OpenAI が新 SOTA リアルタイム音声 API「GPT-Realtime-2」などを発表
OpenAI は、GPT-Realtime-2 を含む 3 つの新しいリアルタイム音声 API をリリースし、推論能力やツール使用、文脈理解において大幅な改善を遂げました。
キーポイント
GPT-Realtime-2 の性能向上と新機能
「最も知的な音声モデル」として位置づけられ、BBA で +15.2% の改善を達成。短語によるプレアム、並列ツール呼び出し、より自然な回復動作、および 32K から 128K へのコンテキスト拡張が実装されています。
専用翻訳・転写モデルの追加
GPT-Realtime-Translate と GPT-Realtime-Whisper が同時にリリースされ、70 以上の入力言語から 13 の出力言語へのストリーミング翻訳や、高精細な文字起こし機能をリアルタイムで提供します。
開発者向けの制御可能性とトーン調整
推論努力レベル(最小〜超高)の選択が可能になり、文脈に応じた冷静・共感的・陽気なトーンの調整や、専門用語の保持能力が強化されています。
GPT-Realtime-2 の高度な推論能力とコンテキスト拡張
「GPT-5 クラスの推論」を実現し、128K のコンテキストウィンドウをサポートすることで、複雑なツール操作や長時間の対話が可能になりました。
リアルタイム翻訳・文字起こし機能の追加
70 以上の言語から 13 言語へのライブ音声翻訳(GPT-Realtime-Translate)と、低遅延なストリーミング文字起こし(GPT-Realtime-Whisper)が利用可能になりました。
ベンチマークでの圧倒的な性能向上
Scale AI の評価では指示保持率が 36.7% から 70.8% に向上し、Artificial Analysis では推論タスクで 96.6% のスコアを記録しました。
性能と機能の大幅な向上
GPT-Realtime-2 は 128K トークンのコンテキストと GPT-5 クラスの推論能力を備え、会話中の中断処理やツール使用に対応するリアルタイム音声モデルです。
影響分析・編集コメントを表示
影響分析
このリリースは、音声 AI を単なるインターフェースから、複雑な推論とツール操作を自律的に行う「知的エージェント」へと進化させる転換点となります。特にコンテキストウィンドウの拡大と並列ツール呼び出し機能により、長時間かつ多段階にわたる複雑なタスクを処理する実用アプリケーションの開発が加速すると予想されます。
編集コメント
音声 AI のパラダイムが「会話の質」から「推論と実行能力」へとシフトしたことを示す画期的な発表です。開発者にとっては、より高度で信頼性の高いボイスエージェントを構築するための強力な基盤が整いました。
OpenAI は 3 ヶ月前に realtime-1.5 をリリースしましたが、これはまだ 4o ベースの知能(Big Bench Audio で +5% の向上)に基づいていたため、相対的には小さな出来事でした。しかし、今日の realtime-2 リリースにおける圧倒的な自信(BBA で +15.2% の向上)は明確に示されており、適切にもてはやされました。
ブログ記事が説明している通り、今回リリースされるのは 3 つのモデルで、これらを「音声入力・音声出力」「音声入力・音声出力(対話型)」と簡略化して捉えることができます。
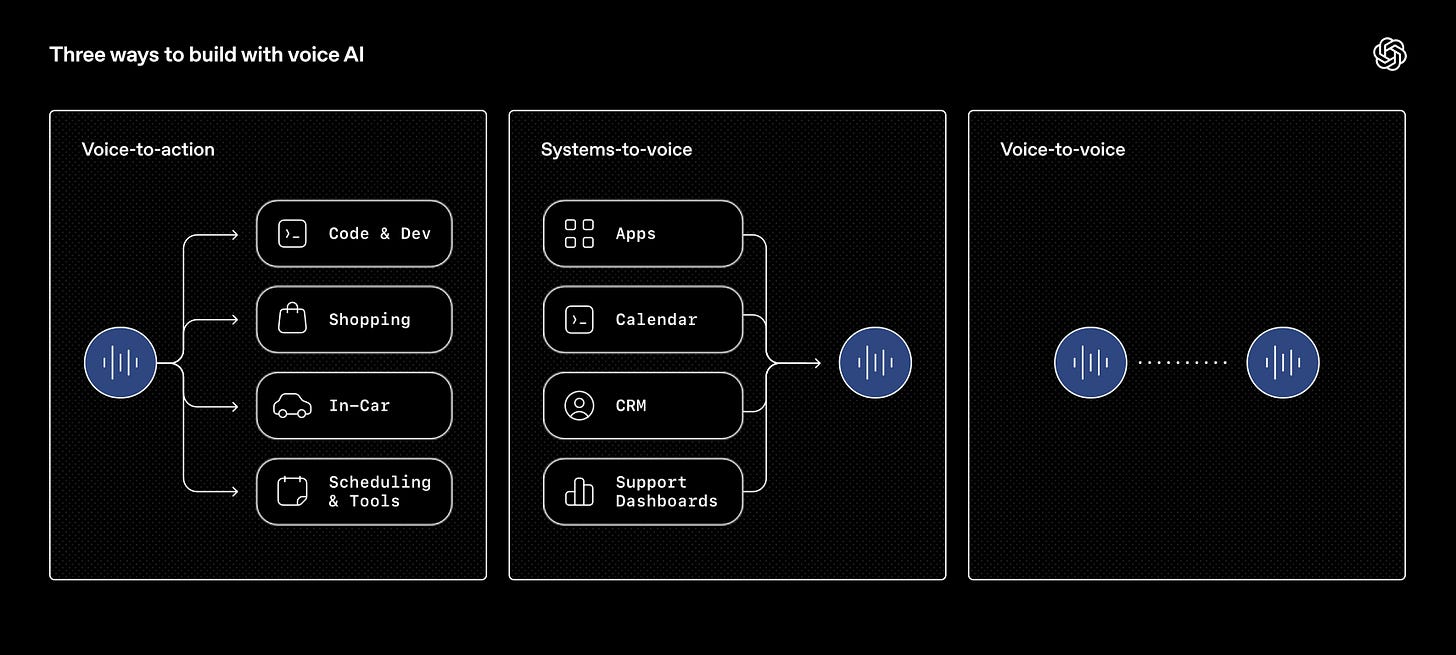
焦点は「音声の質」よりも、むしろ使いやすさにあります。要約すると以下の通りです。
事前フレーズ:開発者は、主要な応答の前に短いフレーズを有効化できます。例えば、「確認しますね」や「少しお待ちください」といった表現です。
並列ツール呼び出しとツールの透明性:モデルは複数のツールを同時に呼び出すことができ、「カレンダーを確認しています」「今すぐ検索しています」といったフレーズでその動作を音声化します。これにより、タスク完了中もエージェントが応答性を保つことができます。
回復機能の強化:モデルは「現在それがうまくいかないようです」などの表現を用いて、失敗したり破綻したりするのではなく、より滑らかに状況を回復できます。
より長いコンテキスト:32K → 128K
ドメイン理解の強化:専門用語、固有名詞、医療用語、その他の語彙をよりよく保持します。
制御可能なトーンと発話:文脈に応じて、冷静に、共感的に、あるいは前向きに話すなど、トーンをより適切に調整できます。
推論努力の調整可能化:開発者は、最小、低、中、高、超高の 5 つの推論レベルから選択できるようになりました(デフォルトは「低」)。
デモ動画では、メインスピーカーが他者と話している際に音声モデルがより適切にチューニングされ、割り込みが減っている様子が示されました:
2026 年 5 月 6 日〜7 日の AI ニュース。12 のサブレッド、544 件の Twitter、および Discord はさらに確認しました。AINews のウェブサイトでは過去のすべての号を検索できます。念のため、AINews は現在 Latent Space の一部となっています。メールの頻度を選択してオン/オフにできます!
AI Twitter リキャップ
トップストーリー:GPT-Realtime-2 と OpenAI 音声 AI コメント
何が起こったか
OpenAI は Realtime API にて、3 つの新しいストリーミング音声モデル「GPT-Realtime-2」「GPT-Realtime-Translate」「GPT-Realtime-Whisper」をリリースしました。OpenAI は GPT-Realtime-2 を「これまでで最も知的な音声モデル」と位置づけ、聴取・推論・割り込みへの対応・ツール使用・展開される会話の持続といった機能を備えたリアルタイム音声エージェントに「GPT-5 クラスの推論能力」をもたらすものとしています @OpenAI。補完的な 2 つのモデルはライブ音声翻訳と文字起こしを対象としており、GPT-Realtime-Translate は 70 以上の入力言語から 13 の出力言語へのストリーミング翻訳をサポートし、GPT-Realtime-Whisper は発話が生じる際にストリーミング形式で文字起こし/字幕を生成します @OpenAI, @OpenAIDevs。OpenAI によると、これらのモデルは現在 Realtime API で利用可能ですが、ChatGPT の音声機能に関するアップグレードはまだ未定です。「続報をお待ちください、準備中ですよ」と述べています @OpenAI。サム・アルトマン氏は今回の発表を行動様式の変化の文脈で捉え、ユーザーが大量のコンテキストを「吐き出す」必要がある際に AI との対話を音声で行う傾向が強まっていると指摘し、OpenAI はまた ChatGPT の音声機能についても改善を進めていると述べています @sama。
事実 vs 意見
事実に基づく記述 / OpenAI および評価者によって直接主張されている内容
モデルファミリー: GPT-Realtime-2, GPT-Realtime-Translate, GPT-Realtime-Whisper は、本日リアルタイム API で利用可能になりました @OpenAIDevs。
GPT-Realtime-2 の機能: 生産環境向けの音声エージェント向けに設計された推論志向のネイティブ音声入力・音声出力モデルです。ツールの使用やアクション実行、割り込みからの回復、より長い会話の維持が可能であり、OpenAI の表現によれば「GPT-5 クラスの推論能力」を備えています @OpenAI, @reach_vb.
コンテキストウィンドウ:コミュニティおよび OpenAI-dev のコメントによると、GPT-Realtime-2 音声エージェントのコンテキストは 128K と報告されています @reach_vb;Artificial Analysis は独立して、コンテキストウィンドウが 32K から 128K に増加し、最大出力トークン数は 32K であると報告しています @ArtificialAnlys。
翻訳:GPT-Realtime-Translate は、70 以上の入力言語から 13 の出力言語へのライブ音声翻訳をサポートしています @OpenAI, @reach_vb。
文字起こし:GPT-Realtime-Whisper は、キャプション、ノート、継続的な音声理解のためのリアルタイム API で低遅延ストリーミング文字起こしを提供します @OpenAIDevs。
プロンプト/制御:OpenAI は、推論の努力、前置き、ツールの動作、不明瞭な音声への対応、正確なエンティティの捕捉、長時間セッションにおける状態維持をカバーする音声プロンプトガイドを発表しました @OpenAIDevs。
独立したベンチマーク:Scale AI によると、GPT-Realtime-2 はその Audio MultiChallenge S2S リーダーボードで首位を獲得し、GPT-Realtime-1.5 と比較して指示保持率が 36.7% から 70.8% に向上し、音声編集やリアルタイム修復においても強力なパフォーマンスを示しました @ScaleAILabs。
独立したベンチマーク:Artificial Analysis は、Big Bench Audio の音声から音声への推論で 96.6%、Conversational Dynamics ベンチマークで 96.1% を達成し、高推論時の初回音声までの平均時間は 2.33 秒、最小推論時は 1.12 秒でした。また、音声料金は入力 1 時間あたり 1.15 ドル、出力 1 時間あたり 4.61 ドルで変更ありません @ArtificialAnlys, @ArtificialAnlys。
推論エフェクト制御:Artificial Analysis は、最小限、低、中、高、超高の調整可能な推論レベルを報告しており、デフォルトは低です @ArtificialAnlys。
エンタープライズ/製品評価:Glean によると、リアルタイム組織音声対話に関する内部評価において、GPT-Realtime-2 は前バージョンに対して有用性が相対的に 42.9% 向上したと報告しています @glean。Genspark は、その「Call for Me Agent」を GPT-Realtime-2 に移行し、有効な会話率が +26% 増加し、通話切断が減少したと述べています @genspark_ai。
意見・解釈・コメント
支持者たちは、この発表を音声エージェントにおける「大きな前進」と表現しました @sama、「完全なるリアルタイムの勝利」@reach_vb、そして複雑な音声エージェントにおいて「実際の業務」に耐えうる最初の音声対音声モデルであると評価しました @kwindla。
より慎重な見解:Simon Willison は、この発表が ChatGPT の音声モード自体がすでにアップグレードされたことを意味するものではないと指摘しています。ChatGPT のアップグレードは「まもなく来るだろう」という雰囲気です @simonw, @simonw。
インターフェースへの懐疑論:Will Depue は、オーディオを VR に例え、「頻繁に興奮を呼ぶが、歴史的にはインターフェースとして定着しにくい」と述べつつ、リアルタイムのツール使用、発話中の推論、ライブ翻訳といった機能が、ついに音声インターフェースを飛躍させる可能性のある機能であると主張しました @willdepue。
より広い UX への楽観論:複数のコメント投稿者が、音声は人間にとってより自然かつ帯域幅効率的であると位置づけ、@BorisMPower はジャ维斯(Jarvis)のような常時利用可能なコンピュータエージェントへの道筋と捉え、@willdepue は最終的にはさらに高帯域幅の脳コンピュータインターフェース(BCI: Brain-Computer Interface)によって置き換えられる可能性を示唆し、@iScienceLuvr も同様の見解を表明しました。
競争環境の文脈:イーロン・マスクは顧客サポート向けに Grok Voice を推進し @elonmusk、リアルタイム音声によるサポートやカスタマーサービス自動化が、現在では各研究機関間における競争の場となっていることを強調しました。
技術詳細とベンチマークデータ
GPT-Realtime-2
OpenAI の Realtime API @OpenAI を通じてリリースされた、ネイティブな音声対音声(speech-to-speech)/リアルタイム音声モデルです。
@OpenAI により、音声エージェント向けに「GPT-5 クラスの推論能力」を備えていると位置づけられています。
以下の機能を持つエージェントのために設計されています:
会話中に推論を行うこと、
ツールを使用したりアクションを実行すること、
割り込みに対応すること、
ユーザーが発話を修正または修復した際に回復すること、
拡張されたコンテキスト(context)によりより長いセッションを維持すること @OpenAI, @reach_vb。
報告されているコンテキスト長:32K から 128K トークンへ増加 @ArtificialAnlys。
報告されている最大出力:32K トークン @ArtificialAnlys。
Artificial Analysis により報告された入力:テキスト、オーディオ、画像 @ArtificialAnlys。
推論努力レベル:最小、低、中、高、超高;デフォルトは低 @ArtificialAnlys。
最初の音声までの時間(Time-to-first-audio):
推論レベルが最小の場合 1.12 秒、
推論レベルが高い場合 2.33 秒 @ArtificialAnlys。
価格設定:
オーディオ入力 1 時間あたり $1.15、
オーディオ出力 1 時間あたり $4.61、
Artificial Analysis によると従来モデルと比較して変更なし @ArtificialAnlys。
対話機能:主要な応答の前に短い前置き(例:「確認します」)をサポートし、ツール呼び出し中は音声による透明性(例:「カレンダーを確認中」)を提供します @ArtificialAnlys。
ベンチマーク
Scale AI Audio MultiChallenge S2S: GPT-Realtime-2 が第 1 位を獲得。GPT-Realtime-1.5 と比較して、指示保持率が 36.7% から 70.8% に改善(APR)。ユーザーがリアルタイムで発話を修正・訂正する際の音声編集能力も優れています @ScaleAILabs。
Artificial Analysis Big Bench Audio: GPT-Realtime-2 のハイバリアントは 96.6% を記録し、Gemini 3.1 Flash Live Preview High と同等であり、以前の最高結果よりも約 13% 上回っていると報告されています @ArtificialAnlys。
Justin Uberti は、Big Bench Audio における GPT-Realtime-1.5 に対する改善を 15 ポイントと要約し、ほぼ飽和状態に達していると指摘しました @juberti。
対話ダイナミクス / フルデュプレックスベンチサブセット: GPT-Realtime-2 のミニマルバリアントは 96.1% を記録し、ポーズ処理とターンテイクにおいて強みを発揮しています @ArtificialAnlys。
GPT-Realtime-Translate
70 以上の入力言語から 13 の出力言語へのライブストリーミング音声翻訳を提供します @OpenAI。
OpenAI の共同創設者である Greg Brockman は、リアルタイムの音声対音声翻訳は同社の設立初期から期待されていたアプリケーションであり、現在は誰でも構築に利用できるようになったと述べています @gdb。
Vimeo は、事前ロードされたキャプションなしでライブ吹き替えを実演し、翻訳が完全にリアルタイムで生成される様子を示しました @Vimeo。
Junling Zhang は新しいリアルタイム翻訳モデルを強調し、API の利用を推奨しています @jxnlco。
Boris Power は、ライブ翻訳は「実際に非常にうまく機能する」と述べ、@BorisMPower で定期的に使用することを計画しています。
GPT-Realtime-Whisper
OpenAI の @OpenAI では、話している人のストリーミング文字起こしを行い、リアルタイムの字幕、ノート、音声理解を実現しています。
Justin Uberti はこれを「リアルタイムストリーミング機能を備えた Whisper」と表現し、@juberti で新しいモデルを使用したデモを更新しました。
Uberti または、リアルタイムタイピングデモにおいて遅延と精度のトレードオフを露呈させるための遅延セレクターも構築しました @juberti。
製品統合とデモ
Glean: GPT-Realtime-2 を搭載したリアルタイム音声を実装し、組織コンテキストに基づいています。内部評価では、前バージョンと比較して有用性が相対的に 42.9% 向上したことが示されました @glean。
Vimeo: GPT-Realtime-Translate を使用したライブ吹き替えをデモンストレーションしました。翻訳はリアルタイムで生成され、事前ロードされた字幕はありません @Vimeo。
Genspark: Call for Me Agent を GPT-Realtime-2 にアップグレードしました。Genspark Realtime Voice が次期リリースです。より鋭い推論、厳格な指示の遵守、有効な会話率が 26% 向上し、通話切断が減少したと主張しています @genspark_ai。
Gradient Bang / game-agent デモ: Kyle Windland は、GPT-Realtime-2 が「実際の作業」を行う音声エージェントにとって十分な性能を持つ最初の OpenAI 音声対音声モデルであると述べました。これは、ツール呼び出しやサブエージェントを備えた複雑なエージェントにおける船載 AI(Ship AI)として示されました @kwindla。
音声制御型マーケットダッシュボード:レヴィン・スタンリーは、GPT-Realtime-2 が意図に基づいてインターフェースを操作するデモを実施しました。「Apple に焦点を当てて」「過去 30 日間のパフォーマンスはどうだった?」「戻る」といった指示に対し、リアルタイムの割り込みと推論が UI ループを「ナビゲーション」から「方向付け」へと変えるものであると主張しています @levinstanley。
リアルタイムデモ:ジャスティン・ウベルティは GPT-Realtime-2 向けに hello-realtime を更新し、電話でのデモ番号を提供しました @juberti;ディエゴ・カベサスは簡易的な GPT-Realtime-2 デモを投稿しました @diegocabezas01;レイ・フェルナンドは「ライブ翻訳の構築」に関するブロードキャストをホストしました @RayFernando1337。
Reachy Mini / ロボティクス音声インターフェースへの関心:クレマン・デラングは、ロボット音声ユースケースに対応できる支援先として Gradium、Kyutai、ElevenLabs といった音声 AI ラブに以前問いかけた後、誰が Reachy Mini に新しい音声機能を追加するかを尋ねました @ClementDelangue。
なぜこれが重要なのか
今回の発表により、音声エージェントは「チャットボットの周りに施された音声入出力のラッパー」から、フルデュプレックス(双方向同時通信)、ツール使用、長文脈処理、推論能力を備えたエージェントへと進化します。技術的な転換点は単に ASR(自動音声認識)や TTS(テキスト読み上げ)が向上したというだけでなく、低遅延のターンテイク、割り込み処理、長いコンテキスト、ツール呼び出しの透明性、調整可能な推論努力といった要素を、単一のリアルタイムループ内で統合した点にあります。これはカスタマーサポート、会議、アクセシビリティ、ライブ翻訳、ロボティクス、ブラウザやコンピュータの制御、テキストチャットでは遅すぎたり不自然だったりするハンズフリーワークフローにおいて極めて重要です。
最も重要な工学的示唆は、音声アプリはプロンプト応答型エンドポイントではなく、状態を保持するリアルタイムシステムとして設計される必要があるということです。OpenAI のプロンプティングガイドでは、開発者に対して推論努力の調整、前書き、ツール動作、不明瞭な音声からの回復、エンティティ抽出、長期間セッションの状態管理へと導くよう明示されています @OpenAIDevs。これは、音声エージェントの品質が、単なるモデル選択だけでなく、ハッチング設計(レイテンシ予算、中断セマンティクス、ツール呼び出し UX、会話メモリ、障害回復)にますます依存するようになることを示唆しています。
残された不確実性は配布に関するものです。API モデルは現在利用可能ですが、Simon Willison の観察 @simonw によると、ChatGPT の音声モードはまだこのアップグレードを受けていません。ChatGPT Voice が同様の機能を獲得するかどうか、またその時期次第では、消費者への影響ははるかに大きくなる可能性があります。それまでは、今回の発表は主に専門的なリアルタイムエージェントを構築する開発者とプラットフォームにとっての利益となります。
続きを読む
原文を表示
OpenAI launched realtime-1.5 3 months ago, but it was a relative drop in the bucket because it was still 4o based intelligence (a +5% bump in Big Bench Audio). You could tell the sheer confidence in today’s realtime-2 release (with a +15.2% bump in BBA), and it was appropriately well received:
As the blogpost explains, 3 models are being released, which one might simplify to “voice-in, voice-out, and voice-to-voice”:
The focus is less about “voice quality”, and more on usability. TLDR:
Preambles: Developers can enable short phrases before a main response, like “let me check that” or “one moment while I look into it”.
Parallel tool calls and tool transparency: The model can call multiple tools at once and make those actions audible with phrases like “checking your calendar” or “looking that up now,” helping agents stay responsive while completing tasks.
Stronger recovery behavior: The model can recover more gracefully by saying things like “I’m having trouble with that right now,” instead of failing or breaking.
Longer context: 32K → 128K
Stronger domain understanding: The model better retains specialized terminology, proper nouns, healthcare terms, and other vocabulary
More controllable tone and delivery: The model can better adjust its tone—speaking calmly, empathetically, or upbeat, based on context
Adjustable reasoning effort: Developers can now select from minimal, low, medium, high, and xhigh reasoning levels, with low as the default.
The Demo video showed off how the audio model is better tuned when the main speaker is speaking to someone else, so it stops interrupting so much:
AI News for 5/6/2026-5/7/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Top Story: GPT-Realtime-2 and OpenAI voice AI commentary
What happened
OpenAI launched three new streaming audio models in the Realtime API: GPT-Realtime-2, GPT-Realtime-Translate, and GPT-Realtime-Whisper. OpenAI positioned GPT-Realtime-2 as its “most intelligent voice model yet,” bringing “GPT-5-class reasoning” to real-time voice agents that can listen, reason, handle interruptions, use tools, and sustain longer conversations as they unfold @OpenAI. The companion models target live speech translation and transcription: GPT-Realtime-Translate supports streaming translation from 70+ input languages into 13 output languages, while GPT-Realtime-Whisper streams transcription/captions as speech is produced @OpenAI, @OpenAIDevs. OpenAI said the models are available in the Realtime API now, while ChatGPT voice upgrades are still pending: “Stay tuned, we’re cooking” @OpenAI. Sam Altman framed the launch around a behavioral shift: users increasingly use voice with AI when they need to “dump” lots of context, and OpenAI is also working on improvements to ChatGPT voice @sama.
Facts vs. opinions
Factual / directly claimed by OpenAI and evaluators
Model family: GPT-Realtime-2, GPT-Realtime-Translate, GPT-Realtime-Whisper are available in the Realtime API today @OpenAIDevs.
GPT-Realtime-2 capabilities: reasoning-oriented native speech-to-speech model for production voice agents; supports tool use/action, interruption recovery, longer conversations, and “GPT-5-class reasoning” per OpenAI’s wording @OpenAI, @reach_vb.
Context window: community/OpenAI-dev commentary reported 128K context for GPT-Realtime-2 voice agents @reach_vb; Artificial Analysis independently reported the context window increased from 32K to 128K, with 32K max output tokens @ArtificialAnlys.
Translation: GPT-Realtime-Translate supports live speech translation from 70+ input languages into 13 output languages @OpenAI, @reach_vb.
Transcription: GPT-Realtime-Whisper provides low-latency streaming transcription in the Realtime API for captions, notes, and continuous speech understanding @OpenAIDevs.
Prompting/control: OpenAI published a voice prompting guide covering reasoning effort, preambles, tool behavior, unclear audio handling, exact entity capture, and state maintenance in long sessions @OpenAIDevs.
Independent benchmarks: Scale AI reported GPT-Realtime-2 took the top spot on its Audio MultiChallenge S2S leaderboard, with instruction retention rising from 36.7% to 70.8% APR versus GPT-Realtime-1.5 and strong performance on voice editing/real-time repair @ScaleAILabs.
Independent benchmarks: Artificial Analysis reported 96.6% on Big Bench Audio speech-to-speech reasoning, 96.1% on its Conversational Dynamics benchmark, average time-to-first-audio of 2.33s at high reasoning and 1.12s at minimal reasoning, and unchanged audio pricing of $1.15/hour input and $4.61/hour output @ArtificialAnlys, @ArtificialAnlys.
Reasoning-effort controls: Artificial Analysis reported adjustable reasoning levels: minimal, low, medium, high, xhigh, with low as default @ArtificialAnlys.
Enterprise/product evals: Glean said GPT-Realtime-2 delivered a 42.9% relative increase in helpfulness over the previous version in internal evals for real-time organizational voice interactions @glean. Genspark said its Call for Me Agent moved to GPT-Realtime-2 and saw +26% effective conversation rate and fewer dropped calls @genspark_ai.
Opinions / interpretation / commentary
Supporters described the launch as a “big step forward” for voice agents @sama, “total realtime victory” @reach_vb, and the first speech-to-speech model good enough for “real work” in complex voice agents @kwindla.
A more cautious view: Simon Willison noted the announcement does not mean ChatGPT Voice Mode itself has upgraded yet; the ChatGPT upgrade “sounds” like it is coming soon @simonw, @simonw.
Interface skepticism: Will Depue compared audio to VR—frequently exciting, but historically not sticky as an interface—while arguing that real-time tool use, reasoning while speaking, and live translation are the kinds of capabilities that could make audio interfaces finally take off @willdepue.
Broader UX optimism: several commenters framed voice as more natural and bandwidth-efficient for humans @BorisMPower, a path toward Jarvis-like always-available computer agents @willdepue, or eventually displaced by even higher-bandwidth BCIs @iScienceLuvr.
Competitive context: Elon Musk pushed Grok Voice for customer support @elonmusk, underscoring that real-time voice support/customer-service automation is now a competitive surface across labs.
Technical details and benchmark data
GPT-Realtime-2
Native speech-to-speech / real-time voice model, released via OpenAI’s Realtime API @OpenAI.
Framed as “GPT-5-class reasoning” for voice agents @OpenAI.
Designed for agents that can:
reason mid-conversation,
use tools/take actions,
handle interruptions,
recover when users revise or repair speech,
sustain longer sessions with expanded context @OpenAI, @reach_vb.
Reported context: 128K tokens, up from 32K @ArtificialAnlys.
Reported max output: 32K tokens @ArtificialAnlys.
Inputs reported by Artificial Analysis: text, audio, and image @ArtificialAnlys.
Reasoning effort levels: minimal, low, medium, high, xhigh; default low @ArtificialAnlys.
Time-to-first-audio:
1.12s at minimal reasoning,
2.33s at high reasoning @ArtificialAnlys.
Pricing:
$1.15/hour audio input,
$4.61/hour audio output,
unchanged versus prior model according to Artificial Analysis @ArtificialAnlys.
Conversational features: supports short preambles before main responses—e.g. “let me check that”—and audible transparency during tool calls—e.g. “checking your calendar” @ArtificialAnlys.
Benchmarks
Scale AI Audio MultiChallenge S2S: GPT-Realtime-2 placed #1; instruction retention improved from 36.7% to 70.8% APR versus GPT-Realtime-1.5; strong voice editing when users repair/revise speech in real time @ScaleAILabs.
Artificial Analysis Big Bench Audio: GPT-Realtime-2 high variant scored 96.6%, reported as equal to Gemini 3.1 Flash Live Preview High and about ~13% above the previous highest result @ArtificialAnlys.
Justin Uberti separately summarized the improvement as 15 percentage points vs. GPT-Realtime-1.5 on Big Bench Audio, near saturation @juberti.
Conversational Dynamics / Full Duplex Bench subset: GPT-Realtime-2 minimal variant scored 96.1%, with strengths in pause handling and turn-taking @ArtificialAnlys.
GPT-Realtime-Translate
Live streaming speech translation from 70+ input languages to 13 output languages @OpenAI.
OpenAI cofounder Greg Brockman said real-time voice-to-voice translation has been an anticipated OpenAI application since the company’s early days and is now available for anyone to build with @gdb.
Vimeo demonstrated live dubbing with no pre-loaded captions, showing translations generated fully live @Vimeo.
Junling Zhang highlighted the new real-time translation model and encouraged API usage @jxnlco.
Boris Power said live translation “actually works incredibly well” and plans to use it regularly @BorisMPower.
GPT-Realtime-Whisper
Streaming transcription as people speak, for real-time captions, notes, and speech understanding @OpenAI.
Justin Uberti described it as “Whisper, but now with realtime streaming” and updated demos to use the new model @juberti.
Uberti also built a delay selector to expose the latency/accuracy tradeoff in a real-time typing demo @juberti.
Product integrations and demos
Glean: shipped real-time voice powered by GPT-Realtime-2, grounded in organizational context; internal evals showed 42.9% relative helpfulness increase over the previous version @glean.
Vimeo: demonstrated live dubbing using GPT-Realtime-Translate, with translations generated live and no pre-loaded captions @Vimeo.
Genspark: upgraded its Call for Me Agent to GPT-Realtime-2; Genspark Realtime Voice is next; claimed sharper reasoning, tighter instruction following, +26% effective conversation rate, and fewer dropped calls @genspark_ai.
Gradient Bang / game-agent demo: Kyle Windland said GPT-Realtime-2 is the first OpenAI speech-to-speech model good enough for his voice agents that do “real work,” showing it as the ship AI in a complex agent with tool calls and subagents @kwindla.
Voice-controlled market dashboard: Levin Stanley demoed GPT-Realtime-2 controlling an interface by intent—“Focus on Apple,” “How did it do over the last 30 days?”, “Go back”—arguing that real-time interruption and reasoning change the UI loop from navigation to direction @levinstanley.
Realtime demos: Justin Uberti updated hello-realtime for GPT-Realtime-2 and provided a phone demo number @juberti; Diego Cabezas posted a quick GPT-Realtime-2 demo @diegocabezas01; Ray Fernando hosted a “Building a Live Translator” broadcast @RayFernando1337.
Reachy Mini / robotics voice interface interest: Clement Delangue asked who would add the new voice capabilities to Reachy Mini @ClementDelangue, after earlier asking voice AI labs such as Gradium, Kyutai, and ElevenLabs who could help with a robot voice use case @ClementDelangue.
Why this matters
The launch pushes voice agents from “speech I/O wrapper around a chatbot” toward full-duplex, tool-using, long-context, reasoning agents. The technical shift is not just better ASR or TTS; it is the combination of low-latency turn-taking, interruption handling, longer context, tool-call transparency, and adjustable reasoning effort in a single real-time loop. That matters for customer support, meetings, accessibility, live translation, robotics, browser/computer control, and hands-free workflows where text chat is too slow or awkward.
The most important engineering implication is that voice apps now need to be designed as stateful real-time systems, not prompt-response endpoints. OpenAI’s prompting guide explicitly points developers toward reasoning-effort tuning, preambles, tool behavior, unclear-audio recovery, entity capture, and long-session state management @OpenAIDevs. This suggests voice-agent quality will increasingly depend on harness design: latency budgets, interruption semantics, tool-call UX, conversational memory, and failure recovery—not just raw model selection.
The remaining uncertainty is distribution. The API model is available now, but ChatGPT voice mode has not yet received the upgrade, per Simon Willison’s observation @simonw. If and when ChatGPT Voice gets the same capabilities, the consumer impact could be much larger. Until then, the launch primarily benefits developers and platforms building specialized real-time agents.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み