LLM推論向上のための推論時スケーリング手法の分類
Sebastian Raschka は、推論時の計算リソース投入による LLM の推論能力向上手法を体系的に分類し、最新の研究動向と実装の知見を提供している。
キーポイント
推論時スケーリングの体系的分類
Chain-of-Thought, Self-Consistency, Best-of-N, Rejection Sampling, Search Over Solution Paths など、推論時に計算リソースを追加投入する主要な手法を明確にカテゴリ化している。
最新研究と再帰的言語モデルの動向
過去数ヶ月間に発表された最新の論文や、再帰的言語モデル(Recursive Language Models)を含む新しいアプローチについて言及し、分野の進化を追跡している。
実証実験に基づく知見の共有
著者自身の書籍執筆過程で実施した数千回のハイパーパラメータ調整実験の結果から、特定の手法が精度を 15% から 52% に向上させるなどの具体的な知見を提供している。
産業利用と研究の架け橋
主要な LLM プロバイダーがすでに採用している手法の学術的側面を整理し、実装コードの公開計画を通じて実践的な導入を支援する内容となっている。
推論時スケーリングの定義と歴史
推論時に計算リソースや時間を追加投入してモデル性能を向上させる手法の総称であり、アンサンブル学習などの古典的機械学習にもその萌芽が見られる。
トレーニングと推論の両立による最適化
モデルの精度向上にはトレーニングリソース(データ量やモデルサイズ)を増やすだけでなく、推論時のスケーリングを併用することでさらに効果が高まる。
本記事の焦点範囲
本稿ではモデルの重みを変更しない「トレーニングフリー」な手法に限定し、推論時スケーリング技術についてのみ詳述する。
影響分析・編集コメントを表示
影響分析
この記事は、LLM の推論能力を向上させるための「計算リソース投入」戦略を体系的に整理し、研究者やエンジニアが最新の手法を選択・実装するための重要な指針となる。特に、単なる理論の列挙ではなく、著者自身の膨大な実験データに基づく具体的な数値(精度向上率)を示している点で、現場での実装判断や研究方針決定に即座に役立つ価値がある。
編集コメント
推論コストと精度のトレードオフを最適化するための手法論として、実務家にとって非常に示唆に富む内容です。特に著者の実験データに基づく具体的な数値は、手法選定の参考として貴重です。
推論時間スケーリングのカテゴリー:LLM推論能力向上に向けて
推論時間スケーリングのカテゴリー:LLM推論能力向上に向けて
 Sebastian Raschka, PhD2026年1月24日∙ 有料会員向け321シェア推論スケーリングは、デプロイされたLLMの回答品質と精度を向上させる最も効果的な方法の一つとなっています。
Sebastian Raschka, PhD2026年1月24日∙ 有料会員向け321シェア推論スケーリングは、デプロイされたLLMの回答品質と精度を向上させる最も効果的な方法の一つとなっています。
その考え方は単純明快です。もし私たちが、もう少し多くの計算リソースと、推論時(モデルを使ってテキストを生成する時)にもう少し多くの時間を費やすことを厭わないなら、モデルにより良い答えを生成させることができるのです。
今日、主要なLLMプロバイダーはすべて、何らかの形の推論時間スケーリングに依存しています。また、これらの手法に関する学術文献も大きく増えています。
今年3月、私は推論スケーリングの状況の概要を書き、いくつかの初期技術をまとめました。
 LLM推論モデル推論の現状
LLM推論モデル推論の現状
この記事では、以前の議論を一歩進め、さまざまなアプローチをより明確なカテゴリーに分類し、過去数ヶ月間に現れた最新の研究を紹介したいと思います。
『Build a Reasoning Model (From Scratch)』の推論スケーリングに関する完全な章を起草する過程で、私はこれらの手法の基本的な種類の多くを自分自身で試すことになりました。ハイパーパラメータチューニングを伴うと、これはすぐに数千回の実行に及び、章でより詳細に取り上げるべきアプローチを理解するために多くの思考と作業が必要でした。(章があまりにも大きくなったので、最終的には2つに分割し、両方とも現在早期アクセスプログラムで利用可能です。)
追記:私は特に、章(複数)の仕上がりに満足しています。基本モデルの精度を約15%から約52%まで向上させており、これまでの書籍の中で最もやりがいのある部分の一つとなっています。
以下に記すのは、最終的な章の流れには完全には合わなかったものの、それでも共有する価値のあるアイデア、メモ、論文の集まりです。
また、時間をかけてGitHubのボーナス資料により多くのコード実装を追加する予定です。
目次(概要)
推論時間スケーリング概要
連鎖的思考プロンプティング
自己一貫性
N個中ベストランキング
検証器を用いた棄却サンプリング
自己改善
解決経路の探索
結論、カテゴリー、組み合わせ
ボーナス:プロプライエタリLLMは何を使っているのか?
記事のウェブビューでは、左側のナビゲーションバーを使用して任意のセクションに直接ジャンプできます。
1. 推論時間スケーリング概要
推論時間スケーリング(推論計算スケーリング、テスト時間スケーリング、または単に推論スケーリングとも呼ばれる)は、推論時により多くの計算リソースと時間を割り当ててモデルの性能を向上させる手法の総称です。
この考え方は長い間存在しており、古典的な機械学習におけるアンサンブル手法は、推論時間スケーリングの初期の例と考えることができます。つまり、複数のモデルを使用することはより多くの計算リソースを必要としますが、より良い結果をもたらすことができます。
LLMの文脈においてさえ、この考え方は長い間存在していました。しかし、昨年OpenAIがo1発表ブログ記事の一つで推論時間スケーリングとトレーニングの関係図を示した際に、特に(再び)人気を博したことを覚えています(Learning to Reason with LLMs)。
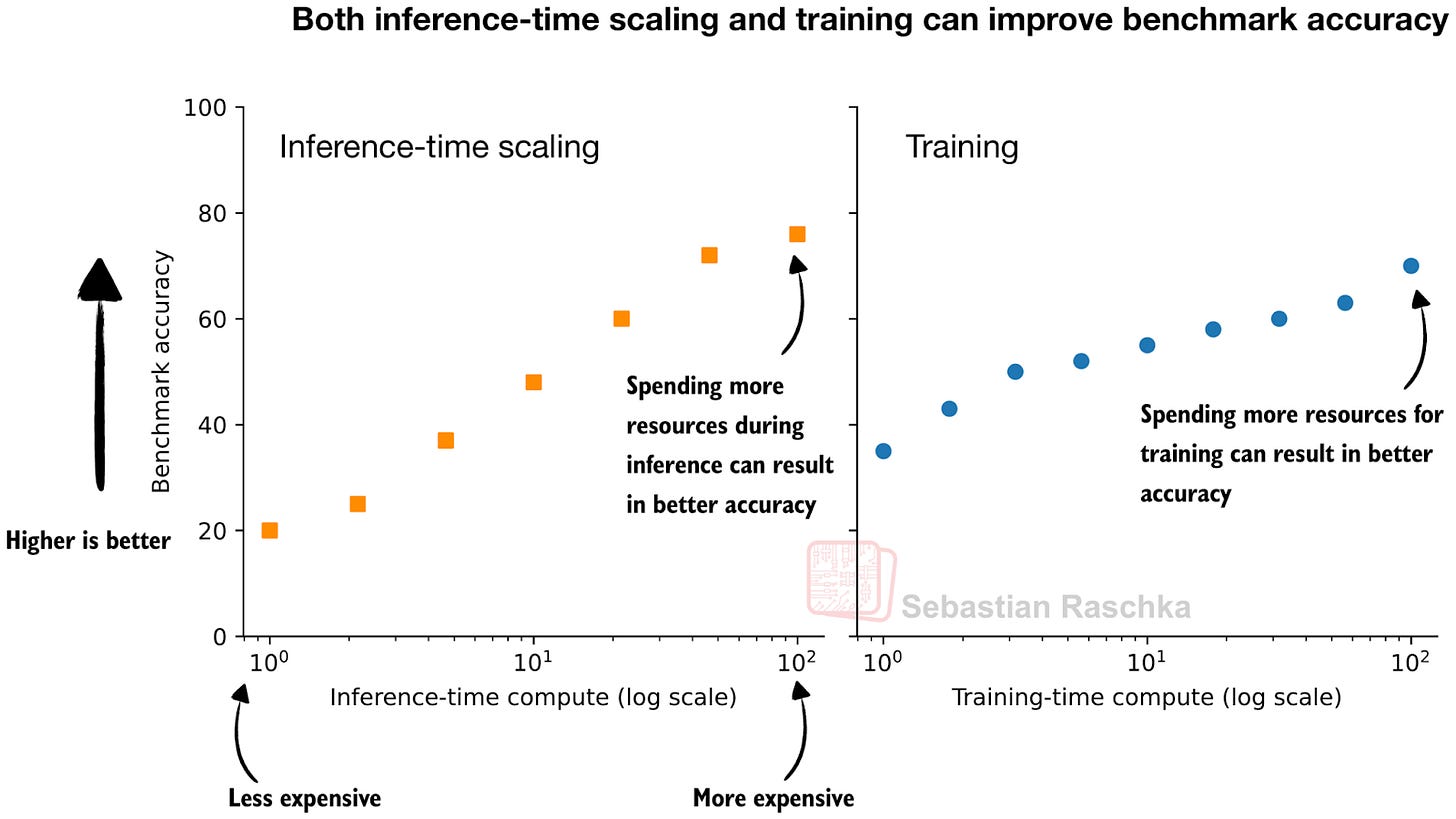 図1:推論時(左)とトレーニング時(右)に追加リソースを費やすことは、一般的にモデルの精度を向上させる。
図1:推論時(左)とトレーニング時(右)に追加リソースを費やすことは、一般的にモデルの精度を向上させる。
OpenAIのブログ投稿から引用したこの図は、LLMを改善するために使用できる2つの調整方法の背後にある考え方をうまく捉えていると思います。トレーニング時(より多くのデータ、より大きなモデル、より多くのまたはより長いトレーニング段階)または推論時に、より多くのリソースを費やすことができます。
実際には、実践的には両方を同時に行う方がさらに良いです:より強力なモデルをトレーニングし、追加の推論スケーリングを使用してそれをさらに良くするのです。
この記事では、図の左側の部分、すなわち推論時間スケーリング技術、つまりモデルの重みを変更しないトレーニング不要の技術にのみ焦点を当てます。
この投稿は有料購読者向けです。
原文を表示
Categories of Inference-Time Scaling for Improved LLM Reasoning
And an Overview of Recent Inference-Scaling Papers (Including Recursive Language Models)
Sebastian Raschka, PhDJan 24, 2026∙ Paid321ShareInference scaling has become one of the most effective ways to improve answer quality and accuracy in deployed LLMs.
The idea is straightforward. If we are willing to spend a bit more compute, and more time at inference time (when we use the model to generate text), we can get the model to produce better answers.
Every major LLM provider relies on some flavor of inference-time scaling today. And the academic literature around these methods has grown a lot, too.
Back in March, I wrote an overview of the inference scaling landscape and summarized some of the early techniques.
The State of LLM Reasoning Model Inference
In this article, I want to take that earlier discussion a step further, group the different approaches into clearer categories, and highlight the newest work that has appeared over the past few months.
As part of drafting a full book chapter on inference scaling for Build a Reasoning Model (From Scratch), I ended up experimenting with many of the fundamental flavors of these methods myself. With hyperparameter tuning, this quickly turned into thousands of runs and a lot of thought and work to figure out which approaches should be covered in more detail in the chapter itself. (The chapter grew so much that I eventually split it into two, and both are now available in the early access program.)
PS: I am especially happy with how the chapter(s) turned out. It takes the base model from about 15 percent to around 52 percent accuracy, which makes it one of the most rewarding pieces of the book so far.
What follows here is a collection of ideas, notes, and papers that did not quite fit into the final chapter narrative but are still worth sharing.
I also plan to add more code implementations to the bonus materials on GitHub over time.
Table of Contents (Overview)
Inference-Time Scaling Overview
Chain-of-Thought Prompting
Self-Consistency
Best-of-N Ranking
Rejection Sampling with a Verifier
Self-Refinement
Search Over Solution Paths
Conclusions, Categories, and Combinations
Bonus: What Do Proprietary LLMs Use?
You can use the left-hand navigation bar in the article’s web view to jump directly to any section.
- Inference-Time Scaling Overview
Inference-time scaling (also called inference-compute scaling, test-time scaling, or just inference scaling) is an umbrella term for methods that allocate more compute and time during inference to improve model performance.
This idea has been around for a long time, and one can think of ensemble methods in classic machine learning as an early example of inference-time scaling. I.e., using multiple models requires more compute resources but can give better results.
Even in LLM contexts, this idea has been around for a long time. However, I remember it became particularly popular (again) when OpenAI showed an inference-time scaling and training plot in one of their o1 announcement blog articles last year (Learning to Reason with LLMs).
Figure 1: Spending additional resources during inference (left) and training (right) generally improves the model’s accuracy.
I think this figure, adapted from OpenAI’s blog post, nicely captures the idea behind the two knobs we can use to improve LLMs. We can spend more resources during training (more data, bigger models, more or longer training stages) or inference.
Actually, in practice, it’s even better to do both at the same time: train a stronger model and use additional inference scaling to make it even better.
In this article, I only focus on the left part of the figure, inference-time scaling techniques, i.e., those training-free techniques that don’t change the model weights.
This post is for paid subscribers
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み