Amazon BedrockとAmazon OpenSearchを用いたハイブリッドRAGソリューションによるインテリジェント検索の構築
AWSはAmazon BedrockとAmazon OpenSearchを組み合わせたハイブリッドRAGソリューションを紹介し、セマンティック検索とテキストベース検索の両方を活用するエージェンティックAIアシスタントの実装方法を詳細に説明している。
キーポイント
エージェンティックAIアシスタントの特徴
従来のチャットボットを超え、大規模言語モデルを活用した動的システムで、複雑なタスクを処理し、マルチステップの会話を維持しながらユーザーニーズに適応する。
RAG(Retrieval-Augmented Generation)の仕組み
LLMの能力と動的データ取得を組み合わせ、API呼び出しやデータベース検索を通じてビジネス固有のデータをリアルタイムで取得し、LLM生成応答に統合する。
ハイブリッド検索アプローチ
セマンティック検索(意味ベース)とテキストベース検索の両方を組み合わせ、Amazon Bedrock、Bedrock AgentCore、Strands Agents、Amazon OpenSearchを使用した実装方法を示している。
ベクトル類似性検索(VSS)の活用
ベクトル埋め込みを事前計算してベクトルデータベースに保存し、コサイン類似度やユークリッド距離などの数学的距離指標を使用して効率的な類似性計算を可能にする。
Amazon Bedrock AgentCoreによるツール統合とデプロイ
定義したツールをAmazon Bedrock AgentCoreと統合し、セキュアでスケーラブルなエージェントのデプロイとランタイムオーケストレーションを実現する。
ハイブリッド検索の高度な実装
セマンティック検索だけでなく、OpenSearchの全機能を活用して、セマンティック、テキストベース、ハイブリッド検索を単一の効率的なクエリで実現する。
最適化されたデータストレージの重要性
効率的なハイブリッド検索のために、データをセマンティック検索候補と構造化データに体系的に分類するデータストレージアプローチが重要である。
重要な引用
Agentic generative AI assistants represent a significant advancement in artificial intelligence, featuring dynamic systems powered by large language models (LLMs) that engage in open-ended dialogue and tackle complex tasks.
This combination of LLM capabilities with dynamic data retrieval is known as Retrieval-Augmented Generation (RAG).
They retrieve data based on the meaning of the search phrase as opposed to keyword or pattern lexical similarity.
The core principle of Vector Similarity Search (VSS) involves finding the closest matches between these numerical representations using mathematical distance metrics such as cosine similarity or Euclidean distance.
Amazon Bedrock AgentCore enables you to deploy and operate highly effective agents securely at scale using any framework and model.
We’ve used the full potential of OpenSearch, enabling semantic, text-based, and hybrid searches, all within a single, efficient query.
影響分析・編集コメントを表示
影響分析
この記事はAWSが提供するクラウドネイティブなAIインフラの成熟度を示しており、企業が実用的なエージェンティックAIアプリケーションを構築するための具体的な道筋を提供している。特にハイブリッド検索アプローチは、セマンティック検索の精度と従来のテキスト検索の確実性を組み合わせることで、実ビジネス環境でのRAGシステムの信頼性向上に貢献する可能性が高い。
編集コメント
AWSのAIサービスエコシステムの統合性が強く感じられる内容で、実務者がすぐに活用できる実践的なガイドとなっている。特にBedrockとOpenSearchの連携は、企業の既存データ資産を活かしたAIアプリケーション開発を加速させるだろう。
エージェント型生成AIアシスタントは、人工知能における重要な進歩を表しており、大規模言語モデル(LLM)によって駆動される動的なシステムで構成され、オープンエンドの対話を行い、複雑なタスクを処理します。基本的なチャットボットとは異なり、これらの実装は広範な知能を備え、複数ステップの会話を維持しながらユーザーのニーズに適応し、必要なバックエンドタスクを実行します。
これらのシステムは、API呼び出しやデータベース参照を通じてリアルタイムで業務固有のデータを取得し、この情報をLLMが生成した回答に組み込んだり、事前に定義された基準に従ってそれらと併せて提供したりします。このLLMの能力と動的なデータ取得の組み合わせは、検索拡張生成(Retrieval-Augmented Generation: RAG)として知られています。
例えば、ホテル予約を扱うエージェント型アシスタントは、まずゲストの特定の要件に一致する宿泊施設を探すためにデータベースを照会します。その後、アシスタントはAPI呼び出しを行って、部屋の空室状況と現在の料金のリアルタイム情報を取得します。この取得されたデータは2つの方法で処理できます。つまり、LLMがそれを処理して包括的な回答を生成するか、またはLLMが生成した要約と併せて表示するかのいずれかです。どちらのアプローチも、ゲストがアシスタントとの継続的な会話の中で統合された正確で最新の情報を受け取ることができます。
本稿では、Amazon Bedrock、Amazon Bedrock AgentCore、Strands Agents、および Amazon OpenSearch を活用し、セマンティック検索とテキストベースの検索の両方を使用する生成型 AI エージェントアシスタントの実装方法について解説します。
RAGシステムにおける情報検索のアプローチ
一般的に、エージェント型生成AIの実装においてRAG機能をサポートする情報検索は、バックエンドデータソースへのリアルタイムクエリ実行またはAPIとの通信を中心に構成されます。その後、その応答は実装によって行われる後続のステップに組み込まれます。高レベルのシステム設計および実装の観点から見ると、このステップは生成AIベースのソリューションに固有のものではありません:データベース、API、およびそれらとの統合に依存するシステムは長らく存在しています。エージェント型AIの実装に伴って出現した特定の情報検索アプローチがあり、最も顕著なのはセマンティックサーチに基づくデータ参照です。これは、キーワードやパターンによる字面での類似性ではなく、検索フレーズの意味に基づいてデータを取得します。ベクトル埋め込みは事前に計算されベクターデータベースに保存されるため、クエリ実行時に効率的な類似度計算が可能になります。ベクトル類似性検索(VSS)の核心原理は、コサイン類似度やユークリッド距離などの数学的距離指標を用いて、これらの数値表現間の最も近い一致を見つけることです。ベクトル表現が事前に計算されているため、これらの数学関数は大規模なデータコーパスの検索において特に効率的です。このプロセスではバイエンコーダーモデルが一般的に使用されます。これらはクエリとドキュメントを個別にベクトルに変換し、モデルがクエリ-ドキュメントのペアを一緒に処理する必要 없이、大規模なスケールで効率的な類似度比較を可能にします。ユーザーがクエリを送信すると、システムはそれをベクトルに変換し、高次元空間内でそれに最も近い位置にあるコンテンツベクトルを検索します。つまり、正確なキーワードが一致しなくても、概念的なセマンティック類似性に基づいて関連する結果を検索できることを意味します。さらに、検索用語がデータセット内のエントリと字面的には近いが意味的には遠い状況では、セマンティック類似性検索は意味的に類似したエントリを「優先」します。
例えば、ベクトル化されたデータセット ["building materials", "plumbing supplies", "2×2 multiplication result"] が与えられた場合、検索文字列「2×4 lumber board」は、「building materials」を最も高いマッチング候補として生成する可能性が高いです。セマンティック検索と LLM 駆動エージェントを組み合わせることで、ユーザーインターフェース側とバックエンドのデータ取得コンポーネントの間で自然言語のアライメントを実現します。LLM はユーザーから提供される自然言語のインプットを処理し、セマンティック検索機能は、エンドユーザーとエージェント間の通信頻度に応じて LLM によって形成された自然言語のインプットに基づいてデータ取得を可能にします。
課題:セマンティック検索だけでは不十分な場合
現実のシナリオを考えてみましょう。ある顧客がホテルを検索し、「フロリダ州マイアミにあるオーシャンビューのラグジュアリーホテル」を見つけたいとします。セマンティック検索は「ラグジュアリー」や「オーシャンビュー」といった概念を理解することに優れていますが、正確な位置情報のマッチングでは苦戦することがあります。検索結果はセマンティックな類似性に基づいて関連性の高いラグジュアリー海辺物件を返すかもしれませんが、それらはフロリダ州マイアミではなく、カリフォルニアやカリブ海など、海へのアクセスがある他の場所にある可能性があります。この制限は、セマンティック検索が正確な属性の一致よりも概念的な類似性を優先するためです。ユーザーがセマンティックな理解(ラグジュアリー、オーシャンビュー)と正確なフィルタリング(フロリダ州マイアミ)の両方を必要とする場合、セマンティック検索のみ reliance すると最適でない結果が生じます。ここでハイブリッド検索が不可欠となります。これは、自然言語記述のセマンティックな理解と、位置情報、日付、特定のメタデータといった構造化された属性に対するテキストベースのフィルタリングの精度を組み合わせます。これに対処するため、以下の両方を実行するハイブリッド検索アプローチを紹介します:
- 自然言語の記述を理解し、意味的に類似したコンテンツを検出するためのセマンティック検索(Semantic search)
- 場所、日付、識別子などの構造化属性に対して正確な一致を可能にするテキストベース検索(Text-based search)
ユーザーが検索フレーズを入力すると、大規模言語モデル(LLM)はまずクエリを分析して特定の属性(例:場所)を特定し、検索可能な値にマッピングします(例えば、「Northern Michigan」→「MI」)。抽出された属性は、セマンティック類似度スコアリングと組み合わせてフィルターとして使用され、結果が概念的に関連するとともにユーザーの要件に正確に一致することを保証します。以下の表は、文脈として明確なテキストのホテル記述を提供したセマンティック検索フローの簡略化された表示を示しています:
ベクトルストアデータ:
hotel-1
Description: The Artisan Loft hotel anchors the corner of Green and Randolph Streets in Big City’s bustling Southwest Loop, occupying a thoughtfully renovated 1920s brick warehouse that celebrates the neighborhood’s industrial heritage. Guests find themselves mere steps from the famed Restaurant Row, with acclaimed dining spots and trendy boutiques dotting the surrounding blocks.
Description Vector: […]
Location: Big City, USA
hotel-2
説明: 荒々しい崖の上に位置し、ビッグサーの劇的な海岸線を一望する「ザ・サイプレスヘイブン」は、大地そのものから切り出されたかのように景観に溶け込んでいます。この静かな42室の聖域は、生きた屋根庭園、床から天井までの窓、地元の石や再生レッドウッドなどの天然素材を用いることで、周囲の環境とシームレスに調和しています。各広々としたスイートには太平洋を臨むプライベートテラスがあり、客は日本製の檜風呂に浸かりながら渡り鳥のクジラを目撃することができます。
説明ベクトル: […]
場所: ビーチシティ、USA
hotel-3
説明: バークシャーの郊外にある数百年の歴史を持つカエデの森に佇む「ウッドランドヘイブンロッジ」は、贅沢さと mindful なシンプルさが交差する静かな逃避先を提供します。19世紀の屋敷を改装したこの施設には、メインハウスと4棟の別荘に分かれた28室が用意されており、それぞれに周囲の木々をフレームのように取り込む床から天井までの窓と回縁(ラップアラウンドポーチ)が備わっています。
説明ベクトル: […]
場所: クワイエットシティ、USA
hotel-4
説明: 中央都市の賑やかな中心街に位置するスカイラインオアシスホテルは、ラグジュアリーとモダニズムの象徴です。この45階建てのガラスと鋼鉄のタワーからは、都市の象徴的なスカイラインや近くの中央川を見渡せる絶景が広がります。500室のエレガントに装飾された客室とスイートがあり、上質な都市体験を求めるビジネス旅行者や観光客に対応しています。ホテルには屋上のインフィニティプール、ミシュラン星付きレストラン、最先端のフィットネスセンターを備えています。立地は優れており、現代美術館、中央都市オペラハウス、活気あふれるリバーフロント地区など、中央都市の主要な観光名所まで徒歩圏内です。
説明ベクトル: […]
場所: 中央都市、米国
検索フレーズ
海沿いのホテルを探しています
検索結果
hotel-2
検索例:
- 検索フレーズ: 「海沿いのホテルを探しています」
- セマンティック検索結果: hotel-2 (ザ・サイプレスヘイブン)
ハイブリッド検索例:
- 検索フレーズ:「セントラルシティの中心部にある、素敵なレストランがあるホテルを探しています」
- ハイブリッド検索結果:hotel-4(意味的な関連性と正確な位置の両方を考慮した最良の一致)
ハイブリッド検索の実装に関する詳細については、Amazon Bedrock Knowledge Bases のハイブリッド検索に関するブログ記事を参照してください。
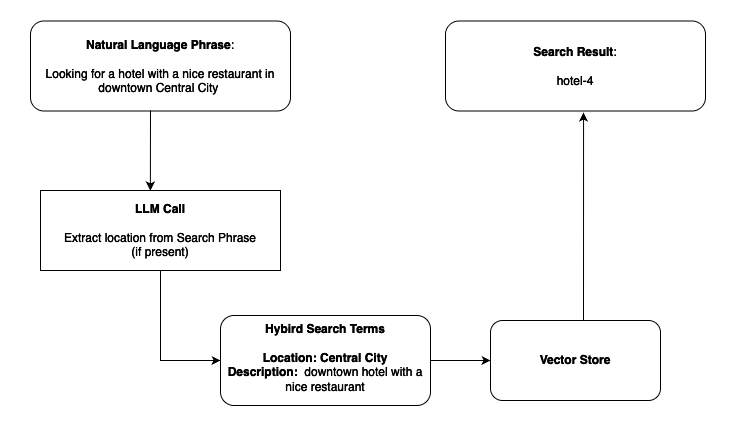
エージェントベースのソリューションの紹介
ユーザーが多様なニーズを持つホテル検索シナリオを考えてみましょう。あるユーザーは「居心地の良いホテルを探して」と尋ねる場合、「居心地が良い」という言葉の意味的な理解が必要です。別のユーザーは「マイアミにあるホテルを探して」と要求する場合、正確な位置によるフィルタリングが必要です。さらに別のユーザーは「マイアミにある高級なビーチフロントホテルを探して」と望む場合、これら二つのアプローチを同時に必要とします。固定されたワークフローを持つ従来の RAG(Retrieval-Augmented Generation:検索拡張生成)実装では、これらの多様な要件に動的に対応できません。私たちのシナリオでは、複数のデータソースを組み合わせ、クエリの特徴に基づいて検索戦略を動的に調整できるカスタム検索ロジックが求められます。エージェントベースのアプローチは、この柔軟性を提供します。LLM(Large Language Model:大規模言語モデル)自体が、各クエリを分析し適切なツールを選択することで、最適な検索戦略を決定します。
エージェントとは何か?
エージェントベースのシステムは、LLM(大規模言語モデル)が問題解決に必要な一連のアクションを決定するため、優れた適応性を提供します。これにより、動的な意思決定ルーティング、インテリジェントなツール選択、自己評価を通じた品質管理が可能になります。次のセクションでは、Amazon Bedrock、Amazon Bedrock AgentCore、Strands Agents、および Amazon OpenSearch を使用して、セマンティック検索とテキストベースの検索の両方を利用する生成型 AI エージェントアシスタントを実装する方法を示します。
アーキテクチャの概要
図 1 は、インテリジェント検索アシスタントに使用できる現代的なサーバーレスアーキテクチャを示しています。これは、Amazon Bedrock の基盤モデル、Amazon Bedrock AgentCore(エージェントのオーケストレーション用)、および Amazon OpenSearch Serverless(ハイブリッド検索機能用)を組み合わせたものです。
クライアントインタラクションレイヤー** クライアントアプリケーションは、Amazon API Gateway を介してシステムと対話します。これはユーザーリクエストに対する安全でスケーラブルなエントリポイントを提供します。「北ミシガン州のビーチフロントホテルを探して」のような質問をユーザーが投げかけると、リクエストは API Gateway を経由して Amazon Bedrock AgentCore にフローします。
Amazon Bedrock AgentCore によるエージェントオーケストレーション** Amazon Bedrock AgentCore は、完全なエージェントのライフサイクルを管理し、ユーザー、LLM、利用可能なツール間のやり取りを調整するオーケストレーションエンジンとして機能します。AgentCore は、推論、アクション、観察の継続的なサイクルであるエージェントループを実装しており、ここでエージェントは:
- Bedrockの基盤モデルを使用して、ユーザーのクエリを分析する
- クエリの要件に基づいて呼び出すべきツールを決定する
- 抽出されたパラメータを用いて、適切なハイブリッド検索ツールを実行する
- 結果を評価し、追加のアクションが必要かどうかを判断する
- 統合された情報でユーザーに応答する
このプロセス全体を通じて、Amazon Bedrock Guardrailsがコンテンツの安全性とポリシー準拠を強制し、適切な応答を維持します。
OpenSearch Serverlessを用いたハイブリッド検索**** 本アーキテクチャは、Amazon OpenSearch Serverlessをベクトルストアおよび検索エンジンとして統合しています。OpenSearchは、意味的な理解のためのベクトル化された埋め込み(vectorized embeddings)と、正確なフィルタリングのための構造化テキストフィールドの両方を保存します。このアプローチが、当社のハイブリッド検索方式を支えています。エージェントがハイブリッド検索ツールを呼び出す際、OpenSearchは以下の要素を組み合わせたクエリを実行します。
- 概念的な理解のためのベクトル類似性を用いた意味的マッチング
- 場所や設備といった正確な制約条件のためのテキストベースのフィルタリング
モニタリングとセキュリティ**** 本アーキテクチャには、システムの性能と使用パターンを監視するためのAmazon CloudWatchが含まれています。AWS IAMは、各コンポーネントにわたるアクセス制御とセキュリティポリシーを管理します。
なぜこのアーキテクチャなのか?**** このサーバーレス設計は、以下の主要な利点を提供します。
- リアルタイムの対話型インタラクションに対する低レイテンシ応答
- 手動介入なしで変動するワークロードを処理するための自動スケーリング
- アイドル状態のインフラストラクチャを持たない従量課金制によるコスト効率性
- 組み込みのモニタリング、ログ記録、セキュリティ機能により本番環境での使用に耐えうる状態
AgentCoreのオーケストレーション機能とOpenSearchのハイブリッド検索機能を組み合わせることで、アシスタントはユーザーの意図に基づいて検索戦略を動的に適応させることができます。これは、固定されたRAG(Retrieval-Augmented Generation)パイプラインでは実現できないことです。
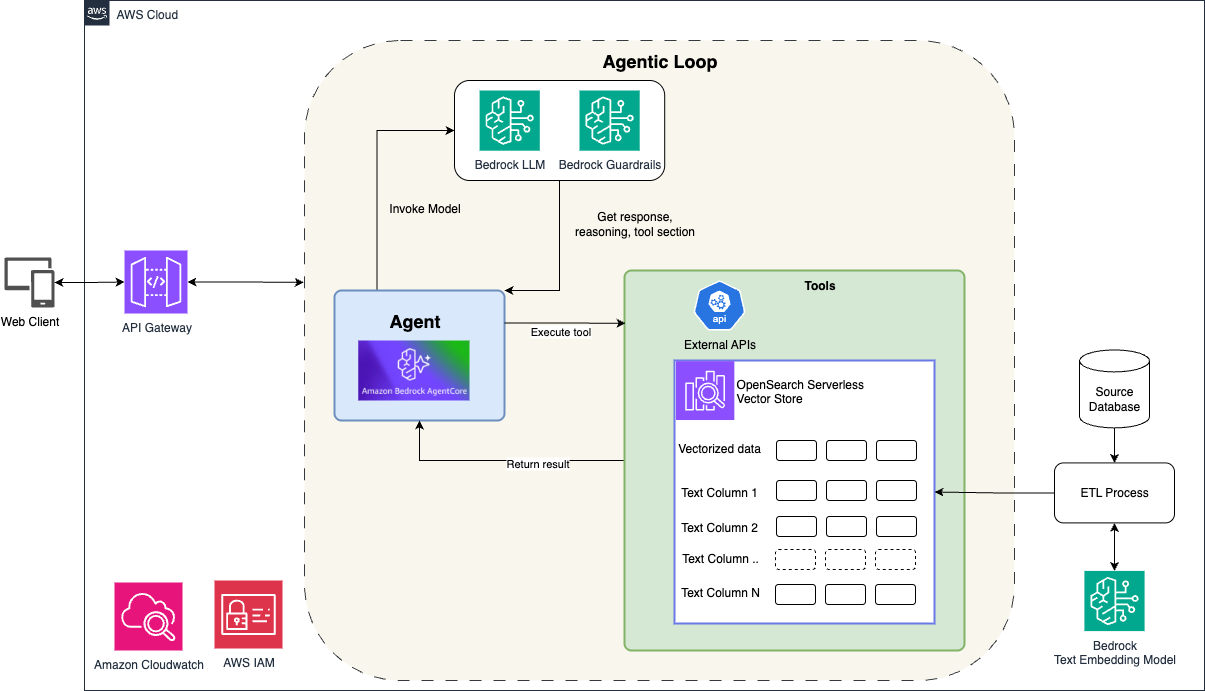
図1
図注:この文書で提供されているコードサンプルおよびアーキテクチャアーティファクトは、デモンストレーションと参照目的のみを意図したものであり、本番環境での使用には適していません。
StrandsおよびAmazon Bedrock AgentCoreを用いた実装
ハイブリッド検索エージェントを構築するために、私たちはStrandsというオープンソースのAIエージェントフレームワークを使用します。これは、ツール呼び出し機能を持つLLM(Large Language Model)ベースのアプリケーションの開発を簡素化するものです。Strandsを使用することで、ユーザークエリに基づいてエージェントがインテリジェントに呼び出すことができる「ツール」として、私たちのハイブリッド検索関数を定義することができます。Strandsのアーキテクチャとパターンに関する包括的な詳細については、Strandsドキュメントを参照してください。
以下が、ハイブリッド検索ツールを定義する方法です:
from strands import tool
@tool
def hybrid_search(query_text: str, country: str = None, city: str = None):
"""
意味的な理解と場所によるフィルタリングを組み合わせたハイブリッド検索を実行します。
ユーザーが記述的な好みと場所の両方を提供した場合、エージェントはこれ呼び出します。
Args:
query_text: 検索対象の自然言語による説明
country: オプションの国フィルター
city: オプションの都市フィルター
"""
# 意味的検索用の埋め込みを生成
vector = generate_embeddings(query_text)
# ベクトル類似度とテキストフィルターを組み合わせたハイブリッドクエリを構築
query = {
"bool": {
"must": [
{"knn": {"embedding_field": {"vector": vector, "k": 10}}}
],
"filter": []
}
}
# 提供された場合、場所フィルターを追加
if country:
query["bool"]["filter"].append({"term": {"country": country}})
if city:
query["bool"]["filter"].append({"term": {"city": city}})
# OpenSearch 内で検索を実行
response = opensearch_client.search(index="hotels", body=query)
return format_results(response)
tools を定義したら、Amazon Bedrock AgentCore と統合してデプロイおよびランタイムのオーケストレーションを行います。Amazon Bedrock AgentCore を使用すると、任意のフレームワークとモデルを使用して、スケーラブルに高効果なエージェントを安全にデプロイおよび運用できます。これは、エージェントを安全にスケーリングするための専用インフラストラクチャと、信頼性の高いエージェントを運用するための制御機能を提供します。
Strands と Amazon Bedrock AgentCore の統合に関する詳細な情報については、AgentCore-Strands 統合チュートリアルをご覧ください。
ハイブリッド検索の実装の詳細
当 AI アシスタント ソリューションの主要な差別化要因は、高度なハイブリッド検索機能です。多くの RAG(Retrieval-Augmented Generation:取得強化生成)実装が意味検索のみ relies しているのに対し、当社のアーキテクチャはこれを超えています。私たちは OpenSearch の全機能を最大限に活用し、意味検索、テキストベースの検索、およびハイブリッド検索を単一の効率的なクエリ内で実行可能にしました。以下のセクションでは、この実装の技術的な詳細について解説します。
2 本柱の実装 私たちのハイブリッド検索実装は、以下の2つの基本的なコンポーネントに基づいています:最適化されたデータ ストレージと多様なクエリ処理。
1. 最適化されたデータ ストレージ
効率的なハイブリッド検索において、データ ストレージへのアプローチは重要です。
データの分類: 私たちはデータを体系的に2つの主要なタイプに分類しています:
意味検索の候補:これには、詳細な説明、コンテキスト、および解説が含まれます。これらのコンテンツは、理解を深める
原文を表示
Agentic generative AI assistants represent a significant advancement in artificial intelligence, featuring dynamic systems powered by large language models (LLMs) that engage in open-ended dialogue and tackle complex tasks. Unlike basic chatbots, these implementations possess broad intelligence, maintaining multi-step conversations while adapting to user needs and executing necessary backend tasks.
These systems retrieve business-specific data in real-time through API calls and database lookups, incorporating this information into LLM-generated responses or providing it alongside them using predefined standards. This combination of LLM capabilities with dynamic data retrieval is known as Retrieval-Augmented Generation (RAG).
For example, an agentic assistant handling hotel booking would first query a database to find properties that match the guest’s specific requirements. The assistant would then make API calls to retrieve real-time information about room availability and current rates. This retrieved data can be handled in two ways: either the LLM can process it to generate a comprehensive response, or it can be displayed alongside an LLM-generated summary. Both approaches allow guests receive precise, current information that’s integrated into their ongoing conversation with the assistant.
In this post, we show how to implement a generative AI agentic assistant that uses both semantic and text-based search using Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents and Amazon OpenSearch.
Information retrieval approaches in RAG systems
Generally speaking, information retrieval supporting RAG capabilities in agentic generative AI implementations revolves around real-time querying of the backend data sources or communicating with an API. The responses are then factored into the subsequent steps performed by the implementation. From a high-level system design and implementation perspective, this step is not specific to generative AI-based solutions: Databases, APIs, and systems relying on integration with them have been around for a long time. There are certain information retrieval approaches that have emerged alongside agentic AI implementations, most notably, semantic search-based data lookups. They retrieve data based on the meaning of the search phrase as opposed to keyword or pattern lexical similarity. Vector embeddings are precomputed and stored in vector databases, enabling efficient similarity calculations at query time. The core principle of Vector Similarity Search (VSS) involves finding the closest matches between these numerical representations using mathematical distance metrics such as cosine similarity or Euclidean distance. These mathematical functions are particularly efficient when searching through large corpora of data because the vector representations are precomputed. Bi-encoder models are commonly used in this process. They separately encode the query and documents into vectors, enabling efficient similarity comparisons at scale without requiring the model to process query-document pairs together. When a user submits a query, the system converts it into a vector and searches for content vectors positioned closest to it in the high-dimensional space. This means that even if exact keywords don’t match, the search can find relevant results based on conceptual semantic similarity. Moreover, in situations where search terms are lexically but not semantically close to entries in the dataset, semantic similarity search will “prefer” semantically similar entries.
For example, given the vectorized dataset: [“building materials”, “plumbing supplies”, “2×2 multiplication result”], the search string “2×4 lumber board” will most likely produce “building materials” as the top matching candidate. Combining semantic search with LLM-driven agents supports natural language alignment across the user-facing and backend data retrieval components of the solution. LLMs process natural language Input provided by the user while semantic search capabilities allow for data retrieval based on the natural language Input formulated by LLMs depending on the end user – agent communication cadence.
The challenge: When semantic search alone isn’t enough
Consider a real-world scenario: A customer is searching for a hotel property and wants to find “a luxury hotel with ocean views in Miami, Florida.” Semantic search excels at understanding concepts like “luxury” and “ocean views,” it may struggle with precise location matching. The search might return highly relevant luxury oceanfront properties based on semantic similarity, but these could be in California, the Caribbean, or anywhere else with ocean access, not specifically in Miami as requested. This limitation arises because semantic search prioritizes conceptual similarity over exact attribute matching. In cases where users need both semantic understanding (luxury, ocean views) and precise filtering (Miami, Florida), relying solely on semantic search produces suboptimal results. This is where hybrid search becomes essential. It combines the semantic understanding of natural language descriptions with the precision of text-based filtering on structured attributes like location, dates, or specific metadata. To address this, we introduce a hybrid search approach that performs both:
- Semantic search to understand natural language descriptions and find semantically similar content
- Text-based search to facilitate precise matching on structured attributes like locations, dates, or identifiers
When a user provides a search phrase, an LLM first analyzes the query to identify specific attributes (such as location) and maps them to searchable values (for example, “Northern Michigan” → “MI”). These extracted attributes are then used as filters in conjunction with semantic similarity scoring, making sure that results are both conceptually relevant and precisely matched to the user’s requirements. The following tables provide a simplified view of the semantic search flow with clear text hotel descriptions provided for context:
Vector store data:
hotel-1
Description: The Artisan Loft hotel anchors the corner of Green and Randolph Streets in Big City’s bustling Southwest Loop, occupying a thoughtfully renovated 1920s brick warehouse that celebrates the neighborhood’s industrial heritage. Guests find themselves mere steps from the famed Restaurant Row, with acclaimed dining spots and trendy boutiques dotting the surrounding blocks.
Description Vector: […]
Location: Big City, USA
hotel-2
Description: Perched on a rugged cliff overlooking the dramatic coastline of Big Sur, The Cypress Haven emerges from the landscape as if it were carved from the earth itself. This intimate 42-room sanctuary seamlessly integrates into its surroundings with living roof gardens, floor-to-ceiling windows, and natural materials including local stone and reclaimed redwood. Each spacious suite features a private terrace suspended over the Pacific, where guests can spot migrating whales while soaking in Japanese cedar ofuro tubs.
Description Vector: […]
Location: Beach City, USA
hotel-3
Description: Nestled in a centuries-old maple forest just outside the Berkshires, Woodland Haven Lodge offers an intimate escape where luxury meets mindful simplicity. This converted 19th-century estate features 28 thoughtfully appointed rooms spread across the main house and four separate cottages, each with wraparound porches and floor-to-ceiling windows that frame the surrounding woodlands.
Description Vector: […]
Location: Quiet City, USA
hotel-4
Description: Nestled in the heart of Central City’s bustling downtown district, the Skyline Oasis hotel stands as a beacon of luxury and modernity. This 45-story glass and steel tower offers breathtaking panoramic views of the city’s iconic skyline and the nearby Central River. With 500 elegantly appointed rooms and suites, the Skyline Oasis caters to both business travelers and tourists seeking a premium urban experience. The hotel boasts a rooftop infinity pool, a Michelin-starred restaurant, and a state-of-the-art fitness center. Its prime location puts guests within walking distance of Central City’s major attractions, including the Museum of Modern Art, the Central City Opera House, and the vibrant Riverfront District.
Description Vector: […]
Location: Central City, USA
Search Phrase
Looking for a hotel by the ocean
Search Results
hotel-2
Search example:
- Search phrase: “Looking for a hotel by the ocean”
- Semantic search result: hotel-2 (The Cypress Haven)
Hybrid search example:
- Search phrase: “Looking for a hotel with a nice restaurant in downtown Central City”
- Hybrid search result: hotel-4 (best match considering both semantic relevance and precise location)
For more details on hybrid search implementations, refer to the Amazon Bedrock Knowledge Bases hybrid search blog post.
Introducing an agent-based solution
Consider a hotel search scenario where users have diverse needs. One user might ask “find me a cozy hotel,” requiring semantic understanding of “cozy.” Another might request “find hotels in Miami,” needing precise location filtering. A third might want “a luxury beachfront hotel in Miami,” requiring both approaches simultaneously. Traditional RAG implementations with fixed workflows cannot adapt dynamically to these varying requirements. Our scenario demands custom search logic that can combine multiple data sources and dynamically adapt retrieval strategies based on query characteristics. An agent-based approach provides this flexibility. The LLM itself determines the optimal search strategy by analyzing each query and selecting the appropriate tools.
Why agents?
Agent-based systems offer superior adaptability because the LLM determines the sequence of actions needed to solve problems, enabling dynamic decision routing, intelligent tool selection, and quality control through self-evaluation. The following sections show how to implement a generative AI agentic assistant that uses both semantic and text-based search using Amazon Bedrock, Amazon Bedrock AgentCore, Strands Agents and Amazon OpenSearch.
Architecture overview
Figure 1 shows a modern, serverless architecture that you can use for an intelligent search assistant. It combines the foundation models in Amazon Bedrock, Amazon Bedrock AgentCore (for agent orchestration), and Amazon OpenSearch Serverless (for hybrid search capabilities).
Client interaction layer** Client applications interact with the system through Amazon API Gateway, which provides a secure, scalable entry point for user requests. When a user asks a question like “Find me a beachfront hotel in Northern Michigan,” the request flows through API Gateway to Amazon Bedrock AgentCore.
Agent orchestration with Amazon Bedrock AgentCore**** Amazon Bedrock AgentCore serves as the orchestration engine, managing the complete agent lifecycle and coordinating interactions between the user, the LLM, and available tools. AgentCore implements the agentic loop—a continuous cycle of reasoning, action, and observation—where the agent:
- Analyzes the user’s query using Bedrock’s foundation models
- Decides which tools to invoke based on the query requirements
- Executes the appropriate hybrid search tool with extracted parameters
- Evaluates the results and determines if additional actions are needed
- Responds to the user with synthesized information
Throughout this process, Amazon Bedrock Guardrails enforce content safety and policy adherence, maintaining appropriate responses.
Hybrid search with OpenSearch Serverless**** The architecture integrates Amazon OpenSearch Serverless as the vector store and search engine. OpenSearch stores both vectorized embeddings (for semantic understanding) and structured text fields (for precise filtering). This approach supporting our hybrid search approach. When the agent invokes the hybrid search tool, OpenSearch executes queries that combine:
- Semantic matching using vector similarity for conceptual understanding
- Text-based filtering for precise constraints like location or amenities
Monitoring and security**** The architecture includes Amazon CloudWatch for monitoring system performance and usage patterns. AWS IAM manages access control and security policies across components.
Why this architecture?**** This serverless design provides several key advantages:
- Low-latency responses for real-time conversational interactions
- Auto-scaling to handle varying workloads without manual intervention
- Cost-effectiveness through pay-as-you-go pricing with no idle infrastructure
- Production-ready with built-in monitoring, logging, and security features
The combination of the AgentCore orchestration capabilities with hybrid search functionality of OpenSearch allows our assistant to dynamically adapt its search strategy based on user intent, something that rigid RAG pipelines cannot achieve.
Figure 1
Figure Note: The code samples and architecture artifacts provided in this document are intended for demonstration and reference purposes only and are not production-ready.
Implementation with Strands and Amazon Bedrock AgentCore
To build our hybrid search agent, we use Strands, an open-source AI agent framework that simplifies developing LLM-powered applications with tool-calling capabilities. Strands allow us to define our hybrid search function as a “tool” that the agent can intelligently invoke based on user queries. For comprehensive details on Strands architecture and patterns, see the Strands documentation.
Here’s how we define our hybrid search tool:
from strands import tool
@tool
def hybrid_search(query_text: str, country: str = None, city: str = None):
"""
Performs hybrid search combining semantic understanding with location filtering.
The agent calls this when users provide both descriptive preferences and location.
Args:
query_text: Natural language description of what to search for
country: Optional country filter
city: Optional city filter
"""
# Generate embeddings for semantic search
vector = generate_embeddings(query_text)
# Build hybrid query combining vector similarity and text filters
query = {
"bool": {
"must": [
{"knn": {"embedding_field": {"vector": vector, "k": 10}}}
],
"filter": []
}
}
# Add location filters if provided
if country:
query["bool"]["filter"].append({"term": {"country": country}})
if city:
query["bool"]["filter"].append({"term": {"city": city}})
# Execute search in OpenSearch
response = opensearch_client.search(index="hotels", body=query)
return format_results(response)
Once we’ve defined our tools, we integrate them with Amazon Bedrock AgentCore for deployment and runtime orchestration. Amazon Bedrock AgentCore enables you to deploy and operate highly effective agents securely at scale using any framework and model. It provides purpose-built infrastructure to securely scale agents and controls to operate trustworthy agents.
For detailed information about integrating Strands with Amazon Bedrock AgentCore, see the AgentCore-Strands integration tutorial.
Hybrid search implementation deep dive
A key differentiator of our AI assistant solution is its advanced hybrid search capability. While many RAG implementations rely solely on semantic search, our architecture extends beyond this. We’ve used the full potential of OpenSearch, enabling semantic, text-based, and hybrid searches, all within a single, efficient query. The following sections explore the technical details of this implementation.
The two-pronged implementation**** Our hybrid search implementation is built on two fundamental components: optimized data storage and versatile query handling.
1. Optimized data storage
The approach to data storage is important for efficient hybrid search.
Data categorization**: We systematically categorize our data into two main types:
Semantic search candidates: This includes detailed descriptions, contexts, and explanations – content that benefits from understa
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み