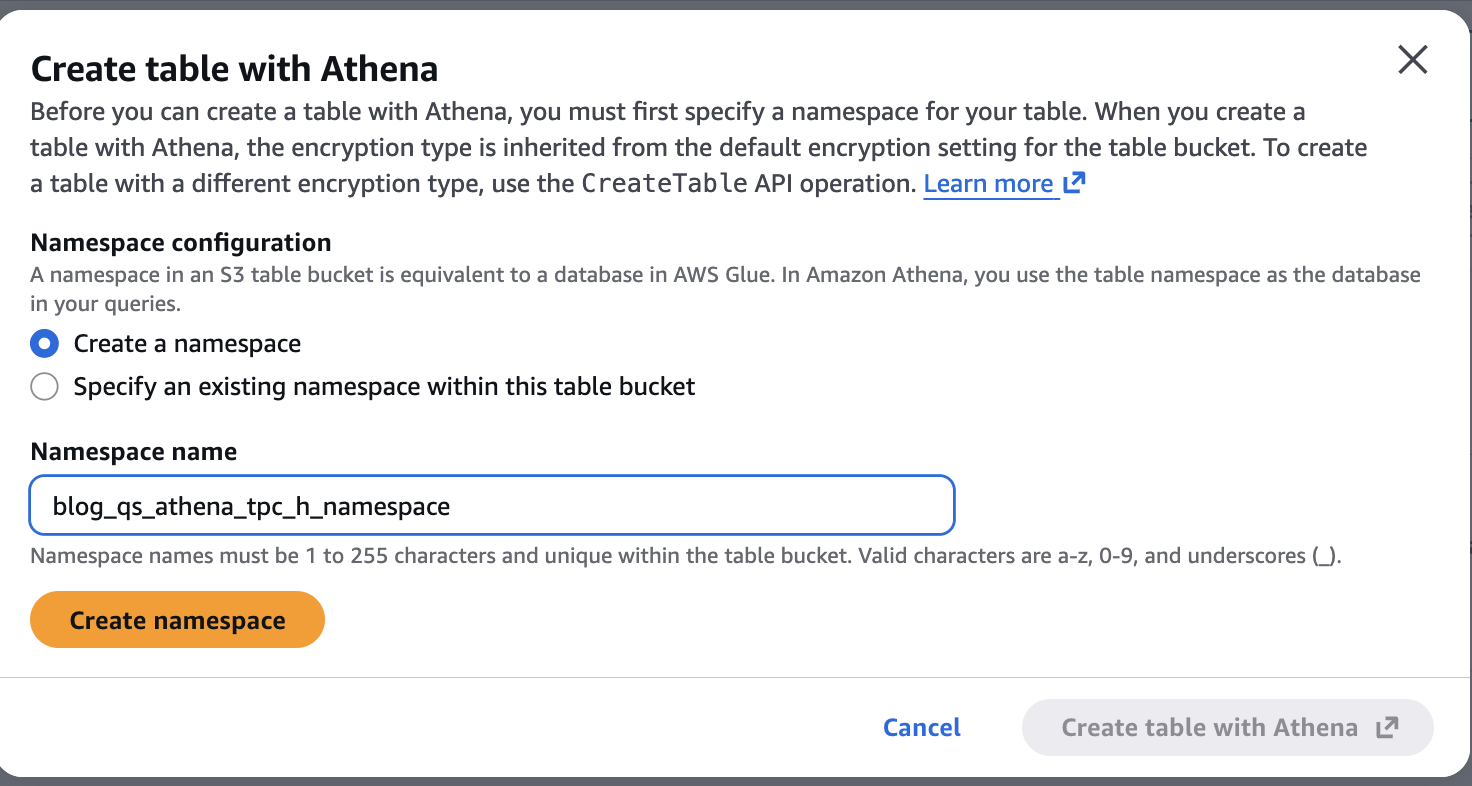
次に、blog-qs-athena-tpc-h-db-sql-s3-table-mar-3 をクリックして、上記の S3 テーブルバケットに関連付けられたネームスペース blog_qs_athena_tpc_h_namespace を作成します。
 image
image
図 7:S3 テーブルネームスペース blog_qs_athena_tpc_h_namespace の作成
ステップ2:外部 CSV テーブルの作成(行項目用) – Athena を使用して、TPC-H 行項目データセットを外部テーブルとして登録します:
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.lineitem_csv
(
L_ORDERKEY BIGINT,
L_PARTKEY BIGINT,
L_SUPPKEY BIGINT,
L_LINENUMBER INT,
L_QUANTITY DECIMAL(15,2),
L_EXTENDEDPRICE DECIMAL(15,2),
L_DISCOUNT DECIMAL(15,2),
L_TAX DECIMAL(15,2),
L_RETURNFLAG STRING,
L_LINESTATUS STRING,
L_SHIPDATE STRING,
L_COMMITDATE STRING,
L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING,
L_SHIPMODE STRING,
L_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/lineitem/'
TBLPROPERTIES ('skip.header.line.count' = '0');
データのプレビュー:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.lineitem_csv LIMIT 10;
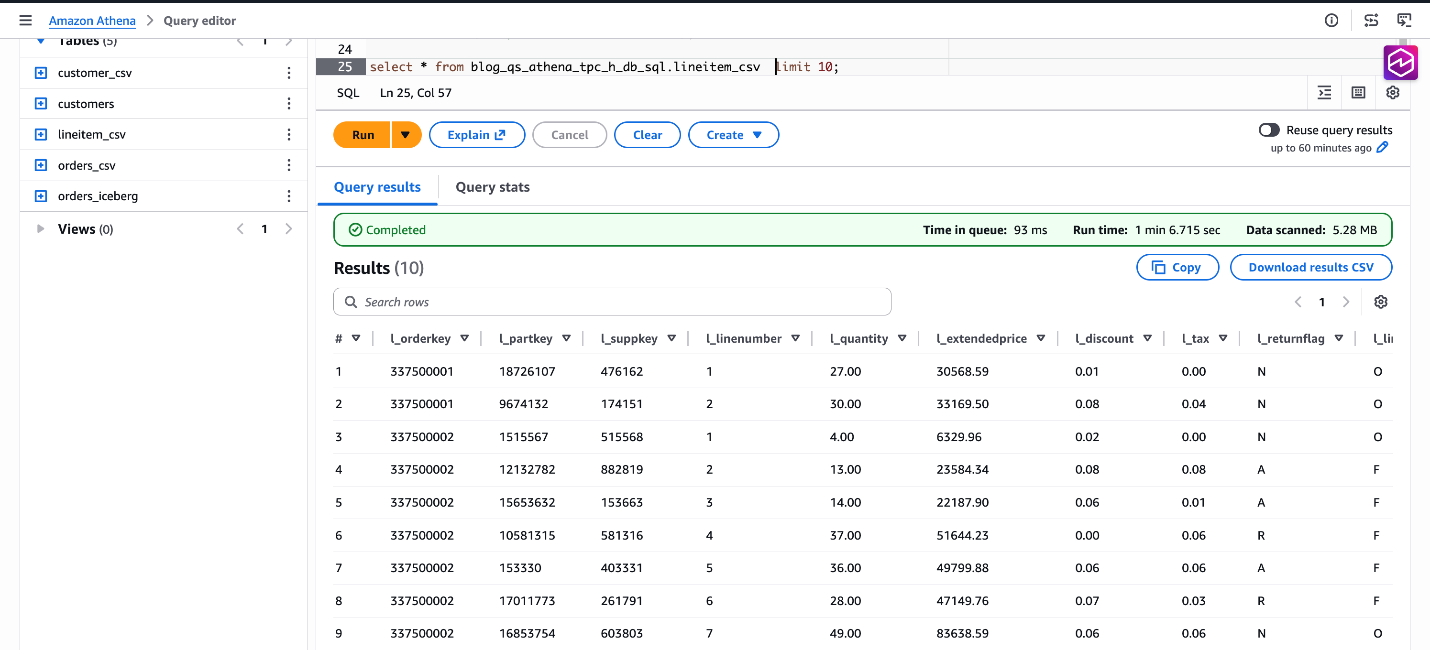
図 8: データ blog_qs_athena_tpc_h_db_sql.lineitem_csv の検証
ステップ 3: CTAS を使用して S3 テーブルを作成する – 最後に、CTAS(Create Table As Select)を使用して、新しいカタログに Parquet 形式の S3 テーブルを作成します。初期データロードを制限するために、CAST(L_SHIPDATE AS DATE) BETWEEN DATE('1998-06-01') AND DATE('1998-12-31') を使用してサンプルの日付範囲でフィルタリングします。
注: 以下のスクリーンショットに示すように、s3tablescatalog を使用して、以下のクエリを実行してください。
CREATE TABLE lineitem_csv_s3_table
WITH ( format = 'PARQUET')
AS
SELECT * FROM AwsDataCatalog.blog_qs_athena_tpc_h_db_sql.linei
原文を表示
Modern enterprises face mounting challenges in extracting actionable insights from vast data lakes and lakehouses spanning petabytes of structured and unstructured data. Traditional analytics require specialized technical expertise in SQL, data modeling, and business intelligence tools, creating bottlenecks that slow decision-making across retail, financial services, healthcare, Travel & Hospitality, manufacturing and many more industries. This architecture demonstrates how agentic AI assistant from Amazon Quick transform data analytics into a self-service capability. It showcases enabling business users to query complex structured datasets and mix with unstructured data to find the valuable insights to improve their business outcomes through intuitive natural language interfaces.
To demonstrate the functionality, we built a lakehouse using the TPC-H datasets as our foundation. This integrated architecture leverages Amazon Simple Storage Service (Amazon S3) as a storage, Amazon SageMaker and AWS Glue for lakehouse, Amazon Athena for serverless SQL querying across multiple storage formats (S3 Table, Iceberg, and Parquet), and multiple features from Quick to build dashboard and conversational AI agents that provide natural language access to data insights. Through integrated knowledge bases using Amazon Quick spaces, this solution democratizes lakehouse data access for business users while preserving enterprise-grade security, governance frameworks, and the scalability required for modern data-driven decision-making across the organization.
Solution Overview
The following diagram shows the overall design and corresponding dataflow that we implemented as part of this blog post.
Figure 1: Overall design diagram Reference following steps for the detailed end to end data flow and user interaction capabilities.
- Data Source Ingestion: Structured Data TPC-H serves as the primary data source, containing benchmark datasets stored in relational database format. AWS hosted the TPC-H data in the publicly available s3 bucket (s3://redshift-downloads/TPC-H/2.18/100GB)
- Data Load: Amazon Athena performs the first query layer, executing serverless SQL queries against the TPC-H structured data to extract, prepare data for processing, load data in S3, and create corresponding catalog in Glue.
- Multi-Format Storage Layer: To illustrate the versatility of Data lake and Lakehouse we saved the data into three optimized storage formats:
Amazon S3 -CSV: Use external table to create Athena table based on existing CSV files.
- Amazon S3 (Apache Iceberg-parquet): ACID-compatible table format enabling time-travel and schema evolution
- Amazon S3 Table: Amazon S3 Tables deliver the first cloud object store with built-in Apache Iceberg support and streamline storing tabular data at scale.
- Metadata Cataloging: AWS Glue Catalog indexes all three storage formats, creating a unified metadata layer that enables seamless querying across different data formats.
- Lakehouse Query Layer: We used the Amazon Athena SQL queries across storage formats (S3 Table, Iceberg, and Parquet) using the Glue Catalog metadata, providing a unified query interface.
- Business Intelligence Pipeline: Structured TPC-H data flows into Amazon Quick, which integrates with Quick Sight to create:
Dataset – We utilized Amazon Athena connection from Amazon Quick to extract structured data to load in Quick SPICE (Super-fast, Parallel, In-memory Calculation Engine) dataset
- Topic – Organized data domains for business context
- Dashboard Using Q – Interactive visualizations with natural language query capabilities to build the dashboard and publish it
- AI Knowledge Enhancement: Parallel to the structured data flow, a Web Crawler for TPC-H specifications ingests unstructured data (documentation, specifications) and feeds it into Knowledge Bases to provide contextual understanding.
- Conversational Agentic AI Layer: Knowledge Bases power Amazon Quick spaces (collaborative environments), which in turn enable the Amazon Quick chat agents with contextual awareness and domain knowledge for natural language interactions.
- End User Access: Users interact with the system through two primary interfaces:
Dashboard Using Q – Visual analytics and self-service Business Intelligence
- Chat Agent – Conversational AI for natural language data exploration
Pre-requisite
Before you get started, make sure you have the following prerequisites:
- An AWS account and Amazon Quick account
- A basic understanding of Amazon Simple Storage Service, Amazon SageMaker, AWS Lake Formation, and Amazon Athena
- Console role with permissions to create the dataset in S3, run Athena queries, create Glue catalog, Lake Formation admin privileges, and access Quick features. To decide the relevant policy/policies reference policy document.
Data Preparation for lakehouse / data Lake
In this section, we will mimic many of the data lake features by working with external tables, which allow querying data stored in Amazon S3 without loading it into a managed storage layer. We will explore Open Table Format (OTF) tables using Apache Iceberg to consider possible ACID transactions supported tables. Amazon managed S3 Tables will be leveraged to showcase how Amazon natively supports Iceberg-compatible table management directly within S3, simplifying lakehouse architecture at scale. Throughout these exercises, we will use the industry-standard TPC-H dataset, a benchmark workload representing a realistic business data model with orders, customers, and line items to make sure our examples are both meaningful and reproducible.
We will leverage Amazon Athena for data preparation. If this is your first time using Amazon Athena, you’ll need to create an Amazon S3 bucket to store your query results. Athena uses S3 as its output location before you can run queries. Follow the official AWS getting started guide to complete this one-time setup: Getting Started with Amazon Athena. Alternately, you can use Managed query results feature.
Tip: Choose an S3 bucket in the same AWS Region as your data sources to avoid cross-region data transfer costs and latency.
Once your S3 output location is configured, you’re ready to proceed.
Create the Glue Database
Start by creating a Glue database that will serve as the metadata catalog for all your tables using Athena. Run the following SQL in the Athena query editor:
CREATE DATABASE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql COMMENT 'TPC-H database'; Figure 2: Database creation blog_qs_athena_tpc_h_db_sql
What this does: This registers a logical database in the AWS Glue Data Catalog, which Athena uses to organize and discover your tables. Tables created in subsequent steps will live under this database.
Create an External Table on S3
Next, create an external table pointing to the TPC-H “customer” dataset stored in a public S3 bucket ('s3://redshift-downloads/TPC-H/2.18/100GB/customer/'). External tables in Athena don’t move or copy data — they query it directly from S3, making this a fast and cost-effective way to explore raw data.
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.customer_csv
(
C_CUSTKEY INT,
C_NAME STRING,
C_ADDRESS STRING,
C_NATIONKEY INT,
C_PHONE STRING,
C_ACCTBAL DOUBLE,
C_MKTSEGMENT STRING,
C_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/customer/'
TBLPROPERTIES ('classification' = 'csv'); Verify the table by previewing a few rows:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.customer_csv LIMIT 10; Figure 3: verify blog_qs_athena_tpc_h_db_sql.customer_csv
Create an Apache Iceberg Table
Next, we will mimic the table using Apache Iceberg, which is an open table format that brings ACID transactions, time travel, and partition evolution to your data lake — making it ideal for production-grade workloads. This is a three-step process.
Step1: Create the S3 Bucket – Before writing SQL queries, set up your storage layer. You can create an S3 bucket using the AWS Management Console or AWS CLI.
For this blog, I’m using the S3 bucket: amzn-s3-demo-bucket
Note: Your bucket name will be different, as S3 bucket names must be globally unique across all AWS accounts.
Step2: Create an External CSV Table for Orders – First, register the raw orders data as an external table in its original format, in our case it’s CSV.
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.orders_csv
(
O_ORDERKEY BIGINT,
O_CUSTKEY BIGINT,
O_ORDERSTATUS STRING,
O_TOTALPRICE DOUBLE,
O_ORDERDATE STRING,
O_ORDERPRIORITY STRING,
O_CLERK STRING,
O_SHIPPRIORITY INT,
O_COMMENT STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = '|')
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/orders/'
TBLPROPERTIES ('classification' = 'csv');Let’s verify the dataset.
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv LIMIT 10;Figure 4: verify blog_qs_athena_tpc_h_db_sql.orders_csv
Step3: Create the Iceberg Table Using CREATE TABLE AS SELECT (CTAS) – Use CREATE TABLE AS SELECT (CTAS) to create a self-managed Iceberg table in Parquet format, partitioned by order date. We’ll load a sample date range O_ORDERDATE BETWEEN ‘1998-06-01’ AND ‘1998-12-31’.
CREATE TABLE blog_qs_athena_tpc_h_db_sql.orders_iceberg
WITH (
table_type = 'ICEBERG',
format = 'PARQUET',
is_external = false,
partitioning = ARRAY['o_orderdate'],
location = 's3://amzn-s3-demo-bucket/tpch_iceberg/orders/')
AS
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_csv
WHERE O_ORDERDATE BETWEEN '1998-06-01' AND '1998-12-31';Verify the Iceberg table data:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.orders_iceberg LIMIT 10; Figure 5: verify blog_qs_athena_tpc_h_db_sql.orders_iceberg
Create an Amazon S3 Table
Amazon S3 Tables are purpose-built, fully managed tables with built-in Apache Iceberg support. It delivers high-performance query throughput without the overhead of managing maintenance operations, such as compaction, snapshot management, and unreferenced file removal. This is a three-step process.
Step1: Create the S3 Table Bucket and Namespace – Navigate to S3 → Table Buckets in the AWS Console to create the bucket blog-qs-athena-tpc-h-db-sql-s3-table-mar-3 and namespace. Alternatively, use the AWS CLI for scripted setup.
Note : You can ignore these steps if you already have an S3 table bucket and namespace available.
Figure 6: Create S3 Table bucket blog-qs-athena-tpc-h-db-sql-s3-table-mar-3
Now let’s create a namespace blog_qs_athena_tpc_h_namespace associated with above S3 table bucket by clicking on the blog-qs-athena-tpc-h-db-sql-s3-table-mar-3.
Figure 7: Create S3 table Namespace blog_qs_athena_tpc_h_namespace
Step2: Create an External CSV Table for Line Items – Use Athena to register the TPC-H line items dataset as an external table:
CREATE EXTERNAL TABLE IF NOT EXISTS blog_qs_athena_tpc_h_db_sql.lineitem_csv
(
L_ORDERKEY BIGINT,
L_PARTKEY BIGINT,
L_SUPPKEY BIGINT,
L_LINENUMBER INT,
L_QUANTITY DECIMAL(15,2),
L_EXTENDEDPRICE DECIMAL(15,2),
L_DISCOUNT DECIMAL(15,2),
L_TAX DECIMAL(15,2),
L_RETURNFLAG STRING,
L_LINESTATUS STRING,
L_SHIPDATE STRING,
L_COMMITDATE STRING,
L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING,
L_SHIPMODE STRING,
L_COMMENT STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/TPC-H/2.18/100GB/lineitem/'
TBLPROPERTIES ('skip.header.line.count' = '0');Preview the data:
SELECT * FROM blog_qs_athena_tpc_h_db_sql.lineitem_csv LIMIT 10;Figure 8: verify data blog_qs_athena_tpc_h_db_sql.lineitem_csv
Step3: Create the S3 Tables Table Using CTAS – Finally, create a Parquet-formatted S3 Tables in your new catalog using CTAS. We filter a sample date range to limit the initial data load based on CAST(L_SHIPDATE AS DATE) BETWEEN DATE(‘1998-06-01’) AND DATE(‘1998-12-31’).
Note: Make sure to use s3tablescatalog to run the following queries as shown in the following screenshot.
CREATE TABLE lineitem_csv_s3_table
WITH ( format = 'PARQUET')
AS
SELECT * FROM AwsDataCatalog.blog_qs_athena_tpc_h_db_sql.linei
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み